1.功能
MapReduce可以将复杂的 、运行于大规模集群上的 并行计算过程高度抽象到了两个函数:Map 和Reduce,并极大的方便了分布式编程工作。
2.实例(词频统计)
1.创建文件
在本地创建文件wordfile1.txt和wordfile2.txt
bash
touch wordfile1.txt
echo "I love Spark" >> wordfile1.txt
echo "I love Hadoop" >> wordfile1.txt
//创建文件
bash
touch wordfile2.txt
echo "Hadoop is good" >> wordfile2.txt
echo "Spark is fast" >> wordfile2.txt
//创建文件
打开Hadoop服务
bash
start-dfs.sh
//开启Hadoop服务
查看是否有/user/hadoop/input目录
bash
hdfs dfs -ls /user/hadoop
//查看目录
创建/user/hadoop/input目录
bash
hdfs dfs -mkdir -p /user/hadoop/input
//创建input目录
创建文件
bash
hdfs dfs -echo "I love Hadoop" > /user/hadoop/input/wordfile1.txt
//创建文件并写入内容
上传文件到HDFS
bash
hdfs dfs -put wordfile1.txt wordfile2.txt /user/hadoop/input
//上传HDFSDFS
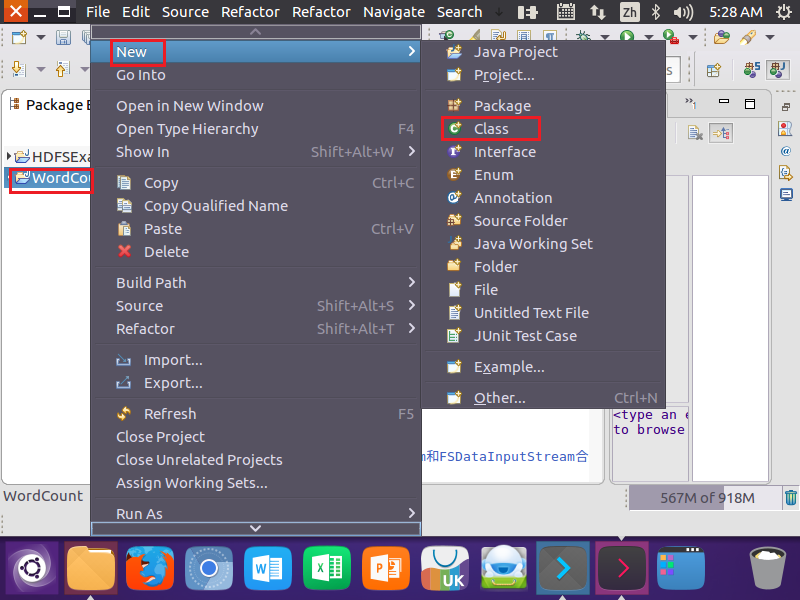
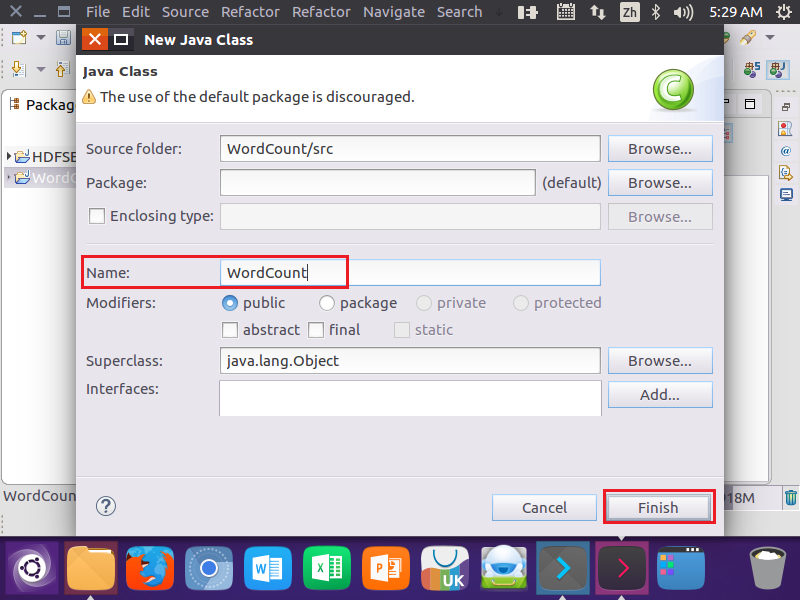
2.在Eclipse中创建项目
3.为项目创建所需要的JAR包
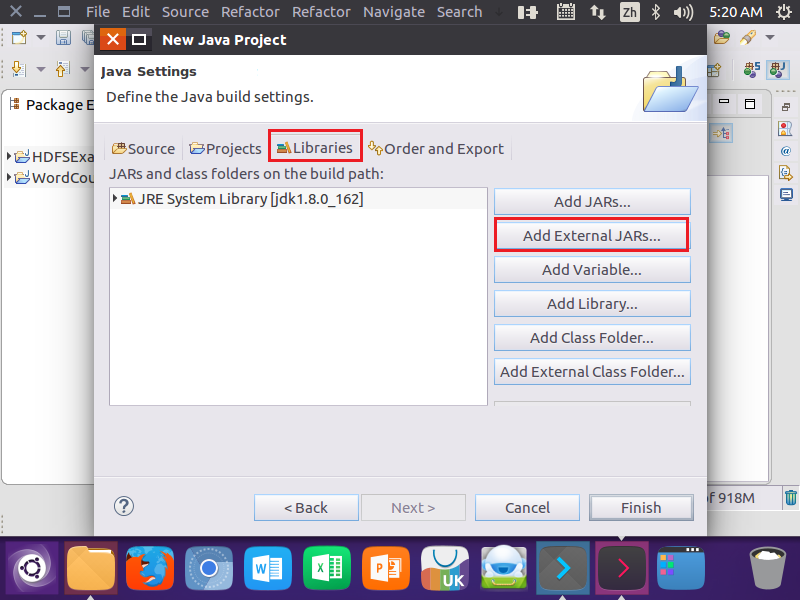
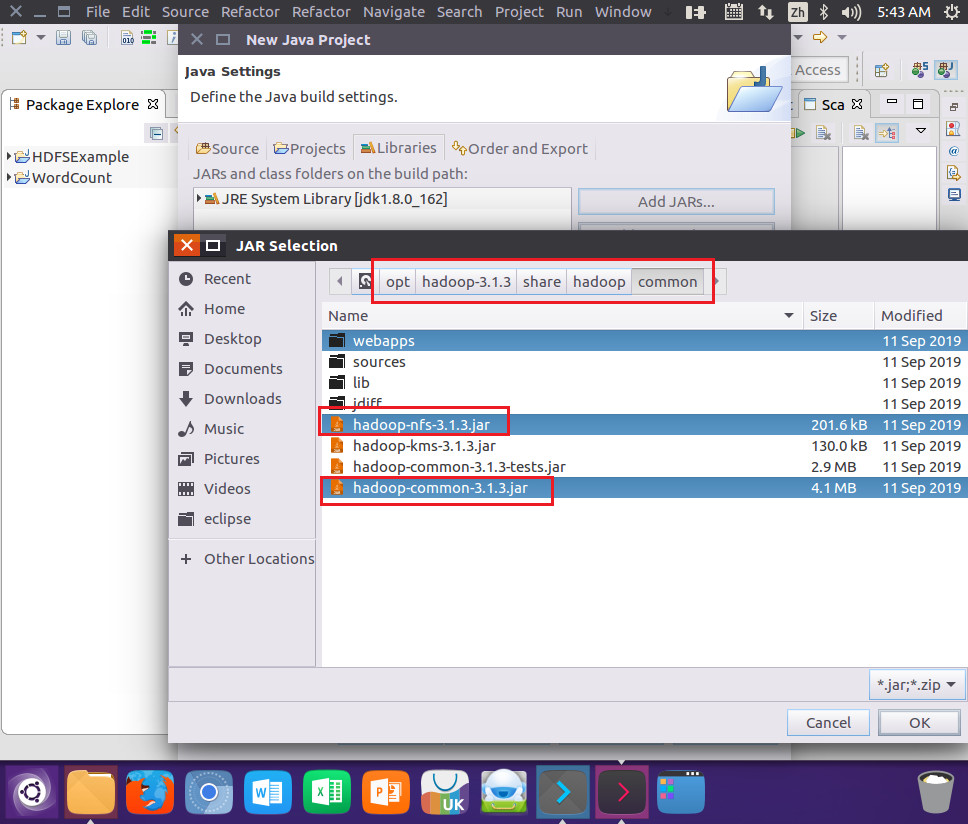
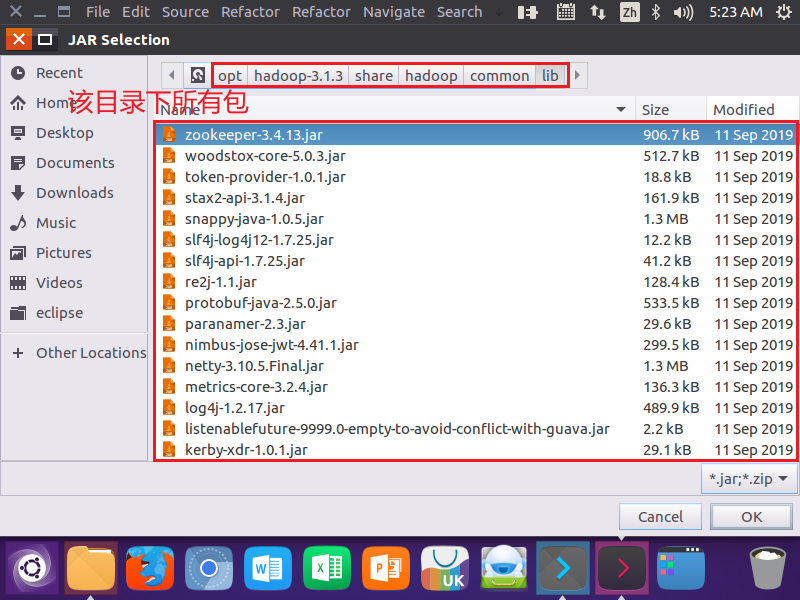
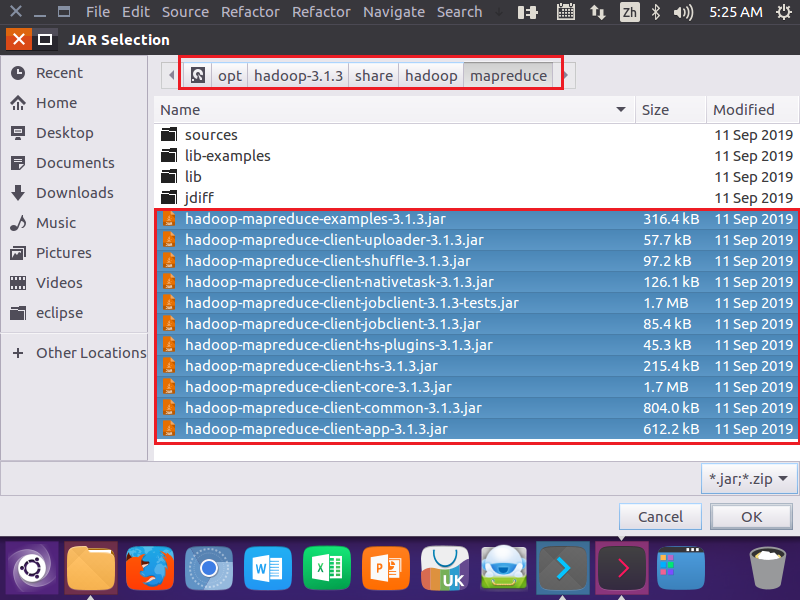
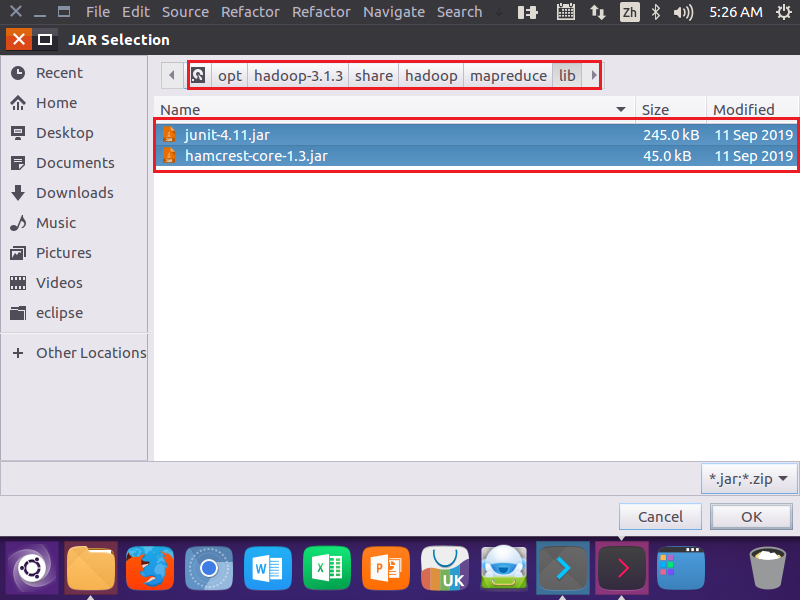
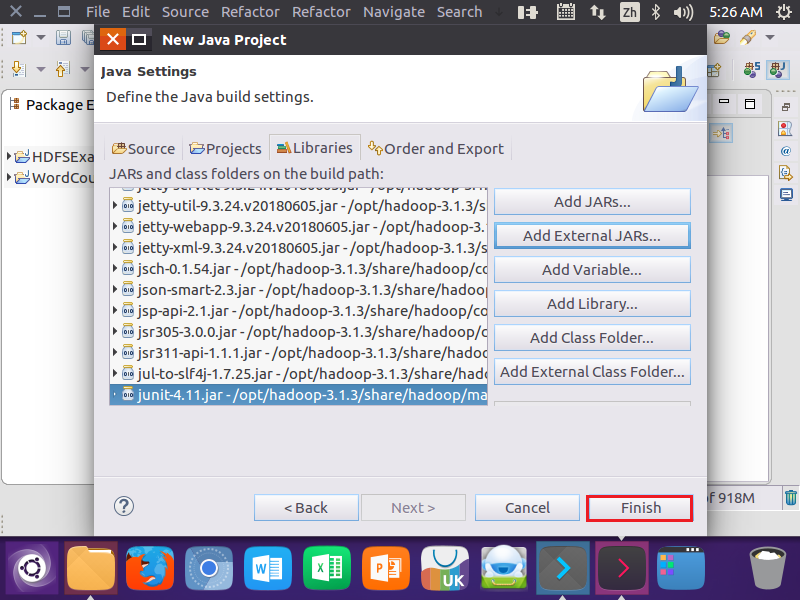
4.编写Java应用程序
java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) { // 优化:使用增强for循环,避免迭代器泛型问题
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
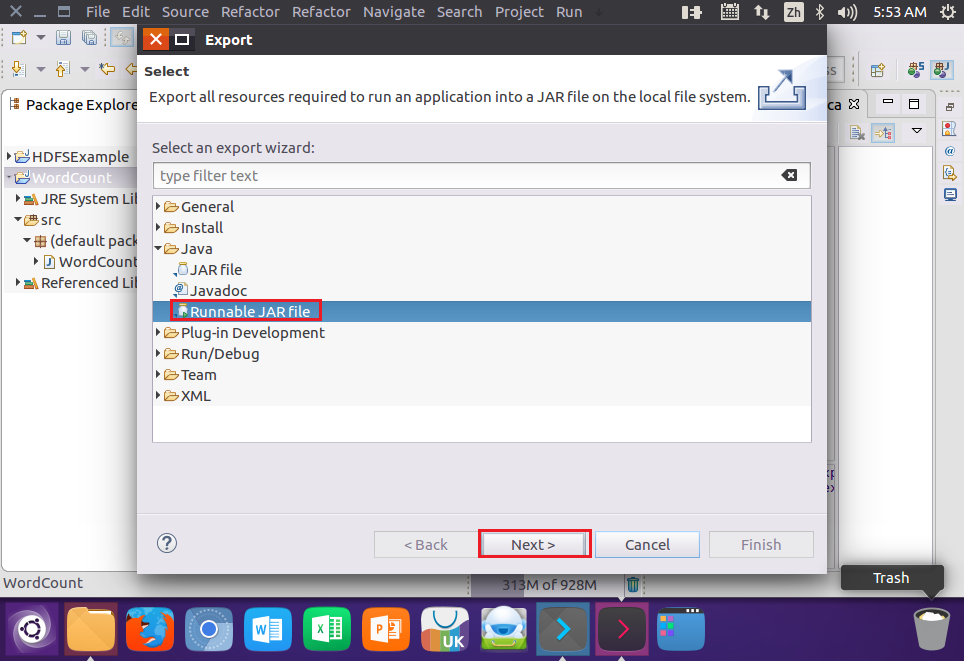
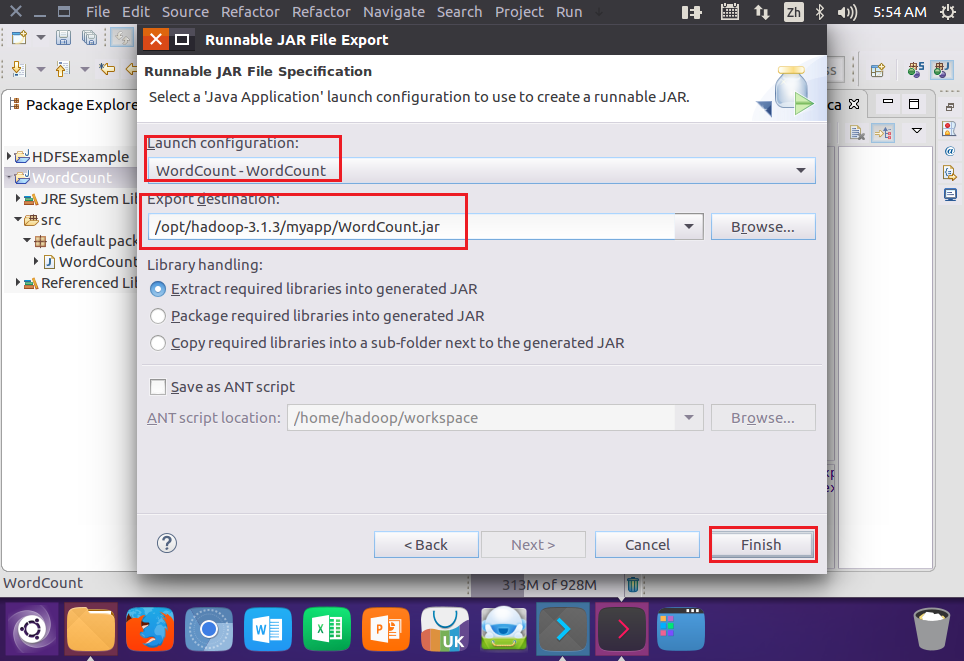
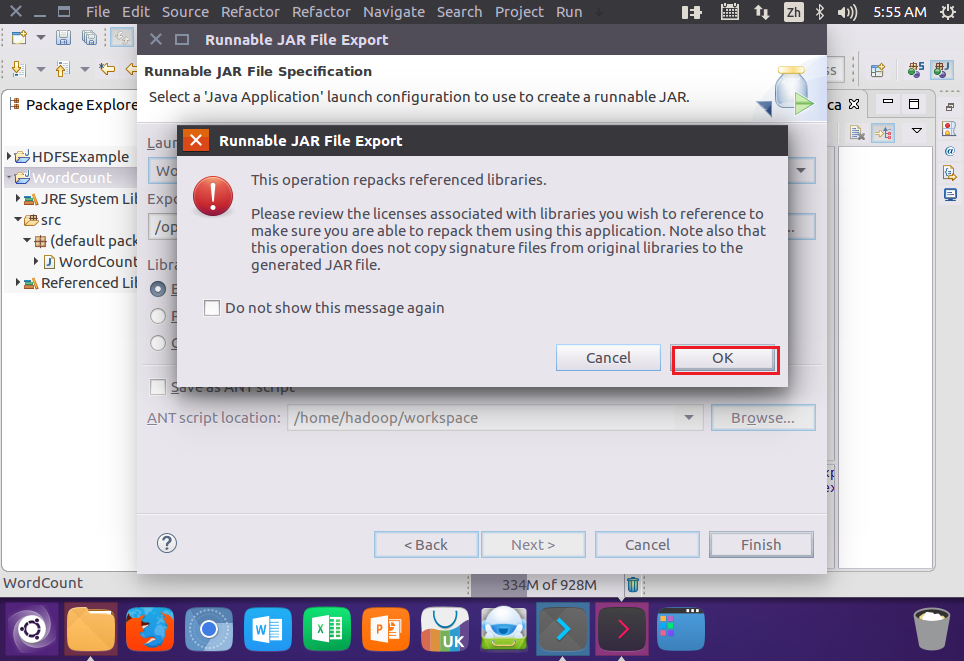
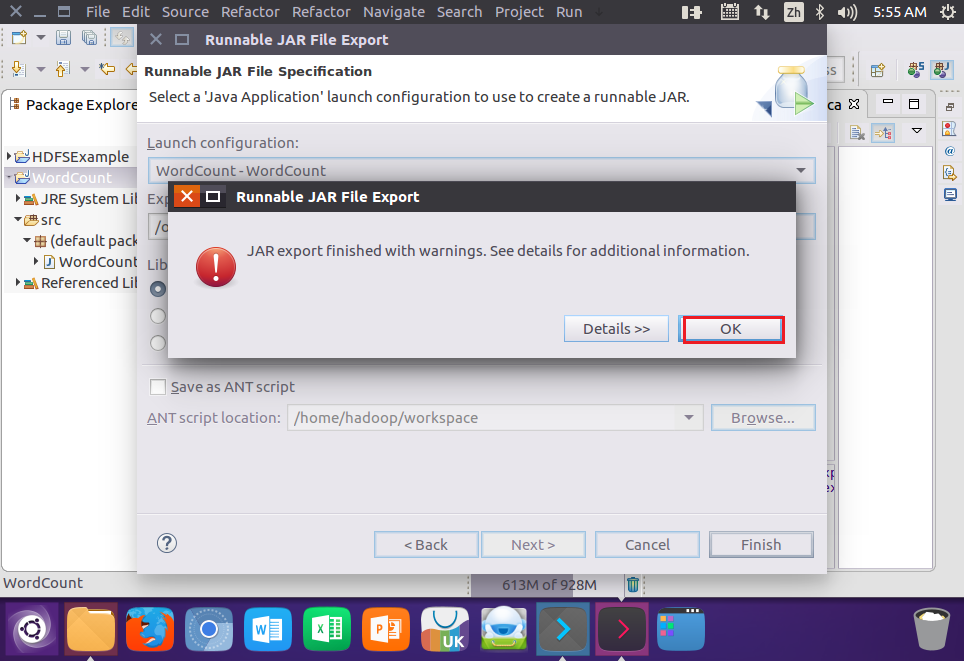
}5.编译打包程序
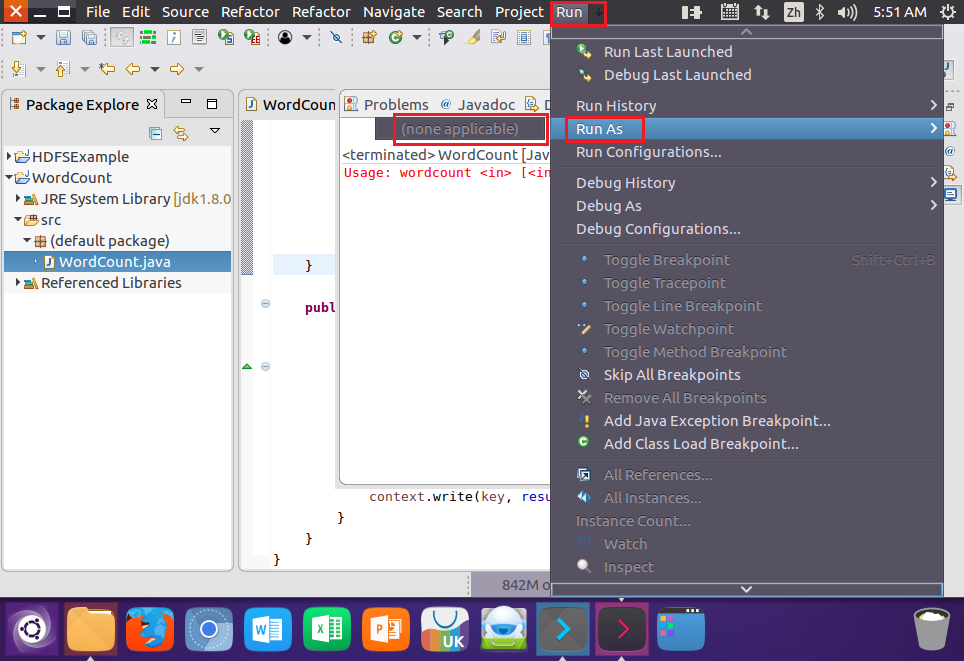
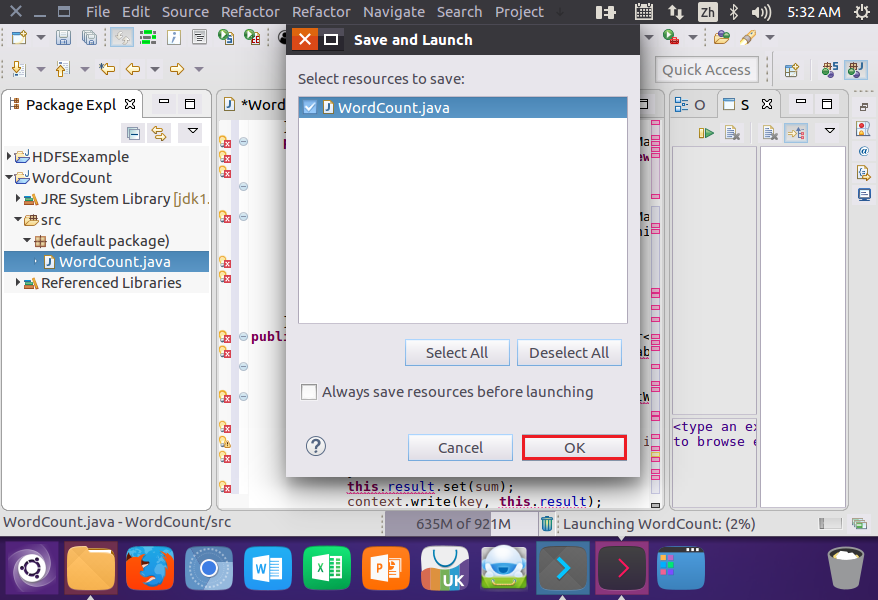
结果:
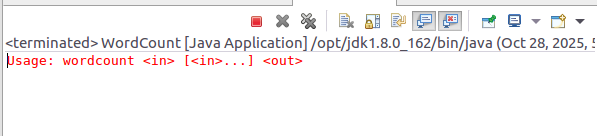
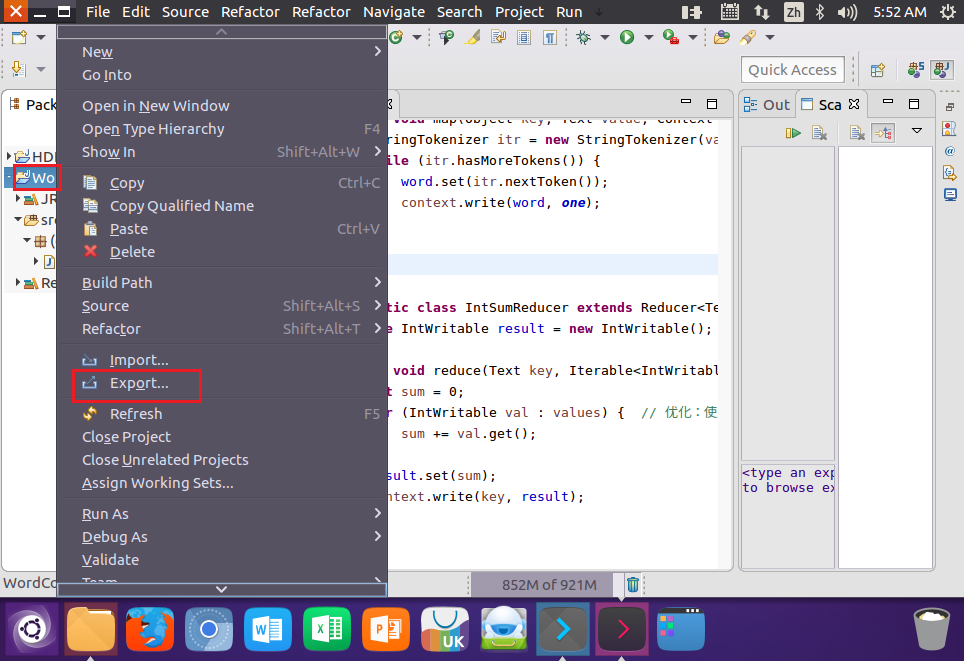
6.运行程序
(先打开Hadoop服务start-dfs.sh start-yarn.sh)
删除HDFS中的input和output目录
bash
hdfs dfs -rm -r input
hdfs dfs -rm -r output
//删除文件

创建input目录
bash
hdfs dfs -mkdir input
//创建input目录
上传文件
bash
hdfs dfs -put ./wordfile1.txt input
hdfs dfs -put ./wordfile2.txt input
//上传文件

运行JAR文件
bash
hadoop jar /opt/hadoop-3.1.3/myapp/WordCount.jar input output
//运行JAR包
查看结果
bash
hdfs dfs -cat output/*
//查看文件
如果要再次运行程序要删除output目录