DexVIP: Learning Dexterous Grasping withHuman Hand Pose Priors from Video
论文
摘要
灵巧的多指机械手具有强大的动作空间,但其形态与人手的相似性在加速机器人学习方面具有巨大潜力。我们提出了 DexVIP 方法,通过从野外的 YouTube 视频中的人手与物体交互中学习灵巧的机械手抓取。我们通过从人手与物体交互的视频中整理抓取图像 ,并在深度强化学习中对机械手的姿势施加先验条件来实现这一目标。我们方法的一个关键优势在于,所学策略能够利用自由形式的野外视觉数据。因此,它能够轻松扩展到新的物体,并且避免了在实验室中收集人类演示的标准做法------这是一种更昂贵且间接获取人类专业知识的方式。通过在 27 个物体上使用 30 自由度的模拟机械手进行实验,我们证明了 DexVIP 相较于缺乏手部姿势先验条件或依赖专门的遥操作设备来获取人类演示的现有方法具有优势,同时训练速度也更快。
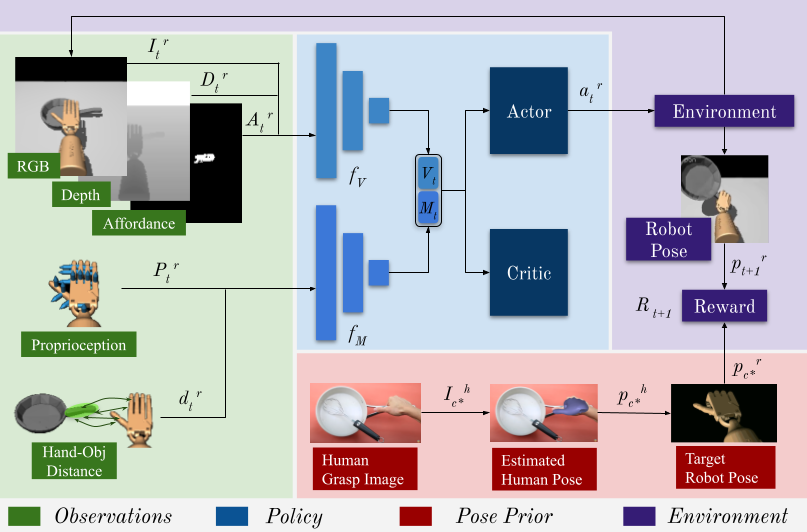
DexVIP是一种从视频中学习灵巧抓取的方法,它利用人类手部姿态先验来指导机器人抓取策略的学习。该方法的核心思想是从YouTube等互联网视频中提取人类与物体交互时的手部姿态,并将这些姿态作为先验知识融入深度强化学习框架中,从而提升机器人抓取的成功率、稳定性和功能性。
主要贡献与方法概述
1. 问题背景:
灵巧多指机器人手具有高自由度的动作空间,但其形态与人类手部相似,这为从人类行为中学习抓取策略提供了可能。传统方法通常依赖实验室环境下采集的人类演示数据(如VR遥操作、运动捕捉等),存在设备依赖性强、数据收集成本高、演示过程间接等问题。DexVIP通过利用互联网视频中的自然人类交互数据,避免了这些限制。
2. 方法流程:
- 数据收集:从HowTo100M数据集中筛选包含人类抓取特定物体的视频帧,构建包含715张图像的数据集(平均每物体26张图像)。
- 手部姿态提取:使用FrankMocap方法从图像中估计3D人类手部关节姿态。
- 姿态聚类与目标生成:对同一物体的多个人类手部姿态进行k-medoid聚类,选择最大簇的质心作为共识目标姿态,并通过逆向运动学将其映射到机器人手部(Adroit手模型)。
- 强化学习框架:在PPO算法基础上,设计奖励函数结合抓取成功奖励(Rsucc)、功能区域接触奖励(Raff)和人类姿态匹配奖励(Rpose)。其中,Rpose仅在机器人手部与物体接触时激活,鼓励其模仿人类抓取姿态。
3. 实验与结果:
- 对比方法:与基于物体质心(COM)、触觉传感器(TOUCH)、视觉功能区域(GRAFF)以及VR演示(DAPG)的方法进行对比。
- 评估指标:抓取成功率、稳定性、功能性和姿态相似性。
- 关键结果:
- DexVIP在27个物体上显著优于基线方法,抓取成功率达68%(ContactDB物体)。
- 训练速度比次优方法快20%,且对噪声感知与驱动具有强鲁棒性(噪声环境下成功率仍达64%)。
- 在未见过的物体上(非ContactDB物体),DexVIP性能下降仅4%,而DAPG下降15%,表明其良好的泛化能力。
4. 优势与创新点
- 数据来源灵活:直接利用互联网视频中的自然人类交互数据,无需专用设备或实验室环境,显著降低数据收集成本。
- 间接监督:仅需视觉姿态先验,而非完整的状态-动作轨迹,减轻了对精确演示数据的依赖。
- 功能导向抓取:通过结合物体功能区域预测和人类姿态先验,鼓励机器人学习适用于后续任务的功能性抓取。
- 强扩展性:新增物体时仅需下载相关视频,可快速适应新对象。
5. 局限性与未来方向
- 当前工作仅在仿真环境中验证,尚未部署到真实机器人。
- 依赖手部姿态估计精度(如FrankMocap的误差),但实验表明其对姿态误差具有鲁棒性。
- 未来计划扩展至更精细的操作任务(如旋转、放置等)。
DexVIP通过将人类视频中的手部姿态先验与强化学习结合,为灵巧抓取提供了一种可扩展、高效的解决方案,推动了从互联网数据中学习机器人技能的研究进展。