前段时间,我们报道过一个非常有趣的现象 ------ 在求医问药这件事上,越来越多的人开始求助于 AI 了,尤其是在病因难以明确的情况下。有人甚至声称 AI 帮自己分析出了求医十年都未查出结果的「疑难杂症」(参见《求医十年,病因不明,ChatGPT:你看起来有基因突变》)。
在 GPT-5 的发布会上,Sam Altman 甚至请来了一位癌症患者,听其讲述 GPT-5 如何在她最无助的时候帮忙解读活检报告、权衡风险,这让她可以带着对自己病情的清晰认知与需要咨询的重要问题走进诊室。

随着 GPT-5 等顶尖模型在现实生活中变得越来越实用,这样的故事会越来越多。而这种变化之所以发生,一方面离不开模型本身「智能」的提升,另一方面也得益于整个智能系统对各类信息综合理解能力的进化。
值得注意的是,这些信息有个共同点。无论是病历里的化验单、影像报告、基因检测表,还是医生的文字诊断和患者的自述,它们虽然以不同模态存在,但归根结底,它们都通过一种名为「文本」的载体来承载。
如果能让 AI 真正看懂这些「文本」里隐藏的所有信息,那它能做的就不仅仅是「读懂文字」(当前有些 AI 虽然支持上传图像,但本质仍是简单地识别上面的文字),而是具备了对多模态信息的「立体化综合理解」。这不仅是大模型深入医疗、金融等领域的「刚需」,也是其以机器人等形式真正走入物理世界的关键。
也正是在这样的技术演化背景下,一个新的讨论方向正在浮现。在今年的 PRCV 大会上,合合信息提出了一个颇具代表性的概念 ------「多模态文本智能」,并举办了以此为主题的精彩论坛。
这一概念的提出,为从业者提供了一个相对清晰的聚焦点,也让多模态研究有了更具体的落脚处。在论坛上,来自高校与企业的研究者围绕感知、认知、决策等关键环节展开讨论,试图厘清多模态文本智能尚待解决的那些难题。
多模态文本智能,研究啥?
文本是人类对客观世界认识、理解和总结的沉淀,它们广泛存在于文字、图像、视频等多模态的媒介形式之中,具有极高的信息密度。正是依托于这些高密度的文本数据,本轮人工智能浪潮才得以实现前所未有的突破。
但迄今为止,AI 对文本的利用仍停留在表层,因为现有的技术还不足以把文本中沉淀的东西完整地「翻译」成机器可以理解的语言。这类「难以翻译」的文本数目惊人,仅 PDF 就可以达到 10B 级别。
小红书 hi lab 团队算法工程师燕青在现场举了一些直观的例子,比如有些文本因为包含复杂的表格、公式而变得难以破解:

有些文本可能用一种并不常用的方式书写:

即使版式、书写方式都没有跳出常规,文本也会因多种信息的交织而变得复杂,比如合同的条款效力与签名位置相关,财报的数据陈述需对照表格验证,医疗报告的诊断结论依赖影像佐证......
从这些角度来看,原有的研究方向------无论是 OCR、文档智能抑或当前最火的多模态大模型------都不足以支撑这种深层次的理解,难以触及信息背后的逻辑、结构与语义关联。
正因如此,「多模态文本智能」被提出。它试图让 AI 突破表层语义,实现对文本中多模态信息的「立体化综合理解」,从而让 AI 真正具备「读懂」世界并主动采取行动的能力。
同时,他们也指出,要让这种愿景真正实现,必须拆解成更细的技术路径:从感知到认知再到决策。这三层就像人类理解世界的过程:先看清楚,再想明白,最后做判断。
目前,每一层都有亟待解决的问题,论坛嘉宾就此展开了讨论。
感知与识别
让机器「看清」文本
感知层面的任务非常明确,就是让 AI 准确识别来自不同来源的文字、图像、表格、公式、印章、签名等要素,并理解它们在空间与语义上的关系。
但就是这看起来最基础的一步,做起来却困难重重。文本模糊不清、版式复杂、语言多样等因素都会影响识别结果,甚至还会诱发幻觉。

针对这些问题,现场嘉宾介绍了多种应对方法。
合合信息图像算法研发总监郭丰俊介绍了他们在智能文档处理方向的进展。可以看到,经过多年的摸索,他们已经把「智能文档处理」这件事情做成了一个技术体系。文档图像底层视觉处理、文字 / 文档识别、版面分析与还原、通用文档解析与抽取等都是他们的重点研发方向。每个方向都有很多棘手的子任务,比如底层视觉处理方向有去摩尔纹、弯曲矫正、手写去除;文字 / 文档识别方向有文字识别、表格识别、场景文字识别、财报识别等。要形成这样一个较为完整的技术体系,往往需要长期的积累与验证,不可能在短时间内完成。
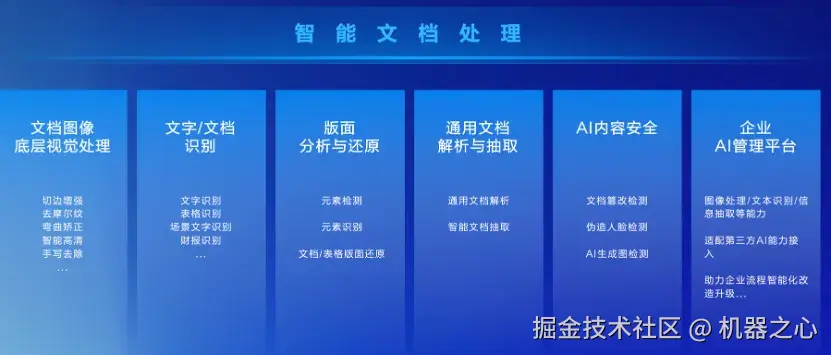
在现场,郭丰俊展示了部分子任务的实际效果。比如,在试卷还原场景中,他们的算法可以将卷面上密集、交错的笔迹完整去除,并通过滤镜生成干净、可读性极高的图像。

在去除摩尔纹这一难题上,他们的技术表现同样令人印象深刻。

而且,这些技术已经在他们的王牌产品 ------ 扫描全能王中得到应用。
论坛上的另外两位嘉宾 ------ 华中科技大学教授刘禹良和小红书 hi lab 团队算法工程师燕青则介绍了他们在文档解析方面的进展,只不过技术思路略有不同。
刘禹良介绍的 MonkeyOCR 可用于英文和中文文档解析,它采用 Structure-Recognition-Relation(结构 - 识别 - 关系)三元组解析范式,可以快速、精准地识别 PDF 等文档并提取信息。这一范式简化了模块化方法的多工具流水线,同时避免了使用多模态大模型处理全页文档时的低效问题。目前,该项目在 GitHub 上已经有 6000 多 star。
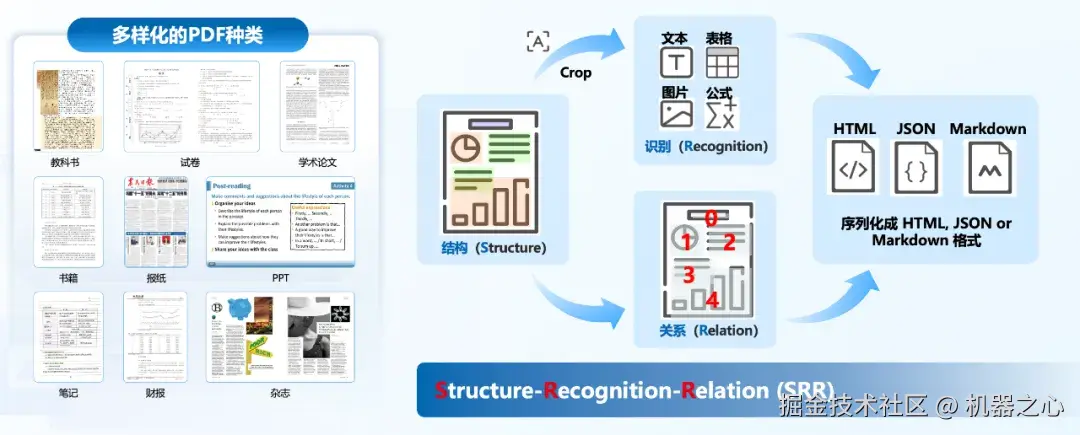
燕青介绍的 dots.ocr 支持多语言文档的解析,能够在单一模型中统一完成版面检测、文本识别、表格解析、公式提取等任务,并保持良好的阅读顺序。他们之所以在一个模型中完成这些任务,是因为他们相信这些任务之间可以相互促进,为彼此提供更多的 context,从而达到更高的性能上限。目前,该项目的 star 量已经超过了 5000。
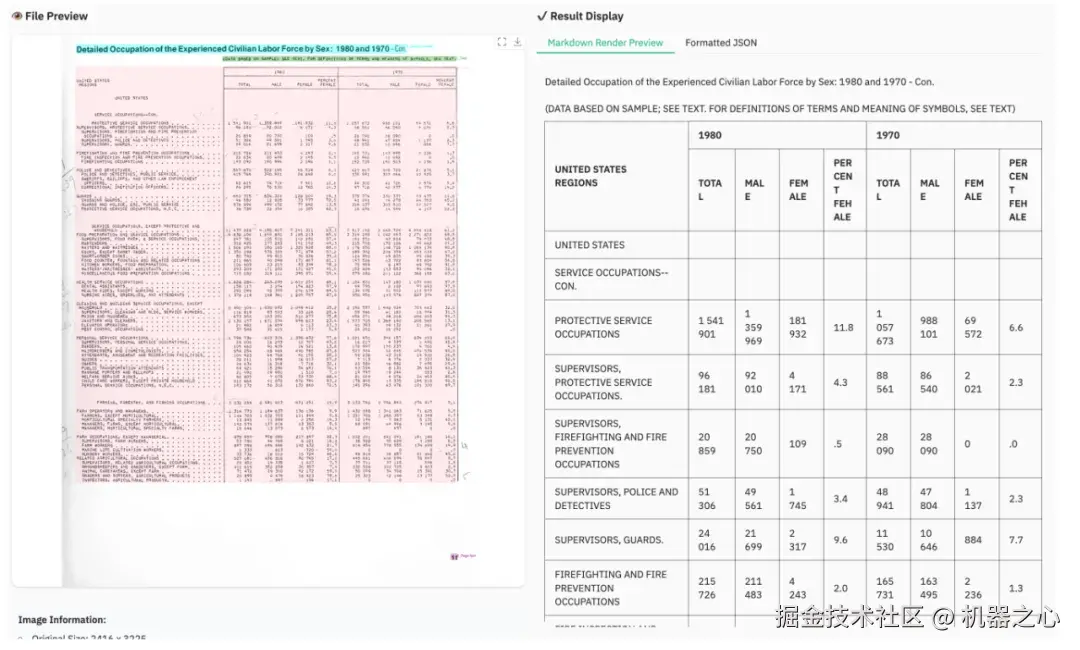
dots.ocr 识别结果。
正如燕青所言,文档解析的精度与完备性对大模型训练、推理有着重要影响。郭丰俊也在现场分享了他们在这方面的发现。比如在下面这个问答场景中,面对同样的文件 / 截图,文档解析能力强的模型明显可以给出更加完整、准确的分析结果。
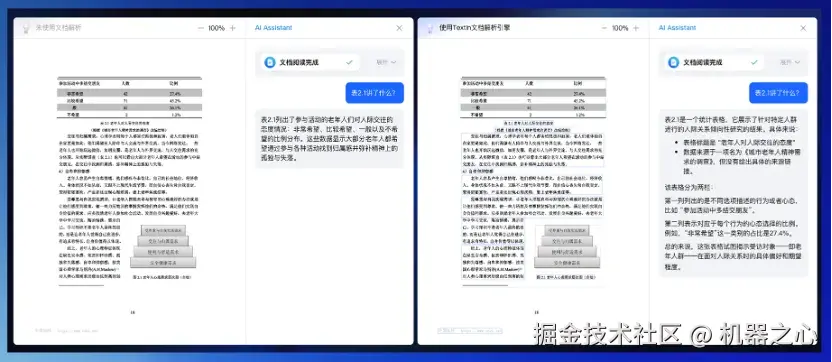
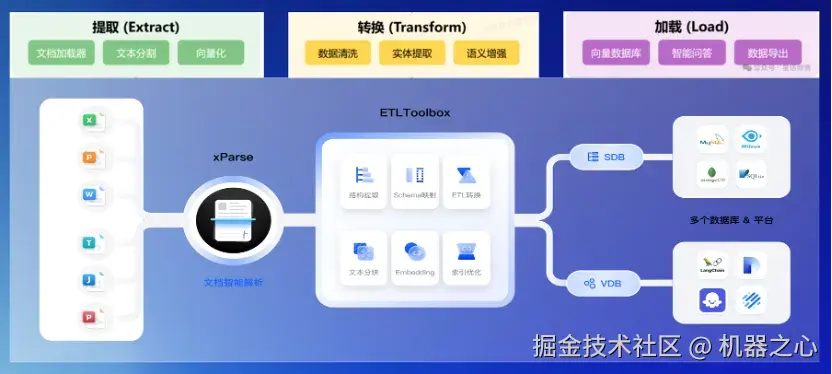
这一结果的背后离不开布局分析(理解文档的物理结构,如段落、表格、标题位置)、语义理解(识别关键实体如姓名、日期、金额、条款,理解它们之间的关系)等底层技术的支撑。不过,和很多只提供单点能力的技术解决方案不同,合合信息将其全部集成到了一个名为 TextIn xParse 的「大模型加速器」上。

「大模型加速器」支持将任意格式、版式的文档(图片、PDF、Doc/Docx 等)高效、精准解析为 Markdown 格式,并通过文本清洗、实体提取和语义增强生成高质量知识素材,进而用于知识库构建与向量数据库管理,可以为大模型提供更高质量的训练数据。
值得注意的是,这一环节也要克服幻觉问题。比如你让模型去识别一个在语义层面无意义的文本,它可能会自作聪明地将其「纠正」:

当遇到视觉上模糊或非语义的场景文本时,大模型往往难以准确识别和理解内容,经常会生成语义上看似合理但视觉上不正确的答案,这种情况被称为语义幻觉。
对于被遮挡的文本,模型可能会擅自「补全」:

总之,幻觉出现的方式可以说是五花八门。目前,这方面的研究还相对较少,但在工业、票据、交通等对文字识别精度要求极高的场景中,这类幻觉将严重影响可用性。

很多 LVLM 在含有文字的图像场景中不能准确地理解或回答涉及图中文字的简单问题:如「在图中蓝色字是什么?」、「这个字母左边是什么字?」等。这类错误往往不仅是识别错字或者漏字,而是模型「看到了文字但给出了不相关/不准确的答案」 。这种幻觉被称为「OCR 幻觉」。
在演讲中,南开大学教授周宇分享了几个与之相关的工作。
首先是一个无需重新训练的语义幻觉抑制框架,该框架针对的是模型「凭借语义先验」生成看上去合理但与图像不符的答案的情况。他们发现,大型多模态模型中那些对文字区域关注更集中的 Transformer 层更不易产生幻觉。据此,他们设计了两步方法:ZoomText 通过「glimpse-refocus」由粗到细的注意力分析自动定位图像中的文字区域,而 Grounded Layer Correction 则在解码时动态利用这些低幻觉层的表示来校正输出,从而在非语义文本上减少错误,同时保持语义文本的准确性。
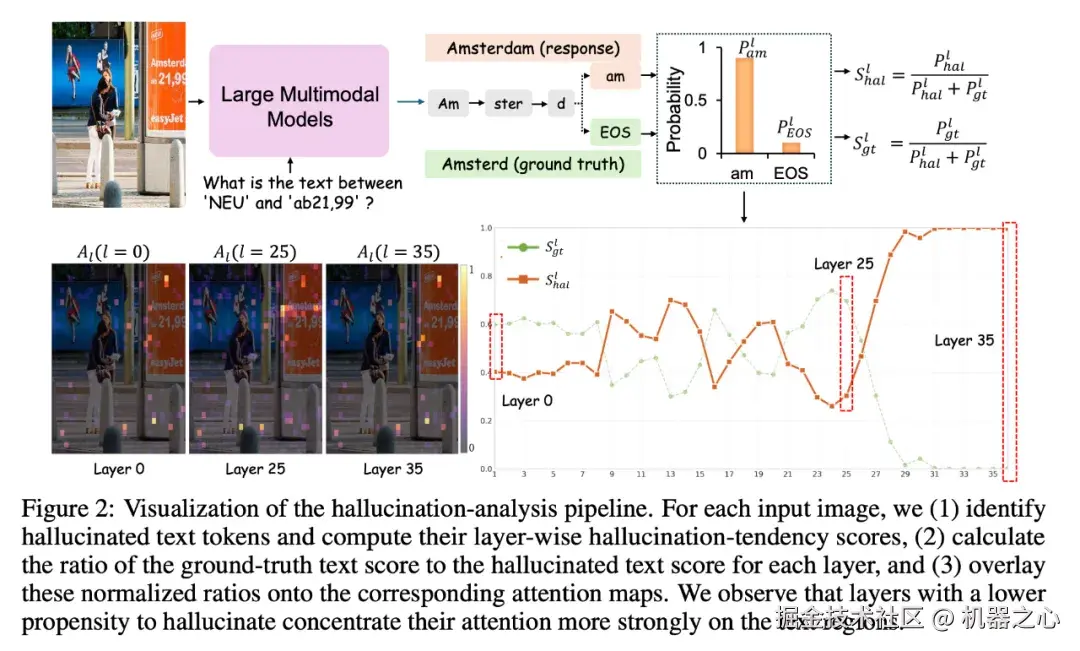
其次是一个专门用于评测和诊断 OCR 幻觉的新基准 HalluText。该基准涵盖九个细分子任务,能够更细粒度地衡量模型的文字感知与推理能力。作者还提出了轻量级的缓解方案 OCRAssistor,通过引入外部 OCR 模型的识别结果并在推理阶段对解码过程进行分布约束,在无需重新训练大模型的前提下显著降低了幻觉率并提升了文字相关任务的准确性。

图源:openreview.net/pdf?id=LRnt...
最后是一个针对真实世界降质文档(如模糊、遮挡、低对比度)的幻觉应对方法。作者首先构建了一个专门评估视觉退化条件下文本识别可靠性的新基准 KIE-HVQA,然后通过引入不确定性标注和多目标奖励机制,引导模型在面对模糊或遮挡区域时学会「拒答」或表达不确定,而非凭空生成答案,从而显著提升了模型在真实世界文档理解任务中的稳健性与可信度。

可以看出,感知层的突破正在让机器逐渐「看清」世界,但看清只是开始。要让 AI 真正理解所见之物,还需要进入更深一层的能力:认知与推理。
认知与推理
让机器「读懂」并「思考」
认知层面的主要目标是让 AI 在看清多模态信息之后学会「思考」。在论坛中,哈尔滨工业大学计算学部长聘教授、博士生导师车万翔介绍的「多模态思维链」是实现这一目标的有效方法。
他首先指出,多模态推理让模型能像人一样在「看」与「想」之间往复,具备动态、可解释的思维过程。但当前主流模型仍主要依赖语言链推理,即虽然输入有图像,但推理过程仍然是文字,这叫 Think about Images,距离真正的视觉思维(Think with Images)尚远。

为了加速从前者到后者的演进,他们通过一系列应用基准的增强让模型学会用视觉去思考,而不仅仅用语言去解释,比如能实现多步多模态推理的 M³CoT、要求模型在推理过程中生成图像辅助线或标注区域的 CoMT、评估模型在复杂约束下规划与决策能力的 MPCC、让模型在推理中动态回溯关键视频帧的 ViTCoT 等。这些工作让 AI 的「理解力」从文字的线性逻辑,转向视觉与推理交织的思维过程。
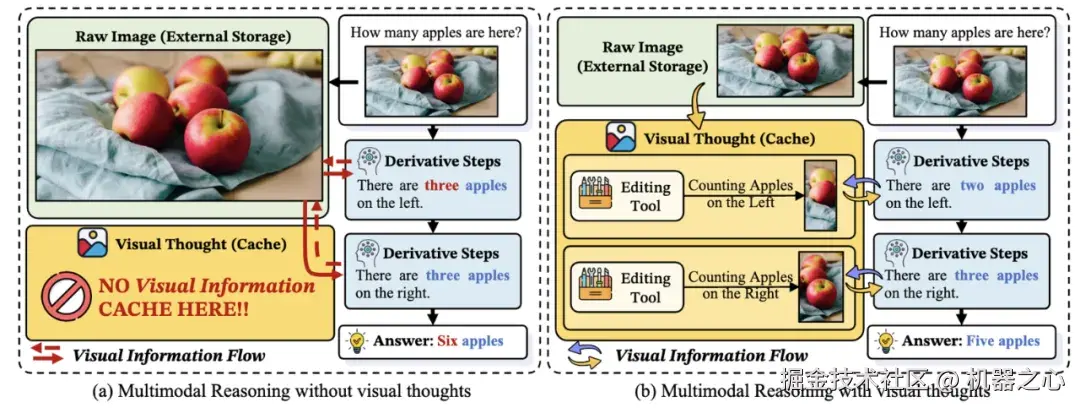
除此之外,车万翔还介绍了他们在理解多模态推理核心机理方面的进展。他们发现,所有的多模态思维链能够起效都是因为有效地传递了「视觉思维(Visual Thoughts)」。这个「视觉思维」相当于一个寄存器,模型每次进行下一步跨模态推理时,都优先从之前的视觉思维中进行存取。它存在的价值是向更深层传播视觉信息,有助于模型做深入的思考。这种可解释性方向的工作为后续研究提供了指引。
决策与行动
让机器「主动」去做
随着模型逐渐具备「看」与「想」的能力,新的问题也随之出现:如果 AI 已经能够在多模态信息中完成推理与判断,那么下一步,它是否能够基于思考结果主动去做?换言之,如何让模型从被动理解走向主动决策与行动,成为多模态文本智能发展的下一个关键命题。
从郭丰俊介绍的合合信息产品中,我们已经看到了这一方向的一些雏形。比如他们的扫描全能王智能高清滤镜可以自行判断图像是否存在质量问题(如光线不足、颜色失真、角度倾斜等),然后动态选择最优处理路径和算法。以往,这一过程需要借助多步人工操作来完成,即用户需要先判断「这张图太暗了」,然后手动找到并点击「亮度调节」工具,再手动调整参数,过程非常繁琐。
此外,扫描全能王里的「翻页自动拍」功能,也是 AI 主动决策的一个小例子。用户只要自然翻页,AI 就能自动识别这一动作并完成拍摄,还能智能去除手部、阴影等干扰,让厚重的纸质资料几分钟就变成整洁的数字文档。
不过,总体来看,业界对多模态文本智能决策层的探索还处在初期,AI 能够完成的动作还相对简单。行业对于这一方向的探索还有很长的路要走。
多模态文本智能
通往 AGI 的现实路径
从嘉宾的分享中我们能感受到,「文本」远不只是信息的载体,它承载着人类理解世界的方式,也隐藏着智能的线索。要真正读懂它、利用它,让机器像人一样理解与思考,其难度比想象中更高。
然而,这恰恰是一个值得全力投入的方向。从当前 AI 的发展与实际落地来看,众多场景的完整闭环实现,都离不开多模态文本智能技术的支撑。以目前 AI 领域广泛应用的 RAG 技术为例,其瓶颈之一正是如何融合多模态文本能力,以更精准地获取并理解不同模态、不同格式的文本信息。
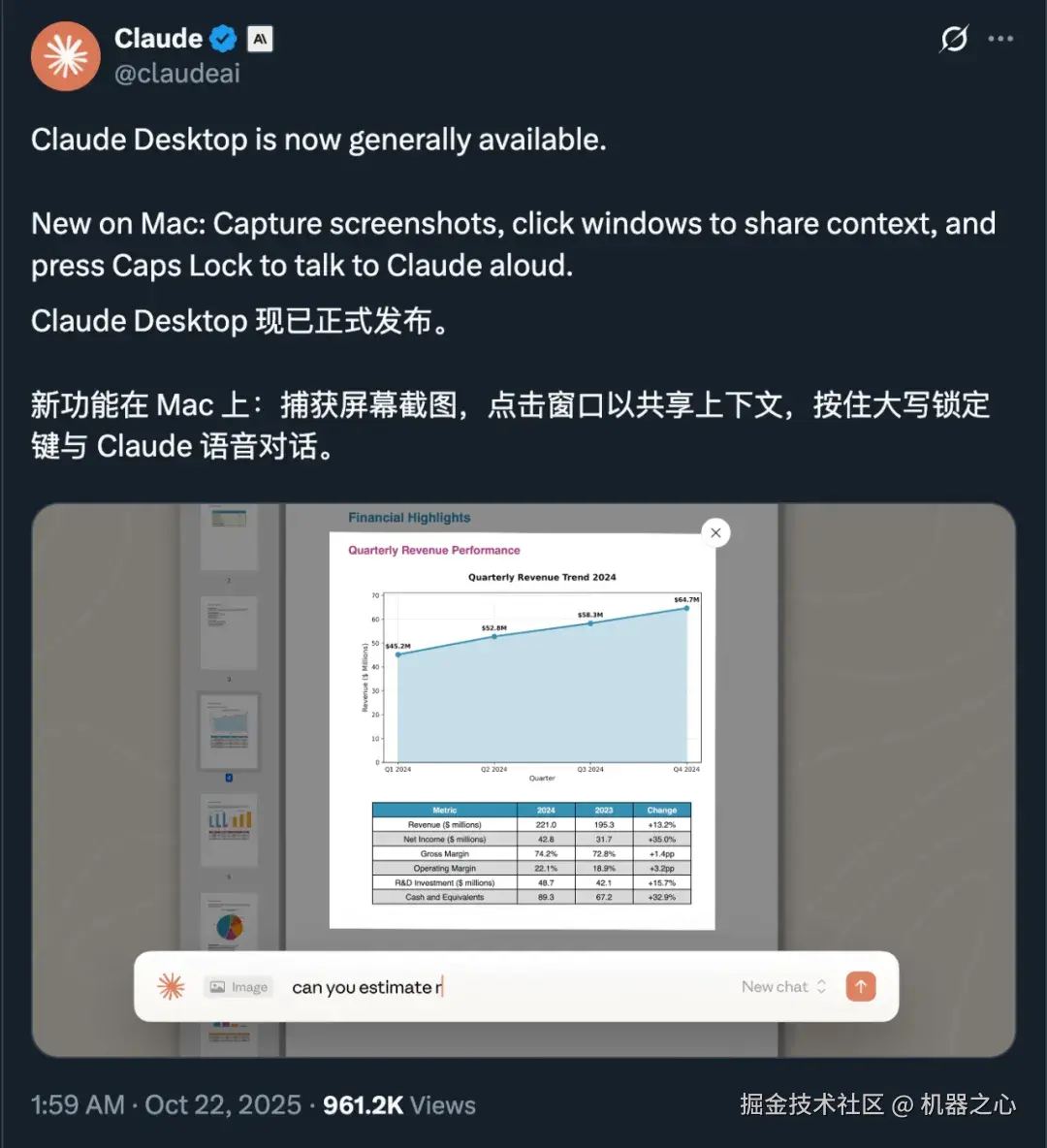
Anthropic 最近发布的官方桌面应用 Claude Desktop,其重要的截图分享上下文功能也需要多模态文本智能技术的支撑。
纵观行业,不少模型与产品已在多模态文本智能方向有所探索 ------ 从 Mistral OCR、Reducto,到 Gemini、GPT-5。然而在实际业务中,现有技术仍多聚焦于文本识别、语义理解等单点能力,尚难以实现从感知、理解到自主决策与行动的全链路闭环。
正因如此,「多模态文本智能」理念的提出恰逢其时。与「通用多模态理解」聚焦于内容的理解环节不同,它将文本智能的认知层级从语义理解,推进至类人推理与自主决策,构建出一条从感知到认知、再到行动的完整技术路径,覆盖范围更广,流程也更系统。合合信息相信,这条路,或许正是通往 AGI 的一条现实路径。
当然,在具体实现层面,这一方向仍有诸多问题亟待探讨。论坛中所分享的内容,不过是冰山一角。这条从「文本」走向「智能」的路径究竟将如何延伸,仍需我们在持续的探索中寻找答案。