🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 ↓↓文末获取源码联系↓↓🍅
基于大数据的全球大学排名数据可视化分析系统-功能介绍
本系统"【python大数据毕设实战】全球大学排名数据可视化分析系统"是一个专注于全球高等教育领域的综合性数据分析平台,旨在将复杂的世界大学排名数据转化为直观、易懂的可视化图表和深度洞察。系统核心构建于Python技术栈,并深度融合了大数据处理框架Hadoop与Spark,以应对海量数据带来的存储与计算挑战。后端采用轻量而强大的Django框架,负责业务逻辑处理与数据接口提供,前端则利用Vue的组件化开发思想和Echarts丰富的图表库,为用户打造一个交互流畅、视觉美观的操作界面。系统的工作流程始于对全球大学排名原始数据的获取,随后利用Spark的分布式计算能力进行高效的数据清洗、预处理与整合,确保了分析结果的准确性与可靠性。在此基础上,系统设计了多维度的数据分析模型,不仅涵盖了传统的排名查询、国家/地区实力对比等宏观分析,还深入到教学、研究、产业收入等多个核心指标的相关性探究,并创新性地引入了K-Means聚类算法,对大学进行科学分群与画像。最终,所有分析结果都通过API接口传递至前端,以动态地图、柱状图、雷达图、散点图等多种形式生动展现,为用户提供了一个全面、动态、且数据驱动的全球高等教育格局观察窗口。
基于大数据的全球大学排名数据可视化分析系统-选题背景意义
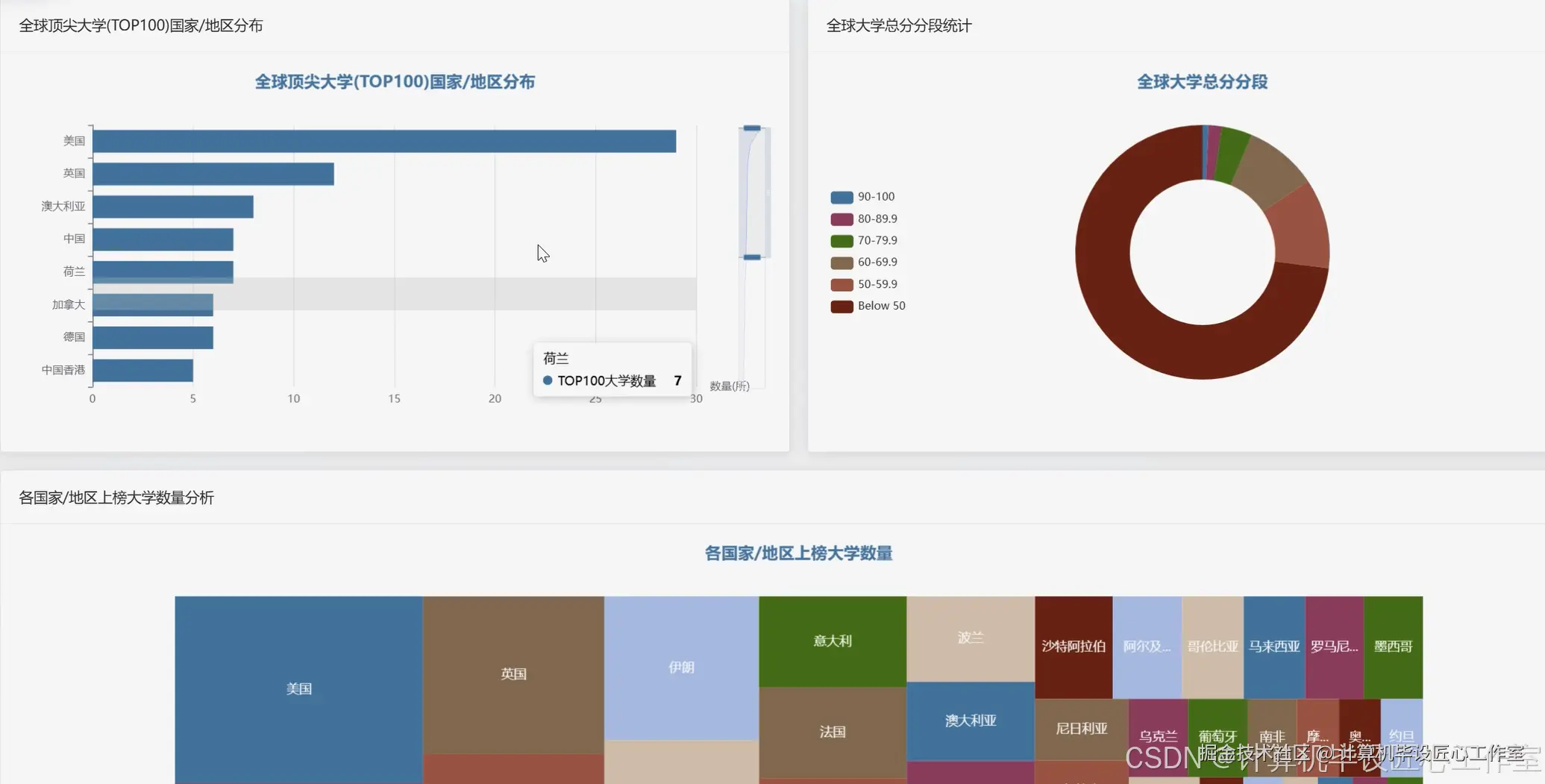
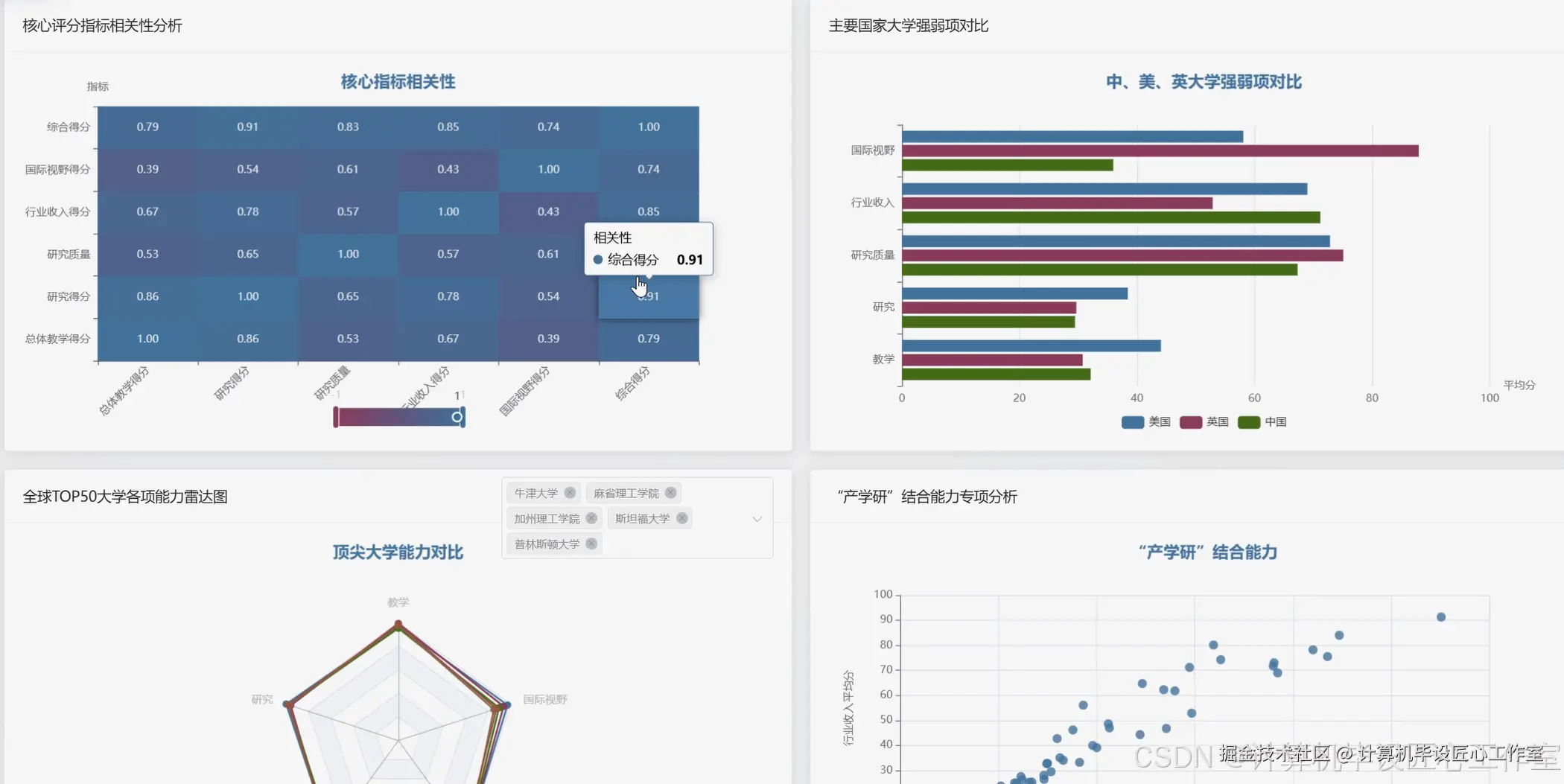
选题背景 在当今全球化的时代,高等教育的选择已成为学生、学者乃至政策制定者面临的一个关键决策点。各类世界大学排名,如泰晤士高等教育世界大学排名、QS世界大学排名等,已成为衡量大学综合实力和国际声誉的重要参考依据。然而,这些排名机构发布的原始数据往往只是庞大的表格,对于普通用户而言,很难从中获得超越简单排名的深入见解。传统的分析方法,例如使用电子表格软件,在处理和分析如此大规模、多指标的数据集时显得效率低下,并且难以执行复杂的多变量关联性分析。用户迫切需要一个更强大、更智能的工具来挖掘这些数据背后的价值。随着大数据技术的飞速发展,我们有能力对这类海量信息进行更深层次的探索和处理。因此,本课题应运而生,旨在利用先进的大数据技术,对全球大学排名数据进行系统性的整合、分析与可视化,从而揭示隐藏在数字背后的教育发展规律与模式,为用户提供一个更丰富、更立体的大学排名解读视角。 选题意义 本课题的实际意义在于,它为所有关注全球高等教育发展的人群提供了一个直观且强大的数据探索工具。对于即将面临升学选择的学生和家长来说,他们不再局限于查看一个单一的、模糊的综合排名,而是可以自由地从不同维度进行筛选和对比,比如查看哪个国家在"研究质量"上表现突出,或者比较心仪几所大学在"国际化"水平和"产业收入"上的具体差异,这帮助他们做出更符合个人需求和职业规划的判断。从技术实现的角度来看,这个项目完整地展示了如何运用现代数据科学技术解决一个特定领域的实际问题。它具体实践了从数据采集、清洗、存储,到利用Spark进行分布式计算与分析,再到最终通过Web技术进行结果呈现的全过程,特别是系统中的聚类分析功能,它超越了简单的排名,尝试根据大学的多维特征对其进行科学分类,为理解不同大学的办学特色和发展模式提供了新的思路。总的来说,这个毕业设计不仅是一个功能性的应用程序,也是一次关于如何将大数据技术应用于教育数据分析领域的有益实践,其成果对于计算机专业的学生完成毕业设计,以及教育领域的研究者进行数据探索都具有较好的参考价值。
基于大数据的全球大学排名数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的全球大学排名数据可视化分析系统-视频展示
基于大数据的全球大学排名数据可视化分析系统-图片展示
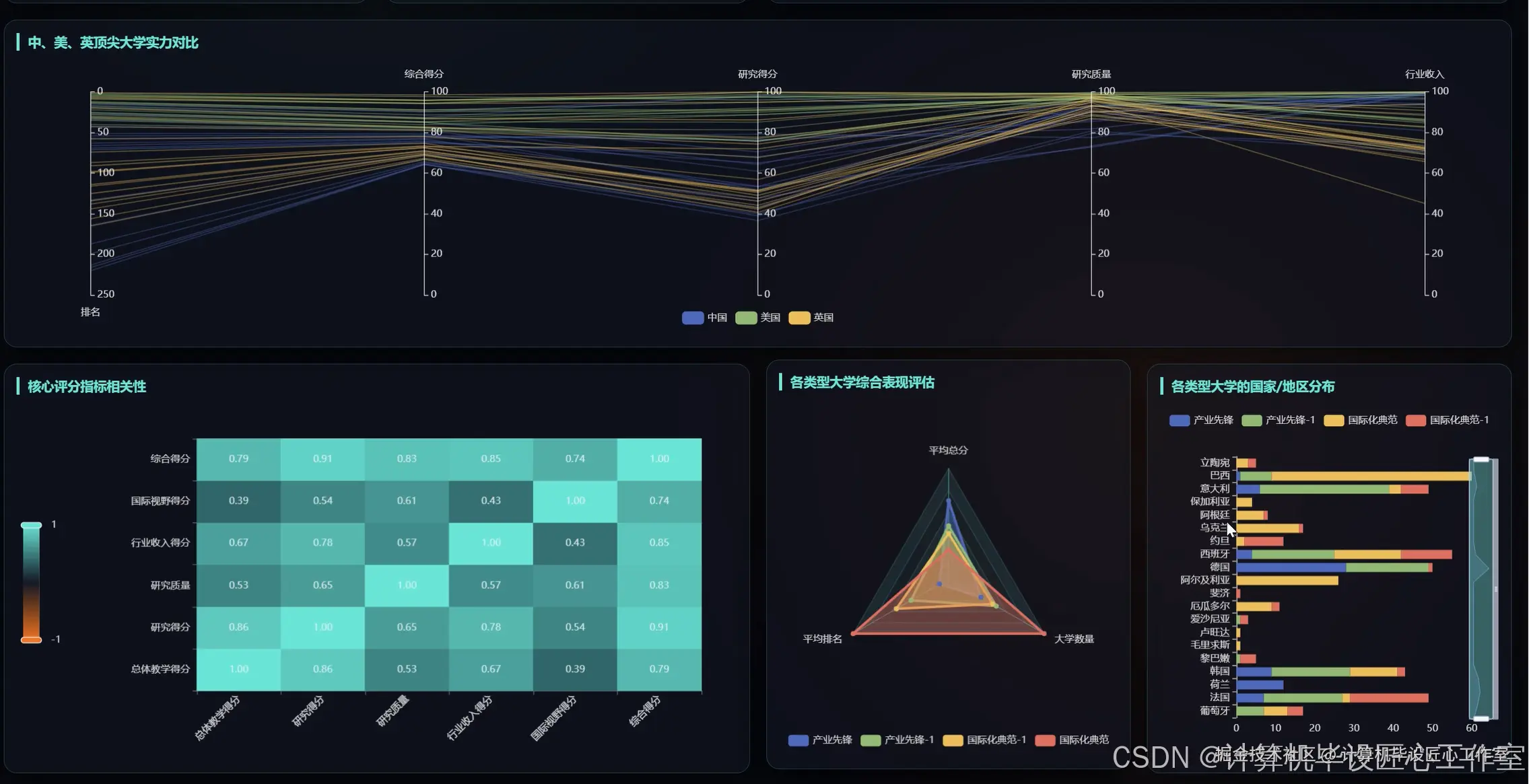
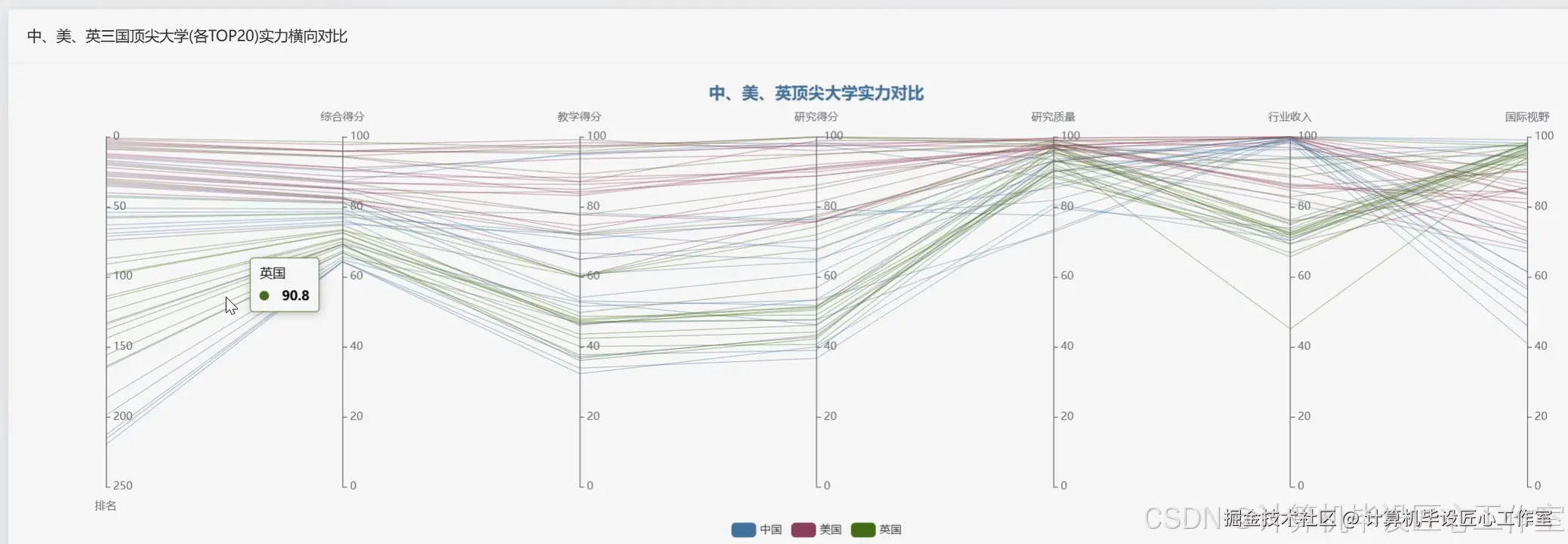
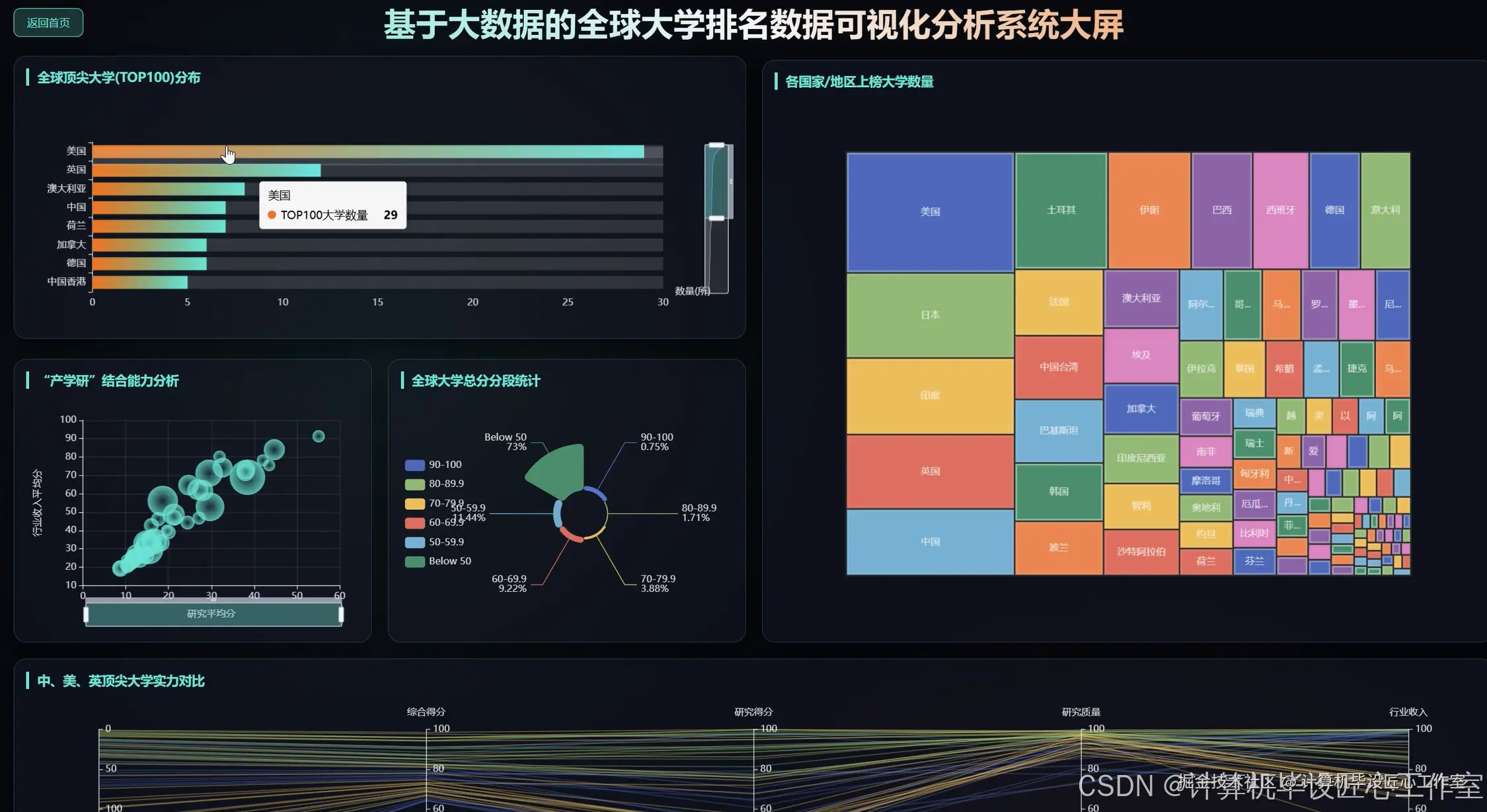
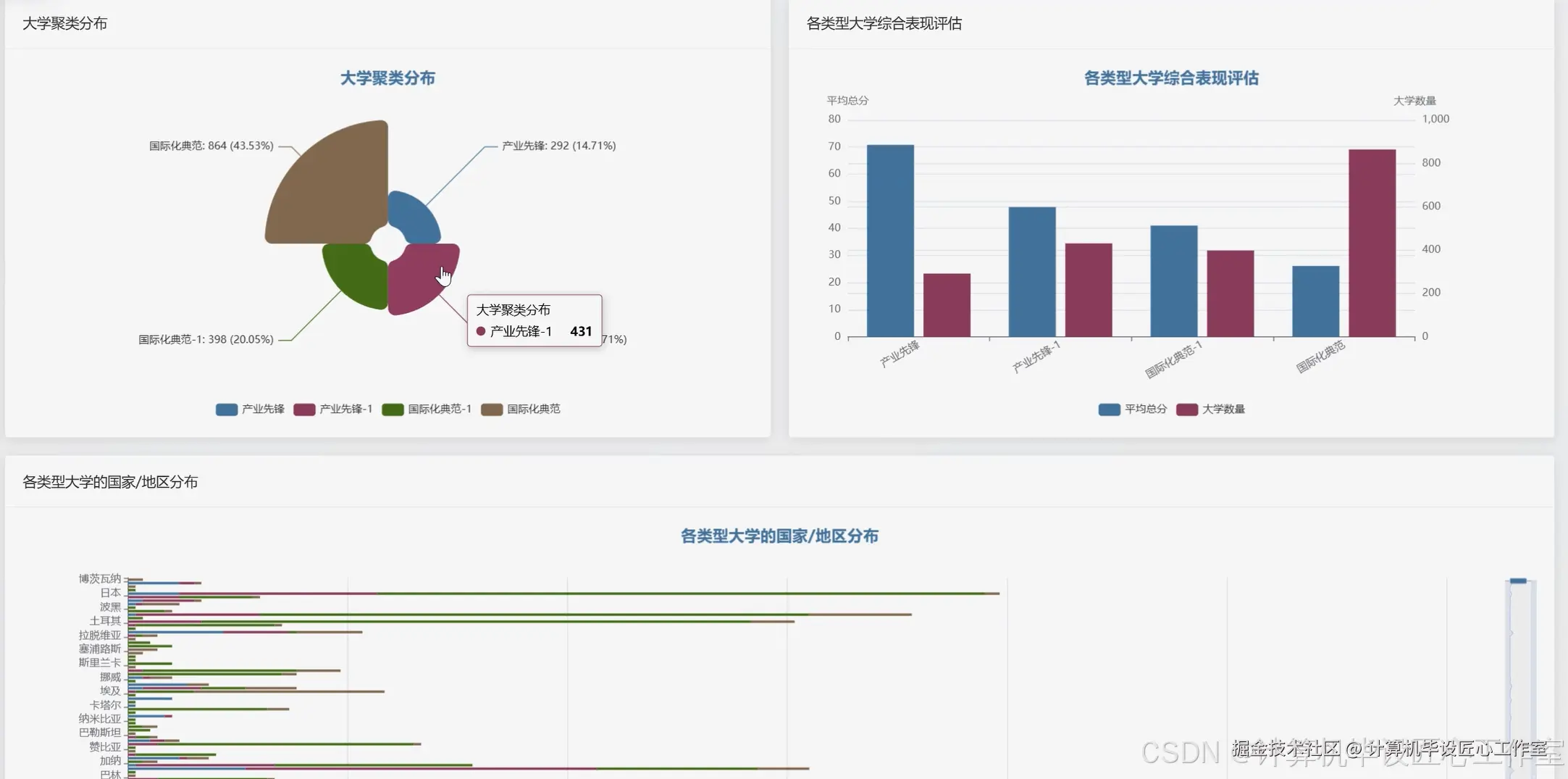
基于大数据的全球大学排名数据可视化分析系统-代码展示
python
from pyspark.sql import SparkSession, functions as F
from pyspark.ml.feature import VectorAssembler, StandardScaler, KMeans
from pyspark.ml import Pipeline
# 初始化SparkSession,这是所有Spark功能的入口点
spark = SparkSession.builder \
.appName("UniversityRankingAnalysis") \
.getOrCreate()
# 功能一:数据清洗与预处理 (使用Spark SQL和DataFrame API)
def clean_and_preprocess_data(df):
# 将数值列的空值填充为0
numeric_cols = [field.name for field in df.schema.fields if field.dataType.typeName() in ['double', 'integer', 'float']]
df_filled_numeric = df.fillna(0, subset=numeric_cols)
# 将文本列的空值填充为"未知"
df_filled_all = df_filled_numeric.fillna("未知", subset=["Location"])
# 使用F.round函数将所有得分列格式化为两位小数
for col_name in ['Overall Teaching Score', 'Research Score', 'Research Quality', 'Industry Income Score', 'International Outlook Score', 'Overall Score']:
df_filled_all = df_filled_all.withColumn(col_name, F.round(df_filled_all[col_name], 2))
# 创建一个映射字典来翻译国家名称
country_mapping = {"United States": "美国", "United Kingdom": "英国", "China": "中国"}
# 使用F.when和F.otherwise创建一个新的翻译后的列,并替换原列
df_translated = df_filled_all.withColumn("Location", F.when(df_filled_all["Location"].isin(country_mapping.keys()), F.create_map([F.lit(x) for x in sum(country_mapping.items(), ())]).getItem(df_filled_all["Location"])).otherwise(df_filled_all["Location"]))
# 删除完全重复的行
df_cleaned = df_translated.dropDuplicates()
return df_cleaned
# 功能二:多维度分析 - 按国家/地区统计大学实力
def analyze_university_strength_by_country(cleaned_df):
# 1. 计算每个国家上榜大学的总数
university_count_df = cleaned_df.groupBy("Location").agg(F.count("University").alias("university_count"))
# 2. 筛选出TOP100的大学,并按国家进行分组计数
top_100_df = cleaned_df.filter(F.col("Rank") <= 100)
top_100_count_df = top_100_df.groupBy("Location").agg(F.count("University").alias("top_100_count"))
# 3. 计算每个国家上榜大学的平均综合得分
average_score_df = cleaned_df.groupBy("Location").agg(F.avg("Overall Score").alias("average_score"))
# 4. 将以上三个分析结果通过国家名称进行关联,得到一个全面的实力分析表
result_df = university_count_df.join(top_100_count_df, "Location", "left_outer").join(average_score_df, "Location", "left_outer")
# 5. 对空值进行处理,并将结果按照TOP100数量进行降序排列
final_result_df = result_df.fillna(0, subset=["top_100_count", "average_score"]).orderBy(F.desc("top_100_count"))
return final_result_df
# 功能三:基于K-Means算法的大学聚类分析
def perform_university_clustering(cleaned_df, k=4):
# 选择用于聚类的特征列
feature_cols = ['Overall Teaching Score', 'Research Score', 'Research Quality', 'Industry Income Score', 'International Outlook Score']
# 步骤1: 使用VectorAssembler将多个特征列合并成一个单一的"features"向量列
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features_vec")
# 步骤2: 使用StandardScaler对特征向量进行标准化,消除量纲影响
scaler = StandardScaler(inputCol="features_vec", outputCol="scaled_features", withStd=True, withMean=True)
# 步骤3: 创建并配置K-Means模型
kmeans = KMeans(featuresCol="scaled_features", predictionCol="cluster", k=k, seed=42)
# 步骤4: 构建一个Pipeline来串联Assembler、Scaler和K-Means
pipeline = Pipeline(stages=[assembler, scaler, kmeans])
# 步骤5: 使用清洗后的数据来训练Pipeline模型
model = pipeline.fit(cleaned_df)
# 步骤6: 使用训练好的模型对数据进行转换,得到带有聚类标签的结果
clustered_df = model.transform(cleaned_df)
# 步骤7: 为结果选择并重命名一些关键列,使其更易于理解
result_df = clustered_df.select("University", "Location", "Overall Score", "cluster")
return result_df基于大数据的全球大学排名数据可视化分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 主页获取源码联系🍅