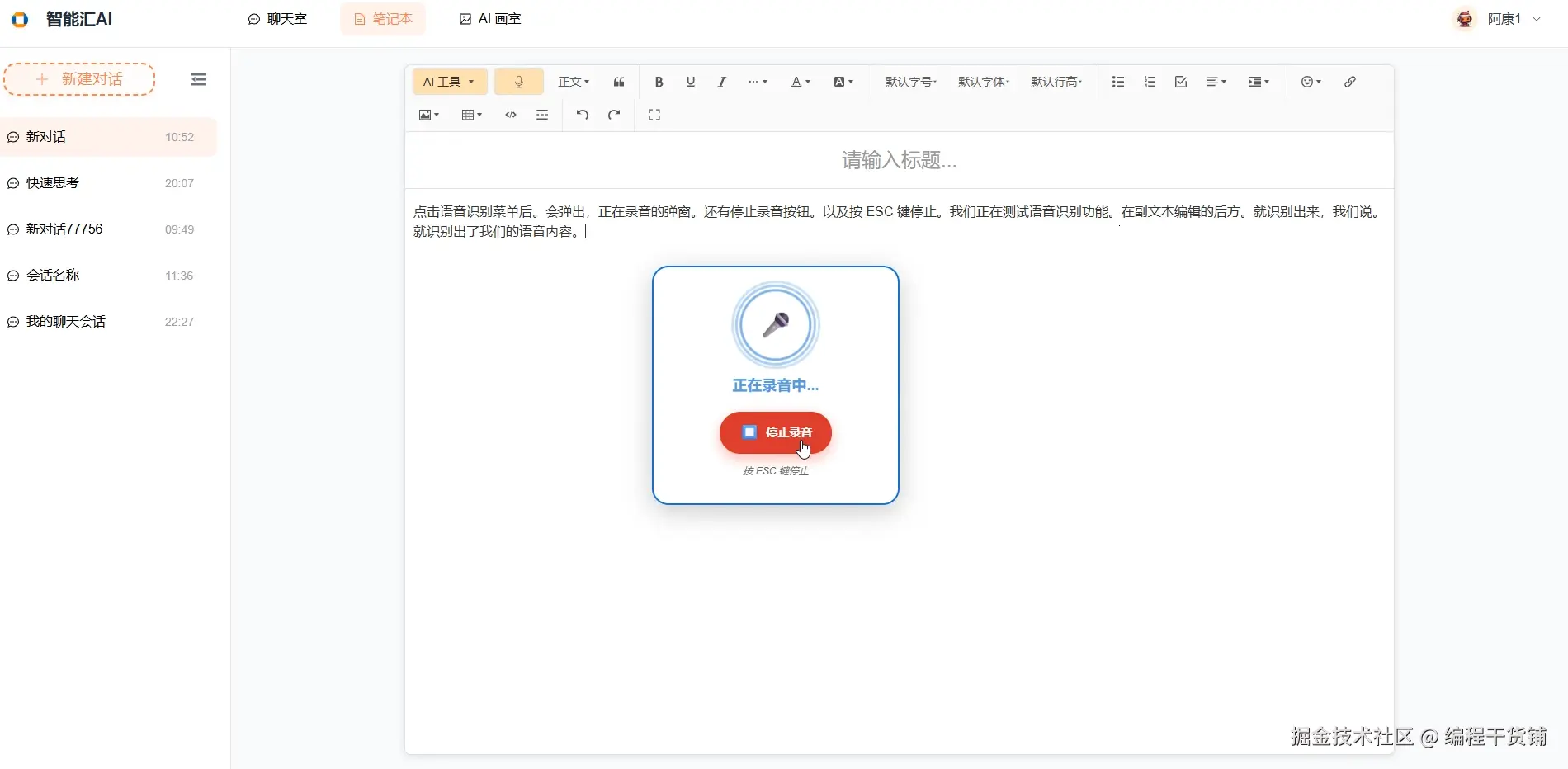
在上篇文章中,我使用了 node.js 封装了豆包模型的语音识别接口,接下来就在前端调用该接口,实现语音识别完整。这篇文章讲拆解如何在 Vue 3.5 框架与 WangEditor 富文本编辑器的基础上,集成完整的语音识别功能,从音频采集、格式转换到实时识别结果插入,全方位呈现可落地的技术方案。
功能定位与技术选型
核心需求拆解
- 实时语音转文字:支持麦克风采集音频,实时返回识别结果并插入编辑器
- 良好的用户体验:提供录音状态可视化、快捷键控制、错误提示
- 兼容性保障:适配主流浏览器,兼顾现代 API 与降级方案
- 稳定性设计:包含连接诊断、错误处理、资源自动释放机制
技术栈选型
- 框架:Vue 3.5 + Composition API(高效的组件逻辑组织)
- 编辑器:WangEditor(轻量、可扩展的富文本编辑器)
- 音频处理:AudioWorklet + ScriptProcessor(高效音频格式转换)
- 通信方式:WebSocket(实时传输音频数据与识别结果)
- UI 组件:Element Plus(错误提示、弹窗等交互组件)
选型核心考量:Vue 3.5 的响应式特性适合状态管理,WangEditor 开放的 API 便于扩展,WebSocket 确保流式数据传输的实时性,双重音频处理方案保障兼容性。
整体架构设计
语音识别功能采用分层设计,各模块职责清晰,便于维护与扩展:
UI交互层(NoteEditor.vue)→ 核心控制层(simpleSpeech.js)→ 音频处理层(audioPcmProcessor.js)→ 通信层(WebSocket) ↓ 诊断工具层(speechConfigChecker.js)
- UI 交互层:提供用户操作入口(录音按钮、状态展示)和结果插入逻辑
- 核心控制层:封装录音启停、连接管理、消息处理等核心逻辑
- 音频处理层:将麦克风采集的音频转换为识别服务支持的 PCM 格式
- 通信层:通过 WebSocket 与后端语音识别服务实时交互
- 诊断工具层:检测环境兼容性、服务可用性,辅助问题排查
核心模块实现详解
1. 音频处理层:PCM 格式转换(audioPcmProcessor.js)
语音识别服务通常要求输入 16kHz 采样率、16 位深度的 PCM 格式音频,而浏览器麦克风采集的是 Float32Array 格式(范围 −1,1),因此需要专门的格式转换模块。
采用 AudioWorklet 实现高效音频处理(浏览器不支持时降级为 ScriptProcessor):
javascript
class AudioPcmProcessor extends AudioWorkletProcessor {
constructor() {
super()
this.bufferSize = 4096 // 缓冲区大小,平衡延迟与性能
this.buffer = new Float32Array(this.bufferSize)
this.bufferIndex = 0
}
process(inputs, outputs, parameters) {
const input = inputs[0]
if (input.length > 0) {
const inputChannel = input[0]
// 填充缓冲区
for (let i = 0; i < inputChannel.length; i++) {
this.buffer[this.bufferIndex] = inputChannel[i]
this.bufferIndex++
// 缓冲区满时处理并发送
if (this.bufferIndex >= this.bufferSize) {
this.processAndSendPcm()
this.bufferIndex = 0
}
}
}
return true
}
processAndSendPcm() {
try {
// Float32 → Int16 PCM 转换:[-1,1] → [-32768, 32767]
const pcmData = new Int16Array(this.buffer.length)
for (let i = 0; i < this.buffer.length; i++) {
const sample = Math.max(-1, Math.min(1, this.buffer[i])) // 限制范围
pcmData[i] = sample < 0 ? sample * 0x8000 : sample * 0x7fff
}
// 用 Transferable 对象传输,避免数据复制
this.port.postMessage(
{ type: 'pcmData', data: pcmData.buffer, length: pcmData.length },
[pcmData.buffer]
)
} catch (error) {
this.port.postMessage({ type: 'error', error: error.message })
}
}
}
registerProcessor('audio-pcm-processor', AudioPcmProcessor)核心亮点:
- 采用缓冲区批量处理,减少通信开销
- 使用 Transferable 对象 转移
ArrayBuffer所有权,提升传输效率 - 严格限制音频采样范围,避免失真
2. 核心控制层:语音识别封装(simpleSpeech.js)
该模块是语音识别功能的核心,封装了录音控制、WebSocket 连接、消息处理等逻辑,对外提供简洁的 API:
javascript
export class SimpleSpeech {
constructor(options = {}) {
// 基础配置
const baseUrl = import.meta.env.VITE_API_BASE_URL || 'http://localhost:3000'
this.serverUrl = `${baseUrl.replace('http', 'ws')}/api/v1/ai/speech-recognition`
this.sampleRate = options.sampleRate || 16000
this.model = options.model || 'bigmodel'
// 状态管理
this.isRecording = false
this.isConnected = false
this.isReady = false
// 音频组件与通信实例
this.audioContext = null
this.audioStream = null
this.workletNode = null
this.ws = null
// 事件回调(解耦UI与核心逻辑)
this.onReady = options.onReady || (() => {})
this.onPartial = options.onPartial || (() => {}) // 中间结果回调
this.onFinal = options.onFinal || (() => {}) // 最终结果回调
this.onError = options.onError || (() => {})
}
// 建立WebSocket连接
async connect() {
try {
const url = `${this.serverUrl}?sampleRate=${this.sampleRate}&model=${this.model}`
this.ws = new WebSocket(url)
this.ws.onopen = () => {
this.isConnected = true
this.onStatusChange('connected')
}
this.ws.onmessage = (event) => {
const data = JSON.parse(event.data)
this.handleMessage(data) // 处理服务端消息
}
this.ws.onclose = () => {
this.isConnected = false
this.isReady = false
this.onStatusChange('disconnected')
}
} catch (error) {
this.onError('连接失败: ' + error.message)
}
}
// 处理服务端消息
handleMessage(data) {
switch (data.type) {
case 'ready':
this.isReady = true
this.onReady() // 服务就绪回调
break
case 'incremental_result':
// 实时返回中间识别结果
this.onPartial({ text: data.text, timestamp: data.timestamp })
break
case 'final_result':
// 语音片段识别完成,返回最终结果
this.onFinal({ text: data.text, timestamp: data.timestamp })
break
case 'error':
this.onError(this.formatErrorMsg(data.message))
break
}
}
// 开始录音
async startRecording() {
if (!this.isConnected || !this.isReady) {
this.onError('请先连接语音识别服务')
return
}
try {
// 获取麦克风权限
this.audioStream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: this.sampleRate,
channelCount: 1, // 单声道
echoCancellation: true, // 回声消除
noiseSuppression: true, // 降噪
autoGainControl: true // 自动增益
}
})
// 创建音频上下文
this.audioContext = new (window.AudioContext || window.webkitAudioContext)({
sampleRate: this.sampleRate
})
const audioSource = this.audioContext.createMediaStreamSource(this.audioStream)
// 优先使用AudioWorklet,失败则降级
try {
await this.audioContext.audioWorklet.addModule('/audioPcmProcessor.js')
this.workletNode = new AudioWorkletNode(this.audioContext, 'audio-pcm-processor')
this.workletNode.port.onmessage = (event) => {
if (event.data.type === 'pcmData' && this.ws?.readyState === WebSocket.OPEN) {
this.ws.send(event.data.data) // 发送PCM数据
}
}
audioSource.connect(this.workletNode)
} catch (error) {
this.createScriptProcessor(audioSource) // 降级方案
}
this.isRecording = true
} catch (error) {
this.onError('录音启动失败: ' + error.message)
}
}
// ScriptProcessor降级方案(兼容旧浏览器)
createScriptProcessor(audioSource) {
const scriptProcessor = this.audioContext.createScriptProcessor(4096, 1, 1)
scriptProcessor.onaudioprocess = (event) => {
if (this.ws?.readyState === WebSocket.OPEN) {
const inputData = event.inputBuffer.getChannelData(0)
// 同上的PCM格式转换逻辑
const pcmData = new Int16Array(inputData.length)
for (let i = 0; i < inputData.length; i++) {
const sample = Math.max(-1, Math.min(1, inputData[i]))
pcmData[i] = sample < 0 ? sample * 0x8000 : sample * 0x7fff
}
this.ws.send(pcmData.buffer)
}
}
audioSource.connect(scriptProcessor)
scriptProcessor.connect(this.audioContext.destination)
}
// 停止录音
stopRecording() {
if (!this.isRecording) return
// 断开音频节点,释放资源
if (this.workletNode) this.workletNode.disconnect()
if (this.scriptProcessor) this.scriptProcessor.disconnect()
// 关闭音频流和上下文
this.audioStream.getTracks().forEach(track => track.stop())
this.audioContext.close()
this.isRecording = false
}
// 格式化错误信息
formatErrorMsg(message) {
if (message.includes('缺少配置')) {
return '后端缺少配置,请设置ARK_APP_ID和ARK_ACCESS_TOKEN'
} else if (message.includes('连接失败')) {
return '无法连接语音识别服务,请检查网络'
}
return message
}
}核心设计思路:
- 采用事件回调解耦 UI 与核心逻辑,提高复用性
- 双重音频处理方案,兼顾现代浏览器性能与旧浏览器兼容性
- 完善的状态管理,避免无效操作(如未连接时启动录音)
- 错误信息格式化,提升用户可理解性
3. UI 交互层:编辑器集成(NoteEditor.vue)
在 Vue 组件中集成 WangEditor 与语音识别核心逻辑,提供用户交互入口和结果展示:
3.1 模板结构设计
html
<template>
<div class="note-editor">
<div class="editor-toolbar">
<Toolbar :editor="editorRef" :defaultConfig="toolbarConfig" :mode="mode" />
</div>
<div class="editor-content">
<Editor v-model="valueHtml" :defaultConfig="editorConfig" @onCreated="handleCreated" />
</div>
<div v-if="isSpeechRecording" class="speech-recording-indicator">
<div class="recording-animation">
<div class="pulse-ring"></div>
<div class="microphone-icon">🎤</div>
</div>
<div class="recording-text">正在录音中...</div>
<button @click="stopSpeechRecognition" class="stop-btn">⏹️ 停止录音</button>
<div class="esc-hint">按 ESC 键停止</div>
</div>
</div>
</template>3.2 核心逻辑实现
javascript
<script setup>
import { ref, shallowRef, onMounted, onBeforeUnmount } from 'vue'
import { Editor, Toolbar } from '@wangeditor/editor-for-vue'
import { SimpleSpeech } from '@/utils/simpleSpeech.js'
import { SpeechConfigChecker } from '@/utils/speechConfigChecker.js'
import { ElMessage } from 'element-plus'
// 编辑器实例(WangEditor要求用shallowRef)
const editorRef = shallowRef(null)
// 语音识别相关状态
const speechRecognition = ref(null)
const isSpeechRecording = ref(false)
const speechStatus = ref('disconnected')
// 工具栏配置(添加语音识别菜单)
const toolbarConfig = {
excludeKeys: ['group-video'],
insertKeys: {
index: 0,
keys: ['voiceReadingMenu'] // 自定义语音识别菜单
}
}
// 编辑器创建完成回调
const handleCreated = (editor) => {
editorRef.value = editor
}
// 初始化语音识别实例
const initSpeechRecognition = () => {
if (speechRecognition.value) return
speechRecognition.value = new SimpleSpeech({
sampleRate: 16000,
model: 'bigmodel',
onReady: () => {
speechStatus.value = 'ready'
},
onPartial: (result) => {
// 实时插入中间识别结果
insertSpeechText(result.text)
},
onFinal: (result) => {
// 插入最终结果(可覆盖中间结果或追加)
insertSpeechText(result.text)
},
onError: (error) => {
ElMessage.error(error)
// 自动运行配置检查,辅助排查问题
runConfigCheck()
}
})
}
// 开始语音识别
const startSpeechRecognitionDirect = async () => {
try {
if (!speechRecognition.value) {
initSpeechRecognition()
}
await speechRecognition.value.connect()
// 等待服务就绪(最多3秒超时)
let retryCount = 0
while (retryCount < 30 && speechStatus.value !== 'ready') {
await new Promise(resolve => setTimeout(resolve, 100))
retryCount++
}
if (speechStatus.value !== 'ready') {
throw new Error('语音识别服务连接超时')
}
await speechRecognition.value.startRecording()
isSpeechRecording.value = true
ElMessage.success('🎤 开始语音识别')
} catch (error) {
ElMessage.error('启动失败: ' + error.message)
}
}
// 停止语音识别
const stopSpeechRecognition = () => {
if (speechRecognition.value && isSpeechRecording.value) {
speechRecognition.value.stopRecording()
isSpeechRecording.value = false
ElMessage.info('⏹️ 语音识别已停止')
}
}
// 插入识别结果到编辑器
const insertSpeechText = (text) => {
const editor = editorRef.value
if (!editor || !text.trim()) return
editor.focus() // 聚焦编辑器
editor.insertText(text) // 插入文本
}
// 全局快捷键监听(ESC停止录音)
const handleGlobalKeydown = (event) => {
if (event.key === 'Escape' && isSpeechRecording.value) {
event.preventDefault()
stopSpeechRecognition()
}
}
// 配置检查(诊断环境和服务问题)
const runConfigCheck = async () => {
const checker = new SpeechConfigChecker()
const results = await checker.runFullCheck()
const report = checker.generateDiagnosticReport(results)
console.log('语音识别配置诊断报告:', report)
}
// 生命周期钩子:绑定事件
onMounted(() => {
// 绑定语音识别菜单点击事件
document.addEventListener('voiceReadingClick', (e) => {
const action = e.detail.action
if (action === 'start') {
startSpeechRecognitionDirect()
} else if (action === 'stop') {
stopSpeechRecognition()
}
})
// 绑定全局快捷键
document.addEventListener('keydown', handleGlobalKeydown)
})
// 生命周期钩子:释放资源
onBeforeUnmount(() => {
// 清理事件监听
document.removeEventListener('voiceReadingClick', handleVoiceReadingClick)
document.removeEventListener('keydown', handleGlobalKeydown)
// 销毁语音识别实例
if (speechRecognition.value) {
speechRecognition.value.disconnect()
speechRecognition.value = null
}
// 销毁编辑器
editorRef.value?.destroy()
})
</script>3.3 样式优化(提升用户体验)
scss
<style lang="scss" scoped>
// 录音状态指示器样式
.speech-recording-indicator {
position: fixed;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
z-index: 2000;
background: rgba(255, 255, 255, 0.95);
border-radius: 20px;
padding: 30px;
text-align: center;
box-shadow: 0 8px 32px rgba(0, 0, 0, 0.2);
.recording-animation {
position: relative;
width: 80px;
height: 80px;
margin: 0 auto 20px;
.pulse-ring {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
width: 60px;
height: 60px;
border: 3px solid #1976d2;
border-radius: 50%;
opacity: 0;
animation: pulseRing 2s ease-out infinite;
}
.microphone-icon {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
font-size: 32px;
z-index: 10;
}
}
.stop-btn {
background: #f44336;
color: white;
border: none;
border-radius: 25px;
padding: 12px 24px;
font-size: 16px;
cursor: pointer;
transition: all 0.3s ease;
}
}
// 脉冲动画
@keyframes pulseRing {
0% {
width: 60px;
height: 60px;
opacity: 1;
}
100% {
width: 120px;
height: 120px;
opacity: 0;
}
}
</style>UI 层核心亮点:
- 录音状态可视化:通过脉冲动画直观展示录音中状态
- 快捷键支持:ESC 键快速停止录音,提升操作便捷性
- 结果实时插入:识别结果即时插入编辑器,无需手动复制
- 资源自动释放:组件卸载时清理事件监听和实例,避免内存泄漏
4. 诊断工具层:配置检查(speechConfigChecker.js)
为了解决用户环境差异导致的功能异常,提供配置检查工具,自动诊断问题:
javascript
export class SpeechConfigChecker {
constructor() {
this.baseUrl = import.meta.env.VITE_API_BASE_URL || 'http://localhost:3000'
}
// 检查后端服务状态
async checkBackendService() {
try {
const response = await fetch(`${this.baseUrl}/health`)
return {
success: response.ok,
message: response.ok ? '后端服务正常' : `状态码: ${response.status}`
}
} catch (error) {
return { success: false, message: '无法连接后端: ' + error.message }
}
}
// 检查语音识别服务可用性
async checkSpeechService() {
try {
const response = await fetch(`${this.baseUrl}/api/v1/ai/speech-recognition`)
return {
success: response.ok,
message: response.ok ? '语音服务可用' : await response.text()
}
} catch (error) {
return { success: false, message: '语音服务检查失败: ' + error.message }
}
}
// 测试WebSocket连接
async testWebSocketConnection() {
return new Promise((resolve) => {
const wsUrl = this.baseUrl.replace('http', 'ws')
const ws = new WebSocket(`${wsUrl}/api/v1/ai/speech-recognition?sampleRate=16000`)
const timeout = setTimeout(() => {
ws.close()
resolve({ success: false, message: 'WebSocket连接超时' })
}, 5000)
ws.onopen = () => {
clearTimeout(timeout)
ws.close()
resolve({ success: true, message: 'WebSocket连接成功' })
}
ws.onerror = () => {
clearTimeout(timeout)
resolve({ success: false, message: 'WebSocket连接错误' })
}
})
}
// 检查浏览器兼容性
checkBrowserCompatibility() {
const features = [
{ name: 'WebSocket', check: () => typeof WebSocket !== 'undefined' },
{ name: 'AudioContext', check: () => typeof AudioContext !== 'undefined' },
{ name: 'getUserMedia', check: () => navigator.mediaDevices?.getUserMedia },
{ name: 'AudioWorklet', check: () => typeof AudioWorkletNode !== 'undefined' }
]
return features.map(item => ({
feature: item.name,
supported: item.check(),
message: item.check() ? '支持' : '不支持'
}))
}
// 生成诊断报告
generateDiagnosticReport(results) {
const report = [
'=== 语音识别配置诊断报告 ===',
`后端服务: ${results.backend.success ? '✅ 正常' : '❌ 异常'} - ${results.backend.message}`,
`语音服务: ${results.speechService.success ? '✅ 正常' : '❌ 异常'} - ${results.speechService.message}`,
`WebSocket: ${results.webSocket.success ? '✅ 正常' : '❌ 异常'} - ${results.webSocket.message}`,
'浏览器兼容性:'
]
results.browser.forEach(item => {
report.push(` ${item.feature}: ${item.supported ? '✅' : '❌'} ${item.message}`)
})
return report.join('\n')
}
}核心价值:
- 自动化诊断环境问题,减少用户反馈与排查成本
- 覆盖服务可用性、网络连接、浏览器兼容性等关键检查点
- 生成结构化报告,便于开发者定位问题
关键技术难点与解决方案
1. 音频格式一致性问题
- 问题:不同浏览器采集的音频参数差异,导致识别服务无法解析
- 解决方案 :
- 强制指定采样率为 16kHz、单声道
- 启用浏览器内置的回声消除、降噪功能
- 统一转换为 16 位 PCM 格式,确保数据标准化
2. 实时性与性能平衡
- 问题:音频数据传输过频繁导致网络开销大,过慢则识别延迟高
- 解决方案 :
- 缓冲区大小设置为 4096 字节(16kHz 单声道约 256ms 数据)
- 使用
Transferable对象避免数据复制,提升传输效率 - 中间结果实时返回,最终结果确认,平衡实时性与准确性
3. 浏览器兼容性问题
- 问题:部分旧浏览器不支持 AudioWorklet 等现代 API
- 解决方案 :
- 实现 AudioWorklet + ScriptProcessor 双重方案
- 提前检查浏览器特性,自动降级
- 提供清晰的兼容性提示,引导用户升级浏览器
4. 资源泄漏风险
- 问题:录音过程中组件卸载或异常退出,导致音频流、WebSocket 未关闭
- 解决方案 :
- 在 Vue 生命周期钩子中统一释放资源
- 录音状态与组件生命周期绑定,卸载时强制停止
- WebSocket 连接关闭时清理相关状态
功能测试与优化建议
测试场景覆盖
- 浏览器兼容性测试:Chrome、Firefox、Edge 等主流浏览器
- 网络环境测试:弱网、断网场景下的错误处理
- 权限测试:麦克风权限拒绝、授予后的状态切换
- 异常场景测试:服务不可用、配置错误等情况
优化方向
- 音频预处理:添加音量检测,过滤静音片段,减少无效数据传输
- 识别结果优化:支持结果编辑、纠错功能
- 多语言支持:根据用户配置切换识别语言
- 离线识别:集成 Web Speech API 作为离线降级方案
- 性能监控:统计识别延迟、成功率等指标,优化用户体验
总结
这篇文章基于 Vue 3.5 和 WangEditor 实现了一套完整的笔记编辑器语音识别功能,通过分层设计实现了模块解耦,兼顾了实时性、兼容性和稳定性。核心亮点包括:
- 高效的音频格式转换方案,确保识别服务兼容性
- 完善的状态管理与错误处理,提升用户体验
- 自动化配置诊断工具,降低问题排查成本
- 可扩展的架构设计,便于后续功能迭代
该方案不仅适用于笔记编辑器,也可迁移到聊天、文档协作等其他需要语音输入的场景。通过合理的技术选型和架构设计,能够有效降低语音识别功能的集成难度,为用户提供便捷、高效的输入体验。