你好,我是 Guide。
前几天,我整理分享了招银网络今年校招开奖的情况,软开的整体总包在 26w~31w(部分可能更低或者更高),一般是 12 薪,公积金按照 12% 标准缴纳,还是挺不错的。
中兴也开奖了,星球里有球友还拿到了 SSP Offer。
根据网上已经爆出的薪资来看,中兴今年给出的 SSP Offer 还挺多的。
下面是中兴今年已经开奖岗位的薪资情况:
- 软开:(15~18)k*12,西安,白菜
- 软开:(16~19)k*12,南京,白菜
- 软开:(19~22)k *12,上海,SP
- 软开(未来领军):(25~28)k*12,深圳,SSP
怎么说呢,开的真心不高,甚至有点低,很多拿到中兴 SSP 的都是硕士 985,人家手里还有其他更好的 Offer,肯定就不会考虑了。
中兴的未来领军招聘要求比较高,会要求你在某个领域有深入研究、论文或者比赛获奖经历。不过,走这个方向拿到 Offer 的,很多都是 SPP,开的薪资也比较高。
中兴的公积金是按照 8% 缴纳,年终通常比较低。另外,工作强度就不多说了,和菊厂差不多,但没有菊厂给的多。
中兴也有招聘 Java 的,下面给大家分享一篇中兴 Java 软开(未来领军)的一面面经。
实习期间做了什么?
如果你有实习经历的话,自我介绍之后,第二个问题一般就是聊你的实习经历。面试之前,一定要提前准备好对应的话术,突出介绍自己实习期间的贡献。
很多同学实习期间可能接触不到什么实际的开发任务,大部分时间可能都是在熟悉和维护项目。对于这种情况,你可以适当润色这段实习经历,找一些简单的功能研究透,包装成自己参与做的,大部分同学都是这么做的。不用担心面试的时候会露馅,只要不挑选那种明显不会交给实习生做的任务,你自己也能讲明白就行了。不过,还是更建议你在实习期间尽量尝试主动去承担一些开发任务,这样整个实习经历对个人提升也会更大一些。
示例:
- 负责订单模块核心流程开发,实现订单状态的精确流转,并保障与库存、支付等模块的数据一致性。
- 负责行为风控黑名单看板的开发,支持查看拉黑用户、批量拉黑以及取消拉黑。
- 基于 Redisson + AOP 封装限流组件,实现对核心接口(如付费、课程搜索)的限流,有效防止恶意请求冲击。
注入 Bean 的注解知道哪些?
Spring 内置的 @Autowired 以及 JDK 内置的 @Resource 和 @Inject 都可以用于注入 Bean。
| Annotation | Package | Source |
|---|---|---|
@Autowired |
org.springframework.bean.factory |
Spring 2.5+ |
@Resource |
javax.annotation |
Java JSR-250 |
@Inject |
javax.inject |
Java JSR-330 |
@Autowired 和@Resource使用的比较多一些。
@Autowired 和 @Resource 的区别是什么?
@Autowired 是 Spring 内置的注解,默认注入逻辑为先按类型(byType)匹配,若存在多个同类型 Bean,则再尝试按名称(byName)筛选。
具体来说:
- 优先根据接口 / 类的类型在 Spring 容器中查找匹配的 Bean。若只找到一个符合类型的 Bean,直接注入,无需考虑名称;
- 若找到多个同类型的 Bean(例如一个接口有多个实现类),则会尝试通过属性名或参数名 与 Bean 的名称进行匹配(默认 Bean 名称为类名首字母小写,除非通过
@Bean(name = "...")或@Component("...")显式指定)。
当一个接口存在多个实现类时:
- 若属性名与某个 Bean 的名称一致,则注入该 Bean;
- 若属性名与所有 Bean 名称都不匹配,会抛出
NoUniqueBeanDefinitionException,此时需要通过@Qualifier显式指定要注入的 Bean 名称。
举例说明:
java
// SmsService 接口有两个实现类:SmsServiceImpl1、SmsServiceImpl2(均被 Spring 管理)
// 报错:byType 匹配到多个 Bean,且属性名 "smsService" 与两个实现类的默认名称(smsServiceImpl1、smsServiceImpl2)都不匹配
@Autowired
private SmsService smsService;
// 正确:属性名 "smsServiceImpl1" 与实现类 SmsServiceImpl1 的默认名称匹配
@Autowired
private SmsService smsServiceImpl1;
// 正确:通过 @Qualifier 显式指定 Bean 名称 "smsServiceImpl1"
@Autowired
@Qualifier(value = "smsServiceImpl1")
private SmsService smsService;实际开发实践中,我们还是建议通过 @Qualifier 注解来显式指定名称而不是依赖变量的名称。
@Resource属于 JDK 提供的注解,默认注入逻辑为先按名称(byName)匹配,若存在多个同类型 Bean,则再尝试按类型(byType)筛选。
@Resource 有两个比较重要且日常开发常用的属性:name(名称)、type(类型)。
java
public @interface Resource {
String name() default "";
Class<?> type() default Object.class;
}如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName。
java
// 报错,byName 和 byType 都无法匹配到 bean
@Resource
private SmsService smsService;
// 正确注入 SmsServiceImpl1 对象对应的 bean
@Resource
private SmsService smsServiceImpl1;
// 正确注入 SmsServiceImpl1 对象对应的 bean(比较推荐这种方式)
@Resource(name = "smsServiceImpl1")
private SmsService smsService;简单总结一下:
@Autowired是 Spring 提供的注解,@Resource是 JDK 提供的注解。Autowired默认的注入方式为byType(根据类型进行匹配),@Resource默认注入方式为byName(根据名称进行匹配)。- 当一个接口存在多个实现类的情况下,
@Autowired和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired可以通过@Qualifier注解来显式指定名称,@Resource可以通过name属性来显式指定名称。 @Autowired支持在构造函数、方法、字段和参数上使用。@Resource主要用于字段和方法上的注入,不支持在构造函数或参数上使用。
考虑到 @Resource 的语义更清晰(名称优先),并且是 Java 标准,能减少对 Spring 框架的强耦合,我们通常更推荐使用 @Resource ,尤其是在需要按名称注入的场景下。而 @Autowired 配合构造器注入,在实现依赖注入的不可变性和强制性方面有优势,也是一种非常好的实践。
推荐阅读:Spring 常见面试题总结(Spring 基础、IoC、AOP、MVC、事务、循环依赖等)
项目中密码是则呢么保存的?
如果我们需要保存密码这类敏感数据到数据库的话,需要先加密再保存。
Spring Security 提供了多种加密算法的实现,开箱即用,非常方便。这些加密算法实现类的接口是 PasswordEncoder ,如果你想要自己实现一个加密算法的话,也需要实现 PasswordEncoder 接口。
PasswordEncoder 接口一共也就 3 个必须实现的方法。
java
public interface PasswordEncoder {
// 加密也就是对原始密码进行编码
String encode(CharSequence var1);
// 比对原始密码和数据库中保存的密码
boolean matches(CharSequence var1, String var2);
// 判断加密密码是否需要再次进行加密,默认返回 false
default boolean upgradeEncoding(String encodedPassword) {
return false;
}
}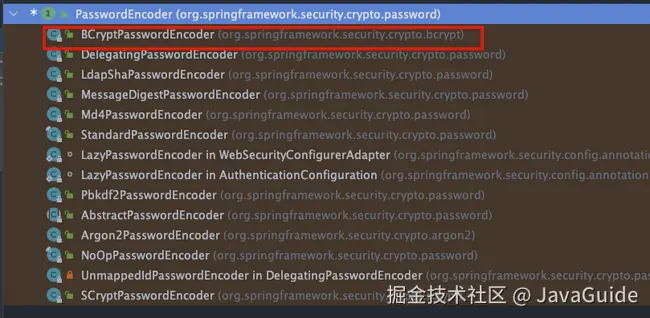
官方推荐使用使用 Bcrypt 这种密钥派生算法(Key Derivation Function,简称 KDF,也称为密码哈希算法)。
我之前分享过一篇文章详细介绍:简历别再写 MD5 加密密码了!。
MySQL InnoDB 和 MyISAM 区别?
MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
MySQL 5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
言归正传!咱们下面还是来简单对比一下两者:
1、是否支持行级锁
MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
也就说,MyISAM 一锁就是锁住了整张表,这在并发写的情况下是多么滴憨憨啊!这也是为什么 InnoDB 在并发写的时候,性能更牛皮了!
2、是否支持事务
MyISAM 不提供事务支持。
InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别,具有提交(commit)和回滚(rollback)事务的能力。并且,InnoDB 默认使用的 REPEATABLE-READ(可重读)隔离级别是可以解决幻读问题发生的(基于 MVCC 和 Next-Key Lock)。
3、是否支持外键
MyISAM 不支持,而 InnoDB 支持。
外键对于维护数据一致性非常有帮助,但是对性能有一定的损耗。因此,通常情况下,我们是不建议在实际生产项目中使用外键的,在业务代码中进行约束即可!
阿里的《Java 开发手册》也是明确规定禁止使用外键的。

不过,在代码中进行约束的话,对程序员的能力要求更高,具体是否要采用外键还是要根据你的项目实际情况而定。
总结:一般我们也是不建议在数据库层面使用外键的,应用层面可以解决。不过,这样会对数据的一致性造成威胁。具体要不要使用外键还是要根据你的项目来决定。
4、是否支持数据库异常崩溃后的安全恢复
MyISAM 不支持,而 InnoDB 支持。
使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 redo log 。
5、是否支持 MVCC
MyISAM 不支持,而 InnoDB 支持。
讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提高性能。
6、索引实现不一样。
虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
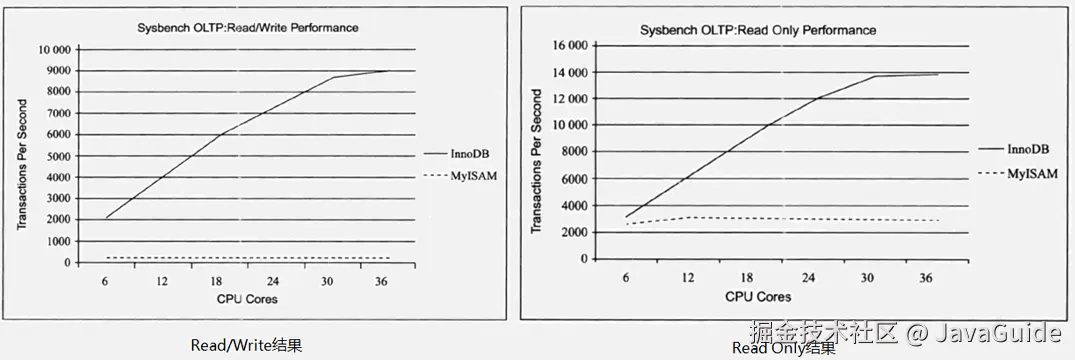
7、性能有差别。
InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是只读模式下,随着 CPU 核数的增加,InnoDB 的读写能力呈线性增长。MyISAM 因为读写不能并发,它的处理能力跟核数没关系。
8、数据缓存策略和机制实现不同。
InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使用键缓存(Key Cache)仅缓存索引页而不缓存数据页。
总结:
- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
- MyISAM 不支持外键,而 InnoDB 支持。
- MyISAM 不支持 MVCC,而 InnoDB 支持。
- 虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
- MyISAM 不支持数据库异常崩溃后的安全恢复,而 InnoDB 支持。
- InnoDB 的性能比 MyISAM 更强大。
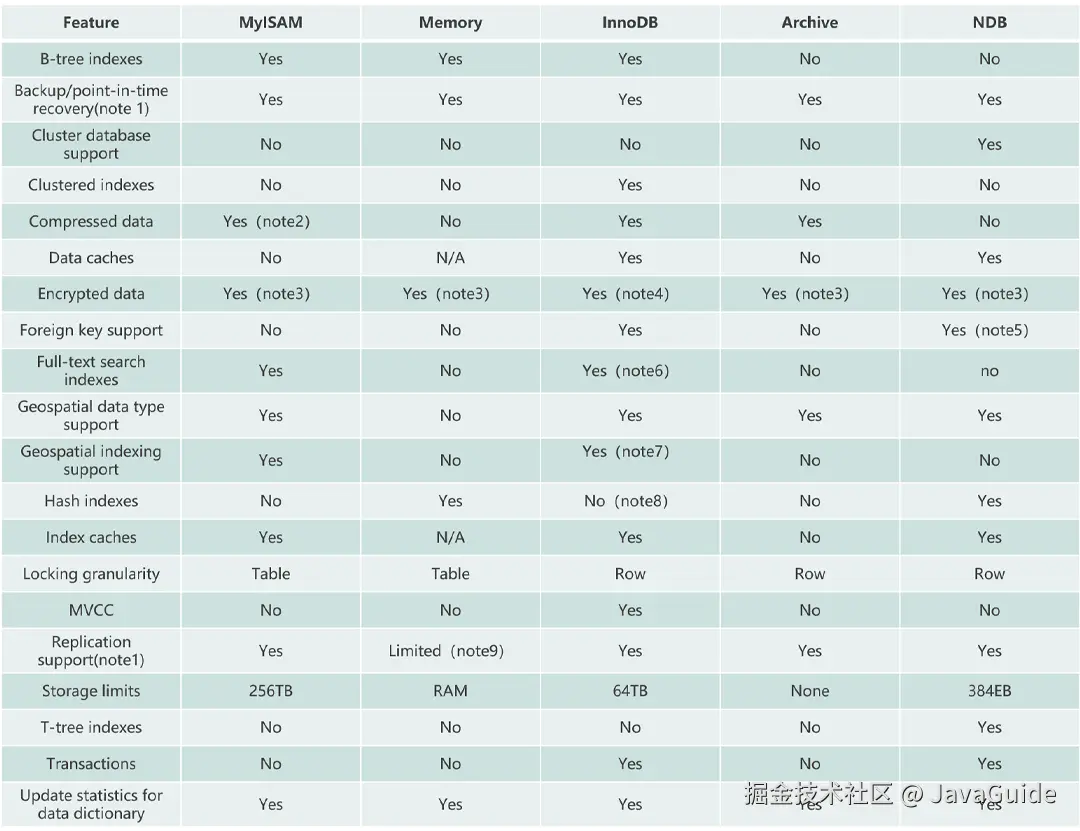
最后,再分享一张图片给你,这张图片详细对比了常见的几种 MySQL 存储引擎。
索引为什么快?
索引之所以快,核心原因是它大大减少了磁盘 I/O 的次数。
它的本质是一种排好序的数据结构,就像书的目录,让我们不用一页一页地翻(全表扫描)。
在 MySQL 中,这个数据结构是B+树。B+树结构主要从两方面做了优化:
- B+树的特点是"矮胖",一个千万数据的表,索引树的高度可能只有 3-4 层。这意味着,最多只需要3-4 次磁盘 I/O,就能精确定位到我想要的数据,而全表扫描可能需要成千上万次,所以速度极快。
- B+树的叶子节点是用链表连起来的 。找到开头后,就能顺着链表顺序读下去,这对磁盘非常友好,还能触发预读。
如何分析 SQL 语句是否走索引查询?
我们可以使用 EXPLAIN 命令来分析 SQL 的 执行计划 ,这样就知道语句是否命中索引了。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
EXPLAIN 并不会真的去执行相关的语句,而是通过 查询优化器 对语句进行分析,找出最优的查询方案,并显示对应的信息。
EXPLAIN 的输出格式如下:
sql
mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)各个字段的含义如下:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
更多 MySQL 高频知识点和面试题总结,可以阅读笔者写的这几篇文章:
- MySQL 常见面试题总结(MySQL 基础、存储引擎、事务、索引、锁、性能优化等)
- MySQL 索引详解
- MySQL 三大日志(binlog、redo log 和 undo log)详解
- MySQL 事务隔离级别详解
- InnoDB 存储引擎对 MVCC 的实现
- SQL 语句在 MySQL 中的执行过程
项目中引入 Redis 具体做了哪些事情?
Redis 除了可以用来缓存高频访问的数据之外,还以用来实现:
- 分布式锁 :通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:如何基于 Redis 实现分布式锁?。
- 限流 :一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
面试中,根据你项目的实际情况去回答即可!
相关阅读:
为什么删除 Redis 而不是更新 Redis
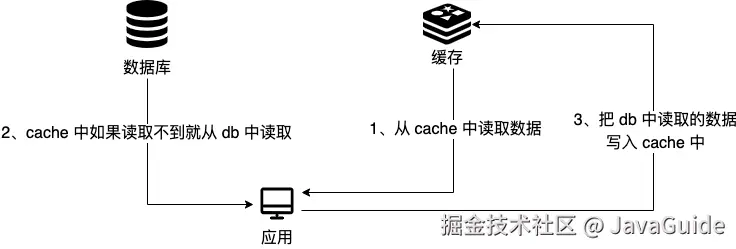
这里探讨的是 Cache Aside Pattern(旁路缓存模式),这是我们平时使用比较多的一个缓存读写模式。
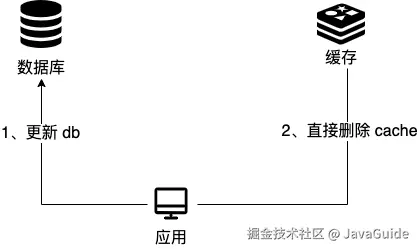
这个策略模式下的缓存读写步骤:
写 :
- 先更新 db;
- 直接删除 cache 。
读 :
- 从 cache 中读取数据,读取到就直接返回;
- cache 中读取不到的话,就从 db 中读取数据返回;
- 再把 db 中读取到的数据放到 cache 中。
为什么删除 cache,而不是更新 cache?
主要原因有两点:
- 对服务端资源造成浪费 :删除 cache 更加直接,这是因为 cache 中存放的一些数据需要服务端经过大量的计算才能得出,会消耗服务端的资源,是一笔不小的开销。如果频繁修改 db,就能会导致需要频繁更新 cache,而 cache 中的数据可能都没有被访问到。
- 产生数据不一致问题 :并发场景下,更新 cache 产生数据不一致性问题的概率会更大。
数据不一致举例说明一下:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。这个过程可以简单描述为:
- 请求 1(写操作) 先把 cache 中的 A 数据删除;
- 请求 2 (读操作) 过来,发现缓存里没有数据 A,于是从 db 中读取旧数据;
- 与此同时,请求 1 再把 db 中的 A 数据更新。
- 请求 2 把从数据库读到的旧值写入了缓存。
这就会导致请求 2 读取到的是旧值。并且,数据库里是新值,缓存里却是旧值,数据不一致了!
在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?
理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
如果更新数据库成功,而删除缓存失败怎么解决?
简单说有两个解决方案:
- 缓存失效时间变短(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
- 增加缓存更新重试机制(常用):如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试删除缓存,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
更多 Redis 高频面试题总结,可以阅读笔者写的这几篇文章:
- Redis 常见面试题总结(上)(Redis 基础、应用、数据类型、持久化机制、线程模型等)
- Redis 常见面试题总结(下)(Redis 事务、性能优化、生产问题、集群、使用规范等)
JVM 哪些区域会出现 OOM?
JVM 运行时数据区域如下:
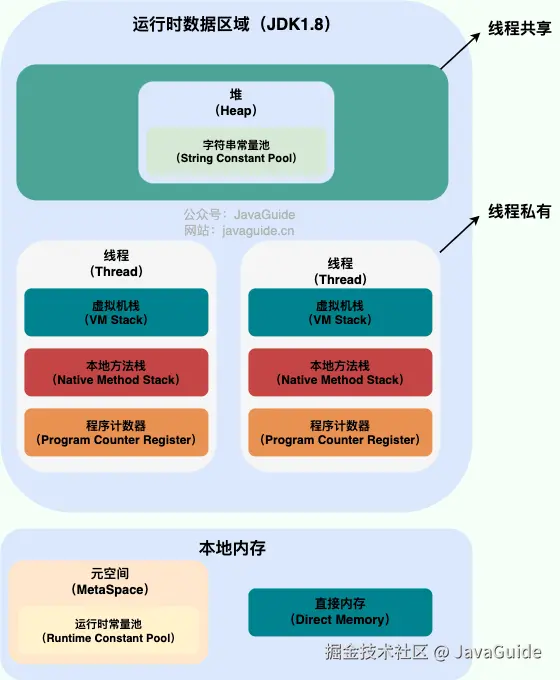
程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。
像虚拟机栈、本地方法栈、堆、直接内存等都可能会出现 OutOfMemoryError 。
OOM 怎么排查?
我们可以通过 MAT、JVisualVM 等工具分析 Heap Dump 找到导致OutOfMemoryError 的原因。
以 MAT 为例,其提供的泄漏嫌疑(Leak Suspects)报告是 MAT 最强大的功能之一。它会基于启发式算法自动分析整个堆,直接指出最可疑的内存泄漏点,并给出详细的报告,包括问题组件、累积点(Accumulation Point)和引用链的图示。
如果"泄漏嫌疑"报告不够明确,或者想要分析的是内存占用过高(而非泄漏)问题,可以切换到**支配树(Dominator Tree)**视图。这个视图将内存对象关系组织成一棵树,父节点"支配"子节点(即父节点被回收,子节点也必被回收)。
下面是一段模拟出现 OutOfMemoryError的代码:
java
import java.util.ArrayList;
import java.util.List;
public class SimpleLeak {
// 静态集合,生命周期与应用程序一样长
public static List<byte[]> staticList = new ArrayList<>();
public void leakMethod() {
// 每次调用都向静态集合中添加一个 1MB 的字节数组
staticList.add(new byte[1024 * 1024]); // 1MB
}
public static void main(String[] args) throws InterruptedException {
SimpleLeak leak = new SimpleLeak();
System.out.println("Starting leak simulation...");
// 循环添加对象,模拟内存泄漏过程
for (int i = 0; i < 200; i++) {
leak.leakMethod();
System.out.println("Added " + (i + 1) + " MB to the list.");
Thread.sleep(200); // 稍微延时,方便观察
}
System.out.println("Leak simulation finished. Keeping process alive for Heap Dump.");
// 保持进程存活,以便我们有时间生成 Heap Dump
Thread.sleep(Long.MAX_VALUE);
}
}为了更快让程序出现 OutOfMemoryError 问题,我们可以故意设置一个较小的堆 -Xmx256m。
IDEA 设置 VM 参数的方式如下图所示:
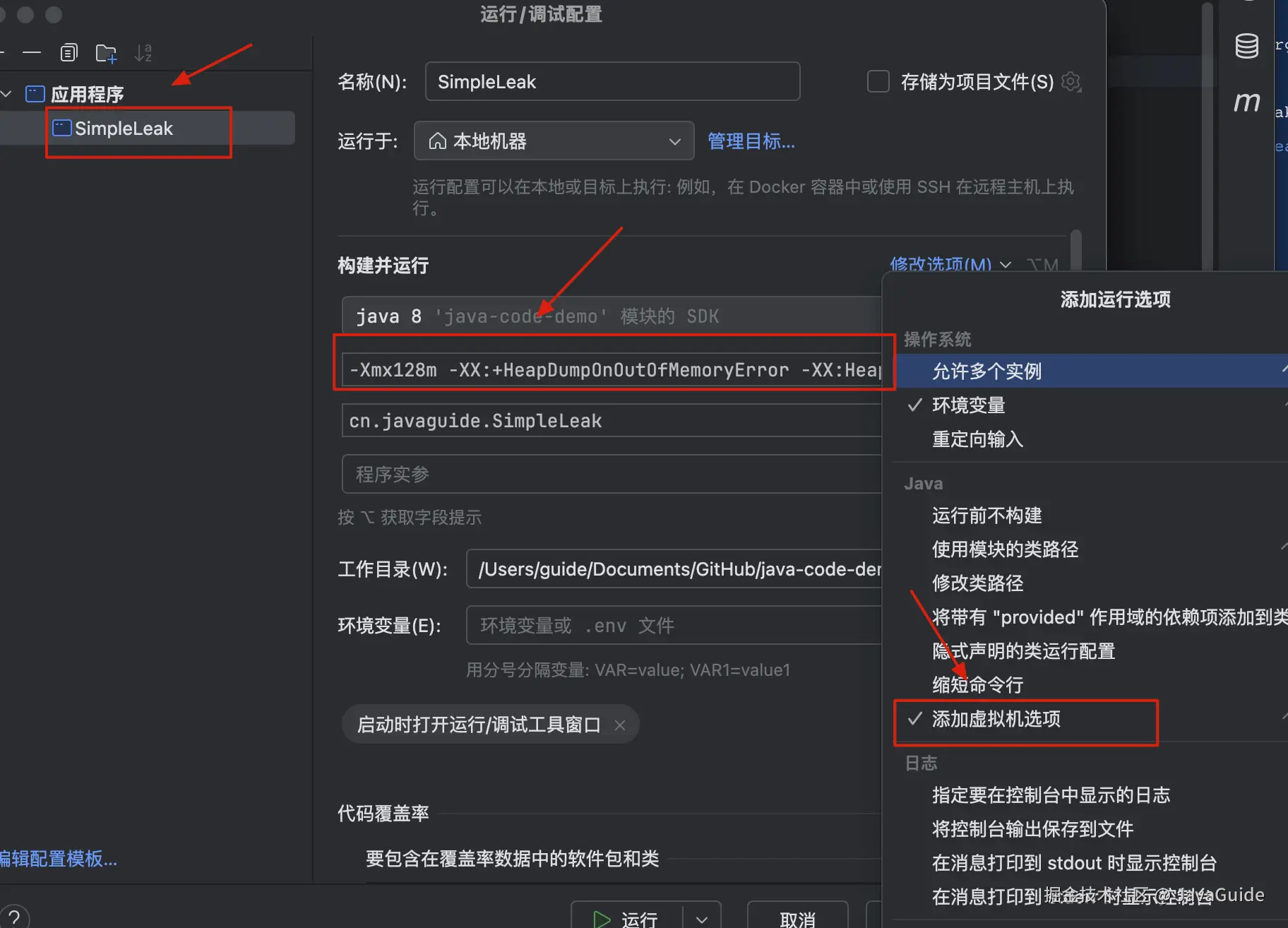
具体设置的 VM 参数是:-Xmx128m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=simple_leak.hprof,其中:
-Xmx128m:设置 JVM 最大堆内存为 128MB。-XX:+HeapDumpOnOutOfMemoryError:当 JVM 发生OutOfMemoryError时,自动生成堆转储文件(.hprof)。-XX:HeapDumpPath=simple_leak.hprof:指定 OOM 时生成的堆转储文件路径及文件名(这里是simple_leak.hprof)。
运行程序之后,会出现 OutOfMemoryError并自动生成了 Heap Dump 文件。
bash
Starting leak simulation...
Added 1 MB to the list.
Added 2 MB to the list.
Added 3 MB to the list.
......
Added 113 MB to the list.
Added 114 MB to the list.
Added 115 MB to the list.
java.lang.OutOfMemoryError: Java heap space
Dumping heap to simple_leak.hprof ...
Heap dump file created [124217346 bytes in 0.121 secs]我们将 .hprof 文件导入 MAT 后,它会首先进行解析和索引。完成后,可以查看它的 "泄漏嫌疑报告" (Leak Suspects Report) 。
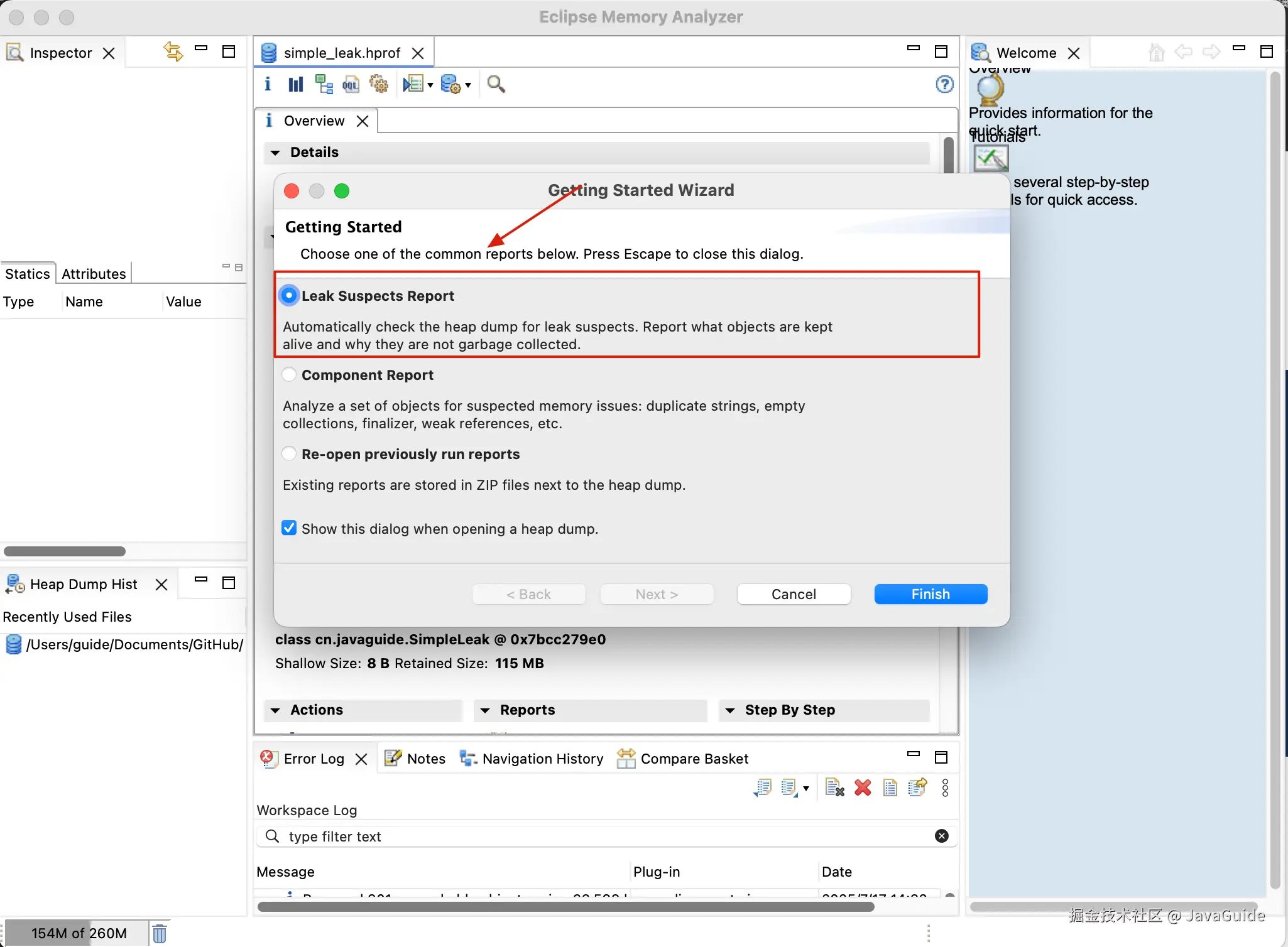
下图中的 Problem Suspect 1 就是可能出现内存泄露的问题分析:
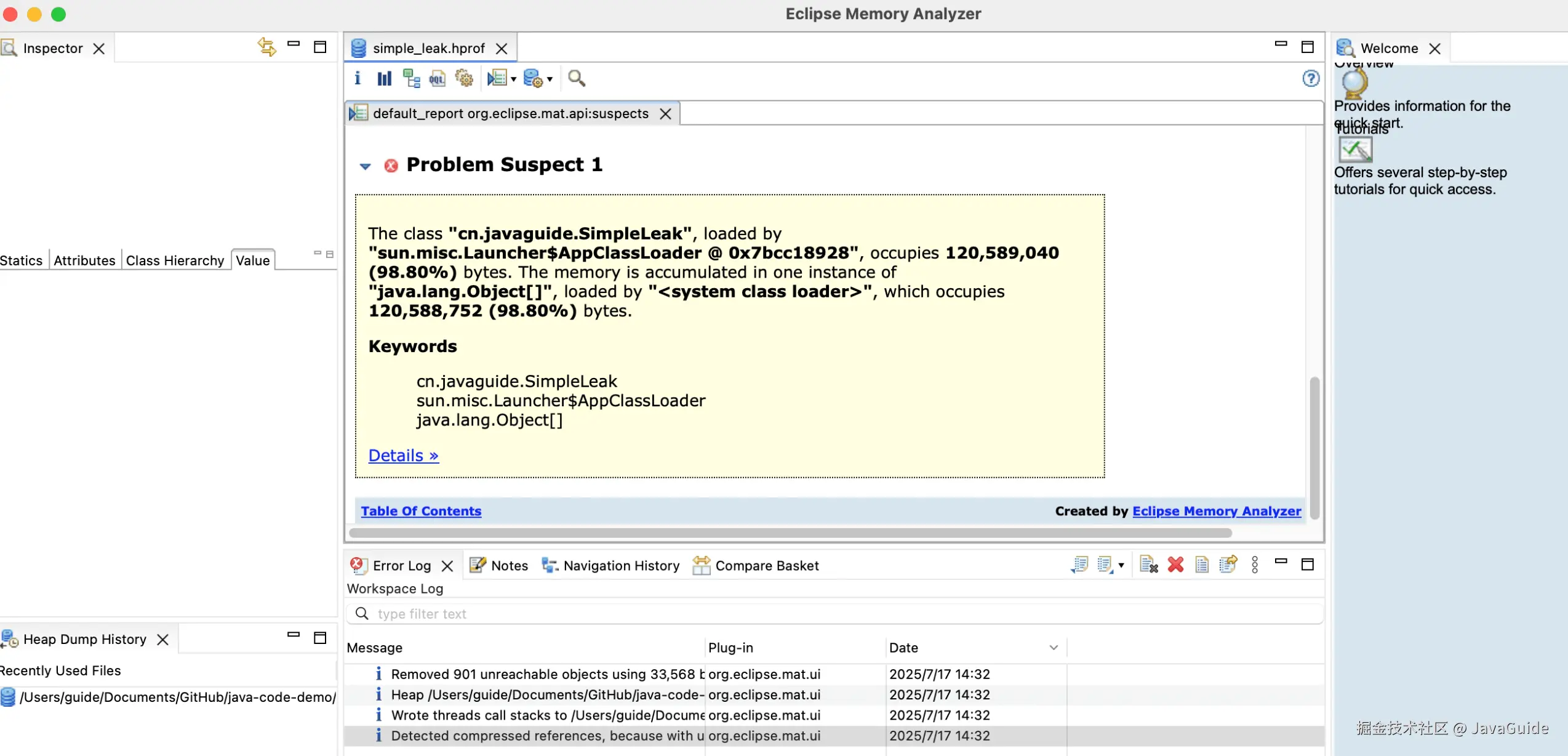
cn.javaguide.SimpleLeak类由sun.misc.Launcher$AppClassLoader加载,占用 120,589,040 字节(约 115MB,占堆 98.80%),是内存占用的核心。- 内存主要被
java.lang.Object[]数组 占用(120,588,752 字节),说明SimpleLeak中可能存在大量Object数组未释放,触发内存泄漏。
Problem Suspect 1 的可以看到有一个 Details,点进去即可看到内存泄漏的关键路径和对象占比:
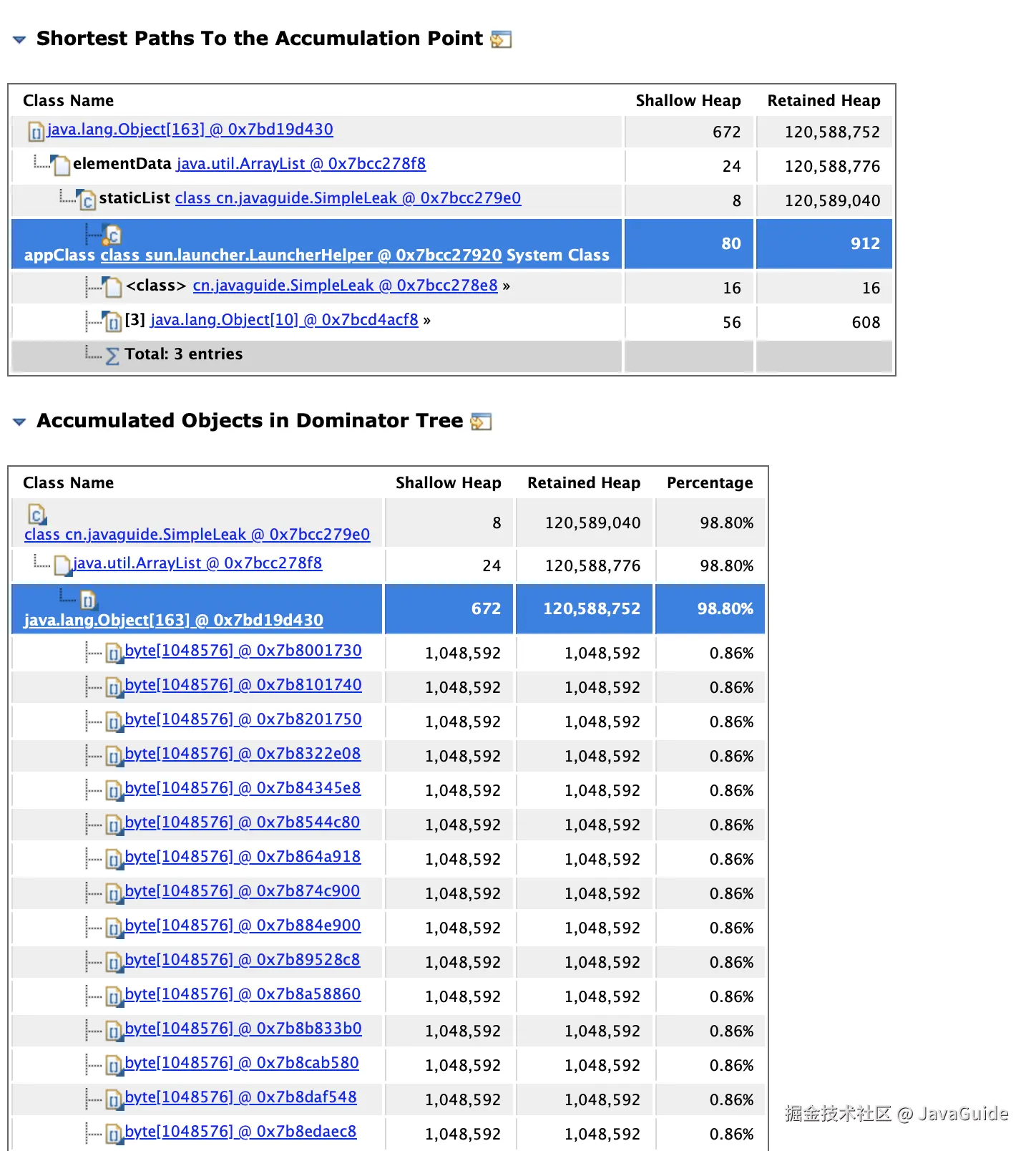
可以看到:SimpleLeak 中的静态集合 staticList 是内存泄漏的 "根源",因为静态变量生命周期与类一致,若持续向其中添加对象且不清理,会导致对象无法被 GC 回收。