通过前面简单的测试(Mac mini M4运行DeepSeek-R1实测:两步搞定,效率惊人!),我们发现得益于统一内存架构,Mac mini M4能够游刃有余地运行DeepSeek-R1模型,而且运行体验整体不错。
使用ollama运行DeepSeek-R1时,默认拉取的是INT4量化后的8B参数模型,模型大小是5.2 GB,模型完全运行在GPU上面,活动监视器显示占用内存5.52 GB。
那我这台16 GB运行内存、256 GB存储的Mac mini M4,到底能运行多大的DeepSeek-R1模型呢?我们今天来一探究竟。
首先,我选择了模型文件大小在16 GB以内的DeepSeek-R1模型共11个,分别是DeepSeek-R1:1.5B模型3个(INT4量化、INT8量化和FP16原生)、7B模型3个(INT4量化、INT8量化和FP16原生)、8B模型3个(INT4量化、INT8量化和FP16原生)、14B模型2个(INT4量化和INT8量化)。
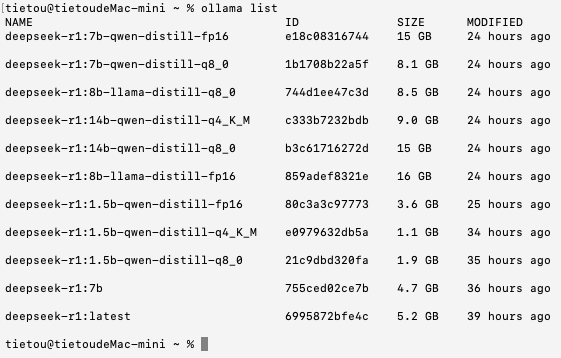
我们由浅入深,按照模型参数规模由小到大、量化精度由低到高的顺序进行测试。
首先是DeepSeek-R1:1.5B的INT4量化模型,模型文件大小1.1 GB,加载时间为10秒,这慢热的登场方式或许暗藏玄机,毕竟其他更大模型的加载时间都比它短得多。
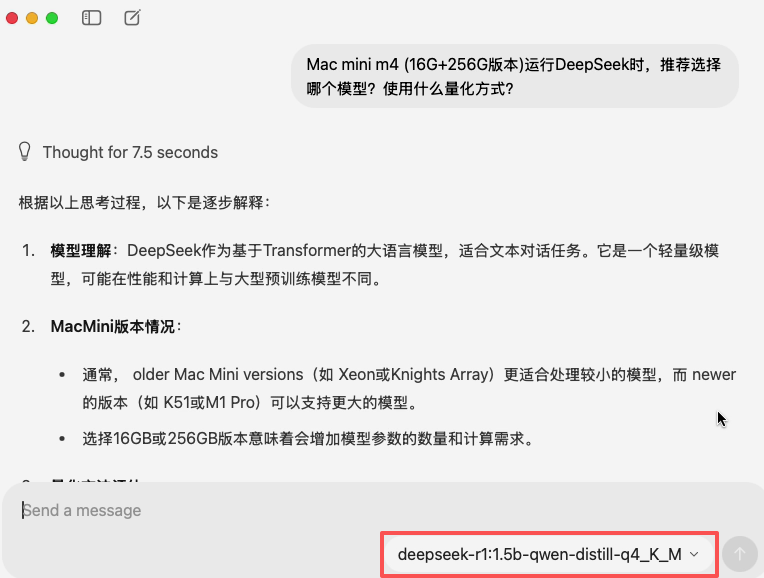
测试时,我们就是用ollama自带的对话窗口,通过对话框中的下拉框切换不同的模型。不得不说,小模型的响应速度堪称动如脱兔,思考+答复的总时间约为13秒,每秒大约能输出200个字符以上。
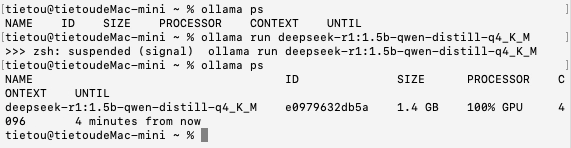
加载模型之后,100%使用GPU进行运算,显示的模型尺寸为1.4 GB。不过,内存占用显示只有300 MB,只有在思考时内存占用才会升上去。
接下来是DeepSeek-R1:1.5B的INT8量化模型,模型文件大小1.9 GB,加载时间为3秒,思考+答复的总时间约为15秒,每秒大约能输出100个字符以上。
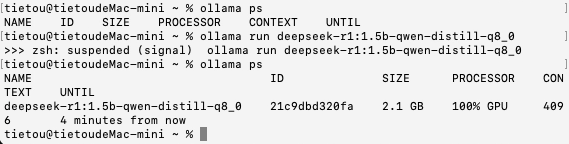
加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为2.1 GB。非对话状态下的内存占用显示也只有300 MB,只有在思考时内存占用才会升上去。
接下来是DeepSeek-R1:1.5B的FP16量化模型,模型文件大小3.6 GB,加载时间为4秒,思考+答复的总时间约为35秒,每秒大约能输出40个字符。
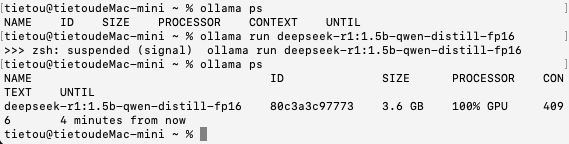
加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为3.6 GB。内存占用显示情况与前述一致,只有在思考时内存占用才会升上去。
接下来是DeepSeek-R1:7B的INT4量化模型,模型文件大小4.7 GB,加载时间为5秒,思考+答复的总时间约为56秒,每秒大约能输出40个字符。
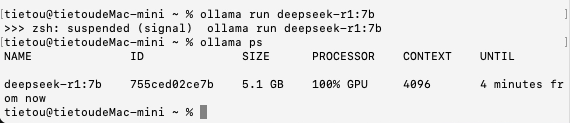
加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为5.1 GB。内存占用显示情况与前述一致,只有在思考时内存占用才会升上去。
接下来是DeepSeek-R1:7B的INT8量化模型,模型文件大小8.1 GB,加载时间为6秒,思考+答复的总时间约为94秒,每秒大约能输出20-30个字符。
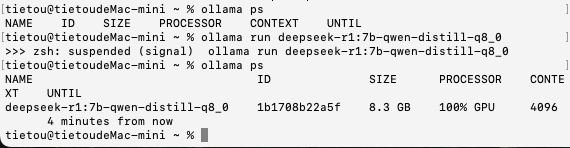
加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为8.3 GB。内存占用显示情况与前述一致,只有在思考时内存占用才会升上去。
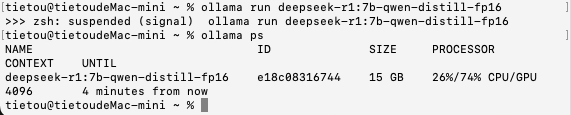
接下来是DeepSeek-R1:7B的FP16量化模型,模型文件大小15 GB,加载时间为11秒;比较遗憾的是,模型回答问题失败了。

与前面的其他模型不同,这个加载模型之后,显示有26%分配到了CPU、74%分配到了GPU进行运算,模型尺寸为15 GB。估计是运行内存空间不足的问题,导致深度思考失败。
接下来是DeepSeek-R1:8B的INT4量化模型,模型文件大小5.2 GB,加载时间为5秒,思考+答复的总时间约为84秒,每秒大约能输出50个字符。

加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为5.9 GB,只有在思考时内存占用才会升上去。
接下来是DeepSeek-R1:8B的INT8量化模型,模型文件大小8.5 GB,加载时间为6秒,思考+答复的总时间约为138秒,每秒大约能输出20-30个字符以上。
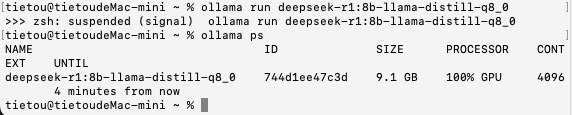
加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为9.1 GB,只有在思考时内存占用才会升上去。
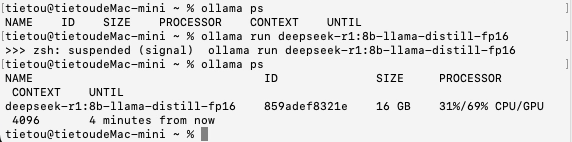
接下来是DeepSeek-R1:7B的FP16量化模型,模型文件大小16 GB,加载时间为12秒;比较遗憾的是,模型回答问题也失败了。
这次加载模型之后,显示有31%分配到了CPU、69%分配到了GPU进行运算,模型尺寸为16 GB。应该也是运行内存空间不足的问题,导致深度思考失败。这引发了我们的思考:其背后的计算资源调度机制究竟是怎样的?
接下来是DeepSeek-R1:14B的INT4量化模型,模型文件大小9 GB,加载时间为6秒,思考+答复的总时间约为170秒,每秒大约能输出20-30个字符。
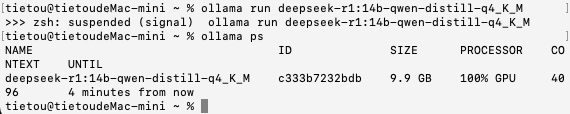
加载模型之后,仍然100%使用GPU进行运算,显示的模型尺寸为9.9 GB,只有在思考时内存占用才会升上去。
接下来是DeepSeek-R1:14B的INT8量化模型,模型文件大小16 GB,加载时间为10秒,;比较遗憾的是,模型回答问题也失败了。
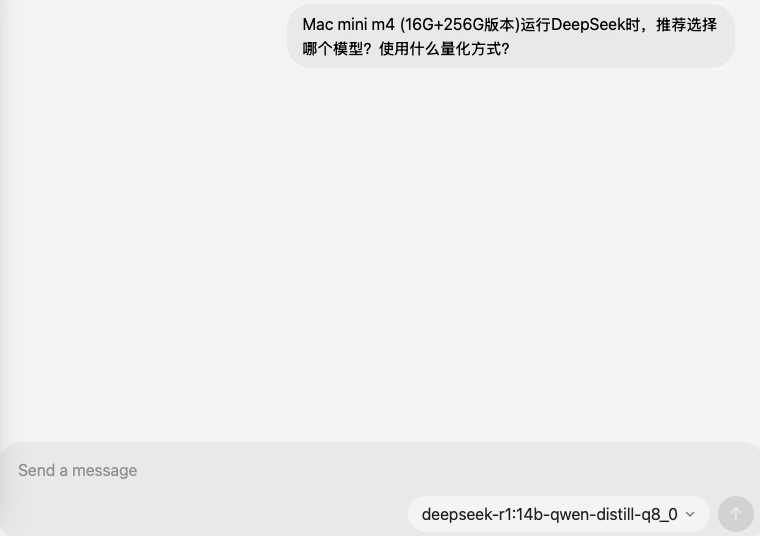
这次加载模型之后,显示有32%分配到了CPU、68%分配到了GPU进行运算,模型尺寸为16 GB。这次肯定是内存空间不足导致的深度思考失败。
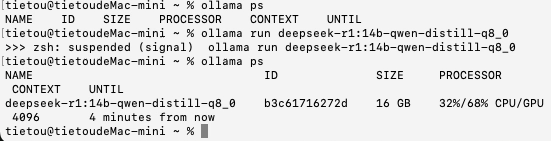
在思考过程中,我们注意活动监视器中内存的使用情况,发现ollama进程的内存占用已经达到了15.92 GB,就连SWAP交换内存都用了4.12 GB,但是SWAP的性能肯定是要差得远,大量使用SWAP交换内存触发了木桶效应,所以最终导致思考失败。
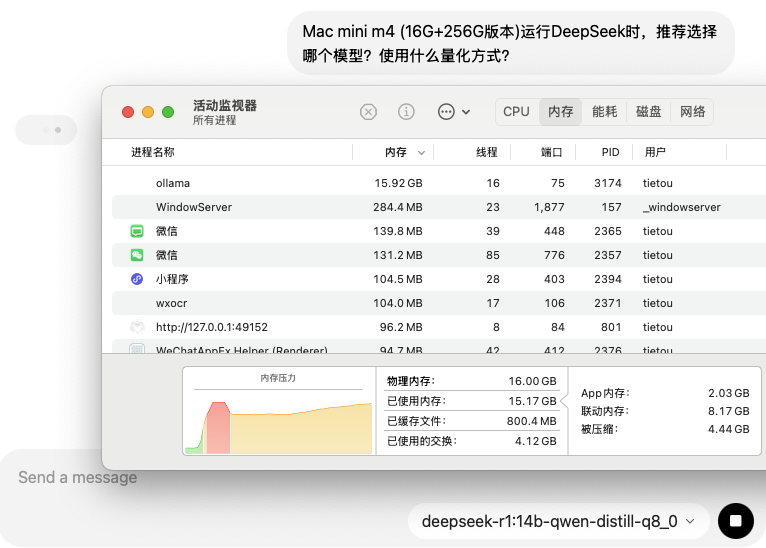
在思考失败之后,我们发现内存压力快速下降。此时,我们再次发起提问。
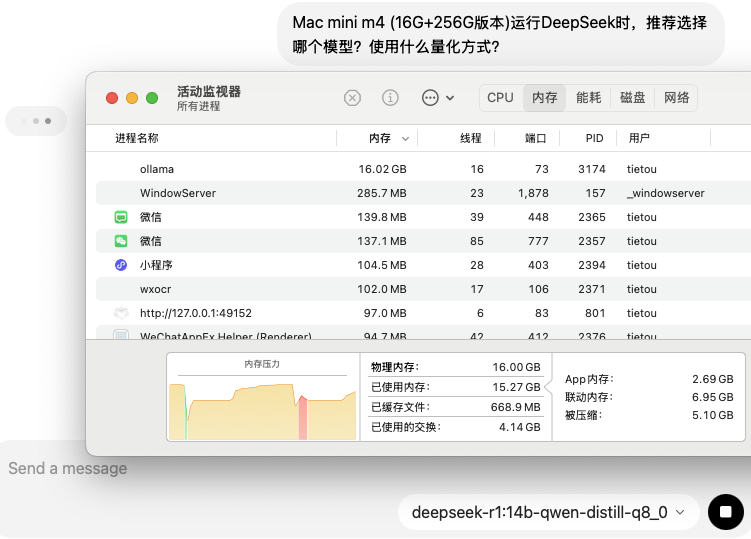
可以看到,ollama的内存使用量竟然突破了16 GB物理内存的上线,达到了16.02 GB。但于事无补,毫无疑问,最后思考还是失败了。
既然ollama显示计算有32%分配到了CPU,那CPU的负载大吗?于是我再次提问。
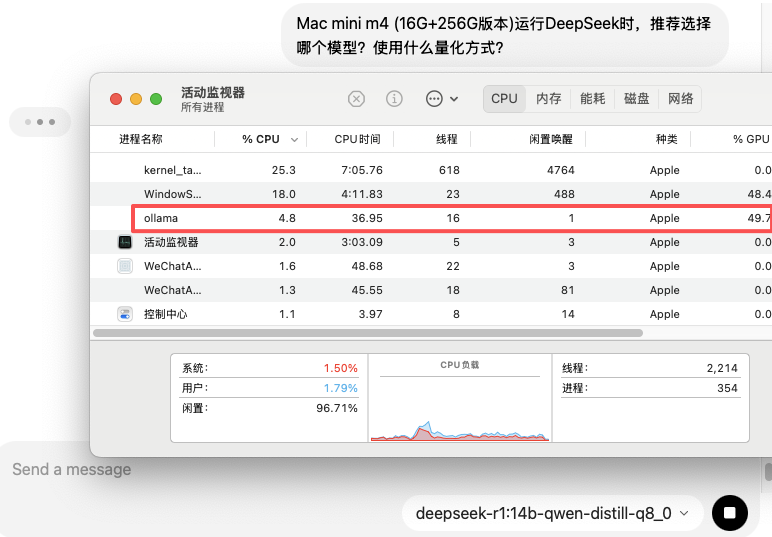
结果发现,CPU这边整体还是很悠闲的,计算主力分布在能效核心1和2上面,4颗性能核心只是稍微参与了一下。
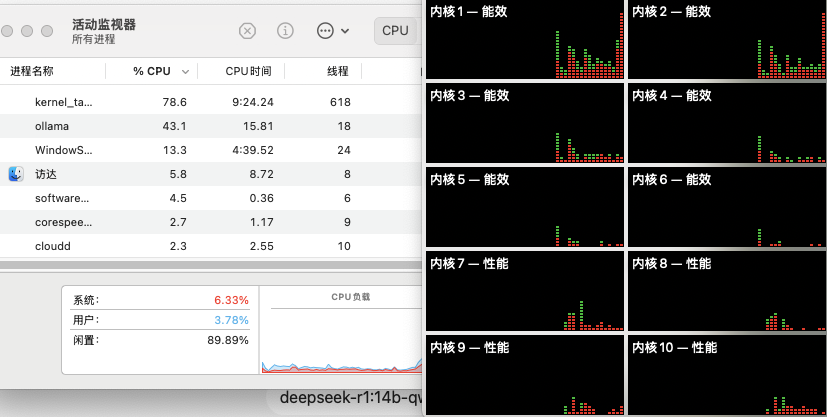
这么看来,想把16 GB统一内存完全分配给GPU用几乎是不可能的。而且,可能是模型参数相比我们之前测评NVIDIA时更大了,所以需要更大的显存,就连DeepSeek-R1:7B的FP16量化模型都跑不起来了,要知道,之前在NVIDIA环境下,它的显存占用大约是14.6 GB。
最后,简单做一下汇总,并与之前的NVIDIA环境做一下对比(目前来看,ollama量化过的DeepSeek模型应该就是最具性价比的选择)。
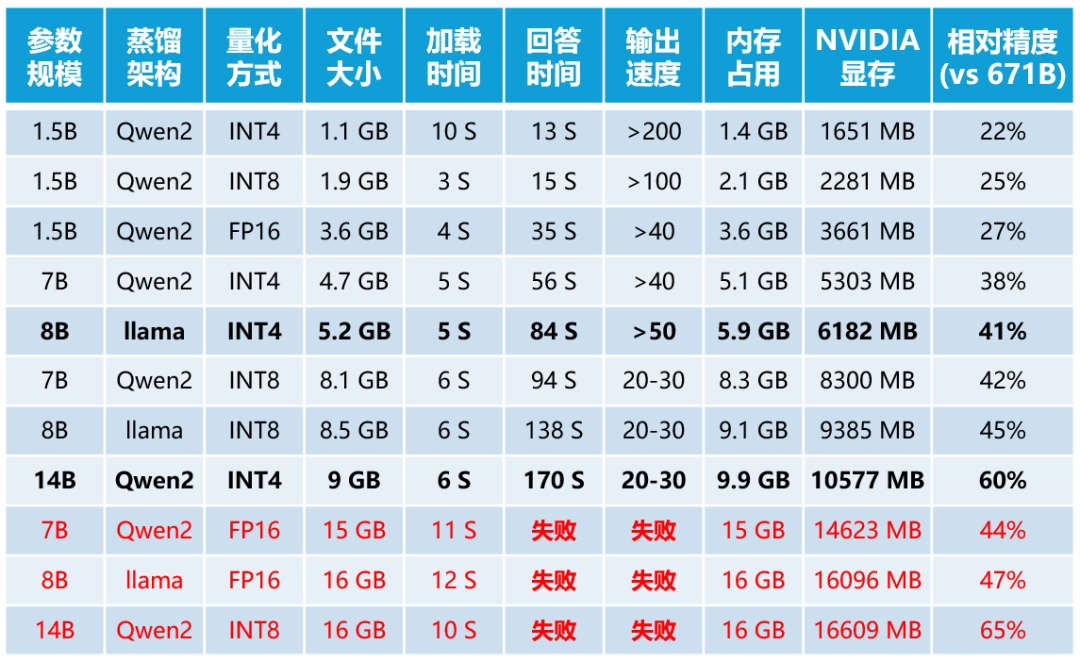
整体来看,官方将默认模型调整为了DeepSeek-R1:8B的INT4量化模型,貌似又是兼顾了大家的体验,相比于DeepSeek-R1:7B的INT4量化模型,牺牲了一部分资源占用,但提高了准确度和输出速度,你觉得这个操作怎么样呢?
目前,16 GB运行内存的Mac mini M4,能够运行的最大模型是INT4量化的DeepSeek-R1:14B,那运行这个模型时Mac mini主机的功耗是多少呢?
计算时的功耗在30瓦-34瓦之间波动,扣掉未启动ollama时的系统功耗5瓦,也就说最高仅需29瓦,你就可以在本地运行INT4量化的DeepSeek-R1:14B模型,堪称四两拨千斤的能效典范!
***推荐阅读***
手慢无!CodeBuddy×腾讯云放送免费服务器,一招教你"空手套白狼"
粉丝福利:5本图书免费送!一本书读懂TCP/IP,掌握互联网的通用语言!
WireGuard太复杂?十分钟教你用Netmaker一键搞定全球组网
远程办公利器:手把手教你搭建FortiGate SSL-VPN安全隧道
告别繁琐命令行:用开源ToughRADIUS轻松管理H3C SSLVPN千名用户
400元自建企业级Wi-Fi!零基础搭建AC+AP环境,全网最简组网指南
免费又专业!FreeRADIUS对接H3C无线网络,完美实现Portal认证
MacOS用户福音:手把手教你在新版macOS上安装H3C iNode客户端
实测确认!MSR路由器自带SSL授权,免费搭建远程接入就这么简单
H3C SSL VPN高阶技巧:从IP绑定到ACL过滤,打造安全远程接入
一劳永逸:实战Ubuntu服务器PXE自动化部署,从此装机so easy
解锁macOS新姿势:手把手教你用SSH远程登录,效率倍增!
Mac mini M4运行DeepSeek-R1实测:两步搞定,效率惊人!
