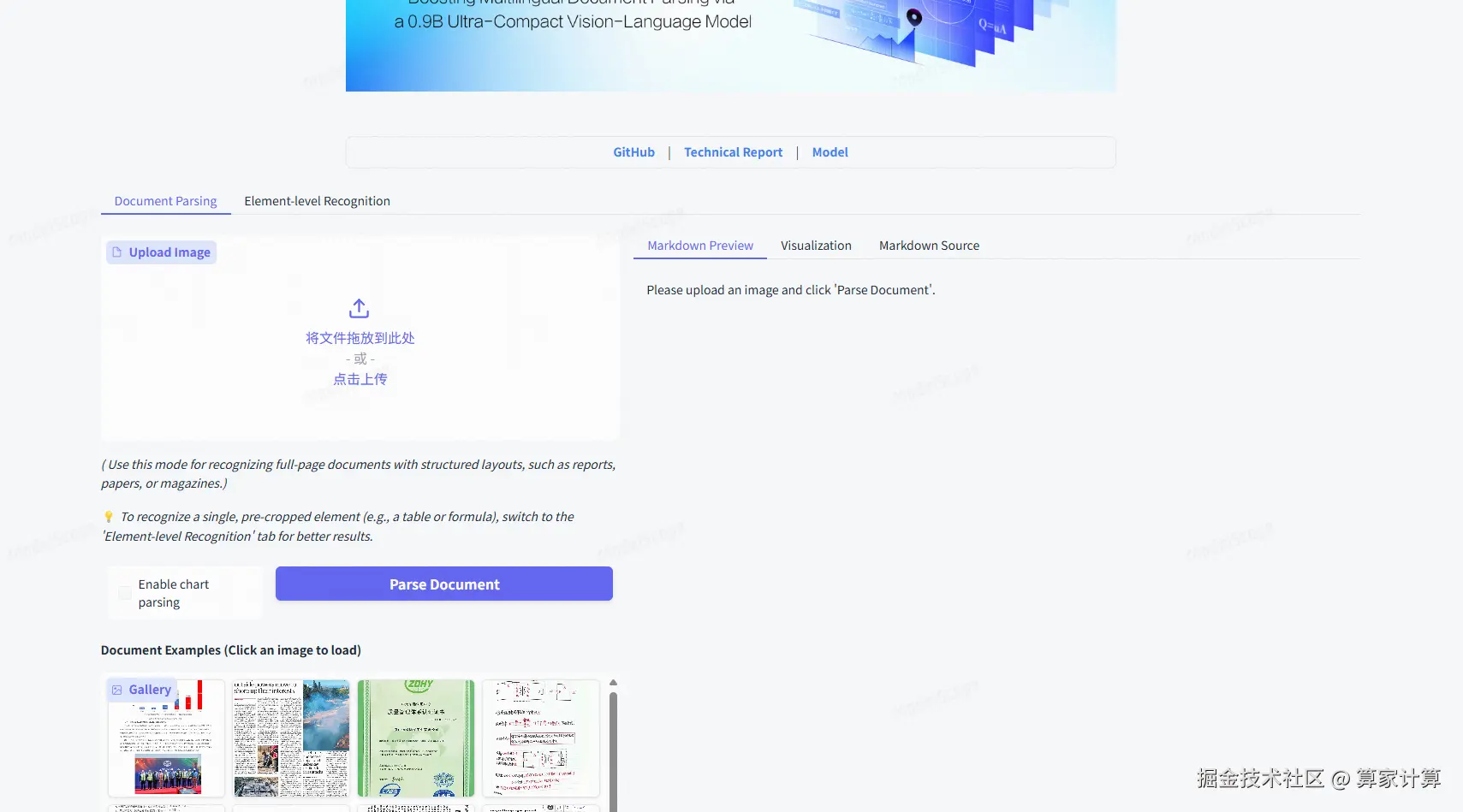
一、介绍
PaddleOCR-VL 是一个针对文档解析的 SOTA 和资源高效的模型。其核心组件是 PaddleOCR-VL-0.9B,这是一个紧凑而强大的视觉语言模型(VLM),它将 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型集成在一起,以实现精确的元素识别。该创新模型高效支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持最低的资源消耗。通过在广泛使用的公共基准和内部基准上的全面评估,PaddleOCR-VL 在页面级文档解析和元素级识别方面均达到了 SOTA 性能。它显著优于现有的解决方案,在顶级 VLM 中表现出强大的竞争力,并提供快速的推理速度。这些优势使其非常适合在实际场景中部署。
核心特性
- 紧凑而强大的 VLM 架构: 我们提出了一种专为资源高效推理设计的新型视觉语言模型,在元素识别方面表现出色。通过将 NaViT 风格的动态高分辨率视觉编码器与轻量级的 ERNIE-4.5-0.3B 语言模型集成,我们显著增强了模型的识别能力和解码效率。这种集成在保持高精度的同时降低了计算需求,使其非常适合高效和实用的文档处理应用。
- 文档解析的 SOTA 性能: PaddleOCR-VL 在页面级文档解析和元素级识别方面都达到了最先进的性能。它显著优于现有的基于流水线的解决方案,并在文档解析方面展现出与领先的视觉语言模型(VLM)的强大竞争力。此外,它在识别复杂的文档元素(如文本、表格、公式和图表)方面表现出色,适用于各种具有挑战性的内容类型,包括手写文本和历史文档。这使其高度通用,适用于各种文档类型和场景。
- 多语言支持: PaddleOCR-VL 支持 109 种语言,涵盖主要的全球语言,包括但不限于中文、英文、日文、拉丁文和韩文,以及使用不同脚本和结构的语言,如俄语(西里尔字母)、阿拉伯语、印地语(天城文)和泰语。这种广泛的语言覆盖大大增强了我们的系统在多语言和全球化文档处理场景中的适用性。
模型架构
二、部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息 1 |
|---|---|
| Ubuntu | 22.04LTS |
| Cuda | V12.6 |
| Python | 3.10 |
| NVIDIA Corporation | 4090 * 1 |
1. 更新基础软件包
查看系统版本信息
bash
# 查看系统版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
配置 apt 国内源
csharp
# 更新软件包列表
apt-get update这个命令用于更新本地软件包索引。它会从所有配置的源中检索最新的软件包列表信息,但不会安装或升级任何软件包。这是安装新软件包或进行软件包升级之前的推荐步骤,因为它确保了您获取的是最新版本的软件包。
csharp
# 安装 Vim 编辑器
apt-get install -y vim这个命令用于安装 Vim 文本编辑器。-y 选项表示自动回答所有的提示为"是",这样在安装过程中就不需要手动确认。Vim 是一个非常强大的文本编辑器,广泛用于编程和配置文件的编辑。
为了安全起见,先备份当前的 sources.list 文件之后,再进行修改:
bash
# 备份现有的软件源列表
cp /etc/apt/sources.list /etc/apt/sources.list.bak这个命令将当前的 sources.list 文件复制为一个名为 sources.list.bak 的备份文件。这是一个好习惯,因为编辑 sources.list 文件时可能会出错,导致无法安装或更新软件包。有了备份,如果出现问题,您可以轻松地恢复原始的文件。
bash
# 编辑软件源列表文件
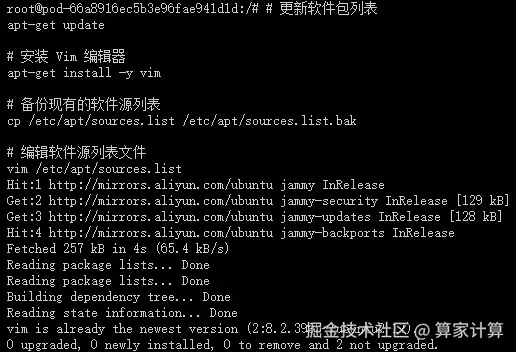
vim /etc/apt/sources.list这个命令使用 Vim 编辑器打开 sources.list 文件,以便您可以编辑它。这个文件包含了 APT(Advanced Package Tool)用于安装和更新软件包的软件源列表。通过编辑这个文件,您可以添加新的软件源、更改现有软件源的优先级或禁用某些软件源。
在 Vim 中,您可以使用方向键来移动光标,i 键进入插入模式(可以开始编辑文本),Esc 键退出插入模式,:wq 命令保存更改并退出 Vim,或 :q! 命令不保存更改并退出 Vim。
编辑 sources.list 文件时,请确保您了解自己在做什么,特别是如果您正在添加新的软件源。错误的源可能会导致软件包安装失败或系统安全问题。如果您不确定,最好先搜索并找到可靠的源信息,或者咨询有经验的 Linux 用户。
使用 Vim 编辑器打开 sources.list 文件,复制以下代码替换 sources.list 里面的全部代码,配置 apt 国内阿里源。
arduino
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse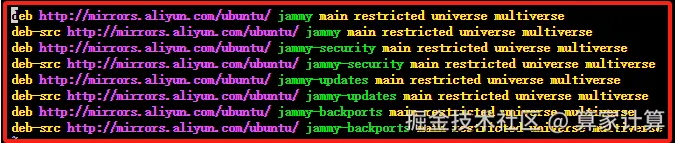
安装常用软件和工具
csharp
# 更新源列表,输入以下命令:
apt-get update
# 更新系统软件包,输入以下命令:
apt-get upgrade
# 安装常用软件和工具,输入以下命令:
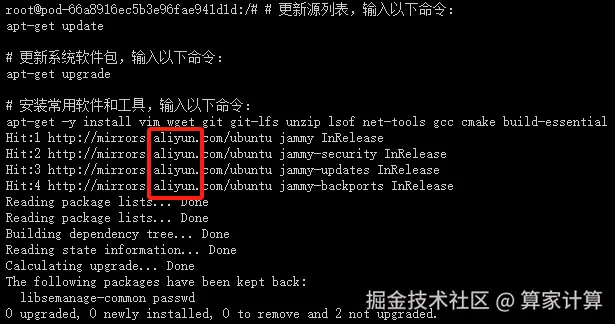
apt-get -y install vim wget git git-lfs unzip lsof net-tools gcc cmake build-essential出现以下页面,说明国内 apt 源已替换成功,且能正常安装 apt 软件和工具
2. 安装 Miniconda
-
下载 Miniconda 安装脚本 :
- 使用
wget命令从 Anaconda 的官方仓库下载 Miniconda 的安装脚本。Miniconda 是一个更小的 Anaconda 发行版,包含了 Anaconda 的核心组件,用于安装和管理 Python 包。
- 使用
-
运行 Miniconda 安装脚本 :
- 使用
bash命令运行下载的 Miniconda 安装脚本。这将启动 Miniconda 的安装过程。
- 使用
bash
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 初次安装需要激活 base 环境
source ~/.bashrc按下回车键(enter)
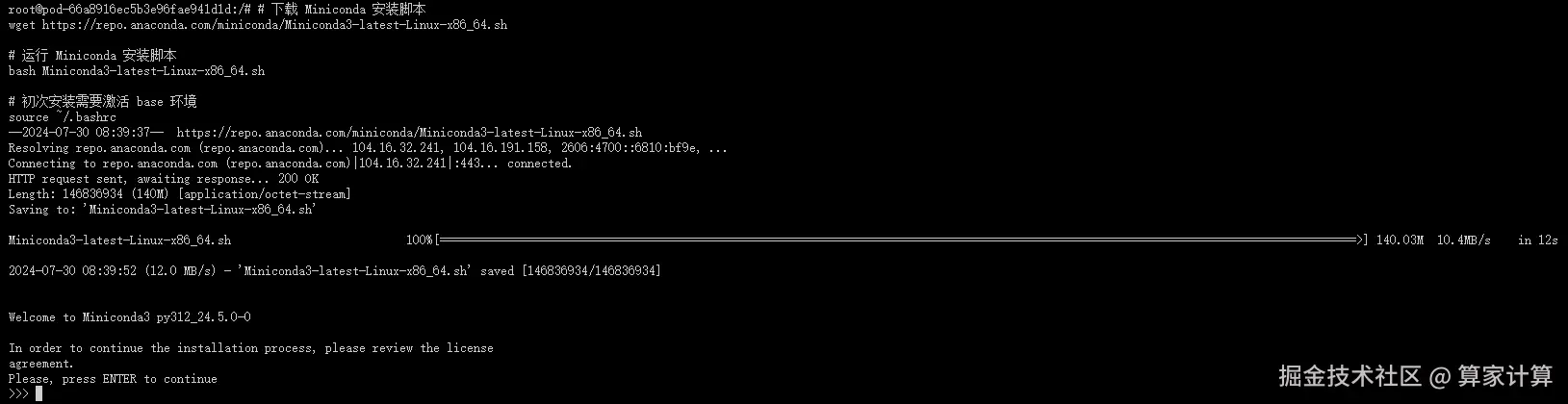
输入 yes
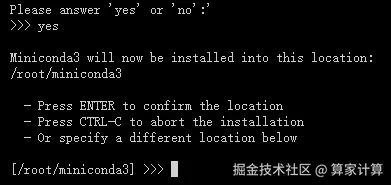
输入 yes
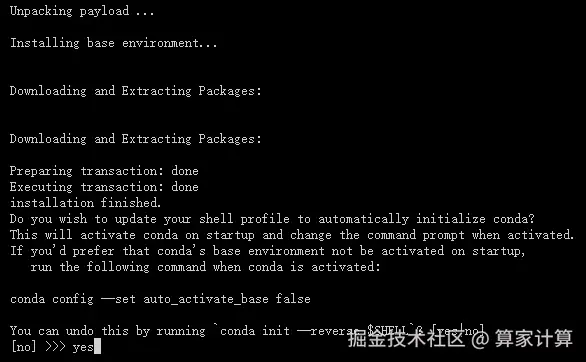
安装成功如下图所示
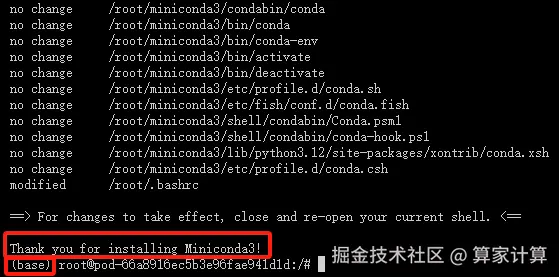
pip 配置清华源加速
bash
# 编辑 /etc/pip.conf 文件
vim /etc/pip.conf加入以下代码
ini
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple注意事项:
- 请确保您的系统是 Linux x86_64 架构,因为下载的 Miniconda 版本是为该架构设计的。
- 在运行安装脚本之前,您可能需要使用
chmod +x Miniconda3-latest-Linux-x86_64.sh命令给予脚本执行权限。 - 安装过程中,您将被提示是否同意许可协议,以及是否将 Miniconda 初始化。通常选择 "yes" 以完成安装和初始化。
- 安装完成后,您可以使用
conda命令来管理 Python 环境和包。 - 如果链接无法访问或解析失败,可能是因为网络问题或链接本身的问题。请检查网络连接,并确保链接是最新的和有效的。如果问题依旧,请访问 Anaconda 的官方网站获取最新的下载链接。
3. 从 github 仓库 克隆项目
- 克隆存储库:
bash
# 克隆项目
git clone https://github.com/PaddlePaddle/PaddleOCR请注意,如果 https://github.com/PaddlePaddle/PaddleOCR 这个链接不存在或者无效,git clone 命令将不会成功克隆项目,并且会报错。确保链接是有效的,并且您有足够的权限访问该存储库。
4. 创建虚拟环境
ini
# 创建一个名为 env 的新虚拟环境(名字可自定义),并指定 Python 版本为 3.10
conda create -n env python=3.10 -y5. 安装模型依赖库
- 切换到项目目录、激活 env 虚拟环境、安装 requirements.txt 依赖
bash
# 切换到 PaddleOCR 项目工作目录
cd /PaddleOCR
# 激活 env 虚拟环境
conda activate env
# 在 env 环境中安装依赖
pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
pip install -U "paddleocr[all]"
pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
pip install -r requirements.txt6. 运行 app.py 文件
bash
#运行app.py
cd /PaddleOCR
conda activate env
python app.py三、网页演示
出现以下 Gradio 页面,代表模型已搭建完成。