1 多态相关面试题
1.1 背景
- C++内存分布有
- 栈
- 堆
- 全局静态存储区
- 常量存储(只读数据区)
- 代码
- 虚拟空间地址:用户空间分布
- 栈
- 文件映射
- 堆
- BSS
- 数据段
- 代码段
- 编译过程:
- 预处理:把头文件中的函数声明拷贝到源文件,避免编译过程中语法分析找不到函数定义
- 编译:词法分析、语法分析、语义分析,同时进行符号汇总(函数名)
- 汇编:将汇编指令翻译为二进制机器码,生成函数名到函数地址的映射,方便通过函数名找到函数定义位置,从而执行函数
- 链接:将多个文件中的符号表汇总合并
- objdump -s -j .rodata +可执行程序 可以通过以上命令查看只读数据区查看虚函数表
1.2 多态实现原理
1.2.1 静态多态
- 编译期确定
- 函数重载
- 允许同一作用域中声明多个功能类似的同名函数
- 这些函数的参数列表,参数个数或者参数顺序不一样(返回值不能作为重载依据)
- 原理就是上面所提到的编译过程的原理
- 类模板和函数模板
- 函数模板:允许定义一种通用的函数形式,其中某些类型是参数化的。编译器根据调用时传入的实际类型参数来生成具体的函数版本
- 类模板:允许定义一种通用的类形式,其中某些类型时参数化的。在实例化类模板时,根据提供的具体类型参数创建特定类型的类
1.2.2 动态多态
- 运行时确定
- 虚函数重写
- 在基类函数前加virtual关键字,在派生类重写该函数
- 运行时将会根据对象类型来调用相应函数
- 如果对象的类型是基类,则调用基类函数
- 如果对象类型是派生类,则调用派生类函数
1.2.3 原理
- 早绑定(静态多态):编译器编译时已确定对象调用的函数的地址
- 晚绑定(动态多态)
- 若类使用virtual函数,则会为类生成虚函数表(一维数组,存放虚函数地址),类对象构造时会初始化该虚函数表指针
- 虚函数表指针在构造函数中初始化
1.3 面试题
1、某个有虚函数类的大小是多少?
答:这里需要主要的是,出了类的成员变量之外,还要计算虚函数指针的大小。一个虚函数表指针在64为的操作系统为8个字节。如果有多继承,那么就得加上多个虚函数表。而且一般操作系统的大小会进行一个字节的对齐,一般是8的倍数
2、动态多态的实现过程(底层实现机制)
- (带virtual关键字的函数)虚函数的类及其子类,在编译过程生成它们的虚函数表
- 在运行时,对象创建时,生成虚表指针(记录类虚函数表地址),根据对象指针或引用指向实际对象,从虚函数表中选择函数调用
3、为什么基类的析构函数设置为虚函数
为了确保在通过基类指针 删除一个派生类对象 时,能够正确调用派生类的析构函数,从而避免资源泄漏和未定义行为。
4、虚函数、虚函数表、虚表指针存在内存哪个区域
- 虚函数在代码段
- 虚函数表在只读数据段(常量数据区)
- 虚表指针与对象存储位置相同(堆或者栈或者全局静态数据区)
5、虚函数表创建时机
- 虚函数表内容在编译器编译的时候已经生成
6、虚函数表指针的创建时机
- 类对象在构造的时候,在构造函数中将虚函数表的地址赋值给对象vptr
- 如果类没有构造函数,则编译器为类生成默认构造函数从而为类对象初始化vptr
- 继承下,虚函数表指针赋值过程
- 调用基类函数的时候,先将基类的虚函数表地址赋值给vptr
- 接着调用子类构造函数时候,又将子类的虚函数表地址赋值给vptr
2 volatile关键字
2.1 背景
在我的原子操作CAS与锁实现-CSDN博客这篇博客中有讲到关于CPU多级缓存的一些知识,这里我再稍微带过,有需要详细了解的可以看上面的博客。
简单而言就是随着CPU的处理速度越来越快,CPU的计算速度已经远远的高于内存的访问速度。于是就在CPU设置了多级缓存,离CPU越近存储数据越少但是读取速度越快。因此在多处理器多核心中,每次读取写入/读取都会先读取缓存的数据再写入/读取内存的数据,即我们一般不会直接将数据写入内存中,就解决了CPU访问内存慢的问题。
但是会出现一个问题,如果两个核心在处理两个线程,并且访问一个变量i,线程1写i写在自己的缓存区,线程2读i并没有在缓存区读到i于是往内存读。但是其实缓存数据和内存数据是不一致的,就会出现数据不一致问题。也就是所谓的缓存一致性问题
2.2 volatile关键字作用
-
易变性(可见性):如1.1背景所说,所谓可见性就是由volatile定义的变量都直接写入内存中,防止出现缓存不一致的问题
-
不可优化的:在上面的那片博客我也提到过关于编译器优化的问题,代码在实际执行的时候与我们书写的顺序可能不同。有可能会被CPU或者编译器进行优化重排,可能导致出现一些bug。但是由volatile定义的变量就不会进行优化(只影响编译器优化 (编译期),不影响 CPU 指令重排序(运行期))
-
顺序执行的:比如下面的这个例子,编译器重排可能会将 i = 1与 i += 1排到一起, j = 1与 j += 1排到一起。但是如果是volatile定义的就不会进行重排
*cppint i = 1; int j = 1; i += 1; j += 2;
2.3 使用场景
- 多线程共享字段(标志位)且常被修改
- 中断服务程序和硬件设备访问相关的情况
误区:volatile没有原子性,原子性要通过原子操作或者锁来实现
2.4 相关面试题
1、C++ 中 volatile 的作用是什么?
答: volatile 告诉编译器:该变量的值可能在程序控制之外被改变(如硬件寄存器、中断服务程序、多线程等),因此:
- 禁止编译器对该变量进行优化(如缓存到寄存器、删除"看似无用"的读写);
- 每次访问都必须从内存中重新读取或写入。
核心目的:防止编译器优化导致程序行为错误
2、volatile 成员函数是什么意思?
答: volatile 修饰成员函数,表示该函数可以在 volatile 对象上调用 。类似于 const 成员函数,volatile 成员函数内部:
- 只能调用其他
volatile成员函数; - 只能访问
volatile或普通成员(但不能修改非mutable非volatile成员)。
3、C++ 的 volatile 能保证多线程可见性或原子性吗?
答:❌ 不能! 这是最常见误区!
- C++98/03 :
volatile完全不涉及线程语义,仅用于防止编译器优化。 - C++11 及以后 :引入了内存模型和
std::atomic,明确说明volatile不适用于多线程同步。 - volatile ≠ 线程安全!多线程共享变量应使用
std::atomic、std::mutex等同步机制。
3 map和 unordered_map区别
map和unordered_map的问题其实主要考察的就是底层的实现原理。map底层是红黑树而unordered_map底层则是hash表。关于这两个数据结构,可以看这我的这两篇博客,有详细的叙述。红黑树底层实现-CSDN博客、海量数据去重的hash-CSDN博客。这里不再赘述
|---------------|----------------------|---------------------------------|
| 特性 | map | unordered_map |
| 底层实现 | 红黑树(自平衡二叉搜索树) | 哈希表(Hash Table) |
| 元素顺序 | 按 key 有序(默认升序) | 无序(取决于哈希函数和桶分布) |
| 查找/插入/删除时间复杂度 | O(log n) | 平均 O(1),最坏 O(n)(哈希冲突严重时) |
| 是否需要 key 可比较 | 是(需支持<运算符或自定义比较函数) | 否,但需要可哈希(提供std::hash或自定义哈希函数) |
| 内存开销 | 较低(每个节点有左右指针和颜色位) | 较高(哈希表需预留空桶,负载因子控制) |
| 迭代器稳定性 | 插入/删除不影响其他迭代器(除被删元素) | 插入可能导致 rehash,使所有迭代器失效 |
一些关于C++中STL的面试题
3.1 面试题
1、key为结构体或类对象,map和unordered_map分别需要如何处理
答:map 基于红黑树,插入/查找时需要比较 key 的大小,因此 key 类型必须支持 严格弱序关系(strict weak ordering)。
- 方法一:重载operator<(最常用)
- 方法二:提供自定义比较函数对象(functor)
- 方法三:使用lambda
哈希表通过 哈希函数 定位桶,再用 相等判断 解决冲突。因此需要:
- 一个 哈希函数 (返回
size_t) - 一个 相等比较函数 (通常是
operator==)
实现步骤:重载 operator== + 提供哈希函数
2、map 的 key 为什么必须可比较?
因为 map 基于红黑树,插入/查找时需通过比较确定元素在树中的位置。默认使用 std::less<Key>(即 < 运算符)。
4 select、poll和epoll的区别
关于select、poll和epoll的讲解我在多篇文章中都有涉及:深入浅出理解epoll原理-CSDN博客、epoll的实现原理-CSDN博客。其实对于一些网络请求的系统调用如read/write等io处理,会分为两步操作:
- 检测:比如read的返回值,其实就是一种检测机制,如果read返回值>0就是接收到了数据
- 处理:将内核缓冲区的数据拷贝到用户态的buf中
那么诸如select、poll和epoll的这些同步检测的IO组件其目的就是替代系统调用的检测的作用。
而在区别上,有以下几点不同:
- 接口上:
- select、poll只有一个接口
- epoll有三个接口:事实上epoll用两个接口实现上述一个接口功能
- 传参及返回值上:
- select:需要传入可读、可写、异常三个集合,返回后仍需要遍历取出就绪事件
- poll:只需要传入一个集合,poll返回后仍需遍历取出就绪事件
- epoll:通过epoll_ctl只需要添加一次,epoll_wait取出就绪事件
- 底层实现上:
- select、poll通过轮询;select是数组、poll是链表
- epoll通过回调机制,将就绪io从红黑树拷贝到就绪队列
- 管理fd上:
- select有FD_SETSIZE
- poll和epoll没有限制
- 触发机制上:
- select、poll只有水平触发
- epoll:有水平触发和边沿触发
- 效率上:
- 少量fd,都比较活跃情况下,select/poll性能更高
- 大量fd,小部分活跃情况下,epoll性能更高
水平触发(LT)和边沿触发(ET)的区别:
|-------------------------|------------------------------------|-----------------------|-------------------------------|
| 模式 | 触发条件 | 行为特点 | 使用方法 |
| LT(Level Triggered) | 只要 fd 处于就绪状态(如缓冲区有数据),就会持续通知 | 默认模式,编程简单,可重复读取 | 即使不一次性读完,下次epoll_wait仍会返回 |
| ET(Edge Triggered) | 仅在 fd 状态发生变化时通知一次(如从无数据 → 有数据) | 高效,减少epoll_wait调用次数 | 必须一次性读完/写完数据(通常配合非阻塞 I/O) |
注意:ET模式下必须使用非阻塞的socket!否则可能因为read阻塞导致其他事件无法处理
5 vector的底层实现
一句话概述:vector底层实现了一个动态数组
5.1 底层实现原理
- 类构成
- class vector : protected _Vector_base:protect继承,基类的public在子类变为protected;其他权限不变
- _Vector_base
- _M_start:容器开始的位置
- _M_finish:容器结束的位置
- _M_end_of_storage:动态内存最后一个元素的下一个位置
- 构造函数
- 无参构造:不会预先申请内存,性能优先
- 初始化元素个数构造
- 申请动态内存
- 避免多次申请动态内存,从而影响性能
- 插入元素
- 插入到最后:检查空间是否需要动态分配内存,并检查是否需要翻倍
- 插入到不是最后:同样检查是否需要动态分配内存和是否需要翻倍,然后将待插入位置之后元素往后平移一位,再插入元素
- 数组的翻倍扩容,会分配一块更大的新内存(通常是原容量的 1.5 或 2 倍),将旧数据拷贝/移动过去,然后释放旧内存。
- 删除元素
- 删除最后一个元素:_M_finish往前移动一位,删除的元素不会释放现有的空间
- 删除不是最后一个元素:待删位置之后的元素所有元素向前移动一位,删除的元素不会释放现有的空间
- 读取元素
- 操作符\[\]:如果越界会返回错误
- at:比操作符多了一个越界判断的操作
- 它们返回都是具体元素的引用
- 修改元素
- vector不支持修改某个位置的元素
- 但是可以通过读取元素,获取引用,然后修改其值
- 先删除后插入
- 释放空间
- swap一个容器
- C++11可以使用shrink_to_fit
5.2 面试题
1、什么时候vector的迭代器会失效?
- 插入元素 :如果导致
capacity改变(即重新分配内存),所有迭代器、指针、引用失效。 - 删除元素:被删除元素及其之后的迭代器失效。
clear()/resize()/assign():所有迭代器失效。
2、vector内存如何释放?
答:调用clear()只会清空元素(size = 0),但不释放内存(capacity不变)。要真正释放内存,可以调用swap或者先clear然后再调用C++11的shrink_to_fit
6 ping的原理
6.1 原理
ping不是独立的协议,而是基于ICMP(Internet控制报文协议)实现的网络工具,核心作用是测试两台主机间的**IP层连通性,**并反馈"通不通""延迟高不高""丢不丢包"这三个关键信息。因为ping是基于IP层的协议,所以能ping通只是说明IP层没有问题。
有一个大的误区就是像网站访问(HTTP)、数据库连接(MySQL)依赖的是传输层(TCP/UDP)和应用层------哪怕ping通,若端口被防火墙拦截、应用没启动,服务照样用不了;反过来,有些服务器为了安全会禁用ICMP(不让ping),但服务却能正常访问
ping的流程本质是"请求-应答 ",核心依赖ICMP的两种报文:Echo Request(回显请求,类型8) 和Echo Reply(回显应答,类型0),步骤拆解如下
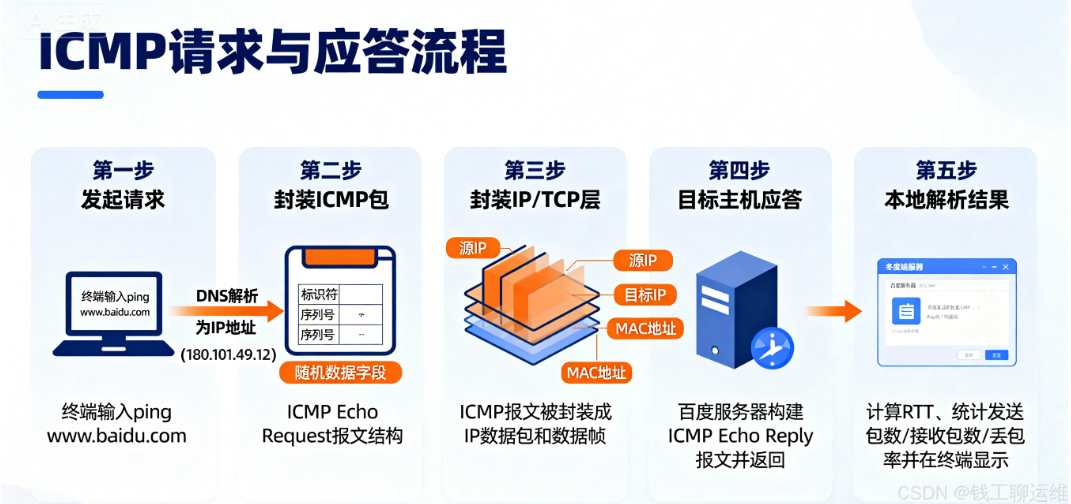
- 封装请求:当你在终端输入ping www.baidu.com的时候,首先会通过DNS将域名解析为IP
- 封装ICMP:本地主机构建一个ICMP Echo Request报文,里面包含两个关键的字段标识符(区分不同ping请求)和序列号(按序排列,方便判断是否丢包),还会携带随机序列(用于校验数据包的完整性)
- 封装至IP层:将ICMPC包封装至IP数据包,再封装层MAC包,通过网卡发送到网络中
- 目标主机应答 :若目标主机(百度服务器)正常且未禁用ICMP,收到请求后会拆包识别到"Echo Request",然后构建一个ICMP Echo Reply报文(把请求里的标识符、序列号、随机数据原封不动返回),按原路径发回本地
- 本地解析结果 :本地主机收到Reply后,计算"发送时间-接收时间"得到往返时间(RTT),并统计"发送包数/接收包数/丢包率",最终显示在终端上。
6.2 面试题
1、ping目标主机"请求超时",怎么判断是哪的问题?
- 先ping 本地回环地址127.0.0.1:若不通,说明本地TCP/IP协议栈有问题(比如Windows的 winsock 损坏,需用netsh winsock reset修复);
- 再ping 本地网卡IP(比如192.168.1.10):若不通,可能是网卡驱动故障或网卡硬件坏了;
- 最后ping 网关IP(比如192.168.1.1):若不通,说明本地到网关的链路有问题(比如网线松了、交换机端口故障);若通,再ping目标主机,此时不通大概率是目标端的问题(比如对方禁用ICMP、防火墙拦截)。
7 手撕单例模式
以下代码的4、5版本最好能够手撕
单例实现要点:
- 构造和析构函数是私有的,不允许外部生成和释放
- 静态成员变量和静态返回单例的成员函数
- 禁止拷贝构造和赋值运算符
版本1:使用全局静态变量作为单例对象。存在问题就是new出来的对象可以释放,但是无法调用到类析构函数,如果析构函数中有一些特殊处理的话可能会发生错误
cpp
// 版本一无法调用析构函数
Singleton1* Singleton1::_instance = nullptr;
class Singleton1{
public:
static Singleton1* getInctance(){
if(_instance == nullptr){
_instance = new Singleton1();
}
return _instance;
}
private:
Singleton1();
~Singleton1(){
cout << "~Singleton1" << endl;
}
Singleton1(const Singleton1&) = delete;
Singleton1& operator=(const Singleton1&) = delete;
Singleton1(const Singleton1&&) = delete;
Singleton1& operator=(const Singleton1&&) = delete;
static Singleton1* _instance;
};版本2:完善版本1中无法调用到析构函数的问题,使用atexit方法,在程序退出的时候会调用这个方法。那么我们实现手动的析构,就可以调用到析构函数
cpp
// 版本二:能够调用析构函数但线程不安全
Singleton2* Singleton2::_instance = nullptr;
class Singleton2{
public:
static Singleton2* getInctance(){
if(_instance == nullptr){
_instance = new Singleton2();
atexit(Destructor);
}
return _instance;
}
private:
Singleton2();
~Singleton2(){
cout << "~Singleton2" << endl;
}
static void Destructor(){
delete _instance;
_instance = nullptr;
}
Singleton2(const Singleton2&) = delete;
Singleton2& operator=(const Singleton2&) = delete;
Singleton2(const Singleton2&&) = delete;
Singleton2& operator=(const Singleton2&&) = delete;
static Singleton2* _instance;
};版本3:实现线程安全的两种方法
- 方法一:单检测,在if前加锁,在多线程环境下确保只有一个对象。但是性能低,因为真正new的线程只会有一个,而其他的线程都是直接return就行
- 方法二:双检测,可以提高性能。但是也会遇到CPU指令重排的问题,就是有可能出现返回了对象但是没有调用构造函数,导致内存泄漏
cpp
// 版本三:采用互斥锁,但是会有内存泄漏问题
Singleton3* Singleton3::_instance = nullptr;
mutex Singleton3::_mutex;
class Singleton3{
public:
static Singleton3* getInctance(){
// lock_guard<mutex> lock(_mutex);// 3.1
if(_instance == nullptr){
lock_guard<mutex> lock(_mutex);// 3.2 双检查
if(_instance == nullptr){
_instance = new Singleton3();
//CPU指令重排:
//1.分配内存
//2.调用构造函数
//3.返回对象指针
atexit(Destructor);
}
}
return _instance;
}
private:
Singleton3();
~Singleton3(){
cout << "~Singleton3" << endl;
}
static void Destructor(){
delete _instance;
_instance = nullptr;
}
Singleton3(const Singleton3&) = delete;
Singleton3& operator=(const Singleton3&) = delete;
Singleton3(const Singleton3&&) = delete;
Singleton3& operator=(const Singleton3&&) = delete;
static Singleton3* _instance;
static mutex _mutex;
};版本4:双检测+原子操作+内存屏障。确保构造函数在返回对象指针之前被调用
cpp
// 版本4:使用内存序防止CPU指令重排导致内存泄漏问题
atomic<Singleton4*> Singleton4::_instance;
mutex Singleton4::_mutex;
class Singleton4{
public:
static Singleton4* getInctance(){
Singleton4* tmp = _instance.load(memory_order_relaxed);
atomic_thread_fence(memory_order_acquire);
if(_instance == nullptr){
lock_guard<mutex> lock(_mutex);// 3.2 双检查
if(_instance == nullptr){
tmp = new Singleton4();
atomic_thread_fence(memory_order_release);
_instance.store(tmp,memory_order_relaxed);
atexit(Destructor);
}
}
return tmp;
}
private:
Singleton4();
~Singleton4(){
cout << "~Singleton4" << endl;
}
static void Destructor(){
delete _instance;
_instance = nullptr;
}
Singleton4(const Singleton4&) = delete;
Singleton4& operator=(const Singleton4&) = delete;
Singleton4(const Singleton4&&) = delete;
Singleton4& operator=(const Singleton4&&) = delete;
static atomic<Singleton4*> _instance;
static mutex _mutex;
};版本五:最常用,一定要会。使用静态局部变量具有线程安全的特性
cpp
class Singleton5{
public:
static Singleton5* getInctance(){
static Singleton5 _instance;
return &_instance;
}
private:
Singleton5();
~Singleton5()
{
cout << "~Singleton5" << endl;
}
Singleton5(const Singleton5&) = delete;// 拷贝构造函数被删除
Singleton5& operator=(const Singleton5&) = delete; // 拷贝赋值运算符被删除
Singleton5(const Singleton5&&) = delete;// 移动构造函数被删除
Singleton5& operator=(const Singleton5&&) = delete;// 移动赋值运算符被删除
};8 字节序问题
- 字节序:占内存超过1字节类型的数据再内存中存放顺序,通常包括大端和小端
- 大端:是指数据的低位字节序保存在内存的高地址中,而数据的高位字节序保存在内存的低地址中
- 小端:是指数据的低位字节序保存在内存的低地址中,而数据的高位字节序保存在内存的高地址中

- 计算机电路处理顺序是从低位往高位处理的,所以计算机内部通常采用小端字节序
- 如果需要逐位运算,或从个位开始运算,小端优
- 奇偶性、比大小、类型转换
- 运算只涉及高位,或要求可读性,大端优
- 判读正负
- 操作系统一般采用小端,而通讯协议一般使用大端
- 如果需要逐位运算,或从个位开始运算,小端优
如何判断机器大小端?
1、指针转换法
cpp
#include <stdio.h>
int is_little_endian() {
int i = 1;
// 等同于 char* p = (char*)&i; return *p;
return *(char*)&i; // 小端:返回 1,说明数据的低字节在内存的低地址存放
// 大端:返回 0,说明数据的低字节在内存的高地址存放
}2、联合体法
cpp
#include <stdio.h>
int is_little_endian() {
union {
int i;
char c;
}un; // 匿名联合体
un.i = 1;
return un.c; // 小端:返回 1,说明数据的低字节在内存的低地址存放
// 大端:返回 0,说明数据的低字节在内存的高地址存放
}网络编程中大小端数据如何转换?
- 约定两端字节序
- 读写数据时候
- 判断当前主机大小端是否为约定字节序
- 是,不做处理
- 否,进行转换
- 判断当前主机大小端是否为约定字节序
- 处理方式
- 逆转
- 位运算
- 数组填充
- socket地址绑定时的字节转换函数(htonl,htons)
9 关键字override,final的作用
- C++11引入的这两个关键字
- 为什么引入?
- 虚函数复写
- 不能阻止某个函数进一步重写
- 本意写一个新函数,错误的重写基类的虚函数
- 本意重写虚函数,但签名不一致,导致在子类重新构造了一个新的虚函数
- 类继承:不能阻止一个类的进一步派生
- 虚函数复写
- override
- 指定子类一个虚函数复写基类的一个函数
- 保证该重写的虚函数与基类的虚函数有相同签名
- final
- 指定某个虚函数不能在派生类中被覆盖,或者某个类不能被派生
- 阻塞类进一步派生
- 阻塞虚函数进一步重写
10 菱形继承
- 什么是菱形继承
- 前提:C++11具备其他语言没有的多继承的特性
- 一个子类可以继承多个父类,这些父类可能继承相同的父类,从而造成菱形继承
- 菱形继承有什么问题
- 浪费存储空间
- 造成二义性
- 怎么解决菱形继承
- 虚继承
- 子类只继承父类的父类
- 继承时带上virtual关键字
- 虚继承底层实现原理
- g++ -fdump-class-hierachy *.cpp(gcc 8.0之前)
- g++ -fdump-lang-class *.cpp(gcc 8.0之后)
- 通过虚表偏移来实现虚继承
- 父类的vptr都有到共同基类的偏移量,从而让子类多继承指向同一个父类的父类
11 条件变量虚假唤醒
在多核处理器下,pthread_cond_signal可能会激活多于一个线程(阻塞在条件变量上的线程)。结果是,当一个线程调用pthread_cond_signal()后,多个调用pthread_cond_wait()或pthread_cond_timedwait()的线程返回。这种效应成为"虚假唤醒"(spurious
wakeup)
在线程池模型中,就有条件变量的使用。在多生产者多消费者的模型,如果线程池的任务队列中没有可以消费的队列,那么多个消费者线程就会阻塞在条件变量中等待。当生产者线程加入一个任务时,此时调用pthread_cond_signal会唤醒多个消费者线程,但实际只需要一个就够了,就会出现虚假唤醒的情况
当然条件变量虚假唤醒时操作系统或底层线程库(如 POSIX 线程 pthreads)允许的行为,因此可以在底层进行修改,但是比较复杂且会降低整体的并发性能。最好是在使用条件变量时始终保持一个关键原则:永远在 while 循环中检查条件,而不是 if 语句
12 reactor和poreactor网络模型区别
- 背景
- reactor是同步io网络模型
- 具体io检测由io多路复用进行检测
- 具体io操作由非阻塞io进行操作
- poreactor是异步io网络模型
- 具体io检测和io操作都是由内核完成
- 同步io与异步io区别
- 同步io调用后,马上能够过去io操作的结果
- 异步io调用后,程序不管io的状态且暂时获取不到io操作结果,用户态程序继续向下执行。io操作由内核进行操作
- 阻塞io和非阻塞io的区别
- 阻塞io:当io未准备就绪时,一直阻塞等待io的就绪
- 非阻塞io:无论io是否准备就绪都进行返回,io就绪时与阻塞io返回一致。io未就绪时会返回-1和错误码通知用户层io未就绪
- 两种通过传入的fd进行区别,即通过fctrl设置具体的fd是否为阻塞
- iocp(异步io)操作流程
- CreateCompletionPort 创建完成端口
- 创建监听的socket,bind,listen,将对应的listenfd绑定到完成端口
- 根据cpu核心创建工作线程,将完成端口传递到工作线程
- 通过GetQueueCompletionStatu阻塞获取io完成
- 然后进行进行业务逻辑处理
- 投递io请求:AcceptEx、RecvEx、SendEx
- reactor是同步io网络模型
- 本质区别
- reactor中先检查IO是否就绪,然后操作io
- poreactor投递请求,所有io操作由内核完成
| 特性 | Reactor | Proactor |
|---|---|---|
| 核心思想 | 同步非阻塞IO | 异步IO |
| IO操作执行者 | 应用程序 | 操作系统内核 |
| 通知内容 | "可读/可写"(事件就绪) | "读/写完成"(操作完成) |
| 应用程序角色 | 被动等待事件就绪,主动执行IO | 被动等待操作完成,只处理结果 |
| 性能与复杂度 | 实现相对简单,在极高负载下,上下文切换和系统调用稍多 | 理论性能更高,减少了用户态/内核态切换,但实现复杂 |
| 编程范式 | 基于回调的事件驱动 | 基于完成回调的异步驱动 |
| 典型代表 | Linux epoll , BSD kqueue, Java NIO | Windows IOCP, Boost.Asio (在Windows下) |
13 进程、线程与协程区别
| 特性 | 进程 | 线程 | 协程 |
|---|---|---|---|
| 基本定义 | 资源分配和拥有的基本单位 | CPU调度的基本单位,是进程中的执行流 | 用户态的轻量级线程,由程序员在用户空间控制 |
| 资源分配 | 系统分配独立的内存空间和资源 | 共享 进程的资源 | 共享 线程的栈和寄存器,拥有自己的栈空间(通常在堆上) |
| 调度器 | 操作系统内核 | 操作系统内核 | 用户自己的程序(在用户态调度) |
| 切换开销 | 非常高 | 较高 | 极低(仅需保存少量寄存器上下文) |
| 并发性 | 进程间并发 | 线程间并发/并行 | 协程间协作式并发,在单个线程内交替执行 |
| 阻塞影响 | 一个进程阻塞,不影响其他进程 | 同一进程内一个线程阻塞,会阻塞整个进程及其所有线程 | 一个协程阻塞,不会阻塞整个线程,线程可以切换到其他协程继续工作 |
| 内存占用 | 大(独立地址空间,通常几MB到几GB) | 较小(默认栈大小几MB) | 极小(栈空间可自定义,通常几KB) |
| 创建/销毁开销 | 大 | 中 | 小 |
| 数据同步 | 需要复杂的进程间通信(IPC) | 需要同步机制(锁、信号量等)保护共享数据 | 由于是协作式且通常在单线程内 ,无需锁来保护共享数据(但需注意执行顺序)。多线程调度可以使用channle、mutex机制同步 |
| 核心优势 | 稳定、安全、隔离性强 | 能利用多核CPU,并行计算 | 超高并发I/O性能,资源消耗极低 |
进程切换、线程切换和协程切换区别:
| 调度者 | 执行模式 | 核心开销来源 | 开销级别 |
|----------|--------------|---------|-----------------------------------------|--------|
| 进程切换 | 操作系统内核 | 抢占式 | 1. 陷入内核 2. 页表切换 & TLB刷新 3. 完整上下文切换 | 高 |
| 线程切换 | 操作系统内核 | 抢占式 | 1. 陷入内核 (系统调用) 2. 线程上下文切换 | 中 |
| 协程切换 | 用户程序/程序员 | 协作式 | 1. 保存/恢复少量寄存器(用户态函数调用级别) | 极低 |
进程切换和线程切换最主要的区别就是是否使用页表,线程切换不需要切换页表!
在高并发网络服务器(如微信、淘宝后台)中,有成千上万的连接需要同时处理。如果为每个连接创建一个线程:
- 内存开销巨大(1万个线程 × 8MB默认栈 ≈ 80GB内存!)。
- 线程频繁切换(由于I/O阻塞)导致CPU大量时间浪费在内核态的系统调用上。
而使用协程:
- 可以轻松创建数百万个协程(每个协程可能只需几KB内存)。
- 当一个协程等待网络数据时,它会主动让出CPU,线程可以立即执行其他就绪的协程。整个过程完全在用户态,没有系统调用和线程切换的开销,使得单线程就能处理极高的并发请求。
简单来说:进程和线程的切换是"内核大佬"在帮你调度,虽然公平但手续繁琐;协程的切换是"你自己"在调度,虽然需要自己协调,但极其高效灵活。
14 fflush和fsync的区别

|------------|-------------------------|---------------------------|
| 特性 | fflush | fsync |
| 所属标准 | C 标准库 (<stdio.h>) | POSIX 系统调用 (<unistd.h>) |
| 输入参数 | FILE * | int fd(文件描述符) |
| 刷新目标 | 用户空间 -> 内核page cache | 内核 page cache → 物理磁盘 |
| 是否保证落盘? | ❌ 否 | ✅ 是(理想情况下) |
| 性能开销 | 低 | 高(涉及磁盘 I/O) |
| 是否需要 root? | 否 | 否(但需对文件有写权限) |
| 常用于 | 确保printf立即输出、日志及时写入内核 | 数据库、关键配置等需要持久化的场景 |
❌误区1 :fflush 能防止断电丢数据
→ 错!它只到内核缓存,没到磁盘。
❌ 误区2 :fsync 可以直接用于 FILE*
→ 错!必须先用 fileno() 转成 fd。
✅ 正确做法 :关键数据写入后,先 fflush 再 fsync。
因此引申出一道面试题:如果写文件时进程宕机了,数据是否会丢失?
- 是否调用fflush
- 如果使用了FILE*但是没有调用fflush:数据可能还在用户空间,进程一崩就会丢失
- 如果调用了fflush:数据从用户态缓冲区 -> 内核page cache,但仍未到磁盘。进程崩了虽不丢,但是如果系统接着断电了,仍可能丢失
- 是否调用fsync
- 没调用:数据在内核的page cache中,由内核异步写回磁盘(通常为30s)
- 调用了:数据强制写入磁盘,即使系统断电也不会丢失
15 简述虚析构函数的作用
- 作用:确保通过基类指针删除派生类对象时,能够正确调用派生类的析构函数从而避免内存泄漏
- 背景:如果一个类被设计为基类(即可能被继承),并且会通过基类指针来管理派生类对象的生命周期(例如使用new创建派生类对象,但用基类指针指向它),那么必须将基类的析构函数声明为虚函数
cpp
class Base {
public:
~Base() { cout << "Base destructor\n"; }
};
class Derived : public Base {
public:
~Derived() { cout << "Derived destructor\n"; }
};
int main() {
Base* ptr = new Derived();
delete ptr; // 仅调用 Base::~Base(),Derived::~Derived() 不会被调用!
}- 总结
- 当类被用作基类且存在多态删除(即通过基类指针 delete 派生类对象)时,必须声明虚析构函数。
- 如果类不是设计为基类(不会被继承),通常不需要虚析构函数,因为虚函数会带来额外的内存开销(虚表)。
- 现代 C++ 最佳实践:只要类包含至少一个虚函数,就应提供虚析构函数。
16 虚函数表和虚函数表指针的创建时机
虚函数表和虚函数表指针是实现运行时多态(动态绑定)的关键机制
- 虚函数表(vtable)
- 创建时机:编译器(由编译器生成)
- 存储位置:通常存储在只读数据段(.rodata和.rdata),属于类的静态信息
- 每个含虚函数的类(包括从基类继承的虚函数)都会有一个唯一的vtable
- vtable中存储的是该类所有的虚函数的函数指针
- 如果派生类拥有自己的vtable,其中会:
- 覆盖基类中被重写的虚函数指针
- 保留基类中未被重写的虚函数指针
- 添加自己新增的虚函数指针
虚函数表在程序加载时就已经存在,不依赖对象的创建
- 虚函数表(vptr)
- 创建时机:运行时,在对象构造过程中由编译器自动插入代码初始化
- 存储位置:作为对象的一部分,通常位于对象内存布局的起始位置
- 每个含有虚函数的对象都会包含一个vptr
17 系统调用的整个过程
当用户程序需要请求操作系统服务(比如读写文件、创建进程等),就需要通过系统调用来实现。整个过程大致可以分为以下几个步骤:
- 用户程序调用封装函数
- 程序通常不会直接触发系统调用,而是调用C库(如glibc)提供的接口函数,例如read()、write()。这些库函数会准备好参数,并设置对应的系统调用
- 陷入内核态
- 接着,程序执行一条特殊的指令(如x86-64上的syscall指令),产生一个软中断或者陷阱(trap),CPU从用户态切换到内核态
- 内核处理系统调用
- 内核接收到中断后,根据系统调用号找系统调用表(sys_call_table),找到对应的服务函数如(sys_write),然后执行具体的内核操作,比如访问硬件、管理资源等
- 返回结果并切回用户态
- 系统调用执行完毕后,结果(成功返回值或错误码)通过寄存器返回给用户程序,内核执行返回指令(如sysret),CPU切换回用户态,程序继续运行
追问:系统调用是否会引起线程或进程切换?
- 大多数系统调用不会切换,如果系统调用执行完后没有进行阻塞或资源等待,则会直接返回用户态,此时CPU仍运行原进程/线程,没有上下文切换
- 某些系统调用可能导致阻塞,就会触发调用器,从而引发进程/线程切换
18 TCP和UDP有什么区别
18.1 TCP和UDP区别
- 是否面向连接
- TCP是面向连接的,通讯前需要三次握手,断开时需要四次挥手。是端对端的连接,支持全双工通讯
- UDP是面向无连接的,不需要三次握手和四次挥手,支持一对一、一对多、多对一和多对对的通讯
- 数据传输方式
- TCP面向字节流。不保留应用层的消息边界,数据像水流一样连续传输,接收方需要自行解析数据块。(存在粘包问题)
- UDP面向数据报。每个udp数据包都是独立的,有明确的边界,接收方收到的就是发送方发出的完整数据单元
- 是否可靠
- TCP是可靠的连接。提供确认机制(ACK)、重传机制、序列号、丢包重发、乱序重组、流量控制和拥塞控制,确保数据完整、有序、不丢失地到达。
- UDP是不可靠传输。不保证数据送达,也不重传、不排序。数据包可能丢失、重复或乱序,由上层应用自行处理。
- 传输效率
- TCP由于有连接建立、确认、重传、流量控制等机制,开销大,延迟较高但是稳定
- UDP头部小(8个字节),无连接开销,传输速度快、延迟低,适合对实时性要求高的场景
- 应用场景
|---------------------------------------|---------|---------------------|
| 场景 | 推荐协议 | 原因 |
| 网页浏览(HTTP/HTTPS)、文件传输(FTP)、电子邮件(SMTP) | TCP | 要求数据完整、准确,不能丢包 |
| 视频直播、在线游戏、语音通话(VoIP)、DNS查询 | UDP | 追求低延迟,少量丢包可接受,实时性优先 |
| 广播/组播(如网络发现、IPTV) | UDP | TCP不支持广播和组播 |
18.2 一些概念
- 确认机制
- 作用:接收方收到数据后,向发送方发送一个确认信号(ACK),表示"我已成功收到这段数据"。
- 原理:TCP 使用累计确认(Cumulative ACK),ACK 报文中携带"期望收到的下一个字节的序列号"。例如,如果接收方回复 ACK=1001,表示前 1000 字节都已正确接收。
- 目的:让对方知道哪些数据已经被接收,避免不必要的重传
- 重传机制
- 作用:当发送方在一定时间内未收到 ACK,就认为数据可能丢失,于是重新发送该数据。
- 触发条件
- 超时重传(Timeout):基于重传计时器(RTO, Retransmission Timeout);
- 快速重传(Fast Retransmit):如果发送方连续收到3 个重复 ACK(比如都确认同一个序列号),说明中间有包丢失,立即重传,无需等待超时。
- 目的:应对网络丢包,保障数据最终能送达。
- 序列号
- 作用:为每个字节的数据分配唯一编号,用于标识数据在原始字节流中的位置。
- 原理 :
- 初始序列号(ISN)在三次握手时协商;
- 后续每个 TCP 报文段的序列号 = 第一个字节的编号。
- 目的 :
- 接收方可以依次判断数据是否重复、是否乱序
- 支持乱序重组和去重
- 丢包重发
- 说明:这是重传机制的具体应用场景
- 当网络阻塞、链路故障等原因导致数据包丢失时,TCP通过ACK确实或者重复ACK检测丢包,并触发重传
- 关键的:TCP的丢包是透明的,上层应用无需关系,协议栈自动处理
- 乱序重组
- 问题背景:IP 网络不保证数据包顺序,可能导致后发的数据先到。
- TCP 解决方案 :
- 接收方根据序列号对收到的数据进行排序;
- 将乱序但完整的数据缓存在接收缓冲区;
- 只有当缺失的"前面"数据到达后,才将连续的数据提交给应用层。
- 目的 :向上层提供有序的字节流,就像数据从未乱序过一样。
- 流量控制
- 目的:防止发送方发得太快,撑爆接受方缓冲区(接受方处理不过来)、
- 机制:使用滑动窗口
- 接收方在ACK报文携带"接收窗口"字段,告诉发送方:"我还能接收多少数据"
- 发送方根据rwnd动态调整发送速率
- 本质:点对点发送-接收能力匹配,保护接受发
- 拥塞控制
- 目的:防止发送方发送太快,导致整个网络过载(拥塞),引发大量丢包甚至网络崩溃
- 与流量控制区别:流量控制是"接受方能力"问题,拥塞控制是"网络路径容量"问题
- 核心机制
- 慢启动:开始时指数增长发送速率(每收到一个ACK,窗口+1)
- 拥塞避免:线性增长,更谨慎
- 拥塞发生:
- 超时 -> 窗口重置为1,重新慢启动
- 快速重传-> 窗口减半("乘性减小"),进入快速恢复
- 关键变量:拥塞窗口(cwnd),实际发送窗口 = min(rwnd,cwnd)
19 malloc是如何分配内存,free是如何释放内存的
19.1 背景
- 进程虚拟地址空间分布
- 从低地址往高地址
- 代码段:二进制可执行代码
- 已初始化数据段:静态常量
- 未初始化数据段:未初始化静态常量
- 堆段:动态分配空间,从低地址往高地址
- 文件映射段:动态库、共享内存
- 栈段:局部变量和函数上下文,从高地址往低地址
- 内核空间:所有进程共享
- 分配的是虚拟内存
- 只有在使用该内存的时候,才会通过缺页异常分配真实的物理内存

19.2 如何分配和释放
- malloc如何分配?
- malloc内部会维护内存池。对于小于128k的内存,malloc会通过brk系统调用获取内存,释放后归还内存池,以减少频繁的系统调用和缺页异常的次数。但是也会增加内存碎片的问题
- 对于大于128k的内存,直接用mmap映射匿名内存,独立管理,释放后归还操作系统
- free如何释放?
- 对于小于128k的内存,归还内存池
- 对于大于128k的内存,立刻归还操作系统
- free如何知道释放大小?
- 在malloc在分配内存的时候,会在头部多申请12个字节header信息,比如malloc(100),实际会申请112个字节
- 而这个header的size字段记录了整个chunk大小(包括header本身)
- free(p)时会通过size的大小进行释放对应的资源