开源模型王座再次易主,依旧是国产模型!
不过之前霸榜的 DeepSeek 和 Qwen 来自杭州,现在变成上海的 MiniMax 了。
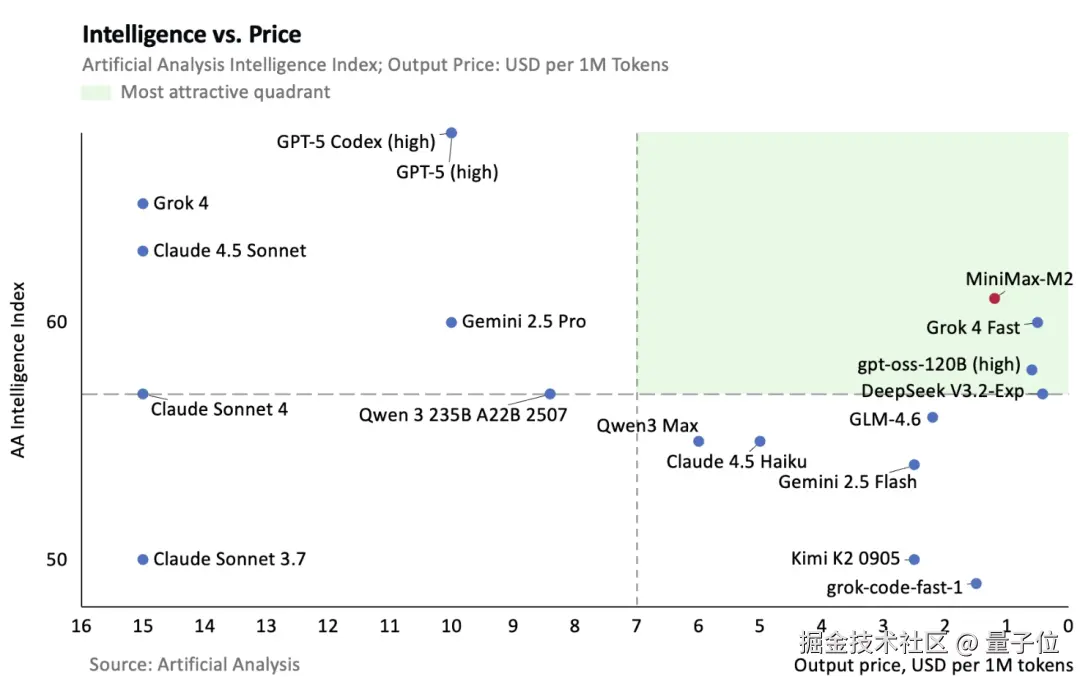
在第三方评测机构 Artificial Analysis 的测试中,MiniMax M2 以 61 分获得了开源模型第一,紧随 Claude 4.5 Sonnet。
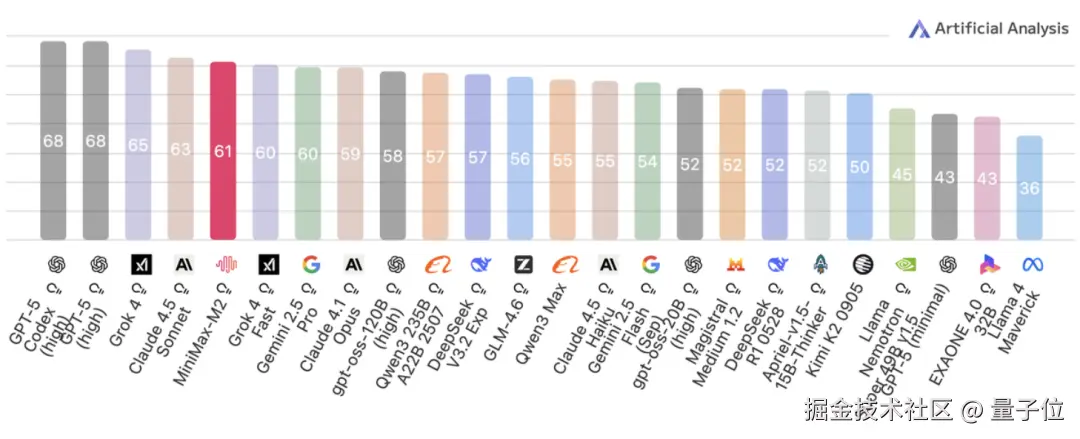
官方介绍,MiniMax M2 专为智能体和编程而生,编程能力和 Agent 表现出众。
而且经济高效,推理速度是 Claude 3.5 Sonnet 的两倍,API 价格却只有 8%。
MiniMax 表示,智能水平、速度和成本在过去被视为 "不可能三角",但随着 M2 的出世,这个三角被打破了。
目前,M2 的完整模型权重已经开源,采用 MIT 协议,在线 Agent 平台和 API 也限时免费。

8% 成本实现 Claude 级水平
MiniMax M2 是一个稀疏度较高的 MoE 模型,总参数量 230B,激活参数量仅有 10B。
网友表示 10B 的激活参数运行起来会非常快,如果配上 Cerebras 或者 Groq 这样的推理加速平台,有望跑到每秒上千 Token。
另一个特色是采用了交错的思维格式,使得模型能够规划和验证跨多个对话的操作步骤,这对于 Agent 推理至关重要。
如开头介绍,MiniMax 官方将 M2 定义为一个专为智能体和编程而生的模型。
它专为端到端开发工作流程而构建,而且表现出对复杂、长链工具调用任务的出色规划和稳定执行能力,支持 Shell、浏览器、Python 代码解释器和各种 MCP 工具的调用。
在 Agent 最关键的三个能力------编程能力、工具使用能力和深度搜索能力上,M2 在工具使用和深度搜索方面都不逊于海外顶尖模型,编程能力也在国内名列前茅。
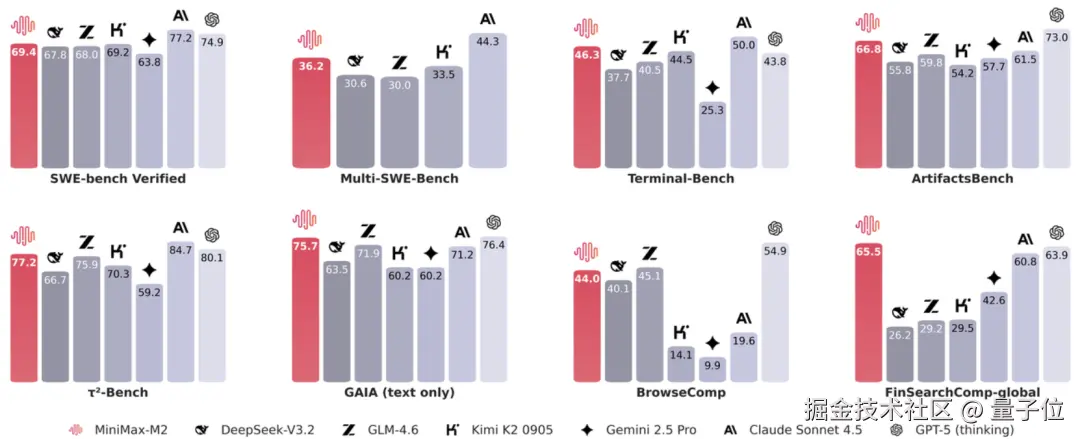
综合表现上,M2 在 Artificial Analysis 的测试中,获得了总排名第五、开源第一的成绩。
该测试使用了 10 个热门数据集,包括 MMLU Pro、GPQA Diamond、人类最后测试、LiveCodeBench 等。
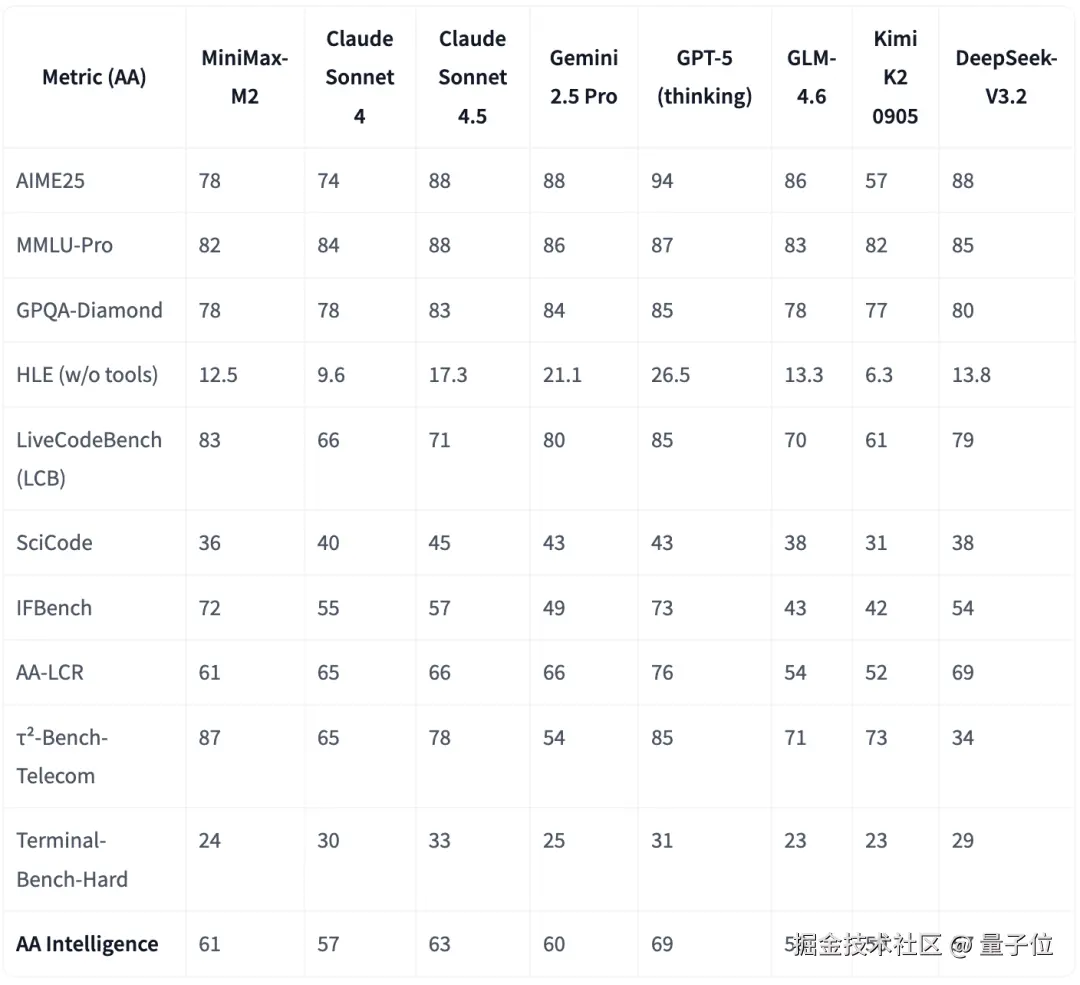
而 M2 的定价是 0.3 美元 / 2.1 人民币每百万输入 Token,1.2 美元 / 8.4 人民币每百万输出 Token,只要 Claude 3.5 Sonnet 的 8%。
以 Artificial Analysis 的成绩为基准,MiniMax 绘制了一张图来比较各大模型性价比(横轴越向右成本越低)。
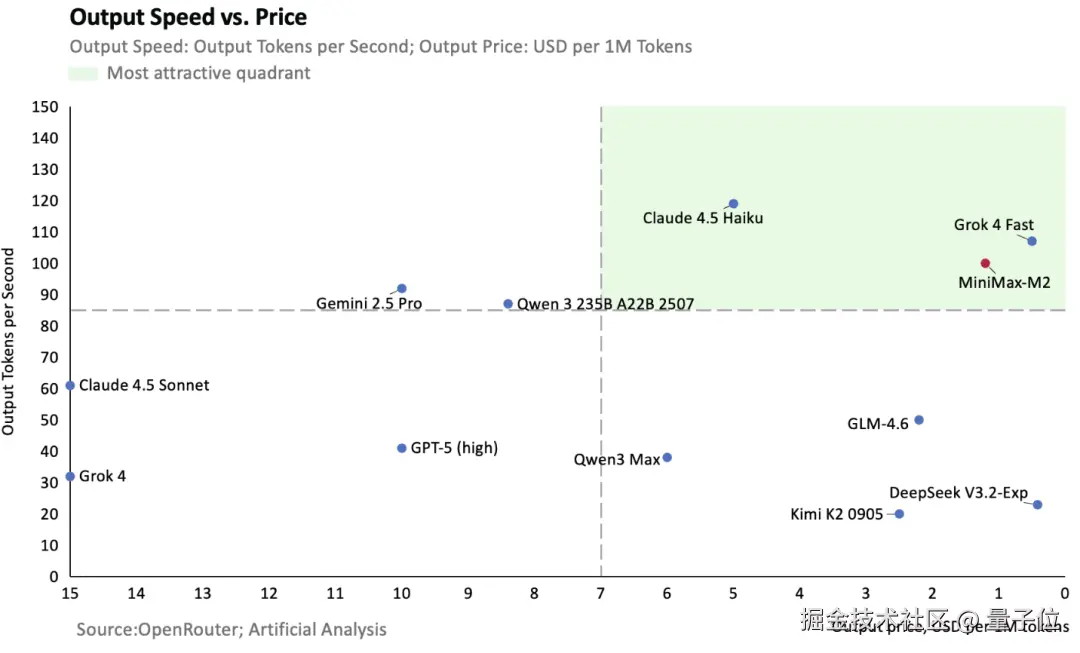
在线推理服务的速度则可达每秒 100Token,MiniMax 也画了一张图体现以速度衡量的性价比。
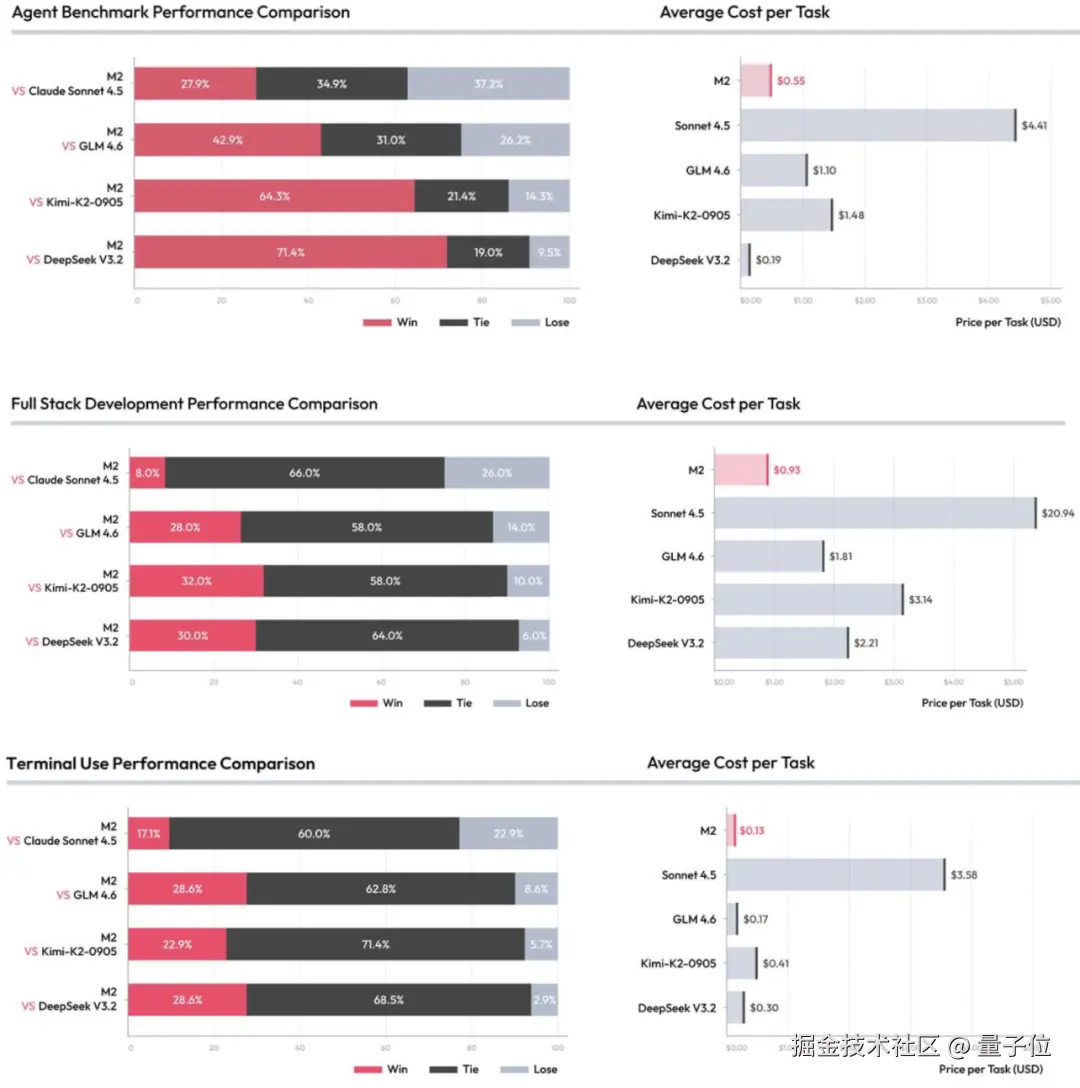
同时,MiniMax 团队还针对智能体、全栈开发和 Terminal Use 三项任务对 M2 和其他模型进行了一对一比拼。
结果 M2 相比于 Claude Sonnet 4.5、GLM 4.6、Kimi-K2 以及 DeepSeek V3.2 均有极高的 Win+Tie 比例,同时成本非常低廉。
为了更直观地体现 M2 的 Agent 能力,MiniMax 已经把 M2 部署到了 Agent 平台,限时免费使用,按官方说法,免费期直到服务器扛不住为止。
同时在该平台上,也展示了许多 MiniMax Agent 的现成作品。
MiniMax Agent:能写程序,还会做 PPT
利用 MiniMax 的 Agent 平台,可以写出各式各样的网页或在线应用。
当然像很多经典游戏,也都能用它在 Web 环境当中复刻并直接部署。
甚至有网友创作的在线五子棋游戏平台,不仅有游戏本体,还引入了在线对战、观战、在线聊天,甚至是用户注册等功能。

除了编程,也可以生成各种主题的调研报告或者 PPT。
在 X 上,也有网友展示了自己用 M2 Agent 编程的实战成果,仅通过三轮反馈就完成了一个足球小游戏的制作。
可以说效果非常不错。
模型表现之外,M2 使用的注意力机制,也引发了网友们的讨论。
混合注意力 vs 全注意力
有网友从 vllm 的代码当中看出了 M2 的更多技术细节,表示 M2 采用类似 GPT-OSS 的全注意力和滑动窗口注意力(SWA)的混合机制,
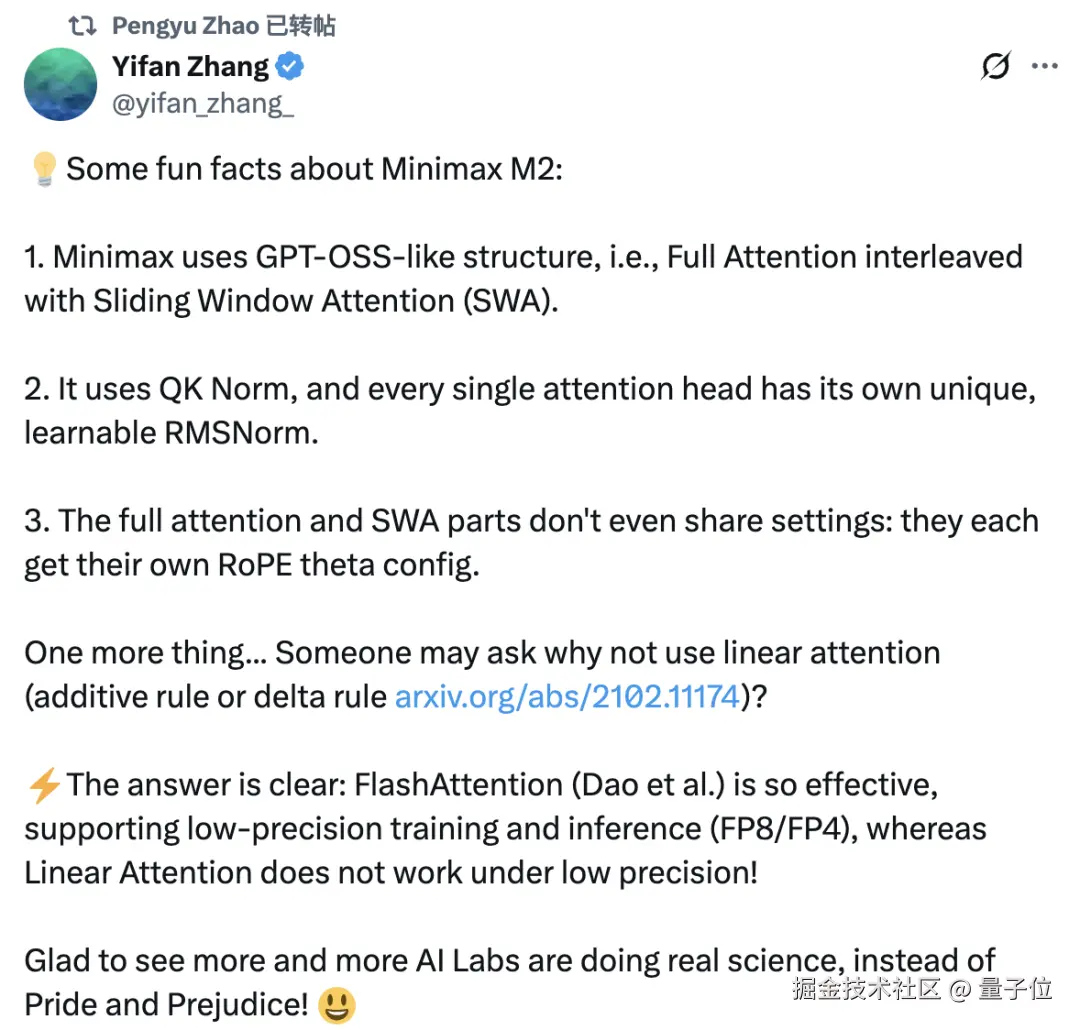
不过 MiniMax NLP 负责人指正,表示一开始确实想在预训练阶段引入 SWA,但发现会造成性能损失,所以最后使用的是全注意力。

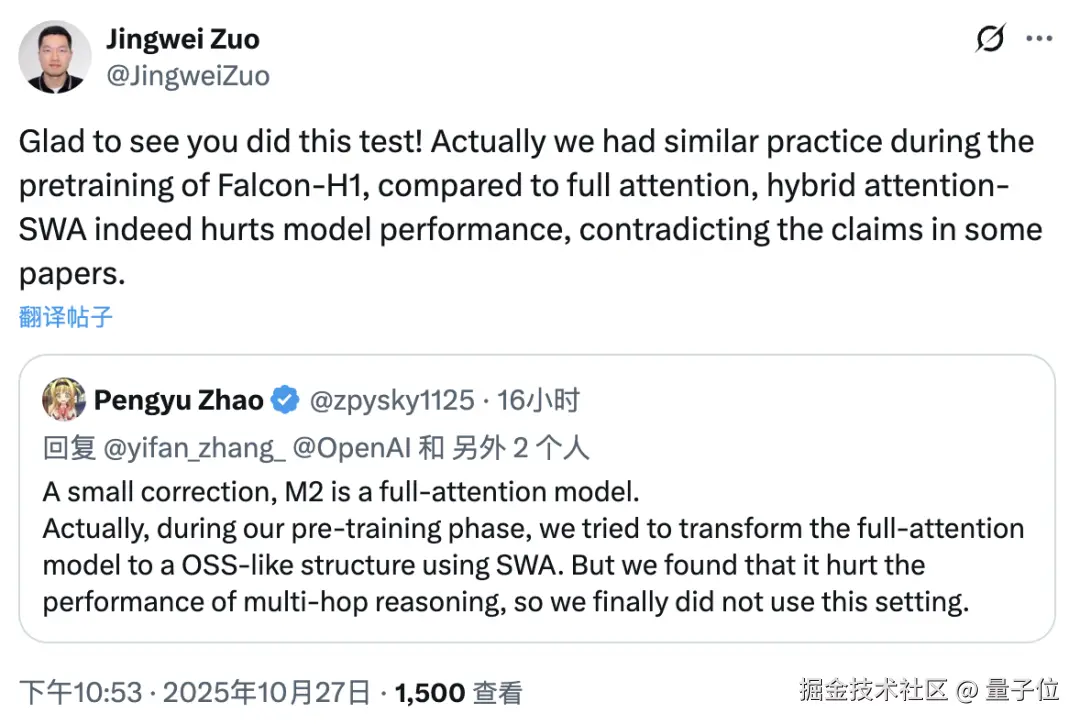
Falcon 团队的技术人员看了之后表示,他们在训练模型的时候也发现了同样的现象,SWA 混合注意力会降低模型性能,这和一些论文的研究不符。
在部分论文和实践中,SWA 在提升效率的同时可以保持性能,如 Mistral 和谷歌 Gemma 模型的相关研究均支持此观点。
但 MiniMax 的实际测试显示其在长程依赖任务上存在局限。

同时,M2 也没有采用 Lightning Attention(线性注意力的一种变体),原因也是因为性能损失。
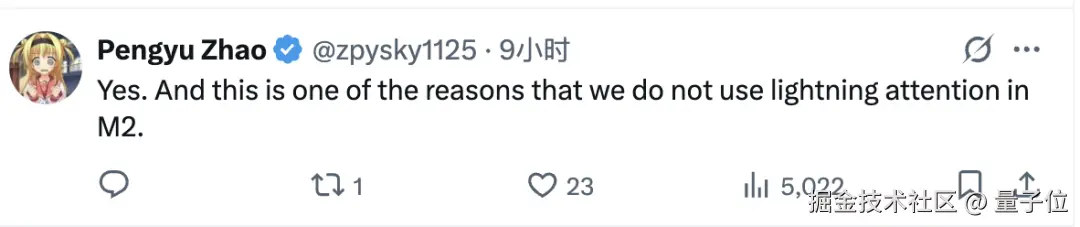
同样与之相反,有论文主张线性注意力在长序列任务中更具优势。
到底哪种路线更优,可能还是要看具体需求,但至少从 M2 的表现上看,MiniMax 选择的的确是一种适合自己的方式。
Agent 平台:agent.minimax.io
Hugging Face:huggingface.co/MiniMaxAI/M...
参考链接:
1www.minimax.io/news/minima...
2venturebeat.com/ai/minimax-...
欢迎在评论区留下你的想法!
--- 完 ---