TL;DR
- 场景:三节点集群已安装完毕,如何 10 分钟内验证连通 / 复制 / 分片 / 分布式查询都正常?
- 结论:按本文 SOP,一条脚本跑完连通性检查 → 创建 ReplicatedMergeTree/Distributed → 跨分片写读压测。
- 产出:cluster_check.sql(系统表体检)、ddl_on_cluster.sql(建表)、mini_bench.sql(压测)。
版本矩阵
| 组件 | 已验证 | 备注 |
|---|---|---|
| ClickHouse | 24.x/25.x | 原生端口 9000(native),HTTP 8123 |
| OS | Ubuntu 22.04/24.04 | 任一均可 |
| 协调服务 | ClickHouse Keeper/ZooKeeper | 已正确配置宏 {shard}/{replica} |
| 集群名 | perftest_3shards_1replicas | 与 config.xml 保持一致 |
最小可运行示例
shell
# 连接任意节点(请改为你的主机/端口/口令)
clickhouse-client -m \
--host <node1> --port 9000 \
--user <user> --password <password>
sql
-- 1) 集群视图应返回3行(3分片×1副本)
SELECT cluster, shard_num, replica_num, host_name, host_address, port
FROM system.clusters
WHERE cluster = 'perftest_3shards_1replicas'
ORDER BY shard_num, replica_num;
-- 2) 基本连通(每节点自报家门)
SELECT hostName() AS node, version() AS ch_version;
-- 3) 复制表 & 分布式表(一次性在全集群创建)
CREATE DATABASE IF NOT EXISTS demo ON CLUSTER perftest_3shards_1replicas;
CREATE TABLE demo.events ON CLUSTER perftest_3shards_1replicas
(
id UUID,
ts DateTime,
v Decimal(18,4)
)
ENGINE = ReplicatedMergeTree(
'/clickhouse/tables/{shard}/demo.events','{replica}'
)
PARTITION BY toYYYYMM(ts)
ORDER BY (ts, id);
CREATE TABLE demo.events_all ON CLUSTER perftest_3shards_1replicas
AS demo.events
ENGINE = Distributed(perftest_3shards_1replicas, demo, events, rand());
-- 4) 写入100k 行到分布式表(随机打到各分片)
INSERT INTO demo.events_all
SELECT generateUUIDv4(), now(), number/10.0
FROM numbers(100000);
-- 5) 快速校验:各分片行数分布
SELECT hostName() AS node, count() AS cnt
FROM demo.events
GROUP BY node
ORDER BY node;
-- 6) 跨分片聚合(验证分布式查询)
SELECT toStartOfMinute(ts) AS m, sum(v) AS s, count() c
FROM demo.events_all
GROUP BY m
ORDER BY m DESC
LIMIT 5;测试连接
shell
clickhouse-client -m --host h121.wzk.icu --port 9000 --user default --password clickhouse@wzk.icu如果可以从 122 连接到 121 说明你的服务已经搭建好了。 你可以测试以下,是否三台节点之间都是互通的,确保服务和服务之间一切正常,方便我们后续的学习研究。 
检验集群
任意连接一个节点,我们进行测试
h121
shell
clickhouse-client -m --host h121.wzk.icu --port 9000 --user default --password clickhouse@wzk.icu
shell
SELECT * FROM system.clusters WHERE cluster = 'perftest_3shards_1replicas';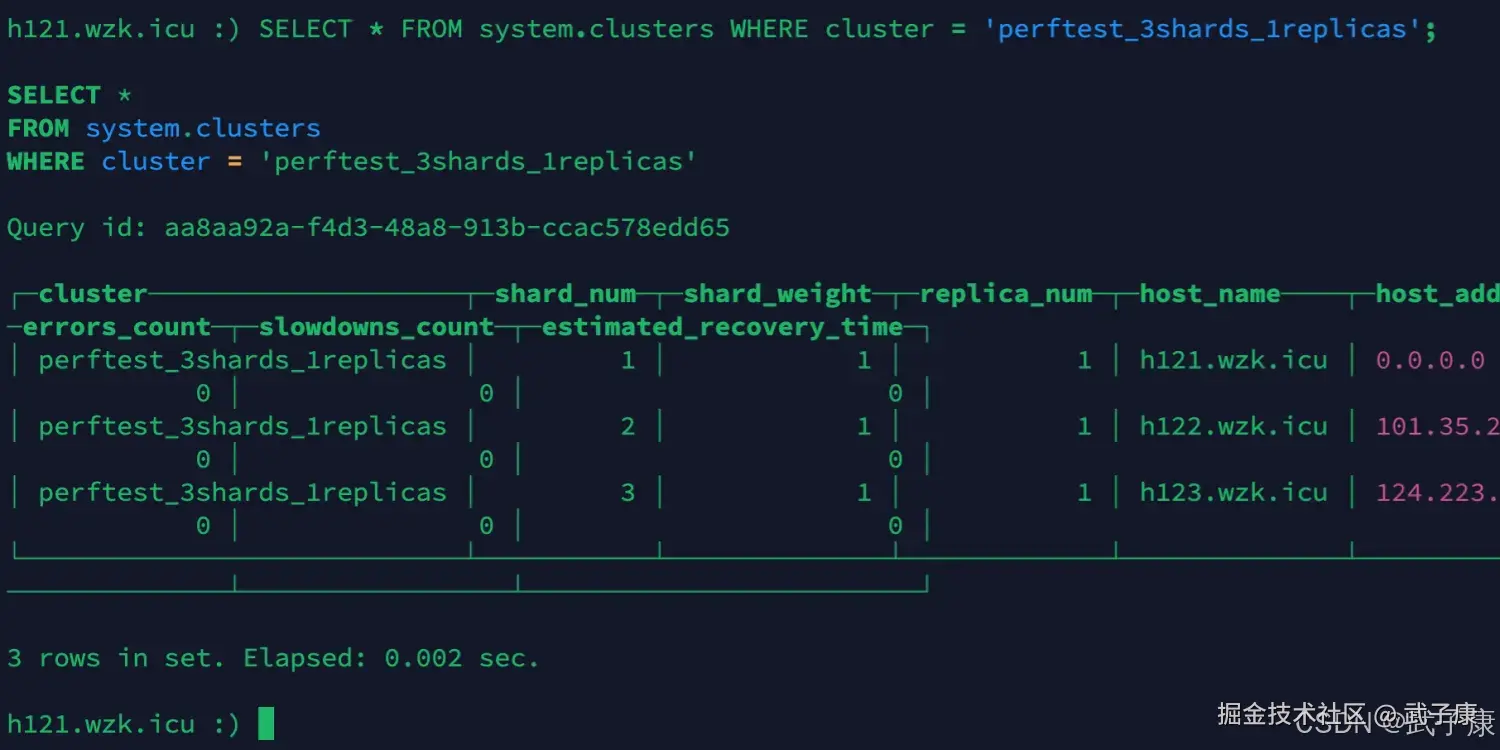
h122
shell
clickhouse-client -m --host h122.wzk.icu --port 9001 --user default --password clickhouse@wzk.icu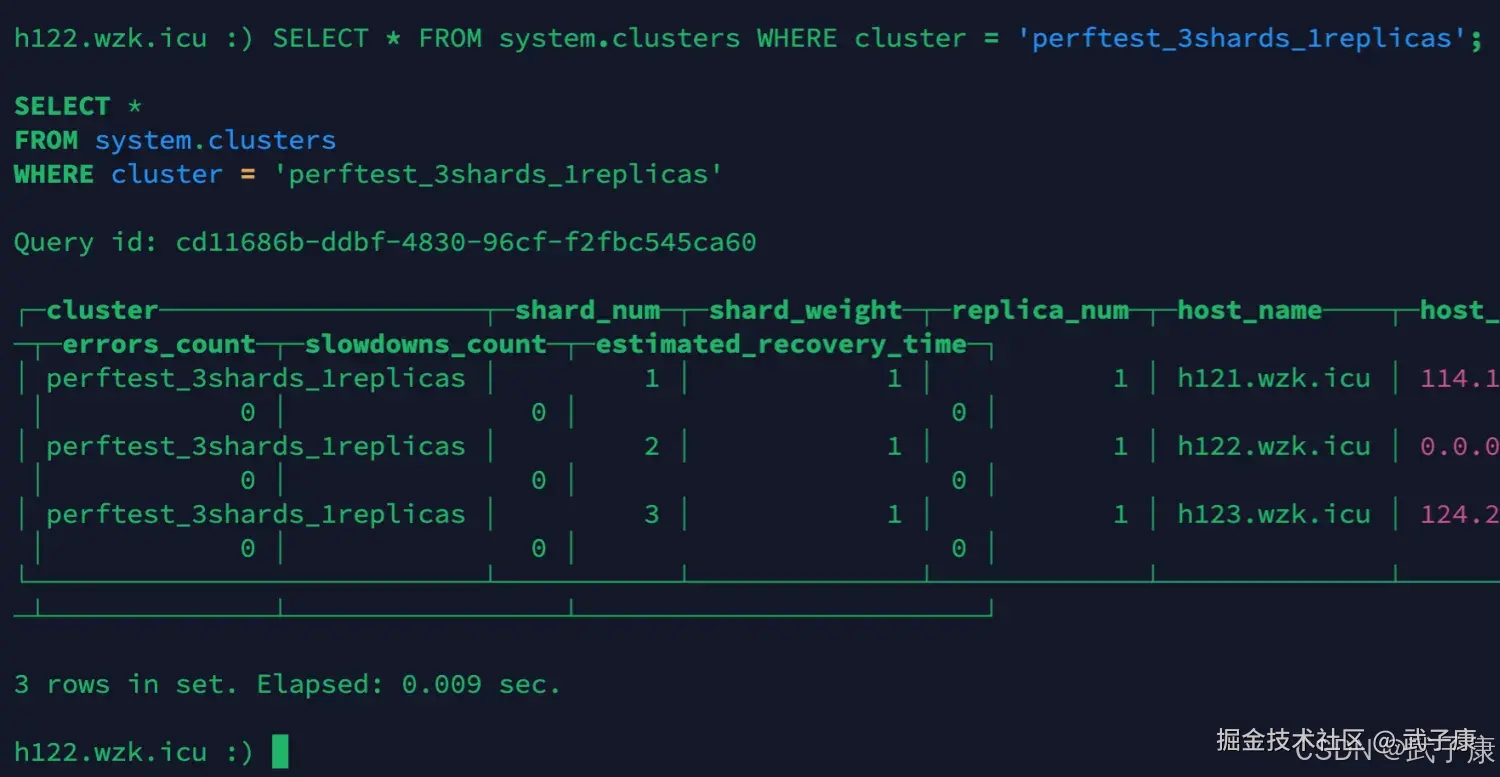
h123
shell
clickhouse-client -m --host h123.wzk.icu --port 9001 --user default --password clickhouse@wzk.icu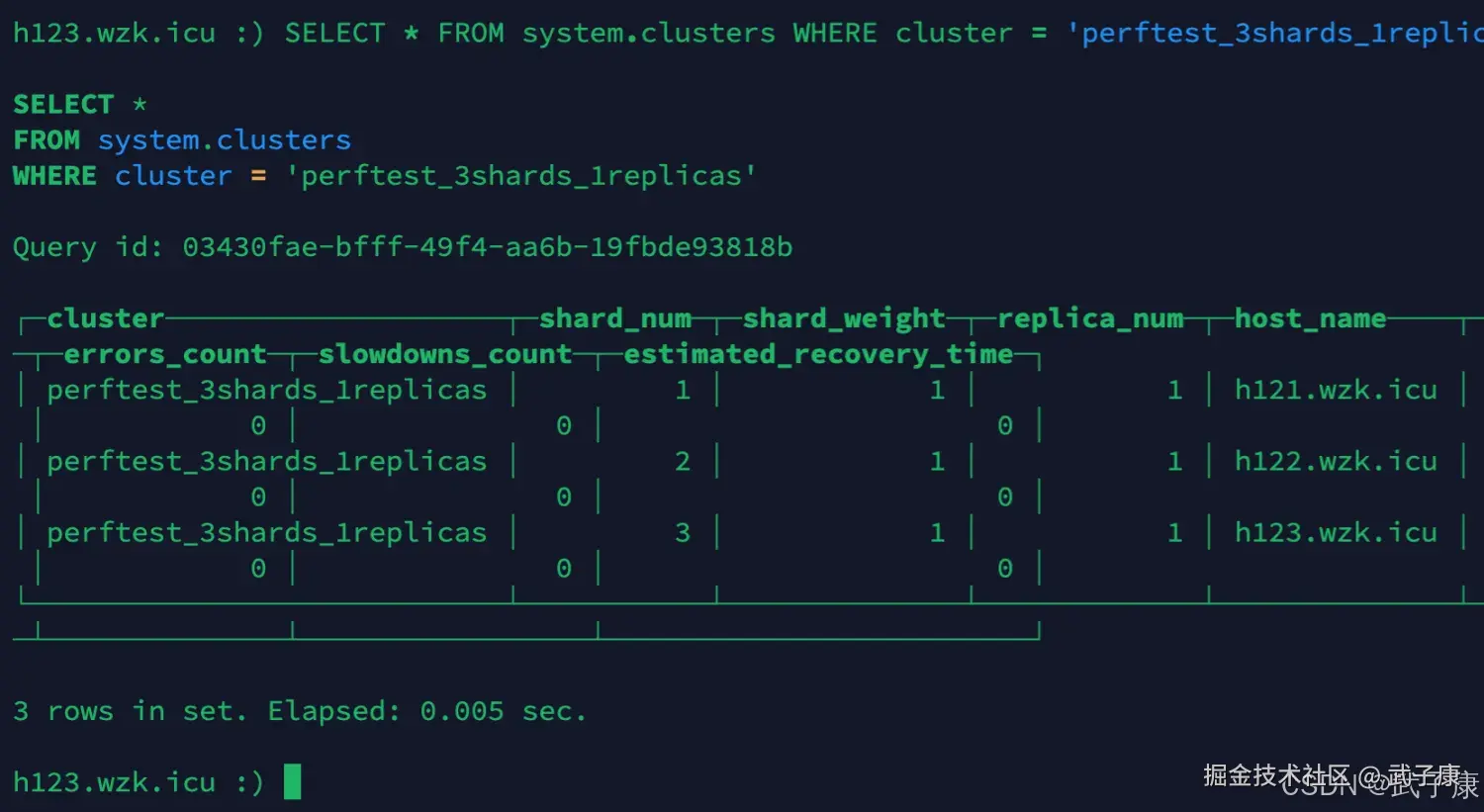
数据类型
简单介绍
ClickHouse作为一个面向OLAP场景的高性能列式数据库,在数据处理语言(DML)支持方面有其独特的设计。与传统的关系型数据库不同,ClickHouse通过以下特性来优化数据处理性能:
-
复合数据类型支持:
- 提供Array、Tuple、Nested等复合数据类型
- 支持Map、JSON等半结构化数据格式
- 例如:
Array(String)可以存储字符串数组,Tuple(Int32, String)可以存储不同类型的组合数据
-
数据修改操作的实现:
- Update和Delete操作是通过ALTER TABLE语句的变种实现的
- 例如:
ALTER TABLE table_name DELETE WHERE condition - 又如:
ALTER TABLE table_name UPDATE column=value WHERE condition - 这种设计避免了传统数据库的锁机制,提高了批量操作的效率
-
性能优化特点:
- 采用批量处理而非单行操作
- 适合大批量数据的分析场景
- 通过MergeTree引擎实现高效的数据修改
- 修改操作是异步执行的,会生成新的数据部分(part)而非原地修改
这种设计使ClickHouse在保持高性能的同时,也能支持必要的数据修改操作,特别适合数据仓库和分析型应用场景。
启动测试
我这里采用了 h121 机器的服务,当然如果你使用别的机器的服务也可以。
shell
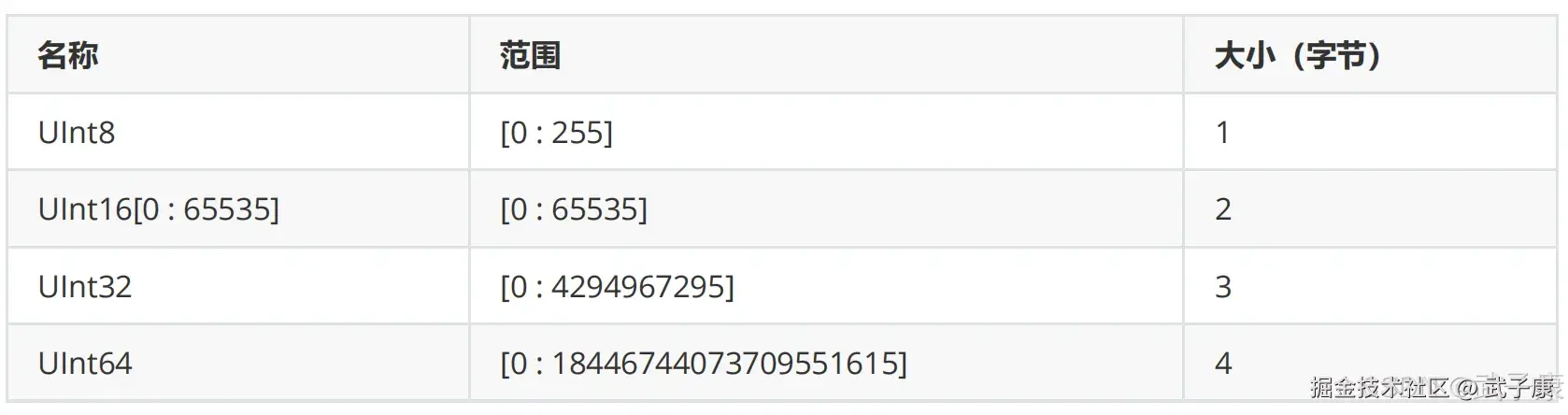
clickhouse-client -m --host h121.wzk.icu --port 9000 --user default --password clickhouse@wzk.icu整型
固定长度的整型,包括有符号整型,和无符号整型。 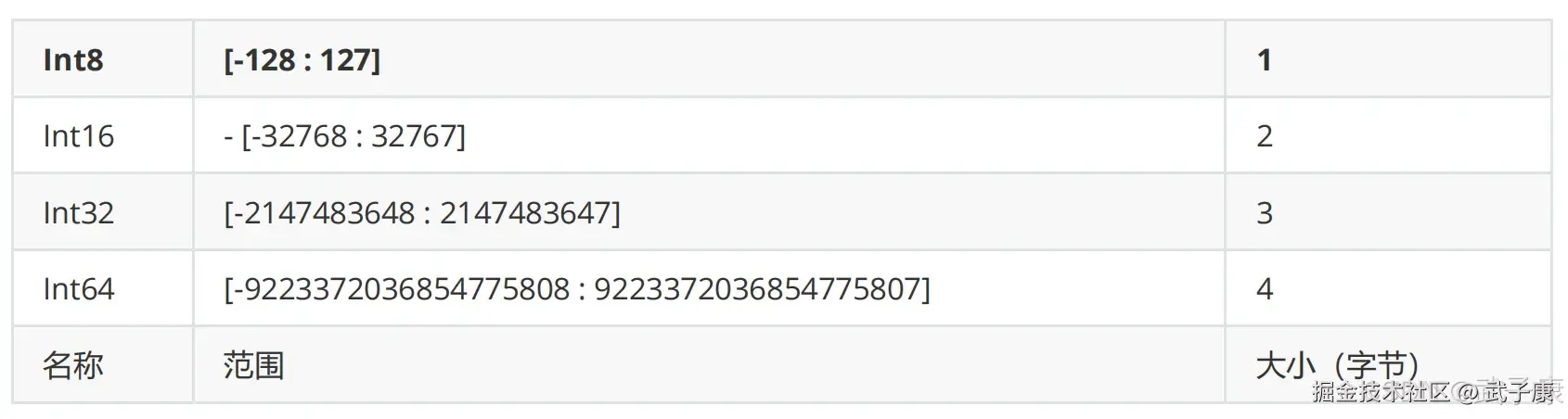
shell
SELECT 255;
SELECT -128;执行的结果截图如下图: 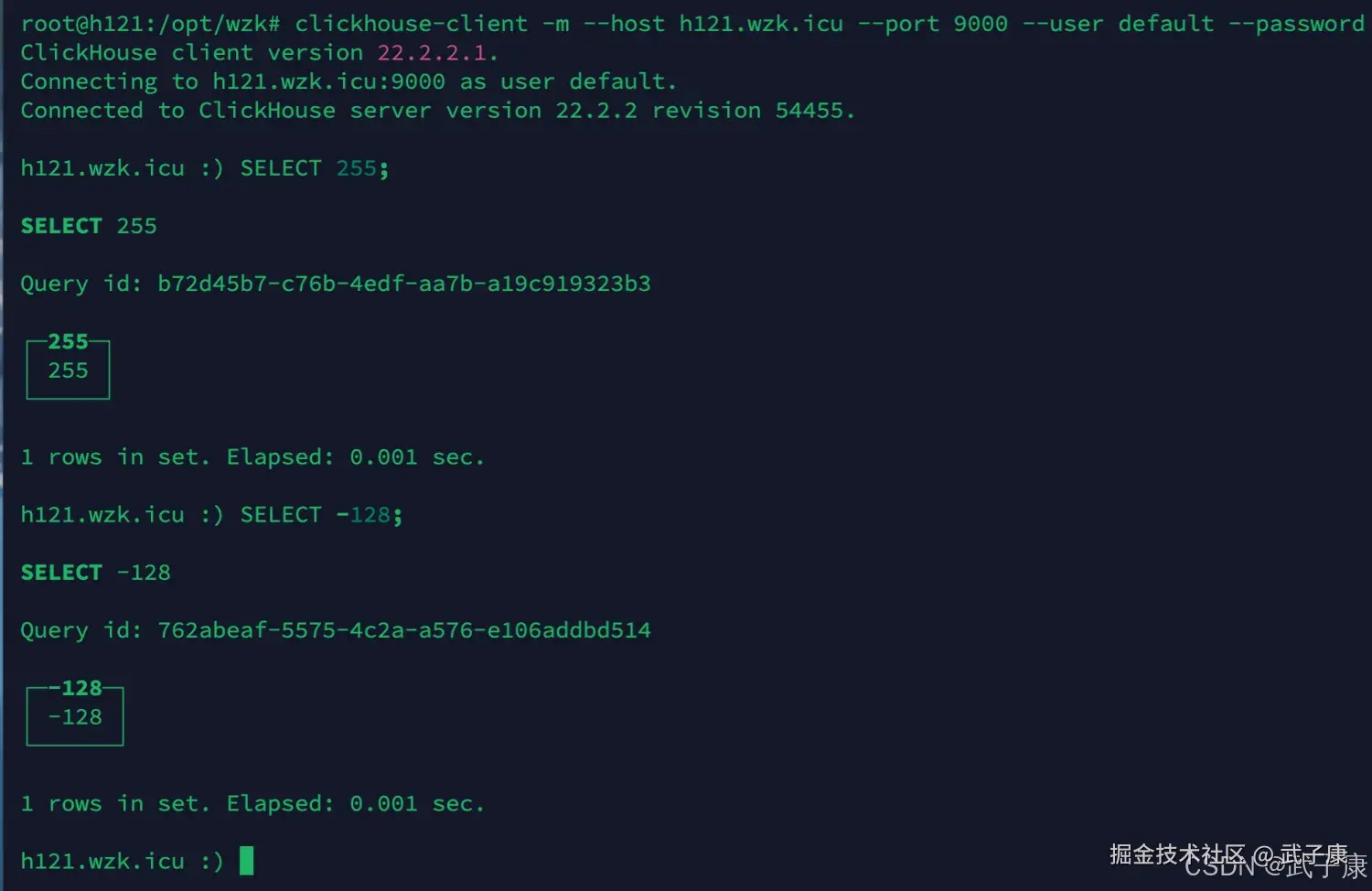
浮点型
 建议尽可能以整数形式存储数据,例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型计算行为可能引起四舍五入的误差。
建议尽可能以整数形式存储数据,例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型计算行为可能引起四舍五入的误差。
shell
SELECT 1-0.9;
SELECT 1/0;
SELECT 0/0;执行的结果如下图: 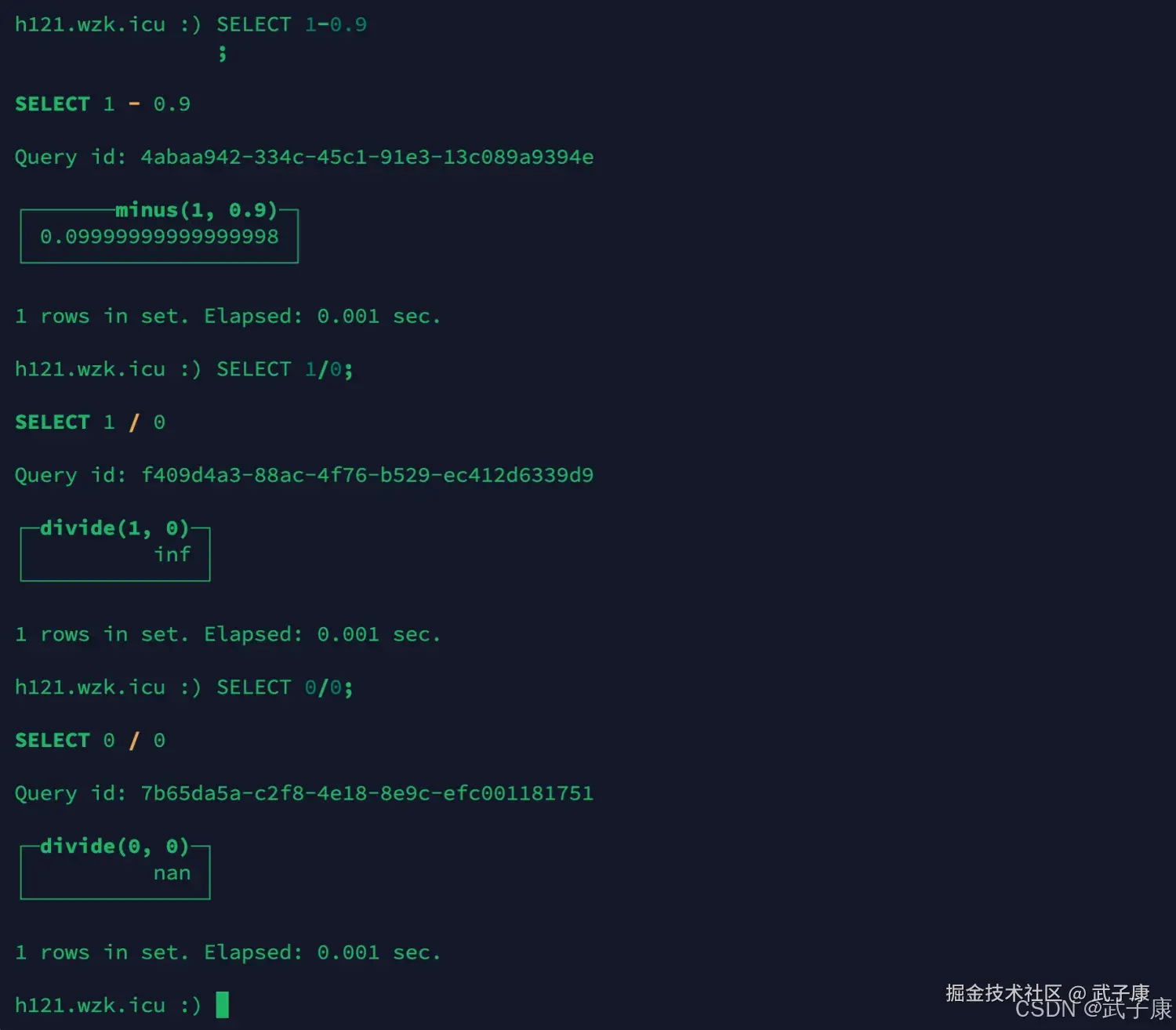
Decimal
如果要求更高精度,可以选择Decimal类型,格式:Decimal(P,S)
- P:代表精度,决定总位数(正数部分+小数部分),取值0-38
- S:代表规模,决定小数位数,取值范围是0-P
ClickHouse对Decimal提供三种简写:
- Decimal32
- Decimal64
- Decimal128
相加、减精度取大
shell
SELECT toDecimal32(2, 4) + toDecimal32(2, 2);
SELECT toDecimal32(4, 4) + toDecimal32(2, 2);运行结果的截图如下图所示: 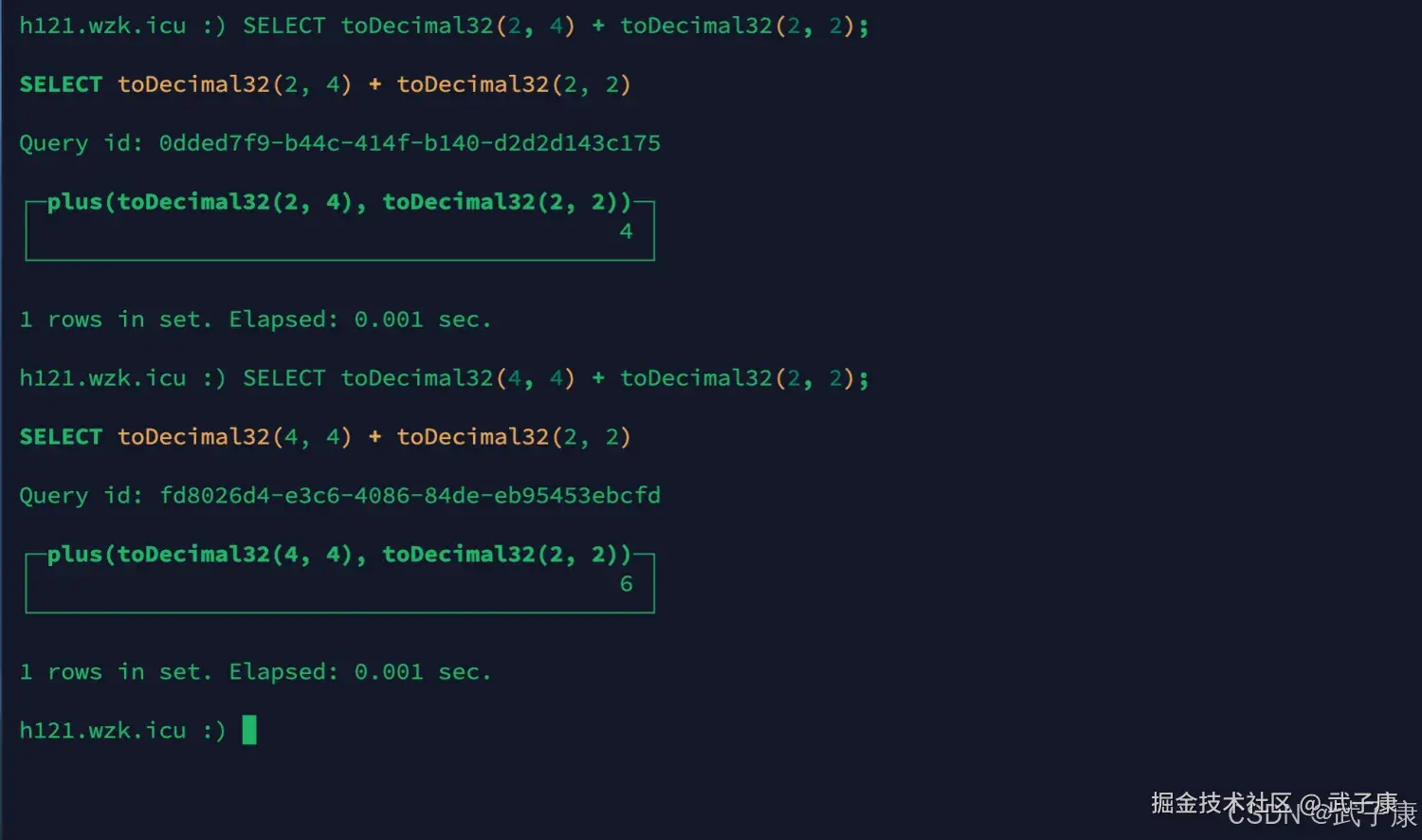
相乘精度取和
shell
SELECT toDecimal32(2, 2) * toDecimal32(4, 4)运行结果的截图如下图所示: 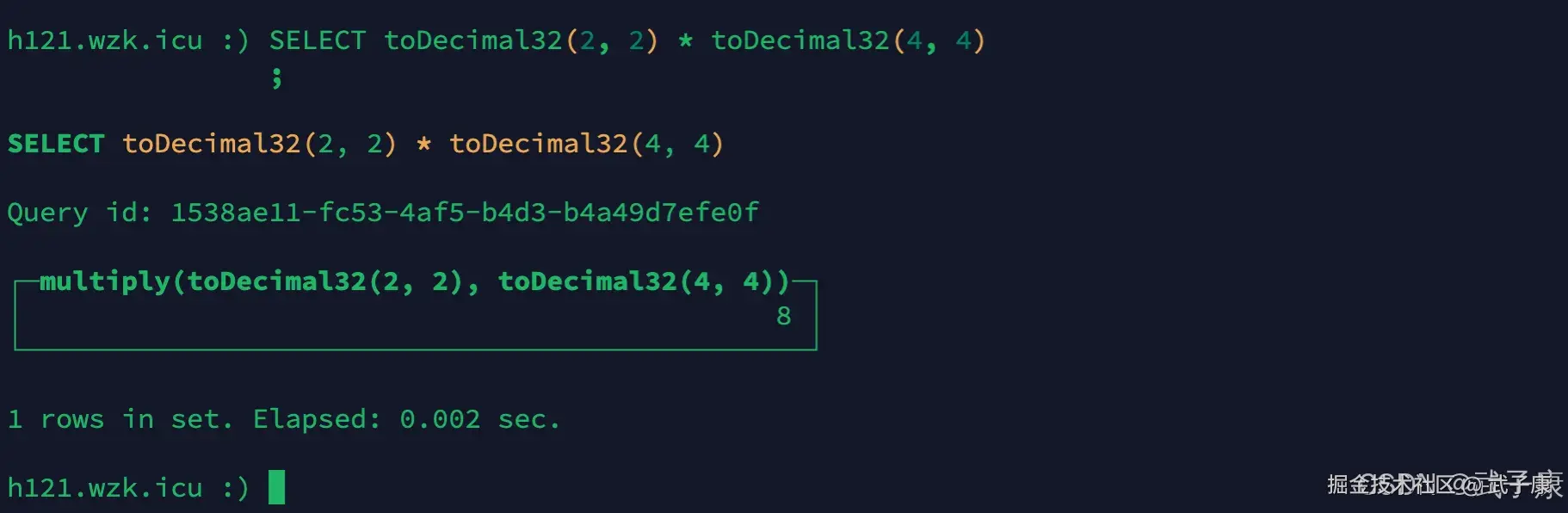
相除精度取被除数
shell
SELECT toDecimal32(4, 4) / toDecimal32(2, 2)运行结果的截图如下图所示: 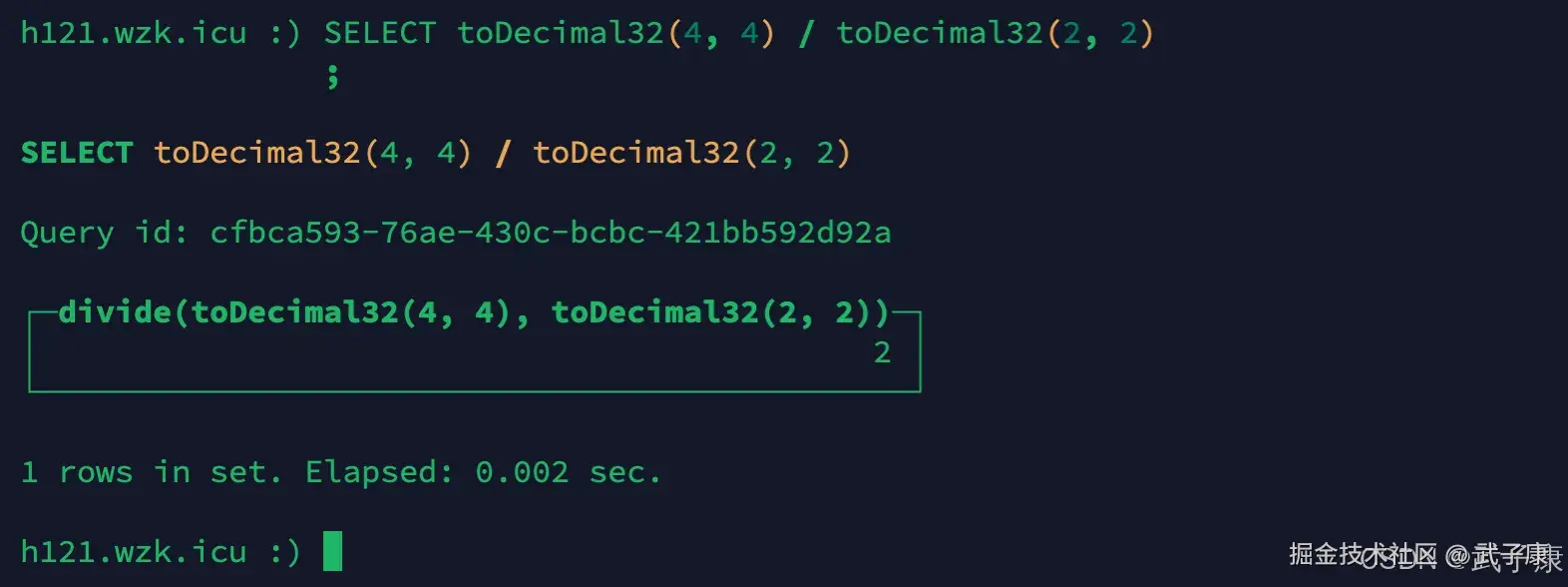
字符串
String
字符串可以任意长度,它可以包含任意的字符集,包含空字节。
FixedString(N)
固定长度为N的字符串,N必须是严格的正自然数。当服务端读取长度小于N的字符串时候,通过在字符串末尾添加空字节来达到N字节长度。当服务端读取长度小于N的字符串的时候,将返回错误。
shell
SELECT toFixedString('abc', 5), LENGTH(toFixedString('abc', 5)) AS LENGTH;执行结果如下图: 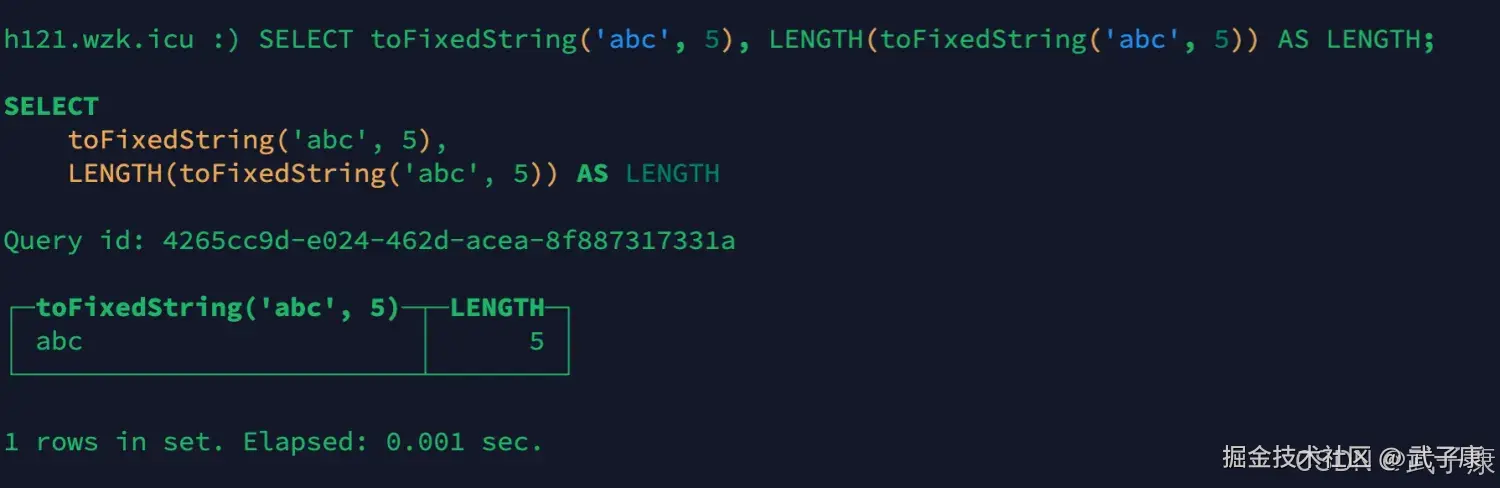
UUID
ClickHouse将UUID这种在传统数据库中充当主键的类型直接做成了数据类型
创建新表
shell
CREATE TABLE UUID_TEST(
`c1` UUID,
`c2` String
)ENGINE = memory;执行结果如下图: 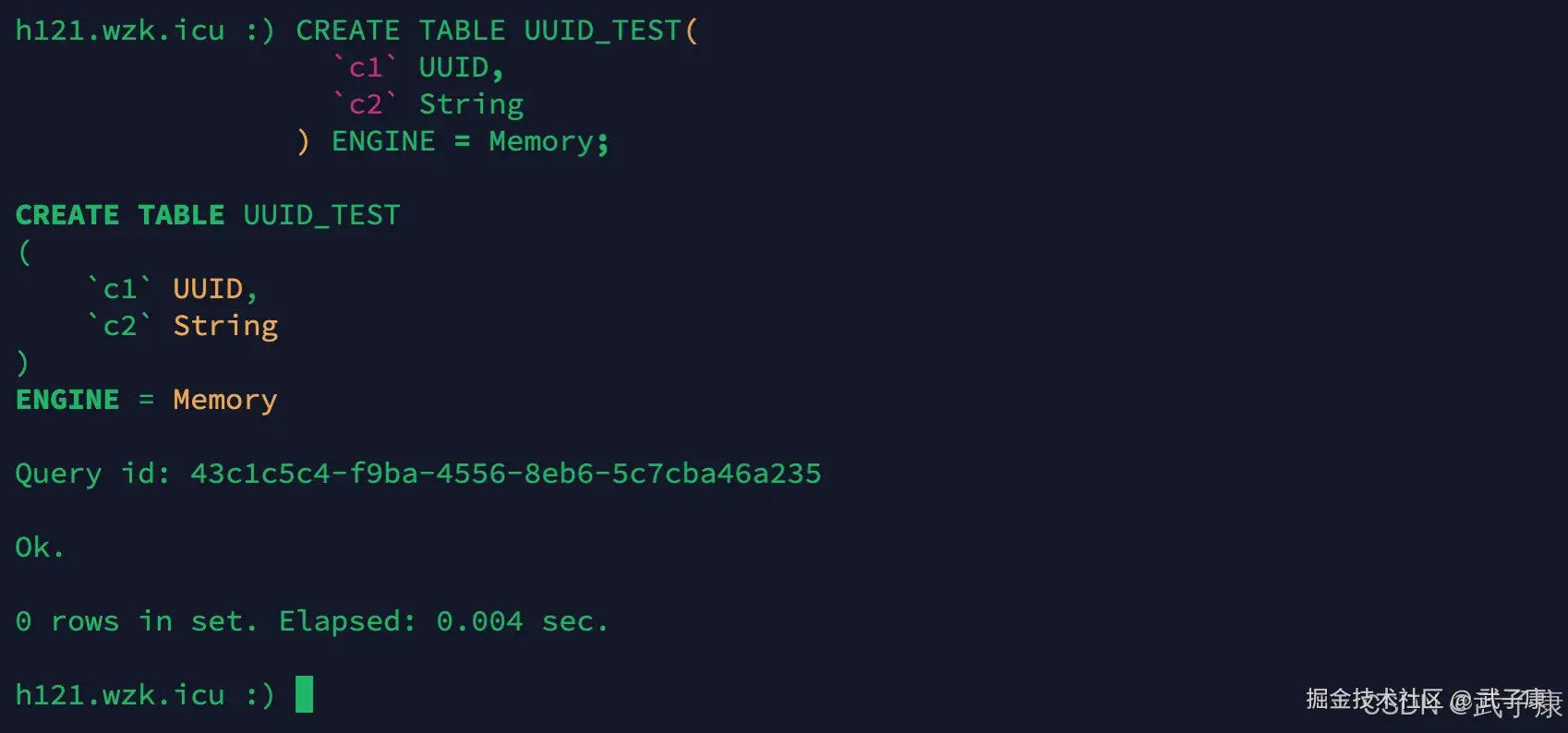
插入数据
shell
INSERT INTO UUID_TEST SELECT generateUUIDv4(), 't1';
INSERT INTO UUID_TEST(c2) VALUES('t2');执行结果如下图: 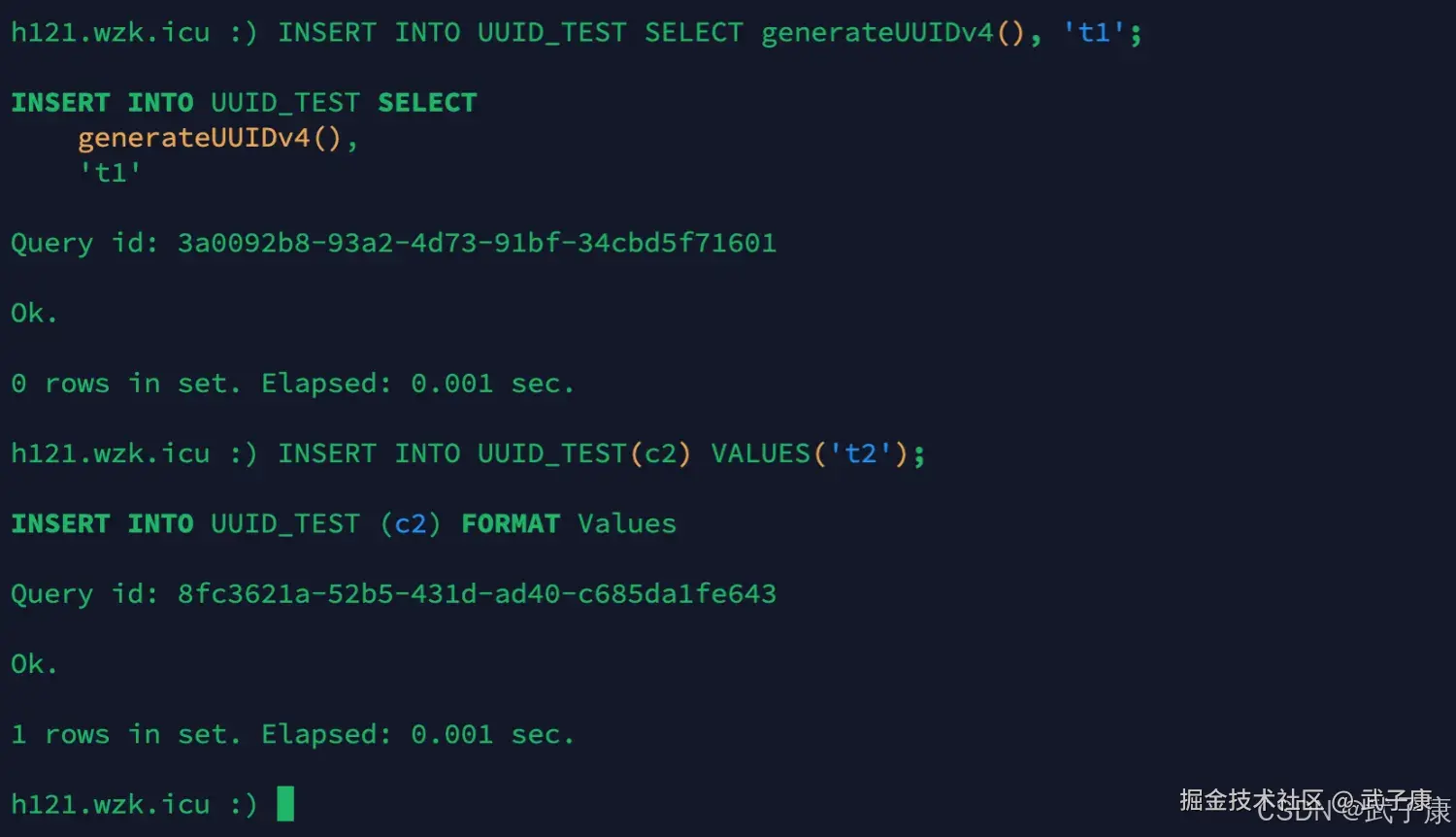
查询结果
shell
SELECT * FROM UUID_TEST;执行结果如下图: 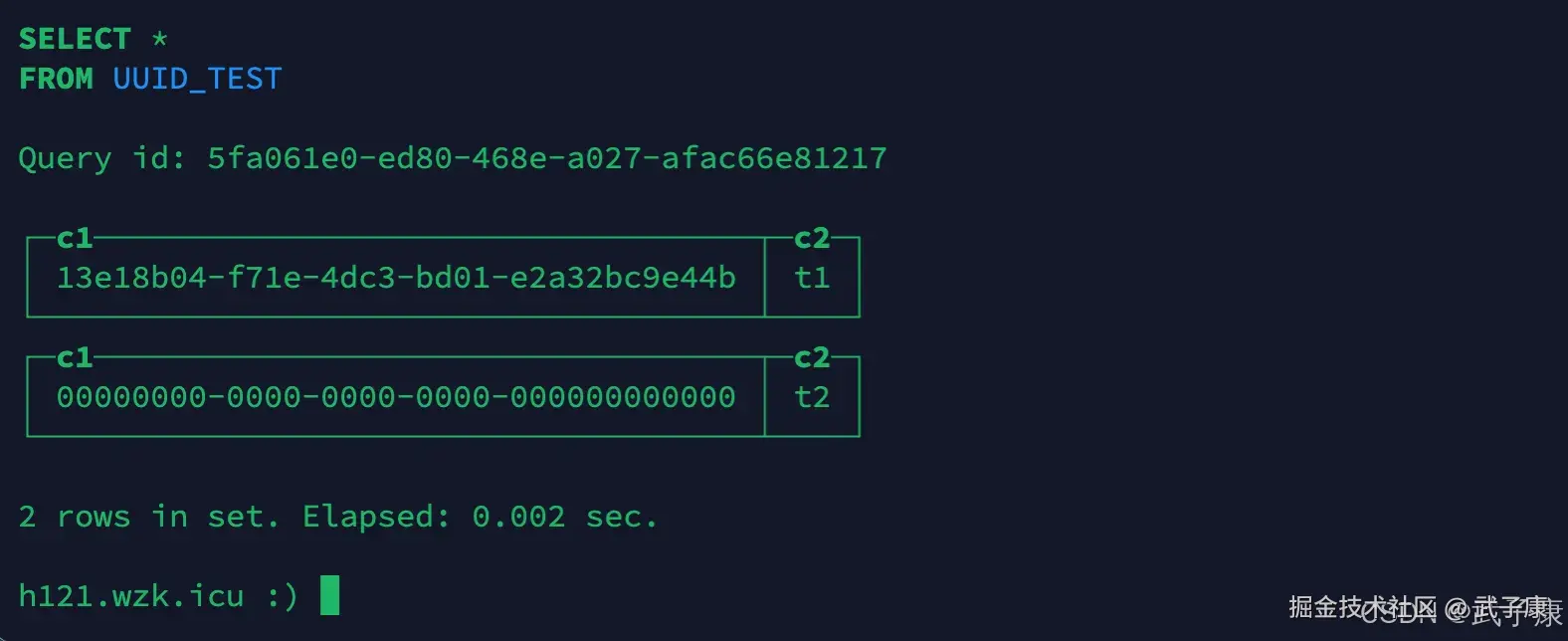
枚举类型
包括 Enum8 和 Enum16 类型,保存 string = integer 的对应关系。 Enum8 用 String = Int8 对描述 Enum16 用 String = Int16 对描述。
创建新表
shell
CREATE TABLE t_enum (
x Enum8('hello' = 1, 'word' = 2)
) ENGINE = TinyLog;执行结果如下所示: 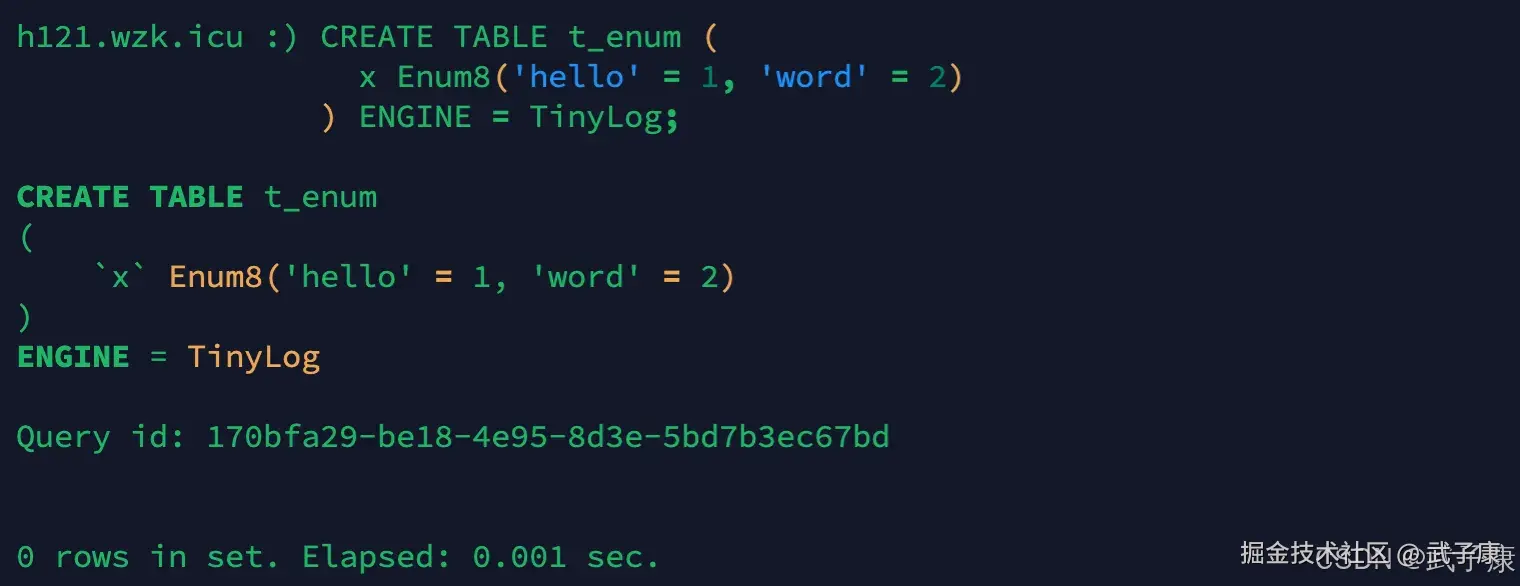 注意:这个列 x 只能存储定义列出的值,"Hello" 或者 "world",如果插入其他值则会报错。
注意:这个列 x 只能存储定义列出的值,"Hello" 或者 "world",如果插入其他值则会报错。
插入数据
shell
INSERT INTO t_enum VALUES ('hello'), ('word'), ('hello');执行结果如下图: 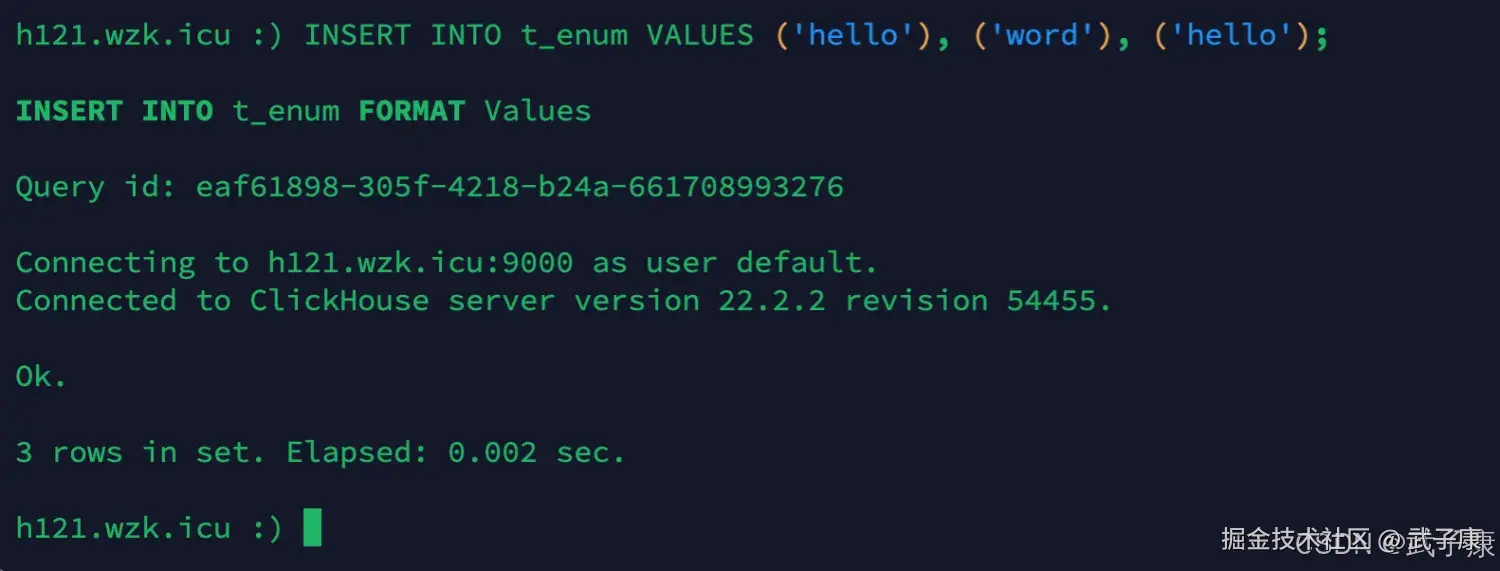
查询数据
shell
SELECT * FROM t_enum;如果需要看到对应行的数值,则必须将Enum转换为整数类型。
shell
SELECT CAST(x, 'Int8') FROM t_enum;执行结果如下图: 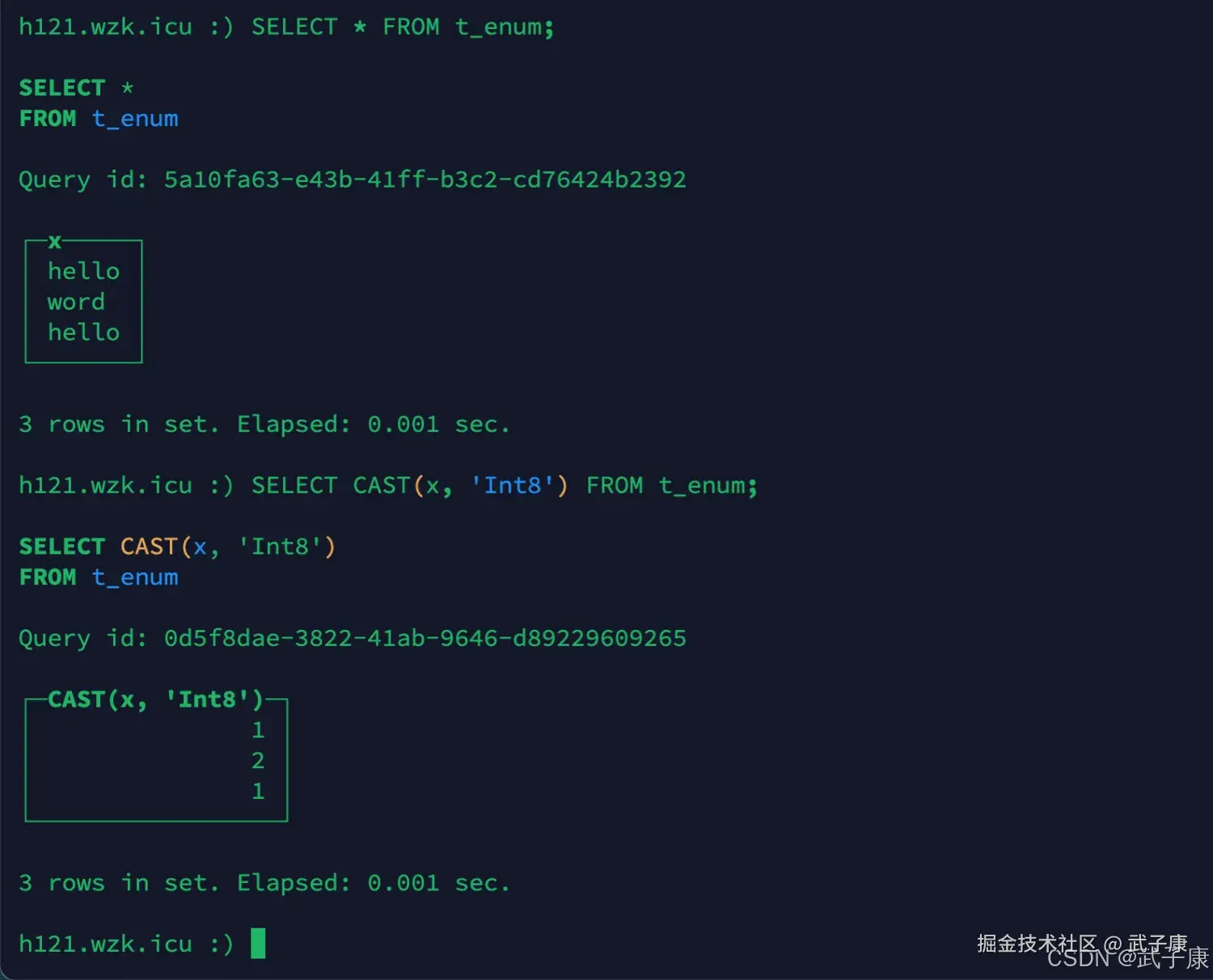
数组
Array(T):由 T 类型元素组成的数组。 T可以是任意类型,包含数组类型,但不推荐使用多维数组,ClickHouse对多维数组的支持有限。 例如,不能再MergeTree表中存储多维数组。
创建数组
shell
SELECT array(1, 2.0) AS x, toTypeName(x);
SELECT [1, 2] AS x, toTypeName(x);执行结果如下图: 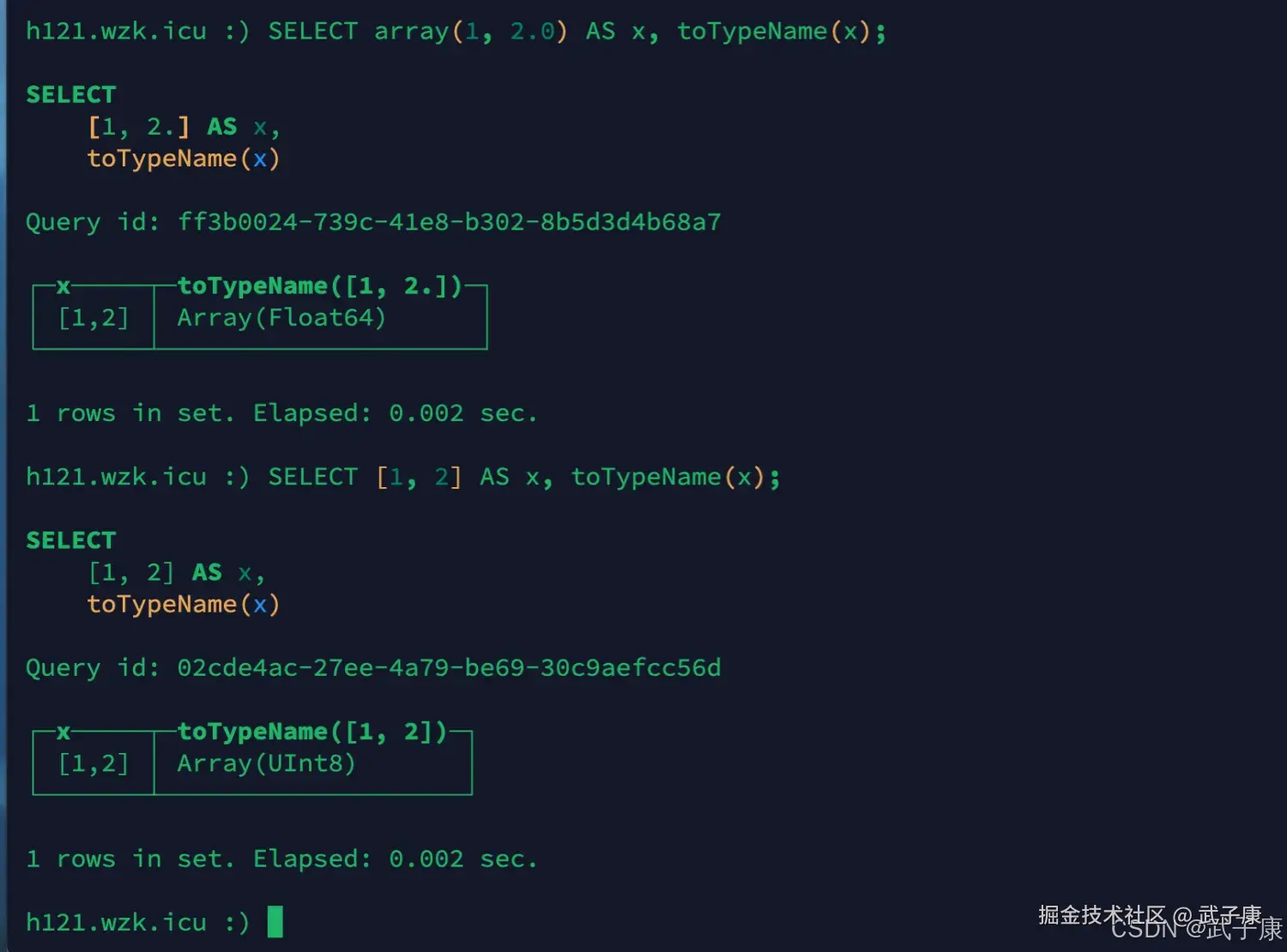 如果是声明字段的时候,则需要指明数据类型:
如果是声明字段的时候,则需要指明数据类型:
shell
CREATE TABLE Array_test (
`c1` Array(String)
) ENGINE = Memory;元组
Tuple(T1,T2):元组,每个元素都有单独的类型。 创建元组的示例:
shell
SELECT tuple(1, 'a') AS x, toTypeName(x);执行的结果如下图: 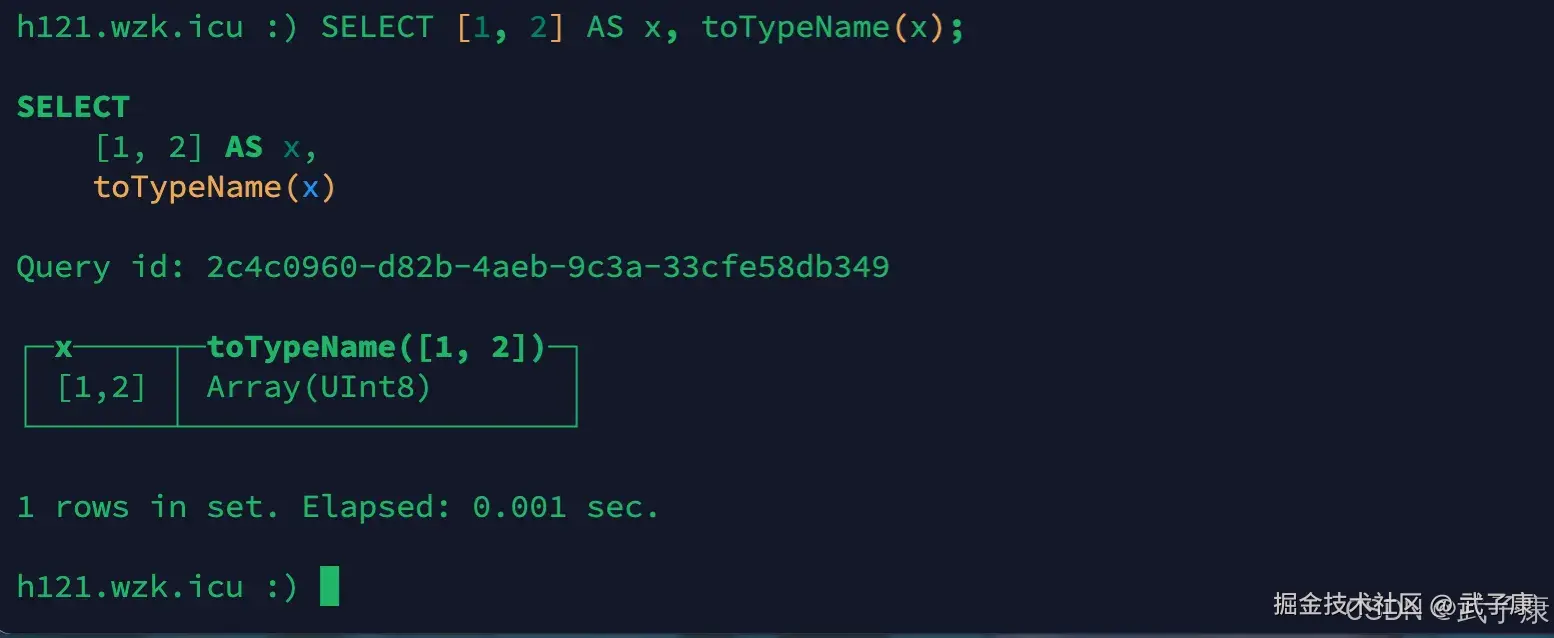 注意:在定义表字段的时候也需要指明数据类型。
注意:在定义表字段的时候也需要指明数据类型。
Date、DateTime
日期类型、用两个字节存储,表示 1970-01-01 (无符号)到当前的日期值。
布尔型
没有单独的类型来存储布尔值,可以使用 UInt8 类型,取值限制为 0 或 1。
错误速查
| 症状 | 可能根因 | 快速定位方法 | 处理建议 |
|---|---|---|---|
| is_readonly=1副本只读 | system.replicas | 检查磁盘/权限/配置 | 修正配置后重启 |
| 分布式表查不到数据 | 写到本地表 | 检查 FROM 表名统一写 events_all | 确保查询和写入表名一致 |
| lag 持续 > 0 | 复制积压 | 查看 system.mutations | 等待或扩容/限速写入 |
| 建表失败 | 宏/路径不一致 | 检查 {shard}/{replica} | 修正 config.xml 配置后重启服务 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解