数据分析
数据分析是通过收集数据,对收集的数据进行清理、处理,解释的过程。把有用的信息提取出来,总结出数据的内在规律。
具体步骤
数据收集
互联网,很多公开的资源,企业招标情况以及公告,会在官网上发布,还有很多平台也会发布数据。可以通过爬虫来获取来自互联网的数据。企业内部也会产生大量的数据,员工流动情况,员工工资、绩效情况等等。娱乐电商平台,每天产生大量的数据并通过这些数据来统计用户浏览内容,用户特征,浏览量,转化情况等等
数据清洗
数据拿到后,很多时候并不能直接进行分析。数据清洗(data cleaning 或 data cleansing)是把原始数据中错误、不完整、不一致或无关的信息识别、修正或删除的过程,使数据变得正确、统一并适合后续分析或建模使用。它是数据预处理的一部分,与数据集成、转换和特征工程紧密相关
为什么要做数据清洗?
- 提高准确性:脏数据会导致统计结果和模型预测偏差甚至完全错误。
- 提升可靠性和可重复性:清洗后别人能更容易复现你的分析流程。
- 降低偏差:缺失或错误数据若不处理会引入系统性偏差。
- 提高模型/算法表现:机器学习模型对异常、空值和错误格式敏感。
- 节约成本和时间:虽然清洗需要时间,但能避免后续反复修正和错误决策造成更大损失。
- 符合合规与审计要求:某些场景需保证数据质量以满足法规或内部审计
常见清洗方法与策略(红色部分为常见情况)
- 探查与概览(数据剖析):查看分布、缺失率、唯一值等。
- 处理空值(也叫缺失值):删除、均值/中位数/众数填充、基于模型预测填充或保留为特殊类别。
- 去重:按主键或关键字段去除重复行。
- 格式统一:日期、货币、单位、大小写规范化。
- 类型转换:把字符串转为数值或日期等合适类型。
- 统一类别:合并同义词或拼写变体("NY"="New York")。
- 处理异常值:检查是数据错误还是有意义的极端值,视情况剔除或截断(capping)。
- 计算字段(表头):根据已有的字段,计算出新的东西。比如有一列是单价,另一列是销量,就可以计算出新的一列销售额。添加了新的字段,就有了新的分析方向
- 验证与校验:规则检查(如年龄不能为负数),交叉字段验证。
- 记录与文档化:记录清洗步骤,保留原始数据快照,保证可回溯。
处理数据
- 把清洗后的数据变成可用于分析或模型的数据;发现模式并构建模型。
- 常做工作:
- 探索性分析(EDA):分布、相关性、分组统计、可视化(直方图、散点图、箱线图)。
- 特征工程:衍生变量、编码分类变量、标准化/归一化、处理时间序列特征、缺失值填充策略。
- 建模/统计分析:选择算法(回归、分类、聚类、时间序列模型)、交叉验证、超参调优、诊断模型性能(AUC、RMSE、混淆矩阵)。
- 工具:Python(pandas、scikit-learn、statsmodels)、R、Jupyter、SQL、Spark(大数据)。
- 注意事项:训练/测试数据分离、防止数据泄露(leakage)、合理评估指标、处理不平衡数据
解释数据
- 把分析结果转化为可理解、可执行的结论与建议;支持决策。
- 常做工作:
- 结果可视化(图表、仪表盘)、摘要关键指标、置信区间与不确定性说明。
- 模型解释:系数解释、特征重要性、SHAP/LIME 等局部/全局解释方法。
- 报告与故事化:构建清晰结论、方法与假设、限制与风险、可操作建议。
- 工具:Tableau、FineBI、Power BI、Matplotlib/Seaborn/Plotly、SHAP、报告模板(PPT/Markdown)。
- 注意事项:针对不同受众(技术 vs 非技术)调整表达深度,避免以相关性误导因果结论,清楚标注假设与数据局限
以上的一系列执行后,最终都是为了驱动决策
应用场景
个人生活:数据分析可以对个人喜好,生活习惯等进行分类,为其提供更加周到的个性化服务。这也是传说中的用户画像:年龄、性别、身高、收入、职业、教育程度、活跃度、是否有孩子、孩子年龄、颜色偏好等等
FineBI
两个网址:
第一个是自己做分析报告的平台,第二个是用来学习的
简介:请查看官网
finebi的两个端:本地版本:学习阶段用的,单机游戏,不能设置权限,不能分享在线链接;在线版本:接单
区别:本地版本可以连接数据库,设置更新数据集;但是在线版本就不行
如何区分当前使用的版本是本地还是在线的:通过网址来区分
有 localhost 是本地的
入门案例
打开这个网址:FineBI在线数据分析平台
在左侧栏找到 我的分析
最主要的是 我的分析,这里是专门做仪表板的,其他的用的不多
进入到 我的分析之后,点击新建文件夹,我命名的是 CSDN,再点击加号,点击分析主题。这样就新建了一个分析主题
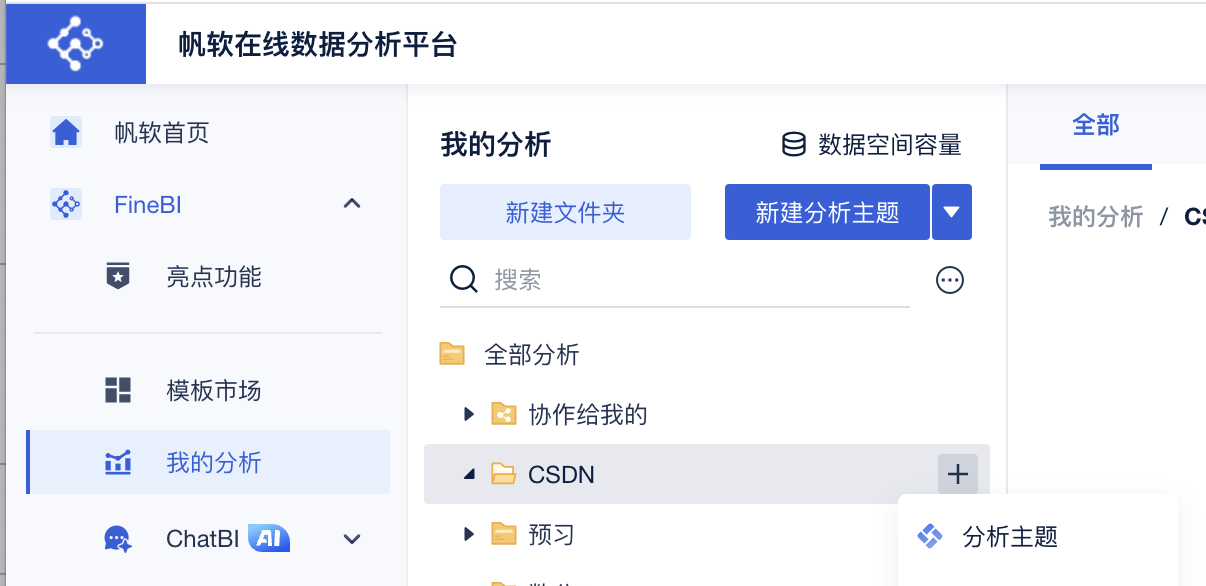
命名为"xxx超市销售分析"
完成:入门案例介绍
把这里的所有一步步照着做一遍就可以了,小白大约需要两小时左右的时间,有一点耐心
