项目参考:代码随想录知识星球
Github链接:Cookies-CGQ/CacheSystem
1、缓存系统项目背景
什么是缓存系统?
缓存通过将高频访问数据暂存在内存中,能显著提升数据访问速度,有效降低延迟并提高系统吞吐量。
为什么要实现缓存系统?
缓存系统的优势: 通过牺牲部分服务器内存资源,缓存系统可以有效减少对磁盘或数据库的直接读写操作(磁盘读写速度远低于内存且承载能力有限),从而显著提升系统响应速度。这一机制尤其适用于高并发场景,通过存储高频访问数据并结合合理的缓存策略,能够大幅提升资源访问效率。
缓存系统的实现机制: 鉴于服务器内存容量有限,无法存储全部数据,因此需要设计缓存淘汰机制。当内存使用达到阈值时,系统会根据预设策略自动选择需要删除的数据,确保缓存资源的高效利用。
在什么地方加入缓存?
参考链接:https://blog.csdn.net/chongfa2008/article/details/121956961
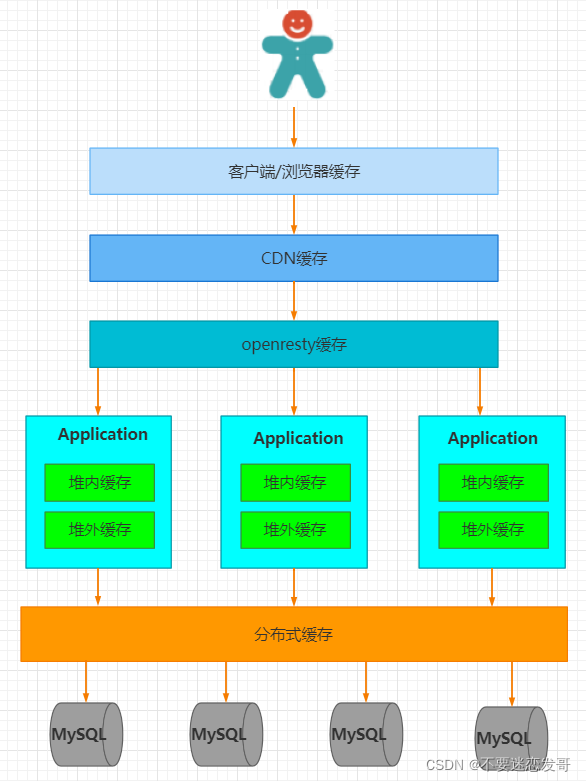
举个例子:假设一个网站,需要提高性能,缓存可以放在浏览器,可以放在反向代理服务器,还可以放在应用程序进程内,同时可以放在分布式缓存系统中。
数据从请求到返回的完整链路包括浏览器、CDN、代理服务器、应用服务器和数据库等多个环节。每个环节均可采用缓存技术优化性能。请求流程始于浏览器/客户端,通过HTTP协议与CDN交互获取数据变更信息;到达代理服务器(如Nginx)时,可通过反向代理获取静态资源;继续向下传递至应用服务器,可采用进程内(堆内)缓存或分布式缓存。当所有缓存均未命中时,才会最终查询数据库。
标准缓存层级依次为:用户请求→HTTP缓存→CDN缓存→代理服务器缓存→进程内缓存→分布式缓存→数据库。
缓存效果与用户距离呈正相关,离用户越近的缓存层效果越显著。
了解:CDN与CDN缓存
CDN 的基本概念
CDN(Content Delivery Network,内容分发网络)是一种分布式服务器系统,通过将内容缓存到全球多个节点,使用户能够从最近的节点获取数据,从而降低延迟、提高访问速度。CDN 的核心目标是通过地理分布的边缘服务器优化内容传输效率。
CDN 缓存的工作原理
CDN 缓存是 CDN 的核心功能之一,通过以下机制实现内容加速:
- 边缘节点缓存:CDN 将静态资源(如图片、CSS、JS 文件)缓存在靠近用户的边缘服务器上,减少回源请求。
- 缓存规则 :根据 HTTP 头(如
Cache-Control、Expires)确定资源的缓存时长,动态内容通常设置为不缓存。- 缓存失效:通过手动刷新(Purge)或自动过期机制更新边缘节点的缓存内容。
2、缓存淘汰策略
常见的缓存淘汰策略有FIFO、LRU、LFU、ARC等,下面详细介绍以上四种缓存淘汰策略。
缓存污染:指访问很少的数据在服务完访问请求后还继续留在缓存中,造成缓存空间的浪费。
缓存污染一旦变严重后,有大量不再访问的数据滞留在缓存中,往缓存中写入新数据时需要先把数据淘汰出缓存,引入额外的时间开销。FIFO
先进先出算法,是最简单的页面替换策略,按照页面进入内存的顺序来决定替换哪个页面。即优先淘汰最早进入内存的页面,不论这些页面之后是否被频繁访问。但是FIFO可能会导致"Belady异常",即随着分配给进程的物理块数增加,缺页次数反而增加。
Belady异常
Belady异常是操作系统内存管理中一个违反直觉但却非常重要的现象。简单来说,它指的是在采用先进先出(FIFO)页面置换算法 时,在某些特定的页面访问序列下,为进程分配更多的物理内存帧(页框) ,其缺页率不降反升的反常情况。
核心概念:
- 只与FIFO算法相关:Belady异常是FIFO算法独有的缺陷。像最优置换算法或最近最久未使用算法等基于"堆栈"的算法则不会出现此现象。
- 违背直觉:通常我们认为,内存越大,程序运行越流畅,缺页中断应该越少。Belady异常挑战了这一常识。
- 根本原因 :FIFO算法只关心页面进入内存的时间先后,而完全忽略了页面的使用频率和重要性。它可能会草率地换出一个即将被再次访问的页面,从而导致不必要的缺页中断。
例子:
访问序列:1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
我们分别模拟当系统为这个进程分配 3个内存帧 和 4个内存帧 时,使用FIFO算法会发生什么。页面装满后,每次缺页都需要置换最早进入的页面。
情况一:分配 3个 内存帧
下表详细展示了整个过程,缺页表示此次访问引发了缺页中断。
访问页面 内存中的页面 (按进入顺序) 缺页 被置换的页面 说明 1 1 缺页 - 初始加载 2 1, 2 缺页 - 初始加载 3 1, 2, 3 缺页 - 内存填满 4 2, 3, 4 缺页 1 置换最早进入的页面1 1 3, 4, 1 缺页 2 置换页面2 2 4, 1, 2 缺页 3 置换页面3 5 1, 2, 5 缺页 4 置换页面4 1 1, 2, 5 命中 - 页面1已在内存 2 1, 2, 5 命中 - 页面2已在内存 3 2, 5, 3 缺页 1 置换页面1 4 5, 3, 4 缺页 2 置换页面2 5 5, 3, 4 命中 - 页面5已在内存 总缺页次数 :9次
情况二:分配 4个 内存帧
现在,我们给进程分配更多的资源------4个内存帧。
访问页面 内存中的页面 (按进入顺序) 缺页 被置换的页面 说明 1 1 缺页 - 初始加载 2 1, 2 缺页 - 初始加载 3 1, 2, 3 缺页 - 初始加载 4 1, 2, 3, 4 缺页 - 内存填满 1 1, 2, 3, 4 命中 - 页面1已在内存 2 1, 2, 3, 4 命中 - 页面2已在内存 5 2, 3, 4, 5 缺页 1 置换最早进入的页面1 1 3, 4, 5, 1 缺页 2 置换页面2 2 4, 5, 1, 2 缺页 3 置换页面3 3 5, 1, 2, 3 缺页 4 置换页面4 4 1, 2, 3, 4 缺页 5 置换页面5 5 2, 3, 4, 5 缺页 1 置换页面1 总缺页次数 :10次
原因分析:对比两个表格,可以清晰地看到,内存帧从3个增加到4个,缺页次数却从9次增加到了10次。这就是Belady异常。
核心原因在于FIFO算法的"短视":它粗暴地认为最早来的页面就是最"没用"的。
- 在3帧 的情况下,虽然内存小,但页面置换相对频繁,反而阴差阳错地保留了一些关键页面(例如,在访问页面5时,内存中保留的是
[1,2,5],这使得后续对页面1和2的连续访问都能命中)。- 而在4帧 的情况下,内存变大,页面1和2在初始阶段一直保留在内存中。但当需要装入新页面5时,FIFO算法却根据"先进先出"的规则,将很快又会被再次访问的页面1置换了出去。这个糟糕的决定引发了一连串的后续缺页(访问1、2、3、4时都发生缺页),导致总体性能下降。
FIFO算法实现
FIFO(先进先出)算法的核心思想是优先淘汰最早进入缓存的页面。这种算法模拟了现实生活中的排队行为,就像排队购物一样,先来的人先服务,先来的人先离开。
cpp//FIFOCache.hpp #include <iostream> #include <queue> #include <unordered_set> #include <vector> class FIFOCache { public: // 构造函数,初始化缓存容量 FIFOCache(int cap) : capacity(cap) {} // 访问页面,返回缺页次数(true表示缺页) bool accessPage(int pageNum) { // 如果页面已在缓存中,不需要置换,直接返回false(未缺页) if (pageSet.find(pageNum) != pageSet.end()) { return false; } // 缺页情况:页面不在缓存中 // 如果缓存已满,需要移除最先进入的页面 if (pageQueue.size() == capacity) { int oldestPage = pageQueue.front(); pageQueue.pop(); pageSet.erase(oldestPage); } // 将新页面加入缓存 pageQueue.push(pageNum); pageSet.insert(pageNum); return true; } // 显示当前缓存中的页面 void displayCache() { std::cout << "当前缓存内容: "; // 由于queue不支持直接遍历,我们需要临时复制内容 std::queue<int> tempQueue = pageQueue; while (!tempQueue.empty()) { std::cout << tempQueue.front() << " "; tempQueue.pop(); } std::cout << std::endl; } // 获取缓存当前大小 int getCurrentSize() { return pageQueue.size(); } // 获取缓存容量 int getCapacity() { return capacity; } private: int capacity; // 缓存容量 std::queue<int> pageQueue; // 存放页面顺序的队列 std::unordered_set<int> pageSet; // 快速判断页面是否存在的集合 };
LRU
最近最少使用(LRU)算法基于这样的假设:设计原则借鉴了时间局部性原理,最近被访问过的数据,未来再次访问的概率较高。因此,它会优先替换最长时间未被访问的页面。LRU算法的性能表现接近最优页面置换算法(OPT),但在处理频繁访问的页面时,其更新开销相对较大。
潜在问题------热点数据丢失
当某个数据在前59分钟内被高频访问(如1万次),表明其具备热点属性。若最后一分钟未被访问,而系统在此期间处理了其他数据请求,可能导致该热点数据被误淘汰。
LRU算法实现
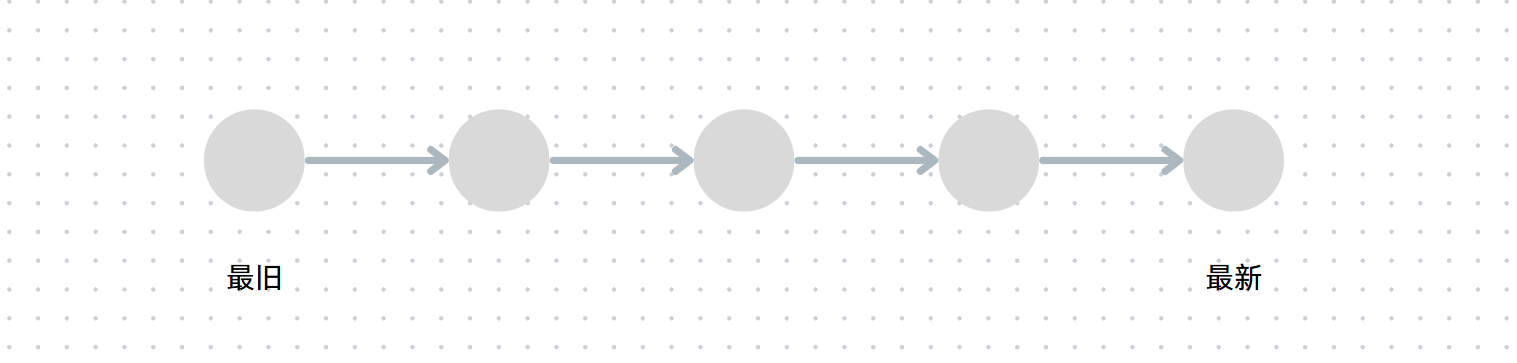
假设有一条时间线,每次替换最长时间未被访问的页面,也就是时间线上左边最左的地方,进行替换。
如果把时间线看成一个链表(满足时序条件),那么最长时间未被访问的页面就是下图链表的最左节点:
初始化一个容量为n的KV结构缓存空间。
对于新增操作:
- 若key已存在,则更新对应value,并将该数据移至缓存最右端(表示最近使用)
- 若key不存在:
- 当缓存未满时,直接在最右端插入新节点
- 当缓存已满时,先移除最左端节点(最久未使用),再在最右端插入新数据
对于访问操作:
- 若key存在,返回对应value并将该数据移至最右端
- 若key不存在,返回-1表示查询失败
(注:最右端代表最新使用,最左端代表最久未使用)
为了实现LRU算法中新增和访问操作的平均时间复杂度控制在O(1)内,可以采用以下优化方案:使用双向链表维护节点间的时序关系,通过链表两端的边界元素快速处理最近使用和最久未使用的节点,确保增删操作的时间复杂度为O(1);同时配合哈希表建立key与节点指针的映射关系,实现O(1)复杂度的快速查询。
cpp//CachePolicy.hpp #ifndef __CACHEPOLICY_HPP__ #define __CACHEPOLICY_HPP__ #include <iostream> #include <memory> #include <unordered_map> #include <mutex> namespace myCache { template <class Key, class Value> class CachePolicy { public: virtual ~CachePolicy() {}; // 添加缓存接口 virtual void put(Key key, Value value) = 0; // key是传入参数 访问到的值以传出参数的形式返回 | 访问成功返回true virtual bool get(Key key, Value& value) = 0; // 如果缓存中能找到key,则直接返回value virtual Value get(Key key) = 0; }; } #endif
cpp//LRU.hpp #ifndef __LRU_HPP__ #define __LRU_HPP__ #include <iostream> #include <memory> #include <unordered_map> #include <mutex> #include "CachePolicy.hpp" namespace myCache { //前向声明 template<class Key, class Value> class LRUCache; template<class Key, class Value> class LRUNode { typedef LRUNode<Key,Value> Node; friend class LRUCache<Key, Value>; private: Key _key; Value _value; size_t _accessCount; //访问次数 std::weak_ptr<Node> _prev; //weak_ptr打破了循环引用 std::shared_ptr<Node> _next; public: LRUNode(Key key, Value value) :_key(key), _value(value), _accessCount(1) {} //获取key Key getKey() const { return _key; } //获取value Value getValue() const { return _value; } //设置value void setValue(const Value& value) { _value = value; } //获取访问次数 size_t getAccessCount() const { return _accessCount; } //增加访问次数 void incrementAccessCount() { _accessCount++; } }; template<class Key, class Value> class LRUCache : public CachePolicy<Key, Value> { typedef LRUNode<Key, Value> Node; typedef std::shared_ptr<Node> NodePtr; typedef std::unordered_map<Key, NodePtr> NodeMap; private: //更新已存在的节点 void updateExistringNode(NodePtr node, const Value& value) { node->setValue(value); moveToMostRecent(node); } //添加新节点 void addNewNode(const Key& key, const Value& value) { if(_nodeMap.size() >= _capacity) { //如果缓存已满,则删除head节点再插入 evictLeastRecent(); } NodePtr newNode = std::make_shared<Node>(key, value); _nodeMap[key] = newNode; insertNode(newNode); } //移动节点到tail void moveToMostRecent(NodePtr node) { removeNode(node); insertNode(node); } //断开节点与链表的联系 void removeNode(NodePtr node) { if(!node->_prev.expired() && node->_next) { auto prev = node->_prev.lock(); prev->_next = node->_next; node->_next->_prev = prev; node->_next = nullptr; } } // 驱逐最近最少访问 void evictLeastRecent() { NodePtr leastRecent = _head->_next; removeNode(leastRecent); _nodeMap.erase(leastRecent->getKey()); } // 插入节点 void insertNode(NodePtr node) { node->_next = _tail; node->_prev = _tail->_prev; _tail->_prev.lock()->_next = node; _tail->_prev = node; } public: LRUCache(int capacity) :_capacity(capacity), _nodeMap(), _mutex() { _head = std::make_shared<Node>(Key(), Value()); _tail = std::make_shared<Node>(Key(), Value()); _head->_next = _tail; _tail->_prev = _head; } ~LRUCache() override = default; //默认析构函数 // 添加缓存接口 void put(Key key, Value value) override { if(_capacity <= 0) return; std::lock_guard<std::mutex> lock(_mutex); auto it = _nodeMap.find(key); if(it != _nodeMap.end()) { //如果当前节点存在,则更新数据并移动到tail updateExistringNode(it->second, value);//更新并移动 return; } //如果当前节点不存在,则插入到tail //如果缓存已满,则删除head节点再插入 //如果缓存未满,则插入到tail addNewNode(key, value); } // key是传入参数 访问到的值以传出参数的形式返回 | 访问成功返回true bool get(Key key, Value& value) override { std::lock_guard<std::mutex> lock(_mutex); auto it = _nodeMap.find(key); if(it != _nodeMap.end()) { //如果存在则更新访问次数并移动到tail moveToMostRecent(it->second);//移动到tail value = it->second->getValue();//返回value return true; } //如果不存在则返回false return false; } // 如果缓存中能找到key,则直接返回value Value get(Key key) override { Value value; if(get(key, value)) return value; else { std::cout << "key not found" << std::endl; return value; } } //删除 void remove(Key key) { std::lock_guard<std::mutex> lock(_mutex); auto it = _nodeMap.find(key); if(it != _nodeMap.end()) { removeNode(it->second); _nodeMap.erase(it); } } private: int _capacity; //缓存容量 NodeMap _nodeMap; //节点映射表<Key, NodePtr> std::mutex _mutex; NodePtr _head; //头节点--最近最久未使用 NodePtr _tail; //尾节点--最近使用 }; } #endif这里的代码还可以给每个节点增加一个时间字段,用来表示将来过期的时间,从而实现定时/不定时过期的淘汰机制,这里不做演示。
基础LRU缺陷
在学习基础LRU缓存算法的实现后,我们不难发现其存在的几个主要问题:
访问模式适应性差:当遇到循环遍历大量不重复数据的情况(如A->B->C->D->A->B->...),LRU算法会逐步清空缓存,导致缓存命中率极低。
缓存污染问题:若缓存中加载了不再被访问的冷数据(如一次性数据),这些数据会挤占热点数据的缓存空间,从而降低缓存利用率。
适用场景有限:在某些特定场景下,"最近最少使用"并不等同于"最不重要"或"最少需要"。
并发性能瓶颈:在多线程高并发环境下,粗粒度的锁机制会导致严重的同步等待开销。
针对这些问题,本文提出了以下优化方案:
- LRU-K算法
- HashLRU算法

LRU-K
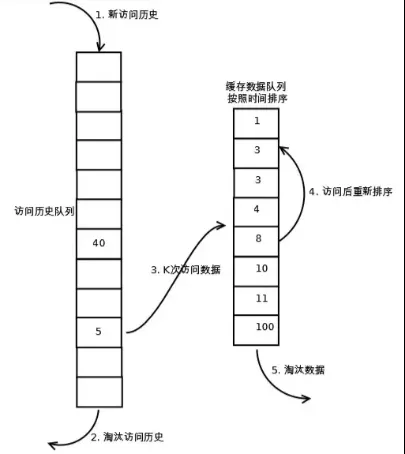
LRU-k算法是LRU算法的改进版本。与基础LRU算法(可视为LRU-1)不同,LRU-k要求数据被访问k次(可自定义)才能进入缓存队列,而非单次访问(put/get)即可缓存。
该算法维护两个队列:缓存队列和数据访问历史队列。当访问数据时,首先将其记录到访问历史队列并累计访问次数。仅当访问次数达到k次阈值时,该数据才会被移入缓存队列,有效防止冷数据污染缓存。同时,访问历史队列同样遵循LRU淘汰机制来管理数据留存。
一般情况下,当k的值越大,缓存的命中率越高,但也使得缓存难以淘汰。综合来说,k = 2 时性能最优。
以下是LRU-k算法的执行流程示意图:
LRUKCache继承上面的LRUCache,LRUCache作为主缓存,用来缓存数据;LRUKCache定义的LRUCache对象作为副缓存,用来缓存访问数据历史记录。
cpp//LRUK.hpp -- LRUKCache直接继承上面的LRUCache #ifndef __LRUK_HPP__ #define __LRUK_HPP__ #include <iostream> #include <memory> #include <unordered_map> #include "LRU.hpp" namespace myCache { template <class Key, class Value> class LRUKCache:public LRUCache<Key, Value> { public: LRUKCache(int capacity, int historyCapacity, int k) :LRUCache<Key, Value>(capacity), _k(k), _historyList(std::make_unique<LRUCache<Key,size_t>>(historyCapacity)) {} Value get(Key key) { //尝试从主缓存中获取数据 Value value{}; bool inMainCache = LRUCache<Key, Value>::get(key, value); //获取并更新访问历史计数 //如果在_historyList存在,则返回的是历史访问计数 //如果不存在,则返回0(取决于get函数) size_t historyCount = _historyList->get(key); historyCount++; _historyList->put(key, historyCount); //如果主缓存有,直接返回 if(inMainCache) { return value; } //如果主缓存没有,尝试从历史缓存中获取数据 if(historyCount >= _k) { auto it = _historyValueMap.find(key); if(it != _historyValueMap.end()) { //有历史值,将其添加到主缓存 Value storedValue = it->second; //从历史记录移除 _historyList->remove(key); _historyValueMap.erase(it); //添加到主缓存 LRUCache<Key, Value>::put(key, storedValue); return storedValue; } //没有历史值记录,无法添加到缓存,返回默认值 } //数据不在主缓存且不满足添加条件,返回默认值 return value; } void put(Key key, Value value) { //检查是否已在主缓存 Value exitingValue{}; bool inMainCache = LRUCache<Key, Value>::get(key, exitingValue); if(inMainCache) { //如果已在主缓存,直接更新值 LRUCache<Key, Value>::put(key, value); return; } //如果不存在于主缓存 //获取并更新访问历史 size_t historyCount = _historyList->get(key); historyCount++; _historyList->put(key, historyCount); //保存值到历史记录映射,供后续get操作使用 _historyValueMap[key] = value; //检查是否达到k次访问阈值 if(historyCount >= _k) { //如果达到,将历史值添加到主缓存 _historyList->remove(key); _historyValueMap.erase(key); LRUCache<Key, Value>::put(key, value); } } public: int _k; // 进入缓存队列的评判标准 std::unique_ptr<LRUCache<Key, size_t>> _historyList; // 用于存储key的历史访问计数 std::unordered_map<Key, Value> _historyValueMap; // 存储未达到k次访问的数据值 }; } #endifHashLRU
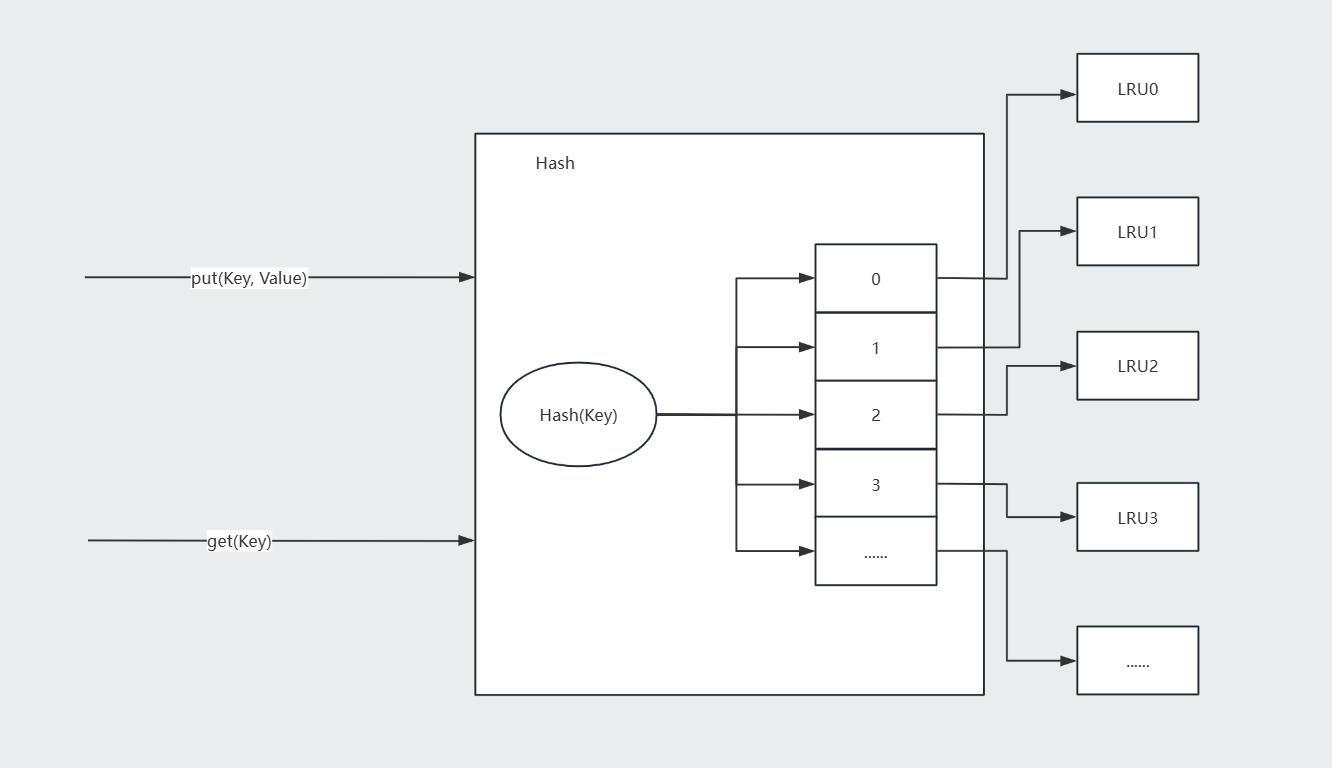
从上述分析可见,该项目的锁粒度较大,且难以直接细化,因为涉及线程安全的环节过多,连读写锁都无法有效优化。为此,我们转变思路,采用LRU分片方案。具体实现结构如图所示:
通过哈希运算将key映射到对应的LRU分片,然后调用该分片的方法。
设想多个线程同时访问单个LRU缓存(LFU同理)时,由于锁的粒度较大,会导致较长时间的同步等待。但如果多个线程同时访问多个LRU分片,同步等待时间就能显著减少。
普通的LRUCache和LFUCache在高并发情况下耗时增加的原因分析
在高并发场景下,线程安全的LRUCache和LFUCache中的锁机制会成为性能瓶颈。虽然低QPS时锁竞争的开销可以忽略不计,但当并发量激增时,线程频繁等待锁释放会显著增加系统耗时,导致整体性能下降。
HashLRUCache和HashLFUCache适应高并发常见
为优化因同步等待导致的性能瓶颈,关键在于缩小临界区范围。我们采用哈希分片机制,将完整数据集划分为多个子集,在现有LfuCache基础上构建HashLfuCache架构,从而显著降低查询延迟。
HashLfuCache通过哈希算法将缓存数据均匀分布到N个LfuCache节点中。查询时先根据相同哈希算法定位目标分片,再在对应分片执行查询操作。这种设计有效提升了LFU算法的并发处理能力,大幅减少了同步等待时间
HashLRUCache算法实现
HashLRUCaches与LRUCache之间是组合关系,前者依赖于后者的实现。
需要注意的是:在采用分片策略后,LRU(LFU)淘汰的元素不再是全局范围内访问频率最低的元素(即全局minFreq_),而是当前分片的minFreq_。这种设计是可接受的,因为当某个LRU(LFU)分片中已存储大量元素,而新元素仍被分配到该分片时,应该优先淘汰当前分片中最不常用的元素,而非全局最不常用元素,这样才能为新元素腾出空间。
cpp//HashLRUCache.hpp #ifndef __HASH_LRU_HPP__ #define __HASH_LRU_HPP__ #include "LRU.hpp" namespace myCache { template<class Key, class Value> class HashLRUCache { private: size_t Hash(Key key) { std::hash<Key> hashFunc; return hashFunc(key); } public: HashLRUCache(size_t capacity, int sliceNum) :_capacity(capacity), _sliceNum(sliceNum > 0 ? sliceNum : std::thread::hardware_concurrency()) { size_t sliceSize = std::ceil(capacity / static_cast<double>(_sliceNum)); for(int i = 0; i < _sliceNum; i++) { _LRUSliceCaches.emplace_back(std::make_unique<LRUCache<Key, Value>>(sliceSize)); } } void put(Key key, Value value) { size_t sliceIndex = Hash(key) % _sliceNum; _LRUSliceCaches[sliceIndex]->put(key, value); } bool get(Key key, Value& value) { size_t sliceIndex = Hash(key) % _sliceNum; return _LRUSliceCaches[sliceIndex]->get(key, value); } Value get(Key key) { Value value; memset(&value, 0, sizeof(Value)); get(key, value); return value; } private: size_t _capacity; //容量 int _sliceNum; //切片数量 std::vector<std::unique_ptr<LRUCache<Key, Value>>> _LRUSliceCaches; //切片LRU缓存 }; } #endifLFU
该算法基于概率思想设计,采用"最不经常使用"的淘汰策略。其核心观点是:若某个对象的访问频率较低,则未来被再次访问的概率也相对较小。实现机制上,当缓存空间不足时,系统会优先淘汰被访问次数最少的数据项。
LFU算法实现
- 缓存空间初始化,以一个正整数作为容量初始化LRU缓存。
- get访问缓存数据,如果关键字key存在于缓存中,则返回关键字的值,否则返回-1;对缓存数据每执行一次get操作,其访问频数就+1。
- put向缓存中加入数据,如果关键字key已经存在,则变更其数据值value,并将其访问频数+1;如果不存在,则向缓存中插入该组key value,即该key首次加入缓存空间,设置其访问频数为1;如果插入操作导致关键字数量超过capacity,则应该逐出访问频数最低且最久未被访问都数据(当访问频数最低的数据不止一个时,淘汰那个最久未被访问的数据)。
算法实现的关键难点在于确保 get 和 put 操作都能以 O(1) 的平均时间复杂度完成。首先我们需要明确 LRU 和 LFU 这两种缓存淘汰策略的核心区别:
- LRU(最近最少使用)仅基于时间维度进行淘汰,即移除最久未被访问的数据项。
- LFU(最不经常使用)则采用双重判断标准:优先淘汰访问频次最低的项;当频次相同时,再按照 LRU 规则淘汰最久未访问的项。
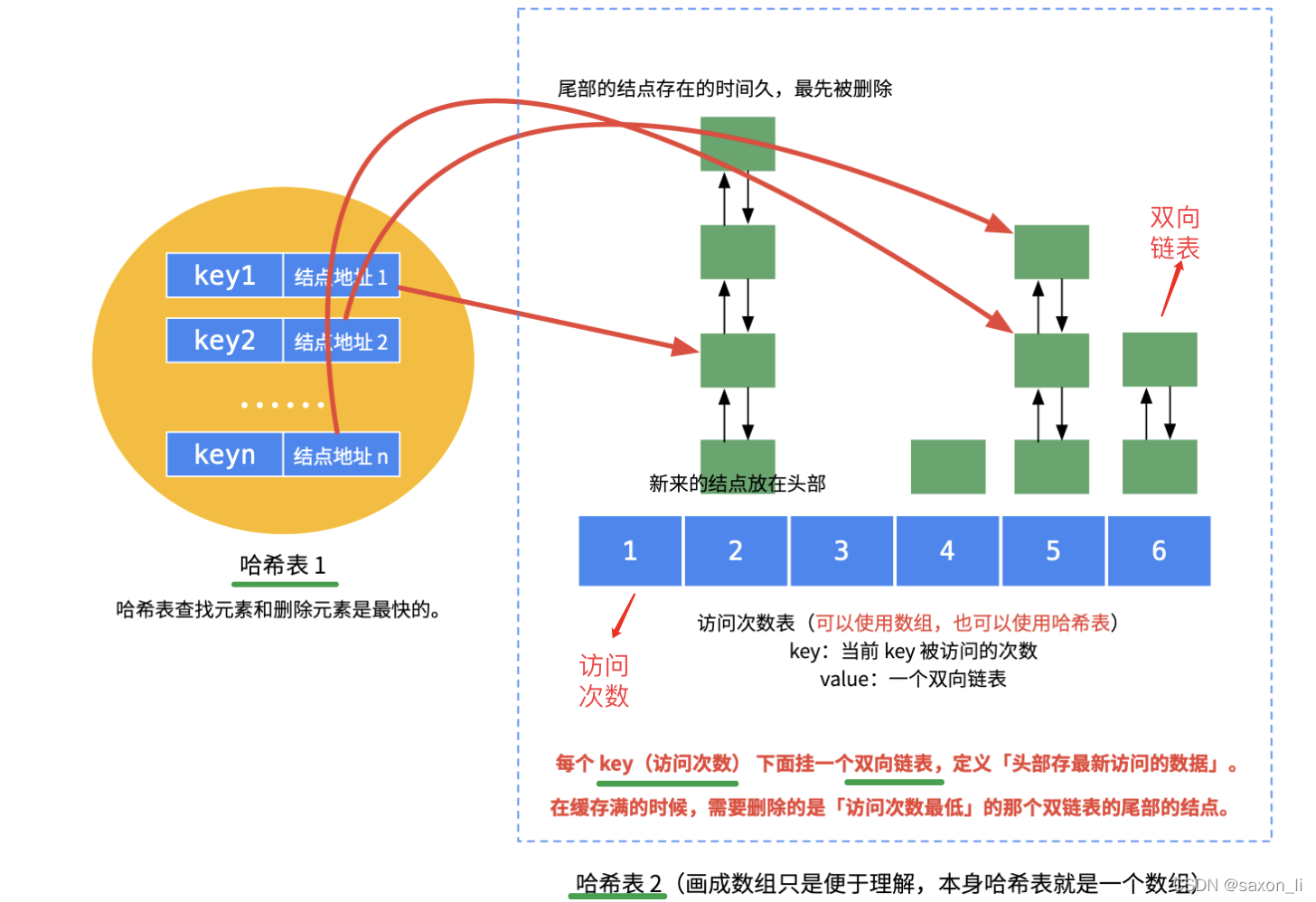
在实现层面,LRU 通常采用一个哈希表配合一个双向链表的结构。而 LFU 由于需要同时考虑访问频次和时间两个维度,其数据结构更为复杂:需要两个哈希表配合多个双向链表来实现。这种设计能够先按频次筛选,再按时间维度进行淘汰决策。其中一个节点哈希表是key与节点地址的映射,用于快速获取数据中key对应的节点信息;另一个频数双向链表哈希表是key被访问的次数与双向链表的映射。
具体数据结构如下图所示:
上面的基础LFU还有很多待优化的点:
- 频率爆炸问题:对于长期驻留在缓存中的热数据,频率计数可能会无限增长,占用额外的存储空间或导致计数溢出。
- 过时热点数据占用缓存:一些数据可能已经不再是热点数据,但因访问频率过高,难以被替换。
- 冷启动问题:刚加入缓存的项可能因为频率为1而很快被淘汰,即便这些项是近期访问的热门数据。
- 不适合短期热点:LFU对长期热点数据表现较好,但对短期热点数据响应较慢,可能导致短期热点数据无法及时缓存。
- 缺乏动态适应性:固定的LFU策略难以适应不同的应用场景或工作负载。
- 锁的粒度大,多线程高并发访问下锁的同步等待时间过长。
针对上述问题,文本进行了以下几点优化:
- 加上最大平均访问次数限制
- HashLFUCache
最大平均访问次数限制的LFU
在LFU算法之上,引入访问次数平均值概念,当平均值大于最大平均值限制时将所有结点的访问次数减去最大平均值限制的一半或者一个固定值。相当于热点数据"老化"了,这样可以避免频次计数溢出,也可以缓解缓存污染,进而解决了频率爆炸问题、过时热点数据占用缓存问题、冷启动问题、不适合短期热点问题。
设置最大平均访问次数的值解决了什么问题?
- 防止某一个缓存的访问频次无限增加,而导致的计数溢出。
- 旧的热点缓存,也就是该数据之前的访问频次很高,但是现在不再被访问了,也能够保证他在每次访问缓存平均访问次数大于最大平均访问次数的时候减去一个固定的值,使这个过去的热点缓存的访问频次逐步降到最低,然后从内存中淘汰出去
- 一定程度上是对新加入进来的缓存,也就是访问频次为1的数据缓存进行了保护,因为长时间没被访问的旧的数据不再会长期占据缓存空间,访问频率会逐步被降为小于1最终淘汰。
cpp//LFUCache.hpp #ifndef __LFUCACHE_HPP__ #define __LFUCACHE_HPP__ #include <iostream> #include <memory> #include <unordered_map> #include <mutex> #include <climits> #include "CachePolicy.hpp" namespace myCache { template <class Key, class Value> class LFUCache; // 某一访问频率的节点链表 template <class Key, class Value> class FreqList { friend class LFUCache<Key, Value>; private: struct Node { int freq; // 访问频率 Key key; Value value; std::weak_ptr<Node> pre; std::shared_ptr<Node> next; Node() : freq(1), next(nullptr) {} Node(Key key, Value value) : freq(1), key(key), value(value), next(nullptr) {} }; typedef std::shared_ptr<Node> NodePtr; int _freq; // 访问频率 NodePtr _head; // 哨兵头节点 NodePtr _tail; // 哨兵尾节点 public: explicit FreqList(int freq) // explicit 防止隐式转换 : _freq(freq), _head(std::make_shared<Node>()), _tail(std::make_shared<Node>()) { _head->next = _tail; _tail->pre = _head; } bool isEmpty() const { return _head->next == _tail; } void addNode(NodePtr node) { if (!node || !_head || !_tail) return; node->pre = _tail->pre; node->next = _tail; _tail->pre.lock()->next = node; _tail->pre = node; } void removeNode(NodePtr node) { if (!node || !_head || !_tail) return; // 判断是否是头或者尾节点 if (node->pre.expired() || node->next == nullptr) return; auto pre = node->pre.lock(); pre->next = node->next; node->next->pre = pre; node->next = nullptr; // 需要确保置空,断开连接,因为智能指针会自动管理内存 } NodePtr getFirstNode() const { return _head->next; } }; template <class Key, class Value> class LFUCache : public CachePolicy<Key, Value> { public: typedef typename FreqList<Key, Value>::Node Node; typedef std::shared_ptr<Node> NodePtr; typedef std::unordered_map<Key, NodePtr> NodeMap; private: //添加缓存 void putInternal(Key key, Value value) { if(_nodeMap.size() == _capacity) { //如果缓存已经满了,删除最不常访问的节点,更新当前平均访问频次和总访问频次 kickOut(); } NodePtr node = std::make_shared<Node>(key, value); _nodeMap[key] = node; addToFreqList(node); addFreqNum(); _minFreq = std::min(_minFreq, 1); //初始node的freq都是1 } //获取缓存 void getInternal(NodePtr node, Value &value) { //找到之后需要将其从低访问频次链表中移除,并将其加入到+1之后的访问频次链表中 value = node->value; removeFromFreqList(node); node->freq++; addToFreqList(node); //如果node在上面+1更新frea之前是最少访问频率的节点,且更新之后之前所在的链表变为空了 //那么需要将_minFreq更新为node的访问频率 if(_minFreq == node->freq - 1 && _freqToFreqList[node->freq - 1]->isEmpty()) _minFreq++; //总访问频次和当前平均访问频次都增加 addFreqNum(); } //移除缓存中的过期数据 void kickOut() { NodePtr node = _freqToFreqList[_minFreq]->getFirstNode(); int decreaseNum = node->freq; _nodeMap.erase(node->key); removeFromFreqList(node); decreaseFreqNum(decreaseNum); } //从频率链表中移除节点 void removeFromFreqList(NodePtr node) { if(!node) return; auto freq = node->freq; _freqToFreqList[freq]->removeNode(node); } //添加到频率列表 void addToFreqList(NodePtr node) { if(!node) return; auto freq = node->freq; //插入之前先判断是否存在该频率的链表 if(_freqToFreqList.find(freq) == _freqToFreqList.end()) { _freqToFreqList[freq] = std::make_shared<FreqList<Key, Value>>(freq); } _freqToFreqList[freq]->addNode(node); } //增加平均访问等频率 void addFreqNum() { _curTotalNum++; if(_nodeMap.empty()) _curAverageNum = 0; else _curAverageNum = _curTotalNum / _nodeMap.size(); //如果当前平均访问次数超过最大平均访问次数,则需要处理 if(_curAverageNum > _maxAverageNum) handleOverMaxAverageNum(); } //减少平均访问等频率 void decreaseFreqNum(int num) { _curTotalNum -= num; if(_nodeMap.empty()) _curAverageNum = 0; else _curAverageNum = _curTotalNum / _nodeMap.size(); } //处理超过最大平均访问次数 void handleOverMaxAverageNum() { if(_nodeMap.empty()) return; int cnt = 0; for(auto it = _nodeMap.begin(); it != _nodeMap.end(); ++it) { //判断节点是否存在 if(!it->second) { _nodeMap.erase(it); continue; } ++cnt; NodePtr node = it->second; removeFromFreqList(node); node->freq -= _maxAverageNum / 2; if(node->freq < 1) node->freq = 1; addToFreqList(node); } _curTotalNum -= (_maxAverageNum / 2) * cnt; _curAverageNum = _curTotalNum / cnt; updateMinFreq(); } //更新最小访问频率 void updateMinFreq() { _minFreq = INT_MAX; for(const auto &freqList : _freqToFreqList) { if(freqList.second && !freqList.second->isEmpty()) _minFreq = std::min(_minFreq, freqList.first); } if(_minFreq == INT_MAX) _minFreq = 1; } public: LFUCache(int capacity, int maxAverageNum = 10) : _capacity(capacity), _minFreq(INT_MAX), _maxAverageNum(maxAverageNum), _curAverageNum(0), _curTotalNum(0) {} ~LFUCache() override = default; void put(Key key, Value value) override { if(_capacity == 0) return; std::lock_guard<std::mutex> lock(_mutex); auto it = _nodeMap.find(key); if(it != _nodeMap.end()) { it->second->value = value; getInternal(it->second, value); return; } putInternal(key, value); } bool get(Key key, Value &value) override { std::lock_guard<std::mutex> lock(_mutex); auto it = _nodeMap.find(key); if(it != _nodeMap.end()) { getInternal(it->second, value); return true; } return false; } Value get(Key key) override { Value value; get(key, value); return value; } // 清空缓存,回收资源 void purge() { _nodeMap.clear(); //资源泄漏问题?-- 改用智能指针 _freqToFreqList.clear(); } private: int _capacity; // 缓存容量 int _minFreq; // 最小访问频率,用于找最少访问频率的节点链表 int _maxAverageNum; // 最大平均访问次数 int _curAverageNum; // 当前最大平均访问次数 int _curTotalNum; // 当前总访问次数 std::mutex _mutex; // 互斥锁 NodeMap _nodeMap; // key-node*映射 //std::unordered_map<int, FreqList<Key, Value>*> _freqToFreqList; // 访问频率与链表映射--这个版本会内存泄漏,改用智能指针 std::unordered_map<int, std::shared_ptr<FreqList<Key, Value>>> _freqToFreqList; // 访问频率与链表映射 }; } #endifHashLFUCache
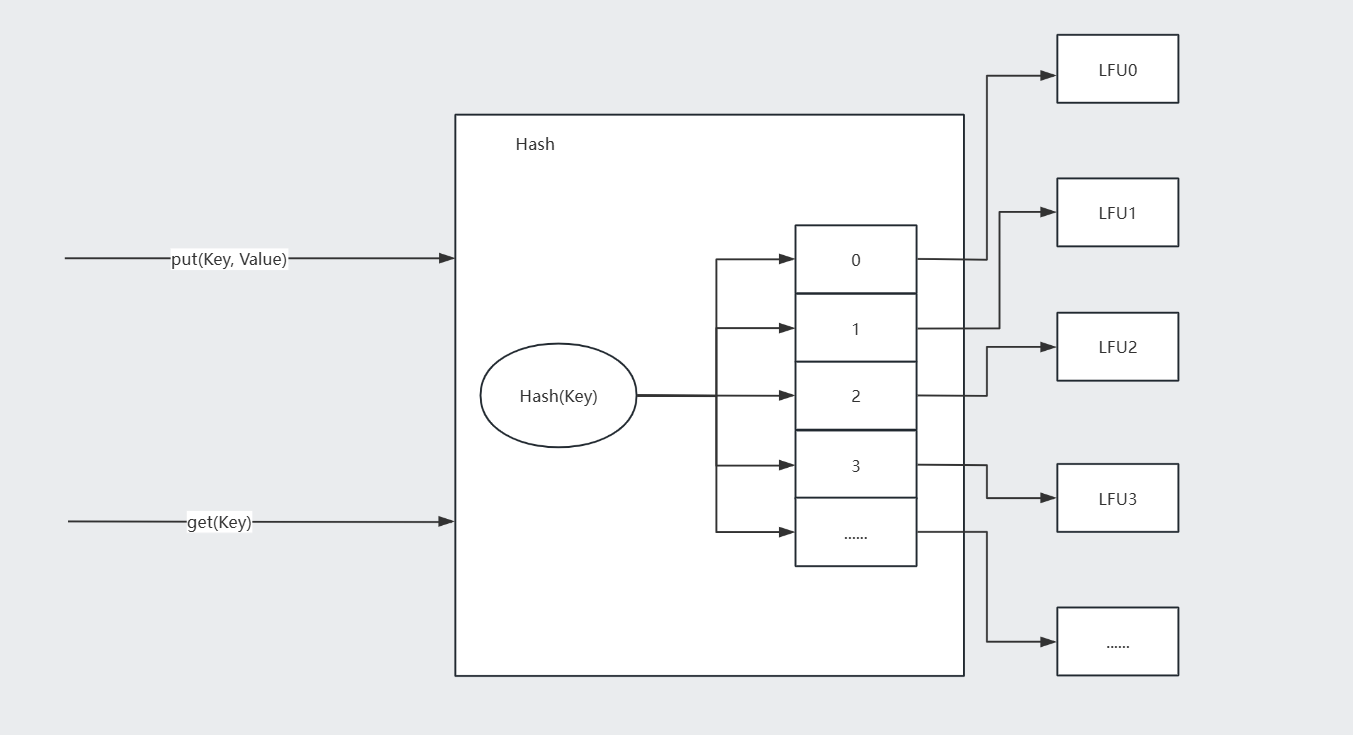
上面实现的LFU与LRU初期存在同样的问题,就是锁的粒度比较大,难以直接细化,涉及线程安全的环节过多,连读写锁都无法有效优化;所以采用LFU分片的方案:
直接组合上面写的LFU,通过Hash分配对应的LFU对象。
cpp//HashLFUCache.hpp #ifndef __HASHLFUCACHE_HPP__ #define __HASHLFUCACHE_HPP__ #include <iostream> #include <memory> #include <unordered_map> #include <mutex> #include <climits> #include <vector> #include <thread> #include <cmath> #include "LFUCache.hpp" namespace myCache { template <class Key, class Value> class HashLFUCache { private: size_t Hash(Key key) { std::hash<Key> hashFunc; return hashFunc(key); } public: HashLFUCache(size_t capacity, int sliceNum, int maxAverageNum = 10) //std::thread::hardware_concurrency()返回当前系统支持的并发线程数(即硬件线程数)的估计值。 :_sliceNum(sliceNum > 0 ? sliceNum : std::thread::hardware_concurrency()), _capacity(capacity) { size_t sliceSize = std::ceil(_capacity / static_cast<double>(_sliceNum)); for(int i = 0; i < _sliceNum; i++) { _LFUSliceCaches.emplace_back(std::make_unique<LFUCache<Key, Value>>(sliceSize, maxAverageNum)); } } void put(Key key, Value value) { size_t sliceIndex = Hash(key) % _sliceNum; _LFUSliceCaches[sliceIndex]->put(key, value); } bool get(Key key, Value& value) { size_t sliceIndex = Hash(key) % _sliceNum; return _LFUSliceCaches[sliceIndex]->get(key, value); } Value get(Key key) { Value value; get(key, value); return value; } void purge() { for(auto& cache : _LFUSliceCaches) { cache->purge(); } } private: size_t _capacity; //缓存容量 int _sliceNum; //切片鼠粮 std::vector<std::unique_ptr<LFUCache<Key, Value>>> _LFUSliceCaches; //切片LFU缓存 }; } #endif
ARC(Adaptive Replacement Cache 自适应缓存替换)
LRU和LFU的缺点分析
LRU算法存在以下局限性:仅记录访问顺序难以有效保留高频访问数据,尤其在突发新数据大量访问时,可能导致近期高频数据被意外淘汰。
LFU算法的主要问题在于:当数据出现短期访问激增后,即便后续访问频率骤降,仍会长期占据缓存空间,从而影响新数据的缓存效率,造成缓存污染问题。
为了能同时应对这两种情况,这时就有了ARC算法。
ARC算法思想
核心思想:ARC结合了LRU和LFU,当数据访问模式偏向于最近访问的内容 时,命中LRU列表的概率会增大 ,从而扩大LRU的空间占比 ;反之,当访问模式倾向于频繁访问 的内容时,LFU列表的命中率会提高 ,导致LFU空间相应增加。
应用场景:该系统特别适合混合访问模式(如近期频繁访问和周期性访问交替出现)的场景,能够通过动态调整缓存分区大小来优化性能表现。
特点:
- 自适应性:
ARC动态调整两个缓存区域的大小:最近使用的元素 和 频繁访问的元素。
根据访问模式自动调整策略,适应不同的工作负载。- 缓存分区:
LRU-like区域:处理新进入的访问数据(类似最近最少使用,LRU)
LFU-like区域:处理频繁访问的数据。(类似LFU)- 避免缓存污染:
ARC在不同的访问模式(如频繁访问与一次性访问)之间表现较好,因为它可以动态调整缓存分区的大小。- 命中率高:
在混合访问模式下,ARC通常能够提供比单一策略更高的缓存命中率。- 解决了LRU的循环缓存问题(缓存抖动),解决了LFU的冷启动问题
缺点:
- 实现复杂度高,维护多种数据结构可能增加CPU开销。
- 在工作负载高度一致(如完全频繁访问)时,优势不明显。
ARC算法实现
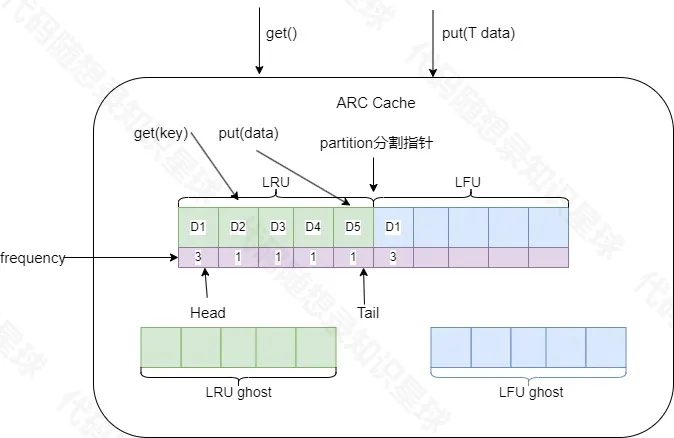
该缓存系统由LRU和LFU两部分组成。系统会根据实际访问模式动态调整分区指针位置(partition),从而灵活调节LRU和LFU的容量占比。此外,LRU和LFU模块各自维护一个淘汰链表(ghost list),用于记录被淘汰的数据项。整体架构如下图所示:
更加详细结构流程图如下:(ps:
ARCCache对象的get方法和put方法实际上调用的是LRU和LFU的get与put方法。frequency指的是该数据的访问频率。)
在缓存中查找需要访问的数据,如果没有命中,表示缓存击穿,将需要访问的数据从磁盘中取出,插入缓存中的
LRU部分对应链表的尾部(ps:头插和尾插没有区别,看个人习惯)。如果命中(LRU部分存在该数据)且LFU链表中没有则判断该数据的访问次数是否大于
transformTime_(自定义的变量,我这里设置为3,代表访问次数超过3次),若大于则将该数据插入LFU对应链表中(一个块至少需要读取transformTime_次,并且要是最近请求的数据,才会被存储到LFU中)。于是,该数据块不仅仅只保存在LRU的缓存目录中,也将保存到LFU中。如果命中且LFU链表中存在,则将数据重新放入LFU链表中对应位置(访问频次计数+1),这样,那些真正被频繁访问的页面将一直呆在缓存中,不会被冷数据的加入而误淘汰,不经常访问的数据会向链表头部移动,最终被淘汰出去。
如果此时
LRU缓存满了,则从LRU链表中淘汰表头部的数据,将淘汰数据的key放入LRU对应的ghost list。然后在LRU的链表尾部添加新数据。如果ghost list的元素满了,按照先进先出的方式淘汰ghost list中的元素头部元素,然后再从尾部插入元素。如未命中缓存的数据根据key发现在LRU对应的
ghost list中,则表示幽灵命中,缓存系统就可以知道,这是一个刚刚淘汰的页面,而不是第一次读取或者说很久之前读取的一个页面。于是根据这个信息来调整内部的partition分割指针以适应当下的访问模式。上述迹象说明当前的LRU缓存太小了,于是将partition分割指针右移一位(也就是LRU缓存空间+1,LFU缓存空间-1),并将命中的key数据从ghost的中移除,将新数据从LRU链表尾部插入。反之如果未命中缓存的数据根据key发现在LFU对应的ghost中,则说明当前访问模式偏向于频繁访问经常被访问的那一些数据,说明当下LFU缓存空间太小了,对应
partition分割指针左移一位,并将命中的key数据从ghost的中移除,将新数据从LRU链表尾部插入。代码实现:
cpp//CachePolicy.hpp #ifndef __CACHEPOLICY_HPP__ #define __CACHEPOLICY_HPP__ #include <iostream> #include <memory> #include <unordered_map> #include <mutex> namespace myCache { template <class Key, class Value> class CachePolicy { public: virtual ~CachePolicy() {}; // 添加缓存接口 virtual void put(Key key, Value value) = 0; // key是传入参数 访问到的值以传出参数的形式返回 | 访问成功返回true virtual bool get(Key key, Value& value) = 0; // 如果缓存中能找到key,则直接返回value virtual Value get(Key key) = 0; }; } #endif
cpp//ArcCacheNode.hpp #ifndef __ARC_CACHE_NODE_HPP__ #define __ARC_CACHE_NODE_HPP__ #include <memory> namespace myCache { template<class Key, class Value> class ArcNode { template<class K, class V> friend class ArcLruPart; template<class K, class V> friend class ArcLfuPart; private: Key _key; Value _value; size_t _accessCount; std::weak_ptr<ArcNode> _prev; std::shared_ptr<ArcNode> _next; public: ArcNode() :_accessCount(1), _next(nullptr) {} ArcNode(Key key, Value value) :_key(key), _value(value), _accessCount(1), _next(nullptr) {} Key getKey() const { return _key; } Value getValue() const { return _value; } size_t getAccessCount() const { return _accessCount; } void setValue(const Value& value) { _value = value; } void incrementAccessCount() { _accessCount++; } }; } #endif
cpp//ArcLruPart.hpp #ifndef __ARCLRU_PART_HPP__ #define __ARCLRU_PART_HPP__ #include <iostream> #include <memory> #include <vector> #include <unordered_map> #include <mutex> #include "ArcCacheNode.hpp" namespace myCache { template<class Key, class Value> class ArcLruPart { public: typedef ArcNode<Key, Value> NodeType; typedef std::shared_ptr<NodeType> NodePtr; typedef std::unordered_map<Key, NodePtr> NodeMap; private: //用于插入时,更新已经存在的节点 bool updateExistingNode(NodePtr node, const Value& value) { node->setValue(value); moveToFront(node); return true; } //添加新节点 bool addNewNode(const Key& key, const Value& value) { if(_mainCache.size() >= _capacity) { //驱逐最近最少访问 evictLeastRecent(); } NodePtr newNode = std::make_shared<NodeType>(key, value); _mainCache[key] = newNode; addToFront(newNode); return true; } //用于获取节点时,更新节点 bool updateNodeAccess(NodePtr node) { moveToFront(node); node->incrementAccessCount(); return node->getAccessCount() >= _transformThreshold; } //添加到头部 void moveToFront(NodePtr node) { if(!node->_prev.expired() && node->_next) { auto prev = node->_prev.lock(); prev->_next = node->_next; node->_next->_prev = prev; node->_next = nullptr; //清空,防止悬空引用 } //添加到头部 addToFront(node); } //添加到头部 void addToFront(NodePtr node) { node->_next = _mainHead->_next; node->_prev = _mainHead; _mainHead->_next->_prev = node; _mainHead->_next = node; } //移除最近最少使用节点 void evictLeastRecent() { NodePtr leastRecent = _mainTail->_prev.lock(); if(!leastRecent || leastRecent == _mainHead) return; //从主链表移除 removeFromMain(leastRecent); //添加到淘汰链表 if(_ghostCache.size() >= _ghostCapacity) { //驱逐淘汰链表最近最少访问 removeOldestGhost(); } addToGhost(leastRecent); //从主缓存映射中移除 _mainCache.erase(leastRecent->getKey()); } //从主链表移除节点 void removeFromMain(NodePtr node) { if(!node->_prev.expired() && node->_next) { auto prev = node->_prev.lock(); prev->_next = node->_next; node->_next->_prev = prev; node->_next = nullptr; //清空,防止悬空引用 } } //从淘汰链表移除节点 void removeFromGhost(NodePtr node) { if(!node->_prev.expired() && node->_next) { auto prev = node->_prev.lock(); prev->_next = node->_next; node->_next->_prev = prev; node->_next = nullptr; //清空,防止悬空引用 } } //添加节点到淘汰链表 void addToGhost(NodePtr node) { //重置节点的访问计数 node->_accessCount = 1; //添加到淘汰节点的头部 node->_next = _ghostHead->_next; node->_prev = _ghostHead; _ghostHead->_next->_prev = node; _ghostHead->_next = node; //添加到淘汰缓存映射中 _ghostCache[node->getKey()] = node; } //驱逐淘汰链表最近最少访问 void removeOldestGhost() { NodePtr leastRecent = _ghostTail->_prev.lock(); if(!leastRecent || leastRecent == _ghostHead) return; //从淘汰链表移除 removeFromGhost(leastRecent); //从淘汰缓存映射中移除 _ghostCache.erase(leastRecent->getKey()); } public: explicit ArcLruPart(size_t capacity, size_t transfromThreshold) :_capacity(capacity), _ghostCapacity(capacity), _transformThreshold(transfromThreshold), _mainHead(std::make_shared<NodeType>()), _mainTail(std::make_shared<NodeType>()), _ghostHead(std::make_shared<NodeType>()), _ghostTail(std::make_shared<NodeType>()) { _mainHead->_next = _mainTail; _mainTail->_prev = _mainHead; _ghostHead->_next = _ghostTail; _ghostTail->_prev = _ghostHead; } //增加节点,返回值bool表示是否需要转换成lfu bool put(Key key, Value value) { if(_capacity == 0) return false; std::lock_guard<std::mutex> lock(_mutex); auto it = _mainCache.find(key); if(it != _mainCache.end()) { return updateExistingNode(it->second, value); } return addNewNode(key, value); } //获取节点--返回值bool表示是否成功获取,shouldTransform表示是否需要转换成lfu bool get(Key key, Value& value, bool& shouldTransform) { std::lock_guard<std::mutex> lock(_mutex); auto it = _mainCache.find(key); if(it != _mainCache.end()) { shouldTransform = updateNodeAccess(it->second); value = it->second->getValue(); return true; } return false; } //检查淘汰链表是否存在该节点,存在在淘汰链表移除节点并返回true,否则返回false bool checkGhost(Key key) { auto it = _ghostCache.find(key); if(it != _ghostCache.end()) { removeFromGhost(it->second); _ghostCache.erase(it); return true; } return false; } //增大容量 void increaseCapacity() { ++_capacity; } //缩小容量 bool decreaseCapacity() { if(_capacity <= 0) { _capacity = 0; return false; } if(_mainCache.size() == _capacity) { //驱逐最近最少访问 evictLeastRecent(); } --_capacity; return true; } private: size_t _capacity; //lru容量 size_t _ghostCapacity; //淘汰容量 size_t _transformThreshold; //lru转换成lfu门槛 std::mutex _mutex; //支持O(1)查找 NodeMap _mainCache; //key 与 node*映射,lru NodeMap _ghostCache; //key 与 node*映射,淘汰 //主链表,支持O(1)增删 NodePtr _mainHead; //lru头 NodePtr _mainTail; //lru尾 //淘汰链表,支持O(1)增删 NodePtr _ghostHead; //淘汰头 NodePtr _ghostTail; //淘汰尾 }; } #endif
cpp//ArcLfuPart.hpp #ifndef __ARC_LFU_PART_HPP__ #define __ARC_LFU_PART_HPP__ #include <iostream> #include <unordered_map> #include <map> #include <memory> #include <vector> #include <list> #include <mutex> #include "ArcCacheNode.hpp" namespace myCache { template <class Key, class Value> class ArcLfuPart { public: typedef ArcNode<Key, Value> NodeType; typedef std::shared_ptr<NodeType> NodePtr; typedef std::unordered_map<Key, NodePtr> NodeMap; typedef std::map<size_t, std::list<NodePtr>> FreqMap; private: bool updateExistingNode(NodePtr node, const Value& value) { node->setValue(value); updateNodeFrequency(node); return true; } bool addNewNode(const Key& key, const Value& value) { if(_mainCache.size() >= _capacity) { //驱逐最近最少访问 evictLeastFrequent(); } NodePtr newNode = std::make_shared<NodeType>(key, value); _mainCache[key] = newNode; if(_freqMap.find(1) == _freqMap.end()) { _freqMap[1] = std::list<NodePtr>(); } _freqMap[1].push_front(newNode); _minFreq = 1; return true; } void updateNodeFrequency(NodePtr node) { size_t oldFreq = node->getAccessCount(); node->incrementAccessCount(); size_t newFreq = node->getAccessCount(); //从原先的链表移除 auto &oldList = _freqMap[oldFreq]; oldList.remove(node); //移除后判断是否为空 if(oldList.empty()) { _freqMap.erase(oldFreq); if(oldFreq == _minFreq) { _minFreq = newFreq; } } //添加到新频率列表 if(_freqMap.find(newFreq) == _freqMap.end()) { _freqMap[newFreq] = std::list<NodePtr>(); } _freqMap[newFreq].push_back(node); } //驱逐最少访问频率节点 void evictLeastFrequent() { if(_freqMap.empty()) return; auto &minFreqList = _freqMap[_minFreq]; if(minFreqList.empty()) return; NodePtr leastNode = minFreqList.front(); minFreqList.pop_front(); if(minFreqList.empty()) { _freqMap.erase(_minFreq); if(!_freqMap.empty()) { //unordered_map 自动排序,第一个元素就是最小频率 _minFreq = _freqMap.begin()->first; } } //节点添加到幽灵缓存 if(_ghostCache.size() >= _ghostCapacity) { removeOldestGhost(); } addToGhost(leastNode); //从主缓存中移除 _mainCache.erase(leastNode->getKey()); } void removeFromGhost(NodePtr node) { if(!node->_prev.expired() && node->_next) { auto prev = node->_prev.lock(); prev->_next = node->_next; node->_next->_prev = prev; node->_next = nullptr; } } void addToGhost(NodePtr node) { node->_next = _ghostTail; node->_prev = _ghostTail->_prev; if(!_ghostTail->_prev.expired()) { _ghostTail->_prev.lock()->_next = node; } _ghostTail->_prev = node; _ghostCache[node->getKey()] = node; } void removeOldestGhost() { NodePtr oldestGhost = _ghostHead->_next; if(oldestGhost != _ghostTail) { removeFromGhost(oldestGhost); _ghostCache.erase(oldestGhost->getKey()); } } public: explicit ArcLfuPart(size_t capacity, size_t transformThreshold) :_capacity(capacity), _ghostCapacity(capacity), _transformThreshold(transformThreshold), _minFreq(0), _ghostHead(std::make_shared<NodeType>()), _ghostTail(std::make_shared<NodeType>()) { _ghostHead->_next = _ghostTail; _ghostTail->_prev = _ghostHead; } bool put(Key key, Value value) { if(_capacity == 0) return false; std::lock_guard<std::mutex> lock(_mutex); auto it = _mainCache.find(key); if(it != _mainCache.end()) { return updateExistingNode(it->second, value); } return addNewNode(key, value); } bool get(Key key, Value& value) { std::lock_guard<std::mutex> lock(_mutex); auto it = _mainCache.find(key); if(it != _mainCache.end()) { updateNodeFrequency(it->second); value = it->second->getValue(); return true; } return false; } //判断是否包含key bool contain(Key key) { return _mainCache.find(key) != _mainCache.end(); } //检查是否在幽灵缓存中 bool checkGhost(Key key) { auto it = _ghostCache.find(key); if(it != _ghostCache.end()) { removeFromGhost(it->second); _ghostCache.erase(it); return true; } return false; } //增加容量 void increaseCapacity() { _capacity++; } //减少容量 bool decreaseCapacity() { if(_capacity <= 0) { _capacity = 0; return false; } if(_mainCache.size() == _capacity) { evictLeastFrequent(); } --_capacity; return true; } private: size_t _capacity; size_t _ghostCapacity; size_t _transformThreshold; size_t _minFreq; std::mutex _mutex; NodeMap _mainCache; NodeMap _ghostCache; FreqMap _freqMap; NodePtr _ghostHead; NodePtr _ghostTail; }; } #endif
cpp//ArcCache.hpp #ifndef __ARC_CACHE_HPP__ #define __ARC_CACHE_HPP__ #include <iostream> #include <memory> #include "ArcLruPart.hpp" #include "ArcLfuPart.hpp" #include "CachePolicy.hpp" namespace myCache { template<class Key, class Value> class ArcCache : public CachePolicy<Key,Value> { private: bool checkGhostCaches(Key key) { bool inGhost = false; if(_lruPart->checkGhost(key)) { if(_lfuPart->decreaseCapacity()) { _lruPart->increaseCapacity(); } inGhost = true; } else if(_lfuPart->checkGhost(key)) { if(_lruPart->decreaseCapacity()) { _lfuPart->increaseCapacity(); } inGhost = true; } return inGhost; } public: explicit ArcCache(size_t capacity = 10, size_t transformThreshold = 2) :_capacity(capacity), _transformThreshold(transformThreshold), _lruPart(std::make_unique<ArcLruPart<Key, Value>>(capacity, transformThreshold)), _lfuPart(std::make_unique<ArcLfuPart<Key, Value>>(capacity, transformThreshold)) {} ~ArcCache() override = default; void put(Key key, Value value) override { checkGhostCaches(key); //插入lru _lruPart->put(key, value); //判断lfu有没有,有则更新lfu部分 bool inLfu = _lfuPart->contain(key); if(inLfu) { _lfuPart->put(key, value); } } bool get(Key key, Value& value) override { checkGhostCaches(key); bool shouldTransform = false; if(_lruPart->get(key, value, shouldTransform)) { if(shouldTransform) { _lfuPart->put(key, value); } return true; } return _lfuPart->get(key, value); } Value get(Key key) override { Value value{}; get(key, value); return value; } private: size_t _capacity; size_t _transformThreshold; std::unique_ptr<ArcLruPart<Key, Value>> _lruPart; std::unique_ptr<ArcLfuPart<Key, Value>> _lfuPart; }; } #endif
3、测试代码
cpp
#include "../LRU/LRU.hpp"
#include "../LRU/LRUK.hpp"
#include "../LRU/HashLRU.hpp"
#include "../LFU/HashLFUCache.hpp"
#include "../LFU/LFUCache.hpp"
#include "../FIFO/FIFOCache.hpp"
#include "../ARC/ArcCache.hpp"
#include <random>
#include <array>
void printResults(const std::string &testName, int capacity, const std::vector<int> &get_operations, const std::vector<int> &hits)
{
std::cout << "=== " << testName << " ===" << std::endl;
std::cout << "缓存容量:" << capacity << std::endl;
std::cout << "LRU - 命中率:" << ((double)hits[0] / get_operations[0]) * 100 << "%" << " (" << hits[0] << "/" << get_operations[0] << ")" << std::endl;
std::cout << "LFU - 命中率:" << ((double)hits[1] / get_operations[1]) * 100 << "%" << " (" << hits[1] << "/" << get_operations[1] << ")" << std::endl;
std::cout << "ARC - 命中率:" << ((double)hits[2] / get_operations[2]) * 100 << "%" << " (" << hits[2] << "/" << get_operations[2] << ")" << std::endl;
}
void testHotDataAccess()
{
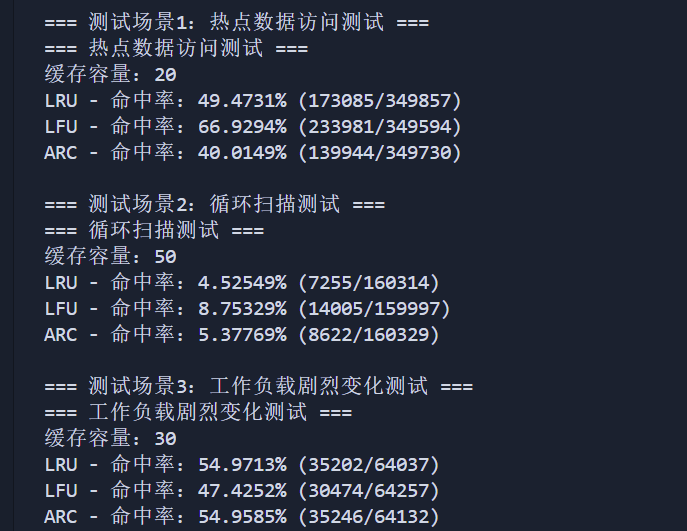
std::cout << "\n=== 测试场景1:热点数据访问测试 ===" << std::endl;
const int CAPACITY = 20; // 缓存容量
const int OPERATIONS = 500000; // 总操作次数
const int HOT_KEYS = 20; // 热点数据数量
const int COLD_KEYS = 5000; // 冷数据数量
myCache::LRUCache<int, std::string> lru(CAPACITY);
myCache::LFUCache<int, std::string> lfu(CAPACITY);
myCache::ArcCache<int, std::string> arc(CAPACITY / 2);
// 生成随机数种子,类似与rand(),但是更优
std::random_device rd;
std::mt19937 gen(rd());
// 基类指针指向派生类对象(多态)
std::array<myCache::CachePolicy<int, std::string> *, 3> caches = {&lru, &lfu, &arc};
std::vector<int> hits(3, 0); // 记录三种策略分别缓存命中次数
std::vector<int> get_operations(3, 0); // 三种策略测试分别get访问缓存总次数
std::vector<std::string> names = {"LRU", "LFU", "ARC"};
// 为所有的缓存对象进行相同的操作序列测试
for (int i = 0; i < caches.size(); ++i)
{
// 先预热缓存,插入一些数据
for (int key = 0; key < HOT_KEYS; ++key)
{
std::string value = "value" + std::to_string(key);
caches[i]->put(key, value);
}
// 交替进行put和get操作,模拟真实场景
for (int op = 0; op < OPERATIONS; ++op)
{
// 大多数缓存系统中读操作比写操作频繁
// 所以设置30%概率进行写操作
bool isPut = (gen() % 100 < 30);
int key;
// 70%概率访问热点数据,30%概率访问冷数据
if (gen() % 100 < 70)
{
key = gen() % HOT_KEYS; // 热点数据
}
else
{
key = HOT_KEYS + (gen() % COLD_KEYS); // 冷数据
}
if (isPut)
{
// 执行put操作
std::string value = "value" + std::to_string(key) + "_v" + std::to_string(op % 100);
caches[i]->put(key, value);
}
else
{
// 执行get操作并记录命中情况
std::string result;
get_operations[i]++;
if (caches[i]->get(key, result))
{
hits[i]++;
}
}
}
}
// 打印测试结果
printResults("热点数据访问测试", CAPACITY, get_operations, hits);
}
void testLoopPattern()
{
std::cout << "\n=== 测试场景2:循环扫描测试 ===" << std::endl;
const int CAPACITY = 50; // 缓存容量
const int LOOP_SIZE = 500; // 循环范围大小
const int OPERATIONS = 200000; // 总操作次数
myCache::LRUCache<int, std::string> lru(CAPACITY);
myCache::LFUCache<int, std::string> lfu(CAPACITY);
myCache::ArcCache<int, std::string> arc(CAPACITY / 2);
std::array<myCache::CachePolicy<int, std::string> *, 3> caches = {&lru, &lfu, &arc};
std::vector<int> hits(3, 0);
std::vector<int> get_operations(3, 0);
std::vector<std::string> names = {"LRU", "LFU", "ARC"};
std::random_device rd;
std::mt19937 gen(rd());
// 为每种缓存算法运行相同的测试
for (int i = 0; i < caches.size(); ++i)
{
// 先预热一部分数据(只加载20%的数据)
for (int key = 0; key < LOOP_SIZE / 5; ++key)
{
std::string value = "loop" + std::to_string(key);
caches[i]->put(key, value);
}
// 设置循环扫描的当前位置
int current_pos = 0;
// 交替进行读写操作,模拟真实场景
for (int op = 0; op < OPERATIONS; ++op)
{
// 20%概率是写操作,80%概率是读操作
bool isPut = (gen() % 100 < 20);
int key;
// 按照不同模式选择键
if (op % 100 < 60)
{ // 60%顺序扫描
key = current_pos;
current_pos = (current_pos + 1) % LOOP_SIZE;
}
else if (op % 100 < 90)
{ // 30%随机跳跃
key = gen() % LOOP_SIZE;
}
else
{ // 10%访问范围外数据
key = LOOP_SIZE + (gen() % LOOP_SIZE);
}
if (isPut)
{
// 执行put操作,更新数据
std::string value = "loop" + std::to_string(key) + "_v" + std::to_string(op % 100);
caches[i]->put(key, value);
}
else
{
// 执行get操作并记录命中情况
std::string result;
get_operations[i]++;
if (caches[i]->get(key, result))
{
hits[i]++;
}
}
}
}
printResults("循环扫描测试", CAPACITY, get_operations, hits);
}
void testWorkloadShift()
{
std::cout << "\n=== 测试场景3:工作负载剧烈变化测试 ===" << std::endl;
const int CAPACITY = 30; // 缓存容量
const int OPERATIONS = 80000; // 总操作次数
const int PHASE_LENGTH = OPERATIONS / 5; // 每个阶段的长度
myCache::LRUCache<int, std::string> lru(CAPACITY);
myCache::LFUCache<int, std::string> lfu(CAPACITY);
myCache::ArcCache<int, std::string> arc(CAPACITY / 2);
std::random_device rd;
std::mt19937 gen(rd());
std::array<myCache::CachePolicy<int, std::string> *, 3> caches = {&lru, &lfu, &arc};
std::vector<int> hits(3, 0);
std::vector<int> get_operations(3, 0);
std::vector<std::string> names = {"LRU", "LFU", "ARC"};
// 为每种缓存算法运行相同的测试
for (int i = 0; i < caches.size(); ++i)
{
// 先预热缓存,只插入少量初始数据
for (int key = 0; key < 30; ++key)
{
std::string value = "init" + std::to_string(key);
caches[i]->put(key, value);
}
// 进行多阶段测试,每个阶段有不同的访问模式
for (int op = 0; op < OPERATIONS; ++op)
{
// 确定当前阶段
int phase = op / PHASE_LENGTH;
// 每个阶段的读写比例不同 - 优化后的比例
int putProbability;
switch (phase)
{
case 0:
putProbability = 15;
break; // 阶段1: 热点访问,15%写入更合理
case 1:
putProbability = 30;
break; // 阶段2: 大范围随机,降低写比例为30%
case 2:
putProbability = 10;
break; // 阶段3: 顺序扫描,10%写入保持不变
case 3:
putProbability = 25;
break; // 阶段4: 局部性随机,微调为25%
case 4:
putProbability = 20;
break; // 阶段5: 混合访问,调整为20%
default:
putProbability = 20;
}
// 确定是读还是写操作
bool isPut = (gen() % 100 < putProbability);
// 根据不同阶段选择不同的访问模式生成key - 优化后的访问范围
int key;
if (op < PHASE_LENGTH)
{ // 阶段1: 热点访问 - 减少热点数量从10到5,使热点更集中
key = gen() % 5;
}
else if (op < PHASE_LENGTH * 2)
{ // 阶段2: 大范围随机 - 范围从1000减小到400,更适合20大小的缓存
key = gen() % 400;
}
else if (op < PHASE_LENGTH * 3)
{ // 阶段3: 顺序扫描 - 保持100个键
key = (op - PHASE_LENGTH * 2) % 100;
}
else if (op < PHASE_LENGTH * 4)
{ // 阶段4: 局部性随机 - 优化局部性区域大小
// 产生5个局部区域,每个区域大小为15个键,与缓存大小20接近但略小
int locality = (op / 800) % 5; // 调整为5个局部区域
key = locality * 15 + (gen() % 15); // 每区域15个键
}
else
{ // 阶段5: 混合访问 - 增加热点访问比例
int r = gen() % 100;
if (r < 40)
{ // 40%概率访问热点(从30%增加)
key = gen() % 5; // 5个热点键
}
else if (r < 70)
{ // 30%概率访问中等范围
key = 5 + (gen() % 45); // 缩小中等范围为50个键
}
else
{ // 30%概率访问大范围(从40%减少)
key = 50 + (gen() % 350); // 大范围也相应缩小
}
}
if (isPut)
{
// 执行写操作
std::string value = "value" + std::to_string(key) + "_p" + std::to_string(phase);
caches[i]->put(key, value);
}
else
{
// 执行读操作并记录命中情况
std::string result;
get_operations[i]++;
if (caches[i]->get(key, result))
{
hits[i]++;
}
}
}
}
printResults("工作负载剧烈变化测试", CAPACITY, get_operations, hits);
}
int main()
{
testHotDataAccess();
testLoopPattern();
testWorkloadShift();
return 0;
}
4、总结
|---------------------------------|-------------------------------------------------------------------------|----------------------------------------------------------|-------------------------------------------------------------------------------|
| 优势 | 缺陷 | 应用场景 |
| LRU(Least Recently Used) | ●实现简单,基于时间的自然访问淘汰策略 ●适合短期热点数据,命中率高 ●易于于其他缓存机制结构结合(如双链表实现) | ●循环缓存问题:对于扫描型访问,可能频繁淘汰热点数据,导致缓存抖动 ●不能很好处理长期热点数据和周期性热点数据 | 适合访问模式稳定、短期热点突出的场景,如: ●web缓存(浏览器页面) ●文件系统缓存(例如内存有限的小型文件系统) ●数据库的缓冲区管理(访问历史稳定) |
| LFU(Least Frequenty Used) | ●更关注访问频率,能够保留长期使用的重要数据。 ●对稳定热点数据的命中率更高 | ●冷启动问题:新数据可能在尚未证明重要性前被淘汰 ●数据频率统计更新有额外的开销 ●不适合访问模式变化频繁的场景 | 适合访问频率稳定、长期热点数据占主导的场景,如: ●热门资源(视频、音乐)的推荐系统缓存 ●机器学习中训练数据的缓存 |
| ARC(Adaptive Replacement Cache) | ●结合LRU和LFU的优点,动态调整策略以适应短期和长期热点。 ●抗抖动能力强,能快速适应缓存 模式的变化。 ●高命中率,适合多样化的访问模式 | ●实现复杂,涉及较多数据结构,开销大 ●动态调整LFU和LRU缓存比例增加了计算成本。 | 适合访问模式多变的场景: ●数据库缓冲区管理 ●文件系统缓存(如ZFS) ●混合型访问模式(扫描+热点)的应用 |