数据:包含 OCR 1.0 数据(多语言 PDF 文档、Word 数据、自然场景 OCR 数据)、OCR 2.0 数据(图表数据、化学公式数据、平面几何数据)、通用视觉数据和 10% 文本数据的混合数据集
模型:
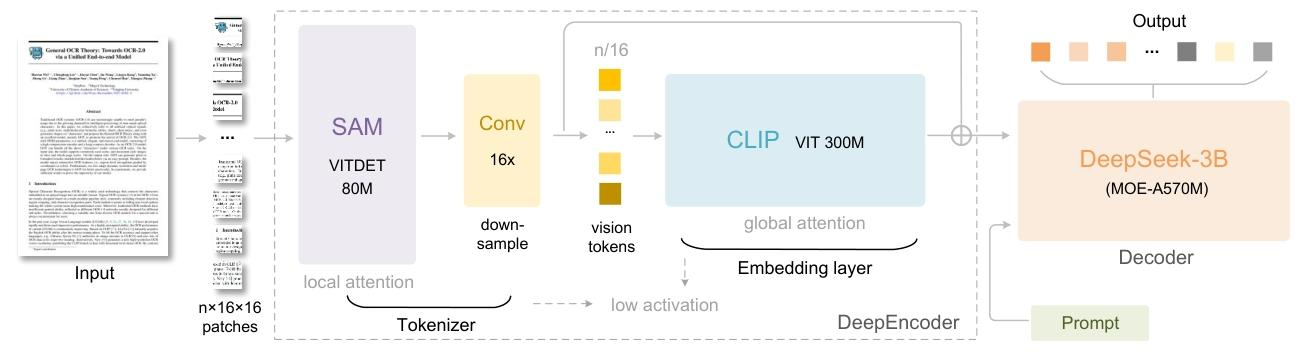
(1)以窗口注意力为主导的视觉感知特征提取组件(采用 80M 的 SAM-base)
(2)通过 2 层卷积模块对视觉令牌进行 16 倍下采样,减少进入全局注意力的token数量
(3)具有密集全局注意力的视觉知识特征提取组件(采用 300M 的 CLIP-large)
(4)多分辨率支持:通过位置编码的动态插值实现单模型对多分辨率输入的适配,满足不同压缩比需求
未解决问题:
(1)当压缩比达到 20 倍时,OCR 精度降至约 60%
(2)几何图形解析的准确性不足
(3)长文档处理不行
感悟:
(1)在10 倍压缩的情况下识别精度还能保持 97%,但论文中解码的精度是字符的准确率,这不代表文本信息重要性,如果100字里面把最重要的3个字传错了呢
(2)虽然视觉 token 数少了,但模型的计算复杂度其实不一定更低,Hugging Face 的版本标注在 A100 40G 上能跑 2500 tokens/s
(3)确实压缩了token,但会不会和文字一样上下文坍塌呢,比如128K上下文的模型,传入超过12.8K的视觉token会怎么样
(4)视觉压缩会比summary压缩要好吗,summary可以很大程度上维持语义信息
(5)模型预训练时学到了先验,或许视觉token的效果不好,但是模型根据部分正确的表征还原了信息,需要破坏视觉输入的文字顺序等方法测试,例如图片从"我喜欢你"->"你欢欢我"
(6)视觉encoder优于text tokenizer,这可能也是成功的原因之一,需要研究更好的tokenizer。现在的text在被tokenizer拆成离散信息后,text encoder需要重新学习句法和语义关系