这次最大的感受:Re做题的时候不要啥都没分析出来就去写代码,不要觉得自己写着写着就能看懂,不可能的,不如先分析好,即使是先猜一下呢,还有就是测试数据不要写0,会和本身就是空的数据混了
Re1
分最少的一题,附件很大而且F12全是Py开头的
断定是python逆向:
pyinstxtractor拆exe程序:

一般情况下,需要找和附件同名的pyc文件进行反编译,但是没找到,比较可疑的是src这个
用pycdc进行反编译:
python
# Source Generated with Decompyle++
# File: src.pyc (Python 3.10)
import hashlib
def get_user_input():
user_input = input('请输入: ').strip()
if len(user_input) != 9:
print('你的输入存在错误!')
continue
if not user_input.isdigit():
print('你的输入存在错误!')
continue
return user_input
def check_md5_match(user_input, target_hash):
input_md5 = hashlib.md5(user_input.encode()).hexdigest()
if input_md5 == target_hash:
return True
def main():
TARGET_HASH = 'b4bb721a74f07177a6dbc3e113c327e3'
user_input = get_user_input()
is_match = check_md5_match(user_input, TARGET_HASH)
if is_match:
flag = "flag{md5(user_input + 'SDnisc')}"
print('验证成功!')
print(f'''Flag: {flag}''')
return None
None('验证失败!')
if __name__ == '__main__':
main()
return None可以看出,首先会对input的内容去除回车和空格/制表符那种
if not user_input.isdigit():其次,不能存在字母,长度为9,进行md5值计算,然后和给出的md5进行比较
所以,结论很明确了,我们只需要进行9位纯数字的md5爆破就可以。
我们当然可以用python写个脚本。但事实证明特别慢,不如用hashcat掩码爆破
hashcat -a 3 b4bb721a74f07177a6dbc3e113c327e3 ?d?d?d?d?d?d?d?d?d -m 0
这里就不进行爆破了,直接给了

然后直接后面加上SDisc,进行md5就是flag
Re2
比较绕,但是比赛还是可以做的(虽然我最后卡死在这上面了)
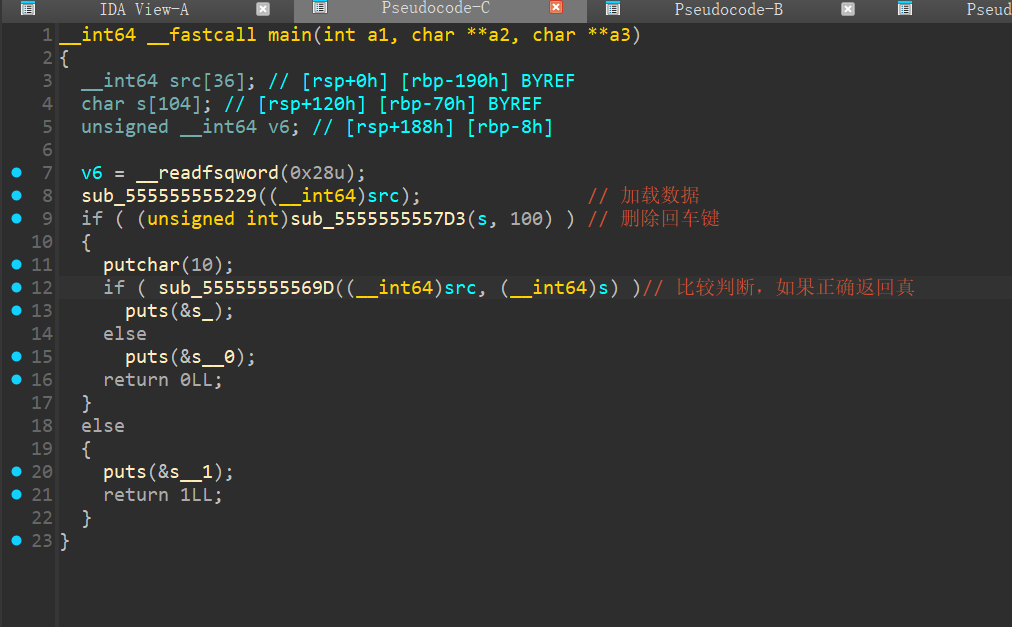
大体看一下,去关注569D那个函数,这是主要的加密函数
但在那之前,我先写一下数据加载的函数
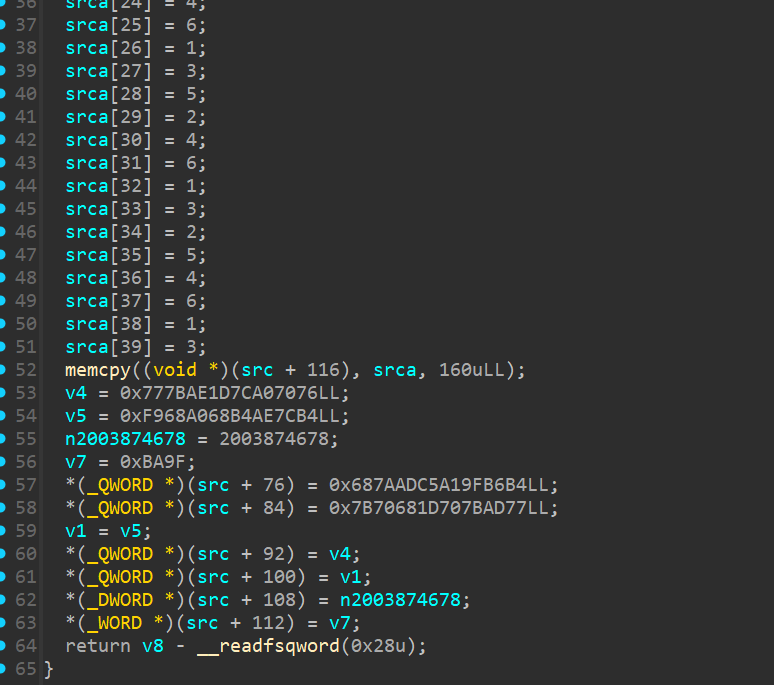
你会发现,所有数据都是在src后76位上开始向后延申数据的,srca是在src的最后,也就是116位以后的160个字节空间内
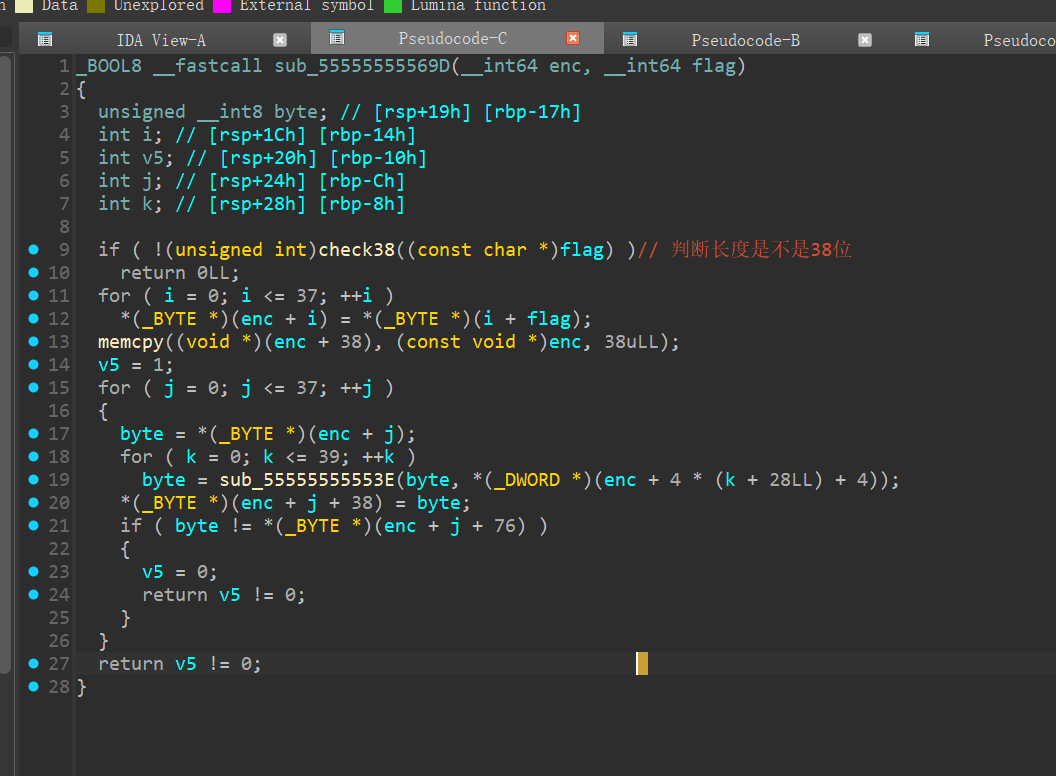
这个函数传入了两个值,一个是enc,也就是加密好的flag,另一个是写进去的flag
首先是判断长度,这里就不详细看了

我感觉这里是最能误导人的点,它把写入的flag的值赋给了加密好的flag?但是实质上,enc的前76位是空的,所以写这个完全没有问题
然后是逐字节加密,每个字节加密40次,第一次加密的时候,传入第一个值的地点是4*28+4=116,很熟悉的位置吧?
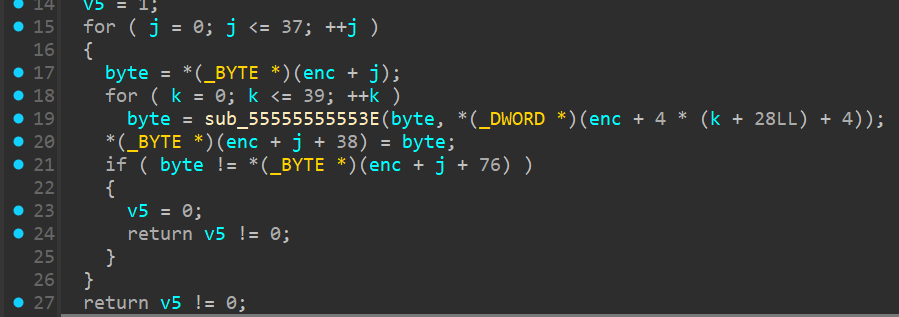
剩下的就是很乱的加密过程了,这里不详细赘述
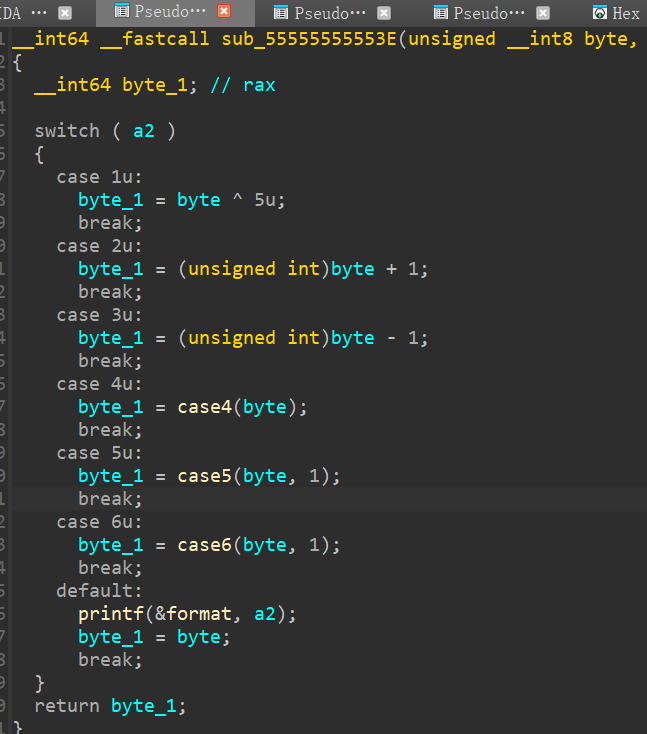
这里说一下,误导我的点:
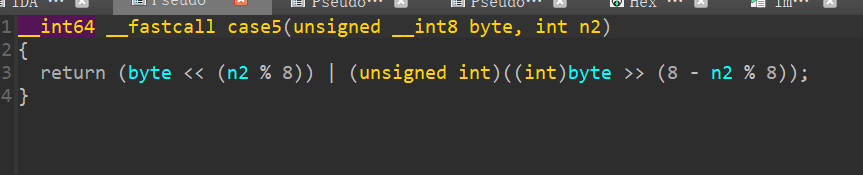
还是太菜了,被位运算卡住了,这里其实画个图会比较清晰,这里相当于左移n2位,然后将溢出的n2位移动到最后,所以我们写逆向代码的时候就要反过来(其实只需要把输入的键反过来就行)
这里贴一下手写的脚本,感觉要比ai给的清晰一点
python
# 本脚本是鹏云杯逆向第三个题,相当于第二个简单的题吧(一共就仨)
# 尝试手写python脚本
key = [0x3, 0x5, 0x1, 0x6, 0x2, 0x4, 0x5, 0x6, 0x3, 0x1, 0x2, 0x5, 0x4, 0x6, 0x1, 0x3, 0x2, 0x5, 0x4, 0x6, 0x1, 0x3, 0x2, 0x5, 0x4, 0x6, 0x1, 0x3, 0x5, 0x2, 0x4, 0x6, 0x1, 0x3, 0x2, 0x5, 0x4, 0x6, 0x1, 0x3]
enc = [0xB4, 0xB6, 0x9F, 0xA1, 0xC5, 0xAD, 0x7A, 0x68, 0x77, 0xAD, 0x7B, 0x70, 0x1D, 0x68, 0x70, 0x7B, 0x76, 0x70, 0xA0, 0x7C, 0x1D, 0xAE, 0x7B, 0x77, 0xB4, 0x7C, 0xAE, 0xB4, 0x68, 0xA0, 0x68, 0xF9, 0x76, 0xB3, 0x70, 0x77, 0x9F, 0xBA]
def switchEnc(en , key):
match key:
case 1:
en = (en ^ 5) & 0xFF
case 2:
en = (en - 1) & 0xFF
case 3:
en = (en + 1 )& 0xFF
case 4:
en = case4(en)
case 5:
en = case5(en, 1)
case _:
en = case6(en ,1)
return en
def case4(en1):
# en2 = case5(en1 + 3, 2)
# return (case6(en2 - 2, 2) - 1) & 0xFF
en2 = (case6((en1 + 1) & 0xFF ,2) + 2) & 0xFF
return (case5(en2, 2) - 3) & 0xFF
def case5(en1 ,n2):
n2 &= 7
en1 = en1 >> (n2 % 8) | en1 <<(8 - n2 % 8)
return en1 & 0xFF
def case6(en1 ,n2):
n2 &= 7
en1 = en1 << (n2 % 8) | en1 >>(8 - n2 % 8)
return en1 & 0xFF
print(len(enc))
for i in range(len(enc)):
for j in key[::-1]:
enc[i] = switchEnc(enc[i] , j)
print(chr(enc[i]),end="")对于溢出问题:我的建议是把所有加法后面都加上防止溢出的&FF