文章目录
- 查询
-
- 可回收且低脂的产品(字符串与运算符)
- 寻找用户推荐人(NULL操作)
- 大的国家
- [文章浏览 I(别名)](#文章浏览 I(别名))
- 无效的推文(单行函数)
- 连接
查询
可回收且低脂的产品(字符串与运算符)
题目链接:1757. 可回收且低脂的产品
注意点:
- windows系统中大小写不敏感,linux中大小写敏感
- 一般字符串、日期使用单引号,别名使用双引号
- 条件中可以使用的运算符
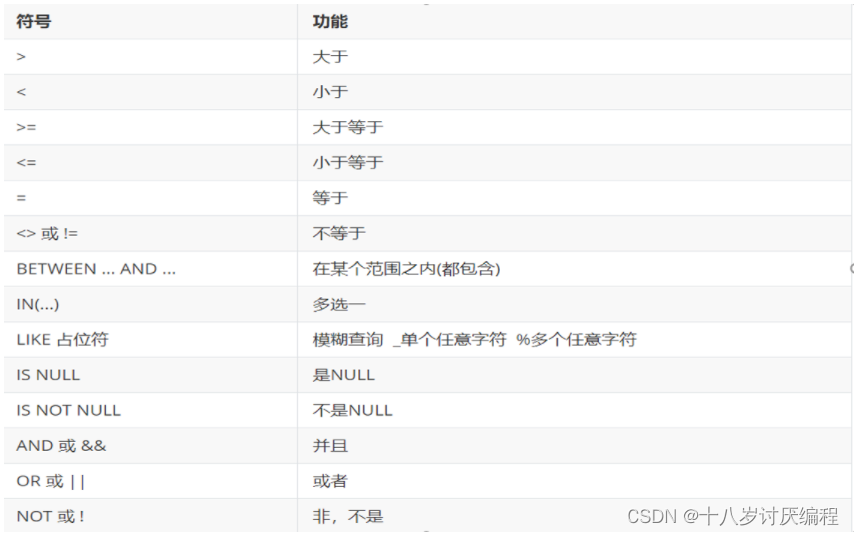
解题代码:
sql
SELECT
product_id
FROM
Products
WHERE
low_fats = 'Y' AND recyclable = 'Y'
;寻找用户推荐人(NULL操作)
题目链接:584. 寻找用户推荐人
注意点:
用 IS NULL / IS NOT NULL 处理 NULL!!!
MySQL 引入 UNKNOWN 作为第三种逻辑值,本质是为了处理 "缺失 / 不确定的数据"(即 NULL) 。
在传统的二值逻辑(TRUE/FALSE)中,"未知" 状态无法被描述 ------ 比如 "查询年龄大于 30 的用户",如果某条记录的 "年龄" 是 NULL(既不是 "大于 30",也不是 "不大于 30",而是 "不知道年龄是多少"),此时用 TRUE 或 FALSE 都无法准确表达这种 "不确定",因此引入 UNKNOWN 来专门代表这种状态。
无论比较运算符是 =、>、<、!= 还是 IN,只要其中一方是 NULL,结果都是 UNKNOWN。
注意:NULL = NULL 的结果不是 TRUE,而是 UNKNOWN!
解题代码:
sql
SELECT
name
FROM
Customer
WHERE
referee_id <> 2 || referee_id IS NULL
; 大的国家
题目链接:595. 大的国家
解题代码:
sql
SELECT
name,population,area
FROM
World
WHERE
area >= 3000000 OR population >= 25000000
;文章浏览 I(别名)
题目链接:1148. 文章浏览 I
涉及知识点:
列的别名
三种定义方式:
- ①直接空格
例:SELECT employee_id emp_id FROM employees; - ②使用AS,全称:alias(别名),可以省略(省略之后就是方式一)
例:SELECT last_name AS lname FROM employees; - ③使用双引号
例:SELECT last_name "Name" FROM employees;
解题代码:
sql
SELECT DISTINCT
viewer_id AS id
FROM
Views
WHERE
author_id = viewer_id
ORDER BY
id
;无效的推文(单行函数)
题目链接:1683. 无效的推文
涉及知识点:
在MySQL中,单行函数 是指对数据表中的每一行记录单独进行运算,并返回一个对应结果的函数(即输入一行、输出一行),是数据查询、转换和处理的核心工具。根据功能可分为字符串函数、数值函数、日期时间函数、转换函数、条件函数等类别,以下是各类别中最常用的单行函数总结:
单行函数的核心作用是 "对值进行处理并返回新值",因此只要 SQL 语句中需要一个 "值" 的位置(如字段、条件、排序依据等),几乎都可以使用单行函数。
一、字符串函数(处理字符/字符串类型数据)
用于字符串的拼接、截取、替换、大小写转换等操作,核心函数如下:
| 函数语法 | 功能说明 | 示例 | 结果 |
|---|---|---|---|
CONCAT(s1, s2, ...sn) |
拼接多个字符串(若有一个参数为NULL,结果整体为NULL) |
CONCAT('My', 'SQL', '5.7') |
MySQL5.7 |
CONCAT_WS(sep, s1,...) |
用指定分隔符sep拼接字符串(自动忽略NULL) |
CONCAT_WS('-', '2024', '10', '12') |
2024-10-12 |
LENGTH(str) |
计算字符串的字节数(注意:UTF-8编码中,中文占3字节,英文占1字节) | LENGTH(' MySQL数据库 ') |
11(空格+英文5+中文2×3) |
CHAR_LENGTH(str) |
计算字符串的字符数(无论中英文,每个字符计1) | CHAR_LENGTH(' MySQL数据库 ') |
7(空格1+英文5+中文1) |
UPPER(str) / LOWER(str) |
将字符串转为全大写/全小写 | UPPER('mysql') / LOWER('MYSQL') |
MYSQL / mysql |
SUBSTRING(str, pos, len) |
截取字符串:pos为起始位置(1开始),len为截取长度(可选,默认到末尾) |
SUBSTRING('HelloWorld', 3, 4) |
lloW |
TRIM([opt] str) |
去除字符串首尾的指定字符(默认去除空格;opt可指定LEADING/TRAILING) |
TRIM(' abc ') / TRIM(LEADING 'x' FROM 'xxabcxx') |
abc / abcxx |
REPLACE(str, old, new) |
将字符串中所有old子串替换为new |
REPLACE('Hello', 'l', 'x') |
Hexxo |
LEFT(str, n) / RIGHT(str, n) |
从字符串左侧 /右侧截取n个字符 |
LEFT('Database', 4) |
Data |
二、数值函数(处理数值类型数据)
用于数值的计算、取整、进制转换等,核心函数如下:
| 函数语法 | 功能说明 | 示例 | 结果 |
|---|---|---|---|
ABS(n) |
计算数值n的绝对值 |
ABS(-10.5) |
10.5 |
ROUND(n, d) |
对n进行四舍五入,d为保留小数位数(默认d=0,即整数;d<0向个位左舍入) |
ROUND(3.1415, 2) / ROUND(123, -1) |
3.14 / 120 |
CEIL(n) / FLOOR(n) |
CEIL(n):向上取整(取大于等于n的最小整数);FLOOR(n):向下取整 |
CEIL(2.1) / FLOOR(2.9) |
3 / 2 |
MOD(n, m) |
计算n除以m的余数(同n % m,结果符号与n一致) |
MOD(10, 3) / MOD(-10, 3) |
1 / -1 |
POWER(n, p) |
计算n的p次方(n^p) |
POWER(2, 3) |
8 |
SQRT(n) |
计算n的平方根(n必须非负) |
SQRT(16) |
4 |
三、日期时间函数(处理DATE/DATETIME/TIME类型数据)
用于日期时间的获取、计算、格式化,是业务中(如订单时间、日志时间)最常用的函数类别之一:
| 函数语法 | 功能说明 | 示例 | 结果(示例) |
|---|---|---|---|
NOW() / CURRENT_TIMESTAMP() |
获取当前日期+时间 (格式:YYYY-MM-DD HH:MM:SS) |
NOW() |
2024-10-12 15:30:45 |
CURDATE() / DATE(NOW()) |
获取当前日期 (格式:YYYY-MM-DD) |
CURDATE() |
2024-10-12 |
CURTIME() / TIME(NOW()) |
获取当前时间 (格式:HH:MM:SS) |
CURTIME() |
15:30:45 |
DATE_FORMAT(dt, fmt) |
将日期时间dt按指定格式fmt转换为字符串(fmt为格式符,如%Y=4位年、%m=2位月) |
DATE_FORMAT(NOW(), '%Y年%m月%d日 %H:%i') |
2024年10月12日 15:30 |
STR_TO_DATE(str, fmt) |
将字符串str按格式fmt转换为日期时间类型(与DATE_FORMAT反向) |
STR_TO_DATE('2024-10-12', '%Y-%m-%d') |
2024-10-12 |
DATEDIFF(d1, d2) |
计算两个日期的差值(d1 - d2,结果为天数,仅关注日期部分) |
DATEDIFF('2024-10-12', '2024-10-01') |
11 |
TIMESTAMPDIFF(unit, d1, d2) |
按指定单位unit计算d2 - d1的差值(unit:Y=年、M=月、D=日、H=时) |
TIMESTAMPDIFF(MONTH, '2024-01-01', '2024-10-12') |
9 |
DATE_ADD(dt, INTERVAL expr unit) |
给日期dt增加指定时间间隔(unit同上) |
DATE_ADD(CURDATE(), INTERVAL 7 DAY) |
2024-10-19 |
YEAR(dt) / MONTH(dt) / DAY(dt) |
从日期dt中提取年 /月/日(同理:HOUR()/MINUTE()/SECOND()提取时间) |
YEAR('2024-10-12') |
2024 |
四、类型转换函数(转换数据类型)
用于在不同数据类型(如字符串、数值、日期)之间转换,核心函数为CAST()和CONVERT():
| 函数语法 | 功能说明 | 示例 | 结果 |
|---|---|---|---|
CAST(expr AS type) |
将表达式expr转换为指定类型type(支持类型:CHAR、INT、DATE、DATETIME等) |
CAST('2024' AS INT) / CAST(123 AS CHAR) |
2024 / '123' |
CONVERT(expr, type) |
与CAST()功能完全一致,仅语法不同 |
CONVERT('3.14' AS DECIMAL(5,2)) |
3.14 |
注意:转换需符合逻辑(如
CAST('abc' AS INT)会返回0,而非报错)。
五、条件函数(按条件返回结果)
类似编程语言中的"分支逻辑",根据条件判断返回不同值,最常用的是IF()和CASE():
IF()函数(简单二分支)
- 语法:
IF(condition, val1, val2) - 逻辑:若条件
condition为TRUE,返回val1;否则返回val2(支持嵌套)。 - 示例:
IF(score >= 60, '及格', '不及格')(分数≥60返回"及格",否则"不及格")。
解题代码:
sql
SELECT
tweet_id
FROM
Tweets
WHERE
LENGTH(content) > 15
;连接
使用唯一标识码替换员工ID(表连接)
题目链接:1378. 使用唯一标识码替换员工ID
注意点:
MySQL数据库的表连接方式
-
内连接(INNER JOIN)
- 语法:
SELECT ... FROM 表A INNER JOIN 表B ON 表A.字段 = 表B.字段; - 通俗理解:只保留两个表中关联条件匹配成功的记录,相当于"取交集"。
- 例子:表A(学生)有id=1,2,表B(成绩)有student_id=1,3,内连接后只保留id=1的匹配记录。
- 语法:
-
左连接(LEFT JOIN / LEFT OUTER JOIN)
- 语法:
SELECT ... FROM 表A LEFT JOIN 表B ON 表A.字段 = 表B.字段; - 通俗理解:保留左表(表A)的所有记录,右表(表B)只保留匹配的记录,不匹配的部分用NULL填充。
- 例子:表A(学生)有id=1,2,表B(成绩)有student_id=1,左连接后保留id=1(匹配成绩)和id=2(成绩为NULL)。
- 语法:
-
右连接(RIGHT JOIN / RIGHT OUTER JOIN)
- 语法:
SELECT ... FROM 表A RIGHT JOIN 表B ON 表A.字段 = 表B.字段; - 通俗理解:与左连接相反,保留右表(表B)的所有记录,左表(表A)不匹配的部分用NULL填充。
- 例子:表A(学生)有id=1,表B(成绩)有student_id=1,3,右连接后保留student_id=1(匹配学生)和student_id=3(学生信息为NULL)。
- 语法:
-
全连接(FULL JOIN)
- 说明:MySQL不直接支持FULL JOIN,但可通过UNION组合左连接和右连接实现。
- 效果:保留两个表的所有记录,互相不匹配的部分用NULL填充,相当于"取并集"。
- 替代语法:
SELECT ... FROM 表A LEFT JOIN 表B ON ... UNION SELECT ... FROM 表A RIGHT JOIN 表B ON ...;
-
交叉连接(CROSS JOIN)
- 语法:
SELECT ... FROM 表A CROSS JOIN 表B;(省略ON条件) - 通俗理解:两个表的所有记录两两组合,即"笛卡尔积",结果行数 = 表A行数 × 表B行数。
- 注意:通常需配合WHERE条件过滤,否则结果可能非常庞大。
- 语法:
解题代码:
sql
SELECT
eu.unique_id,e.name
FROM
Employees AS e LEFT JOIN EmployeeUNI AS eu
ON
e.id = eu.id
;产品销售分析 I
题目链接:1068. 产品销售分析 I
和上一题类似:
sql
SELECT
p.product_name,s.year,s.price
FROM
Sales AS s LEFT JOIN Product AS p
ON
s.product_id = p.product_id
;进店却未进行过交易的顾客(分组与聚合)
题目链接:1581. 进店却未进行过交易的顾客
本题涉及知识点:
①WHERE和HAVING的区别是什么?
在SQL中,WHERE和HAVING都用于筛选数据,但它们的使用场景和作用对象有本质区别,主要区别如下:
- 作用对象不同
-
WHERE:用于筛选原始表中的行 ,作用于单个记录 (即未经过分组的数据)。 它在数据分组(GROUP BY)之前执行,因此不能直接使用聚合函数(如SUM、COUNT等)。 -
HAVING:用于筛选分组后的结果 (即GROUP BY之后的组),作用于整个组。 它在数据分组之后执行,因此可以使用聚合函数来过滤符合条件的组。
- 使用场景不同
-
WHERE:适用于在分组前过滤不需要的记录,减少参与分组的数据量。 -
HAVING:适用于在分组后过滤不符合条件的组(不是以行为筛选单位,而是组!!!)。
- 是否可与聚合函数搭配
-
WHERE:不能直接使用聚合函数(因为它作用于单条记录,聚合函数需要多记录计算)。 -
HAVING:可以直接使用聚合函数(因为它作用于分组后的结果,聚合函数已计算完成)。
- 可筛选的字段
-
WHERE:WHERE 用于在分组(GROUP BY)之前筛选原始数据行,因此它只能基于表中已有的原始字段(非聚合结果)设置条件 -
HAVING:HAVING 用于在分组(GROUP BY)之后筛选组,因此它可以基于以下两类条件:- 聚合函数的结果(如SUM(amount)、COUNT(visit_id)等,这些是分组后计算出的结果)。
- GROUP BY中指定的分组字段(因为分组字段是每个组的 "标识",属于组的属性)。
②MySQL中常用的聚合函数
在MySQL中,聚合函数用于对一组数据进行计算并返回单个结果,通常与GROUP BY配合使用(也可用于整表聚合)。以下是常用的聚合函数及其说明:
COUNT()
-
功能:统计记录(行)的数量。
-
常见用法 :
COUNT(*):统计所有行(包括NULL值和空行)。COUNT(1):等效于COUNT(*),通过常量1统计行存在性。COUNT(字段名):统计指定字段中非NULL值的行数。
-
示例 :
sqlSELECT COUNT(*) AS 总记录数, COUNT(email) AS 非空邮箱数 FROM users;
SUM()
-
功能 :计算指定数值字段的总和(忽略
NULL值)。 -
注意 :仅对数值类型有效,非数值字段会返回
0或NULL。 -
示例 :
sqlSELECT SUM(amount) AS 总销售额 FROM orders;
AVG()
-
功能 :计算指定数值字段的平均值(忽略
NULL值,公式:SUM(字段)/COUNT(非NULL值))。 -
示例 :
sqlSELECT AVG(score) AS 平均分 FROM students;
MAX()
-
功能 :返回指定字段的最大值(适用于数值、字符串、日期等类型,忽略
NULL值)。 -
示例 :
sqlSELECT MAX(price) AS 最高价格, MAX(create_time) AS 最近订单时间 FROM products;
MIN()
-
功能 :返回指定字段的最小值(与
MAX()类似,忽略NULL值)。 -
示例 :
sqlSELECT MIN(age) AS 最小年龄 FROM employees;
GROUP_CONCAT()
-
功能:将分组后同一组的指定字段值拼接成一个字符串(默认用逗号分隔)。
-
常用参数 :
SEPARATOR '分隔符':自定义分隔符(如空格、分号)。DISTINCT:去重后拼接。
-
示例 :
sql-- 按班级分组,拼接学生姓名(用逗号分隔) SELECT class_id, GROUP_CONCAT(student_name) AS 学生名单 FROM students GROUP BY class_id; -- 用分号分隔并去重 SELECT class_id, GROUP_CONCAT(DISTINCT subject SEPARATOR ';') AS 课程列表 FROM courses GROUP BY class_id;
STDDEV()/STD()
-
功能 :计算指定数值字段的标准差(衡量数据离散程度,忽略
NULL值)。 -
示例 :
sqlSELECT STDDEV(score) AS 成绩标准差 FROM exam_results;
VARIANCE()/VAR()
-
功能 :计算指定数值字段的方差(标准差的平方,忽略
NULL值)。 -
示例 :
sqlSELECT VARIANCE(weight) AS 体重方差 FROM athletes;
聚合函数的共性特点
- 忽略
NULL值(COUNT(*)和COUNT(1)除外,它们统计所有行)。 - 通常与
GROUP BY结合,对分组后的数据进行聚合;若不使用GROUP BY,则对全表数据聚合。 - 可与
DISTINCT配合去重后计算(如SUM(DISTINCT 字段)、COUNT(DISTINCT 字段))。
例如,统计不同类别商品的去重供应商数量:
sql
SELECT category, COUNT(DISTINCT supplier) AS 供应商数 FROM products GROUP BY category;解题答案:
sql
SELECT
v.customer_id,COUNT(1) AS count_no_trans
FROM
Visits AS v LEFT JOIN Transactions AS t
ON
v.visit_id = t.visit_id
WHERE
t.transaction_id IS NULL
GROUP BY
v.customer_id
;上升的温度(自连接)
题目链接:197. 上升的温度
解题思路:
自连接
本题考查的是交叉连接,也就是笛卡尔积。当然也可以使用INNER JOIN。
解题代码:
sql
SELECT
w1.id
FROM
Weather AS w1 CROSS JOIN Weather AS w2
WHERE
DATEDIFF(w1.recordDate,w2.recordDate) = 1 AND w1.Temperature > w2.Temperature
;每台机器的进程平均运行时间
题目链接:1661. 每台机器的进程平均运行时间
解题思路:
还是使用自连接
解题代码:
sql
SELECT
a1.machine_id AS machine_id,
ROUND(AVG(a2.timestamp - a1.timestamp),3) AS processing_time
FROM
Activity AS a1 INNER JOIN Activity AS a2
ON
a1.machine_id = a2.machine_id
AND
a1.process_id = a2.process_id
AND
a1.activity_type = 'start'
AND
a2.activity_type = 'end'
GROUP BY
a1.machine_id
;员工奖金
解题思路:
考察左连接
解题代码:
sql
SELECT
e.name,b.bonus
FROM
Employee AS e LEFT JOIN Bonus AS b
ON
e.empId = b.empId
WHERE
b.bonus IS NULL OR b.bonus < 1000
;学生们参加各科测试的次数(多表连接与笛卡尔积)
题目链接:1280. 学生们参加各科测试的次数
考察了多表连接与笛卡尔积
注意:
在 MySQL 中,如果执行 a LEFT JOIN b 时,b 表中有多条记录与 a 表中的一条记录匹配,那么查询结果中会生成多条记录。
具体来说:
a表中的那条记录会被保留- 同时会与
b表中所有匹配的记录分别组合,形成多条结果行 - 最终结果的数量 =
a表中符合条件的记录数 × 对应b表中匹配的记录数
例如:
a表有一条记录:(id=1, name='张三')b表有两条匹配记录:(id=1, a_id=1, address='北京')和(id=2, a_id=1, address='上海')
执行 a LEFT JOIN b ON a.id = b.a_id 后,会得到两条结果:
id name id a_id address
1 张三 1 1 北京
1 张三 2 1 上海这种现象称为"笛卡尔积效应"的一种特殊情况,当连接条件匹配多条记录时就会产生。如果不需要这种效果,可能需要调整连接条件,或使用 DISTINCT、聚合函数(如 GROUP BY)来处理结果。
本题的解题逻辑:
- Student表和Subjects表进行笛卡尔积连接(Student JOIN Subjects)
- 在第一点的基础上拼接Examinations中的每个学生参加每门科目的数量。使用左连接。
- 然后就可以根据st.student_id,su.subject_name进行分组,然后使用聚合函数了
- 有一个值得注意点的点就是:使用聚合函数统计个数的时候,不能直接使用COUNT(*)、COUNT(1),因为这会把null也给统计进去。所以我们因该根据Examinations表中的subject_name来统计个数,而不能通过Subjects表中的subject_name来统计(这样的话没有考的科目也会记为1)。
解题代码:
sql
SELECT
st.student_id,st.student_name,su.subject_name,COUNT(e.subject_name) AS attended_exams
FROM
Students AS st CROSS JOIN Subjects AS su LEFT JOIN Examinations AS e
ON
e.student_id = st.student_id AND e.subject_name = su.subject_name
GROUP BY
st.student_id,su.subject_name
ORDER BY
st.student_id,su.subject_name
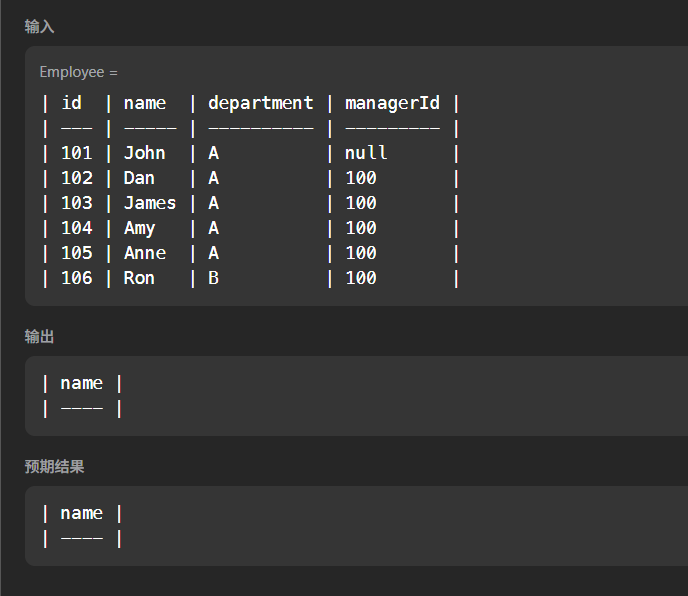
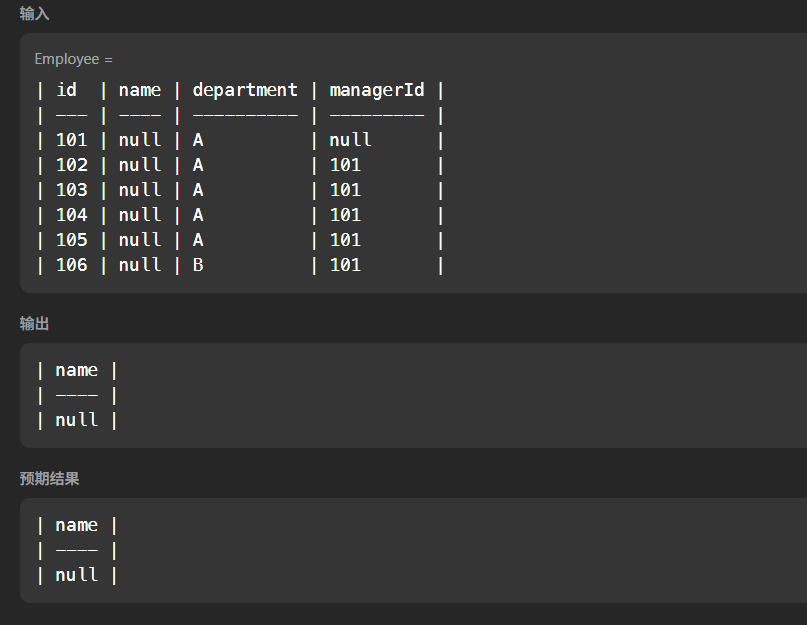
;至少有5名直接下属的经理
题目链接:570. 至少有5名直接下属的经理
解题逻辑:
这一题的注意点在于不能使用左连接,而是应该使用内连接:
如果使用左连接的话,以下两种情况过不了:
sql
SELECT
e2.name
FROM
Employee AS e1 LEFT JOIN Employee AS e2
ON
e1.managerId = e2.id
GROUP BY
e1.managerId,e2.name
HAVING
count(e1.managerId) >= 5 AND e2.name IS NOT NULL
;我们需要不仅要保证员工存在,经理也需要存在,所以使用内连接:
解题代码:
sql
SELECT
e2.name
FROM
Employee AS e1 INNER JOIN Employee AS e2
ON
e1.managerId = e2.id
GROUP BY
e1.managerId,e2.name
HAVING
count(e1.managerId) >= 5
;总结:表连接的使用场景
在 MySQL 中,不同的连接方式用于处理表之间的关联关系,选择哪种连接方式取决于你想要获取的数据范围。以下是各种连接的适用场景:
- 内连接(INNER JOIN)
适用场景 :只需要两个表中匹配条件的记录 。
内连接是最常用的连接方式,它会返回两个表中满足连接条件的交集部分。
例如:查询"学生表"和"成绩表"中所有有成绩记录的学生信息(只显示有成绩的学生)。
sql
SELECT 学生.姓名, 成绩.分数
FROM 学生
INNER JOIN 成绩 ON 学生.学号 = 成绩.学号;- 左连接(LEFT JOIN / LEFT OUTER JOIN)
适用场景 :需要左表的所有记录 ,以及右表中匹配条件的记录;右表中无匹配的记录用NULL填充。
左连接以左表为基础,即使右表没有对应的数据,也会保留左表的全部记录。
例如:查询"所有学生"的信息,以及他们的成绩(包括没有成绩的学生,成绩字段显示 NULL)。
sql
SELECT 学生.姓名, 成绩.分数
FROM 学生
LEFT JOIN 成绩 ON 学生.学号 = 成绩.学号;- 右连接(RIGHT JOIN / RIGHT OUTER JOIN)
适用场景 :需要右表的所有记录 ,以及左表中匹配条件的记录;左表中无匹配的记录用NULL填充。
右连接以右表为基础,功能与左连接对称,只是基准表不同。
例如:查询"所有成绩记录",以及对应的学生信息(包括成绩记录中可能存在的无效学号,学生信息字段显示 NULL)。
sql
SELECT 学生.姓名, 成绩.分数
FROM 学生
RIGHT JOIN 成绩 ON 学生.学号 = 成绩.学号;-
全连接(FULL JOIN / FULL OUTER JOIN)
适用场景 :需要两个表的所有记录 ,无论是否匹配;不匹配的部分用NULL填充。全连接是左连接和右连接的结合,返回两个表的并集。
注意 :MySQL 不直接支持 FULL JOIN ,但可以通过
UNION组合左连接和右连接实现:
sql
-- 实现全连接效果
SELECT 学生.姓名, 成绩.分数
FROM 学生
LEFT JOIN 成绩 ON 学生.学号 = 成绩.学号
UNION
SELECT 学生.姓名, 成绩.分数
FROM 学生
RIGHT JOIN 成绩 ON 学生.学号 = 成绩.学号;总结选择依据:
- 需交集:用内连接(INNER JOIN)。
- 需左表全部 + 右表匹配:用左连接(LEFT JOIN)。
- 需右表全部 + 左表匹配:用右连接(RIGHT JOIN)。
- 需全部记录(包括不匹配的):用全连接(FULL JOIN,MySQL 需用 UNION 模拟)。
根据业务需求中是否需要保留"不匹配的记录"来决定具体使用哪种连接方式。
确认率(条件判断的使用)
题目链接:1934. 确认率
解题思路:
条件判断可以在哪里使用?
在 MySQL 中,条件判断是非常重要的功能,广泛应用于各种查询场景中。以下是条件判断的主要使用场景和常见用法总结:
- WHERE 子句中使用条件判断
最基础的用法,用于过滤行数据:
sql
-- 筛选年龄大于18的用户
SELECT * FROM users WHERE age > 18;
-- 多条件组合
SELECT * FROM products
WHERE price > 100
AND category = 'electronics'
OR (promotion = 1 AND stock > 0);- HAVING 子句中使用条件判断
与 GROUP BY 配合使用,用于过滤聚合后的结果:
sql
-- 筛选平均评分大于4.5的商品分类
SELECT category, AVG(rating) as avg_rating
FROM products
GROUP BY category
HAVING avg_rating > 4.5;- CASE 表达式实现复杂条件判断
可在 SELECT、WHERE、ORDER BY 等多个位置使用,实现多分支判断:
sql
-- 在SELECT中使用,将数值转换为文字描述
SELECT
id,
score,
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END as score_level
FROM students;
-- 在ORDER BY中使用,自定义排序逻辑
SELECT * FROM products
ORDER BY
CASE WHEN promotion = 1 THEN 0 ELSE 1 END,
price;- 聚合函数中使用条件判断
通常用于在聚合时只计算满足特定条件的记录:
sql
-- 计算男性用户的平均工资(忽略女性)
SELECT AVG(CASE WHEN gender = 'male' THEN salary END) as male_avg_salary
FROM employees;
-- 统计不同状态的订单数量
SELECT
COUNT(CASE WHEN status = 'pending' THEN 1 END) as pending_count,
COUNT(CASE WHEN status = 'completed' THEN 1 END) as completed_count
FROM orders;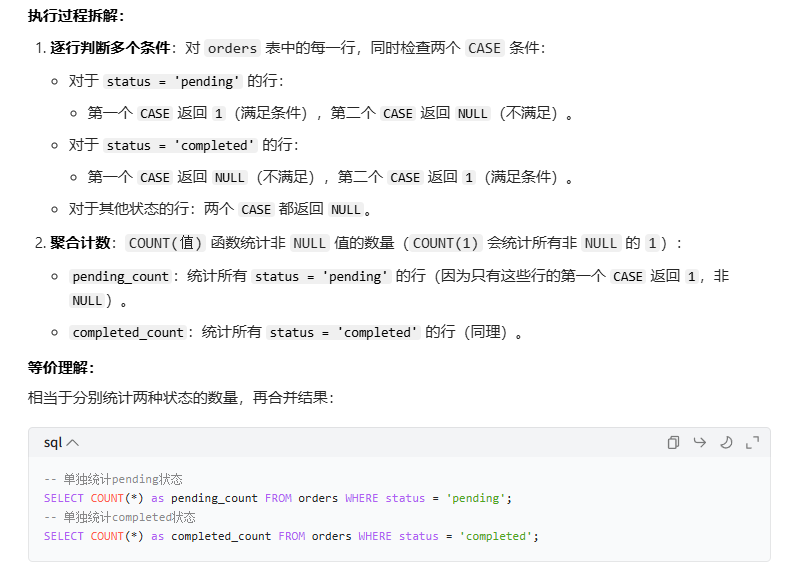
- JOIN 子句中使用条件判断
控制表之间的连接条件:
sql
-- 只连接同部门的员工和经理
SELECT e.name, m.name as manager_name
FROM employees e
LEFT JOIN employees m
ON e.department_id = m.department_id
AND m.is_manager = 1;- UPDATE/DELETE 语句中使用条件判断
控制数据修改或删除的范围:
sql
-- 更新库存不足的商品状态
UPDATE products
SET status = 'out_of_stock'
WHERE stock <= 0;
-- 删除30天前的过期日志
DELETE FROM logs
WHERE created_at < DATE_SUB(NOW(), INTERVAL 30 DAY);- 函数中的条件判断
在自定义函数或存储过程中使用条件逻辑:
sql
CREATE FUNCTION get_discount(price DECIMAL(10,2), is_vip INT)
RETURNS DECIMAL(10,2)
BEGIN
DECLARE discount DECIMAL(10,2);
IF is_vip = 1 THEN
SET discount = price * 0.9;
ELSEIF price > 1000 THEN
SET discount = price * 0.95;
ELSE
SET discount = price;
END IF;
RETURN discount;
END;常用条件判断函数
IF(expr, v1, v2):如果 expr 为真返回 v1,否则返回 v2IFNULL(v1, v2):如果 v1 不为 NULL 则返回 v1,否则返回 v2NULLIF(expr1, expr2):如果 expr1 等于 expr2 则返回 NULL,否则返回 expr1CASE:多分支条件判断(最灵活,推荐优先使用)
IF(expr, v1, v2):简单双分支判断
-
作用 :如果表达式
expr为TRUE(非0、非NULL),返回v1;否则返回v2。 -
语法 :
IF(判断条件, 条件为真时的结果, 条件为假时的结果) -
示例 :
sql-- 判断用户是否成年 SELECT name, age, IF(age >= 18, '成年', '未成年') AS age_status FROM users; -- 计算订单实际支付金额(有折扣则用折扣价,否则用原价) SELECT order_id, price, discount, IF(discount > 0, price * discount, price) AS pay_amount FROM orders;
IFNULL(v1, v2):处理 NULL 值
-
作用 :如果
v1不是NULL,返回v1;否则返回v2(用于替换NULL为指定值)。 -
语法 :
IFNULL(可能为NULL的值, 替换的默认值) -
注意 :仅判断
NULL,不判断0或空字符串('')。 -
示例 :
sql-- 用0替换NULL的库存(避免计算时NULL影响结果) SELECT product_name, IFNULL(stock, 0) AS actual_stock -- 若stock为NULL,返回0 FROM products; -- 计算平均评分(忽略NULL,用0填充) SELECT product_id, AVG(IFNULL(rating, 0)) AS avg_rating -- 评分NULL时按0计算 FROM reviews GROUP BY product_id;
NULLIF(expr1, expr2):值相等时返回 NULL
-
作用 :如果
expr1等于expr2,返回NULL;否则返回expr1(常用于避免除以0等场景)。 -
语法 :
NULLIF(值1, 值2) -
示例 :
sql-- 避免除法运算中除数为0(若除数为0,返回NULL) SELECT total_sales, sales_count, total_sales / NULLIF(sales_count, 0) AS avg_sale -- 若sales_count=0,结果为NULL FROM sales; -- 当名称为空字符串时返回NULL SELECT name, NULLIF(name, '') AS clean_name -- 若name是'',返回NULL FROM users;
CASE表达式:多分支复杂判断
CASE是最灵活的条件判断方式,支持多分支,可替代多层IF()嵌套。有两种语法形式:
形式1:CASE expr WHEN val1 THEN res1 ... ELSE resN END
-
用于判断
expr是否等于某个值(单条件匹配)。 -
示例 :
sql-- 将订单状态码转换为文字描述 SELECT order_id, status, CASE status WHEN 1 THEN '待支付' WHEN 2 THEN '已支付' WHEN 3 THEN '已发货' ELSE '已取消' -- 其他状态默认值 END AS status_desc FROM orders;
形式2:CASE WHEN cond1 THEN res1 ... ELSE resN END
-
用于判断多个不同条件(多条件匹配,更常用)。
-
示例 :
sql-- 根据分数划分等级(多条件范围判断) SELECT student_id, score, CASE WHEN score >= 90 THEN 'A' WHEN score >= 80 THEN 'B' WHEN score >= 60 THEN 'C' ELSE 'D' END AS grade FROM exam_scores; -- 按用户等级计算折扣(组合条件) SELECT user_id, level, consumption, CASE WHEN level = 'VIP' AND consumption > 1000 THEN 0.8 WHEN level = 'VIP' THEN 0.9 WHEN consumption > 500 THEN 0.95 ELSE 1.0 END AS discount FROM users;
总结:函数选择建议
- 简单双分支判断:用
IF()(简洁)。 - 处理
NULL替换:用IFNULL()。 - 需要"值相等时返回 NULL":用
NULLIF()(如避免除0)。 - 多分支、范围判断或复杂逻辑:优先用
CASE(可读性更好,支持更多条件)。
这些函数可在 SELECT、WHERE、ORDER BY、聚合函数(如 SUM()、AVG())等场景中灵活使用,满足各种条件判断需求。
解题代码:
sql
# Write your MySQL query statement below
SELECT
s.user_id,
CASE
WHEN COUNT(c.action) = 0 THEN ROUND(0,2)
ELSE ROUND(COUNT(CASE WHEN c.action = 'confirmed' THEN 1 END) / COUNT(c.action),2)
END AS confirmation_rate
FROM
Signups AS s LEFT JOIN Confirmations AS c
ON
s.user_id = c.user_id
GROUP BY
s.user_id
;