最近被性能组同学盯上了,说我负责的一个基础模块在某硬件平台上,开机阶段有个线程cpu占用较高,需配合调查。
最终发现,系统中的libuv版本较老,特定场景下函数uv__async_spin会长时间空转,消耗较多cpu;新版本的libuv对此做了优化,同样场景下cpu占用时长降幅高达50%以上。
libuv v1.40.0版本引入该问题,v1.45.0修复该问题。
1. 背景
1.1 libuv async基本用法
libuv async机制可以在其他线程唤醒event loop并触发回调函数执行,示例代码如下:
event loop跑在main主线程- 子线程
triggerThread每隔一秒调用一次uv_async_send唤醒主线程的event loop,触发回调函数callback在event loop所在线程执行(即主线程)
c++
#include <unistd.h>
#include <uv.h>
#include <thread>
void callback(uv_async_t* async) {
printf("I'm called\n");
}
int main() {
uv_async_t async;
uv_loop_t* loop = uv_default_loop();
uv_async_init(loop, &async, callback);
std::thread triggerThread([&]() {
while (true) {
sleep(1);
uv_async_send(&async);
}
});
return uv_run(loop, UV_RUN_DEFAULT);
}上述代码执行后,每隔1s调用一次callback,输出示例如下:
css
I'm called
I'm called
...1.2 libuv async工作原理
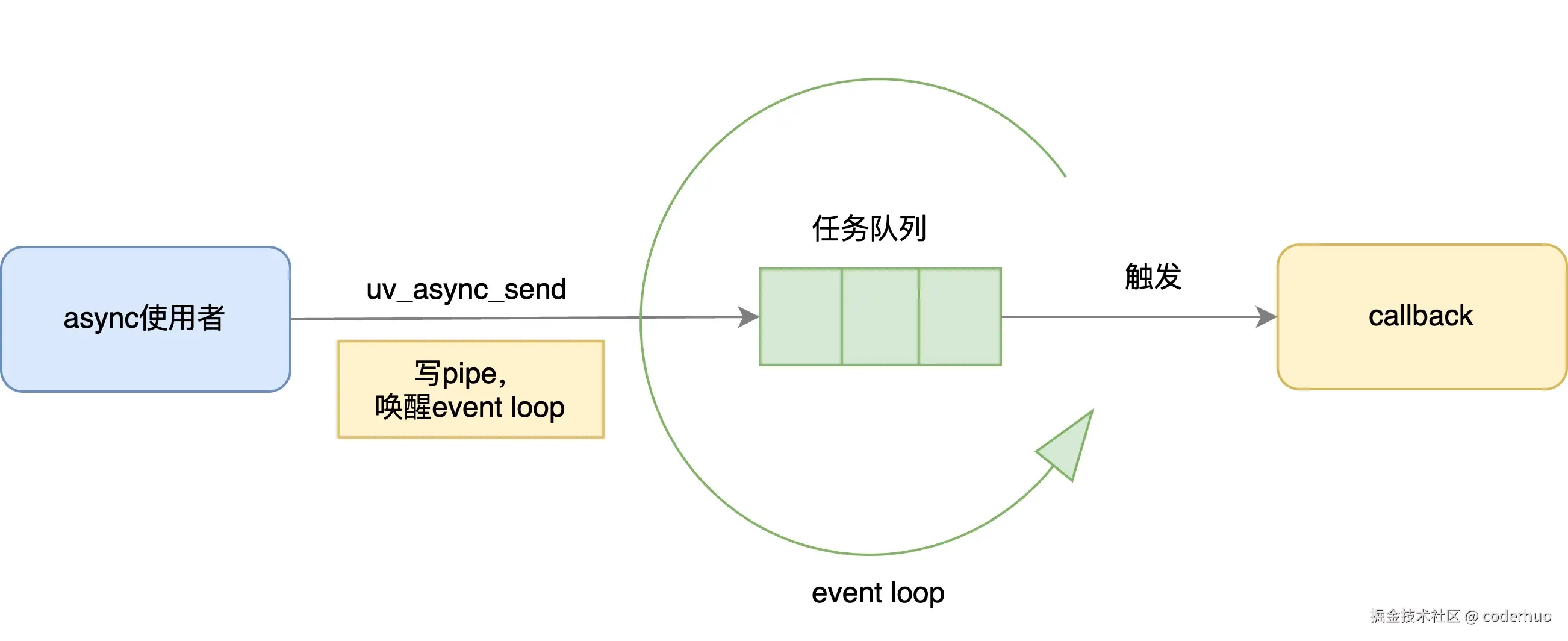
libuv async工作原理如下图所示:
- 用户在其他线程调用
uv_async_send唤醒event loop线程 event loop线程执行uv_async_t绑定的回调函数
我们结合代码看下异步唤醒的流程。
uv_async_send实现如下:
- 尝试 将本
uv_async_t的pending标记从0改为1,表明正在唤醒event loop。注意这里用了尝试 二字,如果pending状态不为0,本次uv_async_send直接返回,啥也没干。这会不会导致无法触发callback? 不会的。如果走到这个流程,说明已经有其他线程在调用uv_async_send了。这就是uv_async_send的折叠效应 ,libuv保证调用uv_async_send一定会触发callback,但不保证每调用一次uv_async_send就触发一次callback,比如连续调用5次uv_async_send,libuv保证至少触发一次callback,但不会多于5次。 - 唤醒
event loop,函数uv__async_send中调用系统函数write(fd, buf, len)函数写pipe - 将本
uv_async_t的pending标记从1改为2,表明本次唤醒事件结束
c
// libuv v1.40.0 src/unix/async.c
int uv_async_send(uv_async_t* handle) {
/* Do a cheap read first. */
if (ACCESS_ONCE(int, handle->pending) != 0)
return 0;
/* Tell the other thread we're busy with the handle. */
if (cmpxchgi(&handle->pending, 0, 1) != 0)
return 0;
/* Wake up the other thread's event loop. */
uv__async_send(handle->loop);
/* Tell the other thread we're done. */
if (cmpxchgi(&handle->pending, 1, 2) != 1)
abort();
return 0;
}event loop线程的uv_run会调用下面的uv__async_io,它又会调用uv__async_spin处理pending状态,判断是否需要调用uv_async_t绑定的callback:
c
// libuv v1.40.0 src/unix/async.c
static void uv__async_io(uv_loop_t* loop, uv__io_t* w, unsigned int events) {
char buf[1024];
ssize_t r;
QUEUE queue;
QUEUE* q;
uv_async_t* h;
assert(w == &loop->async_io_watcher);
// 读取pipe的内容,这里压根不关心内容是啥,也没必要关心
// 注意,这里会一直读取,直到pipe中无数据可读,可以结合前面提到的[折叠效应]细品下为啥
for (;;) {
r = read(w->fd, buf, sizeof(buf));
if (r == sizeof(buf))
continue;
if (r != -1)
break;
if (errno == EAGAIN || errno == EWOULDBLOCK)
break;
if (errno == EINTR)
continue;
abort();
}
// 判断哪些uv_async_t被触发过了,然后调用对应的回调函数
QUEUE_MOVE(&loop->async_handles, &queue);
while (!QUEUE_EMPTY(&queue)) {
q = QUEUE_HEAD(&queue);
h = QUEUE_DATA(q, uv_async_t, queue);
QUEUE_REMOVE(q);
QUEUE_INSERT_TAIL(&loop->async_handles, q);
// 这个uv__async_spin中处理了pending的状态,和前面uv_async_send相对应
if (0 == uv__async_spin(h))
continue; /* Not pending. */
if (h->async_cb == NULL)
continue;
// 调用回调函数
h->async_cb(h);
}
}uv__async_spin实现如下:我们重点关注cmpxchgi(&handle->pending, 2, 0)这一句,它的意思是:
- 如果
handle->pending当前的值是2,将其设置为0,然后返回2;(意思是uv_async_send调用过,但是回调还没触发) - 如果
handle->pending当前的值是0,啥也不干,返回当前值0;(意思是uv_async_send未被调用过) - 如果
handle->pending当前的值是1,啥也不干,返回当前值1;(意思是uv_async_send正在被调用),注意这种情况下uv__async_spin会一直等待直到handle->pending的值变为2,即uv_async_send调用结束,这为本文描述的bug埋下了伏笔。
c
// libuv v1.40.0 src/unix/async.c
static int uv__async_spin(uv_async_t* handle) {
int i;
int rc;
for (;;) {
/* 997 is not completely chosen at random. It's a prime number, acyclical
* by nature, and should therefore hopefully dampen sympathetic resonance.
*/
for (i = 0; i < 997; i++) {
/* rc=0 -- handle is not pending.
* rc=1 -- handle is pending, other thread is still working with it.
* rc=2 -- handle is pending, other thread is done.
*/
rc = cmpxchgi(&handle->pending, 2, 0);
if (rc != 1)
return rc;
/* Other thread is busy with this handle, spin until it's done. */
cpu_relax();
}
/* Yield the CPU. We may have preempted the other thread while it's
* inside the critical section and if it's running on the same CPU
* as us, we'll just burn CPU cycles until the end of our time slice.
*/
sched_yield();
}
}2. 问题场景
下面是问题复现时抓的trace,结合代码分析:
- 主线程在
uv__async_send中调用系统函数write写pipe时cpu被抢占 event loop所在线程21757在事件循环中检测到handle->pending状态为1,也就是uv_async_send正在被调用,所以在uv__async_spin中自旋等待- 最终的结果就是,uv__async_spin总耗时313ms,cpu空转183ms
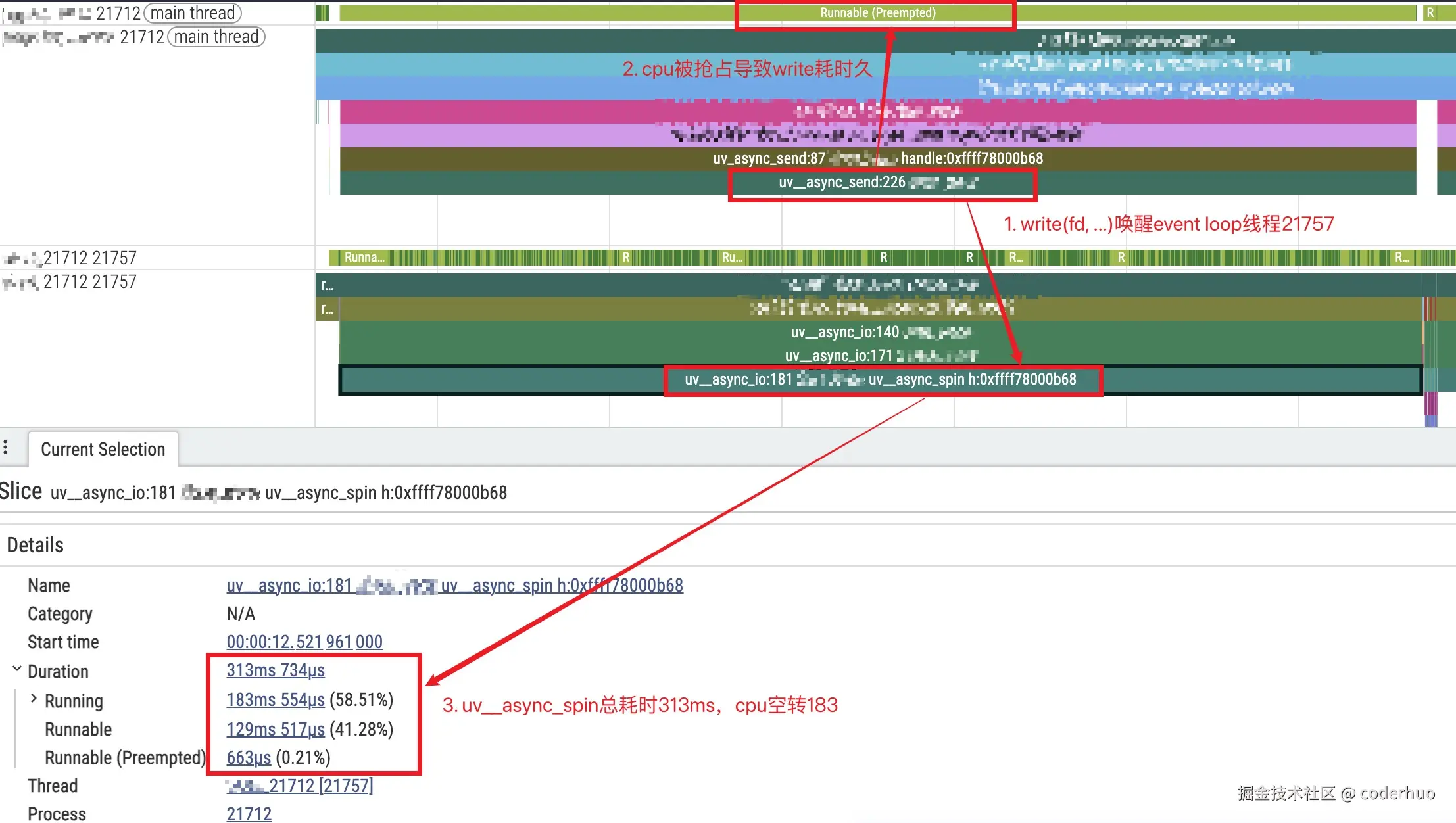
出问题的平台io性能较差,write fd耗时较久,其他io性能好的平台未观察到该现象。 {: .prompt-info }
进一步设想下,这个问题在单cpu场景,或者进程被绑定到某个cpu的场景更容易出现。如下图所示,只要event loop线程在绿色区间被唤醒,都将做无效空转。

3. 修改方案
我们看下libuv当前最新版本v1.51.0中是如何做的。
首先pending状态简化了,只有0和1两个状态,uv_async_send中只做两件事:
- 尝试 将本
uv_async_t的pending标记从0改为1,表明待处理 - 调用
uv__async_send写pipe唤醒event loop
c
// libuv v1.51.0 src/unix/async.c
// 为了便于理解,删除了无关的busy状态
int uv_async_send(uv_async_t* handle) {
_Atomic int* pending;
pending = (_Atomic int*) &handle->pending;
/* Do a cheap read first. */
if (atomic_load_explicit(pending, memory_order_relaxed) != 0)
return 0;
/* Wake up the other thread's event loop. */
if (atomic_exchange(pending, 1) == 0)
uv__async_send(handle->loop);
return 0;
}uv__async_io最大的变化是,不再调用uv__async_spin了,直接判断pending状态:
- 为0说明无需回调uv_async_t绑定的callback
- 为1说明需要回调uv_async_t绑定的callback
干净利落,不再管uv__async_send是否已经调用完成。
c
// libuv v1.51.0 src/unix/async.c
static void uv__async_io(uv_loop_t* loop, uv__io_t* w, unsigned int events) {
// 读取pipe部分和之前相同,这里略过
uv__queue_move(&loop->async_handles, &queue);
while (!uv__queue_empty(&queue)) {
q = uv__queue_head(&queue);
h = uv__queue_data(q, uv_async_t, queue);
uv__queue_remove(q);
uv__queue_insert_tail(&loop->async_handles, q);
// 看到没,uv__async_spin已经没了
/* Atomically fetch and clear pending flag */
pending = (_Atomic int*) &h->pending;
if (atomic_exchange(pending, 0) == 0)
continue;
if (h->async_cb == NULL)
continue;
h->async_cb(h);
}
}回想第2部分的问题场景,新版本libuv的行为是怎么样的呢:
uv__async_io中检测到pending状态为1,直接调用该uv_async_t绑定的callback,然后将pending状态置为0uv__async_send中写pipe完成,下一次事件循环中,uv__async_io再次被触发,但是检测pending状态时发现为0,啥也不干,也就是说,白唤醒了一次。我感觉这样做是对的,比原来的成本低多了。
4. 题外话
具体到实际项目,解决这个问题有两种方案:
- 升级libuv
- 老版本打补丁
具体应该选择哪种方案呢?个人建议:
- 新项目直接升级libuv,理论上新版本应该修复了更多的bug
- 老项目打patch,影响范围可控
我司的libuv是其他团队维护的,针对该问题,他们经过一番讨论,最终选择的也是打补丁的方式。实施后,同样场景下cpu占用时长降幅高达50%以上。
------------------------End:更多内容,请关注我的公众号coderhuo------------------------
