摘要
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10713206
当前大多数研究主要侧重于使用大型模型来提高实验精度,却常常忽视了部署的挑战。在某些遥感设备上,对轻量级算法的需求日益增长。此外,遥感图像(RSIs)通常包含大量小而密集分布的目标,这给检测带来了巨大挑战。为了解决这些问题,我们对YOLOv8s网络进行了改进,开发了一种基于多尺度特征融合与上下文信息(MFFCI-YOLOv8)的轻量级遥感目标检测(RSOD)网络。该网络结合了多尺度特征融合和上下文信息,以准确检测RSIs中的目标。首先,我们引入了带有注意力机制的轻量级CSP瓶颈模块(LCA),该模块利用部分卷积计算和SimAM注意力机制,在减少参数数量和计算复杂度的同时,增强了特征提取能力。其次,我们设计了门控空间金字塔池化快速(GSPPF)模块,以增强模型对尺度和上下文信息的感知能力,从而改善小目标的检测效果。最后,我们采用了多尺度融合轻量级颈部(MFLNeck)模块,以实现更高效的多尺度特征融合,防止小目标信息的丢失。与YOLOv8s相比,我们的整体模型参数量减少了7.7%,计算量(FLOPs)减少了11.9%。我们在两个遥感数据集NWPU VHR-10和VisDrone上验证了MFFCI-YOLOv8的准确性。实验结果表明,与其它RSOD模型和其他YOLO模型相比,我们的模型在保持低计算成本的同时,具有更高的检测精度。
索引词---轻量级,目标检测,遥感图像(RSIs),YOLOv8s。
I. 引言
遥感技术已迅速发展,并被广泛应用于军事侦察、民用生活和自然灾害救援等多个领域。它为土地利用、城市规划和自然灾害监测等应用提供了至关重要的基础1-8。遥感目标检测(RSOD)的主要目标是利用计算机视觉算法对遥感图像(RSIs)中的目标进行分类和检测,以确定目标的精确位置并提取其特征信息。随着全球RSIs数量的大幅增加,对RSOD的需求也显著上升。因此,提高RSOD的性能以实现更精确的定位和分类是遥感领域的一个关键研究方向。
早期的方法,如人工检测,只能检测特定的单类目标,并且在某些场景下效果有限。当环境发生变化时,会导致识别效率低下。传统方法中复杂且多步骤的操作导致了检测速度慢和性能低下。深度学习正在快速发展,特别是卷积神经网络(CNNs)13-16的进步。新的方法和基础框架已被引入用于目标检测。许多研究人员已采用CNNs在自然图像中实现了优异的准确性和改进的检测效率。然而,RSIs具有高度异质性的复杂背景、目标尺度差异显著以及易受恶劣天气和季节变化影响等特点,这进一步增加了检测的难度。因此,在RSOD中实现更高的检测精度仍然是一个挑战。
目前有两种类型的目标检测方法:两阶段和单阶段。两阶段目标检测模型,包括Fast R-CNN17、Faster R-CNN18和Cascade R-CNN19,使用区域建议网络(RPN)生成候选区域,并将其分类为背景或目标区域。然后,RPN的输出被映射到特征图上的相应位置,并送入检测头进行最终的分类和回归。虽然两阶段模型在检测精度方面表现出色,但其模型参数和推理时间是其缺点。为了促进目标检测算法的更广泛应用,对单阶段模型的研究也在进行中。最具影响力的单阶段模型是SSD20和YOLO系列。与R-CNN系列算法不同,这些方法直接在特征图上回归目标的位置,将定位问题转化为回归问题。这种方法可以在一定程度上提高检测速度,但也可能导致精度下降。
YOLO系列已被研究人员不断更新和改进,以解决前代版本中的问题。每一代都成为了其各自时代的经典算法。YOLOv121是一项开创性的工作,通过直接回归位置,显著降低了计算复杂度并提高了运行速度。YOLOv222引入了批归一化和锚框以提高精度。YOLOv323通过采用特征金字塔网络(FPN)24结构实现多尺度融合,进一步改进了小目标检测。此外,YOLOv3还结合了空间金字塔池化(SPP)25以提升性能。YOLOv426通过结合跨阶段局部网络(CSP)27和基于PANet28的多通道特征融合等技术,进一步提高了检测精度和速度。在YOLOv4的基础上,YOLOv5优化了训练速度,并将CSP模块应用于颈部结构,用空间金字塔池化快速(SPPF)模块替换了SPP。YOLOv629侧重于硬件适配,将RepVGG30结构引入YOLO,并用EfficientRep替换了骨干网络。其检测头受YOLOX31启发,进行了轻微优化的解耦操作。YOLOv732提出了一种利用E-ELAN计算块无限堆叠的模型,并增加了一种辅助头训练方法。YOLOv8相比之前的版本实现了更高的精度和更快的检测速度,这将在第二节中描述。
许多研究人员已将YOLO系列用于RSOD任务。Wan等人33提出YOLO-HR网络,通过集成多层FPN和混合注意力模块来提高RSOD的准确性。Tang等人34引入了一个卷积模块来增强通道信息,并增加了一个新的检测头,从而形成了HIC-YOLOv5算法。在轻量级RSOD算法LAI-YOLOv5s35中,提出了一种新的特征融合方法来丰富语义特征,并借鉴ShuffleNetV236使网络更加高效。YOLO-W37采用切片辅助超推理技术来提高数据质量,并引入了一个超轻量级子空间注意力模块来增强目标特征并减少干扰。随着YOLOv8的发布,Li等人38通过结合双通道特征融合和BiFPN39的概念来增强YOLOv8网络,以改进小目标检测。他们还用GhostblockV240结构替换了部分CSP_bottleneck with two convolutions_(C2f)模块,以最小化网络传输过程中的特征损失。Wang等人41为无人机(UAV)场景专门引入了UAV-YOLOv8网络。他们利用BiFormer42模块优化网络,将回归损失函数替换为WIoU43,并通过设计专用卷积模块来提高网络检测速度。Guo等人44引入了密集连接机制,并开发了一种名为C3D的新网络结构模块来替换YOLOv8中的C2f模块,以更全面地保留信息。LAR-YOLOv845算法设计了一种带有注意力机制的双分支架构和一个由注意力引导的双向FPN,有效增强了检测能力。
为了满足部署要求并提高小目标检测能力,我们对YOLOv8s网络进行了增强,开发了一种基于多尺度特征融合与上下文信息的轻量级RSOD网络(MFFCI-YOLOv8)。为了展示我们模型优越的检测和泛化能力,我们在NWPU VHR-1046和VisDrone47数据集上进行了广泛的实验,取得了令人印象深刻的结果。
本文的主要贡献总结如下:
- 我们提出了带有注意力机制的轻量级CSP瓶颈(LCA)模块,这是一种资源高效的特征提取网络。该模块利用通道冗余进行部分通道卷积特征提取,并结合了无参数的SimAM注意力机制48来增强每个神经元的独特性。LCA模块专为满足RSOD硬件平台约束而设计。
- 我们提出了门控空间金字塔池化快速(GSPPF)模块以增强小目标检测。该模块利用逐渐增大的卷积核尺寸来捕获更广泛的跨尺度上下文信息。一个门控机制有选择地整合不同层次的上下文信息,以改善尺度感知和上下文感知能力。
- 我们提出了多尺度融合轻量级颈部(MFLNeck)模块,旨在有效融合高层和低层特征信息。这种交互通过跨尺度整合特征信息来增强对小目标的提取能力。此外,该模块采用轻量级特征融合技术来提高效率并降低计算负载。
本文其余部分组织如下:第二节介绍了YOLOv8s算法、SPPF的当前研究进展以及SimAM模块的介绍。第三节阐述了所提出的MFFCI-YOLOv8模型。第四节提供了实验细节和结果。第五节讨论了MFFCI-YOLOv8。最后,第六节对本文进行了总结。
II. 相关工作
A. YOLOv8s
YOLOv8通过引入新模块和优化前代版本的缺点来提升其性能和通用性,从而扩展了其在各种场景中的适用性。为了便于硬件部署,本文选择参数较少的小版本作为基线。如图1所示,骨干网络是核心,包含了C2f和SPPF模块。C2f模块结合了YOLOv5的CSP结构和YOLOv7的ELAN结构,以增强特征表示并改善梯度流信息,最终提高精度。SPPF模块在骨干网络的末端仍然至关重要。
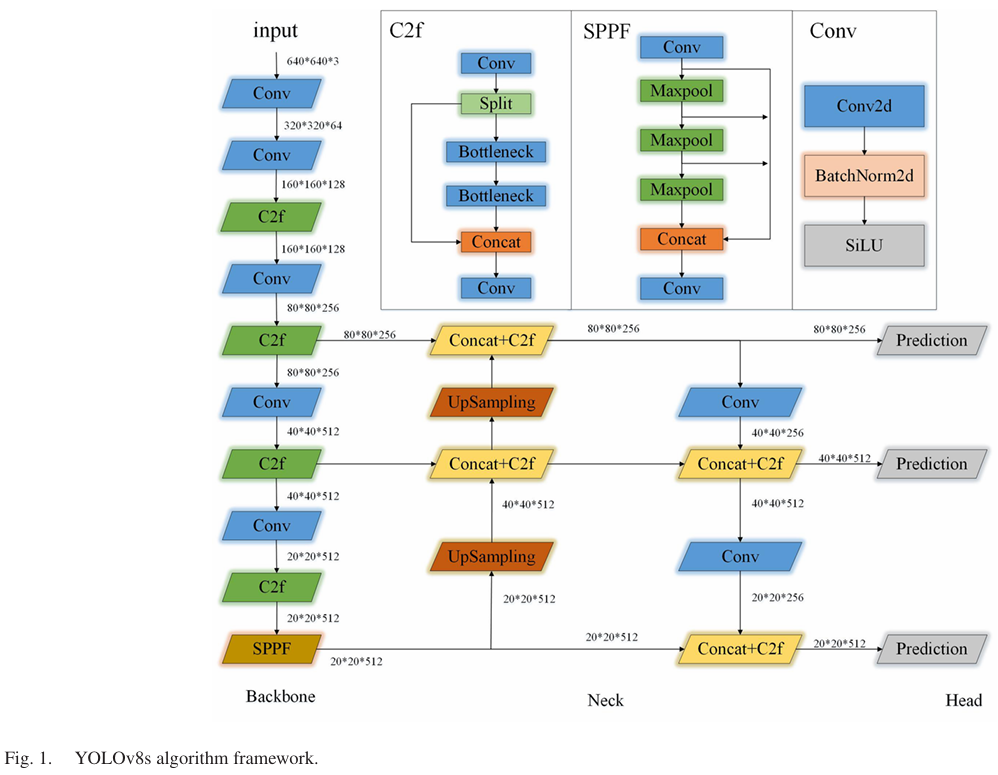
在颈部架构中,YOLOv8s使用FPN--PAN结构进行特征融合,有效地整合了多尺度信息。它选择了无锚框结构,而不是传统的锚框。损失函数由两部分组成:用于分类的二元交叉熵损失,以及用于回归的完整交并比(Complete-IOU)49和分布焦点损失(Distribution Focal Loss)50的组合。
B. SPPF模块
YOLOv8s中的SPPF层结构如图1所示。为了修改通道维度,首先应用一个1×11\times11×1卷积。然后,它依次通过三个大小为5×55\times55×5的最大池化层。随后,每个层在保留特征信息的同时进行拼接,并通过添加残差连接来防止特征丢失。在此阶段,通道数增加四倍,然后通过卷积恢复到原始通道数。YOLOv8s中的SPPF层具有聚合多尺度特征的优势,同时使用的资源更少。与原始的SPPNet不同,它不生成固定长度的输出向量。相反,它在保留空间维度的同时连接来自不同最大池化层的特征。这种方法使用更少的资源有效地结合了多尺度特征。
SPPF层旨在生成输入特征图的多尺度表示。通过在多个尺度上执行池化操作,SPPF使模型能够捕获不同抽象层次的特征。这种能力在需要识别不同尺寸目标的目标检测中尤其有价值。随着时间的推移,研究人员以不同的方式增强了SPPF层。Chen等人51引入了ASPP模块,该模块结合了多个具有不同采样率的并行空洞卷积层。每个采样特征在单独的分支中进行处理,然后融合以产生最终输出,从而增强了跨尺度的特征提取。SPPFS52利用顺序池化策略,对不同尺寸的特征图进行池化。连接这些顺序获得的特征图有助于实现有效的特征表示。为了限制细粒度特征信息的丢失,Zeng等人53为YOLOv7-UAV开发了DpSPPF模块。该模块用相互连接的较小深度可分离卷积层替换了最大池化层,旨在保留详细的特征信息,同时仍然受益于多尺度池化。这些对SPPF模块的增强和适应旨在提高其捕获准确目标检测所必需的多样化和详细特征的能力。
C. SimAM模块
SimAM注意力机制基于既定的神经科学理论,涉及优化一个能量函数来评估每个神经元的重要性。该方法为每层特征图计算三维(3-D)注意力权重,而不引入额外的参数。在图像处理过程中,优先考虑表现出强空间抑制功能的神经元。该方法的一个关键方面是评估目标神经元与其他神经元之间的线性可分性,这由以下能量函数关键定义:
eβ=(−1−β^)2+1N−1∑i=1N−1(−1−x^i)2.e_{\beta}=\left(-1-\hat{\beta}\right)^{2}+\frac{1}{N-1}\sum_{i=1}^{N-1}{\left(-1-\hat{x}_{i}\right)^{2}}.eβ=(−1−β^)2+N−11i=1∑N−1(−1−x^i)2.
在公式中,β^=kββ+bβ\hat{\beta}=k_{\beta}\beta+b_{\beta}β^=kββ+bβ 和 x^i=kβxi+bβ\hat{x}{i}=k{\beta}x_{i}+b_{\beta}x^i=kβxi+bβ,其中 β\betaβ 和 xix_{i}xi 分别代表输入特征 RC∗H∗WR^{C*H*W}RC∗H∗W 中单个通道内的目标神经元和其他神经元。这里,iii 是空间索引,N=H×WN=H\times WN=H×W 表示该通道中神经元的数量。kβk_{\beta}kβ 和 bβb_{\beta}bβ 是线性变换的权重和偏置。最小化此方程可以增强目标神经元 β\betaβ 与同一通道内其他神经元之间的线性可分性。改进后的能量函数为:
eβ=1N−1∑i=1N−1(−1−β^)2+(1−x^i)2+λkβ2.e_{\beta}=\frac{1}{N-1}\sum_{i=1}^{N-1}\left(-1-\hat{\beta}\right)^{2}+(1-\hat{x}{i})^{2}+\lambda{k{\beta}}^{2}.eβ=N−11i=1∑N−1(−1−β^)2+(1−x^i)2+λkβ2.
方程(2)有一个快速的闭式解,由下式给出:
kβ= −2(β−φβ)(β−φβ)2+2ηβ2+2λbβ= −12(β+φβ)kβ\begin{aligned}k_{\beta}&=\;-\frac{2\left(\beta-\varphi_{\beta}\right)}{\left(\beta-\varphi_{\beta}\right)^{2}+2\eta_{\beta}^{2}+2\lambda}\\b_{\beta}&=\;-\frac{1}{2}\left(\beta+\varphi_{\beta}\right)k_{\beta}\end{aligned}kβbβ=−(β−φβ)2+2ηβ2+2λ2(β−φβ)=−21(β+φβ)kβ
其中 φβ\varphi_{\beta}φβ 和 ηβ2\eta_{\beta}^{2}ηβ2 分别表示除 β\betaβ 外该通道中所有神经元的均值和方差。如果单个通道中的所有像素具有相等的分布,则可以计算每个神经元的均值和方差。因此,我们可以推导出最小化能量的公式:
eβ∗=4(η^2+λ)(β−φ^)2+2η^2+2λe_{\beta}^{*}=\frac{4\left(\hat{\eta}^{2}+\lambda\right)}{\left(\beta-\hat{\varphi}\right)^{2}+2\hat{\eta}^{2}+2\lambda}eβ∗=(β−φ^)2+2η^2+2λ4(η^2+λ)
其中 λ\lambdaλ 是正则化系数。方程(5)表明,较低的能量 eβ∗e_{\beta}^{*}eβ∗ 值意味着神经元 β\betaβ 与周围神经元的差异性更大,表明其重要性更高。
III. 所提出的方法
A. 概述
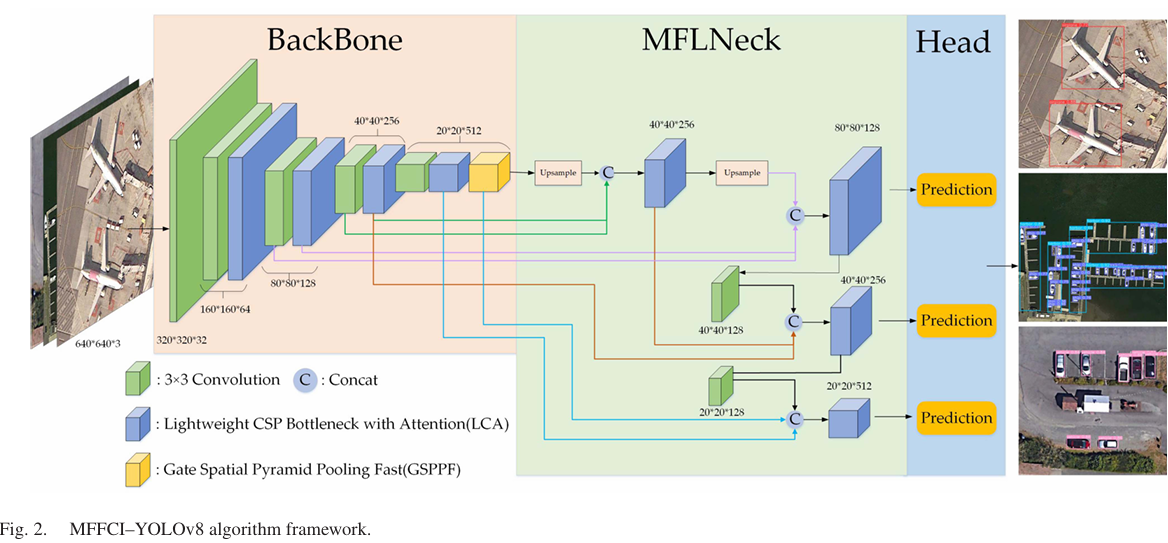
本文对YOLOv8s进行了改进和优化,引入了一种更好的网络框架MFFCI-YOLOv8,用于图2所示的RSOD。首先,输入图像在骨干网络中进行特征提取。在这方面,我们提出了更轻、更快的LCA模块,以减少通道冗余,从而减少参数和计算复杂度。此外,为了提高特征提取能力,引入了无参数的SimAM注意力方法。随后,我们引入了GSPPF模块,以改善尺度感知和上下文感知能力,从而增强整体特征表示。MFLNeck模块能够实现更有效的多尺度特征融合,并辅以融合LCA模块,旨在准确检测更小的目标。最后,在检测头模块中执行目标检测,完成RSOD过程。
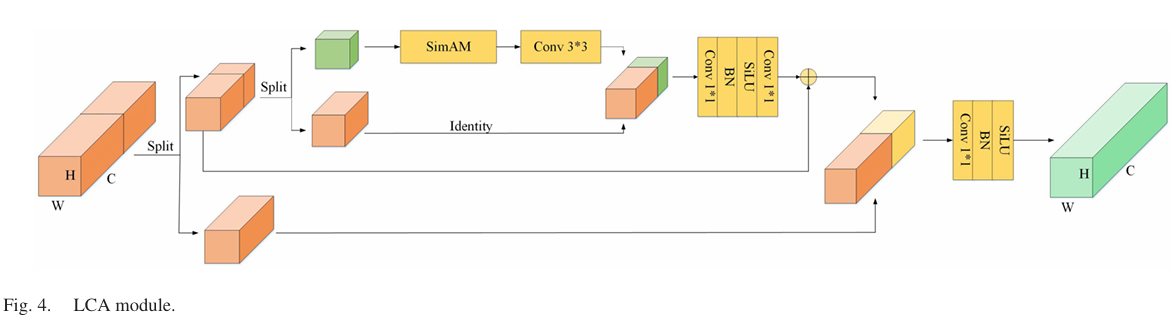
B. 带有注意力机制的轻量级CSP瓶颈(LCA)模块
在CNN中,每个通道代表不同的特征信息。图3显示了从RSI卷积计算中得出的部分通道图像。这些图像在通道间表现出显著的相似性,几乎每个通道都能辨别出飞机的特征。由于网络通常随着通道数量的增加而经历更高的计算复杂度,这一观察强调了特征丰富的CNN架构所伴随的计算需求。

受54的启发,我们认识到减少通道数量可以有效降低计算复杂度。因此,我们设计了一个更轻、更快、更高效的LCA模块,如图4所示。首先,我们输入一个具有特定通道数的特征图 RC×H×WR^{C\times H\times W}RC×H×W。在初始特征提取后,我们将通道数减半,从而有效减少了通道数量。然后,我们选择剩余通道的一个子集 ∂(∂<1/2)\partial(\partial<1/2)∂(∂<1/2) 作为代表进行计算。剩余的通道被进一步划分为 C/2×∂C/2\times\partialC/2×∂ 和 C/2(1−∂)C/2(1-\partial)C/2(1−∂),并应用 k×kk\times kk×k 卷积来提取空间特征。其余通道被直接映射并保持不变。在此卷积操作中,我们只考虑乘法运算,FLOPs可以使用以下公式估算,其中参数数量根据 ∂\partial∂ 的值显著减少:
FLOPs=(C/2×∂)2×k2×H×W.\mathrm{FLOPs}=(C/2{\times}\partial)^{2}{\times}k^{2}\times H{\times}W.FLOPs=(C/2×∂)2×k2×H×W.
在降低计算复杂度的同时,仍然存在特征提取不完整的担忧。为了解决这个问题,我们引入了无参数的SimAM模块,该模块以轻量级的方式增强了特征提取能力。SimAM模块为特征图中的每个神经元分配注意力显著性,以确定其重要性,而无需添加参数。这种方法在层的特征图上推断出3-D注意力权重,有效地提升了特征提取能力。在注意力加权特征映射之后,应用卷积以更高效地提取特征。逐点卷积在拼接阶段后促进通道间信息交互。此外,我们将每一层的特征进行拼接,以丰富特征图中的梯度信息,从而增强数据表示和深度。
C. 门控空间金字塔池化快速(GSPPF)模块
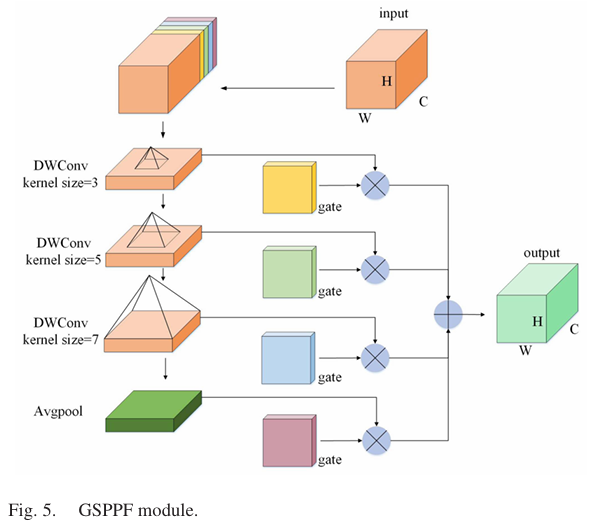
SPPF结构被集成到YOLOv8s框架中,通过提供上下文信息和增加鲁棒性来提高目标识别精度。然而,多次池化操作可能会无意中导致尺度信息丢失,这会影响小目标的表示并对大目标的数据进行压缩。我们提出了GSPPF模块作为解决方案,如图5所示。该模块有效地增强了小目标识别,并比传统的SPPF方法更高效地保留了上下文信息。首先,我们使用逐点卷积来转换输入特征 R^C×H×W\hat{R}^{C\times H\times W}R^C×H×W,将其扩展到四个门控通道,从而实现通道间交互,得到 R(C+4)×H×WR^{(C+4)\times H\times W}R(C+4)×H×W。接下来,我们用三个深度可分离卷积(DWConv)替换了传统的最大池化操作。与最大池化不同,深度可分离卷积是可训练的并表现出结构感知能力。这种选择通过摒弃传统卷积来保持模型的轻量级,同时仍然提供类似于传统卷积的通道特性,但计算开销更低。尽管深度可分离卷积在捕获长距离依赖关系方面存在局限性,这可能会影响RSIs中的小目标检测,但我们使用卷积核大小为 3×33{\times}33×3、5×55{\times}55×5 和 7×77\times77×7 的卷积来在更粗的层次上增强全局上下文感知。这些卷积旨在扩大感受野,从而提高模型捕获更广泛空间依赖关系的能力。为了有效地整合不同层次的上下文,我们采用了一种门控机制,通过加权融合来聚合上下文信息。在聚合过程中,每个层次的上下文都乘以其对应的门控信号。这种方法允许较大的门控信号值放大相关上下文层次的影响,而较小的值则减弱其影响。这种自适应调整使模型能够有选择地结合信息丰富的上下文层次,以增强特征表示。为了捕获空间信息,我们在空间维度上执行平均池化,然后将所有特征相加。这个聚合步骤确保将空间细节全面地整合到最终的特征表示中。
Zlth={DWConv(R),l=1DWConv(Z(l−1)th),l=2,3Avgpool(Z3th),l=4\begin{aligned}Z^{l\mathrm{th}}&=\begin{cases}\mathrm{DWConv}(R),l=1\\\mathrm{DWConv}(Z^{(l-1)\mathrm{th}}),l=2,3\end{cases}\\\mathrm{Avgpool}(Z^{3\mathrm{th}}),l=4\end{aligned}ZlthAvgpool(Z3th),l=4={DWConv(R),l=1DWConv(Z(l−1)th),l=2,3
GSPPF模块显著增强了MFFCI-YOLOv8在不同尺度和上下文数据上提取全面特征表示的能力。它促进了有效的多尺度特征融合,从而整体上增强了模型的检测能力。
D. 多尺度融合轻量级颈部(MFLNeck)模块
FPN旨在使用自上而下的方法整合不同分辨率的特征,以结合多尺度特性。PAN通过增加一个自下而上的路径进行特征聚合,解决了单向信息流的限制。然而,这种增强带来了更高的计算成本。在我们的方法中,我们采用了一种新的跨尺度融合,同时考虑了同层和相邻层的特征。这使得高层信息能够传递到低层特征,从而增强了整体特征表示。其结构如图6所示。
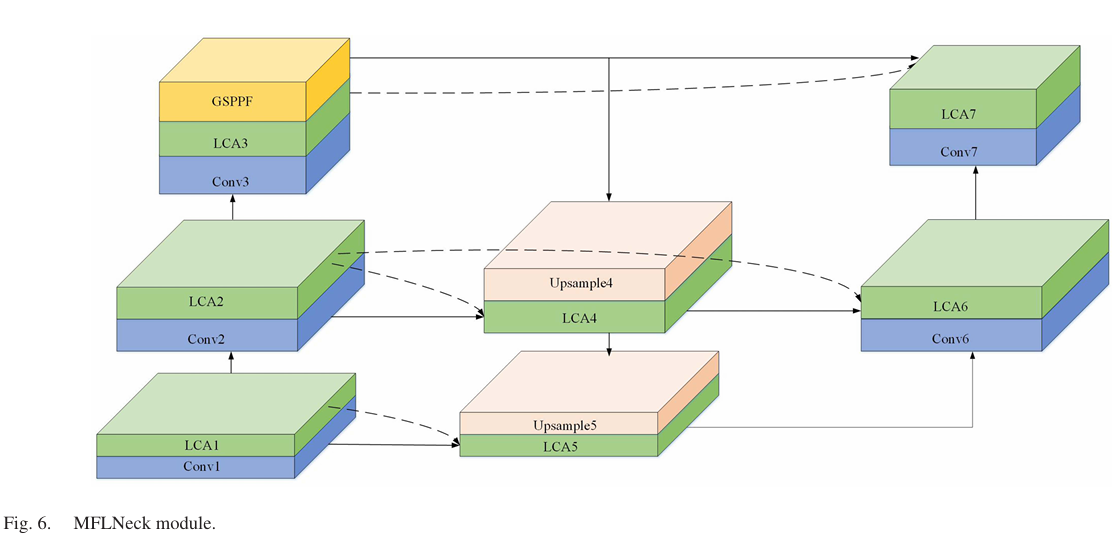
具体来说,在我们的方法中,我们在相邻层之间进行融合操作,例如Conv1、LCA1和Upsample5。此外,在LCA2、LCA4和Conv6之间执行跨层融合。这些融合策略旨在优化跨尺度的特征连接,提高模型有效捕获和利用层次信息的能力。
LCA4=concat(Upsample4,LCA2,Conv2)LCA5=concat(Upsample5,LCA1,Conv1)LCA6=concat(LCA2,LCA4,Conv6)LCA7=concat(LCA3,GSPPF,Conv7).\begin{aligned}&\mathrm{LCA4}=\mathrm{concat}(\mathrm{Upsample4},\mathrm{LCA2},\mathrm{Conv2})\\ &\mathrm{LCA5}=\mathrm{concat}(\mathrm{Upsample5},\mathrm{LCA1},\mathrm{Conv1})\\ &\mathrm{LCA6}=\mathrm{concat}(\mathrm{LCA2},\mathrm{LCA4},\mathrm{Conv6})\\ &\mathrm{LCA7}=\mathrm{concat}(\mathrm{LCA3},\mathrm{GSPPF},\mathrm{Conv7}).\\ \end{aligned}LCA4=concat(Upsample4,LCA2,Conv2)LCA5=concat(Upsample5,LCA1,Conv1)LCA6=concat(LCA2,LCA4,Conv6)LCA7=concat(LCA3,GSPPF,Conv7).
通过融合相邻和重叠的层,我们改进了高层和低层特征的整合。这种方法极大地增强了模型融合和提取特征的能力,特别是对于小目标。因此,该模型实现了对小目标更精确的定位和分类。同时,在特征融合块内,我们利用LCA模块来增强对尺度变化的适应性并减少参数。该模块替换了之前的C2f模块,从而优化了模型中特征整合的效率和有效性。
IV. 实验结果
A. 数据集和评估指标
我们在RSI数据集上验证了MFFCI-YOLOv8方法:
NWPU VHR-10:NWPU VHR-10数据集包含800张超高分辨率RSI,分为10个常见目标类别:飞机(AL)、船舶(SH)、储罐(ST)、棒球场(BF)、网球场(TC)、篮球场(BC)、田径跑道(GR)、港口(HB)、桥梁(BD)和车辆(VC)。我们将数据集随机分为80%用于训练,10%用于验证,10%用于测试。
VisDrone:VisDrone数据集是从各种无人机平台收集的,包含多样化的场景和环境。它包含超过540,000个标注的边界框,涵盖10个预定义类别:行人(PT)、人员(PP)、自行车(BC)、汽车(CA)、货车(VA)、卡车(TR)、三轮车(TC)、带棚三轮车(AT)、公共汽车(BU)和摩托车(MC)。在我们的实验中,我们随机选择了6471张图像用于训练,548张用于验证,1610张用于测试。
mAP(平均精度均值)量化了多类目标检测的性能。其计算公式为:
mAP=1C∑i=1C∫01Pi(Ri)dRi,\mathrm{mAP}=\frac{1}{C}\sum_{i=1}^{C}\int_{0}^{1}P_{i}(R_{i})d R_{i},mAP=C1i=1∑C∫01Pi(Ri)dRi,
其中 CCC 表示数据集中的类别数量,PiP_{i}Pi 和 RiR_{i}Ri 分别表示第 iii 类的精度和召回率。
B. 实现细节
实验使用Python 3.8和PyTorch 1.9框架进行。硬件配置包括Intel® Core™ i7-10700 CPU @ 2.90 GHz和Nvidia GeForce RTX 1080Ti GPU。重要的是,本文中的模型未使用预训练权重进行初始化。优化使用SGD55进行,初始学习率为0.01,动量为0.937。训练时使用的批大小为16。具体来说,对于NWPU VHR-10数据集,模型训练了200个周期。而对于VisDrone数据集,训练持续了150个周期。
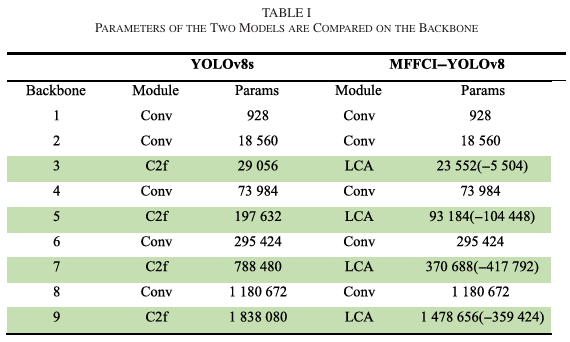
C. 模型参数比较和 ∂\partial∂ 分析
MFFCI-YOLOv8与YOLOv8s在骨干网络上进行了比较。表I显示,MFFCI-YOLOv8通过使用卷积进行局部通道特征提取,显著减少了参数数量。在前五层中,由于通道数较少,这种优势并不明显。然而,随着通道数的增加,我们的模型在第七层和第九层表现出明显的效率增益,分别减少了417,792和359,424个参数。总体而言,我们的模型包含1026万个参数,比YOLOv8s的1112万个参数减少了7.7%。
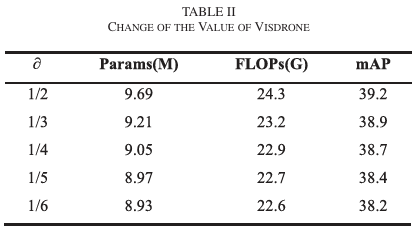
在LCA模块中选择 ∂\partial∂ 的值时,选择较大的值往往会使其效果降低到普通卷积的水平,而选择较小的值则会降低其有效捕获空间信息的能力。我们的实验(详见表II)涉及测试 ∂\partial∂ 的各种值。随着 ∂\partial∂ 的减小(表示用于特征提取的通道更少),参数数量和FLOPs相应减少。然而,这种效率的降低也与准确性的下降相关。对于特定的实验要求,可以选择不同的 ∂\partial∂ 值。为了获得更高的准确性,优选较大的值,而较小的值则有助于构建更轻量的模型。在本文中,我们根据实验目标选择了 ∂=1/2\partial=1/2∂=1/2。
D. 对比实验
为了证明MFFCI-YOLOv8模型的优越性,我们将其与单阶段模型(YOLOv5s、YOLOv6s、YOLOv7tiny和YOLOv8s)、两阶段模型(Faster R-CNN、Cascade R-CNN)以及RSOD算法(HIC-YOLOv5、LAI-YOLOv5和LAR-YOLOv8)进行了比较。
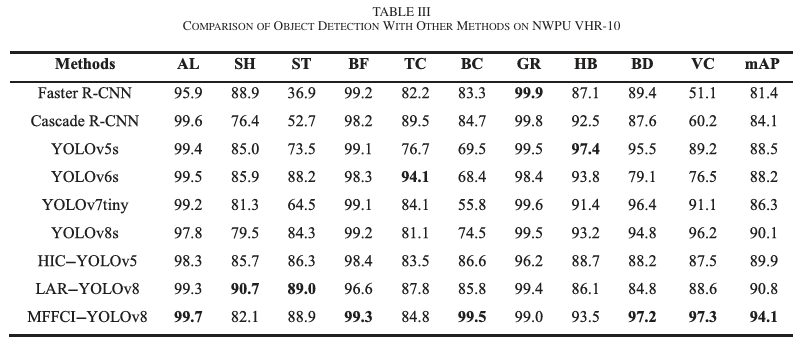
我们使用NWPU VHR-10数据集进行初步实验。表III详细比较了各方法在每个类别上的准确性。显然,我们的方法在五个类别上获得了最佳准确性,总体mAP达到94.1%。MFFCI-YOLOv8比YOLOv8s的准确性提高了4%。我们模型中的GSPPF和MFLNeck组件解决了小目标准确性低的问题。此外,它们显著增强了对不同尺度目标的特征提取性能,并减少了误检。在密集分布的小目标类别车辆(VC)中,我们的模型取得了97.3%的惊人准确性,远超其他模型。

我们在图7中选择了数据集中的10个类别目标进行可视化,展示了MFFCI-YOLOv8对这些目标及其各自类别的准确检测。此外,我们选择了两个包含密集目标的复杂场景图像,这对检测提出了重大挑战。尽管存在这些复杂性,MFFCI-YOLOv8始终表现出其卓越的能力,能够准确检测这些具有挑战性场景中的目标。
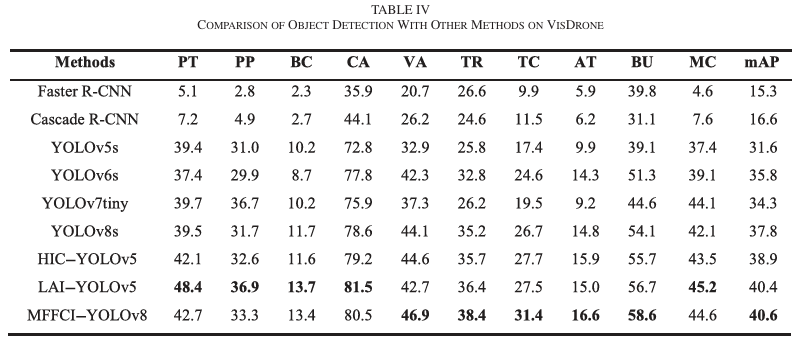
在具有挑战性的VisDrone数据集上进行了实验,以进一步验证所提出的MFFCI-YOLOv8。如表IV所示,在该数据集上,MFFCI-YOLOv8达到了40.6%的mAP,比基线YOLOv8s的整体准确性提高了2.8%。值得注意的是,MFFCI-YOLOv8在所有五个类别上都超过了其他模型,展示了其全面的优越性能。在汽车(CA)类别中取得的高准确性可归因于该类别包含大约160,000个大型目标。相比之下,带棚三轮车(AT)类别只有3778个较小的目标,受到的训练关注较少,导致准确性较低,为16.6%。这些结果凸显了我们的算法在检测RSIs中弱小目标方面的有效性和优越性。

我们在各种场景下进行了可视化实验,包括运动场、城市主干道、十字路口和昏暗的广场,以比较YOLOv5s、YOLOv8s和我们的MFFCI-YOLOv8算法的检测性能。图8说明了这些比较。首先,在操场场景中,放大视图显示该区域有一个广告牌,没有行人,只有我们的模型准确检测到该区域没有行人。在十字路口,待检测目标相对密集,主要由小型物品组成,并且存在遮挡问题。改进后的模型在检测密集小目标方面表现出色,准确识别了目标的正确类别,突显了其在挑战性场景中的有效性。在第三张图像中,有三辆自行车,而其他模型分别只检测到两辆和一辆。然而,MFFCI-YOLOv8成功检测到了所有三辆自行车。此外,即使在低光夜间条件下,我们的模型也能继续准确检测目标。标签表明,其他方法将目标误分类为货车,而我们的模型正确地将其识别为卡车,展示了其在不同环境条件下的适应性。
E. 消融评估
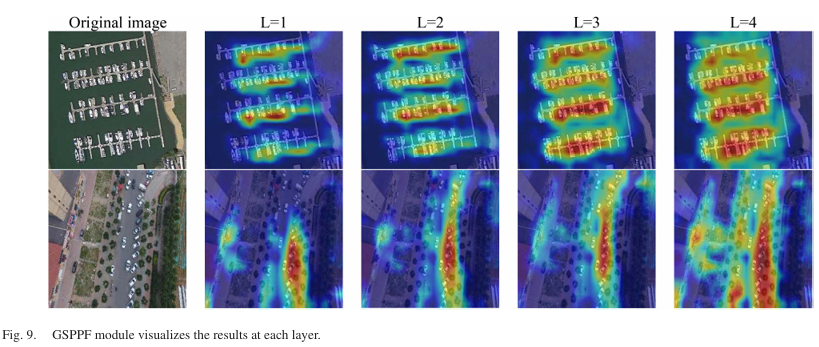
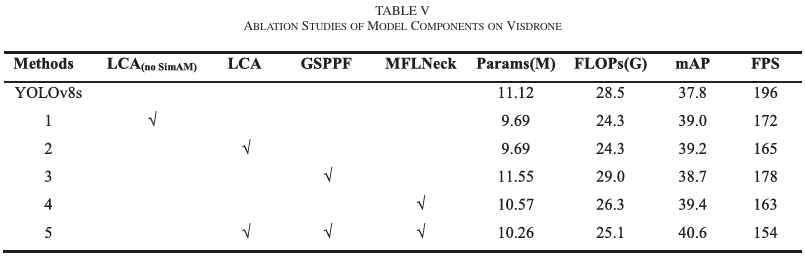
我们在VisDrone数据集上进行了消融实验,以YOLOv8s为基线模型,评估LCA、GSPPF和MFLNeck组件以及SimAM模块的有效性和影响。每个模块的贡献用"√"表示。评估指标包括mAP、参数数量、FLOPs和FPS,结果如表V所示。在实验1和2中,我们考察了LCA模块,该模块通过选择性地利用一部分通道进行在线特征提取的卷积运算。该模块还集成了无参数的SimAM模块,以更好地捕获重要的特征信息,弥补通道数量有限的不足。与YOLOv8s相比,LCA模块将参数数量减少了12.9%,FLOPs减少了14.7%,有效降低了计算复杂度,并将mAP提高了1.2%。然而,我们观察到FPS略有下降。在实验2中,我们引入了SimAM模块,该模块没有改变参数数量或FLOPs,证实了该模块是无参数的,不会增加任何计算负担。此外,准确性提高了0.2%,FPS的降低是可以接受的。这些结果表明,LCA模块不仅高效,而且在有限资源下也能实现卓越的性能。在实验3中,我们研究了GSPPF模块,该模块旨在使用不同内核大小的深度卷积来增强感受野。更大的感受野可以在更粗的粒度上捕获更广泛的全局上下文。此外,门控机制调节不同层次的上下文影响。我们在图9中展示了每一层。该模块的性能符合预期,随着内核尺寸的增加,信息捕获能力得到改善,有利于后续的特征融合。数据显示,该模块的参数数量仅增加了3.8%,FLOPs增加了1.7%,而mAP上升至38.7%。在实验4中,我们研究了MFLNeck模块的作用,该模块采用了一种新颖的特征金字塔来融合更多的高层和低层特征,从而增强了对小目标的检测。这个特征融合模块利用LCA进一步减少了参数数量。随着通道数量的增加,我们的模块能更有效地发挥其功能。在实验5中,我们结合了所有模块。与YOLOv8s相比,我们的模型参数数量减少了7.7%,FLOPs减少了11.9%,mAP提高了2.8%,同时保持了适中的FPS。这些消融研究强调了MFFCI-YOLOv8框架中每个模块的重要性,突显了它们的互补性以及在增强YOLOv8s性能方面的有效性。
V. 讨论
随着对轻量级模型和RSIs中准确目标检测需求的不断增加,我们的方法提供了一种可行的解决方案,在精度和计算约束之间取得了平衡。在本文中,我们提出了MFFCI-YOLOv8,一种轻量级RSOD网络,旨在解决RSIs带来的独特挑战。我们的方法侧重于多尺度特征融合和上下文信息,以提高检测精度,特别是对于小而密集分布的目标。所提出的LCA模块减少了通道冗余并集成了SimAM注意力机制,成功地减少了参数数量和计算复杂度,同时增强了特征提取能力,使其适用于硬件受限的环境。一个关键挑战是在保持模型轻量级的同时确保检测精度。如表V实验1所示,引入SimAM注意力机制使模型能够更好地区分重要的特征通道,从而在降低计算复杂度的同时保持高检测精度。这强调了在轻量级设计中结合适当注意力机制的重要性,以确保对性能的影响最小。此外,如表II所示,通道选择率显著影响模型的整体性能。虽然降低选择率会减少计算负载,但也会导致检测精度略有下降,因此仔细选择适当的值至关重要。
RSIs通常包含大量密集排列的小目标,这对目标检测模型提出了更大的挑战。尽管YOLO系列在常规目标检测任务中表现良好,但在检测小目标方面仍然存在挑战。在本文中,我们引入了GSPPF和MFLNeck模块。GSPPF模块利用不同大小的卷积核来捕获不同尺度的上下文信息,充分考虑了RSIs中目标尺寸的多样性。与传统的最大池化操作相比,使用深度可分离卷积不仅保持了模型的轻量级特性,还改善了对小目标的特征提取。通过门控机制,GSPPF模块可以自适应地选择最有用的上下文信息层次,从而增强模型的多尺度感知能力。这种设计特别适合包含众多小目标的RSIs。MFLNeck模块的一个关键特性是其跨层特征融合策略。除了融合相邻层之间的特征外,我们还增强了跨层的特征交互,确保高层特征能够传播到低层,从而改善小目标检测。通过这种多尺度融合策略,MFFCI-YOLOv8能够更准确地捕获不同尺度目标的特征,显著提高了小目标的定位和分类精度。
基于第四节对MFFCI-YOLOv8的综合分析,NWPU VHR-10和VisDrone数据集上的实验结果表明,尽管我们的模型是一个更轻量级的网络,但与著名的通用目标检测器和遥感目标检测器相比,它在多个类别上实现了最高的准确性,并且总体上优于其他模型。从可视化结果可以看出,通过增强上下文信息和多尺度特征融合,该模型在几个具有挑战性和复杂场景中对密集分布的小目标实现了出色的检测结果。虽然本文的轻量级设计降低了计算成本,但在极端资源受限的硬件环境中进一步降低FLOPs和内存使用仍然是一个值得进一步探索的话题。未来,我们旨在通过模型蒸馏和神经网络剪枝等技术进一步轻量化模型,以降低计算成本并提高推理速度。此外,小而密集分布的遥感目标问题仍然是一个具有挑战性的研究领域,我们将根据实验观察投入更多精力来解决这一问题。
VI. 结论
目前,大量研究工作集中在使用大规模模型来提高实验精度,却常常忽略了部署所面临的挑战。RSIs的特点是目标小而密集。因此,我们提出了一种名为MFFCI-YOLOv8的轻量级RSOD算法,该算法结合了多尺度特征融合和上下文信息。MFFCI-YOLOv8通过引入LCA、GSPPF和MFLNeck模块,不仅展示了强大的特征提取能力,还能高效地融合不同尺度的特征,尤其在检测密集分布的小目标方面表现出色。与YOLOv8s等现有方法相比,它在显著减少参数数量和计算复杂度的同时,实现了更高的精度。我们在两个数据集上取得了更高的准确性,广泛的实验验证了LCA、GSPPF和MFLNeck组件的有效性。MFFCI-YOLOv8有利于在各种RSOD场景的硬件上部署。