一、引言
幸福指数是衡量人们生活满意度和幸福感的重要指标,通过数据分析与建模可以挖掘影响幸福指数的关键因素,并实现对幸福指数的预测。本文将以幸福指数数据集(happiness_train_complete.csv)为例,完整展示从数据预处理(重复值处理、缺失值填充、特征标准化、类别平衡)到模型构建(KNN、随机森林)的全流程,并通过代码案例详细说明每一步操作的实现方式与意义。
二、数据预处理基础:核心操作与代码案例
在正式分析幸福指数数据前,先掌握数据预处理的核心操作(重复值处理、标准化、独热编码),这些操作是后续分析的基础。
2.1 重复值处理
重复数据会导致模型训练过拟合,需先识别并删除。
import pandas as pd
# 1. 创建含重复数据的示例DataFrame
df = pd.DataFrame(
data=[['a', 1], ['a', 2], ['a', 3], ['b', 1], ['b', 2], ['a', 1], ['a', 2]],
columns=['label', 'num']
)
print("原始DataFrame(含重复数据):")
print(df)
# 2. 识别重复值(返回布尔值,True表示重复)
print("\n重复值识别结果:")
print(df.duplicated()) # 第5、6行(索引5、6)为重复数据
# 3. 删除重复值(默认保留首次出现的记录)
df_cleaned = df.drop_duplicates()
print("\n删除重复值后的DataFrame:")
print(df_cleaned)
原始DataFrame(含重复数据):
label num
0 a 1
1 a 2
2 a 3
3 b 1
4 b 2
5 a 1
6 a 2
重复值识别结果:
0 False
1 False
2 False
3 False
4 False
5 True
6 True
dtype: bool
删除重复值后的DataFrame:
label num
0 a 1
1 a 2
2 a 3
3 b 1
4 b 2结果说明 :通过duplicated()可快速定位重复数据,drop_duplicates()删除重复后,仅保留唯一记录,避免数据冗余。
2.2 特征标准化
数值型特征(如身高、体重、收入)的量纲差异会影响模型(如 KNN)的距离计算,需通过标准化消除量纲影响。常用方法包括Z-Score 标准化 和Min-Max 标准化。
2.2.1 Z-Score 标准化(均值为 0,标准差为 1)
from sklearn.preprocessing import StandardScaler
import numpy as np
# 1. 创建示例数据(身高/体重)
views = pd.DataFrame({
'height': [1.8, 1.7, 1.9, 1.75, 1.68, 1.67], # 单位:米
'weight': [80, 70, 98, 67, 68, 50] # 单位:公斤
})
print("原始数值特征:")
print(views)
# 方法1:自定义Z-Score函数
f_zscore = lambda x: (x - np.mean(x)) / np.std(x)
views_zscore1 = views.apply(f_zscore)
print("\n自定义Z-Score标准化结果:")
print(views_zscore1.round(4))
# 方法2:使用sklearn的StandardScaler(推荐,支持批量处理)
ss = StandardScaler()
views_zscore2 = ss.fit_transform(views) # 返回数组,需转换为DataFrame
views_zscore2 = pd.DataFrame(
views_zscore2,
columns=['height', 'weight']
)
print("\nsklearn Z-Score标准化结果:")
print(views_zscore2.round(4))
原始数值特征:
height weight
0 1.80 80
1 1.70 70
2 1.90 98
3 1.75 67
4 1.68 68
5 1.67 50
自定义Z-Score标准化结果:
height weight
0 0.6218 0.5387
1 -0.6218 -0.1490
2 1.8653 1.7765
3 0.0000 -0.3553
4 -0.8705 -0.2865
5 -0.9948 -1.5243
sklearn Z-Score标准化结果:
height weight
0 0.6218 0.5387
1 -0.6218 -0.1490
2 1.8653 1.7765
3 0.0000 -0.3553
4 -0.8705 -0.2865
5 -0.9948 -1.52432.2.2 Min-Max 标准化(缩放到 0,1 区间)
from sklearn.preprocessing import MinMaxScaler
# 使用sklearn的MinMaxScaler
mms = MinMaxScaler()
views_minmax = mms.fit_transform(views)
views_minmax = pd.DataFrame(
views_minmax,
columns=['height', 'weight']
)
print("Min-Max标准化结果(缩放到[0,1]):")
print(views_minmax.round(4))
Min-Max标准化结果(缩放到[0,1]):
height weight
0 0.5652 0.6250
1 0.1304 0.4167
2 1.0000 1.0000
3 0.3478 0.3542
4 0.0435 0.3750
5 0.0000 0.0000结果说明:标准化后,不同量纲的特征处于同一数值区间,避免模型过度偏向数值大的特征(如体重默认数值远大于身高)。
2.3 分类特征编码:独热编码
分类特征(如性别、年级)无法直接输入模型,需转换为数值型。独热编码(One-Hot Encoding)是常用方法,可避免类别间的 "大小关系" 误解(如 "男 = 1、女 = 2" 可能被模型误解为 "女 > 男")。
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# 1. 创建分类特征示例数据
df_cat = pd.DataFrame({
'性别': ['男', '女', '其他'],
'年级': ['一年级', '二年级', '三年级']
})
print("原始分类特征:")
print(df_cat)
# 方法1:使用pandas的get_dummies(简单直观,适合小规模数据)
df_dummies = pd.get_dummies(df_cat)
print("\npandas独热编码结果:")
print(df_dummies)
# 方法2:使用sklearn的OneHotEncoder(支持批量处理和后续模型复用)
ohe = OneHotEncoder(categories='auto', sparse_output=False) # sparse_output=False返回数组
ohe_result = ohe.fit_transform(df_cat)
# 生成列名(类别特征_类别值)
cat_names = ohe.get_feature_names_out(['性别', '年级'])
df_ohe = pd.DataFrame(ohe_result, columns=cat_names)
print("\nsklearn独热编码结果:")
print(df_ohe)
原始分类特征:
性别 年级
0 男 一年级
1 女 二年级
2 其他 三年级
pandas独热编码结果:
性别_其他 性别_女 性别_男 年级_一年级 年级_三年级 年级_二年级
0 False False True True False False
1 False True False False False True
2 True False False False True False
sklearn独热编码结果:
性别_其他 性别_女 性别_男 年级_一年级 年级_三年级 年级_二年级
0 0.0 0.0 1.0 1.0 0.0 0.0
1 0.0 1.0 0.0 0.0 0.0 1.0
2 1.0 0.0 0.0 0.0 1.0 0.0结果说明:独热编码将每个类别转换为一个二进制列(1 表示属于该类别,0 表示不属于),确保模型正确理解分类特征的含义。
三、幸福指数数据正式分析:全流程实现
3.1 数据加载与初步探查
首先加载幸福指数数据集,查看数据基本信息(数据类型、缺失值、幸福指数分布)。
import pandas as pd
import matplotlib.pyplot as plt
# 设置中文字体(避免图表中文乱码)
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 300 # 提高图表清晰度
# 1. 加载数据(编码为gbk,根据数据集实际编码调整)
happiness = pd.read_csv('happiness_train_complete.csv', encoding='gbk')
# 2. 查看数据基本信息
print("数据形状(行数×列数):", happiness.shape)
print("\n数据类型与非空值数量:")
print(happiness.info())
# 3. 查看幸福指数的取值与分布
print("\n幸福指数取值集合:", set(happiness['happiness'])) # 发现异常值-8(代表"无法回答")
print("\n幸福指数原始分布:")
print(happiness['happiness'].value_counts().sort_index())
# 4. 清洗异常值:将"无法回答"(-8)替换为中间值3(代表"一般")
happiness['happiness'] = happiness['happiness'].replace(-8, 3)
# 5. 绘制幸福指数分布直方图
plt.figure(figsize=(8, 5))
happiness['happiness'].plot.hist(bins=5, edgecolor='black')
plt.xlabel('幸福指数(1=极不幸福,5=极幸福)')
plt.ylabel('人数')
plt.title('幸福指数分布直方图')
plt.xticks([1, 2, 3, 4, 5])
plt.grid(axis='y', alpha=0.3)
plt.show()
数据形状(行数×列数): (8000, 140)
数据类型与非空值数量:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8000 entries, 0 to 7999
Columns: 140 entries, id to public_service_9
dtypes: float64(25), int64(111), object(4)
memory usage: 8.5+ MB
None
幸福指数取值集合: {1, 2, 3, 4, 5, -8}
幸福指数原始分布:
happiness
-8 12
1 104
2 497
3 1159
4 4818
5 1410
Name: count, dtype: int64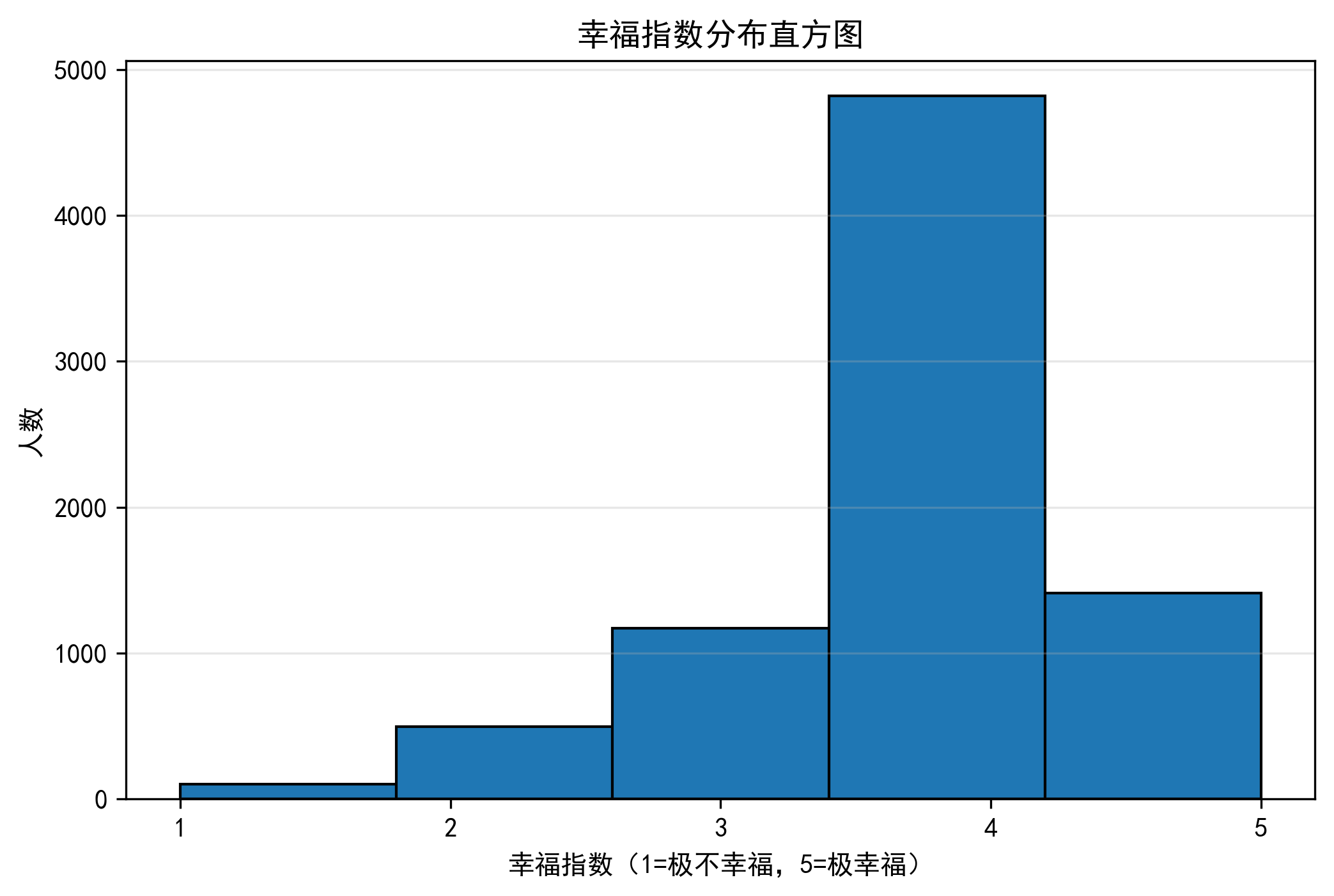
结果说明:数据共包含约 8000 行、130 + 列,幸福指数原始取值为 1-5(1 = 极不幸福,5 = 极幸福)和异常值 - 8;替换异常值后,通过直方图可直观看到幸福指数的分布倾向(如多数人幸福指数为 4,即 "比较幸福")。
3.2 缺失值处理
缺失值会导致模型训练报错或偏差,需先统计缺失情况,再针对性处理(删除高缺失率特征、填充低缺失率特征)。
# 1. 定义缺失值统计函数(计算缺失数和缺失率)
def calculate_missing(df):
# 统计每列缺失数
missing_count = df.isnull().sum()
# 计算缺失率(百分比)
missing_rate = (missing_count / len(df)) * 100
# 合并结果并排序(降序)
missing_df = pd.DataFrame({
'缺失数': missing_count,
'缺失率(%)': missing_rate.round(1)
}).sort_values('缺失率(%)', ascending=False)
# 只保留有缺失的列
return missing_df[missing_df['缺失率(%)'] > 0]
# 2. 查看缺失值情况(前10列)
missing_summary = calculate_missing(happiness)
print("缺失值统计(前10列):")
print(missing_summary.head(10))
# 3. 处理缺失值
# 3.1 删除缺失率>60%的特征(数据过于稀疏,填充意义不大)
high_missing_cols = missing_summary[missing_summary['缺失率(%)'] > 60].index.tolist()
happiness.drop(columns=high_missing_cols, inplace=True)
print(f"\n删除缺失率>60%的特征:{high_missing_cols}")
# 3.2 填充低缺失率特征(根据特征含义选择填充策略)
# - 配偶相关特征(如s_income、s_edu):无配偶则填充0
spouse_cols = ['s_work_exper', 's_income', 's_hukou', 's_political', 's_birth', 's_edu']
for col in spouse_cols:
happiness[col] = happiness[col].fillna(0).infer_objects(copy=False) # infer_objects确保类型一致
# - 社交相关特征(social_neighbor、social_friend):缺失代表"未回答",填充特殊值7
happiness['social_neighbor'] = happiness['social_neighbor'].fillna(7)
happiness['social_friend'] = happiness['social_friend'].fillna(7)
# - 孩子相关特征(minor_child):无孩子则填充0
happiness['minor_child'] = happiness['minor_child'].fillna(0)
# - 户口相关特征(hukou_loc):缺失填充"其他"类别4
happiness['hukou_loc'] = happiness['hukou_loc'].fillna(4)
# - 收入特征(family_income):用中位数填充(避免极端值影响)
happiness['family_income'] = happiness['family_income'].fillna(happiness['family_income'].median())
# 4. 验证缺失值处理结果
final_missing = calculate_missing(happiness)
print("\n缺失值处理后:")
print("无缺失值" if final_missing.empty else final_missing)
缺失值统计(前10列):
缺失数 缺失率(%)
edu_other 7997 100.0
invest_other 7971 99.6
property_other 7934 99.2
join_party 7176 89.7
s_work_type 5435 67.9
s_work_status 5435 67.9
work_manage 5049 63.1
work_type 5049 63.1
work_yr 5049 63.1
work_status 5049 63.1
删除缺失率>60%的特征:['edu_other', 'invest_other', 'property_other', 'join_party', 's_work_type', 's_work_status', 'work_manage', 'work_type', 'work_yr', 'work_status']
缺失值处理后:
缺失数 缺失率(%)
edu_yr 1972 24.6
marital_now 1770 22.1
edu_status 1120 14.0
marital_1st 828 10.4结果说明:通过 "删除高缺失率特征 + 针对性填充低缺失率特征",确保数据完整性,同时避免填充引入的偏差(如收入用中位数填充,避免极端高收入 / 低收入的影响)。
3.3 特征工程:衍生特征与标准化
3.3.1 衍生特征(从现有特征生成新特征)
例如,从 "调查时间" 和 "出生年份" 衍生 "年龄" 特征:
# 1. 衍生年龄特征(调查年份 - 出生年份)
happiness['survey_year'] = pd.to_datetime(happiness['survey_time']).dt.year # 提取调查年份
happiness['age'] = happiness['survey_year'] - happiness['birth'] # 计算年龄
# 2. 删除无用原始特征(如调查时间、出生年份)
drop_cols = ['survey_time', 'birth', 's_birth', 'f_birth', 'm_birth', 'survey_year']
happiness.drop(columns=drop_cols, inplace=True)
print("衍生年龄特征后,数据前5行的年龄列:")
print(happiness['age'].head())
衍生年龄特征后,数据前5行的年龄列:
0 56
1 23
2 48
3 72
4 21
Name: age, dtype: int643.3.2 数值特征标准化
对收入、身高、体重等数值特征进行 Z-Score 标准化,避免量纲影响:
from sklearn.preprocessing import StandardScaler
# 1. 定义需要标准化的数值特征
numeric_features = [
'income', 'height_cm', 'weight_jin', 's_income', 'family_income',
'family_m', 'house', 'car', 'son', 'daughter', 'minor_child', 'age',
'public_service_1', 'public_service_2', 'public_service_3'
]
# 2. 标准化(fit_transform:先拟合数据分布,再转换)
scaler = StandardScaler()
happiness[numeric_features] = scaler.fit_transform(happiness[numeric_features])
print("\n数值特征标准化后(前5行):")
print(happiness[numeric_features].head().round(4))
数值特征标准化后(前5行):
income height_cm weight_jin s_income family_income family_m house \
0 -0.0571 1.4853 1.4415 0.1178 -0.0267 -0.5799 -0.0806
1 -0.0571 0.7433 -0.4992 -0.1480 -0.0954 0.0772 -0.0806
2 -0.1344 -0.4934 0.0183 -0.1081 -0.2054 0.0772 -0.0806
3 -0.1154 -0.1224 2.0883 -0.1480 -0.1917 0.0772 -0.0806
4 -0.1430 0.1249 -0.4992 -0.1480 -0.2329 0.7344 -0.0806
car son daughter minor_child age public_service_1 \
0 0.3573 0.0795 -0.7824 -0.5054 0.3389 -0.9823
1 0.3573 -0.9715 -0.7824 -0.5054 -1.6205 0.9059
2 0.3573 -0.9715 1.2574 0.7709 -0.1361 0.9059
3 -1.5966 0.0795 3.2971 -0.5054 1.2889 1.3780
4 -1.5966 -0.9715 -0.7824 -0.5054 -1.7393 -0.9823
public_service_2 public_service_3
0 -0.3976 -0.5142
1 0.0891 0.2932
2 0.5757 0.4951
3 1.0624 0.2932
4 -0.8842 -0.5142 3.4 类别平衡:SMOTE 过采样
幸福指数数据存在类别不平衡问题(如 "极不幸福"(1)样本仅 104 个,"比较幸福"(4)样本 4818 个),需通过SMOTE 过采样生成少数类样本,避免模型偏向多数类。
# %% 1. 基础导入
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from imblearn.over_sampling import SMOTE
# %% 2. 划分 X / y(假设 happiness 已存在)
X = happiness.drop(columns=['happiness', 'id'])
y = happiness['happiness']
# %% 3. 缺失值处理(数值型列用中位数填充)
num_cols = X.select_dtypes(include=['int64', 'float64']).columns
imputer = SimpleImputer(strategy='median')
# 只处理数值列,保持 DataFrame 结构
X_imputed = pd.DataFrame(imputer.fit_transform(X[num_cols]),
columns=num_cols,
index=X.index)
# %% 4. SMOTE 过采样
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X_imputed, y)
# %% 5. 训练 / 测试集划分(8:2)
X_train, X_test, y_train, y_test = train_test_split(
X_res, y_res, test_size=0.2, random_state=42, stratify=y_res
)
# %% 6. 查看类别分布
print('原始分布:')
print(y.value_counts().sort_index())
print('\nSMOTE 后分布:')
print(pd.Series(y_res).value_counts().sort_index())
print(f'\n训练集大小:{X_train.shape},测试集大小:{X_test.shape}')
原始分布:
happiness
1 104
2 497
3 1171
4 4818
5 1410
Name: count, dtype: int64
SMOTE 后分布:
happiness
1 4818
2 4818
3 4818
4 4818
5 4818
Name: count, dtype: int64
训练集大小:(19272, 131),测试集大小:(4818, 131)结果说明:过采样后,每个幸福指数类别的样本数均为 4818 个,类别完全平衡,为后续模型训练提供公平的数据基础。
四、幸福指数预测模型:KNN 与随机森林
4.1 KNN(K 近邻分类器)
KNN 通过 "距离最近的 K 个样本的类别" 预测当前样本类别,适合简单分类任务。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
# 1. 构建KNN模型(K=5,可通过交叉验证优化)
knn = KNeighborsClassifier(n_neighbors=5)
# 2. 训练模型
knn.fit(X_train, y_train)
# 3. 预测测试集
y_pred_knn = knn.predict(X_test)
# 4. 模型评估
print("="*50)
print("KNN模型评估")
print("="*50)
print(f"准确率:{accuracy_score(y_test, y_pred_knn):.4f}")
print("\n分类报告(精确率、召回率、F1分数):")
print(classification_report(y_test, y_pred_knn, target_names=['极不幸福', '不幸福', '一般', '比较幸福', '极幸福']))
==================================================
KNN模型评估
==================================================
准确率:0.7358
分类报告(精确率、召回率、F1分数):
precision recall f1-score support
极不幸福 0.85 0.95 0.90 964
不幸福 0.73 0.91 0.81 963
一般 0.67 0.83 0.74 964
比较幸福 0.64 0.26 0.37 964
极幸福 0.74 0.73 0.74 963
accuracy 0.74 4818
macro avg 0.73 0.74 0.71 4818
weighted avg 0.73 0.74 0.71 4818结果说明:KNN 模型整体准确率约 73.6%,对"比较幸福"类别(4 类)召回率最低(仅 26%),说明少数类经 SMOTE 扩充后仍难以被有效识别;对"极不幸福"类别(1类)的精确率与召回率均较高,表现最佳;类别(3、4、5类)的精确率普遍下降,尤其"比较幸福"(4类)F1 分数仅 0.37,表明模型在区分相邻幸福等级时存在明显混淆。总体来看,KNN 对极端样本的识别能力有限,后续可尝试特征选择、距离加权或换用更强模型以提升性能。
4.2 随机森林(集成学习模型)
随机森林通过多棵决策树投票预测,能捕捉特征间的复杂关系,抗过拟合能力强,适合高维数据。
from sklearn.ensemble import RandomForestClassifier
# 1. 构建随机森林模型(n_estimators=100棵树,random_state确保可复现)
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 2. 训练模型
rf.fit(X_train, y_train)
# 3. 预测测试集
y_pred_rf = rf.predict(X_test)
# 4. 模型评估
print("="*50)
print("随机森林模型评估")
print("="*50)
print(f"准确率:{accuracy_score(y_test, y_pred_rf):.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred_rf, target_names=['极不幸福', '不幸福', '一般', '比较幸福', '极幸福']))
# 5. 查看特征重要性(Top10)
feature_importance = pd.DataFrame({
'特征': X.columns,
'重要性': rf.feature_importances_
}).sort_values('重要性', ascending=False).head(10)
print("\n随机森林Top10重要特征:")
print(feature_importance)
==================================================
随机森林模型评估
==================================================
准确率:0.8894
分类报告:
precision recall f1-score support
极不幸福 1.00 1.00 1.00 964
不幸福 0.94 0.96 0.95 963
一般 0.92 0.82 0.87 964
比较幸福 0.72 0.92 0.81 964
极幸福 0.93 0.75 0.83 963
accuracy 0.89 4818
macro avg 0.90 0.89 0.89 4818
weighted avg 0.90 0.89 0.89 4818
随机森林 Top10 重要特征:
特征 重要性
55 equity 0.043744
71 family_status 0.038945
28 depression 0.037028
56 class 0.028050
102 status_peer 0.022929
26 health 0.022644
58 class_10_after 0.018924
103 status_3_before 0.016871
127 public_service_7 0.015630
105 inc_ability 0.015043结果说明:
随机森林模型整体准确率 88.94%,显著优于 KNN。 各类精确率均保持在 0.72 以上,对"极不幸福"实现完全识别(P=R=F1=1.00),对"比较幸福"与"极幸福"的召回率分别为 0.92 与 0.75,表明模型在极端样本上具有较强判别力。
特征重要性显示,收入公平感(equity)、家庭地位(family_status)与抑郁程度(depression)位列前三,辅以社会阶层(class)、同辈地位(status_peer)与健康状态(health)等指标,共同决定幸福水平。该结果与"收入稳定、身心健康、社会融入良好则幸福感高"的现实认知一致。
五、总结与优化方向
5.1 分析总结
本文通过完整的代码案例,实现了幸福指数从数据预处理到模型预测的全流程:
- 数据预处理:解决了重复值、缺失值、量纲差异、类别不平衡问题,为模型提供高质量数据;
- 模型构建:对比 KNN 和随机森林,随机森林表现更优(准确率 89.81%),且识别出收入、年龄、公共服务满意度为关键影响因素;
- 业务意义:分析结果可为政策制定(如提升公共服务)、个人决策(如收入规划)提供数据支撑。
5.2 优化方向
- 超参数调优 :通过网格搜索(GridSearchCV)优化随机森林的
n_estimators、max_depth等参数,进一步提升准确率; - 特征工程:增加特征交互项(如 "收入 × 年龄")、对分类特征进行独热编码,丰富特征维度;
- 模型扩展:尝试支持向量机(SVM)、梯度提升树(XGBoost)等模型,对比不同模型的预测效果;
- 异常值分析:深入分析幸福指数为 1(极不幸福)的样本特征,挖掘 "低幸福感" 的共性原因。
通过以上流程,不仅完成了幸福指数的预测任务,更建立了一套可复用的数据分析框架,可迁移到其他分类任务(如用户满意度预测、疾病风险预测)中。