
最近使用 Apache DolphinScheduler 调度任务,不可避免地使用到【补数据】功能,经过不断尝试,终于成功运行了【补数据】功能,以此帖记录。
- 版本说明:3.1.9
补数据功能简介
"补数据" 在 Apache DolphinScheduler 中指的是 补数据(Complement Data) 功能,用于补充执行历史时间段内的工作流实例。
补数据功能概述
补数据是工作流执行的一种特殊模式,让用户可以为过去的时间段批量创建和执行工作流实例。这在以下场景中特别有用:
- 需要重新处理历史数据
- 系统故障后需要补充缺失的数据处理
- 新增数据处理逻辑后需要回填历史数据
- 定期批量数据处理
补数据配置参数
在工作流启动界面中,补数据功能包含以下配置选项:
-
是否是补数据 (
whether_complement_data): 开关选项,启用补数据模式 -
调度日期 (
schedule_date): 指定需要补数据的时间范围 :- 支持日期选择和手动输入两种方式
- 格式为
yyyy-MM-dd HH:mm:ss,多个日期用逗号分隔 - 限制最多输入100条日期
-
执行方式 (
mode_of_execution):- 串行执行: 按顺序逐个执行补数据任务
- 并行执行: 同时执行多个补数据任务
-
并行度 (
parallelism): 当选择并行执行时,可以设置自定义并行度来控制同时执行的任务数量- 这有助于避免大量补数据任务对服务器造成过大影响
-
执行顺序 (
order_of_execution) :- 按日期升序执行: 从最早的日期开始执行
- 按日期降序执行: 从最近的日期开始执行
使用补数据功能操作步骤
首先是工作流的任务配置,见下图
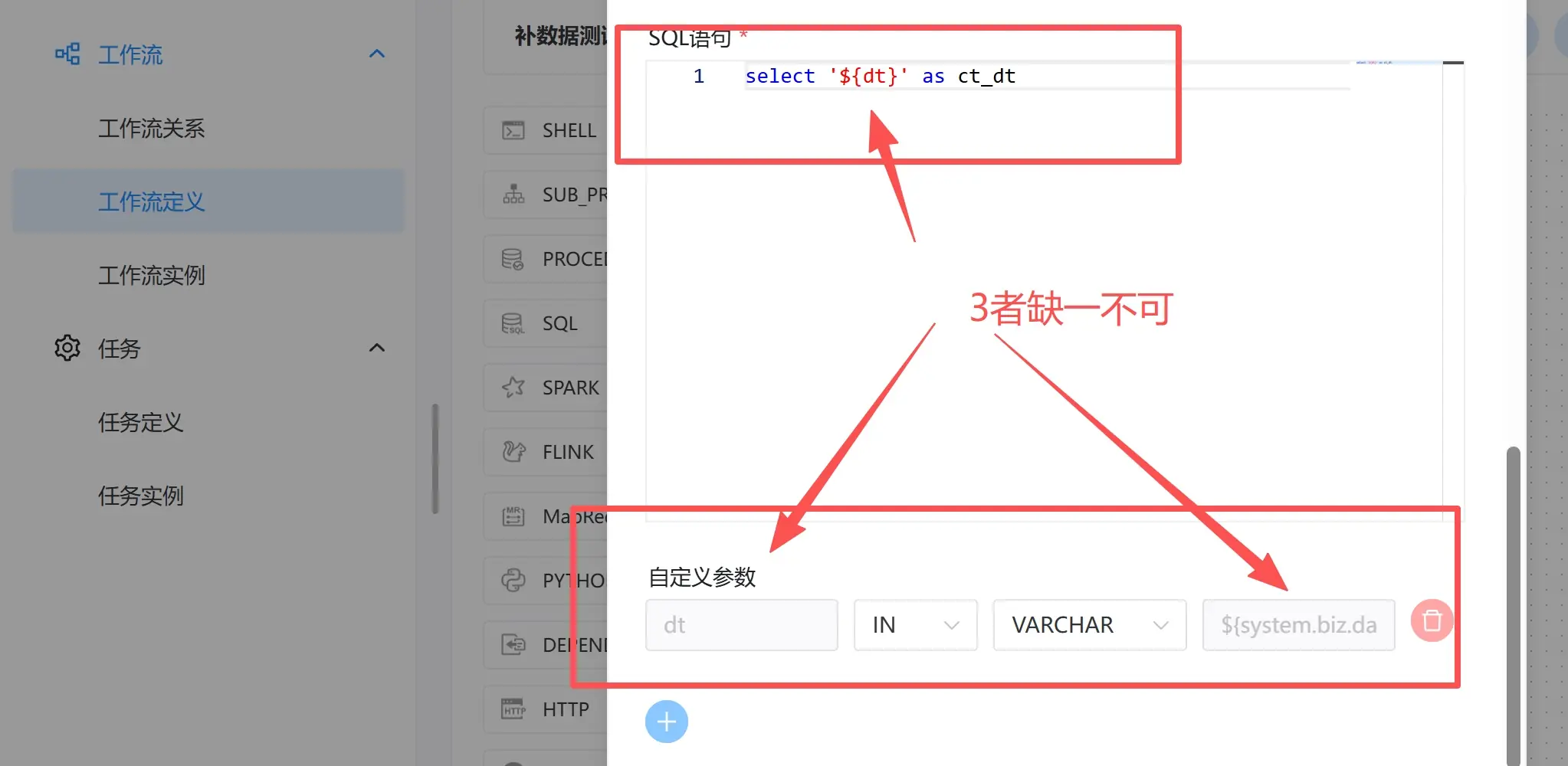
接着,保存工作流,未设置全局变量。上线工作流。
最后,运行工作流,运行参数见下图
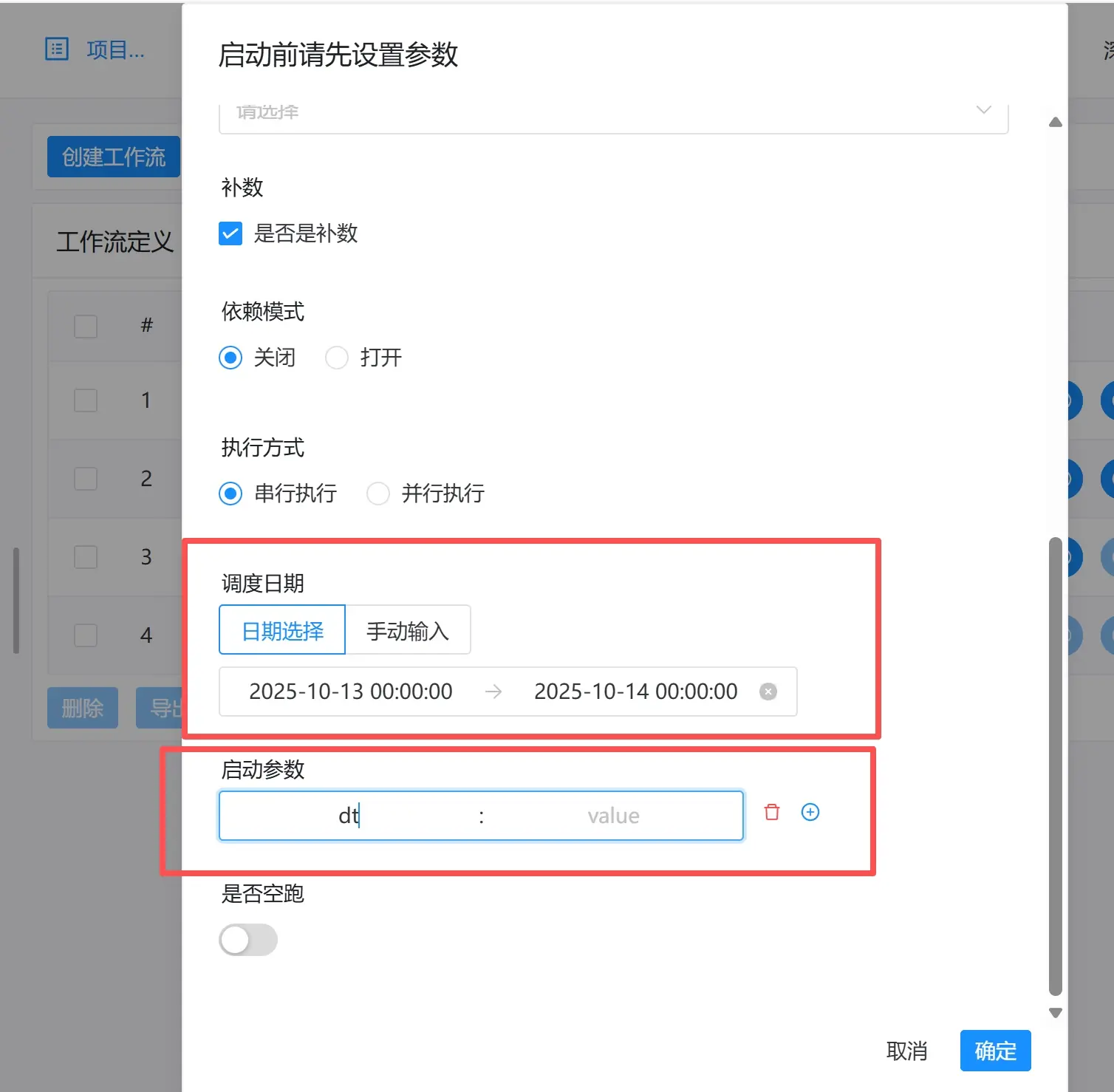
- 选择补数据的日期范围
- 【启动参数】为定义任务时设置的参数dt,value为空即可。
- 点击【确定】后自动运行
验证结果
点击【工作流实例】,查看运行结果。
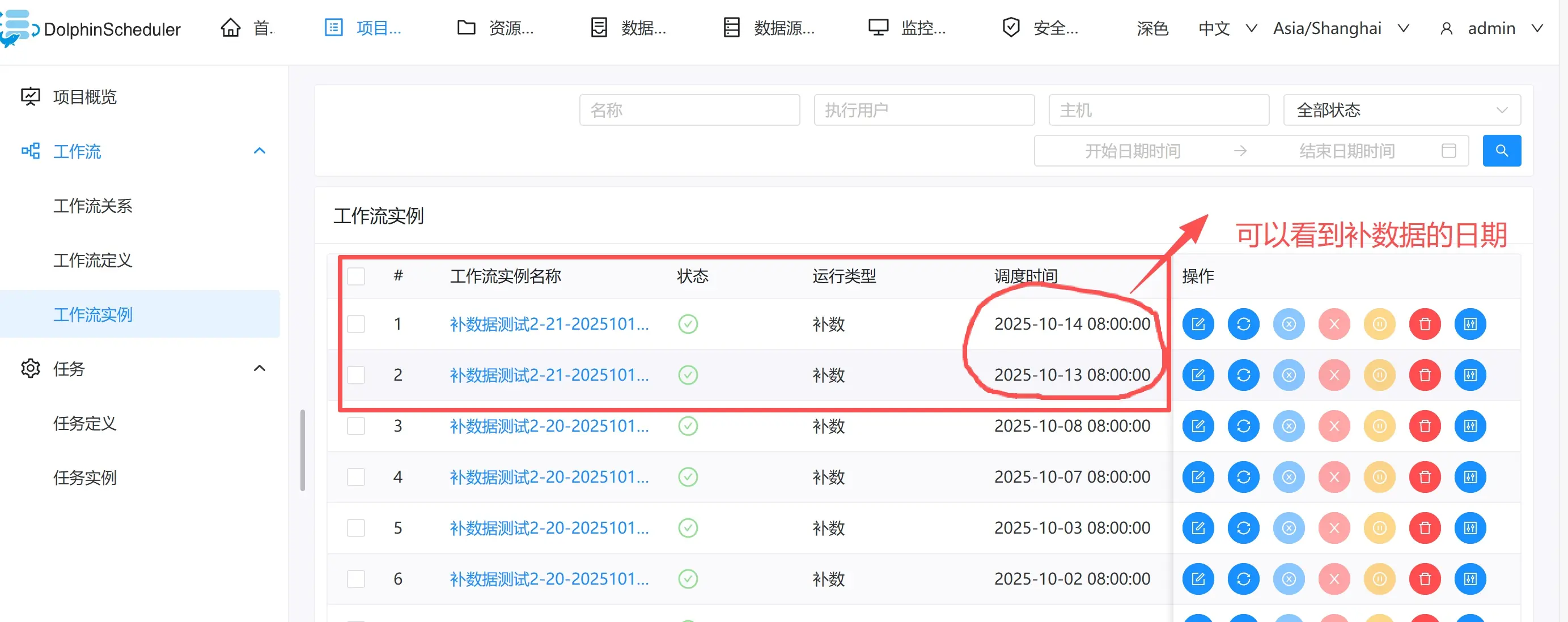
点击第1个实例进入,查看日志
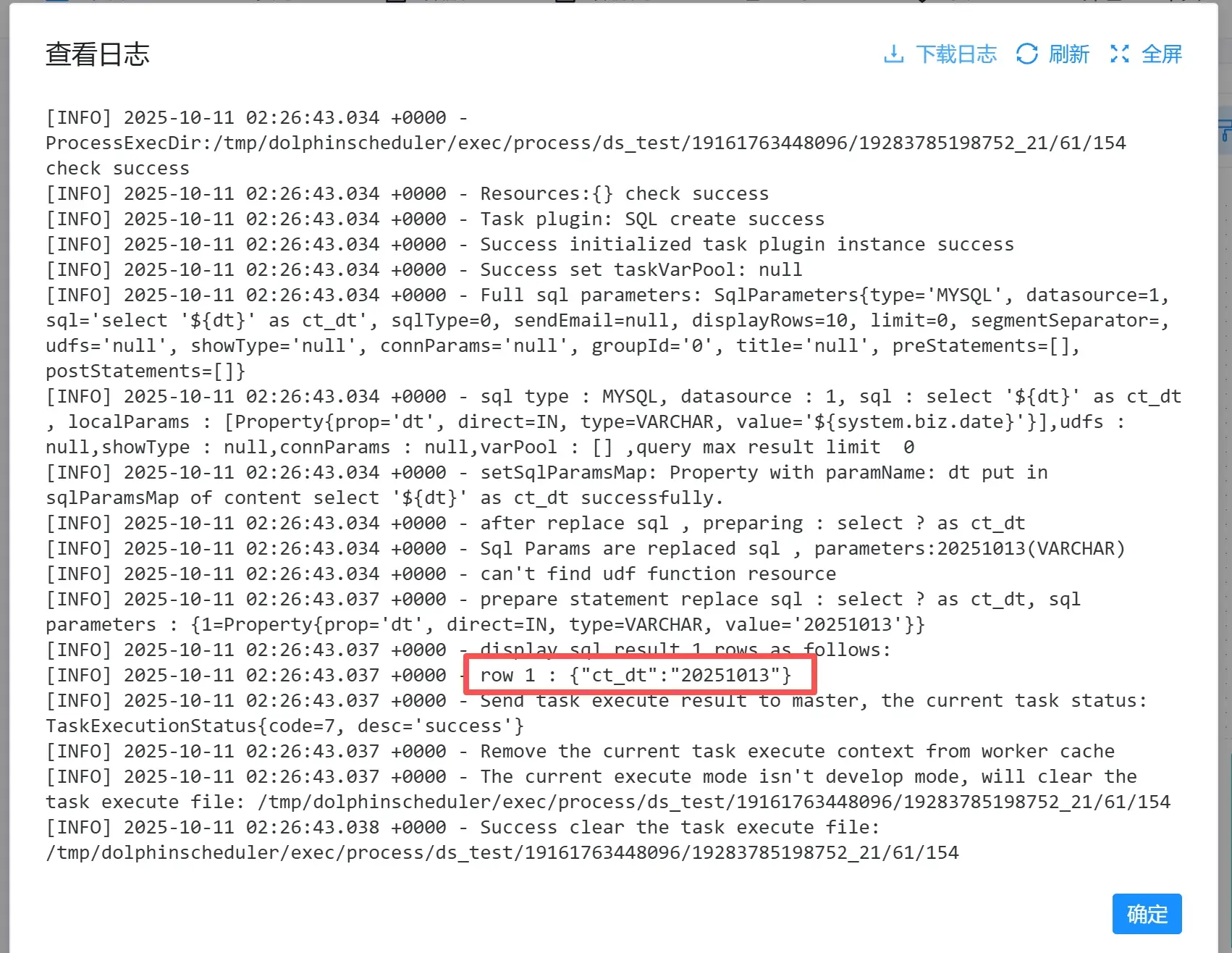
结果显示,SQL 运行结果为补数据选择的日期,补数据功能正常可用。
Notes
补数据功能是 Apache DolphinScheduler 工作流管理中的重要特性,通过灵活的配置选项(执行方式、并行度、执行顺序等)来满足不同的数据补充需求。在使用时需要注意合理设置并行度,避免对系统资源造成过大压力。