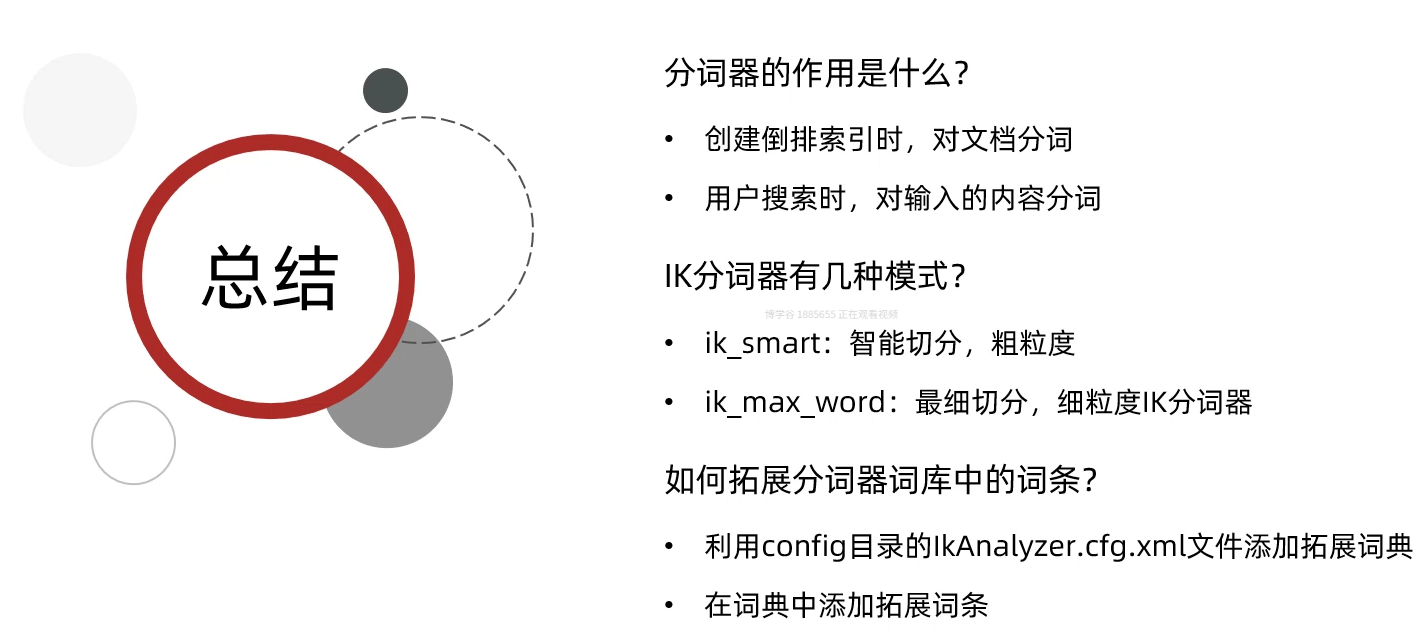
目录
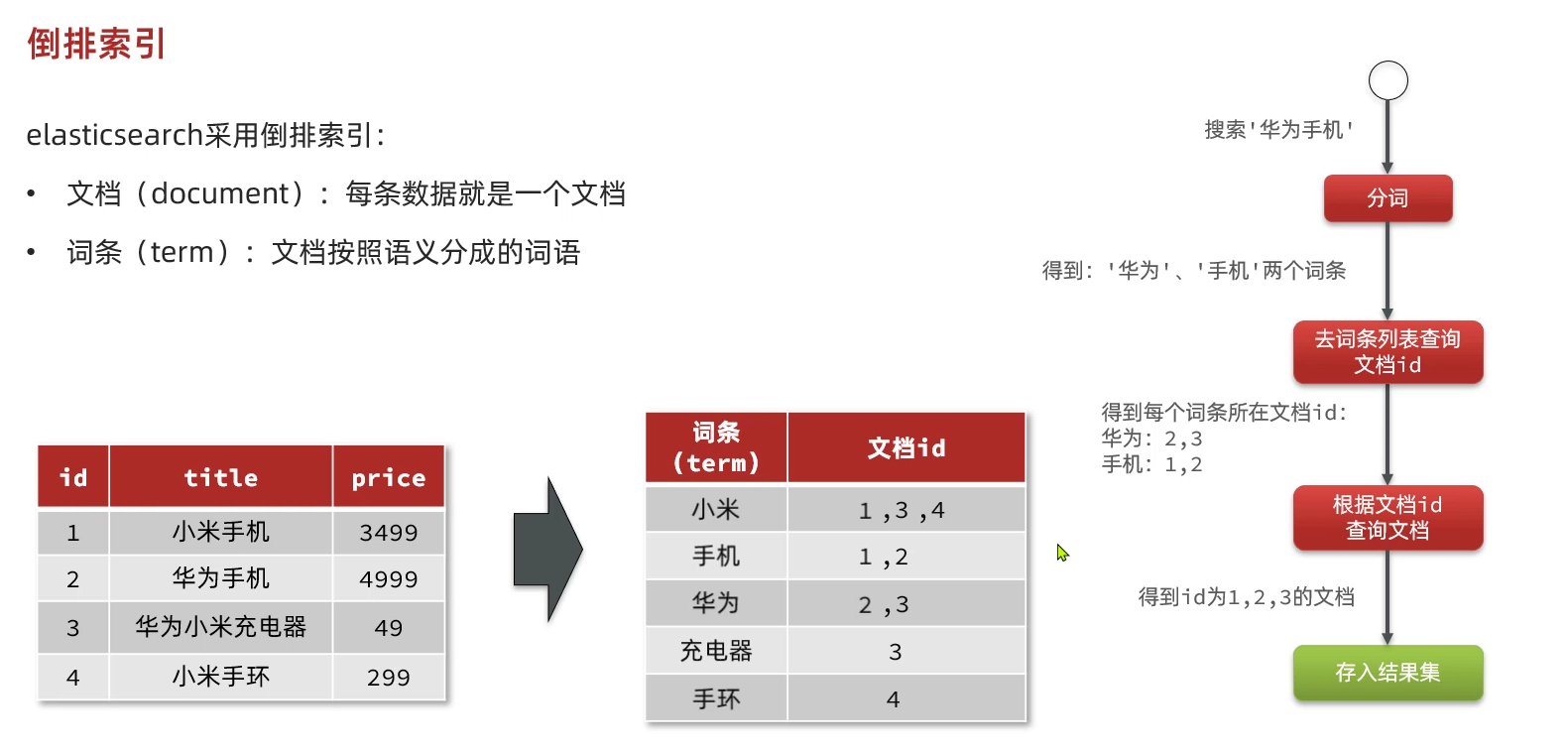
一、倒排索引
IK分词器:
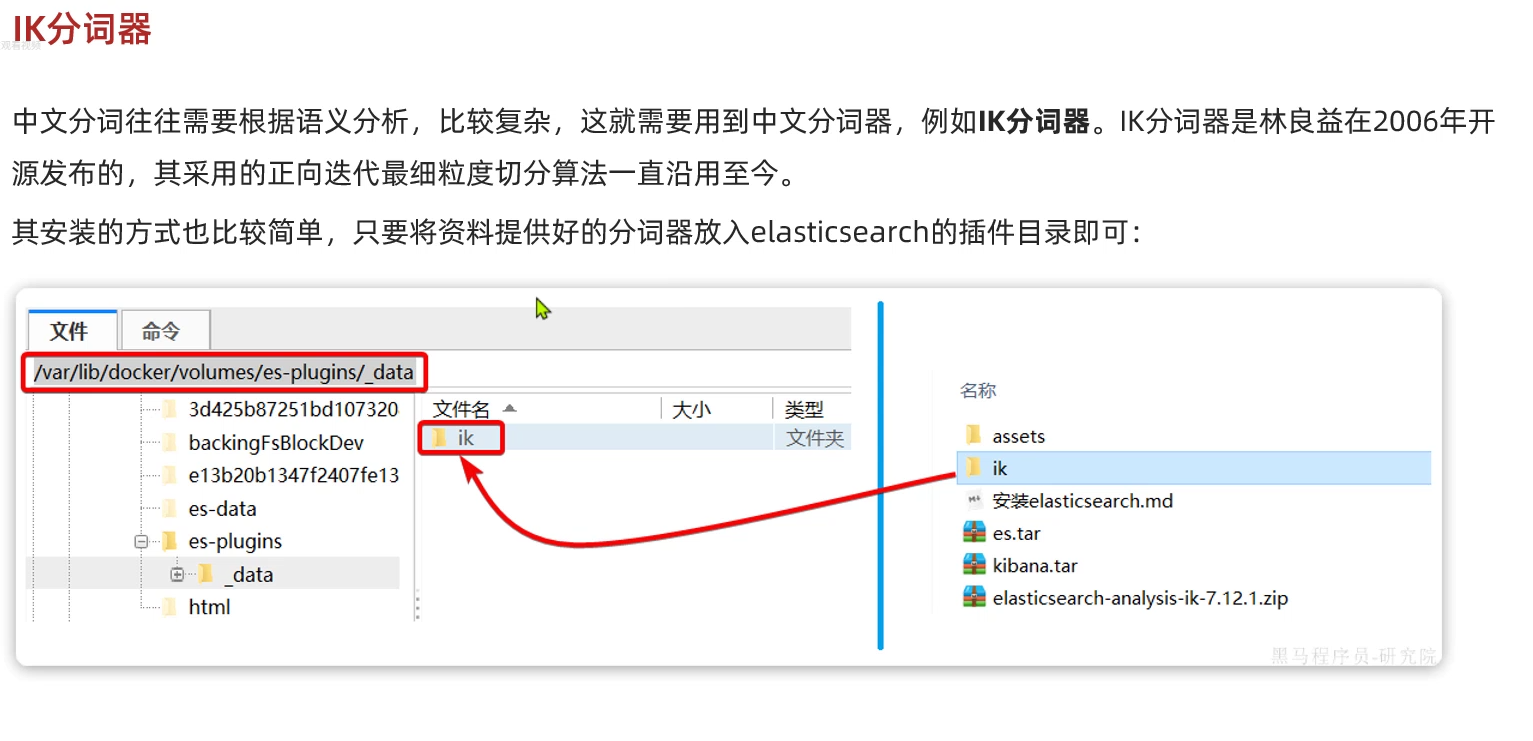
接下来我们来安装一下IK分词器:
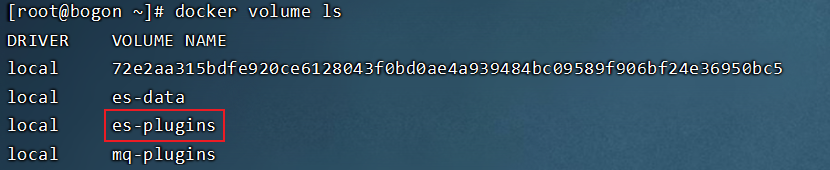
1.在虚拟机当中输入:docker volume ls查看数据卷,找到elasticsearch的插件:
2.根据插件名称查看内部路径信息:docker volume inspect es-plugins
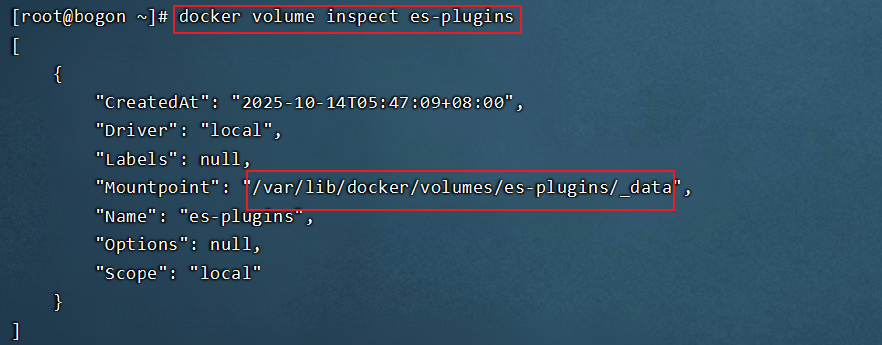
3.将我们解压后的elasticsearch-analysis-ik-7.12.1文件夹放到该路径下:
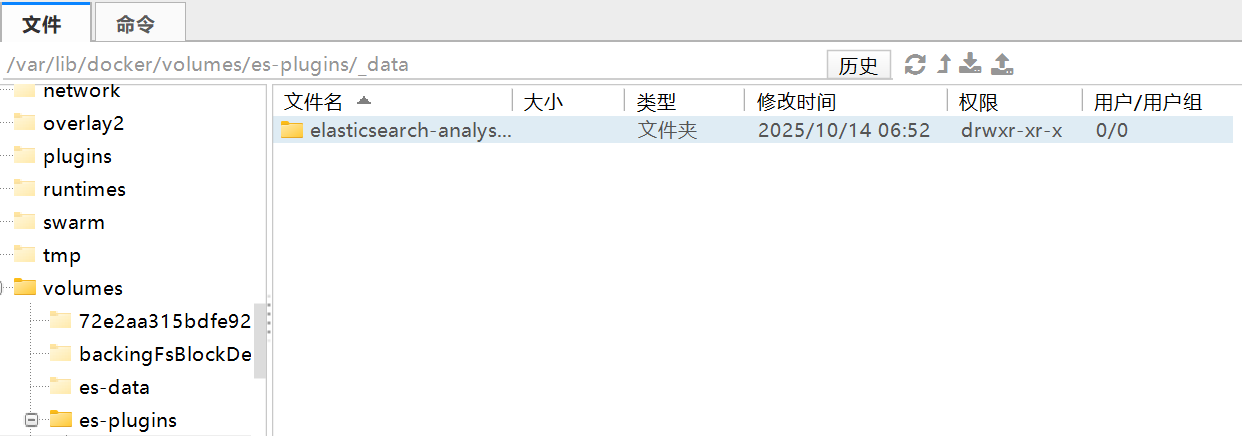
最终重启(docker restart es)就可以啦
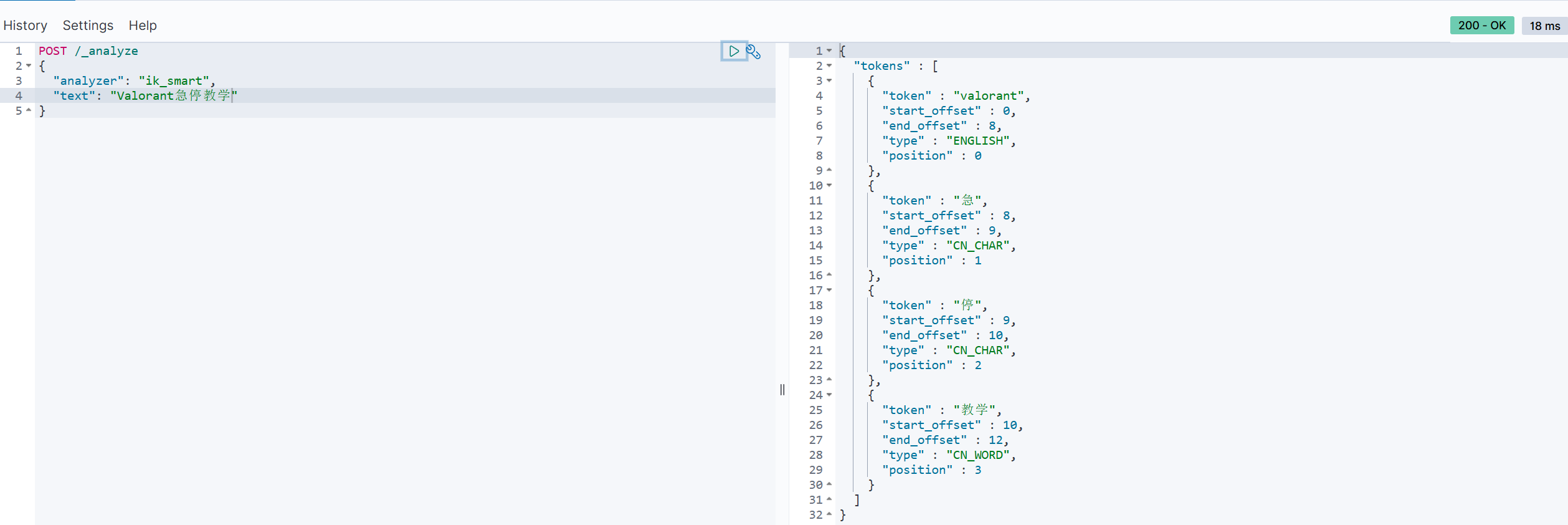
这里简单口述一下分词器的原理,实际上就是分词器当中有一个词典,词典包含了中文大部分的有意义的词句;当我们输入一串搜索内容时,分词器将这一串内容分成一个个符号,通过一个一个、两个两个、三个三个......的方式逐个遍历拼接,然后到词典当中查找,如果有该词,则放入结果集当中,没有则不管;但是随着时代发展,很多网络用词、新词逐渐出现,这样我们在词典当中是查不到这个词的,也就不会触发文档的返回;所以我们可以在config目录下的文件配置新词,而且还可以设置屏蔽词
二、ES核心概念:

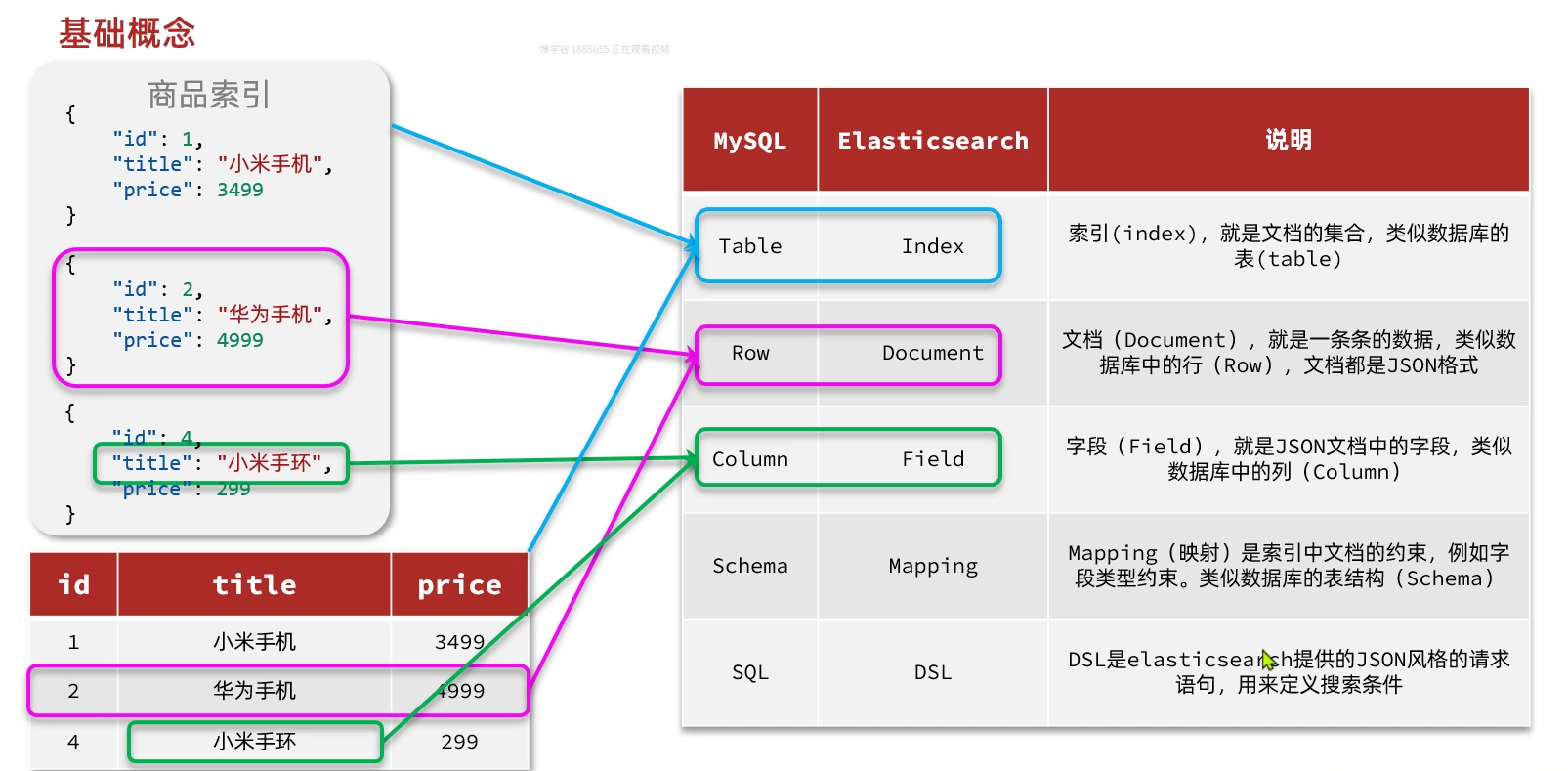
创建索引库:
相当于是数据库当中创建表


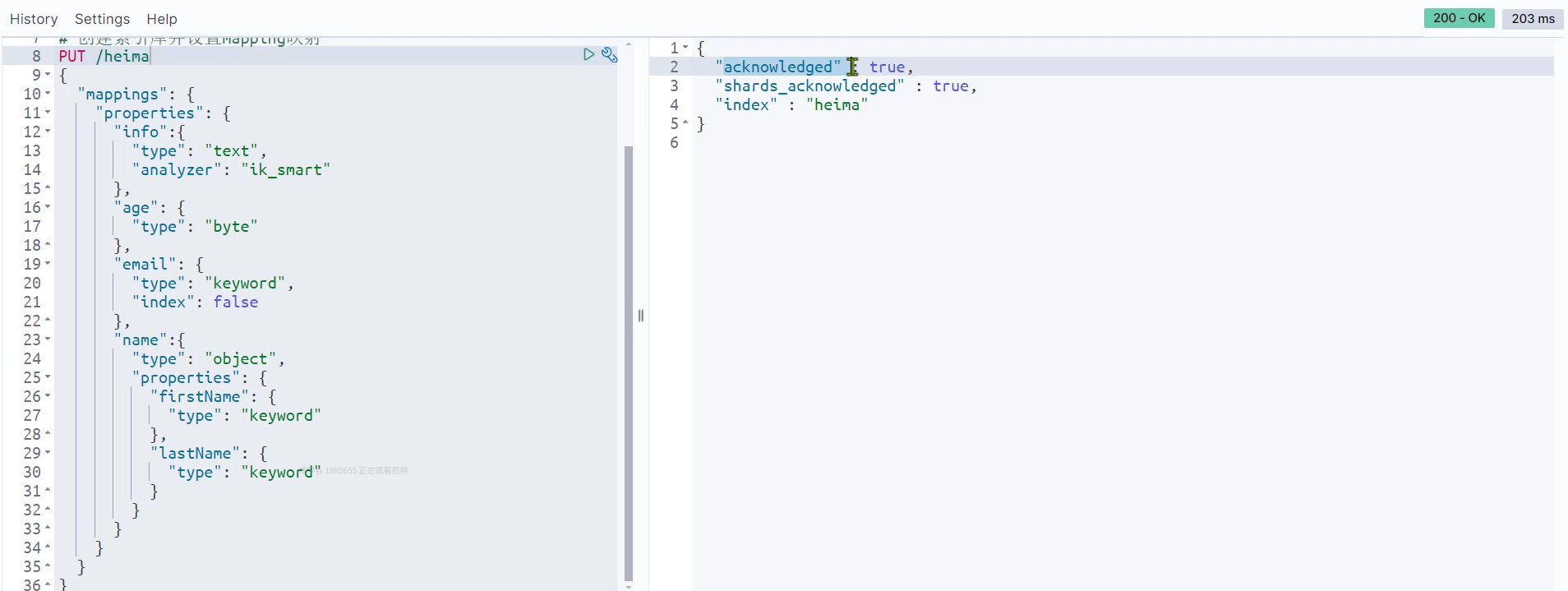
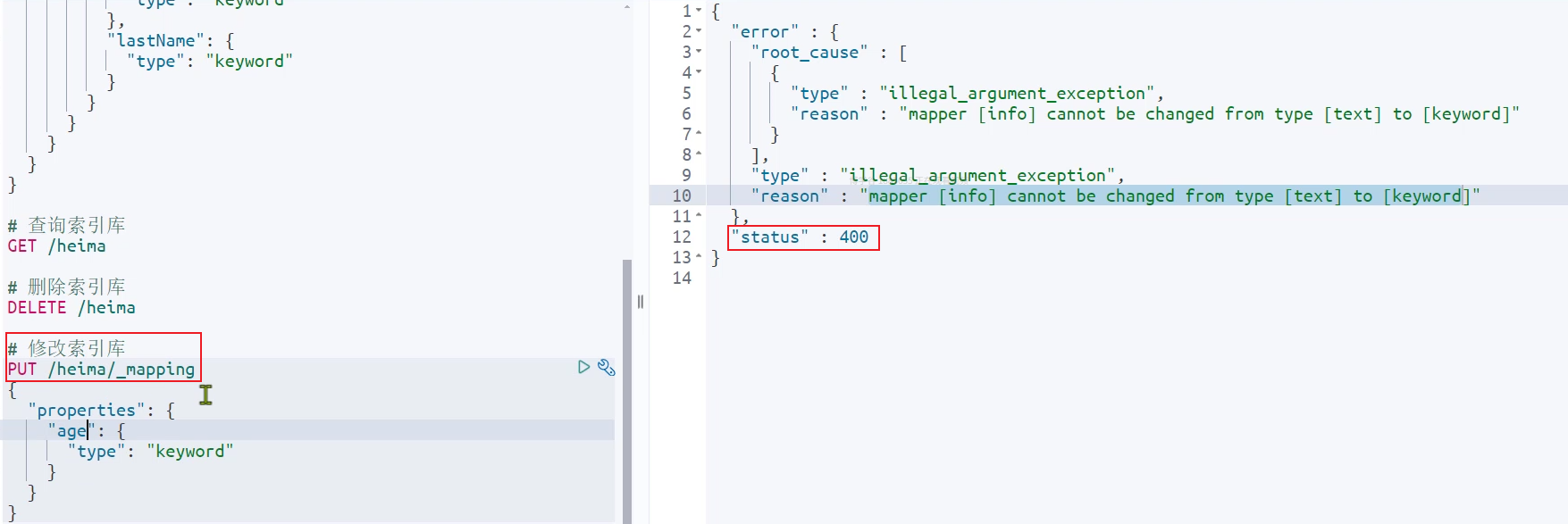
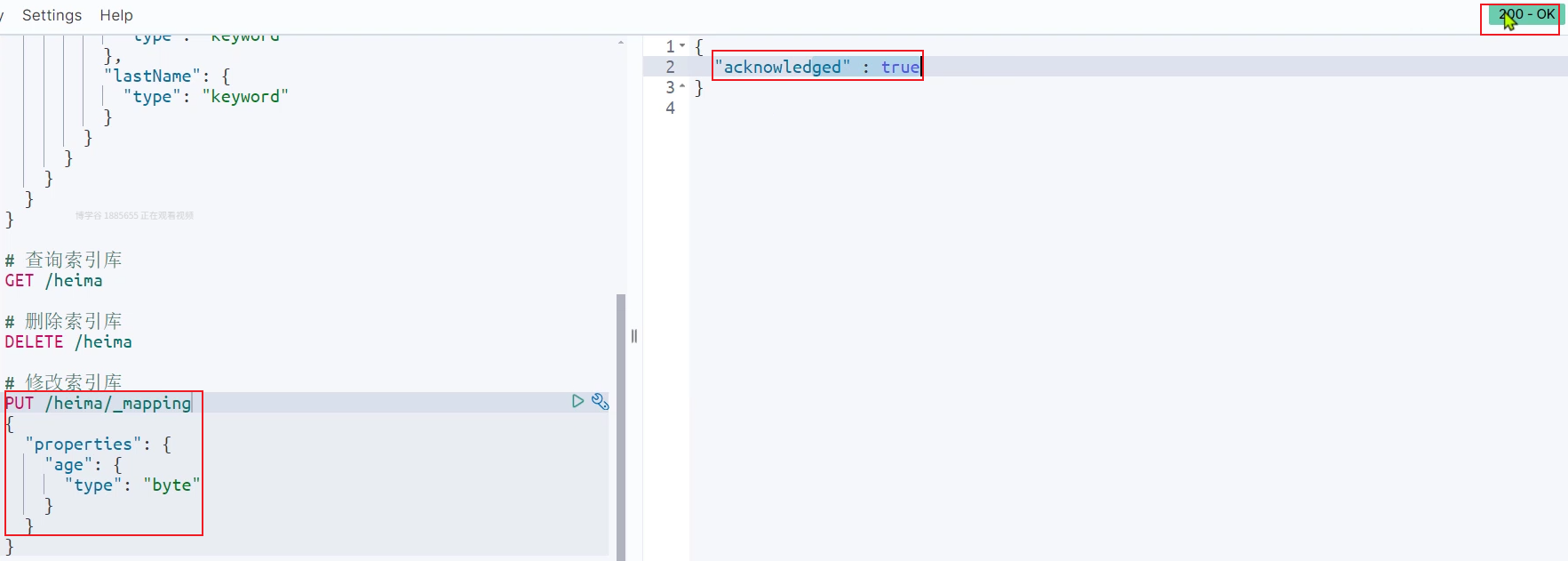
ES默认不允许修改已有的映射,但是可以添加:
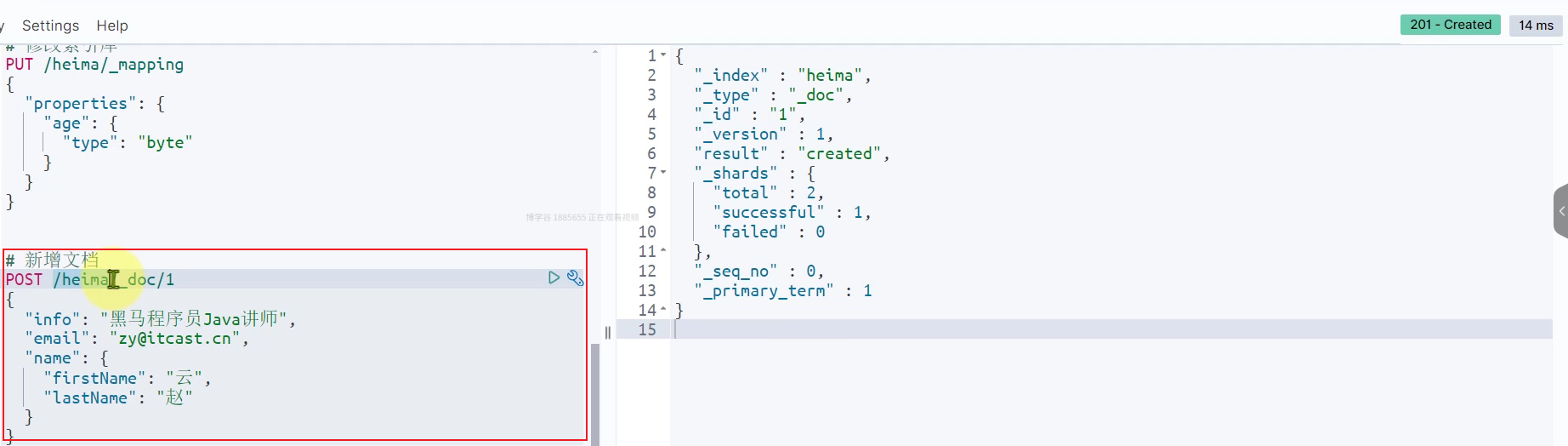
文档操作:
相当于是数据库当中操作数据

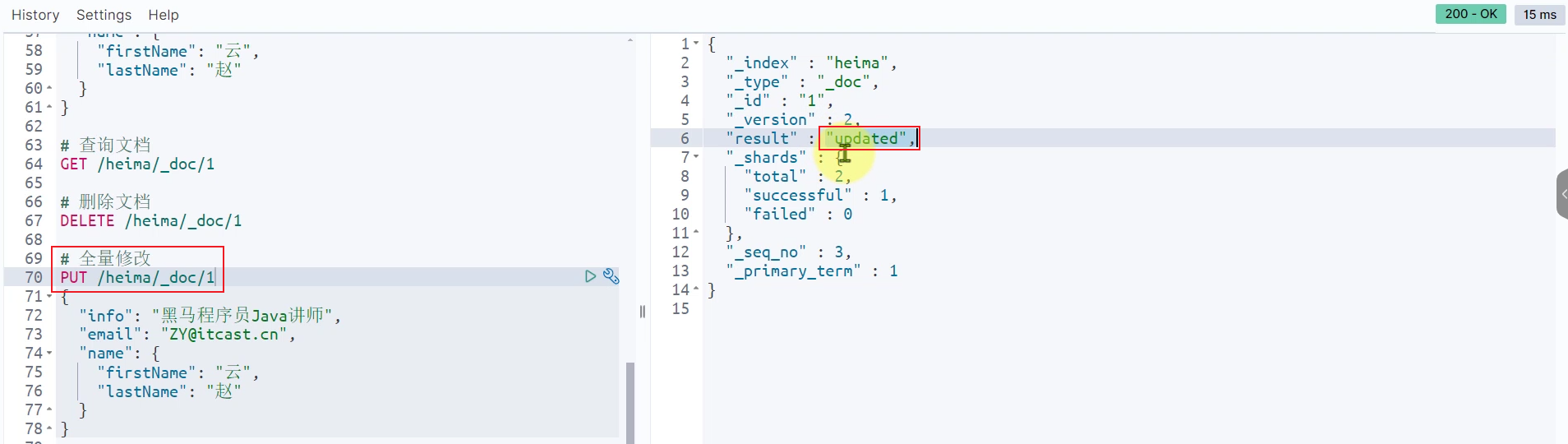
全量修改:先删除后新增
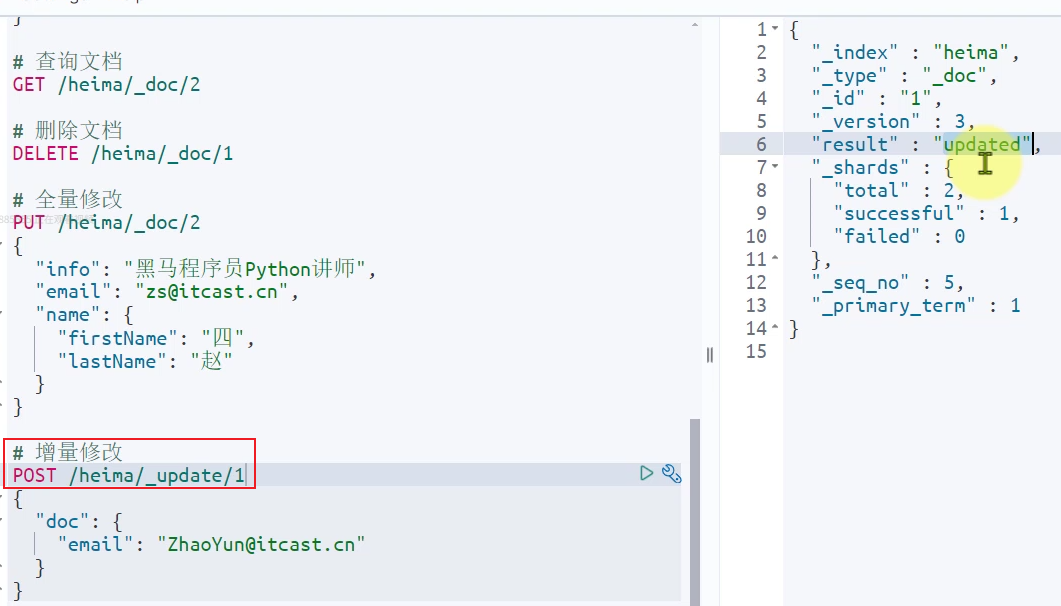
局部修改(增量修改)

批量处理:

三、JavaRestClient:
客户端初始化:
1.在item-service微服务当中引入依赖:(因为商品查找功能在该服务当中)
XML
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>2.到父工程当中指定ES版本:(由于SpringBoot当中内置了es但是版本不一致,所以需要另外配置)
XML
<properties>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>3.初始化RestHighLevelClient:
java
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));商品Mapping映射:
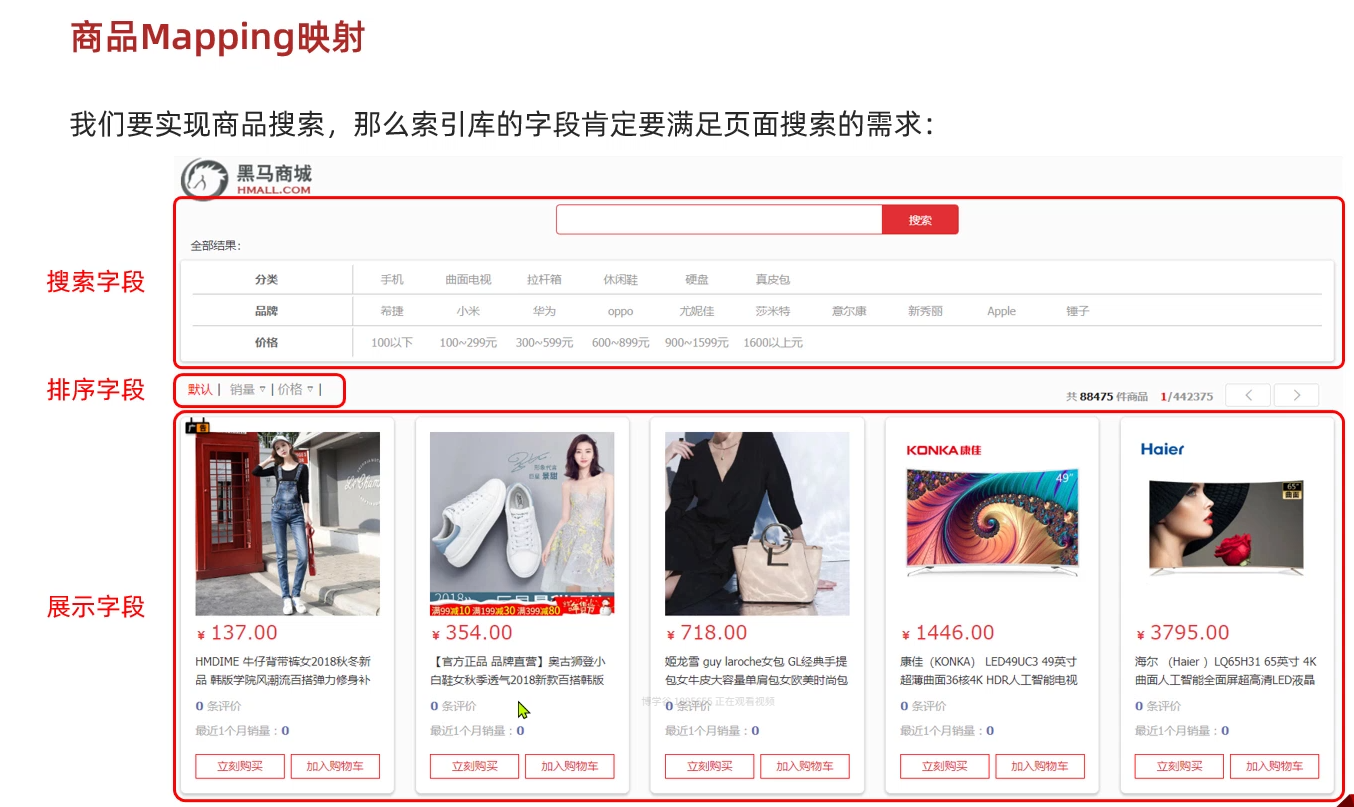
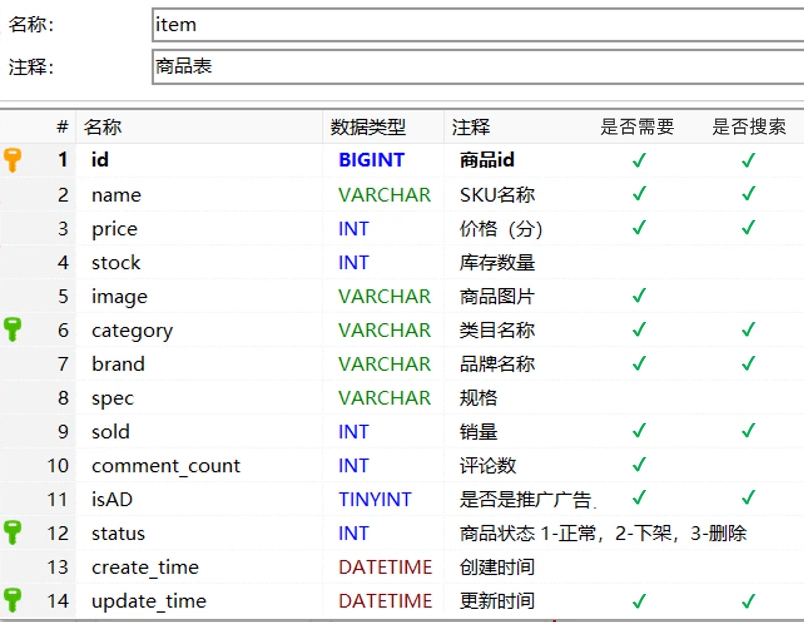
java
PUT /items
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"price":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
},
"category":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer",
"index": false
},
"isAD":{
"type": "boolean"
},
"updateTime":{
"type": "date"
}
}
}
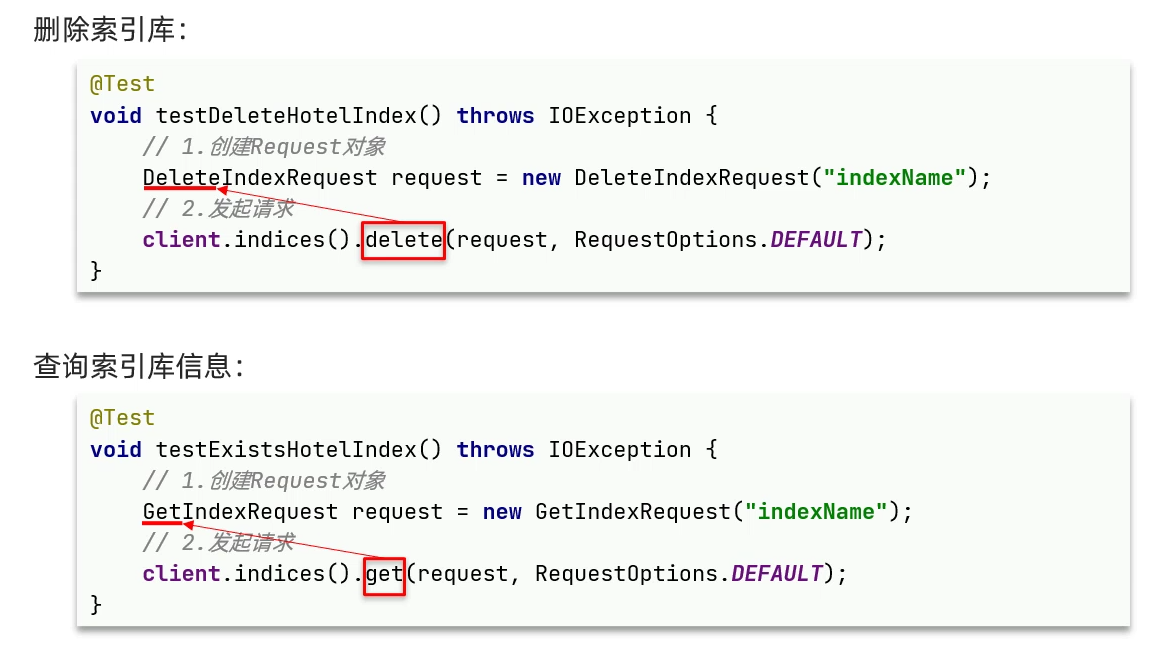
}索引库操作:
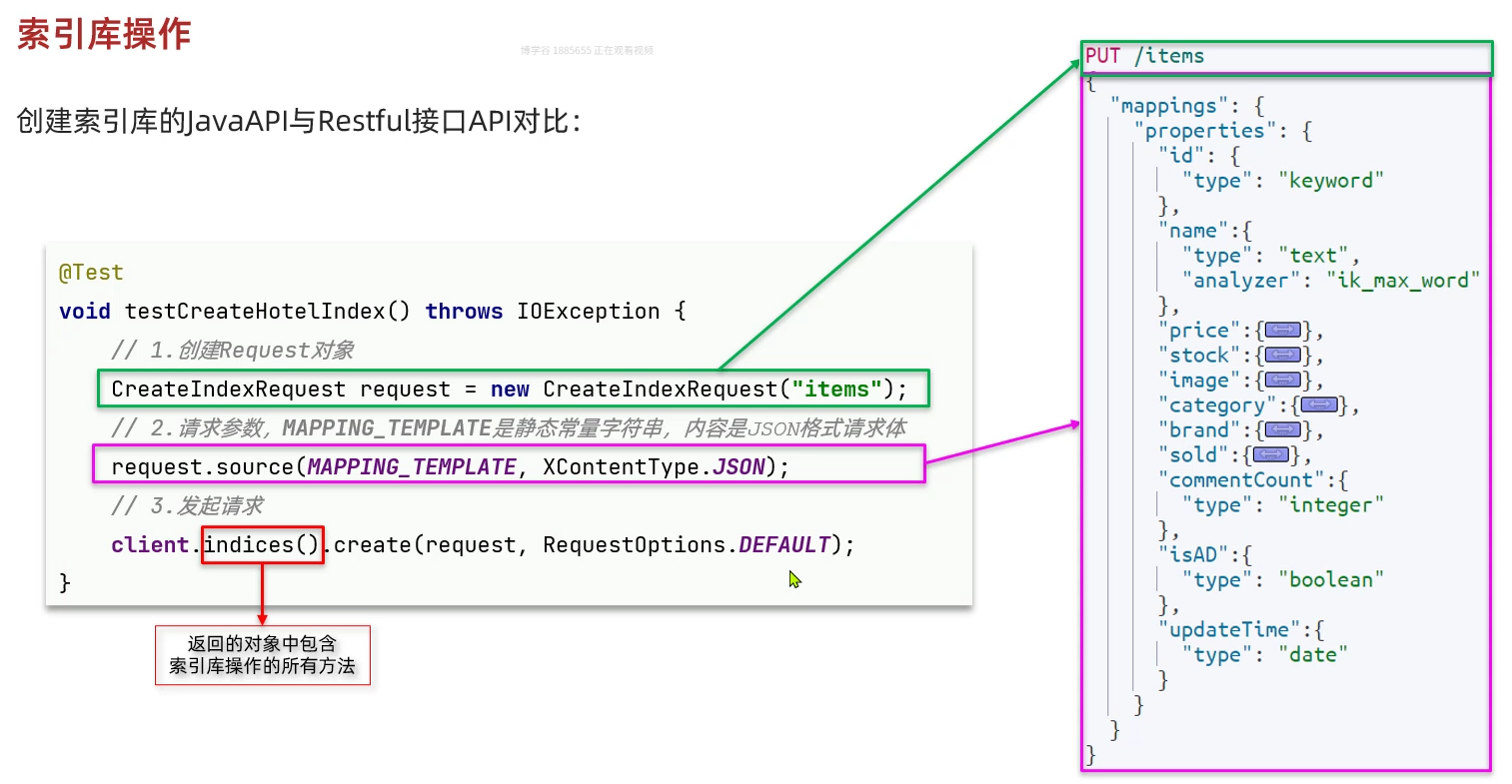
JAVA中操作文档:
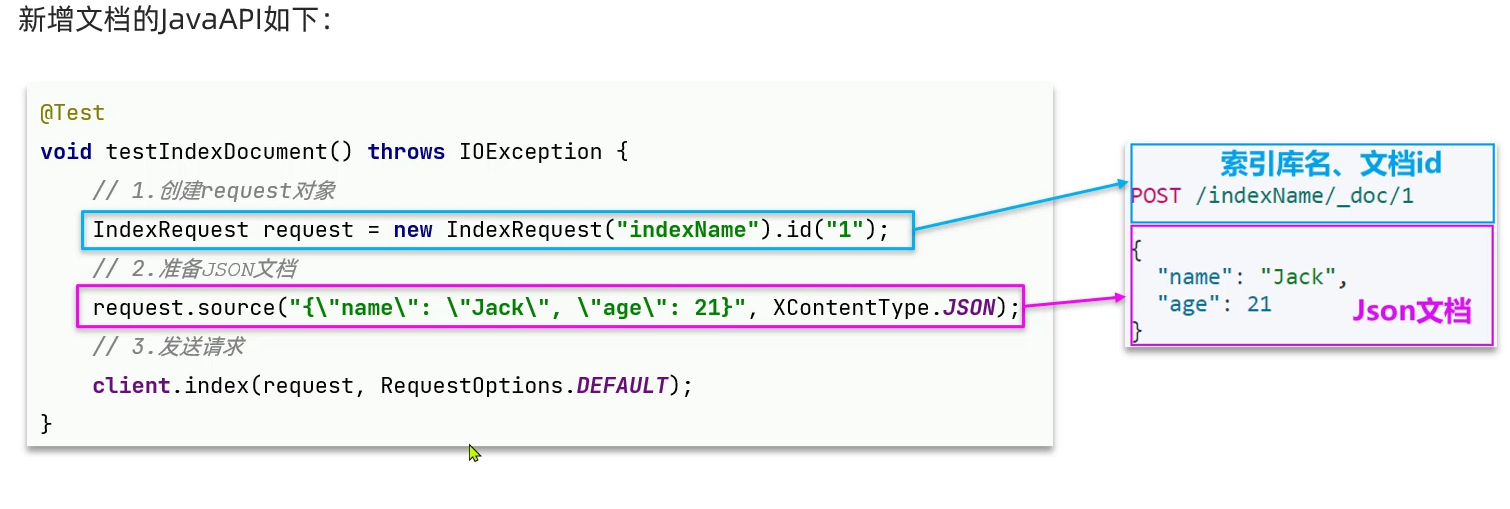
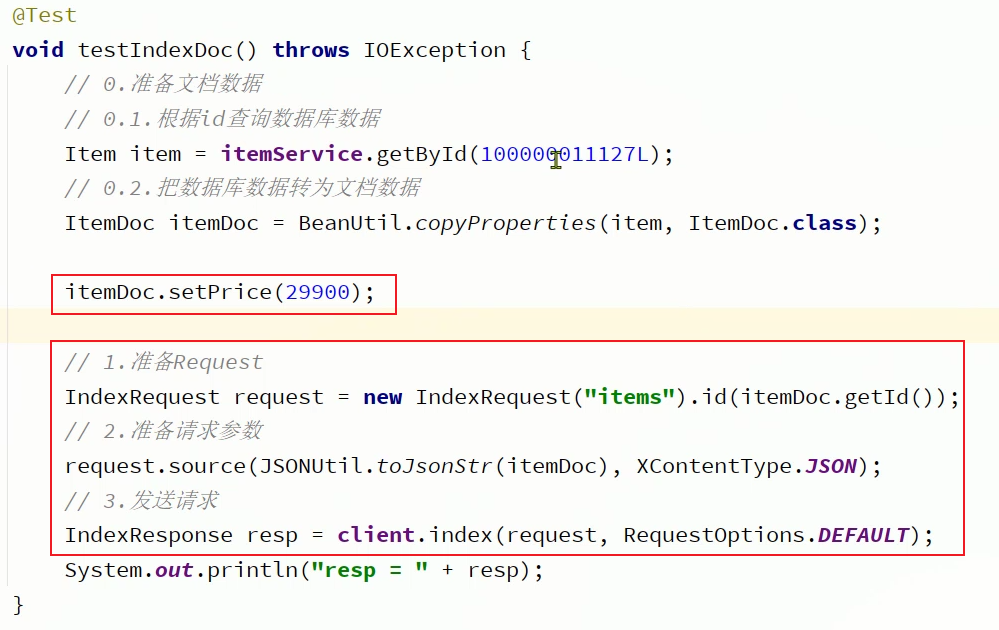
新增文档:
删除文档:

查询文档:

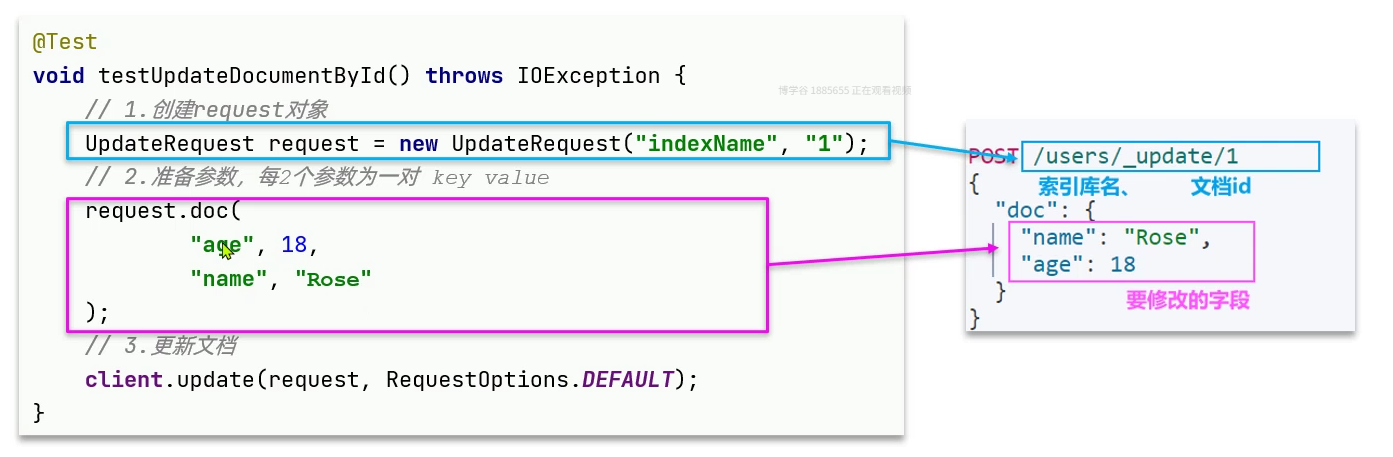
修改文档:

全量更新:
局部更新:
JAVA中操作文档小结:

批处理:
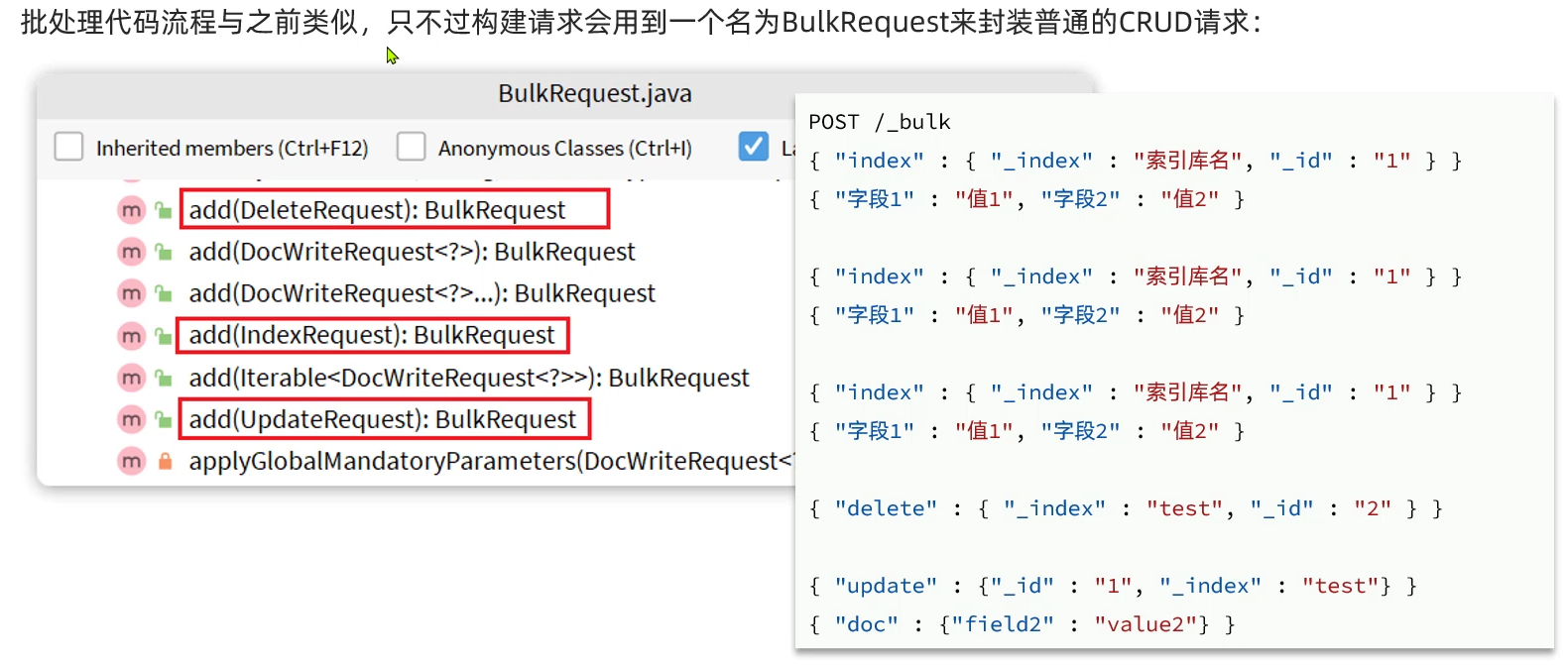
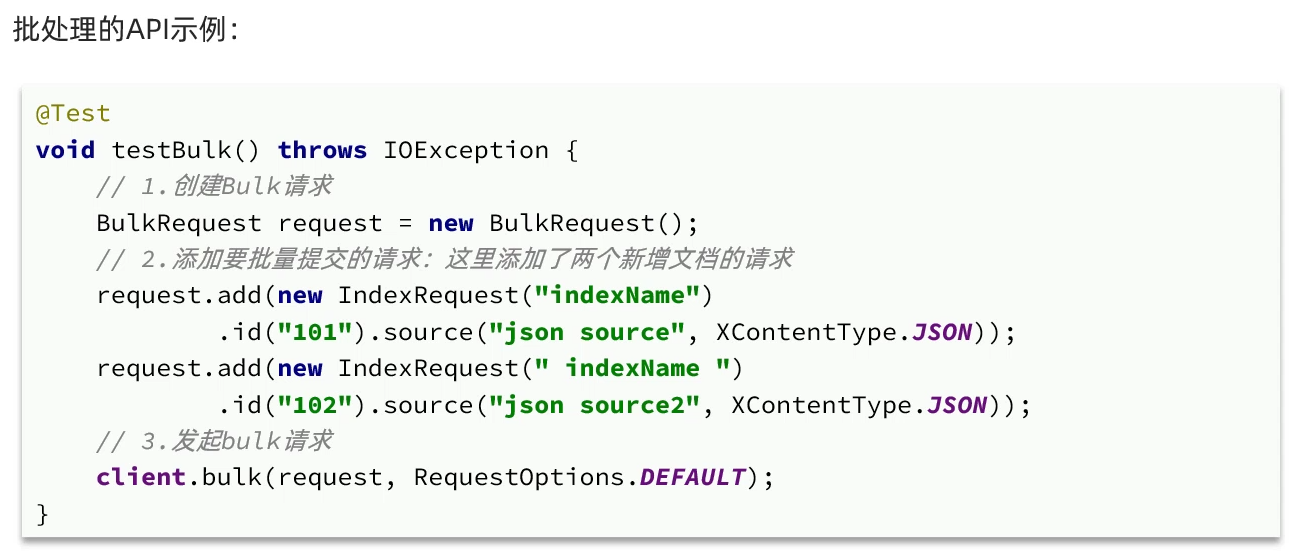
当我们要导入商品数据时,由于商品数量达到数十万,因此不可能一次性全部导入。建议采用循环遍历方式,每次导入1000条左右的数据。
item-service的DocumentTest测试类中,编写单元测试:
java
@Test
void testLoadItemDocs() throws IOException {
// 分页查询商品数据
int pageNo = 1;
int size = 1000;
while (true) {
Page<Item> page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));
// 非空校验
List<Item> items = page.getRecords();
if (CollUtils.isEmpty(items)) {
return;
}
log.info("加载第{}页数据,共{}条", pageNo, items.size());
// 1.创建Request
BulkRequest request = new BulkRequest("items");
// 2.准备参数,添加多个新增的Request
for (Item item : items) {
// 2.1.转换为文档类型ItemDTO
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest()
.id(itemDoc.getId())
.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
// 翻页
pageNo++;
}
}