写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
11.1 介绍
-
11.2 标签
-
11.3 注释
-
11.4 Scales
11.1 介绍
在 Chapter 10 中,您学会了如何使用绘图作为探索工具。 当您制作探索性绘图时,您甚至在查看之前就知道该图将显示的变量。 您是出于目的制作每个绘图,可以快速查看它,然后转到下一个绘图。 在大多数分析过程中,您会生产数十或数百个绘图,其中大多数立即被扔掉。
现在您了解了您的数据,您需要将您的理解传达给他人。 您的听众可能不会分享您的背景知识,也不会在数据上投入大量投资。 为了帮助他人迅速建立一个良好的心理模型,您将需要投入大量精力,以使图尽可能自我解释。 在本章中,您将学习 ggplot2 提供的用来做这些的工具。
本章重点介绍您创建良好图形所需的工具。 我们假设您知道您想要什么,只需要知道如何做。 因此,我们强烈建议将本章与一本良好的一般可视化书配对。 我们特别喜欢 Albert Cairo 的 The Truthful Art。 它不会教导创建可视化的机制,而是专注于创建有效图形所需的考虑。
11.1.1 先决条件
在本章中,我们将再次关注 ggplot2。 我们还将使用一些 dplyr 进行数据操作,scales 去覆盖默认 breaks,labels,transformations 和 palettes,以及一些 ggplot2 拓展包,包括 Kamil Slowikowski 的 ggrepel (https://ggrepel.slowkow.com),和 Thomas Lin Pedersen 的 patchwork (https://patchwork.data-imaginist.com)。 不要忘记,如果您还没有安装它们,则需要使用 install.packages() 安装这些软件包。
library(tidyverse)
library(scales)
library(ggrepel)
library(patchwork)11.2 标签
将探索性图形转换为说明性图形时,最简单的起点是具有良好的标签。 您使用labs() 函数添加标签(labels)。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
color = "Car type",
title = "Fuel efficiency generally decreases with engine size",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
caption = "Data from fueleconomy.gov"
)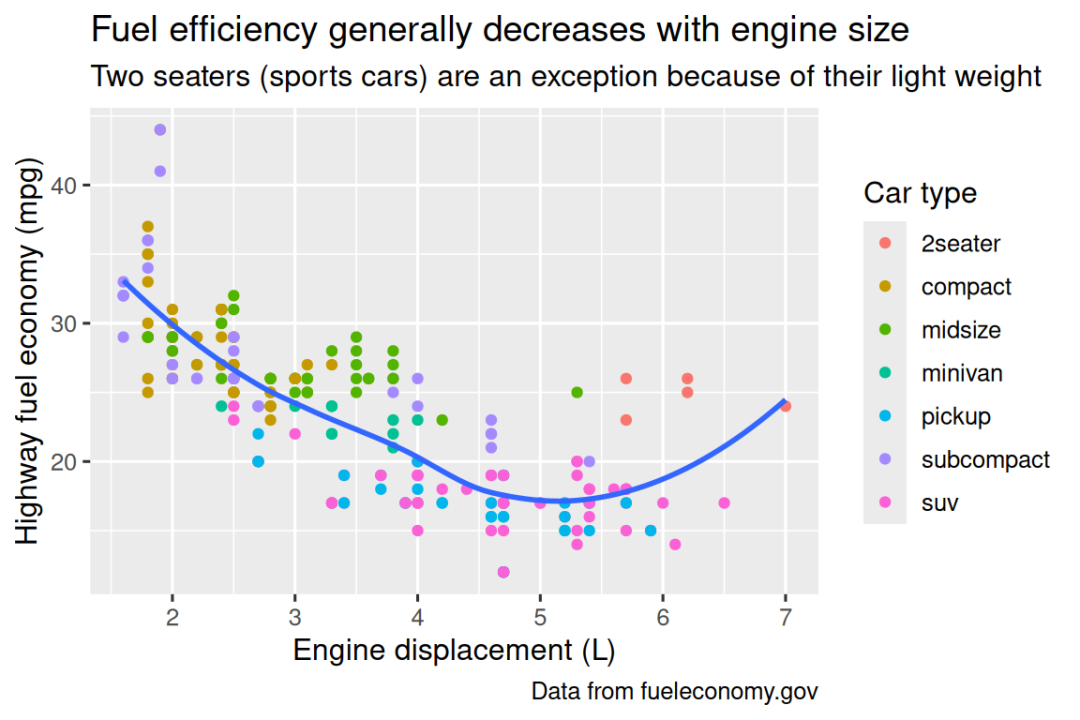
绘图标题(title)的目的是总结主要发现。 避免仅描述绘图的标题,例如 "A scatterplot of engine displacement vs. fuel economy"。
如果您需要添加更多文本,则还有其他两个有用的标签:subtitle 在标题下方用较小的字体添加了其他细节,caption 在图的右下方添加了文本,通常用于描述数据来源。 您还可以使用 labs() 替换 axis 和 legend titles。 通常,用更详细的描述替换简短名称并包括单位是一个好主意。
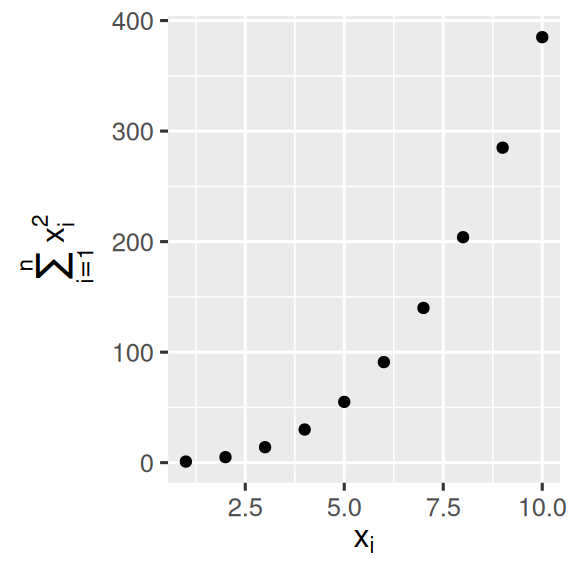
可以使用数学方程而不是文本字符串。 只需切换 "" 为 quote(),然后阅读 ?plotmath 中的可用选项:
df <- tibble(
x = 1:10,
y = cumsum(x^2)
)
ggplot(df, aes(x, y)) +
geom_point() +
labs(
x = quote(x[i]),
y = quote(sum(x[i] ^ 2, i == 1, n))
)
11.2.1 练习
-
用自定义的
title,subtitle,caption,x,y和color标签在 fuel economy data 上创建一个绘图。 -
使用 fuel economy data 重新创建以下绘图。 请注意,点的颜色和形状因驱动列车类型而异。
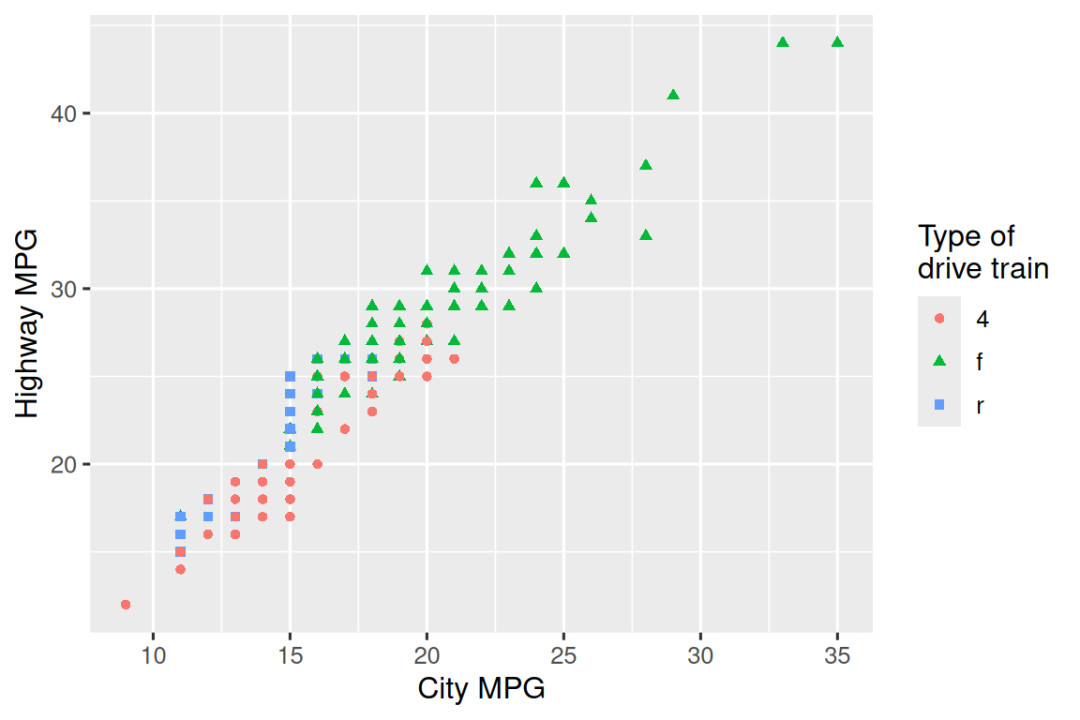
-
探索您在上个月创建的图形,并添加内容丰富的标题,以使其他人更容易理解。
11.3 注释
除了标记图的主要组成部分外,它通常对标记单个观察结果或观察群也很有用。 您可以使用的第一个工具是 geom_text()。geom_text() 类似于 geom_point(),但它具有额外的美学:label。 这使得它可以在图中添加文本标签。
标签有两种可能的来源。 首先,您可能有一个提供标签的 tibble 数据。 在以下图中,我们拔出了每种驱动器类型中发动机尺寸最高的汽车,并将其信息保存为一个名为 label_info 的新数据框。
label_info <- mpg |>
group_by(drv) |>
arrange(desc(displ)) |>
slice_head(n = 1) |>
mutate(
drive_type = case_when(
drv == "f" ~ "front-wheel drive",
drv == "r" ~ "rear-wheel drive",
drv == "4" ~ "4-wheel drive"
)
) |>
select(displ, hwy, drv, drive_type)
label_info
#> # A tibble: 3 × 4
#> # Groups: drv [3]
#> displ hwy drv drive_type
#> <dbl> <int> <chr> <chr>
#> 1 6.5 17 4 4-wheel drive
#> 2 5.3 25 f front-wheel drive
#> 3 7 24 r rear-wheel drive然后,我们使用此新数据框直接标记这三个组,以直接使用标签来替换图例。 使 fontface 和 size 参数,我们可以自定义文本标签的外观。 它们比绘图上的其余文本大。 (theme(legend.position = "none") 关闭所有图例 --- 我们将很快谈论它.)
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point(alpha = 0.3) +
geom_smooth(se = FALSE) +
geom_text(
data = label_info,
aes(x = displ, y = hwy, label = drive_type),
fontface = "bold", size = 5, hjust = "right", vjust = "bottom"
) +
theme(legend.position = "none")
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'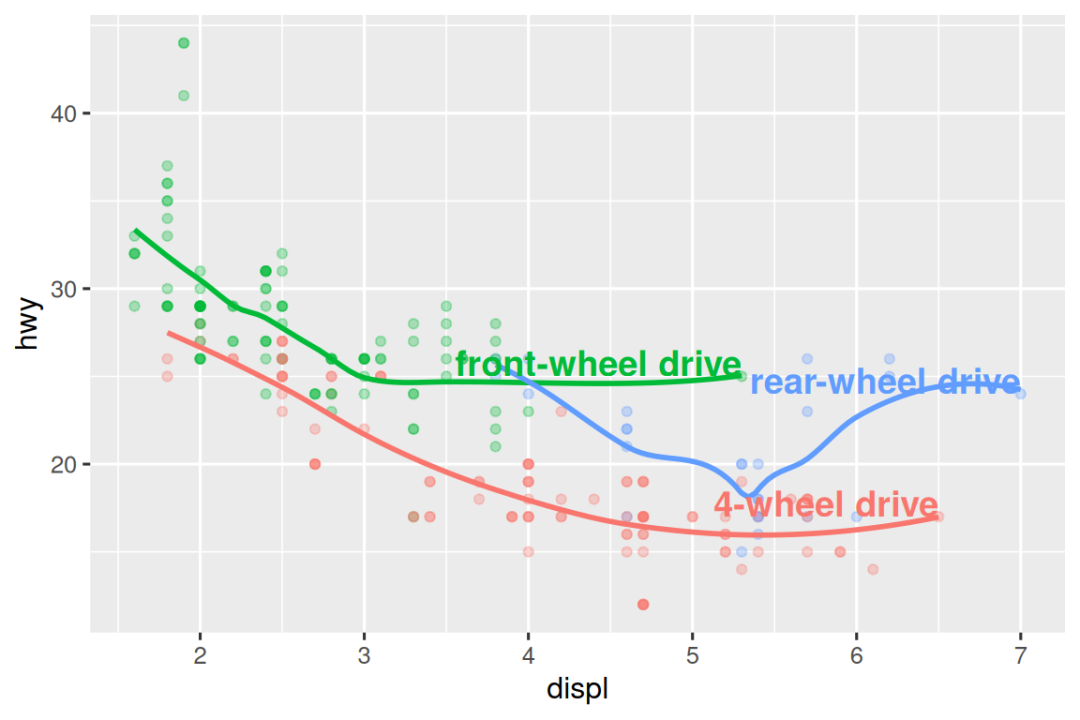
请注意,使用 hjust(水平对齐)和 vjust(垂直对齐)来控制标签的对齐。
但是,我们上面制作的带注释的图很难阅读,因为标签彼此重叠,并且与点重叠。 我们可以使用 ggrepel 软件包中的 geom_label_repel() 函数来解决这两个问题。 这个有用的软件包将自动调整标签,以免重叠:
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point(alpha = 0.3) +
geom_smooth(se = FALSE) +
geom_label_repel(
data = label_info,
aes(x = displ, y = hwy, label = drive_type),
fontface = "bold", size = 5, nudge_y = 2
) +
theme(legend.position = "none")
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'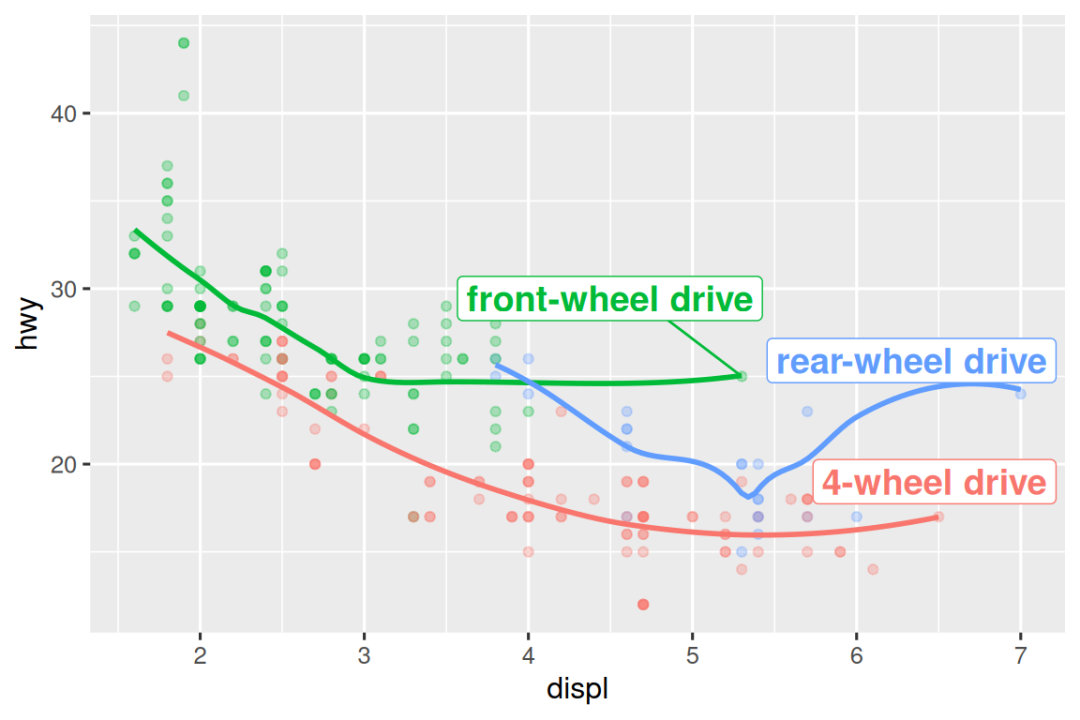
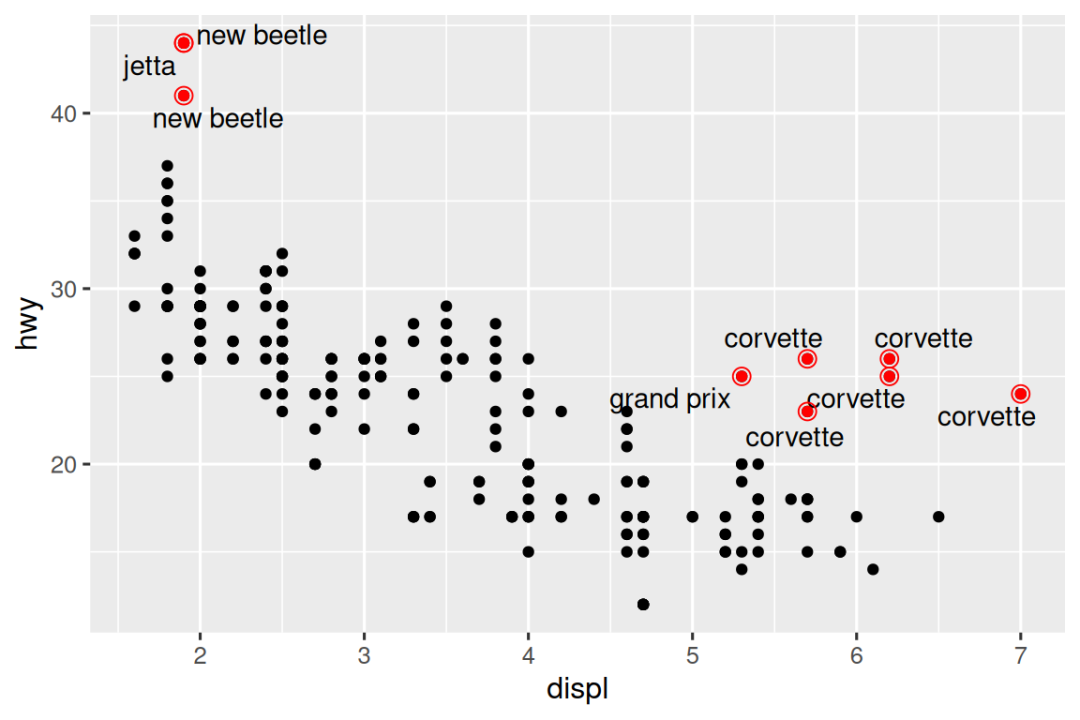
您也可以使用相同的想法使用 ggrepel 软件包中的 geom_text_repel() 突出显示图上的某些点。 请注意此处使用的另一种方便的技术:我们添加了第二层大的空心点,以进一步突出标记的点。
potential_outliers <- mpg |>
filter(hwy > 40 | (hwy > 20 & displ > 5))
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
geom_text_repel(data = potential_outliers, aes(label = model)) +
geom_point(data = potential_outliers, color = "red") +
geom_point(
data = potential_outliers,
color = "red", size = 3, shape = "circle open"
)
请记住,除了 geom_text() 和 geom_label() 之外,您还可以在 ggplot2 中使用许多其他 geoms,以帮助您注释您的绘图。 一些想法:
-
使用
geom_hline()和geom_vline()添加参考线。 我们通常会使它们变厚(linewidth = 2)和变白色(color = white),然后将它们绘制在主要数据层下方。 这使得它们易于看到,而无需从数据中吸引注意力。 -
使用
geom_rect()绘制围绕感兴趣点的矩形。 矩形的边界由美学xmin,xmax,ymin,ymax定义。 另外,请查看 ggforce package 软件包,特别是geom_mark_hull(),它允许您用 hulls 注释点子集。 -
将
geom_segment()与arrow参数一起使用,将注意力吸引到用箭头的点上。 使用美学x和y来定义起始位置,然后xend和yend定义结束位置。
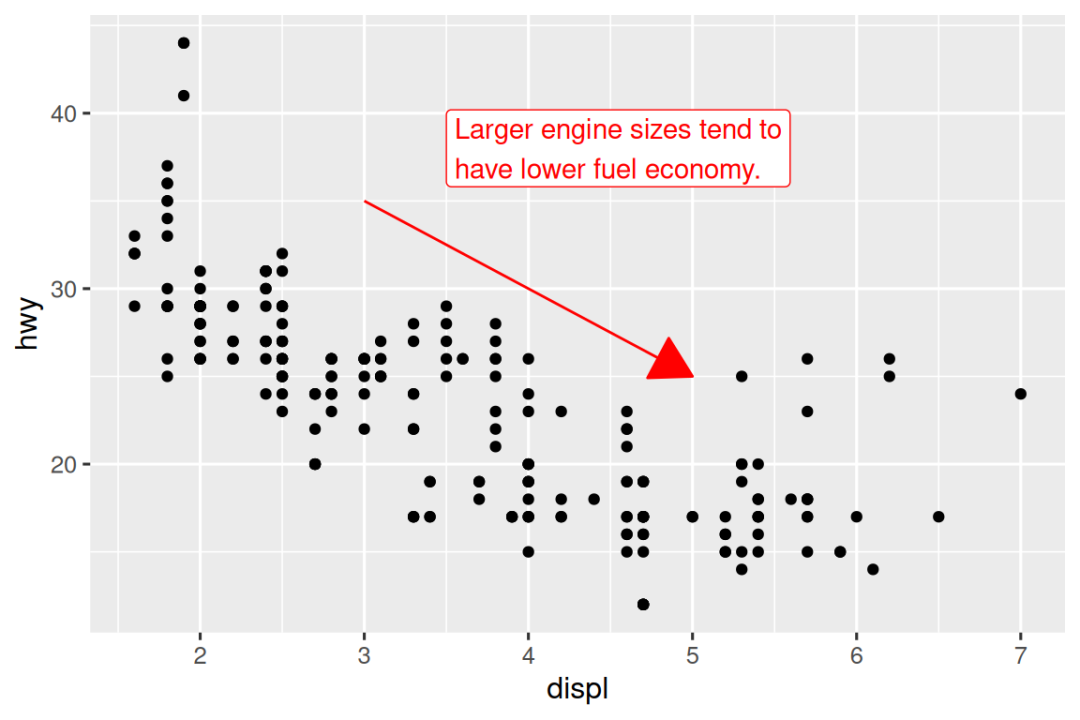
向图添加注释的另一个方便函数是 annotate()。 根据经验,geoms 通常对于突出数据子集很有用,而 annotate() 对于将一个或几个注释元素添加到图中很有用。
要演示使用 annotate(),让我们创建一些文本以添加到我们的图中。 文本有点长,因此我们将使用 stringr::str_wrap() 自动添加换行,给定您每行所需的字符数:
trend_text <- "Larger engine sizes tend to have lower fuel economy." |>
str_wrap(width = 30)
trend_text
#> [1] "Larger engine sizes tend to\nhave lower fuel economy."然后,我们添加两个注释层:一个带有 label geom,另一个带有 segment geom。 两者中的 x 和 y 美学都定义了注释应在哪里开始,并且 segment 注释中的 xend 和 yend 美学定义了该 segment 的最终位置。 还请注意,segment 使用箭头风格。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
annotate(
geom = "label", x = 3.5, y = 38,
label = trend_text,
hjust = "left", color = "red"
) +
annotate(
geom = "segment",
x = 3, y = 35, xend = 5, yend = 25, color = "red",
arrow = arrow(type = "closed")
)
注释是传达您的可视化主要要点和有趣功能的强大工具。 唯一的限制是您的想象力(以及您对定位注释的耐心在美学上令人愉悦)!
11.3.1 练习
-
使用
geom_text()及 infinite positions 将文本放在图的四个角落。 -
使用
annotate()在上一个图的中间添加 point geom,而无需创建 tibble。 自定义点的形状,大小或颜色。 -
geom_text()的标签如何与 faceting 相互作用? 如何将标签添加到一个 facet? 您如何在每个 facet 放置不同的标签? (提示:考虑要传递给geom_text()的数据集。) -
geom_label()控制背景框外观的参数是什么? -
arrow()的四个参数是什么? 他们如何工作? 创建一系列展示最重要选项的图。
11.4 Scales
您可以使绘图更好地进行交流的第三种方法是调整 scales。 Scales 控制美学映射如何在视觉上表现出来。
11.4.1 默认 scales
通常, ggplot2 自动为您添加 scales。 例如,当您输入时:
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class))ggplot2 自动在场景后面添加默认 scales:
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
scale_x_continuous() +
scale_y_continuous() +
scale_color_discrete()请注意 scales 的命名方案:scale_ 然后是美学的名称,然后是 _,然后是 scale 的名称。 默认 scales 是根据与以下相符的变量类型命名的:continuous,discrete,datetime,date。scale_x_continuous() 将来自 displ 的数值显示在 x 轴的连续数字线上,scale_color_discrete() 为每种汽车类选择颜色,等。 有很多非默认的 scales,您将在下面学习。
已经仔细选择了默认 scales,以便在各种输入中做得很好。 但是,您可能需要覆盖默认值,原因有两个:
-
您可能需要调整默认 scale 的某些参数。 这使您可以执行诸如更改轴上的 breaks 或图例上的关键标签之类的事情。
-
您可能需要完全替换 scale,并使用完全不同的算法。 通常,您可以做得比默认值更好,因为您对数据有更多了解。
11.4.2 轴刻度和图例键
轴(axes)和图例(legends)统称为 guides。 轴用于 x 和 y 美学;图例用于其他所有内容。
有两个主要参数会影响轴上 tick 的外观和图例中的 key:breaks 和 labels。breaks 控制 ticks 的位置或与 keys 关联的值。labels 控制与每个 tick/key 关联的文本标签。breaks 的最常见用途是覆盖默认选择:
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
scale_y_continuous(breaks = seq(15, 40, by = 5)) 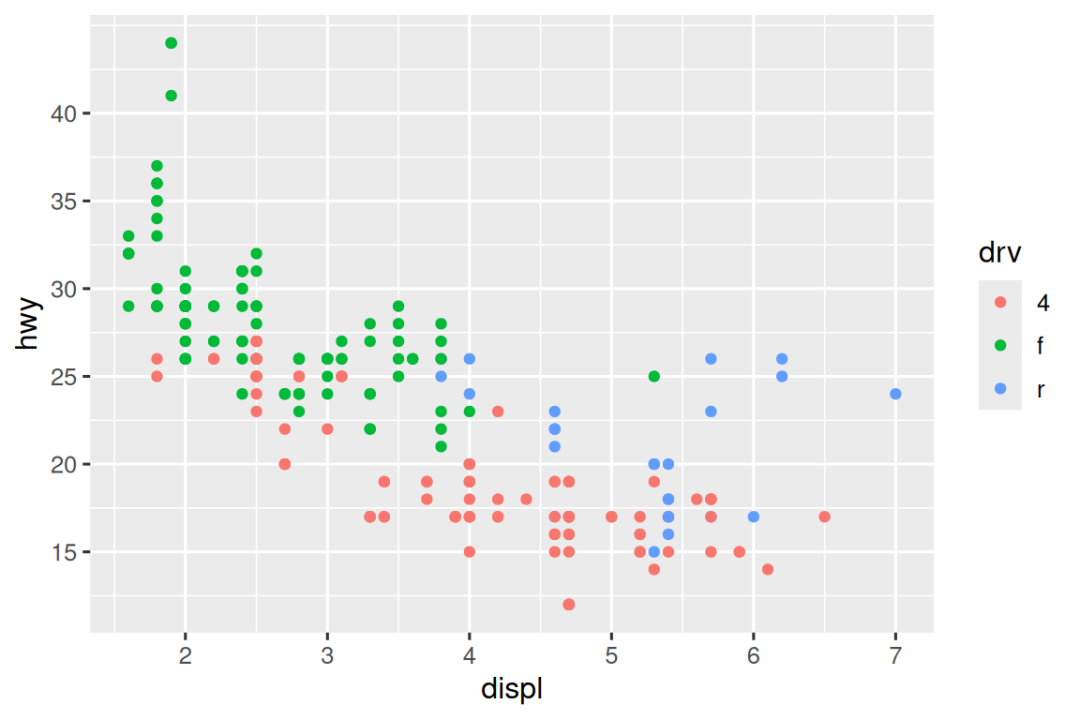
您可以以相同的方式使用 labels(一个特征向量与 breaks 相同的长度),但是您也可以将其设置为 NULL 以完全抑制标签。 这对于地图可能很有用,也可以发布您无法共享绝对数字的图。 您还可以使用 breaks 和 labels 来控制图例的外观。 对于分类变量的离散 scales,labels 可以是现有 levels 名称和所需标签的命名列表。
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(labels = NULL) +
scale_color_discrete(labels = c("4" = "4-wheel", "f" = "front", "r" = "rear"))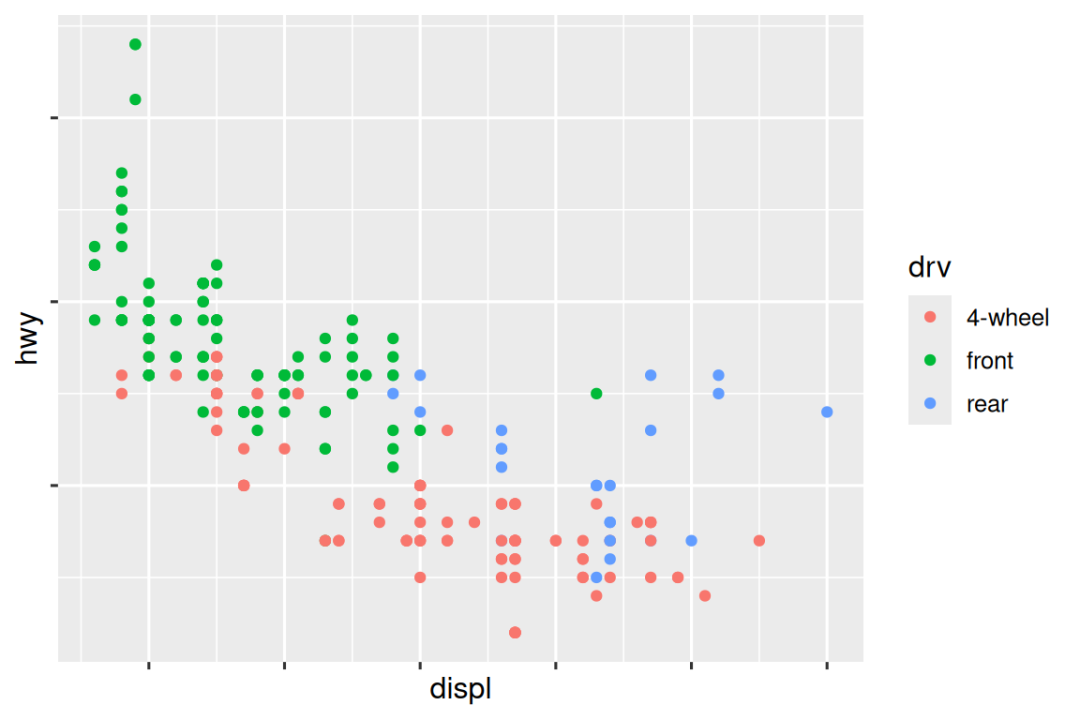
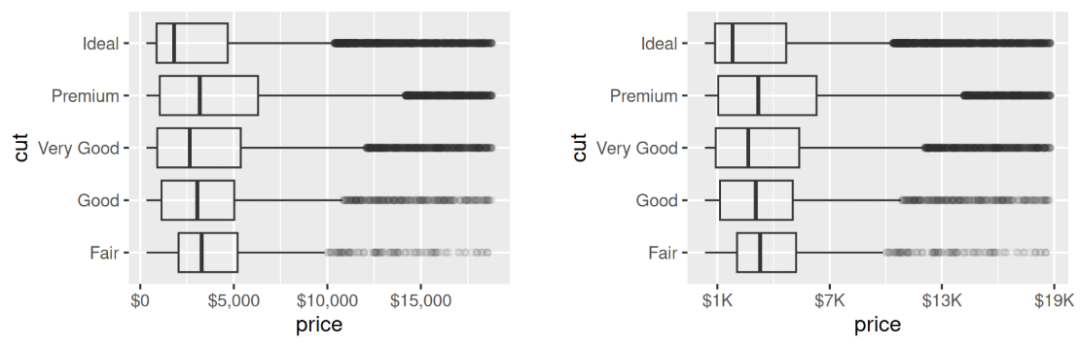
labels 参数以及来自 scales 软件包的标签函数也可用于格式化数字为货币,百分比等。 左侧的绘图显示了带有 label_dollar() 的默认标签,该标签添加了一个美元符号以及一个千分位逗号。 右侧的绘图进一步添加了自定义,通过将美元值除以 1,000 并添加后缀 "K"(用于"千")并添加自定义 breaks。 请注意,breaks 是数据的原始 scale。
# Left
ggplot(diamonds, aes(x = price, y = cut)) +
geom_boxplot(alpha = 0.05) +
scale_x_continuous(labels = label_dollar())
# Right
ggplot(diamonds, aes(x = price, y = cut)) +
geom_boxplot(alpha = 0.05) +
scale_x_continuous(
labels = label_dollar(scale = 1/1000, suffix = "K"),
breaks = seq(1000, 19000, by = 6000)
)
另一个方便的标签函数是 label_percent():
ggplot(diamonds, aes(x = cut, fill = clarity)) +
geom_bar(position = "fill") +
scale_y_continuous(name = "Percentage", labels = label_percent())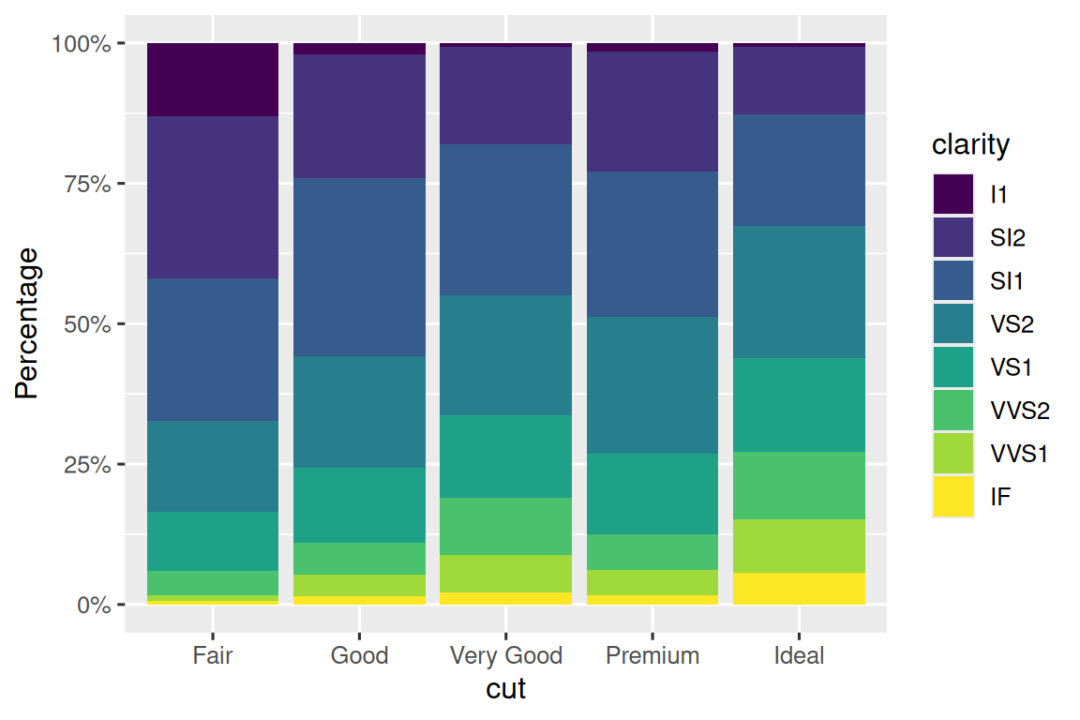
breaks 的另一个用途是,当您有相对较少的数据点并希望准确地突出观察结果时。 例如,以这一绘图为例,显示了每位美国总统何时开始并结束任期。
presidential |>
mutate(id = 33 + row_number()) |>
ggplot(aes(x = start, y = id)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_x_date(name = NULL, breaks = presidential$start, date_labels = "'%y")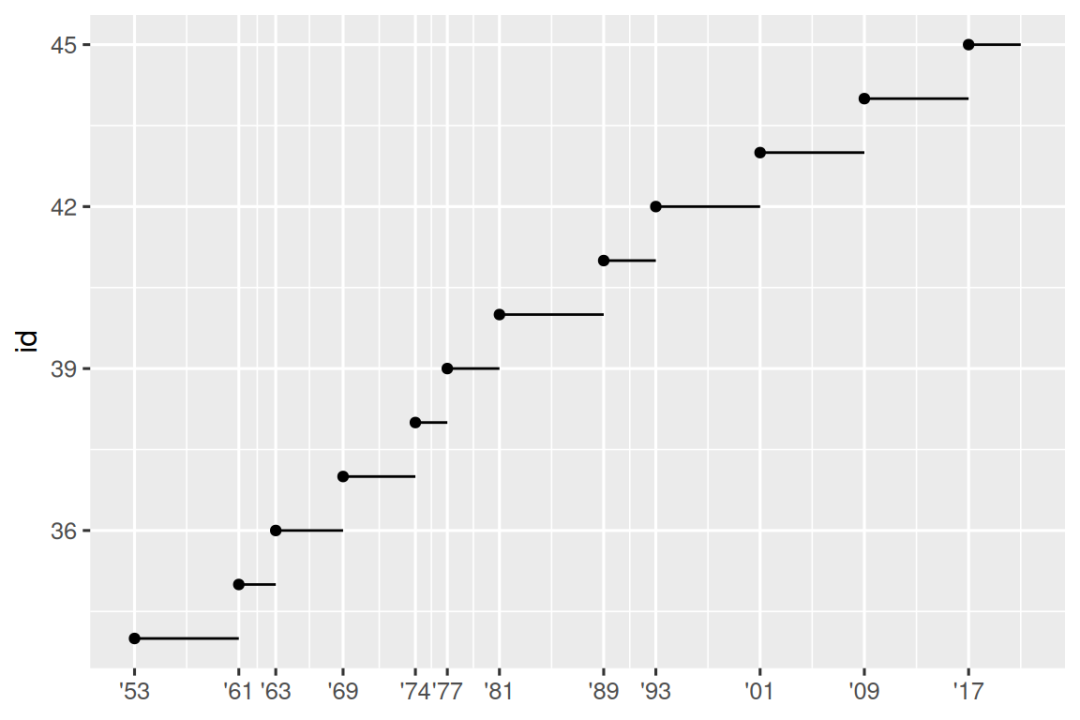
请注意,对于 breaks 参数,我们将 start 变量替换为 presidential$start 向量,是因为我们无法为此参数进行美学映射。 另请注意,date 和 datetime scales 的 breaks 和 labels 的规范有些不同:
-
date_labels采用与parse_datetime()形式相同的格式规范。 -
date_breaks(此处未显示),使用 "2 days" 或 "1 month" 之类的字符串。
11.4.3 图例布局
您通常会使用 breaks 和 labels 来调整轴。 尽管它们也都为图例工作,但您更有可能使用其他一些技术。
为了控制图例的整体位置,您需要使用 theme() 设置。 我们将在本章末尾回到 themes,但简而言之,它们控制着绘图的非数据部分。 theme 设置 legend.position 控制绘制图例的位置:
base <- ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class))
base + theme(legend.position = "right") # the default
base + theme(legend.position = "left")
base +
theme(legend.position = "top") +
guides(color = guide_legend(nrow = 3))
base +
theme(legend.position = "bottom") +
guides(color = guide_legend(nrow = 3))
如果您的绘图短而宽,则将图例放在顶部或底部,如果它高而窄,则将图例放在左或右侧。 您也可以使用 legend.position = "none" 来抑制图例的显示。
要控制单个图例的显示,请与 guides() 一起使用 guide_legend() 或 guide_colorbar()。 下面的示例显示了两个重要的设置:使用 nrow 控制图例的行数,使用 override.aes 覆盖一种美学以使点更大。 如果您使用低 alpha 在图上显示许多点,这将特别有用。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
theme(legend.position = "bottom") +
guides(color = guide_legend(nrow = 2, override.aes = list(size = 4)))
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'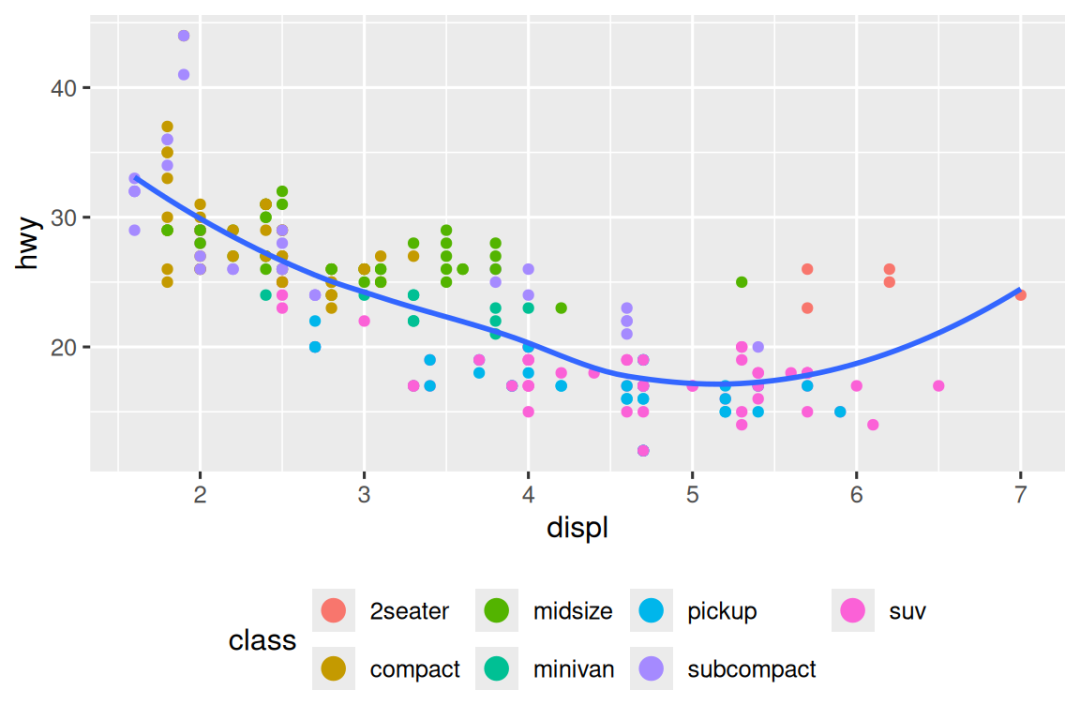
请注意,guides() 中参数的名称匹配美学的名称,就像 labs() 中一样。
--------------- 未完待续 ---------------
本期翻译贡献:
@TigerZ生信宝库
注:本文已开启快捷转载,欢迎大家转载,只需标明文章出处即可。