案例地址:IP信息备案
jsl讲解
特点:
- 请求三次,前两次请求失败状态码为521,或者cookie名字为jsl开头:
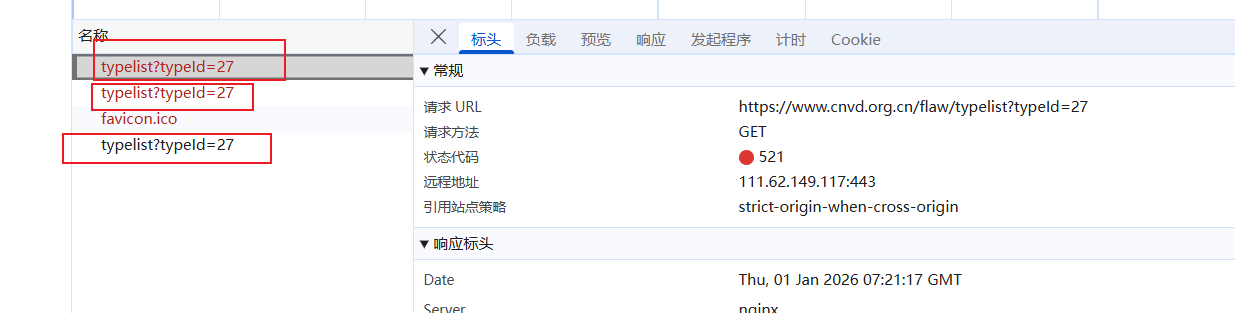

执行流程:
1.网站第一次请求返回一串简单js代码组成第二次请求的cookie
2.带着第一次产生的cookie发起第二次请求得到一大段js代码,此代码用于生成加密的cookie
3.带着加密cookie参数和第一次请求得到的cookie参数发起第三次请求得到数据
定位cookie位置
我们清除cookie后打开脚本断点,然后进入到第二次请求得到js代码的地方:
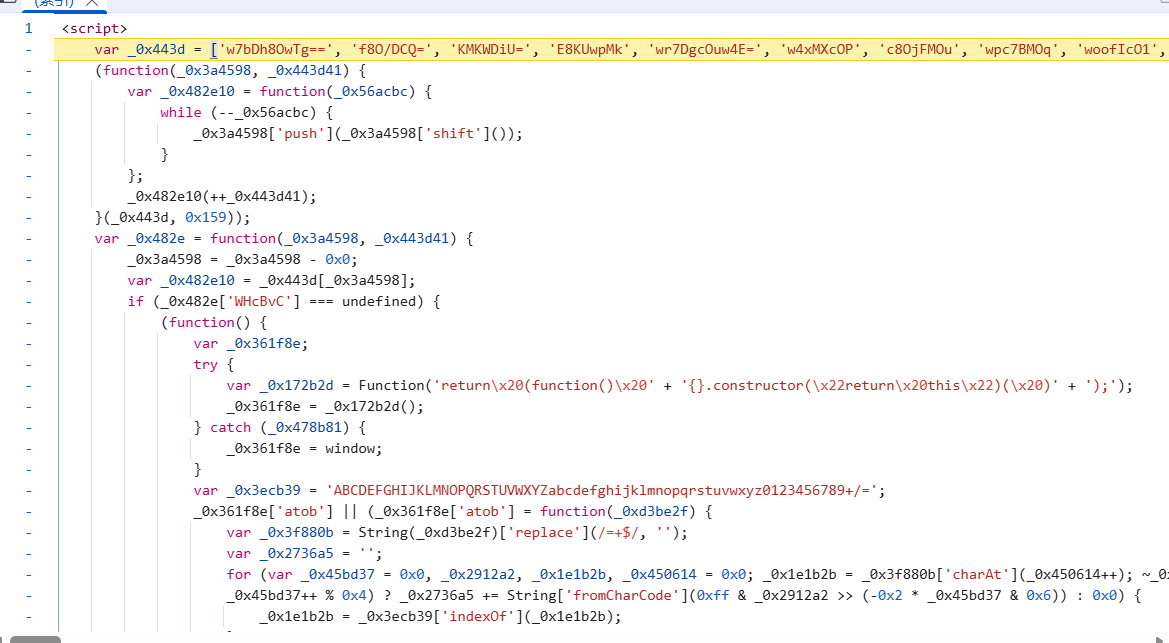
打开hook-cookie,hook到之后来到上一个栈:
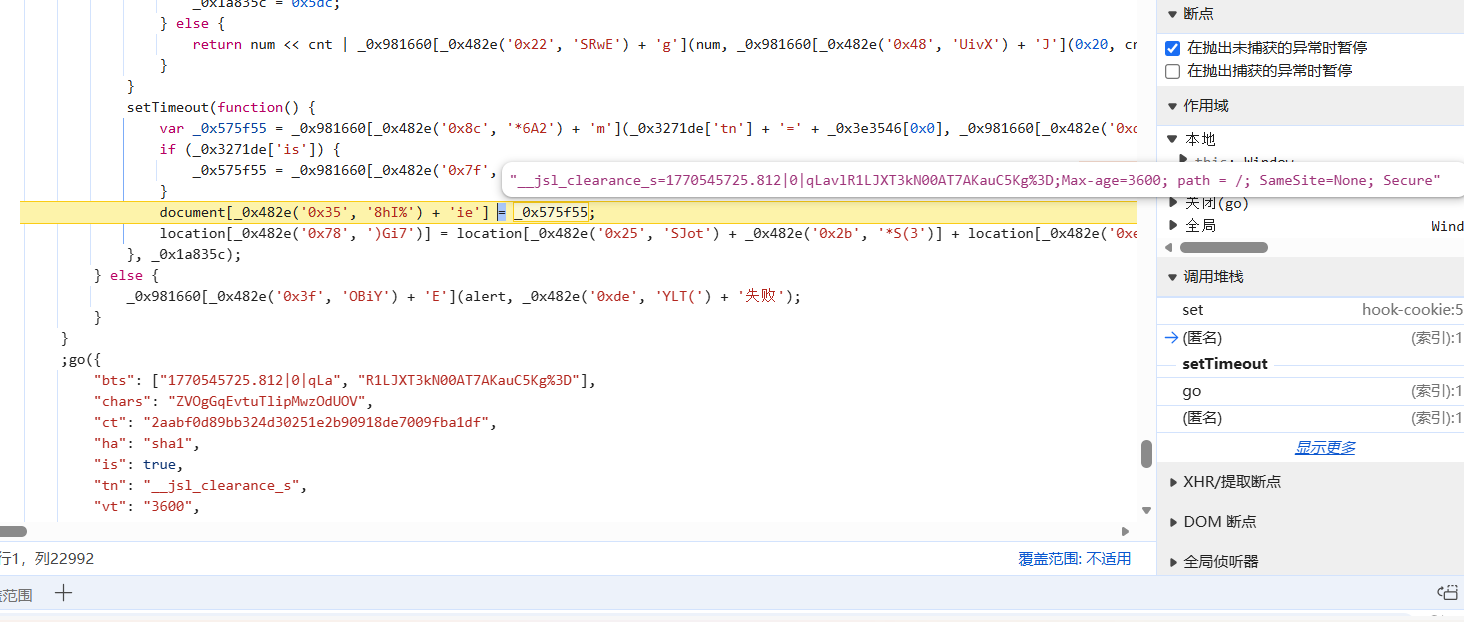
开始分析代码(最好将代码替换一下,固定下来)
分析js代码
这里我将结论贴上,大家可以根据网站来自行分析(其实一看我框的地方就不用分析了),很多函数基本都是拼接字符串用的,然后字符串都是固定的,除了path;后面的时间(要他也没啥用,不用管)
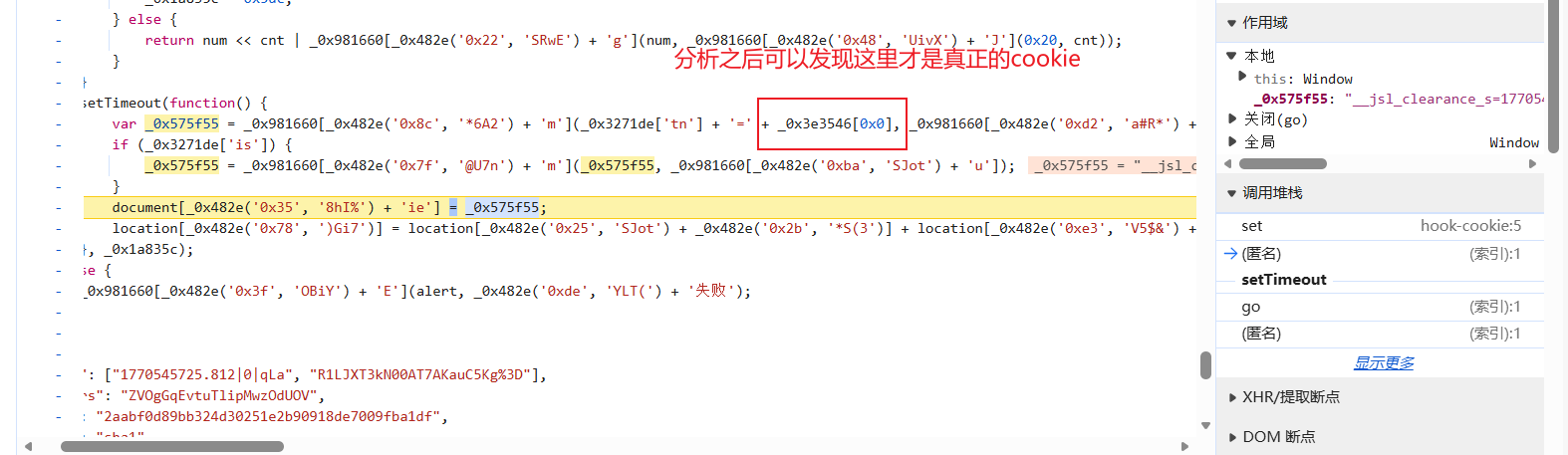
然后我们顺着这个数组网上找:
 找到生成位置之后,打断点跟过来分析:
找到生成位置之后,打断点跟过来分析:

这里第一个函数是用其第一个入参(函数)作用于后两个入参,熟悉的配方,直接跟进第一个参数中(函数):
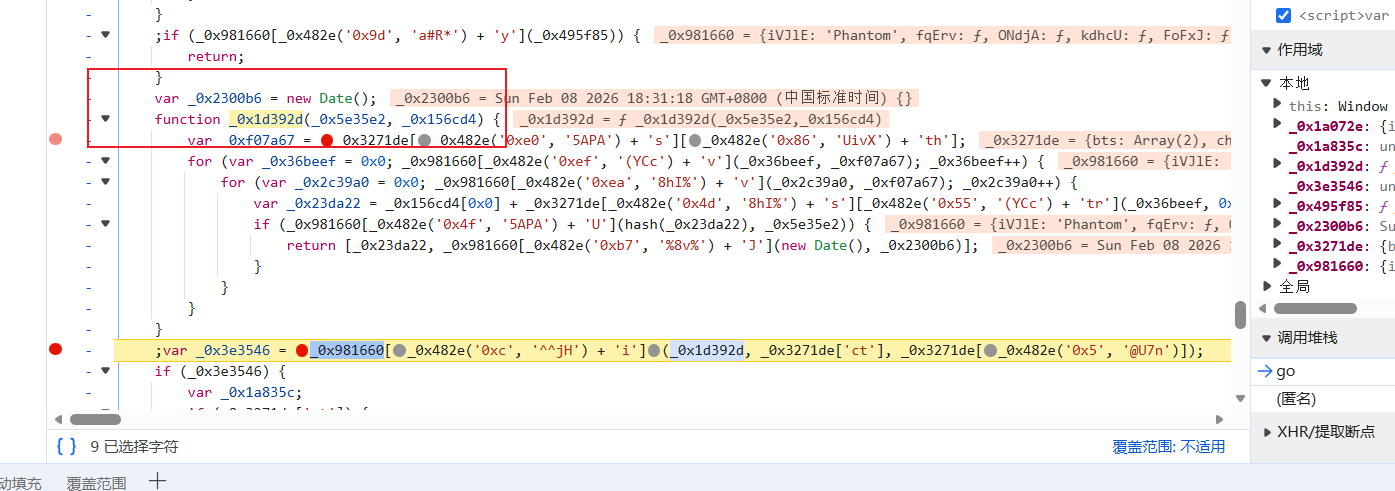
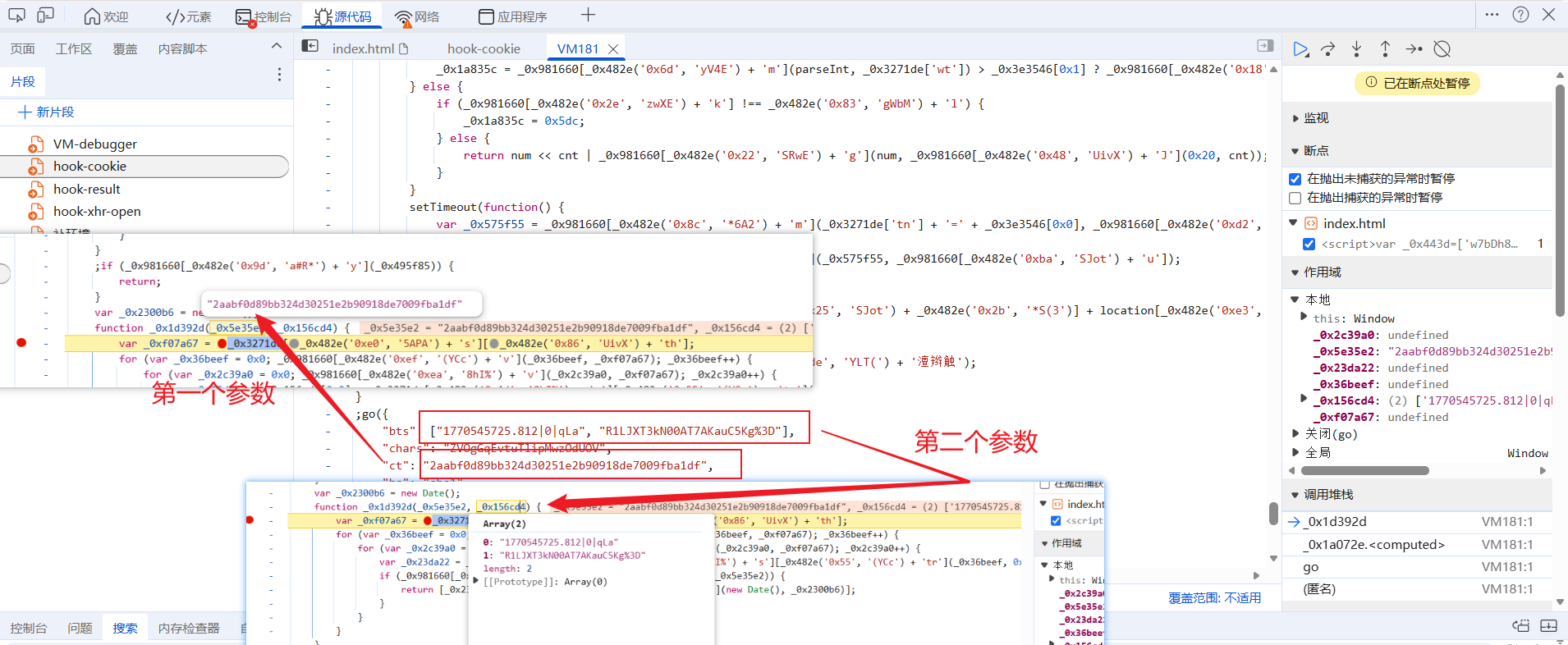
往里面一点一点跟,你会发现for循环遍历的次数是go入参的chars键的值的长度,然后通过循环取出chars的值里的字符来拼接到第二个入参两字符串中间,然后通过go入参规定的hash算法加密后和第一个入参对比,一样后停止循环然后得到cookie:
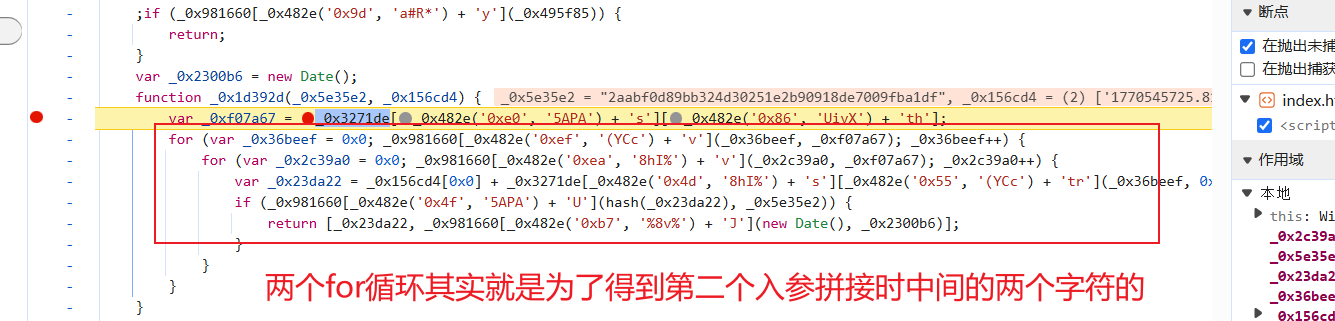
其实核心代码就是这里了,可以看一下返回值:
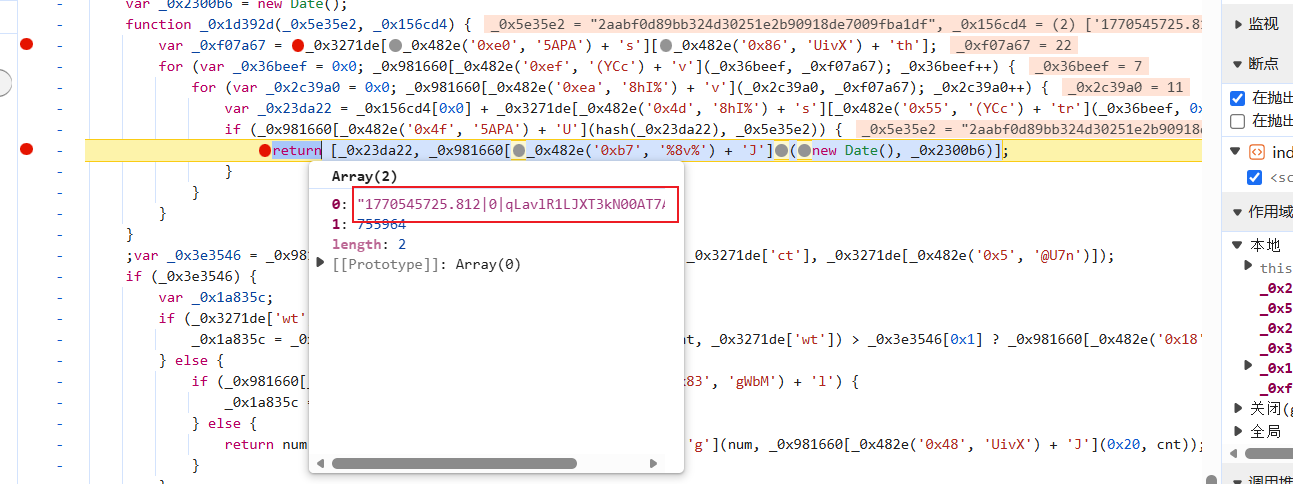
OK,我们直接开扣
扣代码
扣下来函数调用和函数:
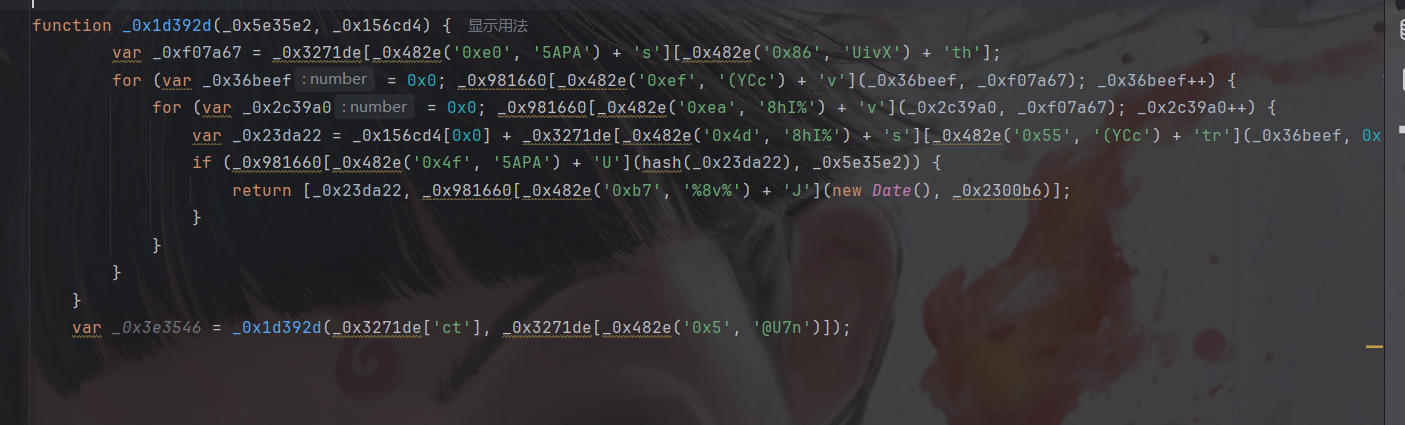
然后补一下go的入参:
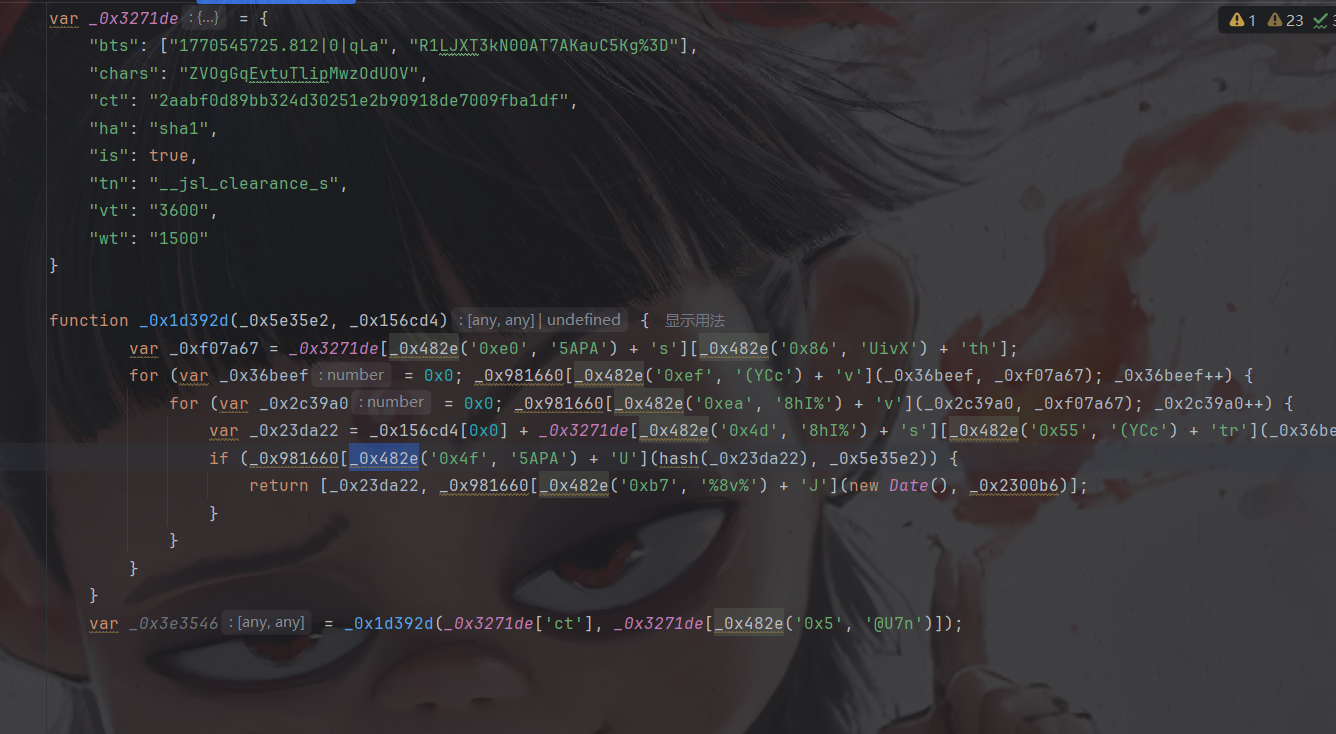
然后函数返回就需要第一个,所以把第二个删掉:
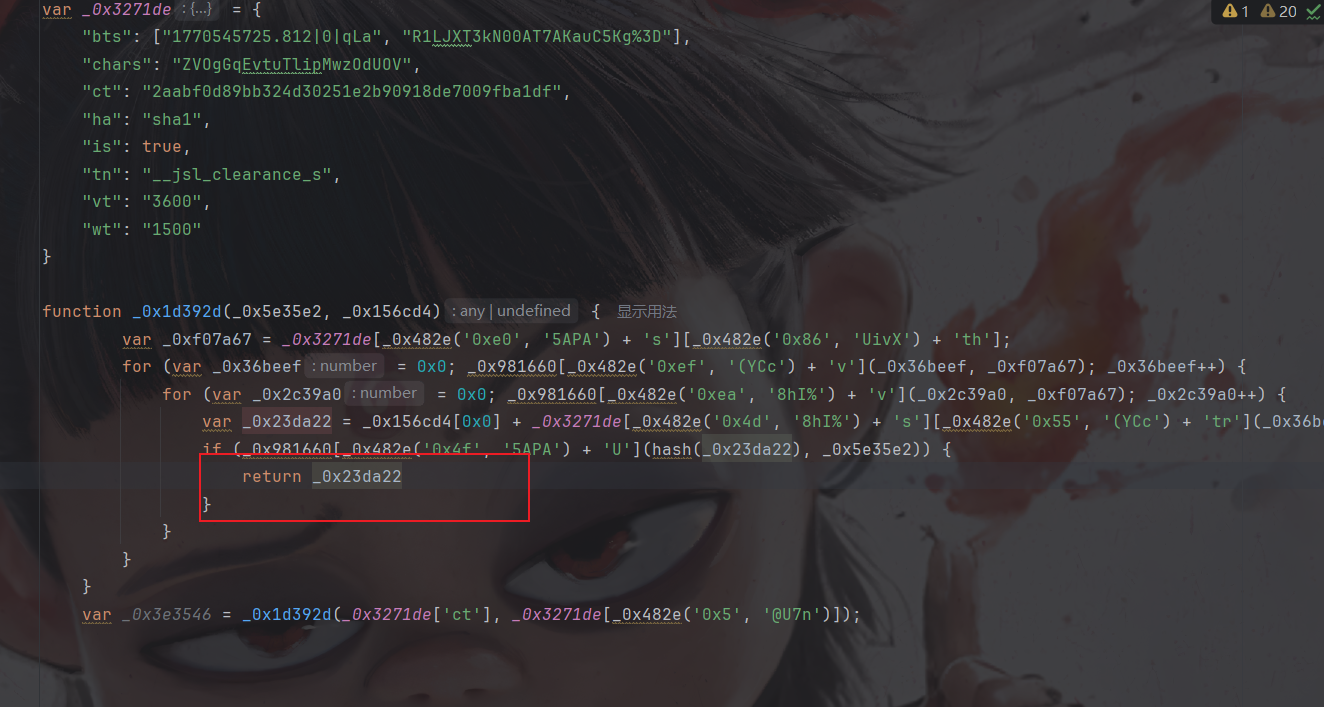
然后可以选择将解密函数,大数组,自执行拿过来(这么拿的话基本就相当于全扣了),然后将一些第一个参数作用在第二个参数的函数手动删除,但我选择手动还原一下:
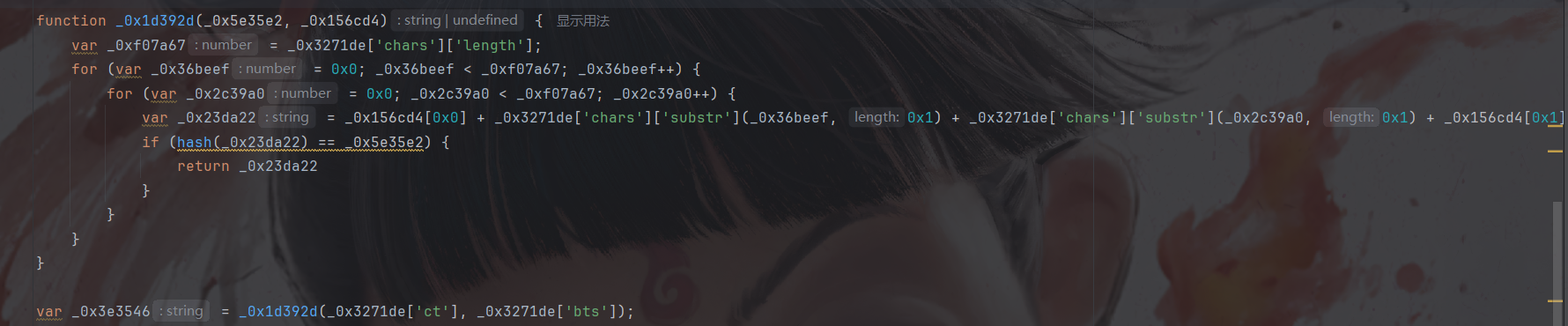
然后补上hash函数以及go参数:
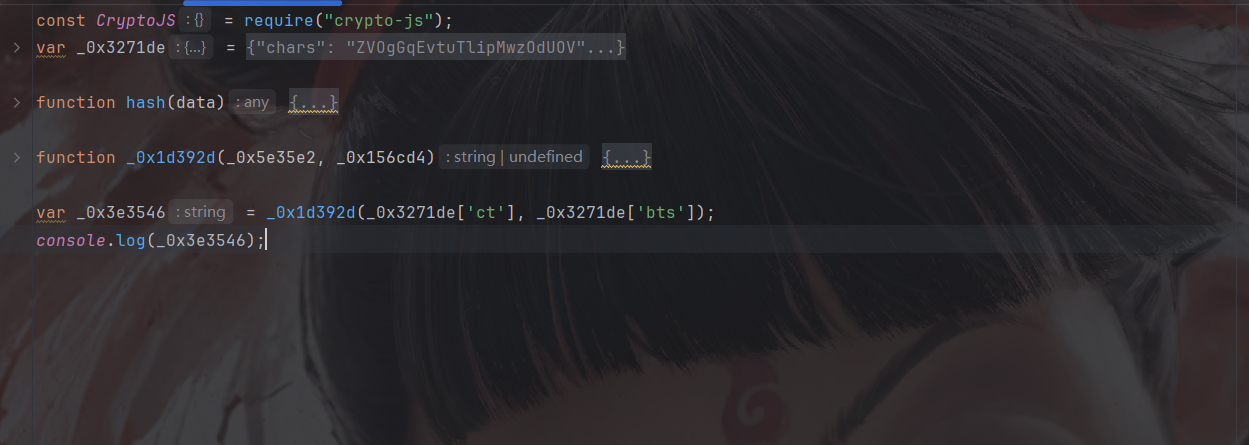
这样运行就能得到结果了,然后我们交给ai大模型给我们做一个纯算
纯算
直接出结果
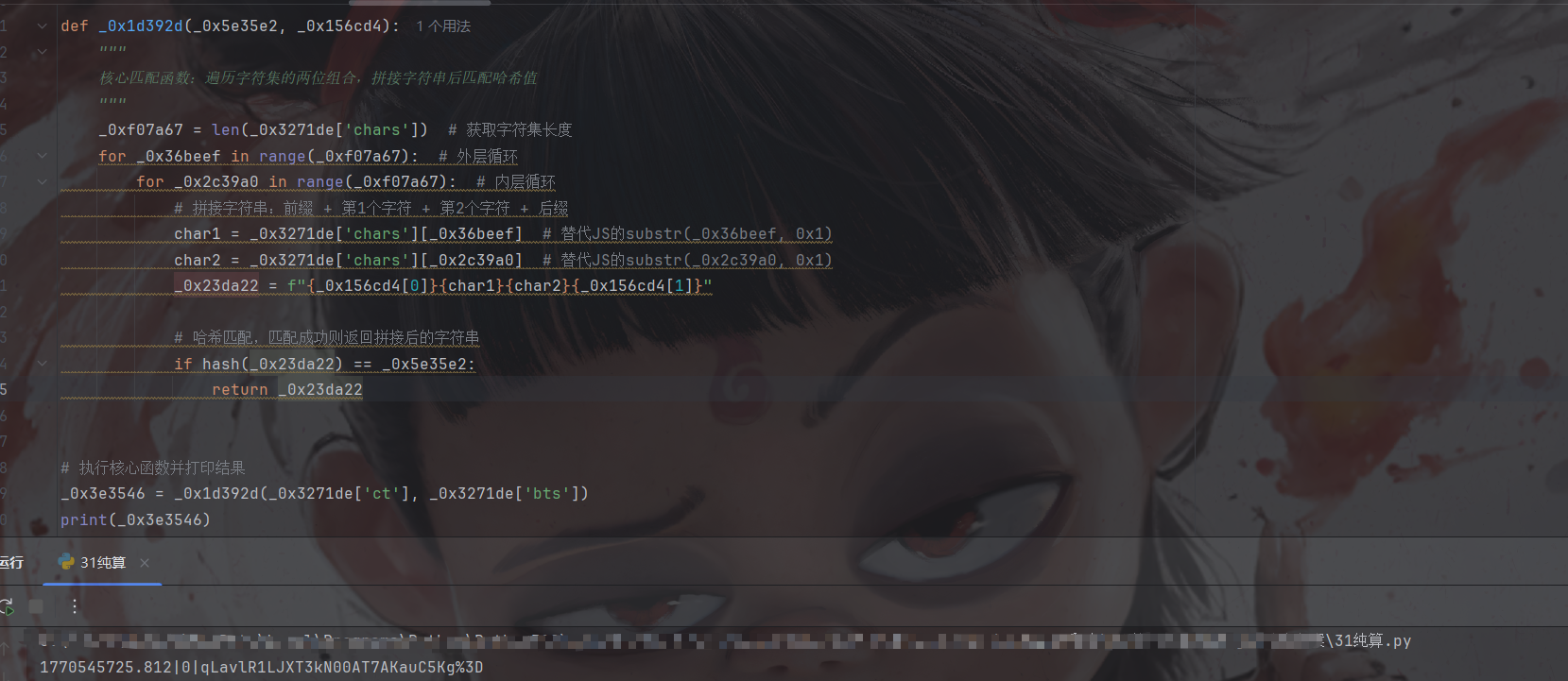
小结
之前我们说拿gov那个案例做,但是那个抖音我出视频了,所以就换了一个网站,逻辑都是一样的,文章如有问题请及时提出,加油加油