为什么会导致数据不一致
关于缓存和数据库不一致的情况,主要有以下几种情况:
- 更新数据的时候,redis中的缓存和mysql中的数据是存储在不同地方的,两者之间的更新是独立的,既然是独立那么肯定会有一段时间的短暂不一致
- 程序可能会宕机,在宕机后数据库的内容就可能和缓存中的内容不一样了
- 在分布式情况下,主从集群之间需要进行数据同步,自然也会导致数据的一致性存在问题
缓存策略有什么
- Cache-Aside (旁路缓存) 、
- Read/Write-Through (读/写穿透)
- Write-Behind (异步写回)
Cache-Aside 旁路缓存模式
这是最经典、也是应用最广泛的缓存更新策略。其核心思想是:应用层代码直接与缓存和数据库交互,并负责维护两者之间的数据一致性。
读操作流程:
-
应用接收读请求,首先查询 Redis 缓存。
-
缓存命中 (Cache Hit):直接从 Redis 获取数据并返回。
-
缓存未命中 (Cache Miss):从后端数据库查询数据。
-
将从数据库查到的数据写入 Redis 缓存(设置合理的过期时间 TTL)。
-
将数据返回给客户端。
写操作流程: 写操作的顺序是一个经典且极易出错的面试题。常见的操作有两种:"先更新数据库,再删除缓存" 和 "先删除缓存,再更新数据库"。
最佳实践是:"先更新数据库,再删除缓存"。 为什么?
-
一致性更高:在高并发场景下,如果先删除缓存,一个读请求可能会在数据库更新前读取到旧数据并写回缓存,造成数据不一致。而先更新数据库,再删除缓存,即使删除失败,也只是造成短时间的缓存不一致(可以通过重试机制弥补),并且后续的读请求会从数据库加载最新数据。
-
操作原子性:更新数据库和删除缓存这两个操作并非原子性。如果删除缓存失败,可以通过消息队列的方式进行补偿,确保最终一致性。
代码示例:
java
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private Jedis jedis;
@Autowired
private ProductMapper productMapper;
private static final String PRODUCT_CACHE_KEY_PREFIX = "product:";
@Override
public Product getProductById(Long id) {
String cacheKey = PRODUCT_CACHE_KEY_PREFIX + id;
// 1. 读缓存
String productJson = jedis.get(cacheKey);
if (productJson != null && !productJson.isEmpty()) {
// 缓存命中
return JSON.parseObject(productJson, Product.class);
}
// 2. 缓存未命中,查询数据库
Product product = productMapper.selectById(id);
if (product != null) {
// 3. 更新缓存
jedis.setex(cacheKey, 3600, JSON.toJSONString(product)); // 设置1小时过期
}
return product;
}
@Override
@Transactional
public void updateProduct(Product product) {
// 1. 更新数据库
productMapper.updateById(product);
// 2. 删除缓存
String cacheKey = PRODUCT_CACHE_KEY_PREFIX + product.getId();
jedis.del(cacheKey);
}
}优点:
-
逻辑简单:实现清晰,应用代码直接控制缓存逻辑。
-
灵活性高:可以根据业务需求,对不同的数据进行精细化的缓存控制。
-
异常隔离:缓存服务的故障不会直接影响到数据库的读写。
缺点:
-
代码侵入性:缓存逻辑与业务代码耦合。
-
缓存穿透风险:首次请求或缓存过期后,会有大量请求直接打到数据库。
Read/Write-Through (读/写穿透)
该策略的原则是应用层只于缓存交互,由缓冲层与数据库进行数据同步。
读穿透 (Read-Through): 应用查询缓存,如果缓存未命中,由缓存服务自身负责从数据库加载数据,并返回给应用。对应用层来说,缓存是唯一的交互入口。
写穿透 (Write-Through): 应用更新数据时,只调用缓存的更新接口。如果缓存存在,更新缓存,由缓存服务负责将数据写入缓存,并同步写入后端数据库。如果不存在,交由缓存直接更新数据库,总之都是与缓存层进行交互。
优点:
-
应用层简化:应用代码逻辑变得非常简单,无需关心后端数据库。
-
数据一致性强:写操作是同步的,可以保证缓存和数据库的强一致性。
缺点:
-
实现复杂:需要缓存中间件的支持,或者在缓存层进行二次开发。
-
性能开销:写操作的性能会因为需要同步写数据库而有所降低。
异步写回模式 (Write-Behind Caching Pattern)
与写穿透类似,应用层只与缓存交互。不同之处在于,写操作只更新缓存,然后立即返回,由缓存服务异步地将数据批量或定时写入数据库。
Write-Back主要使用在计算机设计结构中,比如CPU的缓存、操作系统中的文件系统缓存都采用了这种方法,主要用于写多的情景,因为是和缓存打交道,写完就返回了
优点:
-
极高的写性能:应用端的写操作非常快,因为只操作内存。
-
降低数据库压力:可以将多次写操作合并为一次批量写入,极大减轻数据库负载。
缺点:
-
数据可能丢失:如果缓存服务宕机,尚未同步到数据库的数据将会丢失。
-
一致性较弱:数据是最终一致性,在异步写入完成前,缓存和数据库存在数据不一致的窗口。
二、Cache-Aside 的数据一致性问题
在复杂的业务场景下,尤其是在高并发环境中,单纯的 Cache-Aside 模式可能会遇到数据一致性挑战,主要有以下几种情况:
- 先更新Mysql,再更新Redis
- 先更新Redis,再更新Mysql
- 先删Redis,再更新mysql
- 先删Redis,再更新Mysql,再更新Redis
注意:这里的Redis 即为缓存 ,Mysql 即为 数据库
先更新Mysql,再更新Redis
场景:有两个相邻的请求,请求一为将 a 修改为 10 ,请求二为将 a 修改为 12,请求一先于请求二
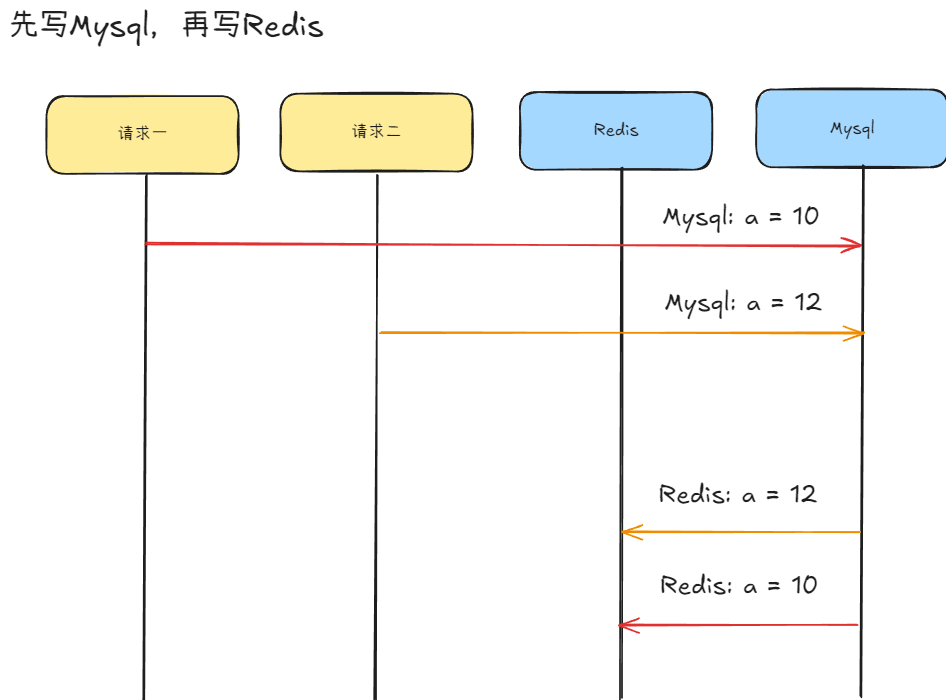
如果请求一在将数据写回redis的时候被某些原因阻塞了一会,导致写入redis时候的数据慢于请求二,那么次数redis中的a为 10 ,但是按照理论上来说是应该是要是为 12 的,所以此时即为脏数据。
先更新Redis,再更新Mysql
场景:有两个相邻的请求,请求一为将 a 修改为 10 ,请求二为将 a 修改为 12,请求一先于请求二
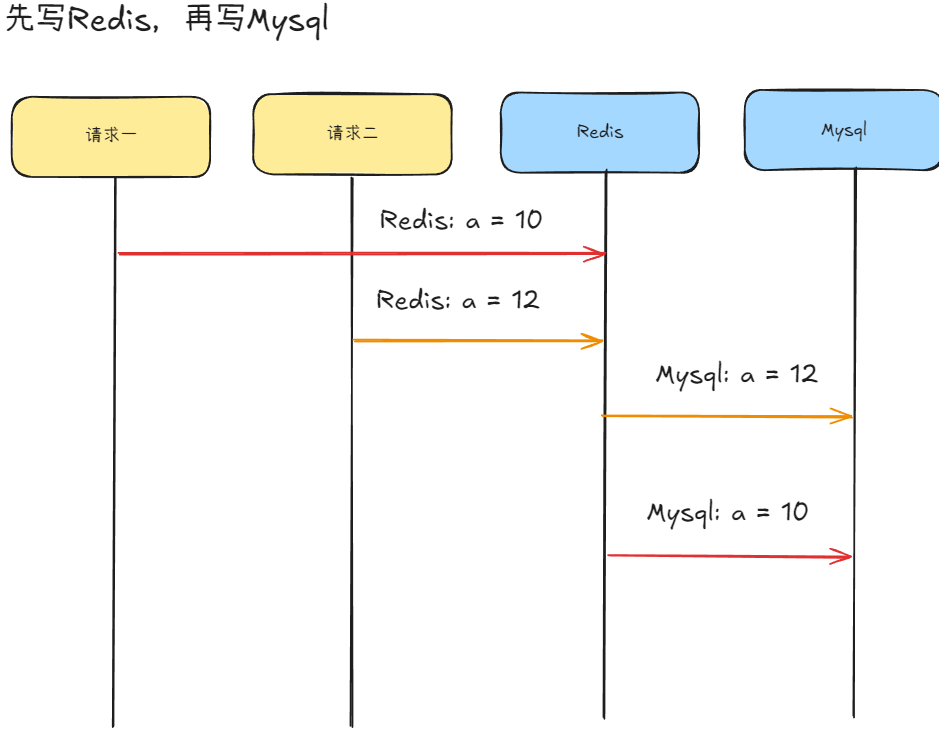
发生异常情况的场景同上,请求一因为某些原因被阻塞了,导致写入数据库的时间晚于请求二,并且这样会造成无效写操作变多,因为redis可能还一次都没有被读取就又要重写了
先删Redis,再更新Mysql
场景:有两个相邻的请求,请求一为将 a 修改为 10 ,请求二查询 a 的值,请求一先于请求二
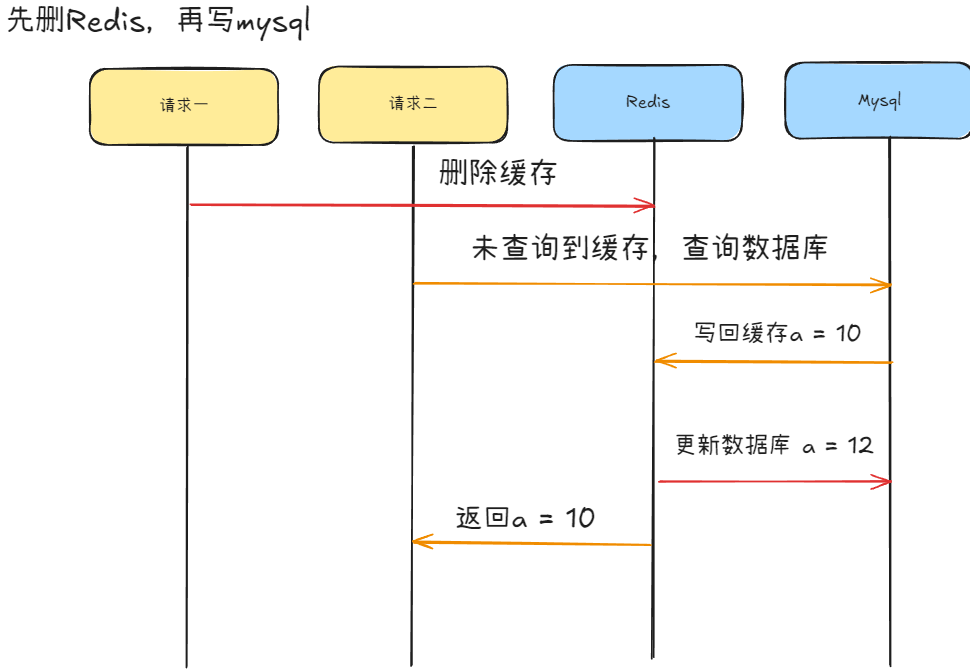
读请求会比写请求来的快,所以有可能在请求一写数据的时候,请求二刷入redis的还是老数据,
先删Redis,再更新Mysql,再删Redis
场景:有两个相邻的请求,请求一为将 a 修改为 10 ,请求二查询 a 的 值,请求一先于请求二
此为延迟双删策略 (Delayed Double Deletion)
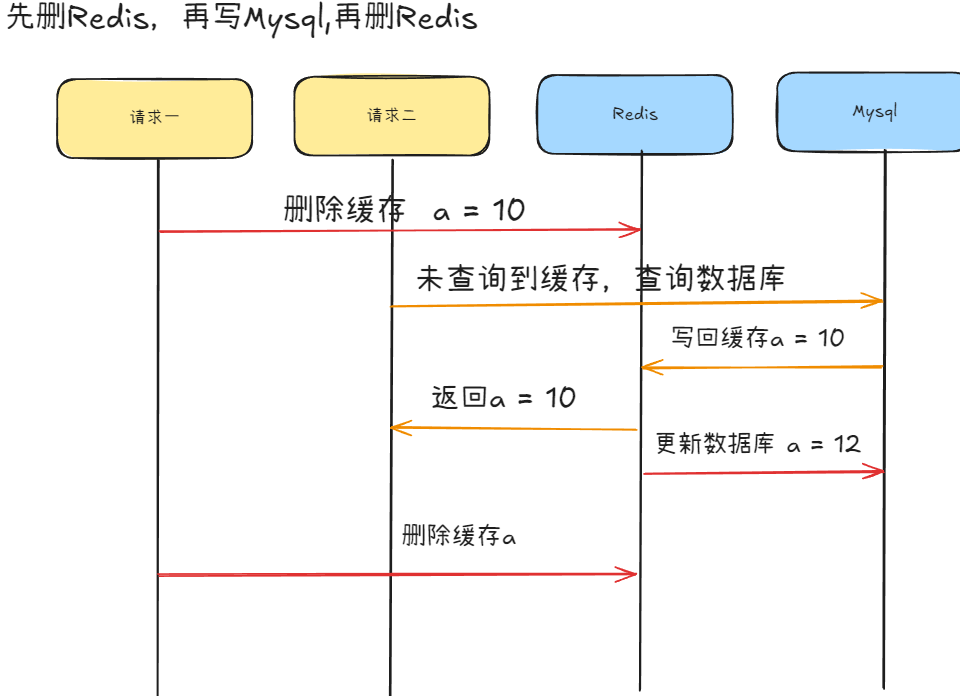
这是对 "先更新msql,再删除redis" 方案的优化,主要为了解决在并发场景下,旧数据被重新写入缓存的问题。
操作流程:
- 先删除缓存。
- 再更新数据库。
- 延迟一段时间后(例如 500ms),再次删除缓存。
这个延迟时间的设定是为了确保,在步骤 2 更新数据库期间,如果有读请求读取了旧数据并写入缓存,这个被污染的缓存也能在延迟后被删除。
注意: 延迟双删也有副作用
写请求 数据库 缓存 读请求 1. 更新数据A=新值 2. 删除缓存A 3. 读A(缓存缺失) 4. 读A(返回新值) 5. 回填A(新值) 6. 延迟删除A(误删正确的新值!) 7. 读A(缓存缺失,重新回填)→ 额外性能损耗 写请求 数据库 缓存 读请求
- 误删正确数据 (反效果)
如上图所示:第二次删除可能恰好发生在读请求回填新数据之后,导致缓存被清空,引发缓存击穿。 - 异步删除可能失败
若消息丢失或消费失败,缓存中长期保留旧数据(无兜底机制)。 - 延迟时间无法精确设定
网络抖动、GC暂停、DB主从延迟等因素导致"等待时间"难以量化,可能过短(残留脏数据)或过长(性能浪费)。
先更新Mysql,在删Redis

在这种情况下的异常情况发生的几率很少,
- 需要满足 缓存刚好失效,
- 更新数据库的时间比写入缓存的时间来的还短
所以这是基本上不可能的。所以是一个比较稳妥的数据一致性解决方法
订阅数据库变更 (Binlog)
这是保证最终一致性的"银弹"。通过中间件(如 Canal、Debezium)订阅 MySQL 的 Binlog,可以近乎实时地捕获数据库的所有数据变更(INSERT, UPDATE, DELETE)。然后由一个专门的服务消费这些变更消息,并精确地更新或删除对应的 Redis 缓存。
优点:
- 业务解耦:缓存更新逻辑与业务代码完全分离,降低了系统复杂度。
- 高可靠性:基于消息队列,即使缓存更新服务暂时不可用,消息也不会丢失,保证了最终一致性。
- 实时性高 :Binlog 的捕获是毫秒级的,可以实现准实时的数据同步。
缺点: - 架构复杂:需要引入并维护额外的中间件(Canal, Kafka 等),增加了运维成本。
三、策略选择与总结
| 策略 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 旁路缓存 (Cache-Aside) | 最终一致性 (较高) | 读性能高,写性能中 | 低 | 绝大多数读多写少的场景,对短暂数据不一致容忍度较高。 |
| 读/写穿透 (Read/Write-Through) | 强一致性 (写穿透) | 读性能高,写性能受数据库影响 | 中 | 需要缓存与数据库强一致,且能接受写性能损失的场景。 |
| 异步写回 (Write-Behind) | 最终一致性 (较弱) | 读写性能极高 | 中 | 对写性能要求极高,且能容忍数据在缓存宕机时丢失的场景,如点赞、计数。 |
| 延迟双删 | 最终一致性 (很高) | 中 | 中 | 对数据一致性要求非常高的并发写场景。 |
| 订阅 Binlog | 最终一致性 (极高) | 高 | 高 | 系统复杂,数据变更频繁,需要将缓存更新与业务逻辑彻底解耦的大型系统。 |