ELK 日志分析平台核心组件部署与日志收集指南
ELK(Elasticsearch、Logstash、Kibana)及轻量级日志收集工具 Filebeat 展开,详细阐述了 Kibana 部署与使用、Filebeat 安装配置及日志收集流程,同时对比了 Filebeat 与 Logstash 的差异,旨在帮助用户掌握 ELK 生态下的日志管理能力
一、Kibana:Elasticsearch 可视化与管理平台
Kibana 是开源可视化平台,提供 Web 界面用于 Elasticsearch 集群管理、日志汇总分析与搜索,官方文档路径为https://www.elastic.co/guide/en/kibana/current/setup.html
1. 部署流程(以 VM1 服务器为例,版本 6.5.2)
| 步骤 | 操作命令与说明 |
|---|---|
| 1. 安装 Kibana | 下载 RPM 包并安装:wget https://artifacts.elastic.co/downloads/kibana/kibana-6.5.2-x86_64.rpm``rpm -ivh kibana-6.5.2-x86_64.rpm |
| 2. 配置核心参数 | 编辑配置文件/etc/kibana/kibana.yml(过滤注释与空行后关键配置):server.port: 5601(服务端口)server.host: "0.0.0.0"(监听所有 IP,允许外部访问)elasticsearch.url: "http://10.1.1.12:9200"(连接 Elasticsearch 集群地址)logging.dest: /var/log/kibana.log(日志路径,需手动创建并授权)创建日志文件并修改权限:touch /var/log/kibana.log``chown kibana.kibana /var/log/kibana.log |
| 3. 启动并设置开机自启 | systemctl start kibana(启动服务)systemctl enable kibana(设置开机自启)lsof -i:5601(验证端口是否监听,进程用户为 kibana) |
| 4. 访问验证 | 浏览器输入http://Kibana服务器IP:5601,进入 Kibana 首页 |
2. 汉化配置
-
下载汉化包:
wget https://github.com/anbai-inc/Kibana_Hanization/archive/master.zip -
解压到指定目录:
unzip Kibana_Hanization-master.zip -d /usr/local -
执行汉化脚本(需提前安装 Python,RPM 版 Kibana 安装目录为):
/usr/share/kibana/ cd /usr/local/Kibana_Hanization-master/ python main.py /usr/share/kibana/ -
重启 Kibana 生效:
systemctl stop kibana && systemctl start kibana
3. 核心功能使用
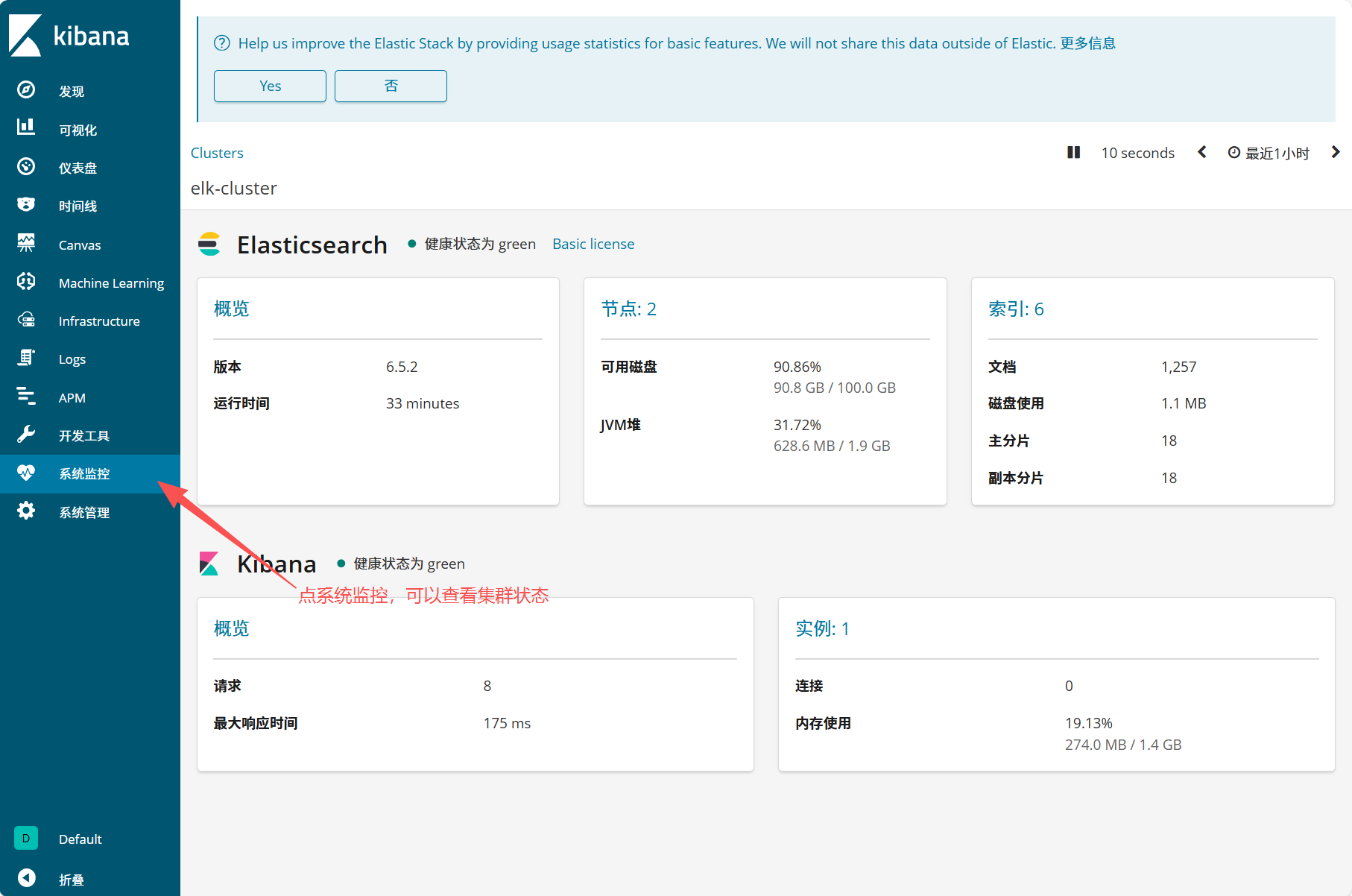
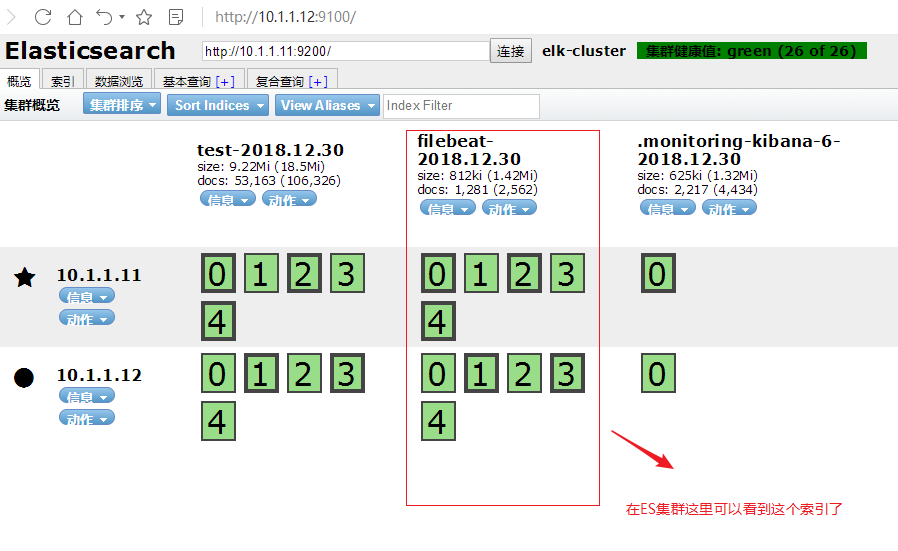
(1)查看 Elasticsearch 集群信息
- 进入 Kibana 界面,点击左侧 "系统管理"→"Elasticsearch"→"概览"
- 可查看集群状态(健康状态为 green 表示正常)、节点数(如 2 个)、索引数(如 4 个)、JVM 堆内存使用、磁盘可用率等关键指标
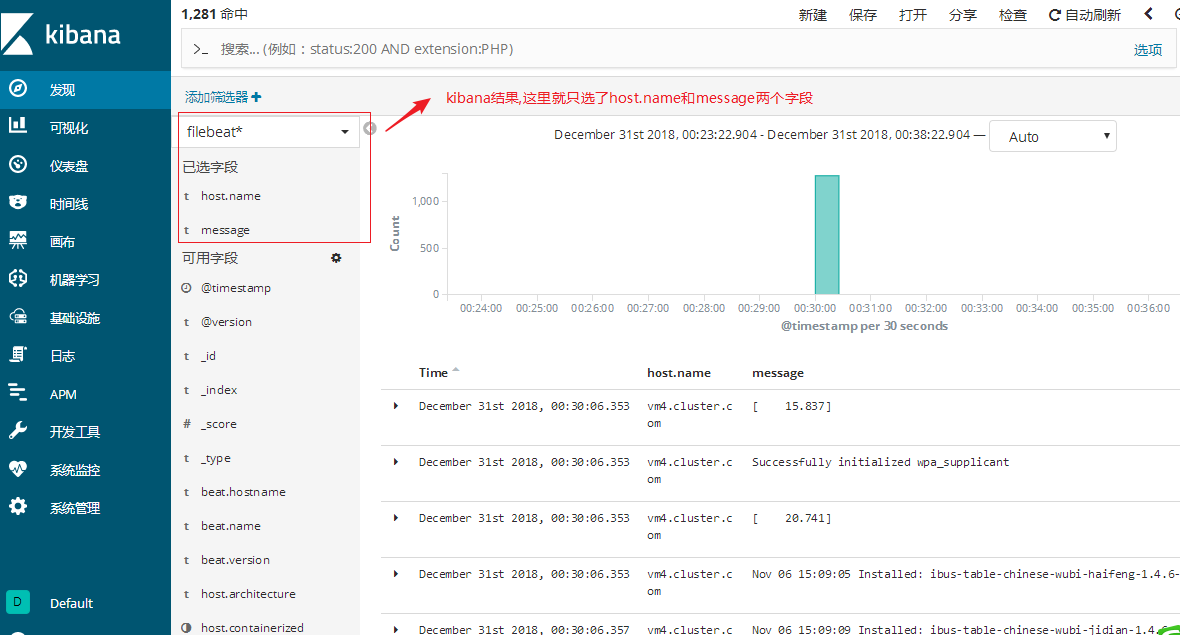
(2)查看 Logstash 日志索引
- 点击 "系统管理"→"Kibana"→"索引模式"
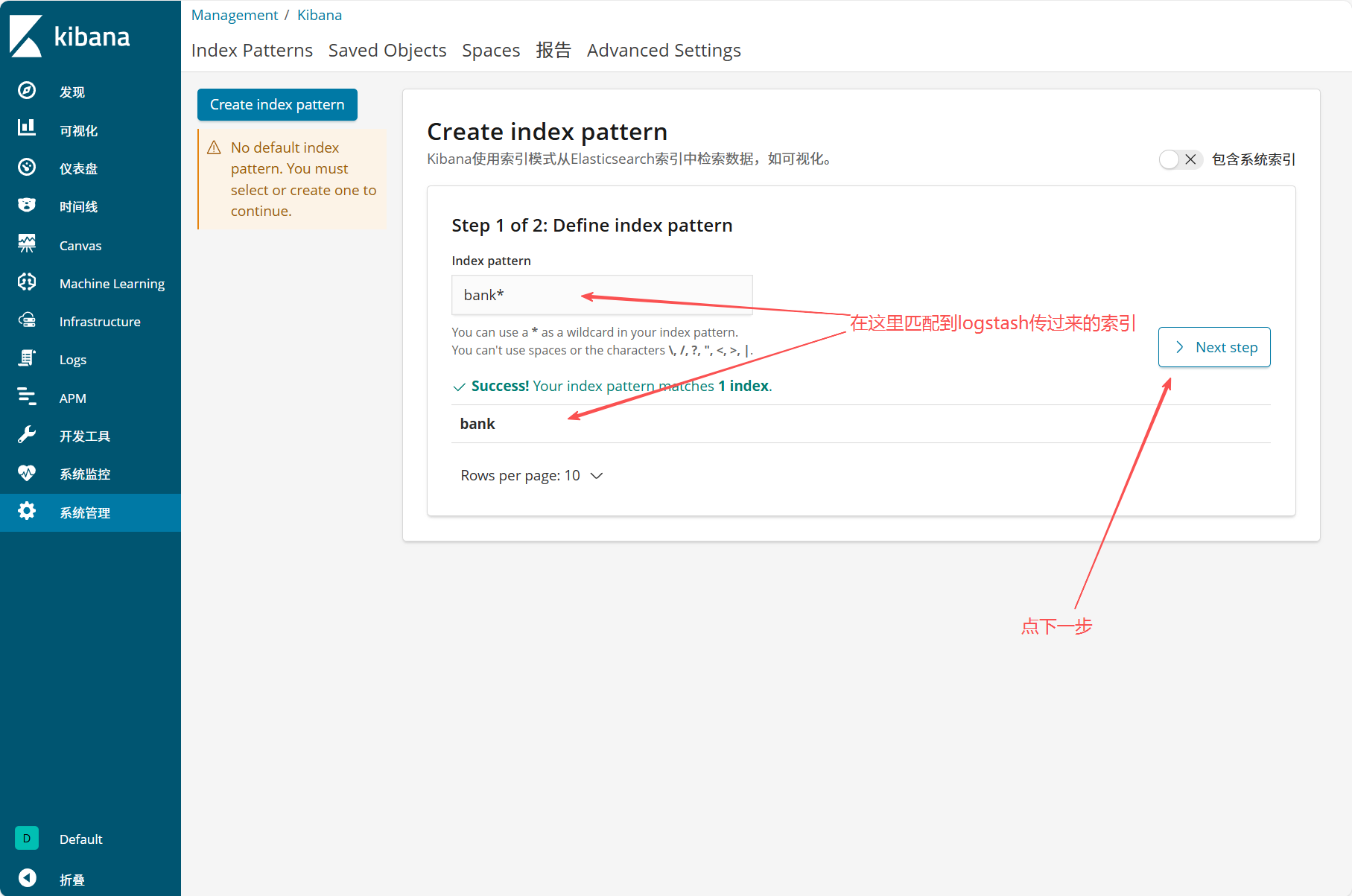
- 点击 "Create index pattern",输入索引匹配规则(如
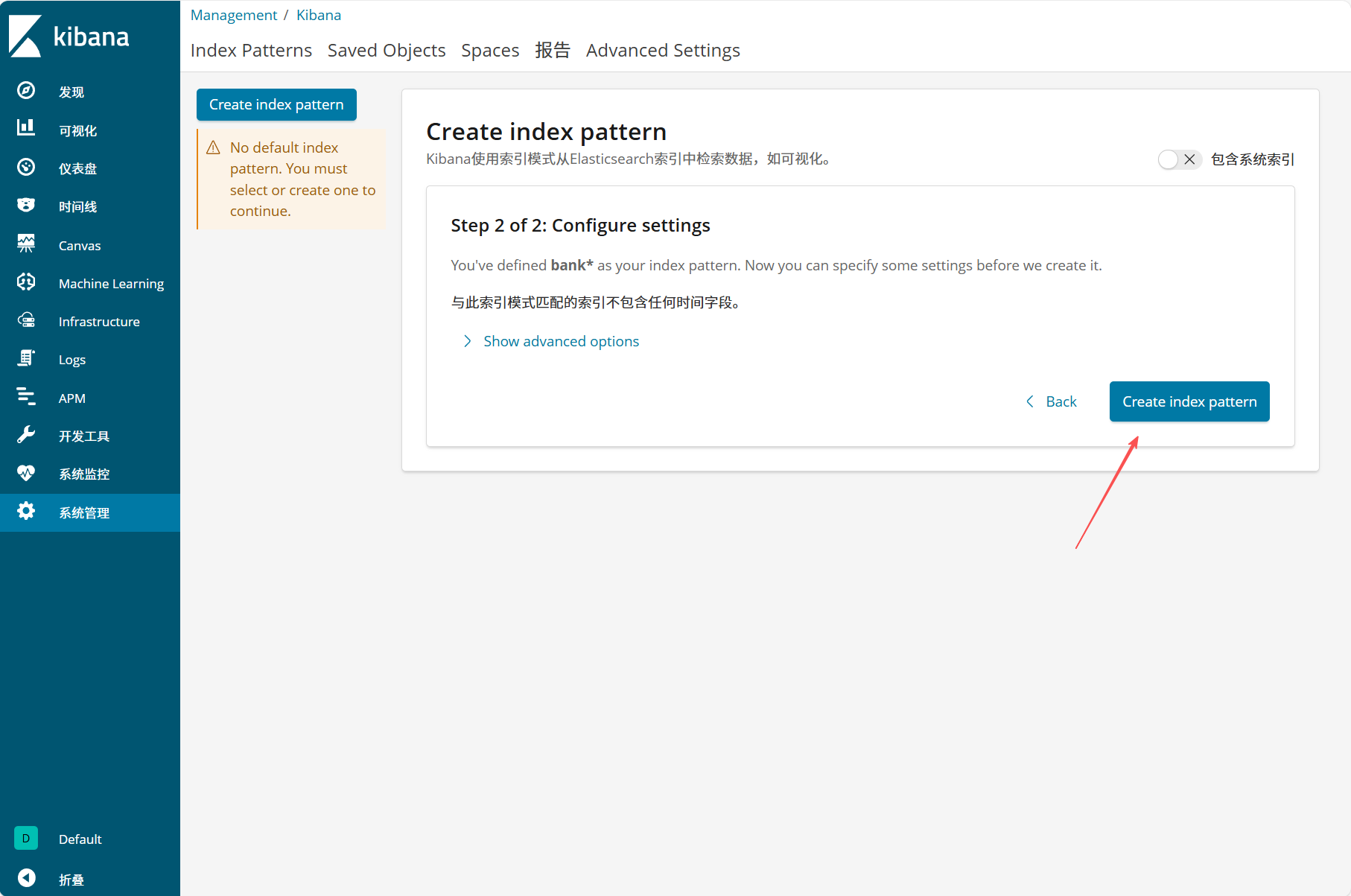
test*,匹配 Logstash 传输的索引),点击 "Next step" - 可选设置时间过滤字段(如
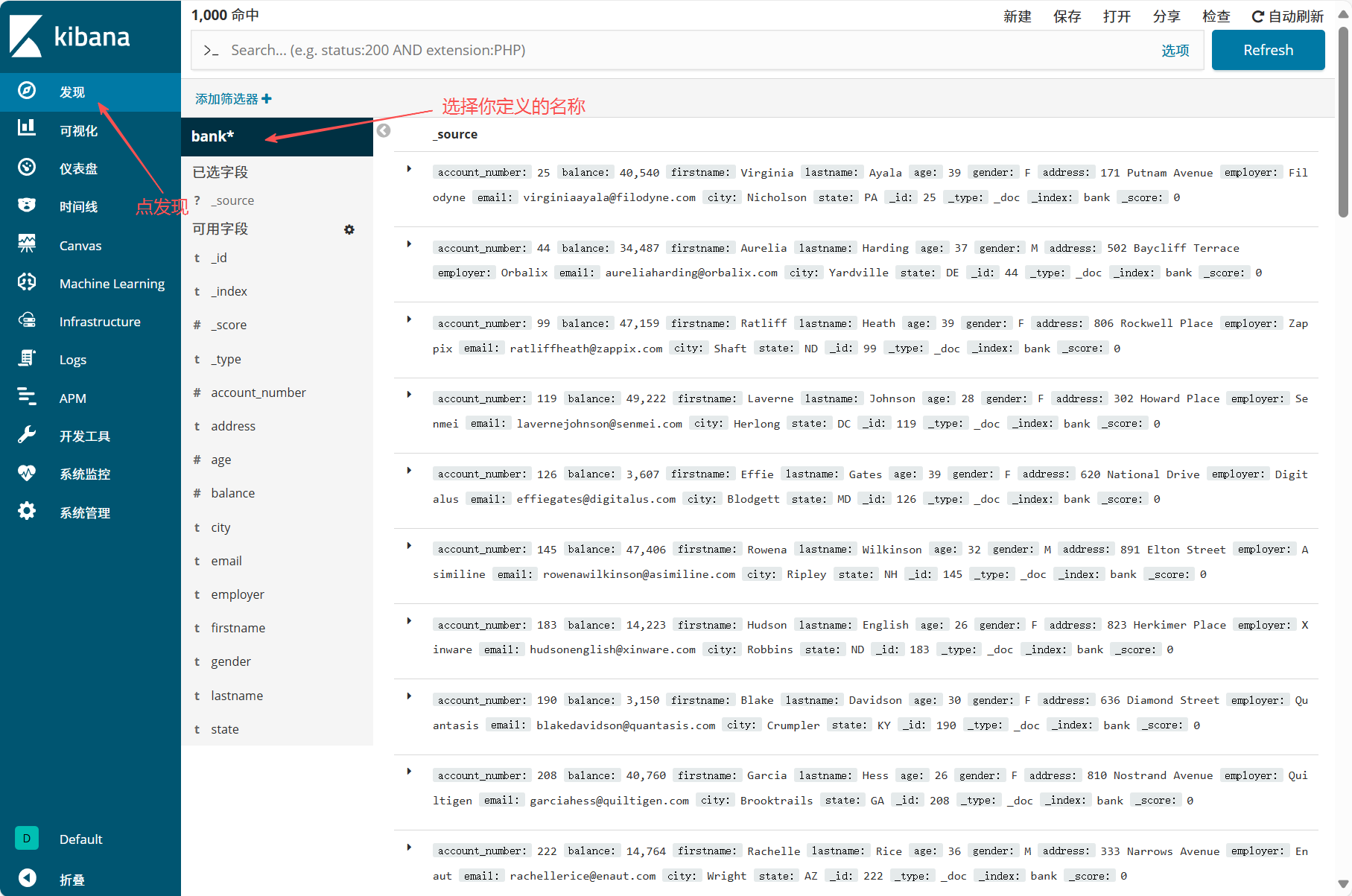
@timestamp),完成后点击 "Create index pattern" - 进入 "发现" 模块,选择创建的索引模式,即可查看日志数据
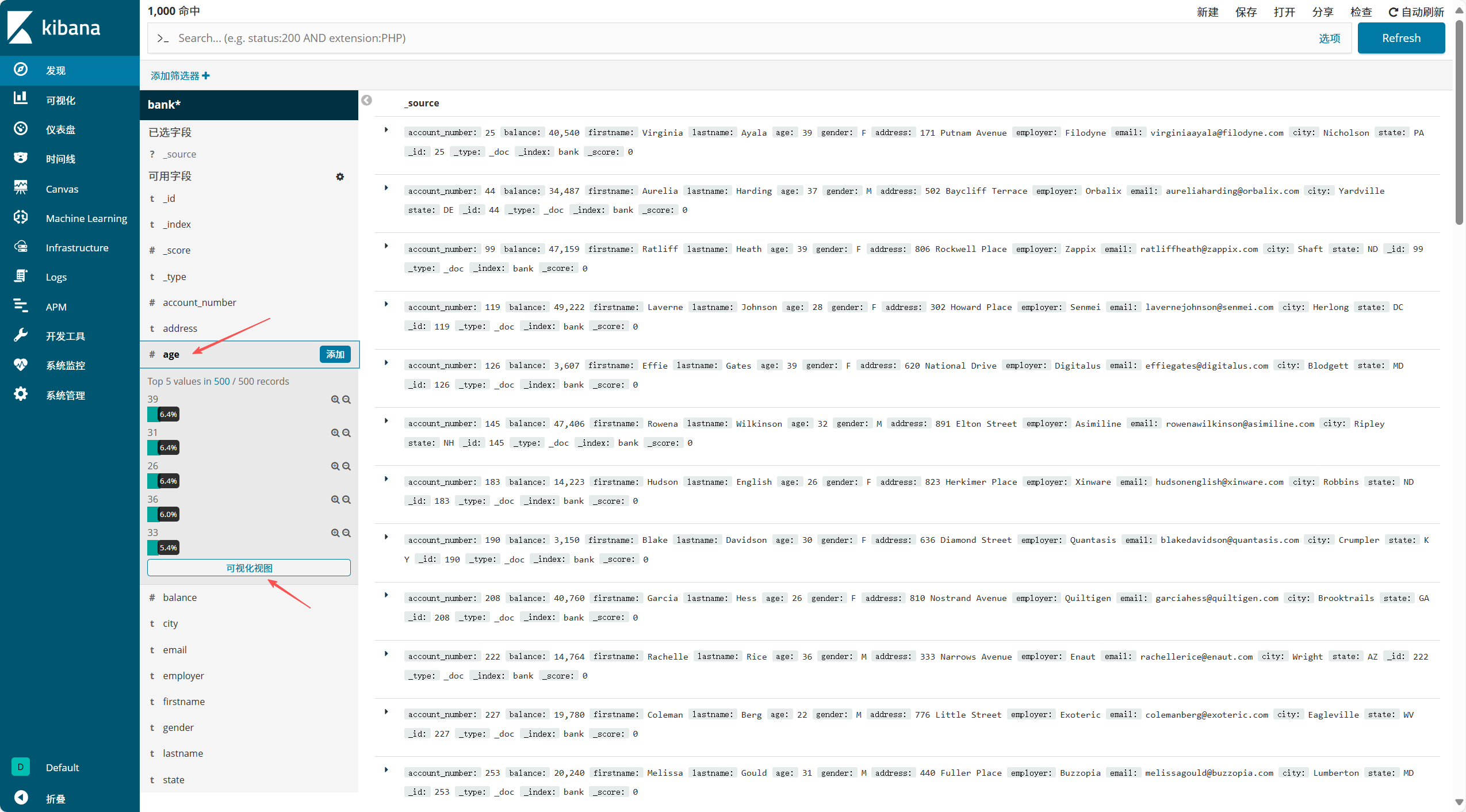
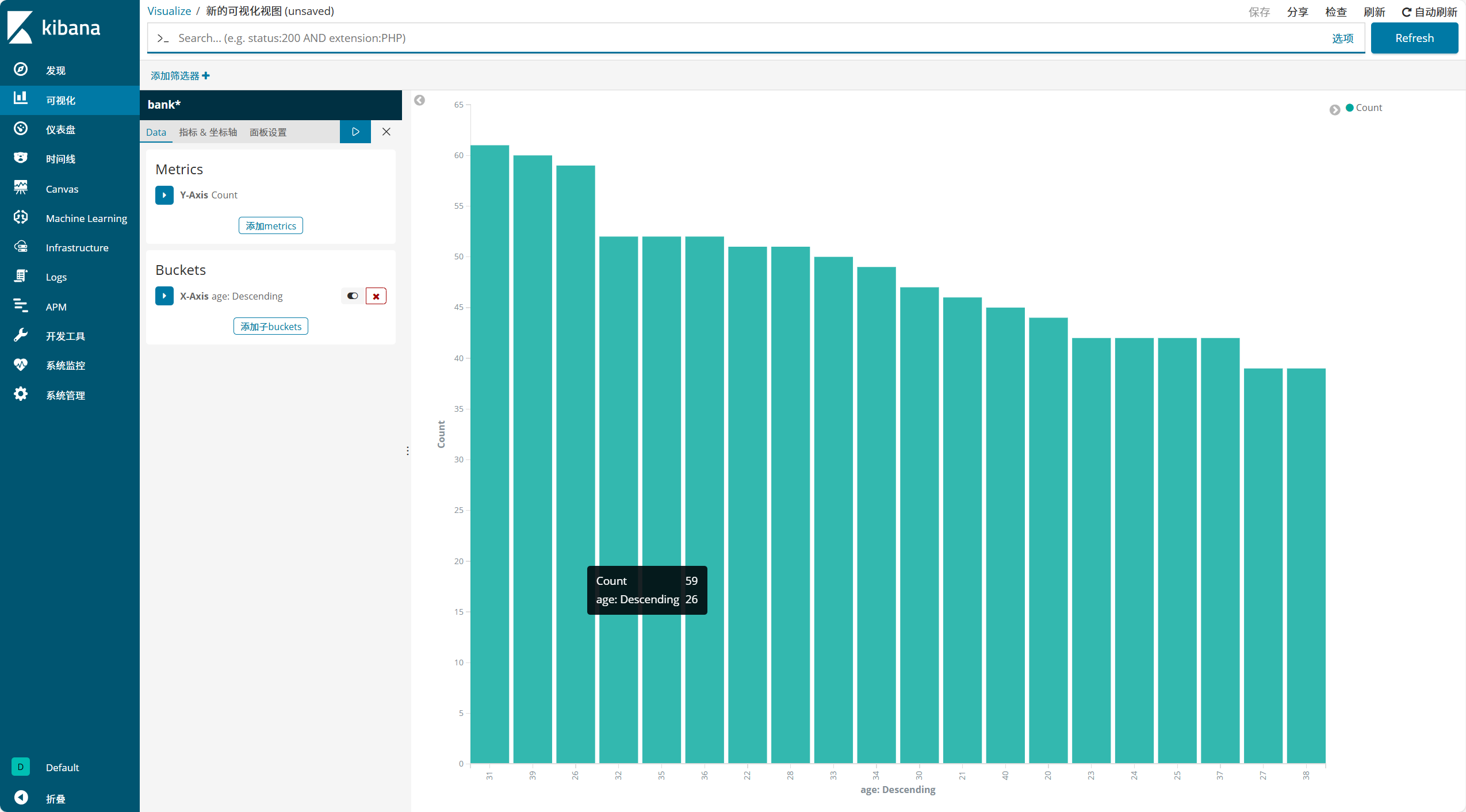
(3)创建可视化图形
- 点击左侧 "可视化"→"创建可视化视图",选择图表类型(如折线图、柱状图、饼图等)
- 选择数据来源(即已创建的索引模式),设置查询条件(如
status:200 AND extension:PHP筛选特定日志) - 配置图表参数(如 X 轴选择
@timestamp,时间间隔设为 Auto 或 30 分钟),点击生成图形 - 自定义图形名称(如 "yum 日志条数统计")并保存,后续可在 "仪表盘" 中添加该可视化组件
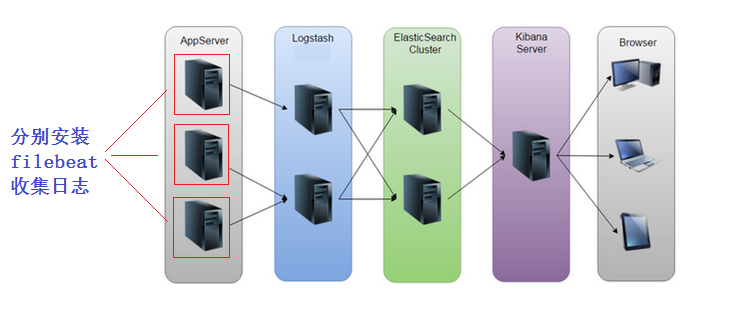
二、Filebeat:轻量级日志收集工具
Logstash 资源消耗高(占用内存多),若在多台应用服务器部署会增加性能负担,而 Filebeat 是 Beats 家族中专注于日志收集的轻量级工具,占用资源少,效率高
1. Beats 家族简介
| 工具名称 | 功能用途 |
|---|---|
| Packetbeat | 收集网络流量数据 |
| Metricbeat | 收集系统、进程、文件系统的 CPU、内存等指标数据 |
| Filebeat | 收集日志文件数据(本文核心工具) |
| Winlogbeat | 收集 Windows 事件日志 |
| Auditbeat | 收集审计日志 |
| Heartbeat | 收集系统运行时监控数据 |
2. 核心优势(对比 Logstash)
- 资源占用低:轻量级设计,CPU、内存消耗远低于 Logstash,适合在应用服务器(如 Nginx、MySQL 服务器)直接部署
- 部署灵活:可直接将日志传输到 Elasticsearch(EFK 架构),也可先传输到 Logstash(ELK 架构)进行过滤处理
- 高效稳定:独立收集单日志文件,日志更新时触发传输,且各日志传输独立不干扰
具体示例:
前置准备:
[root@vm2 ~]# cd elasticsearch-head/
[root@vm2 elasticsearch-head]# ls
crx Gruntfile.js node_modules proxy test
Dockerfile grunt_fileSets.js nohup.out README.textile
Dockerfile-alpine index.html package.json _site
elasticsearch-head.sublime-project LICENCE plugin-descriptor.properties src
[root@vm2 elasticsearch-head]# nohup npm run start &
[1] 10177
[root@vm2 elasticsearch-head]# nohup: ignoring input and appending output to 'nohup.out'
[root@vm2 elasticsearch-head]# ss -anlt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:9100 *:*
LISTEN 0 128 *:111 *:*
LISTEN 0 128 *:6000 *:*
LISTEN 0 5 192.168.122.1:53 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 128 127.0.0.1:631 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 127.0.0.1:6010 *:*
LISTEN 0 128 :::111 :::*
LISTEN 0 128 :::9200 :::*
LISTEN 0 128 :::6000 :::*
LISTEN 0 128 :::9300 :::*
LISTEN 0 128 :::22 :::*
LISTEN 0 128 ::1:631 :::*
LISTEN 0 100 ::1:25 :::*
LISTEN 0 128 ::1:6010 访问(http://192.168.100.20:9100/)
kibana
kibana介绍
Kibana是一个开源的可视化平台,可以为ElasticSearch集群的管理提供友好的Web界面,帮助汇总,分析和
搜索重要的日志数据
文档路径: https://www.elastic.co/guide/en/kibana/current/setup.html
kibana部署
在kibana服务器(我这里是VM1)上安装kibana:(注:这里是上传)
[root@vm1 ~]# rz -E
rz waiting to receive.
[root@vm1 ~]# rpm -ivh kibana-6.5.2-x86_64.rpm
warning: kibana-6.5.2-x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:kibana-6.5.2-1 ################################# [100%]配置kibana:
[root@vm1 ~]# vim /etc/kibana/kibana.yml
.....
server.port: 5601 //端口
server.host: "0.0.0.0" //监听所有,允许所有人能访问
elasticsearch.url: "http://192.168.100.20:9200" //ES集群的路径
logging.dest: /var/log/kibana.log //这里加了kibana日志,方便排错与调试日志要自己建立,并修改owner和group属性:
[root@vm1 ~]# touch /var/log/kibana.log
[root@vm1 ~]# chown kibana.kibana /var/log/kibana.log 启动kibana服务:
[root@vm1 ~]# systemctl start kibana
[root@vm1 ~]# systemctl enable kibana
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
[root@vm1 ~]# lsof -i:5601
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 10366 kibana 11u IPv4 62719 0t0 TCP *:esmagent (LISTEN)通过浏览器访问 http://kibana服务器IP:5601:
kibana汉化
https://github.com/anbai-inc/Kibana_Hanization/
上传压缩包并解压:
[root@vm1 ~]# rz -E
rz waiting to receive.
[root@vm1 ~]# unzip Kibana_Hanization-master.zip -d /usr/local/
Archive: Kibana_Hanization-master.zip
88b5f8cef28a720f27a5cb327c906554fbdff7ed
creating: /usr/local/Kibana_Hanization-master/
inflating: /usr/local/Kibana_Hanization-master/README.md
creating: /usr/local/Kibana_Hanization-master/config/
inflating: /usr/local/Kibana_Hanization-master/config/kibana_resource.json
creating: /usr/local/Kibana_Hanization-master/image/
inflating: /usr/local/Kibana_Hanization-master/image/grokdebugger.png
inflating: /usr/local/Kibana_Hanization-master/image/kibana.png
inflating: /usr/local/Kibana_Hanization-master/image/login.png
inflating: /usr/local/Kibana_Hanization-master/image/monitoring.png
inflating: /usr/local/Kibana_Hanization-master/image/visual.png
inflating: /usr/local/Kibana_Hanization-master/image/visualize.png
inflating: /usr/local/Kibana_Hanization-master/image/welcome.png
inflating: /usr/local/Kibana_Hanization-master/main.py
extracting: /usr/local/Kibana_Hanization-master/requirements.txt
[root@vm1 ~]# cd /usr/local/Kibana_Hanization-master/这里要注意:1,要安装python; 2,rpm版的kibana安装目录为/usr/share/kibana/
[root@vm1 Kibana_Hanization-master]# python main.py /usr/share/kibana/
文件[/usr/share/kibana/node_modules/x-pack/plugins/monitoring/ui_exports.js]已翻译。
文件[/usr/share/kibana/node_modules/x-pack/plugins/monitoring/public/register_feature.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/apm.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/canvas.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/commons.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/timelion.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/infra.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/kibana.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/login.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/ml.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/monitoring.bundle.js]已翻译。
文件[/usr/share/kibana/optimize/bundles/vendors.bundle.js]已翻译。
文件[/usr/share/kibana/src/core_plugins/kibana/index.js]已翻译。
文件[/usr/share/kibana/src/core_plugins/kibana/ui_setting_defaults.js]已翻译。
文件[/usr/share/kibana/src/core_plugins/kibana/public/dashboard/index.js]已翻译。
文件[/usr/share/kibana/src/core_plugins/kibana/server/tutorials/kafka_logs/index.js]已翻译。
文件[/usr/share/kibana/src/core_plugins/timelion/index.js]已翻译。
文件[/usr/share/kibana/src/ui/public/chrome/directives/global_nav/global_nav.js]已翻译。
恭喜,Kibana汉化完成!汉化完后需要重启:
[root@vm1 Kibana_Hanization-master]# systemctl stop kibana
[root@vm1 Kibana_Hanization-master]# systemctl start kibana再次通过浏览器访问 http://kibana服务器IP:5601:
通过kibana查看集群信息:
通过kibana查看logstash收集的日志索引:
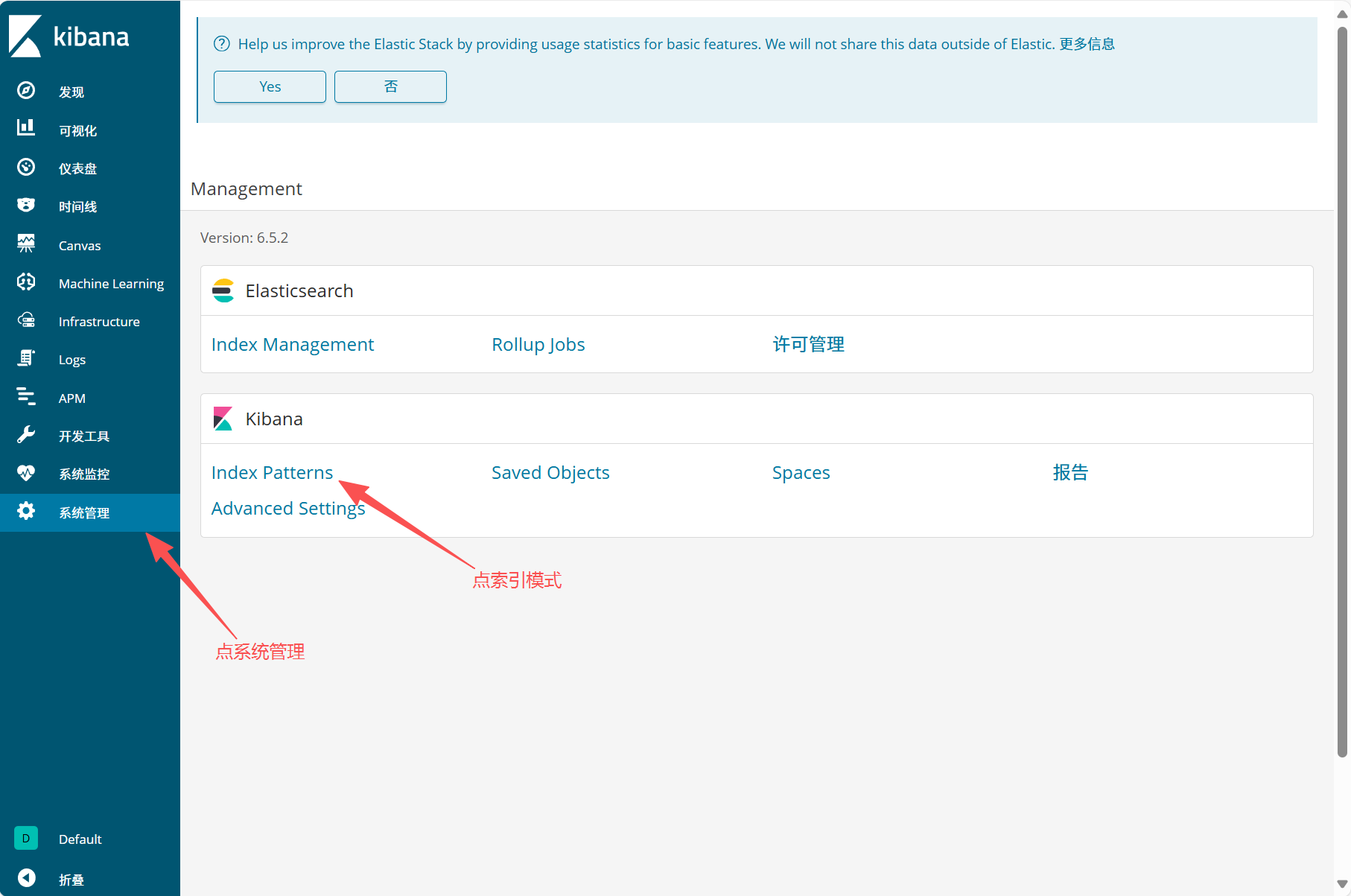
最后点发现查看:
通过kibana查看可视化图形
filebeat
因为logstash消耗内存等资源太高,如果在要采集的服务上都安装logstash,这样对应用服务器的压力增
加。所以我们要用轻量级的采集工具才更高效,更省资源
beats是轻量级的日志收集处理工具,Beats占用资源少
Packetbeat: 网络数据(收集网络流量数据)
Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat: 文件(收集日志文件数据)
Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
Auditbeat:审计数据 (收集审计日志)
Heartbeat:运行时间监控 (收集系统运行时的数据)
我们这里主要是收集日志信息, 所以只讨论filebeat
filebeat可以直接将采集的日志数据传输给ES集群(EFK), 也可以给logstash(5044端口接收)
filebeat收集日志直接传输给ES集群
下载并安装filebeat(再开一台虚拟机vm4模拟filebeat, 内存1G就够了, 安装filebeat)
[root@vm4 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.2-x86_64.rpm
[root@vm4 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.2-x86_64.rpm
--2025-10-24 16:13:14-- https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.2-x86_64.rpm
Resolving artifacts.elastic.co (artifacts.elastic.co)... 34.120.127.130, 2600:1901:0:1d7::
Connecting to artifacts.elastic.co (artifacts.elastic.co)|34.120.127.130|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 11470951 (11M) [application/octet-stream]
Saving to: 'filebeat-6.5.2-x86_64.rpm'
100%[================================================================>] 11,470,951 1.76MB/s in 7.3s
2025-10-24 16:13:23 (1.49 MB/s) - 'filebeat-6.5.2-x86_64.rpm' saved [11470951/11470951]
[root@vm4 ~]# rpm -ivh filebeat-6.5.2-x86_64.rpm
warning: filebeat-6.5.2-x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:filebeat-6.5.2-1 ################################# [100%]配置filebeat收集日志:
[root@vm4 ~]# vim /etc/filebeat/filebeat.yml
......
filebeat.inputs:
- type: log
enabled: true //改为true
paths:
- /var/log/*.log //收集的日志路径
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.elasticsearch: //输出给es集群
hosts: ["192.168.100.20:9200"] //es集群节点IP
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~启动服务:
[root@vm4 ~]# systemctl restart filebeat
[root@vm4 ~]# systemctl enable filebeat
Created symlink from /etc/systemd/system/multi-user.target.wants/filebeat.service to /usr/lib/systemd/system/filebeat.service.验证:在es-head和kibana上验证(验证过程省略, 参考前面的笔记)
练习:可以尝试使用两台filebeat收集日志,然后在kibana用筛选器进行筛选过滤查看。(可先把logstash
那台关闭logstash进行安装filebeat测试)
filebeat传输给logstash
在logstash上要重新配置,开放5044端口给filebeat连接,并重启logstash服务
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["192.168.100.20:9200"]
index => "filebeat2-%{+YYYY.MM.dd}"
}
stdout { //再加一个标准输出到屏幕,方便实验环境调试
}
}
~ 如果前面有使用后台跑过logstash实例的请kill掉先
[root@vm3 ~]# cd /usr/share/logstash/bin/
[root@vm3 bin]# pkill java
[root@vm3 bin]# ./logstash --path.settings /etc/logstash/ -r -f /etc/logstash/conf.d/test.conf 配置filebeat收集日志:
[root@vm4 ~]# cat /etc/filebeat/filebeat.yml | grep -v '#' |grep -v '^$'
filebeat.inputs:
- type: log
enabled: true //改为true
paths:
- /var/log/*.log //收集的日志路径
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash: //这两句非常重要,表示日志输出给logstash
hosts: ["192.168.100.30:5044"] //IP为logstash服务器的IP,端口5044对应logstash上的配置
processors:
- add_host_metadata: ~
- add_coud_metadata: ~启动服务:
[root@vm4 ~]# systemctl stop filebeat
[root@vm4 ~]# systemctl start filebeat去ES-head上验证:
在kibana创建索引模式(过程省略,参考上面的笔记操作),然后点发现验证
filebeat收集nginx日志
在filebeat这台服务器上安装nginx,启动服务。并使用浏览器访问刷新一下,模拟产生一些相应的日志
(强调: 我们在这里是模拟的实验环境,一定要搞清楚实际情况下是把filebeat安装到nginx服务器上去收
集日志)
[root@vm4 ~]# yum -y install epel-release
[root@vm4 ~]# yum -y install nginx
[root@vm4 ~]# systemctl restart nginx
[root@vm4 ~]# systemctl enable nginx修改filebeat配置文件,并重启服务
[root@vm4 ~]# cat /etc/filebeat/filebeat.yml |grep -v '#' |grep -v '^$'
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
- /var/log/nginx/access.log 只在这里加了一句nginx日志路径(按需求自定义即可)
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["10.1.1.13:5044"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
[root@vm4 ~]# systemctl stop filebeat
[root@vm4 ~]# systemctl start filebeat3, 验证(在kibana或es-head上查询)
练习: 尝试收集httpd,mysql日志
实验中易产生的问题总结:
filebeat配置里没有把output.elasticsearch改成output.logstash
filebeat在收集/var/log/*.log日志时,需要对日志进行数据的改变或增加,才会传。
当/var/log/yum.log增加了日志数据会传输,但不会触发配置里的其它日志传输。(每个日志的传输
是独立的)
filebeat收集的日志没有定义索引名称, 我这个实验是在logstash里定义的。(此例我定义的索引名叫
filebeat2-%{+YYYY.MM.dd})
es-head受资源限制可能会关闭了,你在浏览器上验证可能因为缓存问题,看不到变化的结果。
区分索引名和索引模式(index pattern)名
filebeat日志简单过滤
[root@vm4 ~]# grep -Ev '#|^$' /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/yum.log
- /var/log/nginx/access.log
include_lines: ['Installed'] 表示收集的日志里有Installed关键字才会收集
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["10.1.1.13:5044"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
[root@vm4 ~]# systemctl restart filebeat测试方法:
通过 yum install 和 yum remove 产生日志,检验结果
结果为: yum install 安装可以收集, yum remove 卸载的不能收集
其它参数可以自行测试
exclude_lines
exclude_files