美团开源首个视频大模型,一出手就是SOTA级别。
今天,"送外卖"的美团正式发布了名为LongCat-Video的开源视频生成模型。

作为美团首个开源视频大模型,LongCat-Video拥有136亿参数,在文生视频、图生视频两大核心任务中综合性能达到了当前开源领域的SOTA级别。其部分核心维度表现甚至可与谷歌最新、最强的闭源模型Veo3相媲美。
技术突破:从短视频到5分钟长视频的跨越
LongCat-Video的突出能力在于其出色的长视频生成表现。该模型能够稳定输出5分钟级别的长视频,且无质量损失,达到了行业顶尖水平。
长视频生成一直是行业的难点问题。传统方法在生成长视频时往往面临色彩漂移、画质降解、动作断裂等痛点。而LongCat-Video通过原生视频续写任务预训练,从根源上规避了这些问题,保障了跨帧时序一致性与物理运动合理性。
模型采用Diffusion Transformer(DiT)架构,创新性地通过"条件帧数量"实现任务区分。这一设计使单个模型原生支持三大核心任务:文生视频无需条件帧、图生视频输入1帧参考图、视频续写依托多帧前序内容,形成了完整的任务闭环。
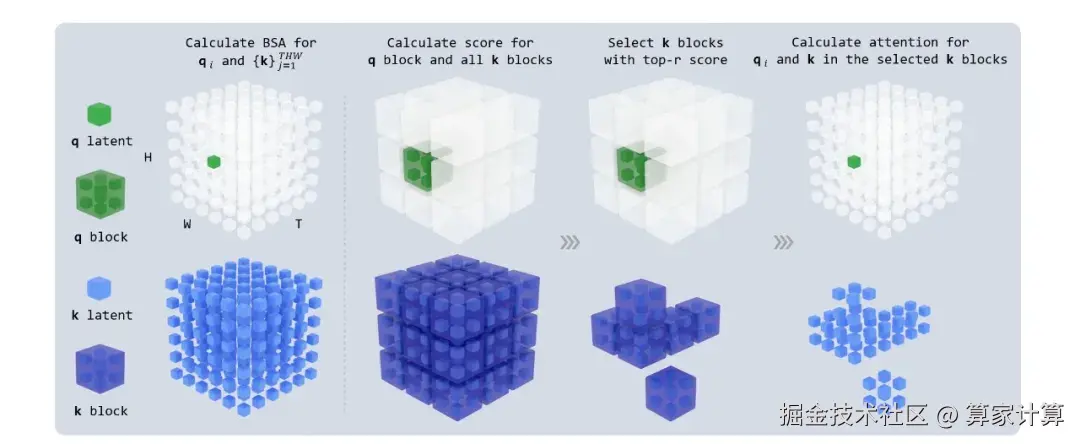
在效率优化方面,研究团队通过"二阶段粗到精生成+块稀疏注意力+模型蒸馏"三重优化策略,将视频推理速度提升至10.1倍,实现了效率与质量的最佳平衡。
美团对LongCat-Video的定位远不止于一个视频生成工具。官方表示,此次发布的视频生成模型是为探索"世界模型"迈出的第一步。
世界模型因其能让AI真正理解、预测甚至重构真实世界,被业界视作通往下一代智能的核心引擎。作为能够建模物理规律、时空演化与场景逻辑的智能系统,世界模型能赋予人工智能"看见"世界运行本质的能力。
美团LongCat团队认为,视频生成模型有望成为构建世界模型的关键路径。通过视频生成任务压缩几何、语义、物理等多种形式的知识,AI得以在数字空间中模拟、推演乃至预演真实世界的运行。
性能表现
根据技术报告,LongCat-Video的评估围绕内部基准测试和公开基准测试展开,覆盖文本生成视频、图像生成视频两大核心任务。
在VBench等公开基准测试中,LongCat-Video在参评模型中整体表现优异。具体数据显示,该模型在文本对齐度、运动连贯性等关键指标上展现显著优势,仅次于Veo3和Vidu Q1。
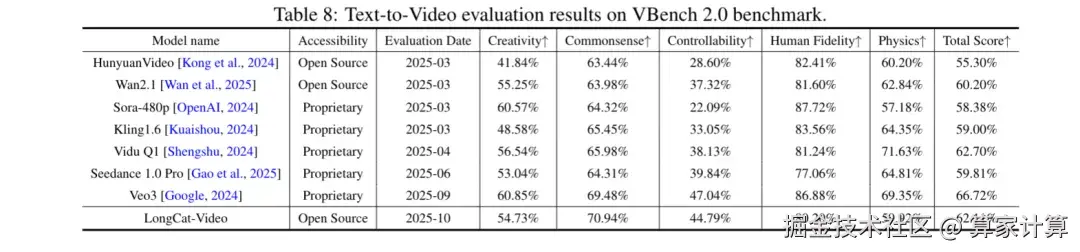
值得注意的是,LongCat-Video在常识性维度(运动合理性、物理定律遵循)上处于第一的领先优势,凸显了优秀的物理世界建模能力。
对于用户而言,这意味着生成的视频内容不仅视觉上逼真,在物理规律遵循方面也更加符合真实世界的运行逻辑。
例如,模型生成的"水上芭蕾"视频,既需要具备高度的细节捕捉能力,还需要能够处理复杂的光影效果、环境模拟和动态场景。
LongCat-Video采用的是MIT开源协议,商业使用的高自由度使得Hugging Face高级主管甚至用三连问来表示惊叹:"中国团队竟然发布了一个MIT协议的基础视频模型???"

对于整个视频生成领域,LongCat-Video的开源意味着什么?有评论认为,其长视频生成能力(稳定输出5分钟)表明"我们离视频AI的终极形态又更进一步"。
一个"送外卖"的公司为何要研发视频大模型?
其实,这已经不是美团第一次"不务正业"了。从八月底开始,美团龙猫大模型就在不停地发布新品,先是推出了开源基础模型LongCat-Flash-Chat,随后又上线了LongCat-Flash-Thinking,在逻辑、数学、编码、Agent多任务中均达成SOTA水平。

美团CEO王兴曾在财报电话会议中阐述AI战略:"AI将颠覆所有行业,我们的策略是主动进攻而非被动防御。" 据王兴当时披露,美团对于AI的部署分为三个层面:分别是AI在工作中的应用、AI在产品中的应用以及构建美团内部大语言模型。
随着AI技术在视频领域的不断渗透,未来视频创作或许会迎来一场新的变革。
美团的这次跨界创新也提供了一个有趣案例:当AI技术日益成熟,行业边界正在变得模糊。
在这个快速演进的AI时代,美团的LongCat-Video或许只是一个开始。