文章目录
- 项目所需知识
-
- web介绍
- URL介绍
- OSI模型与TCP/IP模型
- 当互联网中的两台主机通过http协议进行通信时,应用层负责的工作是什么?应用层的下层负责的工作又是什么?
- 什么是BS模型?
- 请你简单介绍一下在双端通信过程中数据的封装和解包过程
- 如何获取一个网站的IP地址?
- 浏览器网络中获取资源的过程
-
- 为什么要有域名呢?我们一般指定互联网中的一台主机,用的不都是IP地址吗?
- 为什么浏览器中输入域名就可以访问对端服务器呢?具体的访问过程是怎样的呢?
- [1. DNS域名解析](#1. DNS域名解析)
- [2. 向资源所在的服务器发起三次握手,建立tcp链接](#2. 向资源所在的服务器发起三次握手,建立tcp链接)
- [3. 浏览器构建并发送http请求报文](#3. 浏览器构建并发送http请求报文)
- [4. 信息在网络中传输](#4. 信息在网络中传输)
- 5.服务器接收到请求信息,根据请求生成响应数据
- [6. TCP四次挥手断开连接](#6. TCP四次挥手断开连接)
- [7. 浏览器解析响应并渲染页面:](#7. 浏览器解析响应并渲染页面:)
- http协议
-
- http/1.0版本简单介绍
- [为什么http 1.0 要设置成无状态的?](#为什么http 1.0 要设置成无状态的?)
- http协议如何记录用户的状态信息?
-
- [第一种方案:让HTTP 有状态,记录用户的状态信息(不合适)](#第一种方案:让HTTP 有状态,记录用户的状态信息(不合适))
- [第二种方案: cookie 和 session 方案(现阶段采用的方案)](#第二种方案: cookie 和 session 方案(现阶段采用的方案))
- [cookie和session 方案详细介绍](#cookie和session 方案详细介绍)
- HTTP请求报文和响应报文的格式分别是怎样的?
- 状态码
- 请求方法
- 请求报头/响应报头的常见字段
- 一、请求报头常见字段
- 二、响应报头常见字段
- GET请求和POST请求的区别
- 强缓存与协商缓存
-
- [1. 强缓存](#1. 强缓存)
- (1)`Expires`(HTTP/1.0)
- (2)`Cache-Control`(HTTP/1.1,优先级更高)
- [2. 协商缓存](#2. 协商缓存)
- [(1)`Last-Modified` 与 `If-Modified-Since`策略](#(1)
Last-Modified与If-Modified-Since策略) - [(2)`ETag` 与 `If-None-Match`策略(优先级更高)](#(2)
ETag与If-None-Match策略(优先级更高)) - [3. 缓存流程总结](#3. 缓存流程总结)
- [4. 应用场景](#4. 应用场景)
- HTTP1.0和HTTP1.1的区别
- HTTP2.0和HTTP1.1的区别
- HTTP3.0的特点
- [如何用VScode远程连接 SSH 服务器?](#如何用VScode远程连接 SSH 服务器?)
- 项目内容
项目所需知识
(注意:本节里面说的都是该项目相关的常考八股,本身内容就很长,想看项目的建议目录转到第二节)
web介绍
什么是www?什么是web?
WWW是环球信息网的缩写,(亦作"Web"、"WWW"、"'W3'",英文全称为"World Wide Web"),中文名字为"万维网","环球网"等,常简称为Web
3W它其实是一套访问互联网资源的一套生态,它规定了我们访问资源的方式是通过我们的 URL 来访问,它将互联网中的各种内容称之为各个资源,通过设计 HTTP 协议将资源从远端拉取到本地等等。上面这一整套对访问互联网资源的规定我们可以统称为3W
什么是web客户端?什么是web服务器?
web客户端其实就是你电脑中的浏览器
web服务器就是各大网站后台的服务器
web客户端(浏览器)发展史
- 1990年11月,世界上第一台Web服务器和Web浏览器诞生
- 1993年1月,NCSA(美国国家超级计算机应用中心,National Center for SupercomputerApplications,简称NCSA)研发html内联显示图片的浏览器Mosaic,不久,windows和苹果mac版的Mosaic相继出现,NASA httpd 1.0也差不多这个时期出现
- 1994年12月网景公司Netscape Navigator1.0(网景领航员)浏览器出现(这个浏览器可以访问图片)
- 1995年微软发布IE1.0和2.0(微软一共抄了俩次,一次就是抄袭苹果麦卡金的图形化界面,另一次就是抄袭领航员的能显示图片的浏览器)
紧随其后,web服务器标准Apache0.2诞生 - 1995年左右,微软和网景针对html标准开始打仗
2000年,网景衰落(因为微软有它自己的业务生态,大家电脑上装的都是windows操作系统,微软就可以在windows系统上内置IE浏览器) - 2004年,Mozilla(缩写MF或MoFo,全称Mozilla基金会,是为支持和领导开源的Mozilla项目而设立的一个非营利组织)基金发布firefox,第二次浏览器大战又开始了
- 随后, IE发布6,7,8,9,10版本,同步Chrome,Opera,Safari浏览器也开始抢占市场今天的浏览器格局形成
web服务器端(http协议)发展史
| 版本 | 发布时间 | 核心特性与革新 |
|---|---|---|
| HTTP/0.9 | 1991年 | 仅支持GET请求,无头部信息、状态码,仅能传输HTML文本,是极简的"单行协议"。 |
| HTTP/1.0 | 1996年 | 引入请求头/响应头、多种请求方法(GET/POST/HEAD等)、状态码,支持多类型数据传输;但每次请求需新建TCP连接,性能较低。 |
| HTTP/1.1 | 1997年 | 新增持久连接(Keep-Alive)、流水线请求、缓存控制、虚拟主机、分块传输编码等;解决了HTTP/1.0的连接开销问题,但仍存在"队头阻塞"(单连接串行处理请求)。 |
| HTTP/2 | 2015年 | 采用二进制协议、多路复用(单TCP连接同时处理多个请求)、头部压缩(HPACK)、服务器推送;彻底解决HTTP/1.x的队头阻塞,大幅提升并发性能。 |
| HTTP/3 | 2020年 | 基于UDP的QUIC协议,取代TCP;实现0-RTT握手、连接迁移,解决TCP拥塞控制导致的队头阻塞,在弱网环境下性能更优。 |
为什么早期互联网公司都喜欢做浏览器?现在又不咋做了呢?
因为早期用户想上网,只能通过电脑的浏览器,我要是做了个浏览器,让用户用我的浏览器来上网,我就可以在浏览器中夹带我的私货------给我的产品打广告,推销我的产品
而现在,在移动互联网时代,手机中的任何一款软件都可以上网,用户用浏览器用的少了。但其实手机app上网用的还是http协议
URL介绍
什么是互联网中的资源?什么是URL?
我们将互联网中的各种视频、图片、音频、文本文件统称为资源,每一份资源都有一个唯一的url将其在互联网中标识出来
URI、URL、URN三者概念
- URI是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
- URL是uniform resource locator,统一资源定位符,URL是URI的一种,即URL可以用来标识一个资源,而且还指明了如何locate定位这个资源。
- URN是uniform resource name,统一资源命名,也是一种具体的URI,通过名字来标识资源,比如mailto:javanet@java.sun.com。
URI、URL、URN三者区分
- URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI.
- URL是 URI 的子集。任何东西,只要能够唯一地标识出来,都可以说这个标识是 URI 。如果这个标识是一个可获取到上述对象的路径,那么同时它也可以是一个 URL ;但如果这个标识不提供获取到对象的路径,那么它就必然不是URL 。
举个粒子
- URI: /home/index.html
- URL: www.xxx.com:/home/index.html
浏览器中URL的格式是什么?
协议名+ : // + 服务器域名/服务器IP + 服务器端口号 + / + 资源在服务器上的路径
http://host[":"+port][abs_path]
-
http表示要通过HTTP协议来定位网络资源 -
host表示合法的Internet主机域名或者IP地址,本主机IP:127.0.0.1 -
port指定一个端口号,为空则使用缺省端口80 -
abs_path指定请求资源的URI,如果URL中没有给出abs_path,那么当它作为请求URI时,必须以"/"的形式给出,通常这个工作浏览器自动帮我们完成。
其中值得注意的是,上面的格式中有不少关键字是可以省略不写的,比如
- 服务器端口号就往往可以省略不写
- 因为访问服务器的端口号与协议是深度绑定的。如果采用的协议是HTTP,那么访问服务器的端口号一定是80。如果协议用的是HTTP,那么访问的端口号一定是443。
- 资源在服务器上的路径也可以省略不写
- 服务器在收到这种http请求时,就给客户端返回默认路径下的资源。如果URL中没有给出abs_path,那么当它作为请求URI时,必须以"/"的形式给出,通常这个工作浏览器自动帮我们完成,因此这个斜杠我们也可以不写
- 如果用户的URL没有指明要访问的某种资源(路径),虽然浏览器默认会添加"/",但依旧没有告知服务器要访问什么资源!此时,默认返回对应服务的首页!
OSI模型与TCP/IP模型
OSI模型,是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,将计算机网络通信划分为七个不同的层级,每个层级都负责特定的功能。每个层级都构建在其下方的层级之上,并为上方的层级提供服务。七层从下到上分别是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。虽然OSI模型在理论上更全面,但在实际网络通信中,TCP/IP模型更为实用。TCP/IP模型分为四个层级,每个层级负责特定的网络功能。
- 应用层:该层与OSI模型的应用层和表示层以及会话层类似,提供直接与用户应用程序交互的接口。它为网络上的各种应用程序提供服务,如电子邮件(SMTP)、网页浏览(HTTP)、文件传输(FTP)等。
- 传输层:该层对应OSI模型的传输层。它负责端到端的数据传输,提供可靠的、无连接的数据传输服务。主要的传输层协议有TCP和UDP。TCP提供可靠的数据传输,确保数据的正确性和完整性;而UDP则是无连接的,适用于不要求可靠性的传输,如实时音频和视频流。
- 网际层:该层对应OSI模型的网络层。主要协议是IP,它负责数据包的路由和转发,选择最佳路径将数据从源主机传输到目标主机。IP协议使用IP地址来标识主机和网络,并进行逻辑地址寻址。
- 网络接口层:该层对应OSI模型的数据链路层和物理层。它负责物理传输媒介的传输,例如以太网、Wi-Fi等,并提供错误检测和纠正的功能。此外,网络接口层还包含硬件地址(MAC地址)的管理。
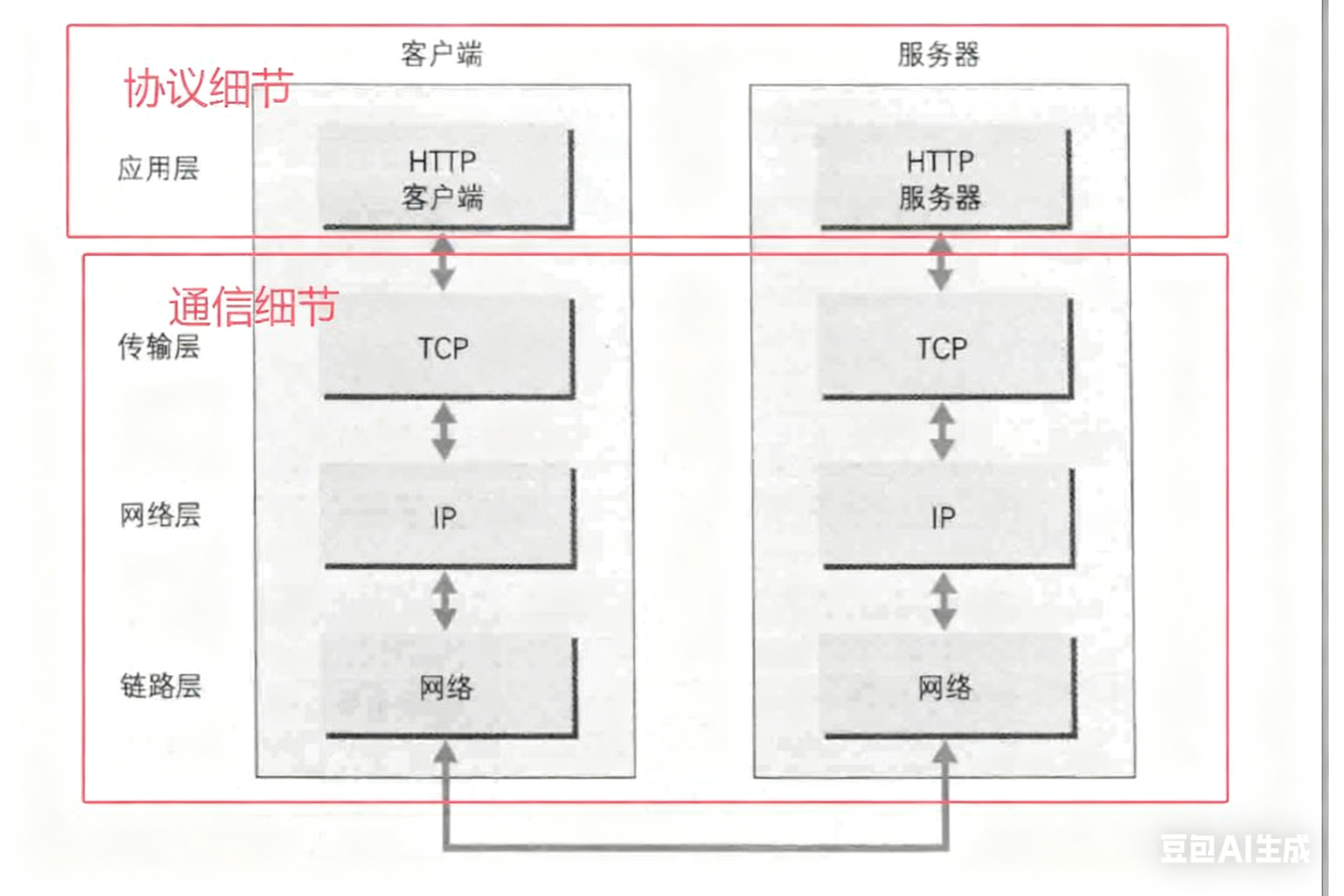
当互联网中的两台主机通过http协议进行通信时,应用层负责的工作是什么?应用层的下层负责的工作又是什么?
应用层的下层(包括传输层、网络层、数据链路层)负责的工作都是确保信息能够从一端完整、按序、及时地传输到另一端
而应用层就默认,双方都能拿到对方发来的数据,应用层负责将这些数据按照软件自定义的方式做进一步解析处理
什么是BS模型?
B就是browser,浏览器
S就是server,服务器
其实BS模型也叫做CS模型(客户端------服务器模型)
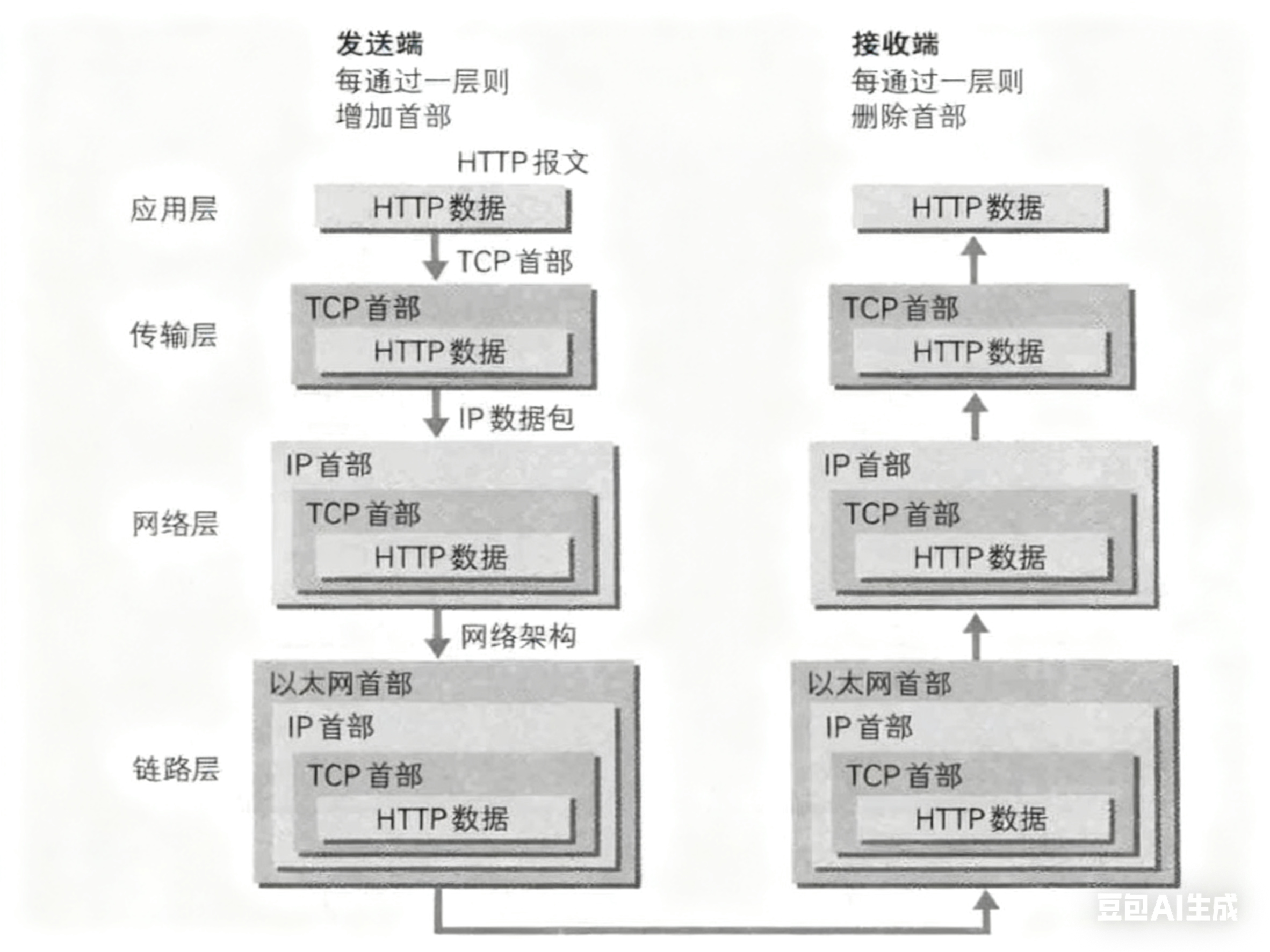
请你简单介绍一下在双端通信过程中数据的封装和解包过程
如何获取一个网站的IP地址?
cmd下输入指令 ping + 网址
浏览器网络中获取资源的过程
为什么要有域名呢?我们一般指定互联网中的一台主机,用的不都是IP地址吗?
IP地址无法做有效的分辨,而域名有很好的辨识度,更方便用户去分辨和记忆。比如182.61.200.108,给你这串数字,你啥都看不出来,但是你看www.baidu.com这串域名,你基本上就能看出这是什么网站
为什么浏览器中输入域名就可以访问对端服务器呢?具体的访问过程是怎样的呢?
网址输入进浏览器之后,浏览器首先会对URL进行解析,检查浏览器中是否缓存有该url标识的资源(如果之前请求过该资源,该资源就可能会缓存到浏览器中),如果有直接返回;如果没有,则需要通过网络获取
下面我们介绍浏览器从网络中获取资源的过程
1. DNS域名解析
什么是DNS域名解析?为什么要进行域名解析?
你要从网络中获取资源,肯定要先知道这个资源在互联网中的哪台服务器中存着(写信得先填地址)。这时候有人就说了,你域名不就能够定位一台服务器吗?没错,但是你信息在网络中传输,靠的是路由器给你转发。而路由器并不认得域名,你给他一个域名,他没法确定应该从哪个端口将你的IP数据报转发出去。而你给他一个IP地址,他就知道怎么给你转发。
因此我们在发起请求之前,必须要先根据资源所在网站的域名,得到资源所在服务器的IP地址,这一过程就叫做域名解析
如何进行域名解析?(域名解析的过程)
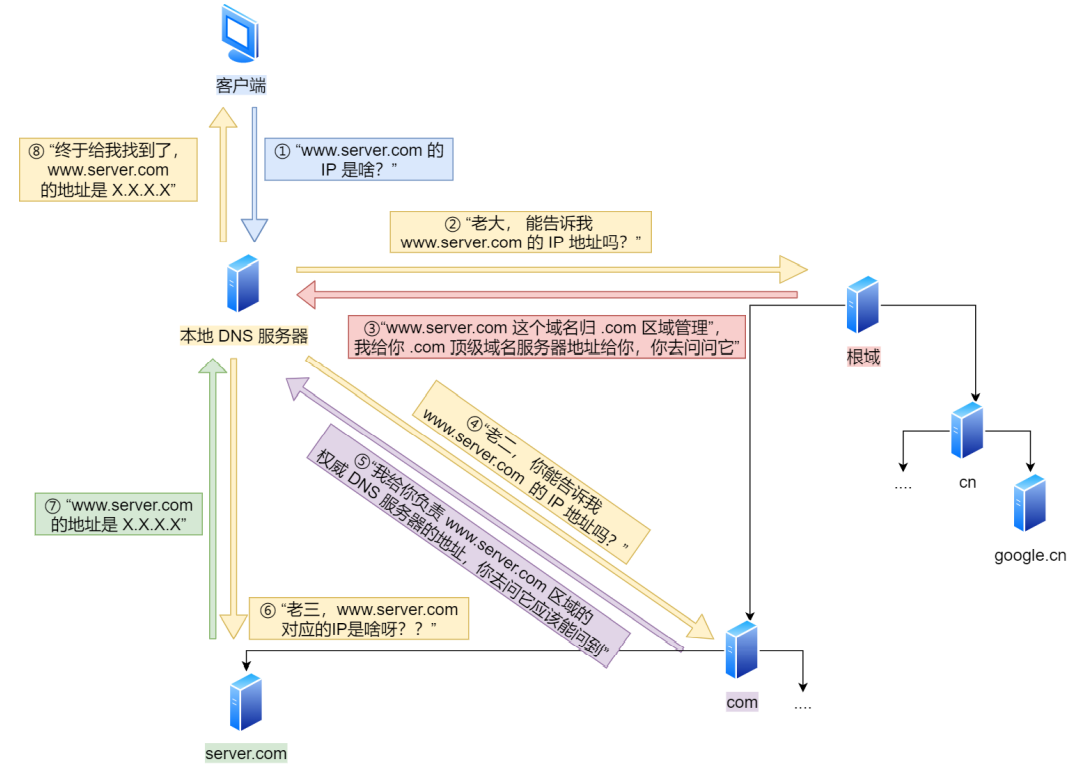
进行DNS域名解析时,首先我们会依次查询本地DNS缓存、本地HOST文件、路由器缓存,如果缓存中有对应的IP地址,则我们直接返回结果,就不用向DNS服务器请求了
如果本地缓存中没有,则浏览器会向先本地的DNS服务器(基本上都是中国移动提供的)发送一个DNS查询请求。如果本地DNS解析器有该域名的ip地址,就会直接返回,如果没有缓存该域名的解析记录,它会向根DNS服务器发出查询请求。
根DNS服务器并不能直接给出域名对应的IP,但它能告诉本地DNS服务器------接下来应该向哪个顶级域(.com/.net/.org)的DNS服务器继续查询。接着本地DNS服务器向着根域名服务器指定的顶级域名服务器发出查询请求。
顶级域DNS服务器也不负责具体的域名解析,但它能告诉本地DNS解析器应该前往哪个权威DNS服务器查询下一步的信息。本地DNS服务器会按照顶级域名服务器的指示,继续向顶级域名服务器指定的权威DNS服务器发送查询请求。
权威DINS服务器是负责存储特定域名和IP地址映射的服务器,也就是说向他查询是一定能查到的。当权威DNS服务器收到查询请求时,它会查找"example.com"域名对应的IP地址,并将结果返回给本地域名服务器。
本地DNS服务器将收到的IP地址返回给浏览器,并且还会将域名解析结果缓存在本地,以便下次访问时更快地响应
本地域名服务器返回的报文里面就存储着这个域名对应的IP地址,当浏览器收到这个报文,从里面解析出正文部分的IP地址时,DNS域名解析的过程就结束了
总结来说,DNS解析时会按本地浏览器缓存->本地Host文件->路由器缓存->本地DNS域名服务器->各级DNS域名服务器的顺序查询域名对应IP,直到找到为止。
2. 向资源所在的服务器发起三次握手,建立tcp链接
通过DNS协议拿到资源所在的服务器的ip地址之后,我们就可以根据这个ip地址向对方发起三次握手,请求建立tcp连接
3. 浏览器构建并发送http请求报文
连接建立后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的Cookie等数据附加到请求头中,向服务器构建请求信息。如果是HTTPS的话,还涉及到HTTPS的加解密流程。
4. 信息在网络中传输
构建好的请求报文经过一层层的封装,在网络中通过路由器一次又一次的路由转发,最终到达了资源所在的服务器,并被服务器成功接收
5.服务器接收到请求信息,根据请求生成响应数据
资源服务器在收到请求之后,会先对请求报文进行解析,看看这个请求的类型,请求的资源是什么,应该给他返回些啥东西。然后构建响应报文发回浏览器
6. TCP四次挥手断开连接
通信结束之后,浏览器向服务器发起四次挥手,与服务器IP断开TCP连接
7. 浏览器解析响应并渲染页面:
浏览器解析响应头。若响应头状态码为301、302,会重定向到新地址;若响应数据类型是字节流类型,一般会将请求提交给下载管理器;若是HTML类型,会进入下一部渲染流程。
浏览器解析HTML文件,创建DOM树,解析CSS进行样式计算,然后将CSS和DOM合并,构建渲染树;最后布局和绘制渲染树,完成页面展示。
http协议
http/1.0版本简单介绍
下面我们首先介绍一下http 1.0版本协议的一些基本特性
-
HTTP服务器的程序很简单,1000行以内就能写完,而且通信速度很快
-
支持传输任意类型的数据对象
比如:文本、图像、音频、视频、二进制文件等,正在传输的类型在http报文的Content-Type字段中加以标记
-
无连接(如何理解无连接?)
- 总结来说就是,HTTP协议中并没有与链接相关的规定(比如建立连接、维护链接、释放连接的规定)
- 通信之前建立链接是 TCP 协议的特点,而 应用层的HTTP协议对链接这个概念是没有感知的。他只是知道把 HTTP 请求交给下层协议,下层协议可以传送到对端,对端应用层根据HTTP协议将请求处理完毕之后,他只是知道将我的响应交给下层协议,协议中并没有连接相关的概念,无论是http/1.1还是1.0,他都是具有这样的特点。
- 因为我们传输层通过TCP协议进行数据传输之前,必须得先联立链接 ,而应用层通过HTTP协议进行数据传输之前,并不需要,这个工作交给下层协议去负责,我不用管这些,我只负责把数据封装打包交给我的下层协议,对方就能收到,对方也同样如此。这就叫做无链接。
- 每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,就会断开TCP连接。采用这种方式可以节省传输时间。(http/1.0具有的功能,http/1.1兼容)
-
无状态(如何理解无状态?)
- 所谓的无状态就是 HTTP 每一次发送一次请求到对方,那么对方并不会记录上这次请求是谁发的,同样的,我们的发送方他也不会记录说我曾经发送过这个请求
- 也就是双方在进行通信的过程中,在收到对方发来的HTTP报文之后,完全没有任何记录双方状态的动作
- 你同一台主机通过浏览器向同一个web服务器先后发送两次HTTP请求,服务器端在接收到第二次HTTP请求的时候,并不会把你认出来。即他并不知道你以前也向他发送过HTTP请求
- 在具体一点儿就是,你是一个b站的用户,你通过浏览器访问了B站的网页。第一次访问时你创建并登录了自己的账号。请问第二次你再通过这台电脑的这个浏览器访问b站的时候,HTTP协议会帮你自动登录吗?
答案是不会!你通过实践知道实际上第二次你会自动登录,但这个事情并不是HTTP完成的,而是由cookie和session来完成的
为什么http 1.0 要设置成无状态的?
http协议每当有新的请求产生,就会有对应的新响应产生。协议本身并不会保留你之前的一切请求或者响应,这是为了更快的处理大量的事务,确保协议的可伸缩性。
http协议如何记录用户的状态信息?
可是现在很多时候,用户就想让网站记住自己的账号和密码,以便自己下次再访问的时候,实现自动登录,这就与HTTP的无状态特性相矛盾了,对此我们应该如何处理呢?方法无非就两种
第一种方案:让HTTP 有状态,记录用户的状态信息(不合适)
目前的HTTP只负责 HTTP 请求的发送和response响应报文的处理,主要解决的是双方应用层通信的功能。而维护用户状态,它属于业务层次上的东西,如果把这个记录用户状态的功能集成在 HTTP协议中,会让 HTTP 的功能本身变得很臃肿,所以对我们来讲这个是不合适的
第二种方案: cookie 和 session 方案(现阶段采用的方案)
第二种就是我们现阶段所采用的方案叫做 cookie 和 session 方案,主流的一般是 session 加 cookie 两种方案。当你第一次登录的时候,那么我们的服务器端会为你形成一个 session ID,保存在你本地,从此往后每次通信时你都要携带这个ID。只要你向目标服务器发起请求时,请求报文属性当中包含这个session ID ,并且在被接收并解析时,服务器在session ID库中找到了这个ID,服务器就会把该ID历史上保存的状态信息都读取出来,这样就认得我们了
cookie和session 方案详细介绍
上面我们只是说了cookie和session 方案的大致 思路,下面我们要具体展开说一下。
(1)如何通过cookie和session机制记录用户状态?
光说太干了,下面我们来看俩例子
通过Cookie机制记录用户状态
- Set-Cookie(响应报头) :假如说客户端在服务器中完成了用户的注册,紧接着服务器向客户端发送回送报文时,会在响应头中携带
Set-Cookie字段:Set-Cookie: user_id=123; Path=/; Expires=Wed, 27 Sep 2025 10:00:00 GMT,将Cookie信息(如键值对、有效期、作用路径等)发送到客户端。客户端浏览器在收到之后就会将服务器发来的cookie存储在浏览器缓存中 - Cookie(请求报头) :客户端后续向服务器发送请求时,会在请求头中携带前面缓存下来的
Cookie字段,将之前存储的Cookie信息回传给服务器。例如:Cookie: user_id=123,服务器通过解析该字段就可以识别用户身份或状态
通过session机制记录用户状态
- 客户端在服务器中完成了用户的注册之后,服务器会为该用户生成一个Session ID,然后服务器会将该
Session ID写入回送报文的Set-Cookie报头 中(如Set-Cookie: JSESSIONID=abc123; Path=/),然后将响应报文发回客户端。客户端浏览器在收到响应报文之后,就会将服务器发来的Session ID存储在浏览器缓存中 - 客户端后续请求时,通过Cookie报头 携带
Session ID(如Cookie: JSESSIONID=abc123),服务器据此识别用户并关联对应的Session数据。
简言之,Cookie机制直接使用Set-Cookie(响应)和Cookie(请求)报头;Session机制则借助这两个Cookie报头来传递Session ID,间接实现用户状态记录。
(2)Cookie和Session的区别?
- 存储位置:Cookie 数据存储在用户的浏览器中,而 Session 数据存储在服务器上。
- 数据容量:Cookie 存储容量较小,一般为几 KB。Session 存储容量较大,通常没有固定限制,取决于服务器的配置和资源。
- 安全性:由于 Cookie 存储在用户浏览器中,因此可以被用户读取和篡改。相比之下,Session 数据存储在服务器上,更难被用户访问和修改。
HTTP请求报文和响应报文的格式分别是怎样的?
无论是请求报文还是响应报文,总体上都是由三部分构成,首部行+报头,然后是一个空行后面跟正文。对于请求报文是请求行+请求报头+空行再加请求正文。响应报文是状态行+响应报头+空行再加响应正文。
请求报文的请求行中记录请求方法、URI和HTTP版本号。响应报文的状态行中记录HTTP版本号、状态码和状态码描述。
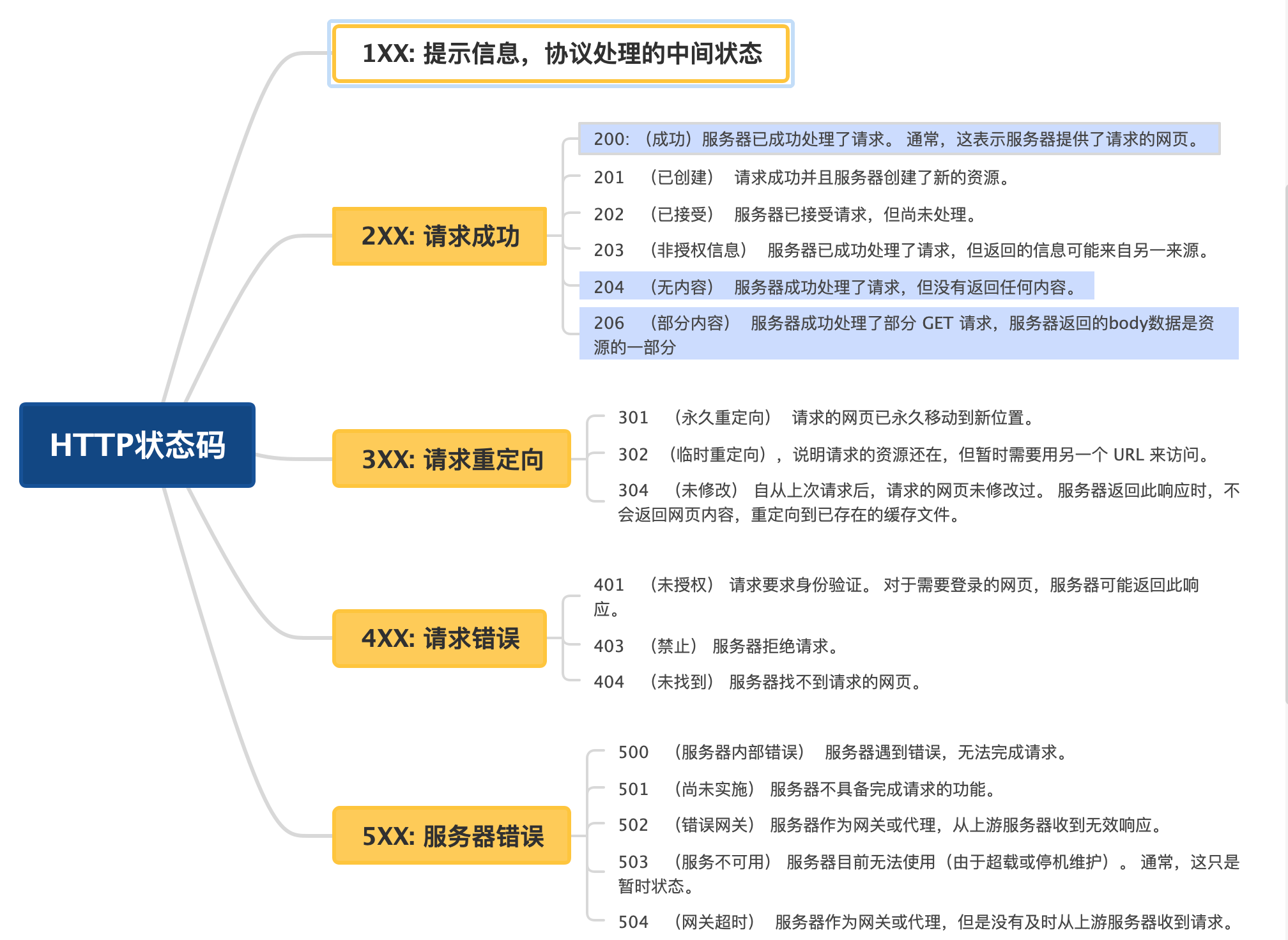
状态码
请求方法
用户的上网行为分析:目前所有的上网行为,宏观上,只有两种情况:
- 浏览器想从服务器拿下来某种资源(打开网页,下载等)
- 浏览器想把自己的数据上传至服务器
- 用户为什么要把自己的数据上传到服务器?
- 为了上传视频,登录,注册等,这就需要服务器对其上传上来的数据进行数据处理
在HTTP1.0版本中,只有三种请求方法
| 方法 | 功能描述 | 核心特性 |
|---|---|---|
| GET | 从服务器获取资源(如页面、图片) | 幂等(多次请求结果一致)、可缓存、请求参数拼接在URL中(有长度限制) |
| POST | 向服务器提交数据(如表单提交、上传文件) | 非幂等(多次请求可能产生不同结果)、请求数据放在请求体中(无长度限制,更安全) |
| HEAD | 与GET功能一致,但仅返回响应头,不返回响应体 | 用于快速获取资源的元信息(如文件大小、修改时间),不占用带宽传输体数据 |
HTTP/1.1在HTTP/1.0基础上对请求方法进行了很多扩展,共支持9种核心请求方法 (后续HTTP/2、HTTP/3均沿用这些方法,并没有继续新增请求方法):
| 方法 | 功能描述 | 幂等性 | 核心场景 |
|---|---|---|---|
| GET | 获取资源 | 是 | 浏览网页、查询数据 |
| POST | 提交数据(创建/修改资源) | 否 | 表单提交、文件上传、API数据提交 |
| HEAD | 获取资源响应头(无响应体) | 是 | 检查资源是否存在、获取文件大小 |
| PUT | 向服务器上传/替换资源(全量更新) | 是 | 接口中"更新资源"(如覆盖文件、全量修改用户信息) |
| DELETE | 请求服务器删除指定资源 | 是 | 接口中"删除资源"(如删除文件、删除用户) |
| CONNECT | 建立隧道连接(用于HTTPS) | 否 | 客户端通过代理服务器建立与目标服务器的TCP连接(如HTTPS的TLS握手前的隧道) |
| OPTIONS | 询问服务器对指定URL支持的请求方法 | 是 | 跨域请求(CORS)中"预检请求",确认服务器允许的方法/头信息 |
| TRACE | 回显服务器收到的请求,用于调试 | 是 | 测试网络链路是否正常(实际中因安全风险较少使用) |
| PATCH | 部分更新资源(增量更新) | 否 | 接口中"部分修改资源"(如仅修改用户的手机号,无需传全量信息) |
GET:请求url指定的静态网页资源
下面是一个具体的例子:客户端想从服务器获取一篇文章内容(ID 为 100),因此构建的GET请求报文如下:
GET /api/articles/100 HTTP/1.1
Host: blog.example.com #表明请求服务器的域名
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) Safari/605.1.15 # 记录客户端的主机信息
Accept: text/html,application/xhtml+xml # 告诉服务器,我客户端目前能够支持的响应报文数据格式
Accept-Encoding: gzip, deflate # 告诉服务器,我客户端能够支持的数据压缩方式
Connection: keep-alive # 告诉服务器我想建立一个长连接服务器将请求的资源写在正文中,返回的响应报文格式如下:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8 # 告诉客户端,我响应体中的数据格式
Content-Length: 2560 # 告诉客户端我响应体的长度
Last-Modified: Wed, 30 Jul 2025 10:30:00 GMT # 告诉客户端,他请求资源的最后修改时间
Cache-Control: max-age=3600 # 告诉客户端,一小时之内如果再次请求该资源,可以直接使用浏览器缓存副本,无需向服务器重新请求。
<!DOCTYPE html>
<html>
<head><title>HTTP请求方法详解</title></head>
<body>
<h1>GET与POST的区别</h1>
<p>...</p> <!-- 文章正文内容 -->
</body>
</html>POST:向服务器提交数据
POST常用于用户注册、提交表单、上传文件等需要用户上传数据的场景
比如客户端现在想注册一个新用户(用户提交表单),于是构建的POST请求报文如下:
POST /api/register HTTP/1.1
Host: user.example.com # 客户端请求服务器的主机域名
Content-Type: application/x-www-form-urlencoded # 告诉服务器,我请求报文正文部分的数据格式
Content-Length: 62 # 告诉服务器,我请求报文正文部分的数据长度
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/116.0.0.0 # 告诉服务器,客户端的主机信息
Accept: application/json # 告诉服务器,客户端支持的响应体格式
# 正文部分,里面记录的是此次注册的新用户的信息
username=johndoe&email=john@example.com&password=SecurePass123&age=28服务器端收到请求,并注册成功之后,构建对应的响应报文,告知客户端注册成功了
HTTP/1.1 201 Created
Content-Type: application/json
Content-Length: 98
Date: Thu, 31 Jul 2025 19:00:00 GMT
Set-Cookie: sessionid=abc123; HttpOnly; Path=/
{
"success": true,
"message": "用户注册成功",
"user_id": 5678,
"username": "johndoe"
}PUT:更新url指定的资源
PUT常用于更新用户的完整信息,修改文章的全部内容,或者覆盖服务器上的某个配置文件,下面是一个POST请求报文的示例
PUT /api/users/123 HTTP/1.1 # 请求行部分
#下面是请求报头
Host: example.com
Content-Type: application/json
Content-Length: 108
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
#下面是正文
{
"id": 123,
"username": "newname",
"email": "new@example.com",
"age": 30,
"status": "active"
}PATCH:对资源进行部分更新
举个例子:假设用户信息存储在服务器,原始数据如下
json
{
"id": 456,
"username": "oldname",
"email": "old@example.com",
"age": 25,
"address": "Old Street 123"
}现在我们只需要更新用户的邮箱和年龄,其他字段保持不变,此时适合使用 PATCH 请求,构建的PATCH请求报文如下
PATCH /api/users/456 HTTP/1.1
Host: example.com
Content-Type: application/json
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
Content-Length: 68
{
"email": "updated@example.com",
"age": 26
}服务器收到请求报文之后,对相应数据进行修改,返回修改之后的结果
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 220
Date: Thu, 31 Jul 2025 17:00:00 GMT
{
"id": 456,
"username": "oldname", // 未修改的字段保持不变
"email": "updated@example.com", // 已更新
"age": 26, // 已更新
"address": "Old Street 123", // 未修改的字段保持不变
"message": "用户信息部分更新成功"
}DELETE:删除url指定的资源
假设服务器上有一条 ID 为 789 的订单记录,现在需要删除该订单,此时适合使用 DELETE 请求,客户端构建DELETE请求报文如下
DELETE /api/orders/789 HTTP/1.1
Host: example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0.0.0 Safari/537.36
Connection: keep-alive服务器收到DELETE报文后,成功删除对应资源,并构建响应报文发送返回
HTTP/1.1 204 No Content
Date: Thu, 31 Jul 2025 18:00:00 GMT
Server: NginxHEAD:获取报文首部,不返回报文主体
服务器收到HEAD请求报文之后,并不会返回url指向的完整资源(并不会将请求的资源写入响应报文的正文部分),而是仅会将资源的基本信息(比如资源大小。资源修改时间等)写入响应报头中,正文空缺,然后直接发送返回。有人看到这个HEAD请求方法就比较奇怪,什么情况下只需要获取首部,不需要返回整个资源呢?请设想有下面的场景:某台服务器中有一个很大的资源,而用户只是想检查服务器中是否存在该资源,或者只是想获取资源的更新时间,并不想查看资源的具体内容,这种情况下服务器如果还按照GET请求去处理,直接传整个资源,就会极大地浪费网络资源,而引入HEAD请求方式之后,服务器构建的响应报文体积就很小,这样既提高了效率,也节省了带宽。
举例:比如说我们想检查一张图片是否存在,或获取其大小、修改时间(不下载图片本身),构建的HEAD请求报文如下:
HEAD /images/banner.jpg HTTP/1.1
Host: static.example.com
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 16_0 like Mac OS X)
Accept: image/jpeg,image/png
Connection: keep-alive如果请求的资源存在,服务器返回的响应报文如下:
HTTP/1.1 200 OK
Content-Type: image/jpeg
Content-Length: 204800
Last-Modified: Tue, 29 Jul 2025 15:45:00 GMT
Cache-Control: max-age=86400
ETag: "a1b2c3d4"OPTIONS:查询服务器支持的请求方法
举个例子:客户端希望了解服务器中/api/users 资源支持哪些 HTTP 方法(如 GET、POST 等),因此向服务器发送 OPTIONS 请求:
OPTIONS /api/users HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0.0.0 Safari/537.36
Connection: keep-alive服务器收到OPTIONS请求之后,返回的响应报文如下:
HTTP/1.1 200 OK
Allow: GET, POST, PUT, DELETE, OPTIONS
Content-Length: 0
Date: Thu, 31 Jul 2025 16:00:00 GMT不同请求方法的传参方式
不同的请求方法,传参方式也不相同
- 像GET、HEAD、OPTIONS、DELETE这些方法,都是采用URL传参
- 像POST方法,就是采用请求体传参
- 像PUT、PATCH方法,就是采用URL+请求体的方式传参
请求报头/响应报头的常见字段
HTTP报头分为请求报头 和响应报头,以下是各自的常见字段及说明:
一、请求报头常见字段
| 字段名 | 说明 | 示例 |
|---|---|---|
| Host | 指定请求的服务器域名(HTTP/1.1 必选) | Host: www.example.com |
| User-Agent | 客户端(浏览器/工具)的标识信息 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0 |
| Accept | 客户端可接收的响应数据格式 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
| Accept-Encoding | 客户端支持的压缩编码 | Accept-Encoding: gzip, deflate |
| Authorization | 身份认证凭证(如Token、Basic认证) | Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9... |
| Content-Type | 请求体的数据格式(仅带请求体的方法需用,如POST/PUT) | Content-Type: application/json Content-Type: application/x-www-form-urlencoded |
| Content-Length | 请求体的字节长度(仅带请求体的方法需用) | Content-Length: 128 |
| Cookie | 客户端存储的Cookie数据(用于会话管理) | Cookie: session_id=abc123; user_id=123 |
| Connection | 控制TCP连接(如keep-alive表示长连接) |
Connection: keep-alive |
| If-None-Match | 资源的ETag值(用于缓存验证,配合条件请求) | If-None-Match: "123456" |
| Origin | 跨域请求的源域名(CORS预检请求必带) | Origin: http://www.client.com |
二、响应报头常见字段
| 字段名 | 说明 | 示例 |
|---|---|---|
| Content-Type | 响应体的数据格式 | Content-Type: application/json; charset=utf-8 |
| Content-Length | 响应体的字节长度 | Content-Length: 256 |
| Server | 服务器软件标识 | Server: Nginx/1.21.0 |
| Set-Cookie | 服务器向客户端设置Cookie | Set-Cookie: session_id=xyz789; Path=/; Expires=Wed, 27 Sep 2025 10:00:00 GMT |
| Location | 重定向的目标URL(配合301/302状态码) | Location: https://www.new-example.com |
| ETag | 资源的实体标签(用于缓存和条件请求) | ETag: "789abc" |
| Last-Modified | 资源最后修改时间 | Last-Modified: Tue, 20 Sep 2025 09:00:00 GMT |
| Expires | 响应的过期时间(缓存控制) | Expires: Thu, 28 Sep 2025 12:00:00 GMT |
| Access-Control-Allow-Origin | 跨域资源共享(CORS)的允许源 | Access-Control-Allow-Origin: http://www.client.com |
| Cache-Control | 缓存策略(如max-age=3600表示缓存1小时) |
Cache-Control: max-age=3600, public |
这些字段覆盖了HTTP通信中"身份识别、数据格式、缓存控制、跨域安全、会话管理"等核心场景,是理解HTTP协议交互的关键要素。
GET请求和POST请求的区别
GET请求和POST请求的区别:
- 用途:GET请求通常用于获取数据,POST请求用于提交数据。
- 数据传输:GET请求将参数附加在URL之后,POST请求将数据放在请求体中。
- 安全性:GET请求由于参数暴露在URL中,安全性较低;POST请求参数不会暴露在URL中,相对更安全。
- 数据大小:GET请求受到URL长度限制,数据量有限;POST请求理论上没有大小限制。
- 幂等性:GET请求是幂等的,即多次执行相同的GET请求,资源的状态不会改变;POST请求不是幂等的,因为每次提交都可能改变资源状态。
- 缓存:GET请求可以被缓存,POST请求默认不会被缓存。
强缓存与协商缓存
在Web开发中,强缓存和协商缓存是浏览器缓存机制的两种核心方式,用于减少网络请求、提升页面加载速度并降低服务器压力。它们的主要区别在于判定资源过期的方式不同
- 强缓存策略的判断方式:客户端查看当前时间是否已经超过了资源的过期时间(做出判断的人是客户端)
- 协商缓存的判断方式:客户端向服务器发起请求,向服务器询问资源是否过期(做出判断的人是服务器)
1. 强缓存
强缓存策略指的是:当客户端收到请求的资源之后,会将该资源缓存到浏览器本地,并设定一个过期时间。在过期之前,如果用户通过浏览器再次请求该资源,我们就不用再通过网络向服务器请求该资源了,而是直接读取浏览器缓存,将该资源渲染成页面呈现给用户即可。
强缓存策略的实现方式:通过HTTP响应头中的 Expires 或 Cache-Control 字段控制。
(1)Expires(HTTP/1.0)
- 是一个绝对时间(GMT格式),表示资源的过期时间。
- 例如:
Expires: Wed, 28 Sep 2025 12:00:00 GMT - 问题:依赖客户端本地时间,如果客户端时间被修改,可能导致缓存失效或过期资源被误判为有效。(比如我是12点收到的数据,过期时间设置为当天18点。本来到17点时,该资源的有效时间就剩一个小时了,但是我在17点时修改了客户端的时间,把时间又调成了12点,这时候该资源的有效时间又变成4小时了)
(2)Cache-Control(HTTP/1.1,优先级更高)
-
使用相对时间(秒),优先级高于
Expires,解决了客户端时间偏差的问题。 -
常用指令:
max-age=3600:资源在3600秒(1小时)内有效。public:资源可被浏览器和中间代理服务器缓存。private:资源仅能被浏览器缓存(默认值)。no-cache:不使用强缓存,需强制进行协商缓存。no-store:完全不缓存资源(每次都请求服务器)。
-
示例 :
Cache-Control: max-age=3600, public表示资源1小时内有效,且可被代理服务器缓存。
2. 协商缓存
协商缓存策略是强缓存策略的补充:当强缓存失效(过期或未命中)时,浏览器会向服务器重新发起资源请求。服务器收到请求之后,首先会判断**服务器资源是否更新*
- 若未更新,服务器就不会返回请求的资源(因为这个资源在浏览器缓存中有,只是过期了),而只会返回304状态码,意思是重定向到浏览器缓存中的资源,让浏览器修改一下过期时间,继续使用本地缓存的资源
- 若已更新,服务器就会返回200状态码和新资源
实现方式:通过 Last-Modified/If-Modified-Since 或 ETag/If-None-Match 字段配对使用。
(1)Last-Modified 与 If-Modified-Since策略
Last-Modified字段用来记录资源最近一次修改的时间- 比如
Last-Modified: Wed, 27 Sep 2025 10:00:00 GMT表示最近一次修改的时间是今天早上10点 - 服务器每次向浏览器返回资源时,都会在响应报文的
Last-Modified字段中给出返回资源的当前版本
- 比如
If-Modified-Since用来向服务器询问资源的某个时间版本是否是该资源的最新版本。- 比如当缓存过期后,浏览器在请求头中携带
If-Modified-Since: Wed, 27 Sep 2025 10:00:00 GMT - 这其实就是在询问服务器在
Wed, 27 Sep 2025 10:00:00 GMT时间后是否又对资源做过更新操作,也可以理解成问资源在Wed, 27 Sep 2025 10:00:00 GMT这个时间的版本是不是该资源的最新版本
- 比如当缓存过期后,浏览器在请求头中携带
带有If-Modified-Since:字段的请求报文被服务器接收之后,服务器会去查看请求报文中URL指向的资源版本,然后将当前版本与请求报文If-Modified-Since:字段中的版本号进行对比
- 若相同,说明资源未修改,服务器返回
304 Not Modified(不返回资源内容)。 - 若不相同,说明资源已修改,返回
200 OK和新资源,在响应报文的Last-Modified中给出该资源最新的版本号
Last-Modified 与 If-Modified-Since策略的局限性:
- 只能精确到秒级,若资源在1秒内多次修改,无法识别。
- 某些操作(如文件重命名但内容不变)会导致时间变化,但实际内容未改,会误判为更新。
(2)ETag 与 If-None-Match策略(优先级更高)
ETag字段中记录的是一个由资源内容映射得到的哈希值。- 当资源被修改时,资源的内容就发生了变化,那由资源内容映射得到的哈希值也会发生变化,
ETag字段的值就会变化。
- 当资源被修改时,资源的内容就发生了变化,那由资源内容映射得到的哈希值也会发生变化,
If-None-Match字段用来询问服务器当前ETag是否与If-None-Match字段中的值一致。- 比如缓存过期后,请求头携带
If-None-Match: "abc123",就是询问服务器当前资源的ETag是否是"abc123"
- 比如缓存过期后,请求头携带
浏览器会将本地缓存的资源的ETag 值写入请求报文的 If-None-Match字段中,用来询问服务器资源当前的ETag 有么有更新。请求报文发出后没过一会,服务器就会收到请求报文,然后就会去检查资源当前的ETag值和请求报文If-None-Match字段中的值是否一致
- 若服务器ETag一致(资源未变),返回
304 Not Modified,告诉浏览器资源没有更新,接着用你本地缓存就行 - 若ETag不一致(说明资源已变),服务器会返回
200 OK和新资源,并将该资源最新的ETag写入响应报文的ETag字段中发回浏览器
优势:
- 能识别秒级内的内容变化,精度更高。
- 不受文件修改时间影响,仅基于内容判断
- 如果资源仅仅是修改时间更新,内容没有更新,那其实实际上是没必要更新的,但是这种情况如果按照
Last-Modified与If-Modified-Since策略,服务器是会重发一遍 资源的,这就造成了带宽资源的浪费 - 此时如果采用
ETag与If-None-Match策略,就不用更新了
- 如果资源仅仅是修改时间更新,内容没有更新,那其实实际上是没必要更新的,但是这种情况如果按照
3. 缓存流程总结
- 浏览器请求资源时,先检查强缓存 :
- 若未过期,直接使用本地缓存(状态码:
from memory cache或from disk cache)。 - 若已过期,进入协商缓存流程。
- 若未过期,直接使用本地缓存(状态码:
- 协商缓存阶段,浏览器携带缓存标识(
If-Modified-Since或If-None-Match)向服务器请求:- 服务器判断资源未更新:返回
304,浏览器使用本地缓存。 - 服务器判断资源已更新:返回
200和新资源,浏览器更新缓存。
- 服务器判断资源未更新:返回
4. 应用场景
- 强缓存 :适合静态资源(如图片、CSS、JS),通过设置较长的
max-age减少请求。 - 协商缓存:适合频繁更新的资源(如HTML页面),确保用户获取最新内容的同时,减少不必要的资源传输。
通过合理配置两种缓存策略,可显著提升Web性能和用户体验。
HTTP1.0和HTTP1.1的区别
HTTP2.0和HTTP1.1的区别
HTTP3.0的特点
如何用VScode远程连接 SSH 服务器?
https://blog.csdn.net/qq_42417071/article/details/138501026
项目内容
项目文件构成简单介绍
-
在linux家目录下创建一个项目目录HTTP
-
在项目目录中创建TcpServer.hpp(该文件用于TCP连接的管理)
- hpp后缀的文件有什么特点?
- 这种文件通常是将C++中类的声明与具体成员函数实现的代码写在一起,比较适合于源代码公开的项目
-
vim TcpServer.hpp
TcpServer类的框架
socket地址重用问题
什么是socket地址重用?
就是你调用setsockopt函数,启用 SO_REUSEADDR 选项,就可以允许在同一端口上多次绑定套接字(这就是socket地址重用)
为什么要socket地址重用?如何实现socket地址重用?
现在我有一个问题,如果一台服务器上同时维持着两千个TCP连接,这时候第2001台主机连上了服务器,此时服务器崩了,此时很有可能服务器无法立即重启,这是为什么?在双十一时间段内,1s内就有可能发生成千上万单的交易,我是不可能等的!所以我怎样才能让服务器立即重启呢?
- vim HttpServer.hpp
1
pthread_create(&tid, nullptr, Entrance::HandlerRequest, _sock);这里传参时最后为什么不能直接传&sock,而是要拷贝一份之后再传指针呢?
(1)生命周期问题:
sock 是一个局部变量,它的生命周期仅限于定义它的代码块。当主线程中的代码块执行完毕后,sock 会被销毁,其占用的内存空间会被释放。 而新创建的线程可能在主线程的代码块执行完毕之后才开始访问 &sock 指向的内存。此时,&sock 指向的内存已经被释放,新线程访问这块内存会导致未定义行为,例如读取到无效的数据或者引发段错误。
(2)多线程并发问题:
在多线程环境下,如果多个线程同时使用同一个局部变量的地址,会导致数据竞争问题。假设在一个循环中不断接受新的连接并创建新线程:当新线程还未开始访问 &sock 时,主线程可能已经接受了下一个连接,sock 的值会被更新。这样,新线程最终访问到的 sock 值可能不是它应该处理的连接的套接字描述符。
- vim Makefile
1
文本
bin=HttpServer
cc=g++
LD_FLAGS=-std=c++11 -lpthread
src=main.cc
( b i n ) : (bin): (bin):(src)
(cc) -o @ \^ (LD_FLAGS)
.PHONY:clean
clean:
rm $(bin)
bin=httpserver:定义了最终生成的可执行文件名,这里指定为 httpserver。
cc=g++:指定了用于编译的编译器,这里使用的是 g++,即 GNU C++ 编译器。
LD_FLAGS=-std=c++11 -lpthread:定义了链接器的参数。-std=c++11 表示使用 C++11 标准进行编译;-lpthread 表示链接 pthread 库,用于支持多线程编程。
src=main.cc:指定了项目的源文件,这里只有一个 main.cc 文件。
( b i n ) : (bin): (bin):(src):这是一个规则,目标是 (bin)(即可执行文件 httpserver),依赖是 (src)(即源文件 main.cc)。表示当目标文件不存在,或者依赖文件比目标文件新时,需要执行下面的命令来构建目标。
(cc) -o @ \^ (LD_FLAGS):这是构建目标的命令。
$(cc) 会被替换为之前定义的 g++。
-o @ 表示指定输出文件, @ 表示指定输出文件, @表示指定输出文件,@ 是一个 Makefile 内置变量,代表当前规则的目标文件名,即 httpserver。
$^ 也是 Makefile 内置变量,代表当前规则所有的依赖文件,这里就是 main.cc。
$(LD_FLAGS) 会被替换为之前定义的链接器参数 -std=c++11 -lpthread。
g++ -o httpserver main.cc -std=c++11 -lpthread
.PHONY:clean:声明 clean 是一个伪目标。伪目标不对应实际的文件名,主要用于定义一些执行特定操作的命令集合,避免与同名文件冲突导致规则不生效。
clean::定义了 clean 目标的规则。
rm ( b i n ) : c l e a n 目标对应的命令,作用是删除之前定义的可执行文件 h t t p s e r v e r ( (bin):clean 目标对应的命令,作用是删除之前定义的可执行文件 httpserver( (bin):clean目标对应的命令,作用是删除之前定义的可执行文件httpserver((bin) 会被替换为 httpserver)。当在命令行执行 make clean 时,就会执行这条命令来清理生成的可执行文件。
整体命令的作用是使用 g++ 编译器,根据 C++11 标准并链接 pthread 库,将 main.cc 编译并链接生成 httpserver 可执行文件。
2:lesson 27 20:00
这个版本增加的内容其实就是:
加上了test_cgi的编译,一次make,多生成了一个目标文件
以及新增加了一个output功能
你命令行输入make output,系统就会自动帮我们把可执行文件http_server和test_cgi,还有wwwroot目录下的所有文件,都拷贝一份到output目录下
原文
bin=httpserver
cgi=test_cgi
cc=g++
LD_FLAGS=-std=c++11 -lpthread
curr= ( s h e l l p w d ) s r c = m a i n . c c A L L : (shell pwd) src=main.cc ALL: (shellpwd)src=main.ccALL:(bin) $(cgi).
PHONY:ALL
( b i n ) : (bin): (bin):(src)
(cc) -o @ $^ ( L D F L A G S ) (LD_FLAGS) (LDFLAGS)
(cgi):cgi/test_cgi.cc
(cc) -o @ $^.
PHONY:clean
clean:
rm -f (bin) (cgi)
rm -rf output
.PHONY:output
output:
mkdir -p output
cp $(bin) output
cp -rf wwwroot output
cp $(cgi) output/wwwroot
变量定义
bin=httpserver :
定义最终可执行文件名为 httpserver。
cgi=test_cgi :
定义CGI 程序名为 test_cgi。
cc=g++ :
指定使用 g++ 编译器来编译代码。
LD_FLAGS=-std=c++11 -lpthread :
设置链接选项,指定使用 C++11 标准,并链接线程库(用于支持多线程)。
curr=$(shell pwd) :
通过 shell 命令获取当前工作目录,并赋值给变量 curr。
指定主源文件为 main.cc。
构建目标
ALL 目标
ALL:(bin) (cgi)
表示 ALL 目标依赖于 httpserver 和 test_cgi 这两个可执行文件的构建。
.PHONY:ALL
声明 ALL 为伪目标,不对应实际文件。.PHONY的作用就是防止编译器偷懒,无论之前目标文件是否生成过,你都得给我重新生成一遍
$(bin) 目标(即 httpserver )
( b i n ) : (bin): (bin):(src)
表示 httpserver 可执行文件依赖于 main.cc 源文件。
(cc) -o @ \^ (LD_FLAGS)
这条命令使用 g++ 编译器,根据链接选项,将 main.cc 编译并链接成名为 httpserver 的可执行文件。其中 @ 代表目标文件( h t t p s e r v e r ), @ 代表目标文件(httpserver), @代表目标文件(httpserver),^ 代表所有依赖文件(main.cc )。
$(cgi) 目标(即 test_cgi )
$(cgi):cgi/test_cgi.cc
表明 test_cgi 可执行文件依赖于 cgi/test_cgi.cc 源文件。
(cc) -o @ $^ 用 g++ 编译器将 cgi/test_cgi.cc 编译成 test_cgi 可执行文件。
清理目标
clean 目标
.PHONY:clean 声明 clean 是伪目标。rm -f (bin) (cgi) 用于删除 httpserver 和 test_cgi 这两个可执行文件;rm -rf output 用于递归删除名为 output 的目录及其内容,用于清理构建产生的文件。
输出目标
output 目标
.PHONY:output 声明 output 为伪目标。
mkdir -p output 创建名为 output 的目录(如果不存在),-p 选项确保父目录不存在时也能一并创建。
cp $(bin) output 将 httpserver 可执行文件复制到 output 目录。
cp -rf wwwroot output 将名为 wwwroot 的目录及其内容递归复制到 output 目录。
cp $(cgi) output/wwwroot 将 test_cgi 可执行文件复制到 output/wwwroot 目录下 。 主要用于整理和部署构建生成的文件到指定目录。
3.最终版本(到这里有人就会问,你这CGI多出来的这个";"是啥意思啊?)
豆包解释
在 Makefile 中加 \ 是为了实现续行 。Makefile 语法要求命令行必须以制表符 \t 开头,并且默认一行就是一条完整命令。当一条命令过长,需要换行书写时,就使用 \ 来告诉 Make 工具,这行还未结束,下一行内容和本行是同一条命令。
在你提供的代码中:
cd $(curr)/cgi;\ 这里的 \ 表示该命令未结束,下一行内容与之是一体的。
make clean;\ 同理, \ 表示命令延续到下一行 。
cd -;\ 也是利用 \ 实现换行书写命令,保证这三条命令在逻辑上各自完整,同时在格式上可以分行显示,增强代码可读性。
如果不加的话,我们make没法成功,就像下图这样会一直Make刷屏,加了之后就成功了
- vim protocol.hpp
这个文件专门用来解析http报文,并对报文的要求做出响应
8.vim util.hpp
这个文件专门用来实现一些与通信弱相关的功能
9.vim Log.hpp
为什么要写日志?
通过日志,我们可以实现,只要对面向我发出了链接请求,并且我完成了某个特定的步骤,我就可以在我服务器的终端看到对应的日志信息,类似于这样
目标:
日志级别:
info表示正常级别
warning表示报警基本
erro表示错误级别
fatal表示致命错误(最高级别)
代码实现
请问图中为什么要有#define LOG这一行的代码?直接用Log函数不是挺好的吗?
图中 #define LOG(level, message) Log(#level, message) 这行代码的作用主要有以下几点:
-
简化代码书写
定义了一个宏 LOG 后,在后续代码中就可以使用 LOG 来替代更复杂的函数调用形式。比如当想要记录日志时,只需写 LOG(INFO, "This is an info message") ,而不需要每次都完整写出 Log("INFO", "This is an info message", FILE , LINE ) (这里 FILE 和 LINE 是预定义宏,分别表示当前源文件名和行号,图中代码虽未完整体现,但实际日志函数常需这些信息 )。这样能减少代码冗余,让代码书写更简洁直观,提高编码效率。
-
实现参数字符串化
宏定义中的 #level 实现了参数的字符串化操作。当调用 LOG(INFO, "message") 时,#level 会将 INFO 转换为字符串 "INFO" 。这使得在日志记录函数 Log 中能方便地处理日志级别字符串,确保日志级别能以正确的字符串形式输出或用于后续处理。
-
便于代码维护和修改
如果后续需要对日志记录的逻辑或参数传递方式进行修改,只需要在 #define LOG 这一处宏定义进行调整,而不需要在所有调用日志记录的地方逐个修改。例如,如果要在日志记录时添加更多参数或修改参数的传递顺序,修改宏定义即可,增强了代码的可维护性。
写好Log.hpp之后,我们就可以在其他文件的某些关键位置上添加log(),比如
项目核心问题
信息的读取与发送流程如下:
1.main函数创建并初始化出一个制定端口号的http_server对象
创建httpserver对象的构造函数如下
http_server的初始化函数如下
TcpServer::getinstance定义如下,其实我们可以看到getinstance的工作就是创建一个单例,并完成单例的初始化。
创建TCPserver对象的构造函数如下
TcpServer::InitServer()的定义如下,干的活就是完成监听套接字的创建、绑定,并将创建出来的套接字设置为监听状态
Socket函数用来创建一个监听套接字
Bind函数用来将Socket中创建好的监听套接字和本次通信的对端套接字绑定在一起
Listen函数用来让我们server端的监听套接字处于监听状态
2.main函数调用HttpServer::loop()
3.LOOP中获取监听套接字,然后调用accept从监听套接字listen_sock的请求队列中取出一个请求,然后专门创建一个线程用于处理这个请求,accept返回的这个套接字sock从此之后就和这个请求深度绑定了,它就是我们本地进程与对端主机沟通的桥梁,我们往后想向对端发送数据,其实就是执行语句send(sock, ...),我们接收对端发来的数据,其实就是调用recv(sock,...)
4.业务核心逻辑
1.读取http请求报文的请求行和报头
RecvHttpRequestLine从接受缓冲区中读取请求行数据,将数据读到http_request.request_line中
这个函数通过recv从接收缓冲区中读取一行的数据(为什么不直接用getline或者gets读?)
为什么不能直接用这份代码读取请求?
因为buffer的大小有限,并不能保证把一个http报文读完,这就很有可能会出现数据粘包的问题
为什么不能用C/C++提供的gets或者getline这样的库函数来按行读取?
因为在不同系统中的换行符(行分隔符)有可能是不一样的,这就要求我们在做数据读取时,要兼容各种行分割符,但是getline的默认行分隔符只有\n,所以不能直接用
#ifdef DEBUG是啥意思?
我们可以通过在gcc编译时-DDEBUG来加一个debug选项,让编译器在编译时编译这块内容
#ifdef DEBUG 是 C/C++ 语言中的预处理指令,属于条件编译的范畴,作用是根据是否定义了名为 DEBUG 的宏来决定是否编译特定代码块。具体解释如下:
预处理阶段,编译器会先处理预处理指令。#ifdef 指令会检查指定的宏(这里是 DEBUG )是否已经被定义。如果 DEBUG 宏已经通过 #define 指令定义过了(例如 #define DEBUG ),那么 #ifdef DEBUG 与 #endif 之间的代码会被保留并参与后续编译;如果 DEBUG 宏未被定义,这部分代码就会在编译过程中被编译器忽略,不参与实际编译。
调试代码:在开发过程中,开发者常使用 #ifdef DEBUG 来包裹调试相关代码,如添加输出调试信息的语句(像打印变量值、函数执行流程等 )。开发阶段定义 DEBUG 宏(如在代码开头添加 #define DEBUG ),就能让调试代码参与编译运行,方便排查问题。程序发布时,去掉 DEBUG 宏定义,调试代码就不会被编译进最终程序,避免多余代码影响性能或暴露内部信息。例如在前面提供的代码中,DEBUG 宏定义下的代码通过 recv 接收数据并打印,用于测试调试,非调试阶段就不会编译执行。
条件化编译不同版本代码:可以根据不同需求,通过宏定义决定编译哪部分代码。比如针对不同平台、不同功能模式等编写不同代码实现,用条件编译指令按需编译。
通过recv中的MSG_PEEK选项,窥探接收缓冲区中的第一个字符
RecvHttpRequestHeader从接受缓冲区中读取请求报头,将数据读到http_request.request_header中
2.解析http请求报文:将一份http请求报文对应的一大长串字符串信息转化成http_request对象中的各种属性信息,写入http_request各字段中
ParseHttpRequestLine():从http_request.request_line中读取请求方法、uri和版本号
ParseHttpRequestHeader():从http_request.request_header中读取各字段的信息,将这些信息从vector中提取出来,以kv的形式存储在map当中
RecvHttpRequestBody():通过recv将接收缓冲区中的正文数据读取到http_request对象的request_body中
3.构建http响应报文:
原码
构造响应报文之前,我们要思考一个问题,就是我们应该给客户端返回什么?
答案是返回客户端在请求报文中请求的资源
那么问题又来了,我服务器这里确实有很多资源,但我怎么知道他请求的是哪一个资源呢?
答案就是,在客户端发来的http请求报文中,里面给出了请求资源在服务器中的路径地址,服务器根据这个地址去自己的文件目录中检索,就可以找到客户端想要请求到的资源
现在问题又来了,如何获得请求报文中给出的请求资源地址呢?
答案就藏在http请求报文第一行(请求行)中的uri字段中
如果请求方法是POST,那么uri就是我们要求的资源地址
如果请求方法是GET,那么uri的前半段就是我们要求的资源地址(后半段是有可能是上传的数据,前后用符号&隔开)
在完全解决上一个问题之后,我们拿到了请求资源的路径信息,请问我们如何才能知道,这个路径信息是否有效呢?
什么叫做有效的路径信息?
我服务器拿着这个路径信息去检索,发现没有检索到路径中指明的那个文件,或者在我的服务器中压根就不存在这条路径,那我们就称这个路径信息是无效的,反之,就是有效的
如何才能知道,这个路径信息是否有效呢?
我们的解决方法是采用stat函数,读取http_request.path指向文件的属性信息
如果返回值为0,说明成功读取,那么这个文件就是真实存在的
如果返回值为-1,说明调用失败,文件不存在
在解决上一个问题之后,我们默认这时候已经拿到了客户端请求资源的地址,并且这个地址是有效的,那我们就知道我们应该给客户端返回啥了。这时候就有一个问题:
就是如果用户请求的是一个静态网页,那我直接给他返回对应html文件就行了
但如果用户请求报文中含有用户上传上来的数据,他想让我帮他处理这个数据,返回对应的结果,那问题就变复杂了,我们就用cgi机制来解决,子进程执行完毕之前,会将处理结果写入管道,父进程将数据从管道中读出之后再写在response_body中
下面我们就可以调用BuildHttpResponseHelper构造响应报文了(注意:BuildHttpResponseHelper只负责构造状态行和响应报头,正文部分因为没有固定的格式,我们在最后SendHttpResponse()中单独处理)
在前面process函数处理结束的时候,都会将任务处理的状态码写入http_response.status_code中,后面我们在调BuildHttpResponseHelper的时候,就能直接通过http_response.status_code获得前面请求处理的状态码了
在BuildHttpResponseHelper中,我们首先构建响应报文的状态行(因为不同状态码的处理流程是一样的),然后再根据不同的状态码填写不同的响应报头
状态码为200=OK时的响应报头构建
其他异常状态码的响应报头构建
4.发送http响应报文:调用send函数,将响应报文发送给客户端
一条http请求报文的生命周期
首先就是客户端向服务器发送连接请求,通过三次握手建立起TCP连接
然后客户端构建好http请求报文,调用send之后,操作系统会自动将该请求发送到服务器端(这里的自动是什么意思?)
用户层调用send函数,将报文从用户缓冲区发送到内核中的发送缓冲区后,操作系统会自动将发送缓冲区中的http请求报文进一步封装,然后发送到服务器端,服务器端的操作系统也会自动将受到的报文一步步解封,剥到最后就剩http请求报文了,将其放入内核区的接受缓冲区中,这个过程用户层就不用问了
服务器端受到这条请求报文之后,会将该请求报文插入到监听套接字的请求队列中
然后服务器端调用accept,创建出一个新线程,专门用于处理该请求,同时accept也会为将该请求放到一个专门的小缓冲区中,这个缓冲区中所有的请求报文都是来自同一台主机,这就是accept的返回值对应的接收缓冲区
背后干的事情就相当于,把该http请求报文读到了文件fd中,这个文件fd也就是我们后面理解的server端接收缓冲区
因为你listen_sock对应的接收缓冲区中,有很多来自不同客户端的请求,但是通信肯定是只能1对1的,所以我就要把这个大接受缓冲区中的报文,按照发送方分成一个个的小接收缓冲区,每个小缓冲区中,发送方都是同一个客户端,每个小缓冲区也都有一个对应的文件描述符fd
那这个fd是不是就是accept的返回值呢?答案不是,原因是accept的返回值是一个套接字描述符,套接字不仅要负责接收这个客户端的数据,还要负责向客户端发送数据,因此一个套接字,至少就要对应两个缓冲区(一个接受缓冲区,一个发送缓冲区)
我们将上面accept的返回值记为sock,然后我们程序中调用recv(sock, ...),就可以从缓冲区中把请求报文读上来了,读上来之后我们分析分析,生成对应的响应报文,调用send(sock,...)就可以把响应报文发回去了
差错处理的实现
服务器处理http请求的时候,错误的类型有哪些,我们分别应该如何处理?
1.读取错误
什么叫做读取错误?
服务器没能从接收缓冲区中读取到一份完整的http请求报文
读取是否完毕?不一定
对于这种错误 我们可以不给对方回应,直接终止处理进程,退出即可!
读取差错处理
如果读取出错,就很省事,因为我们就不再需要返回响应报文了
为此我们在类中引入一个变量stop,如果我们读取出错,就将stop置1
stop一旦置1,我们构建和发送响应报文的任务就不用做了
2.逻辑错误
什么叫做逻辑错误?
数据从接收缓冲区中成功读取出来,但是在处理数据的过程中出现了逻辑错误(比如404,500等)
对于这种错误,我们是一定要给客户端回送一个响应报文的
逻辑差错处理
什么叫做逻辑差错?
就是你http请求报文顺利地从接受缓冲区读到了用户缓冲区中,但是你后续做数据处理的时候出错了,比如404/500等错误
如何判断数据处理process过程中是否出现了差错?
根据ProcessNonCgi或ProcessCgi返回值来判定
因为我们的状态码HttpResponse::status_code默认就是OK
主要就是看ProcessNonCgi和ProcessCgi执行过程中是否会把status_code改成非正常的状态码(中间出现一些差错,就有可能会改,比如:
ProcessNonCgi或ProcessCgi执行完毕之后,会返回一个状态码,如果中间一切正常,这个返回的状态码就是OK,如果不正常,就返回其他状态码
差错处理与正常处理有什么不同?
差错处理与正常处理的响应报文,从状态行、响应报头到正文都不一样
差错响应报文的状态行、响应报头该怎么构建?
差错响应报文的正文该怎么构建?
我们会在这里打开对应的差错html文件,并将打开的文件描述符写入http_response.fd中
再在最后的sendfile中将这个文件直接送往发送缓冲区,之后再关闭这个文件
3.写入错误
什么叫做写入错误?
就是我服务器端向发送缓冲区中写入数据时,没能成功写入
如何处理写入错误?
在InitServer()时调用signal函数,将当前进程收到信号SIGPIPE之后的处理方式设置忽略即可(没错,就这一步,没有其他步骤了,这就处理完了)
signal(SIGPIPE, SIG_IGN);
为什么要这么做?这么做咋就把写入错误给处理了呢?
当对端关闭连接之后,那边的操作系统会通知你这边的操作系统,然后你这边的操作系统就会向当前进程发送信号SIGPIPE
当前进程收到信号SIGPIPE之后就会被终止,
但我们不想让httpserver进程直接终止,我们还想让它继续开着,接收新的请求
所以我们就需要对这个信号进行忽略,就算对面关了,给我发了这个信号,我也不搭理你,我该写啥还写啥,能写多少是多少
如果不忽略,在写入时候,server可能直接崩溃
构建响应
接口sendfile介绍
为什么要引入sendfile?
注意看下面的图,原本如果我们想将一份磁盘中的数据发送出去,应该先将数据从磁盘读到内核缓冲区,再读到用户缓冲区,再从用户缓冲区读到内核缓冲区,再读到网卡中发送出去
现在引入sendfile之后,可以将这份数据从磁盘读到内核缓冲区之后,下一步直接从内核缓冲区读到网卡中,省去了中间用户层传输的步骤,节省了时间
接口sendfile介绍
sendfile 是 Linux 系统提供的一个系统调用函数,定义在 <sys/sendfile.h> 头文件中,常用于实现零拷贝技术,减少数据在内存之间的拷贝次数以及 CPU 在数据传输过程中的参与度,提升网络性能。
使用格式
#include <sys/sendfile.h>ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
参数说明
out_fd:输出文件描述符 ,数据将被发送到这个描述符所代表的目标位置。在网络传输场景中,通常是已连接的套接字描述符,用于将数据发送到网络连接对端。从 Linux 2.6.33 开始,也可以是任意文件描述符,使应用场景更广泛,不限于网络传输,也可用于本地文件拷贝。
in_fd:输入文件描述符 ,数据从这个描述符对应的文件中读取。必须是支持类似 mmap 函数的文件描述符,即指向真实存在的文件,不能是 socket、管道等其他类型的文件描述符,决定了 sendfile 主要用于从文件读取数据并传输的场景。
offset:指定从读入文件流的哪个位置开始读取数据。若设置为 NULL,则使用读入文件流的默认起始位置,即从文件开头读数据。在需随机访问文件特定位置数据传输的场景中,可通过设置该值精准读取和传输数据。
count:指定在文件描述符 in_fd 和 out_fd 之间传输的字节数,决定一次 sendfile 调用传输的数据量大小。
返回值
成功执行时,返回实际传输的字节数。
执行失败时,返回 -1 ,并设置相应的 errno 错误码,可据此定位和解决问题。
数据传输流程
操作系统利用 DMA(直接内存访问)技术将 in_fd 所指向文件的数据从磁盘读取到内核缓冲区。
数据在内核空间中直接从内核缓冲区拷贝到与 out_fd(通常是 socket 对应的缓冲区)相关的内核缓冲区。此过程数据始终在内核空间传输,避免了在用户空间和内核空间之间来回拷贝,减少上下文切换和 CPU 拷贝次数 。
数据通过 DMA 从与 socket 相关的内核缓冲区传输到网络接口,完成数据发送。在较新的实现中,当文件数据被拷贝到内核缓冲区时,不会将全部数据拷贝到 socket 相关缓冲区,而是仅将记录数据位置和长度相关的元数据保存到 socket 相关缓存,实际数据由 DMA 模块直接发送到协议引擎,再次减少一次数据拷贝操作。
应用场景
在网络编程中应用广泛,尤其适用于高效传输文件的场景 ,如:
文件服务器:可将服务器上的文件快速发送给客户端。当有客户端连接时,接受连接请求,通过 sendfile 函数将文件内容直接发送给客户端,避免数据在用户空间的拷贝,提高文件传输效率。在处理大量文件传输或高并发网络请求时优势明显。
Web 服务器:以 Nginx 为例,当作为静态文件服务器时,开启 sendfile 配置项能大幅提高性能。因为静态文件传输无需经过用户空间过多逻辑处理,可利用 sendfile 在内核空间直接传输文件数据。但当 Nginx 作为反向代理时,in_fd 是 socket 而非文件句柄,不符合 sendfile 参数要求,该配置项就无作用了。
你响应报文的正文部分是在什么时候构建的呢?
如果是CGI模式
父进程会在子进程结束之后调用read读取管道文件中子进程的返回结果,将结果读入response_body中
完整传递过程:我们就在子进程任务处理完之后,将子进程的处理结果通过管道传递给父进程,然后父进程再调用send将这个结果从用户缓冲区发送到内核中的发送缓冲区,最后由操作系统内核自动将缓冲区中的数据封装成TCP报文段,然后发给对端
如果是非CGI模式
当我们拿到请求资源的地址时,我们就直接调用sendfile将文件发出去了,并不是说将资源读到body中,再调send把body发出去(这是CGI模式的做法)
如果是静态网页请求,我们就在发送完响应报头和空行之后,直接调用sendfile,将请求的资源从磁盘直接发送到内核发送缓冲区中,然后再由操作系统内核自动将缓冲区中的数据封装成TCP报文段,然后发给对端
HTTP的CGI机制
CGI机制介绍
什么是CGI机制?
所谓的CGI机制。是指HTTP server并不承担具体任务的执行工作。具体的任务处理工作交给其他可执行程序处理。HTTP server仅仅负责传递请求报文的参数、调用具体的任务处理程序,接收任务处理结果并返回给客户端。相当于HTTPserver仅仅是搭了一个台,真正唱戏的另有其人。
为什么说现在很少有人用CGI机制了呢?
原因就是因为CGI机制是http协议中属于非常底层、非常重要的机制,已经内嵌进各种语言的函数中,不用我们专门去调用,函数内部自动就帮我们封装好了,你直接调函数就行
什么时候需要使用CGI来进行数据处理呢?
用户上传数据时
CGI机制设计
创建子进程,在子进程中进行程序替换
父子进程的框架
管道的约束
程序替换
程序替换只替换代码和数据,并不替换内核进程相关的数据结构,包括:文件描述符表
在我重新编写makefile文件,测试cgi机制时,我遇到了一个问题,就是服务器老是显示找不到wwwroot/test_cgi这个文件,导致我test_cgi.cc中的代码无法被测试,为什么呢?
原因就是我运行的httpserver文件不对,应该运行在output目录下的http文件,这是因为stat函数中传的路径,如果是相对路径的话,是指在当前程序所在文件目录下的相对路径,如果我们运行的是HTTP_test目录下的可执行程序httpserver,那相对路径应该是output/wwwroot/test_cgi
CGI机制总结
其中红色流程图代表的就是CGI机制下的任务处理流程,蓝色就对应静态网页请求
如果把中间的过程看做一个黑箱,只看两头,那么CGI程序的标准输入和标准输出其实都是浏览器(这就是CGI机制的最大作用)
有了CGI机制之后,我们就可以将服务器的通信与具体数据处理过程解耦合,通信细节交给其他函数,数据处理交给CGI函数
我在CGI函数中编程,不需要再关心CGI函数是如何拿到浏览器中的数据的,也不需要再关心CGI函数如何将处理后的数据发送给浏览器,我只用知道,在CGI函数中,fd=0标准输入流就可以从浏览器中读数据,fd=1标准输出流就是可以向浏览器发数据
多请求并发处理问题
引入线程池之前,这里传参时最后为什么不能直接传&sock,而是要拷贝一份之后再传指针呢?
// 答:(1)生命周期问题:sock 是一个局部变量,它的生命周期仅限于定义它的代码块。当主线程中的代码块执行完毕后,sock 会被销毁,其占用的内存空间会被释放。
// 而新创建的线程可能在主线程的代码块执行完毕之后才开始访问 &sock 指向的内存。此时,&sock 指向的内存已经被释放,新线程访问这块内存会导致未定义行为,例如读取到无效的数据或者引发段错误。
// (2)多线程并发问题:在多线程环境下,如果多个线程同时使用同一个局部变量的地址,会导致数据竞争问题。假设在一个循环中不断接受新的连接并创建新线程:当新线程还未开始访问 &sock 时,主线程可能已经接受了下一个连接,sock 的值会被更新。这样,新线程最终访问到的 sock 值可能不是它应该处理的连接的套接字描述符。
你这个自主实现的服务器如何解决海量请求同时访问的问题呢?
答案就是拓展硬件,提供与处理海量请求相匹配的硬件资源
然后再根据硬件资源调整软件
当然,我们当前的处理方式显然是不够高效的,我们的优化方案就是采用线程池技术,通过线程池技术就可以缓解这个并发问题
引入线程池之后的架构
引入线程池之后的架构设计
设计思路
线程池架构
引入线程池之后,项目的执行逻辑是怎样的?(引入线程之后的项目架构)
命令行输入./httpserver 8081
main函数创建一个针对8081端口的httpserver对象
main函数执行httpserver->Loop()
1.Loop内部的执行逻辑其实很简单,首先就是要创建并获取线程池和TCPServer的单例
创建TCPServer的单例的过程中我们要针对8081端口new一个tcpserver对象,完成监听套接字的创建、绑定,然后让其处于监听状态
创建线程池的过程中我们要完成池子中6个初始线程的创建,然后让这些线程都去执行ThreadRoutine
ThreadRoutine中干的啥事情呢?
首先就是不断地尝试从任务队列中取任务,如果没取到(任务队列为空),那就让线程陷入阻塞等待,如果取到了,就去执行,执行完毕之后接着尝试从任务队列中取任务
任务属于是生产者消费者模型中的产品(临界资源),因此无论是从队列中取任务(消费产品)还是向队列中插入新的任务(生产任务)都需要加锁
2.然后调用accept就不断地从8081端口的请求队列中拿出请求,然后开一个新套接字描述符sock专门用于处理这个请求
开一个新的接收缓冲区,专门用于接收来自这个客户端的http请求报文,开一个新的发送缓冲区,专门用来向这个客户端发送请求,这组缓冲区有一个统一的文件描述符,这就是accept的返回值,也就是我们图中的sock
3.将sock打包成一个任务,然后插入到任务队列中
这里有人肯定会问,这就完了吗?你光插入不处理怎么能行呢?
答案是你只要管派任务就完事了,其实在你派任务之前,我们线程池单例就已经创建好6个线程再等你给他们派任务了,正搁这卡着呢
一旦你Loop那边向线程池的任务队列中添加了任务,我这边线程池立马就可以唤醒阻塞等待中的进程
然后线程就可以执行后面的代码,从队列中取出任务,然后执行这个任务
这个任务执行具体都干些啥呢?
我们可以看看ProcessOn的定义
handler是CallBack类的对象,handler(sock)其实是一个仿函数,对应执行的其实是CallBack类中的HandlerRequest函数
在HandlerRequest函数中,我们完成请求报文的接受和响应报文的构建与发送(具体是咋接收、咋构建、咋发送的呢?请看)
一直重复2和3两个步骤,直到stop标志位被置为1,这说明程序发生了错误,服务器终止运行
如何在项目各个模块之间传递任务,实现各模块之间的解耦?
请问图中为什么要用while语句而不用if语句呢?
主要就是为了防止虚假唤醒问题
什么是虚假唤醒问题?为什么换成while就能够防止呢?
在多线程编程中,存在 "虚假唤醒" 的情况 。当线程因条件变量等待被唤醒时,并不一定是因为条件满足了(比如任务队列不为空 ),可能是系统原因或其他干扰导致的误唤醒。如果使用if语句,一旦发生虚假唤醒,线程就会继续执行后续从任务队列取任务的操作,但此时任务队列可能仍然为空,这样就会导致错误(比如空指针访问、非法内存访问等 )。而使用while语句,即使发生虚假唤醒,线程被唤醒后会再次检查TaskQueueIsEmpty()条件是否为真。若仍然为空,线程会继续等待,从而避免了因虚假唤醒带来的错误操作 。
使用while循环可以保证在整个等待过程中,只要条件不满足(任务队列为空 ),线程就持续等待。而if语句只是在进入时检查一次条件,若后续条件发生变化(比如在检查后、执行操作前,任务队列又变为空 ),if语句无法再次检查并处理这种情况,使用while循环则能持续监控条件,确保在真正满足从任务队列取任务的条件时才进行后续操作。
为什么要用单例模式?如何实现单例模式?
为什么要用单例模式?
采用单例模式,能确保整个应用程序中只有一个线程池实例,便于集中管理线程资源,合理控制线程数量,避免无节制创建线程带来的资源浪费和性能问题 。同时也方便被多个模块或者对象复用
如何实现单例模式?
1.把类的构造和赋值操作符给禁了
2.在成员函数中定义一个静态变量------instance表示单例的指针,并在类外进行初始化
3.写一个接口GetInstance用于获取单例
大项目编写过程中应该如何调试?
灵活运用LOG日志,可以起到一个打断点的作用
cd ...
./build.sh
这是一个运行脚本,就可以帮我们快捷执行一套指令
cd output
./httpserver 8081
表单测试
什么是表单?
表单就是前端html语言中的一种类型,是在网页中用于收集用户输入信息的重要交互元素,它能够让用户与网页进行信息交互,将数据提交给服务器进行处理。
如何进行表单测试?
你先在html语言中创建一个表单
然后我们就可以通过表单向服务器中传递数据了,这就是表单测试
CGI对其他语言是否支持?
在cgi机制中,我们会根据客户端发来的资源请求路径,找到对应的可执行文件,然后在子进程中做相应的进程替换。因为我服务器进程就是用cpp写的,所以替换的可执行程序当然可以是cpp文件编译生成的,既然如此我就想问了,路径可以指向一个java文件吗?可以是python文件吗?路径可以指向一个shell脚本文件吗?(脚本文件也可以直接执行)
答案是都可以
我们先写一个简单的脚本文件
放到./output/wwwroot目录下
注意这一步很关键!给这个文件添加可执行权限:chmod u+x shell_cgi.sh
然后客户端请求这个资源
数据库访问测试
首先把库下下来
然后把库传到云服务器上(这里如果rz失败,很有可能是权限问题,切换成root用户就好了)
然后用tar -xzvf解压得到库文件
打开之后最重要的就是这俩文件,然后我们就把这俩复制到上级目录
然后我自己写一个mysql的测试文件
gcc编译生成可执行文件(我们也可以使用静态链接,加一个-static和-ldl )
注意这时候我们的可执行文件有可能还是没法执行,原因可能是?如何解决?
因为这种可执行程序是动态链接形成的,马上执行的时候是需要连接动态库的(动态库里面有库函数的具体实现),但是如果你找不到动态库所在路径,那就没法执行
对于这种情况我们就export LD_LIBRARY_PATH=./lib/将动态库所在路径添加到环境变量中即可
export LD_LIBRARY_PATH=./lib/解释
export:是 Linux 命令,用于将变量导出为环境变量 ,让后续执行的程序能访问该变量的值。
LD_LIBRARY_PATH:是一个重要的环境变量。在 Linux 系统中,程序在运行时,动态链接器(如 ld - linux.so)会依据此变量的值来查找所需的动态链接库。默认情况下,系统会去 /lib 和 /usr/lib 等标准路径找库文件,但当程序依赖的库不在这些标准路径时,就需通过设置 LD_LIBRARY_PATH 来告知系统额外的库文件查找路径。
./lib/:这里指定了当前目录(. 表示当前目录)下的 lib 文件夹作为额外的库文件查找路径。这意味着后续运行的程序,动态链接器会到当前目录的 lib 文件夹中查找所需的动态链接库。
然后运行这个可执行文件,在源文件中我们连接了数据库,并向数据库中发送了一条数据,执行完毕之后我们就可以看看数据库中究竟有没有收到这条数据(收到了)
最后我们此次测试功能是:我在web界面通过表单提交数据,浏览器根据表单形成对应的POST请求报文,然后发送到服务器端的mysql进程,插入到指定的数据库中(你自己测测试试,实验很成功),中间为了测试方便,我们把makefile文件进行了一点小优化,可以看看这里面最后一版6. vim Makefile
数据库的测试工作主要是起步难,即你如何在C++文件中连接数据库(如何让一个连接数据库的c++文件在gcc下正常编过),然后实现客户端浏览器与数据库服务器之间的数据交互
项目总结
项目重点
http请求和响应的实现
请求方法:GET和POST(CGI和非CGI模式处理)
项目拓展
技术层面的拓展
支持http/1.1版本,也就是长连接实现(有难度,难度在于链接管理和粘包)
改成epoll
通过cgi直接访问redis
改成一个请求转发服务器(代理服务器)
应用层面的拓展
在线博客
在线个人简历,如果对方在表单中提交了一个联系方式,你的服务器端会自动将这个联系方式发到你的QQ/手机上
在线画图板
在线视频(目前其实已经支持视频了,content type添加网页类型,然后前端加一个播放按钮)(之所以没演示,是因为服务器配置有点低,运行起来比较卡)
在线的网络计算器(年月日,时间戳转化)
项目遗留问题