概览:本文介绍了阻塞I/O、非阻塞I/O、多路复用I/O和异步I/O 四种模型,在实际的操作系统和计算机中I/O本质总是阻塞的,通过返回fd状态和轮询的方式来使I/O在应用层不阻塞,然后通过多路复用的方式更高效实现这种不阻塞的效果。然后介绍了Node中异步I/O的实现,由于计算机本身的设计使得并不存在真正异步I/O,需要通过线程池来模拟出异步I/O。
I/O模式
I/O模式介绍
1.文件描述符
类unix操作系统将I/O抽象为文件描述符(file description,下面简称fd),可读/可写流都可以看做读一个"文件",打开文件和创建Socket等都是获取到一个fd文件描述符。
2.操作I/O时发生了什么
操作流就是读和写(read/write),下面用read进行说明。read时需要CPU进入内核态等待操作系统处理数据,等操作系统完成后会响应结果。用户态切换到内核态仅仅是CPU执行模式切换,线程本身并未改变,CPU进入内核态才能进行外部设备(外设)的准备工作,从而支持后续数据复制到内核缓冲区,完成后再切换回用户态,然后真正的读数据到用户程序。
3.五种I/O模式

如图,操作系统有5种I/O模式。
- blocking
- nonblocking
- multiplexing
- signal-driven (很少使用,不介绍)
- async I/O 可以的话,不妨看完下面详细介绍后再回过头看这张图,对5种模式进行对比,相信你认识一定会更加深刻。
阻塞I/O (blocking)
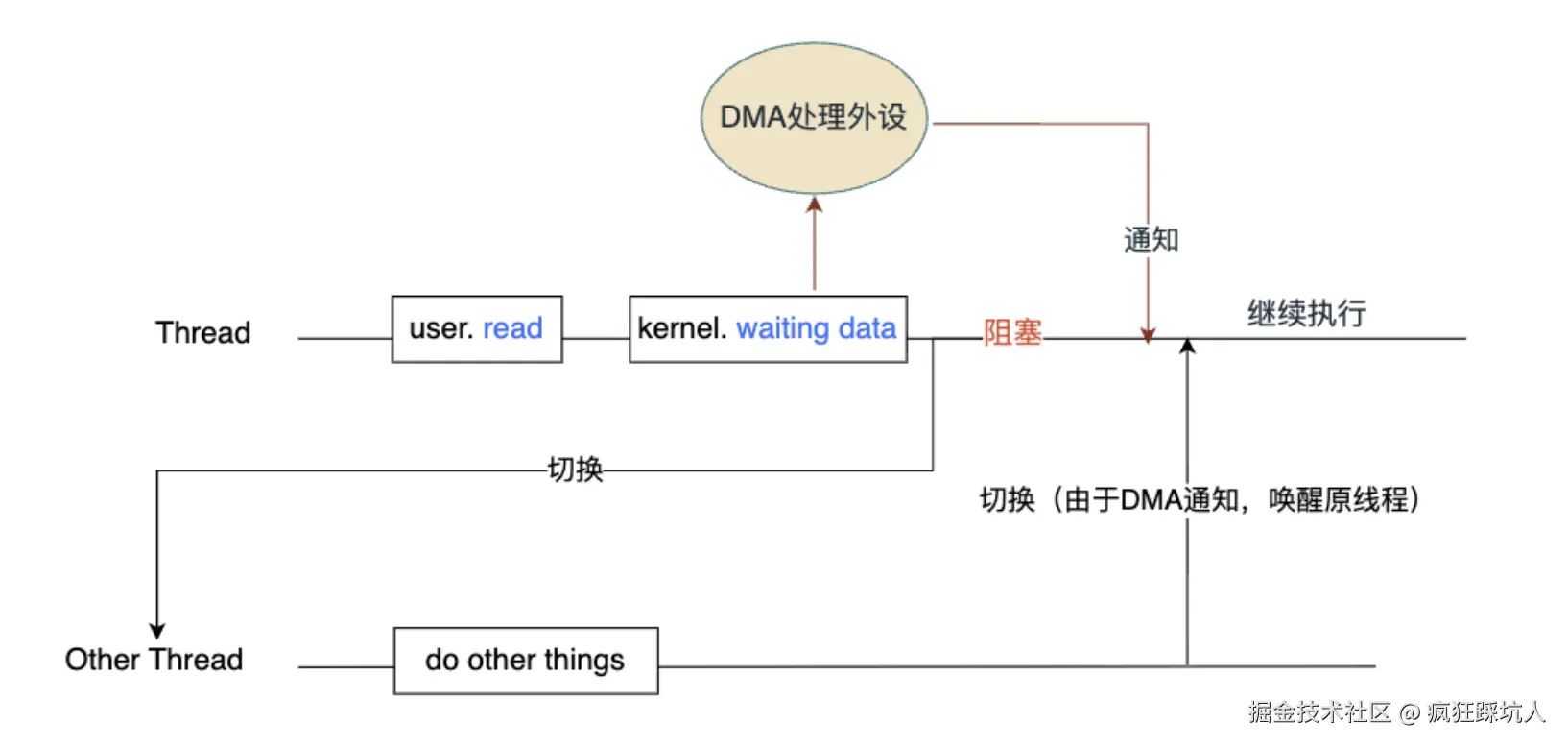
- 当用户态调用read API读流时,操作系统陷入内核态开始准备数据。
- 此时read是阻塞的。CPU是会切换到其他线程,做其他事的。原因就是现代计算机(采用了DMA技术)对于这种磁盘读取工作中的数据传输部分CPU是不参与 的,交给了DMA控制器 负责,等处理好了DMA会发出一个CPU中断,通知CPU切换回原来的线程继续处理。
- 所以线程一定是阻塞的,当前线程的执行权让出去了,也就是说没有CPU时间片继续执行当前线程。
- 内核态数据准备完成,原来的Thread被唤醒,继续执行,表现为API读流返回了数据。
P.S. DMA是通知操作系统,唤醒原来Thread,继续执行。并不是通知Thread的具体某段程序执行,而是之前被阻塞时执行到哪,现在就继续执行哪里。
非阻塞I/O (non-blocking)
为甚么还要有非阻塞I/O? 显然,阻塞I/O会导致后面的代码不能继续执行,在要处理多个I/O的情况下就是串行发起I/O操作了。而非阻塞I/O就是希望发起I/O操作是并发的(不用等上一个流操作结束才发起下一个)。
非阻塞I/O: 调用read去读fd的数据时,立即返回fd的状态结果,不阻塞后面代码的执行。此时操作系统就需要考虑如何实现这种非阻塞,如管理多个I/O流。
c++
/*伪代码*/
fd = openStream(); //打开文件,创建Socket等都能获得一个fd,不阻塞
n = read(fd); //读取这个fd的数据,不阻塞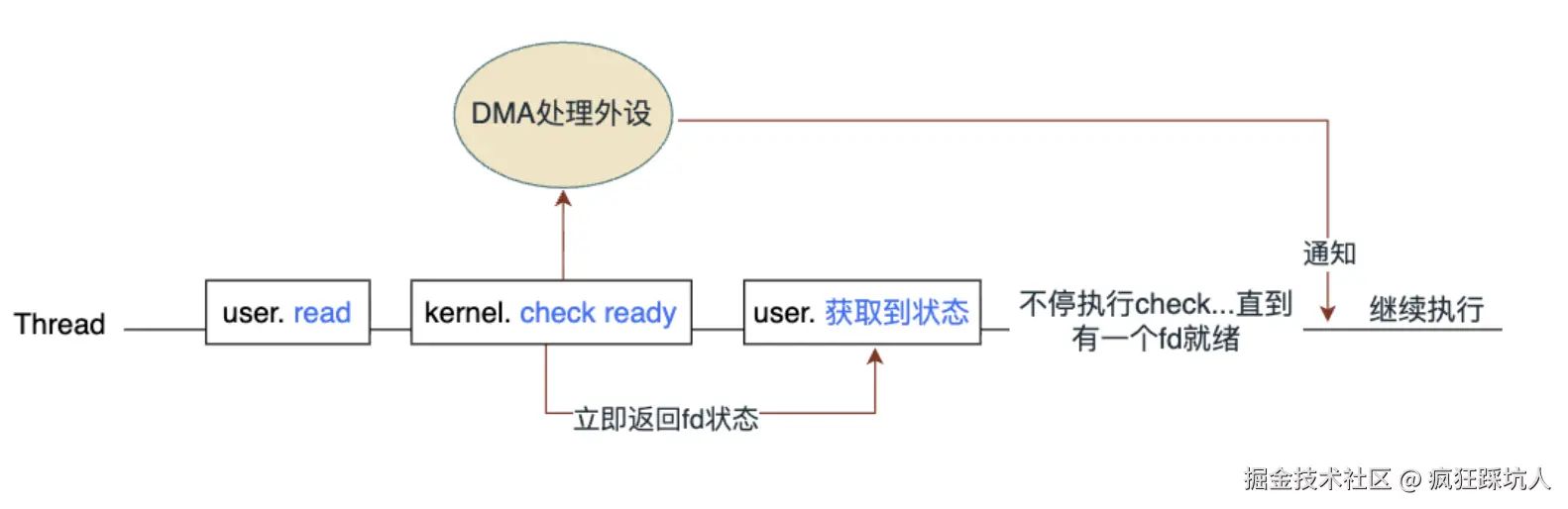
- 当用户态调用read API读流时,操作系统陷入内核态检查数据是否就绪。
- 此时read是不阻塞的,可以继续执行后面的代码。但是后续需要不断「check」(就是read)来检查数据是否就绪。
- DMA通知唤醒Thread(如果Thread一直都是激活状态,不存在被唤醒这一动作)。「check」发现有fd的数据就绪,就进行数据处理。
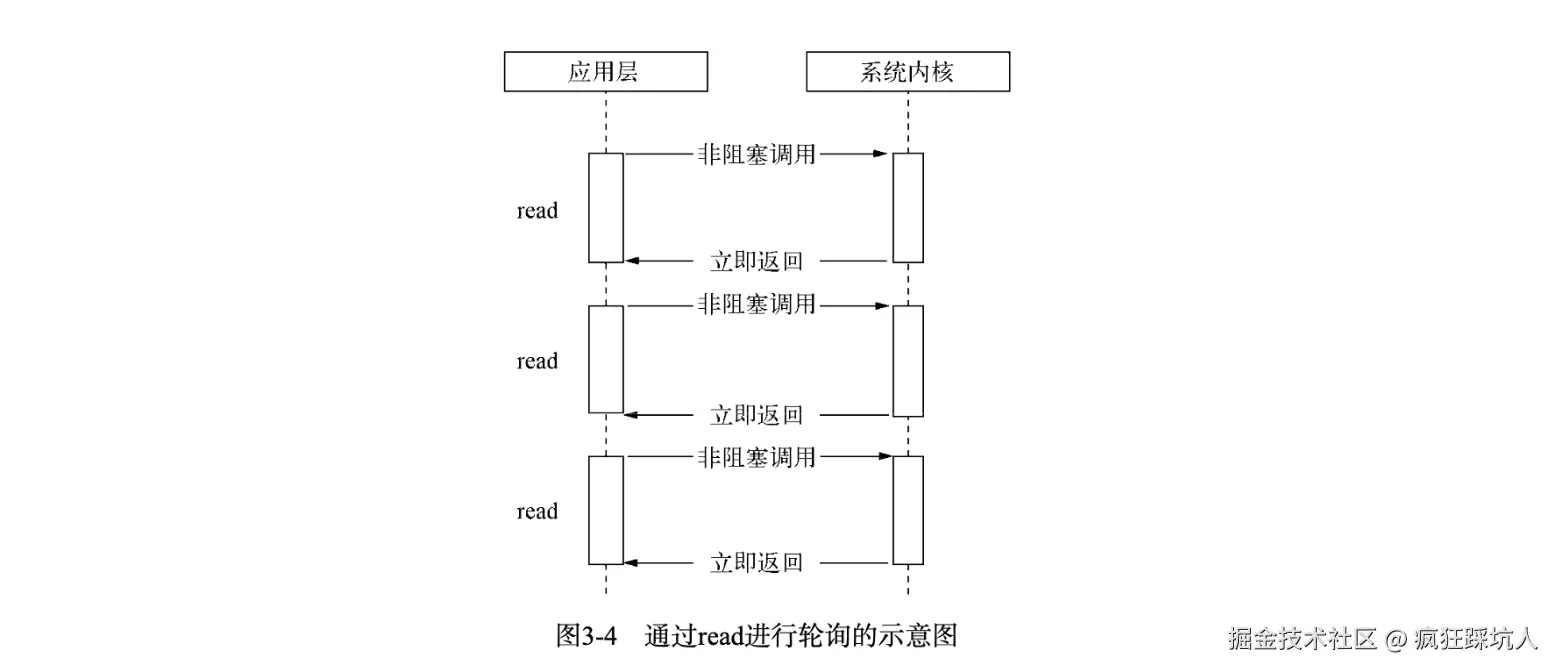
非阻塞I/O 是指read读数据能立即返回fd状态,而不用等待,但是需要你主动去read。如下图所示(图来自《深入浅出Nodejs》):
C++伪代码实现
c++
// 文件描述符集合
std::vector<int> fds = {fd1, fd2, fd3}; // 假设有3个需要监控的文件描述符
// 设置为非阻塞模式
for(auto& fd : fds) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
// 轮询循环
while(true) {
bool all_done = true;
// 应用层轮询每个文件描述符
for(auto fd : fds) {
char buffer[1024];
ssize_t n = read(fd, buffer, sizeof(buffer)); // 非阻塞调用
if(n > 0) {
// 成功读取到数据
process_data(buffer, n);
}
else if(n == 0) {
// 连接关闭
remove_fd(fd);
}
else if(n < 0) {
if(errno == EAGAIN || errno == EWOULDBLOCK) {
// 数据未就绪,立即返回 - 继续轮询其他fd
continue;
} else {
// 真实错误
handle_error(fd);
}
}
// 检查是否还有需要处理的数据
if(has_pending_operations()) {
all_done = false;
}
}
// 可选的短暂休眠避免CPU占用过高
if(all_done) {
usleep(1000); // 1s休眠
}
// 退出条件
if(should_exit) break;
}此时,还需要我们手动一个个检查fd的状态。下面就介绍I/O多路复用,它做到了批量监听多个fd状态,不用我们手动去管理监听每一个fd了。
I/O多路复用(multiplexing)
类unix操作系统下,多路复用的方式有 select, poll, epoll(macos/freeBSD 上的替代品是 kqueue)。而在windows下面则直接使用IOCP(基于线程池的异步I/O方式),下面会介绍。 select、poll分别早在1983年、1986年就出现了,而epoll知道Linux2.6(大约2003)年才出现。 现代系统都是非阻塞I/O大都采用epoll或者IOCP的方式作为主流I/O并发方案了。
select
通过select()系统调用来监视多个fd的数组,返回一个int值(表示了fd就绪的个数),当调用select会阻塞,直到有一个fd就绪。
c++
int select(int maxfdp, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);
//maxfdp:被监听的文件描述符的总数;
//readset:读fd集合
//writeset:写fd集合
//exceptset
//timeout:用于设置select函数的超时时间,即告诉内核select等待多长时间之后就放弃等待。
//返回值:超时返回0;失败返回-1;成功返回大于0的整数,这个整数表示就绪描述符的数目。下图展示了select方式(图来自《深入浅出Nodejs》):
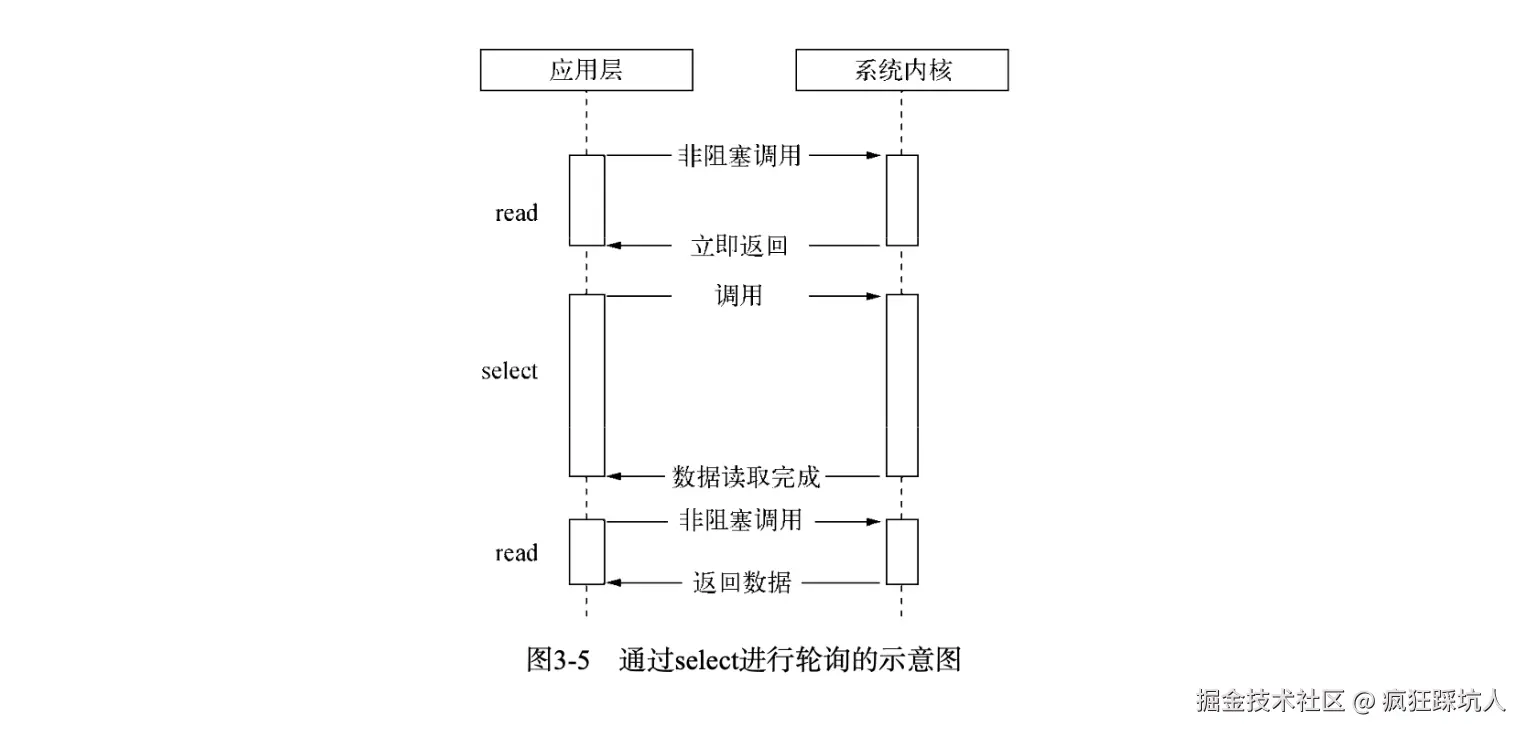
具体过程大致如下: 1、调用select()方法,上下文切换转换为内核态 2、将fd从用户空间复制到内核空间 3、内核遍历所有fd,查看其对应事件是否发生 4、如果没发生,将进程阻塞,当设备驱动产生中断或者timeout时间后,将进程唤醒,再次进行遍历 5、返回遍历后的fd 6、将fd从内核空间复制到用户空间
poll
poll是对select差不多,当调用poll会阻塞。但进行了一定改进:使用链表维护fd集合(select内是使用数组),这样没有了maxfdp的限制。
c++
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// fds:polld结构体集合,每个结构体描述了fd及其事件
// nfs:指定 `fds`数组中的元素个数,类型 `nfds_t`通常为无符
// timeout:等待时间,`-1`表示阻塞等待直到有事件发生;`0`表示立即返回(非阻塞);大于 `0`则表示最长等待时间
// 返回值:超时返回0;失败返回-1;成功返回大于0的整数,这个整数表示就绪描述符的数目。
c++
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 需要监视的事件(输入) */
short revents; /* 实际发生的事件(输出) */
};下图展示了poll方式(图来自《深入浅出Nodejs》):
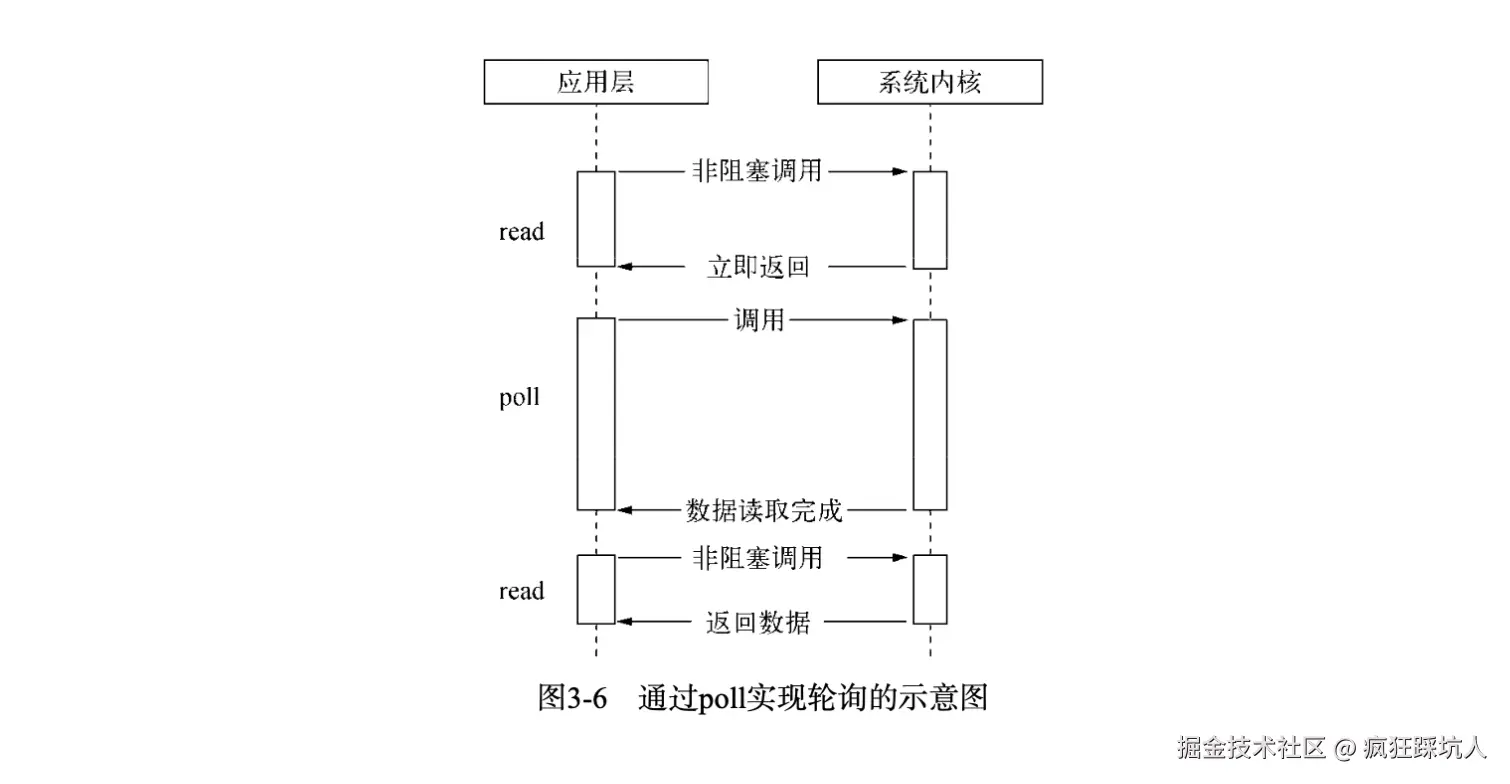
poll方式伪代码
c++
// 主循环
while (1) {
int ret = poll(fds, nfds, 3000); // 等待 3 秒
if (ret < 0) {
perror("poll error");
break;
} else if (ret == 0) {
printf("[poll] 超时,没有事件\n");
continue;
}
// 遍历所有 fd,检查哪些 revents 有标志
for (int i = 0; i < nfds; i++) {
if (fds[i].revents & POLLIN) {
char buf[1024];
ssize_t n = read(fds[i].fd, buf, sizeof(buf) - 1);
if (n > 0) {
buf[n] = '\0';
process_data(buf, n, fds[i].fd);
} else if (n == 0) {
// EOF,连接关闭
remove_fd(fds, &nfds, i);
i--; // 数组被压缩,重新检查当前位置
} else if (n < 0 && errno != EAGAIN && errno != EWOULDBLOCK) {
perror("read error");
remove_fd(fds, &nfds, i);
i--;
}
}
}
if (nfds == 0) {
printf("所有 fd 都关闭了,退出。\n");
break;
}
}poll和select的区别不大,都是要遍历fd看是否有就绪。最大的区别在于poll没有监视的fd集合大小限制(因为采用的链表),而select有大小限制(因为内部采用的数组存储,可以通过参数maxfdp修改,默认1024)。
epoll
epoll_create创建一个 epoll 实例,同时返回一个引用该实例的文件描述符
c++
int epoll_create(int size);epoll_ctl 会将文件描述符 fd 添加到 epoll 实例的监听列表里,同时为 fd 设置一个回调函数,并监听事件 event,如果红黑树中已经存在立刻返回。当 fd 上发生相应事件时,会调用回调函数,将 fd 添加到 epoll 实例的就绪队列上。
c++
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd 即 epoll_create 返回的文件描述符,指向一个 epoll 实例
// 表示要监听的目标文件描述符
// op 表示要对 fd 执行的操作, 例如为 fd 添加一个监听事件 event
// event 表示要监听的事件
// 返回值 0 或 -1,表示上述操作成功与否。epoll 模型的主要函数epoll_wait,功能相当于 select。调用该函数时阻塞,等待事件通知唤醒进程。
c++
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
// epfd 即 epoll_create 返回的文件描述符,指向一个 epoll 实例
// events 是一个数组,保存就绪状态的文件描述符,其空间由调用者负责申请
// maxevents 指定 events 的大小
// timeout 类似于 select 中的 timeout。如果没有文件描述符就绪,即就绪队列为空,则 epoll_wait 会阻塞 timeout 毫秒。如果 timeout 设为 -1,则 epoll_wait 会一直阻塞,直到有文件描述符就绪;如果 timeout 设为 0,则 epoll_wait 会立即返回
// 返回值表示 events 中存储的就绪描述符个数,最大不超过 maxevents。下图展示了epoll方式(图来自《深入浅出Nodejs》):
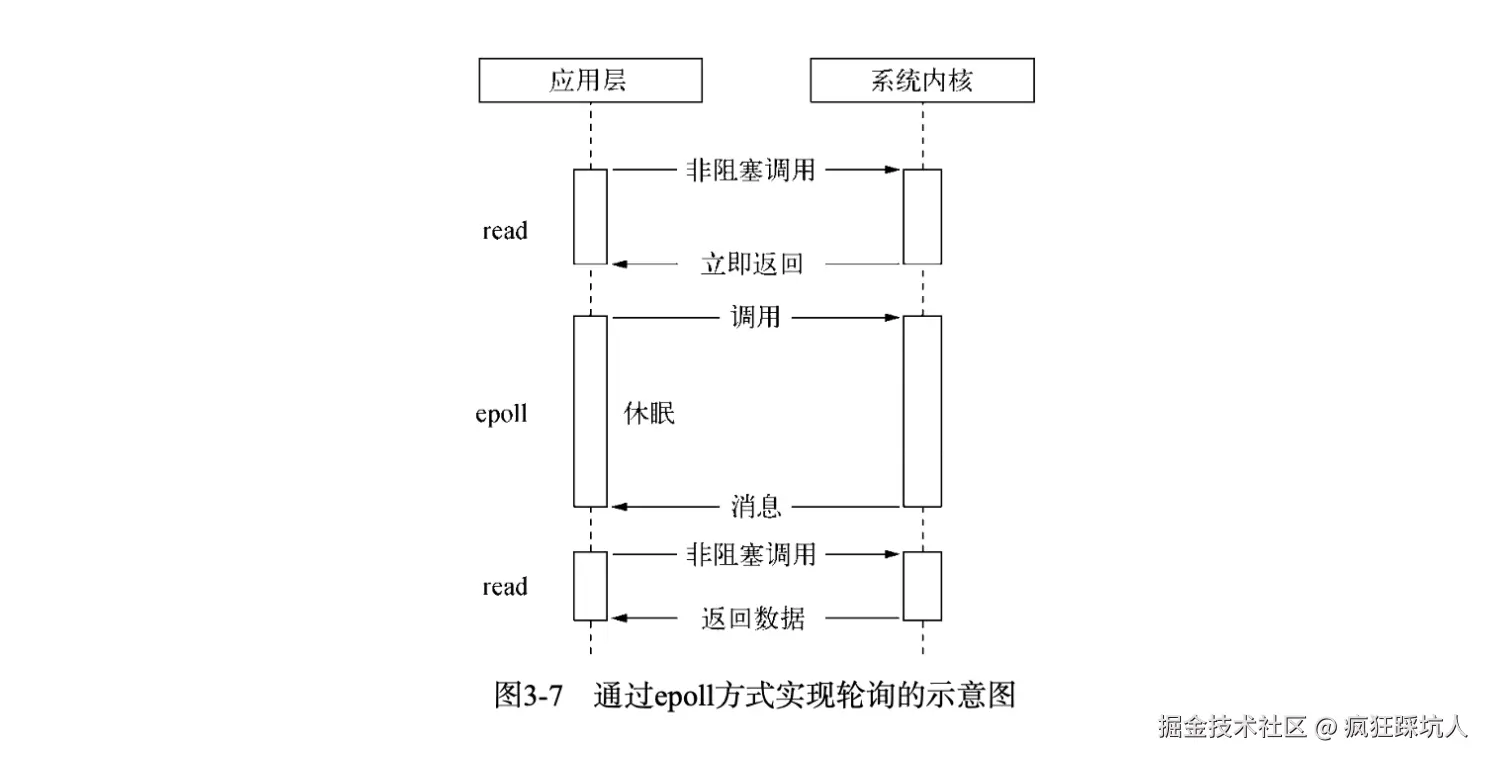 epoll方式伪代码
epoll方式伪代码
c++
int epfd = epoll_create(1024);
struct epoll_event ev, events[MAX_CONN];
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd, &ev);
while (1) {
int n = epoll_wait(epfd, events, MAX_CONN, -1);
for (int i = 0; i < n; i++) {
if (events[i].events & EPOLLIN) {
// 处理可读事件
}
}
}select和poll存在的缺点:
- 内核线程需要遍历一遍fd集合,返回给用户空间后需要应用层再遍历一遍fd数组。
- 每次select/poll都会内核空间到用户空间拷贝fd集合。
- 性能开销随fd线性增加,时间复杂度O(n)
epoll主要改进点:
- 通过
epoll_ctl提前给fd设置一个事件回调函数 ,fd上有事件触发了就执行回调函数,把fd放到一个就绪队列上,这样在内核线程是不存在遍历fd集合的,时间复杂度O(1)。 epoll_wait不会对fd集合在内核空间和用户空间拷贝, 而是"利用mmap()文件映射内存加速与内核空间的消息传递,减少拷贝开销。"
到这里,我们可以试着总结non-blocking和多路复用区别和联系。 区别:
- non-blocking I/O:靠不断"主动轮询"实现不阻塞
- I/O 多路复用:靠"事件通知 + 轮询"实现更高效的不阻塞 个人理解,广义的来说,多路复用本身也是一种非阻塞I/O。
异步I/O
尽管epoll已经利用了事件来降低CPU的耗用,但是休眠期间CPU几乎是闲置的,对于当前线程而言利用率不够,那么是否有一种理想的异步I/O呢?
下图展示了理想的异步I/O(图来自《深入浅出Nodejs》):
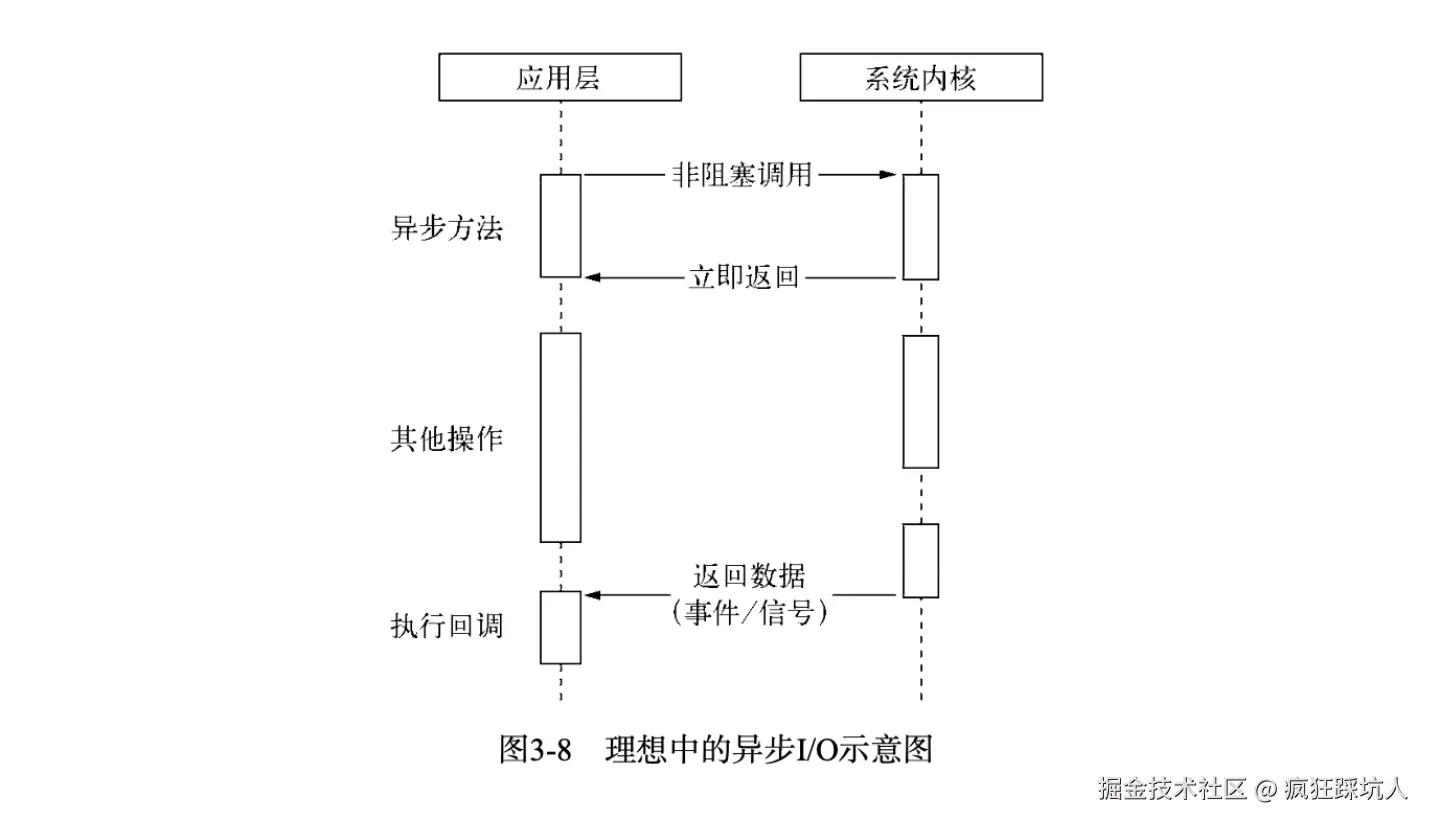
真正的异步I/O是在操作流时(发起异步操作)即不阻塞后续的代码执行,又不需要自己去主动轮询(read),只需要内核通知应用层执行回调(并且数据从内核空间读取到用户空间也是不阻塞的)。很遗憾,这种异步I/O几乎不存在(之所以说几乎,是因为Linux原生提供了一种这样的异步I/O------AIO,但存在缺陷)。
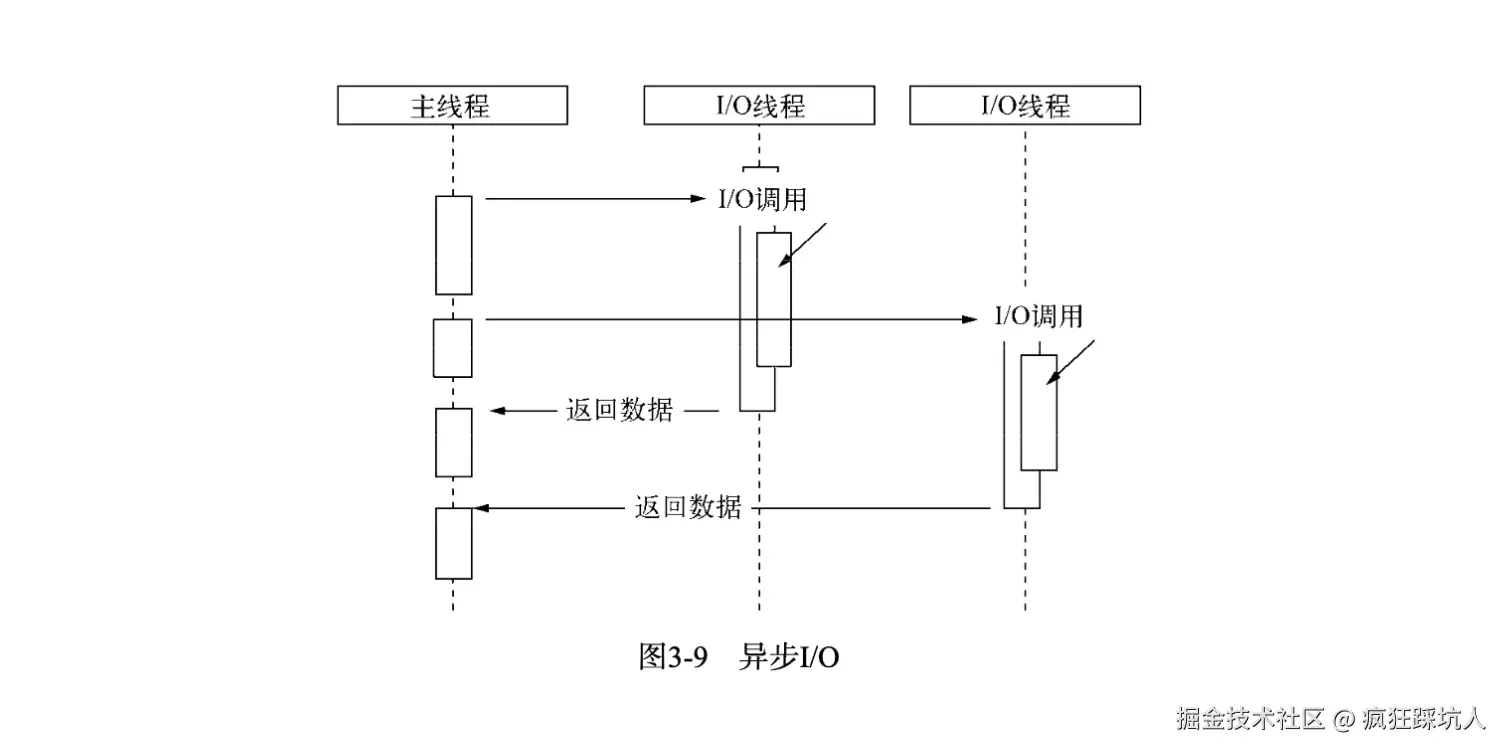
现实中的异步I/O,基本上都是通过线程池的方式来实现的,windows的IOCP也是内核级别实现了线程池。
在Node单线程中,通过让其他部分线程进行「阻塞I/O」或者「非阻塞I/O+轮询技术」来完成数据获取,等数据获取完成后通知主线程执行回调。此时主线程是不会让出CPU执行权的,可以一直继续执行其他代码。这样就实现了异步I/O。
下图展示了线程池模拟的异步I/O(图来自《深入浅出Nodejs》):
由于Windows和*nix的平台差异,Node提供了libuv作为抽象封装层来对不同平台做兼容性判断。 下图展示了Node的libuv架构(图来自《深入浅出Nodejs》):
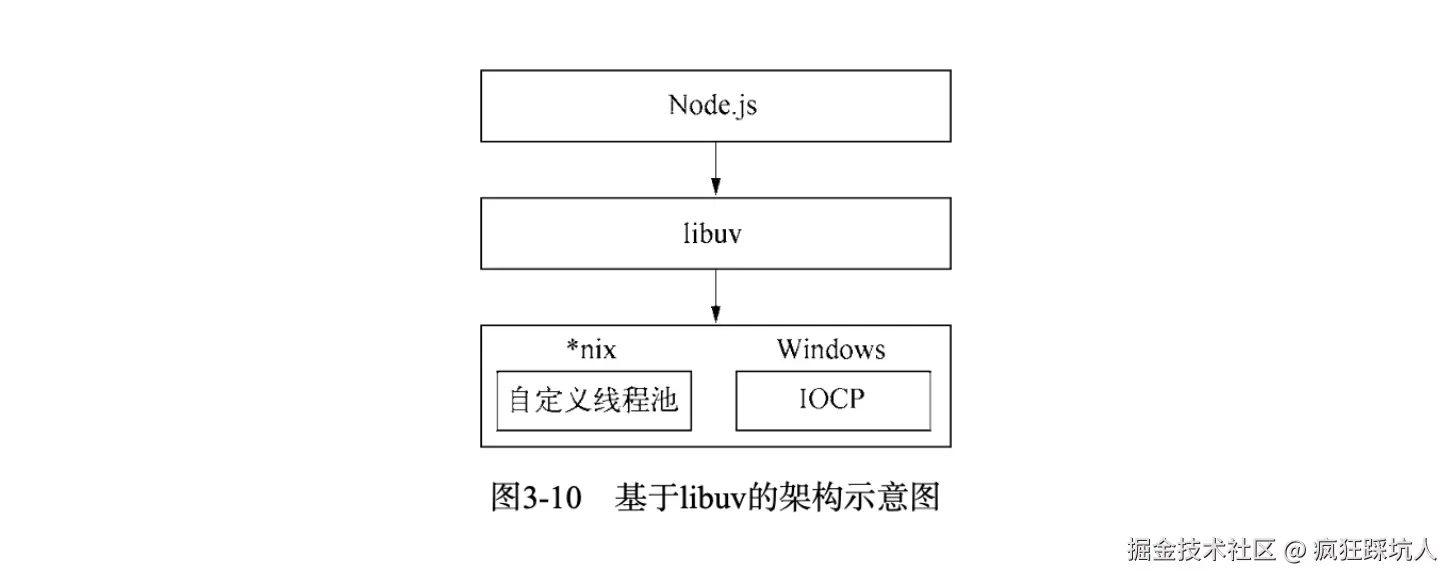
Node的事件循环
请求对象 :一个异步I/O的发起,libuv会产生一个封装好的请求对象。比如fs.open会产生一个FSReqWrap的对象。
观察者: 可以理解成观察者模式中的观察者,它主要是观察判断事件队列中是否有事件了,当有事件了就需要去处理这个事件。
这里我用一张流程图说明发起异步I/O是如何被线程池执行,然后通过事件通知主线程的流程。
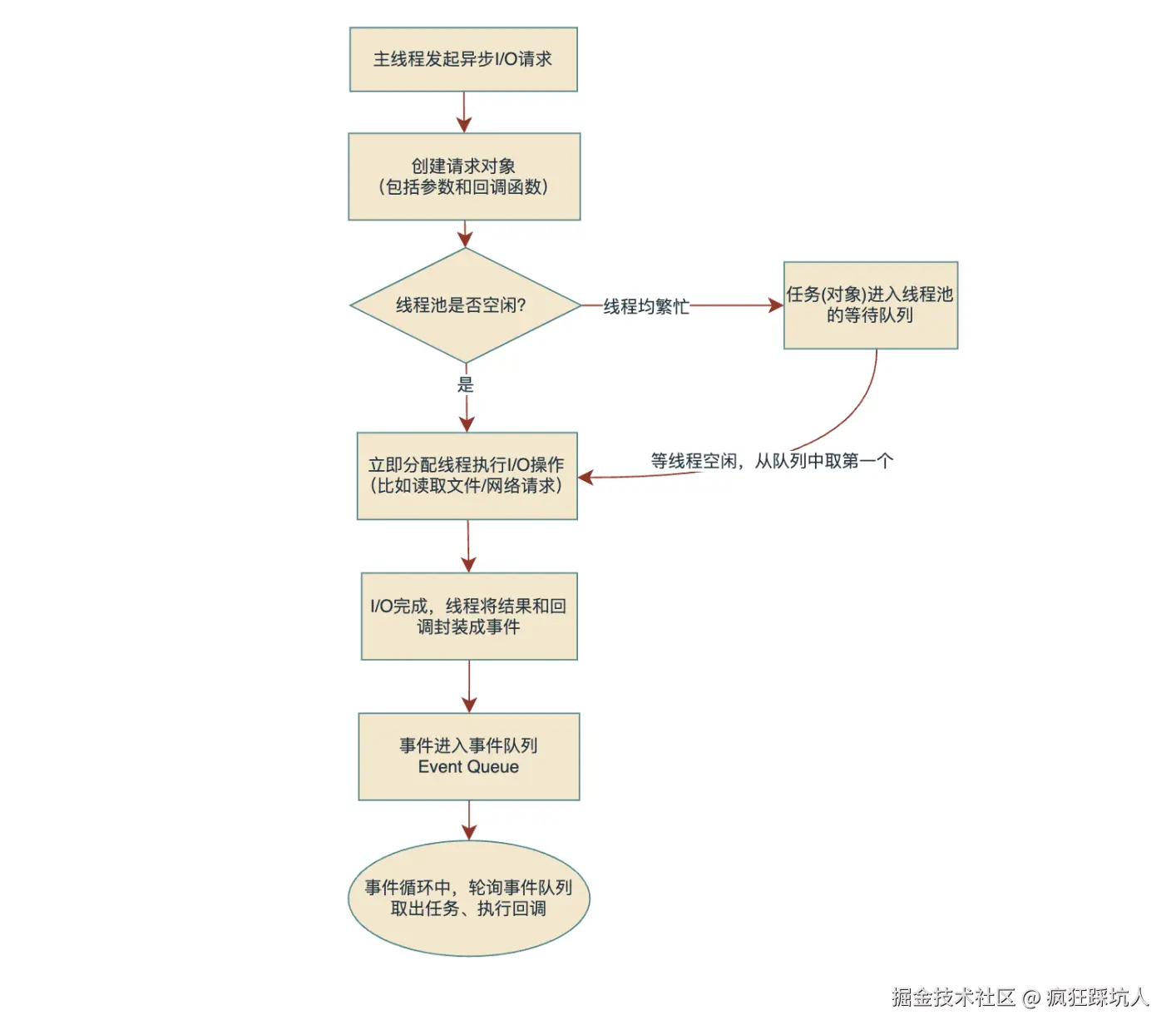
当异步任务执行的结果放入了事件队列,此时观察者 会在主线程同步任务执行完后,查看事件队列中是否有事件任务,有则取出执行。等这个任务(同步代码)执行完后接着取下一个任务执行,一直循环,这就是Node的事件循环
P.S.这里的事件队列是一个笼统的队列概念,可以理解成包括宏任务队列和微任务队列。
总结
本文介绍了阻塞I/O、非阻塞I/O、多路复用I/O和异步I/O 四种模型,在实际的操作系统和计算机中I/O本质总是阻塞的,通过返回fd状态和轮询的方式来使I/O在应用层不阻塞,然后通过多路复用的方式更高效实现这种不阻塞的效果。然后介绍了Node中异步I/O的实现,由于计算机本身的设计使得并不存在真正异步I/O,需要通过线程池来模拟出异步I/O。
在多路复用中,结合C++伪代码和图示的方式展示了select/poll/epoll的原理和差异,Linux中通常使用epoll(mac中有类似的kqueue)来实现非阻塞I/O,具备不用遍历fd集合和反复拷贝fd集合的性能优点。
最后,介绍了基于线程池的异步非阻塞I/O的实现原理,再结合事件队列和观察者实现了Node事件循环。
参考资料
Select、Poll、Epoll、 异步IO 介绍 【操作系统】I/O 多路复用,select / poll / epoll 详解 深入浅出Nodejs