JVM
基本概念
JVM是Java的虚拟机,开发Java的时候,我们通常都需要安装JDK,JDK中就包含了JRE,JRE里就包含了JVM
从Java源码到JVM的运行之中有不可分割的关系:
-
编译阶段:Java的源文件
.java经过javac编译器生成字节码文件.class,并保存到硬盘中 -
类加载阶段:此时JVM开始运行------当程序第一次使用到这个类,比如创建对象、访问静态成员时,JVM的类加载器会再次翻译成 二进制 机器指令
- 将
.class文件读取到内存中 - 经过 "加载------连接------初始化" 三个阶段
- 最后以类对象的结构存储到元空间中
- 将
-
执行阶段:类的信息加载好后,程序中运行需要创建的对象,包括调用的方法栈帧等时候,就会按规则分配在
- 堆
- 栈
- 元数据区
- 程序计数器等
通过上面简单的描述,对JVM有了初步的认识,那上面提到的堆 / 栈 / 元数据区 / 程序计数器等等,这些又是什么?这就关系到JVM的内存划分了。除此之外,我们需要对JVM的三个核心内容有个详细的了解
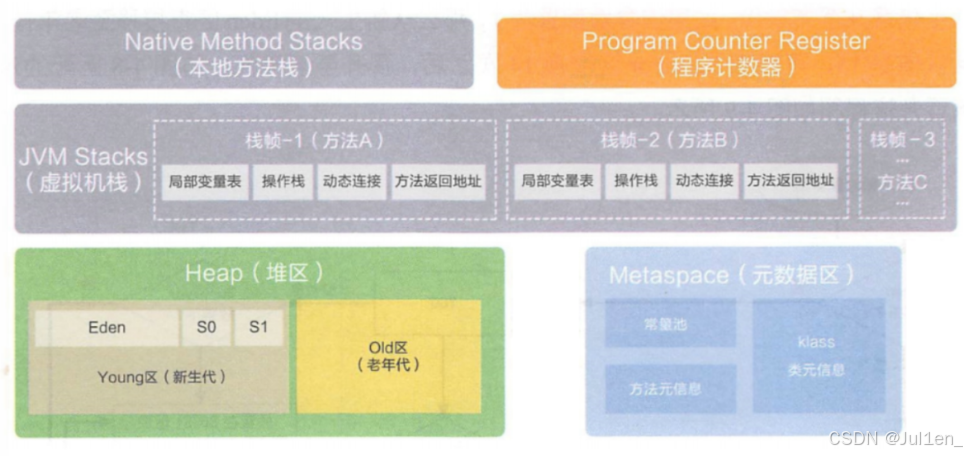
JVM的内存区域划分
每次运行Java程序,内存都是由JVM通过操作系统申请分配的一大块内存,内存中又有不同的模块
进而的,每次运行Java程序,本质上就创建了一个对应的JVM,每个Java进程内部都包含了JVM
内存中主要包含以下核心模块
-
程序计数器
这是一块很小的区域,只保存了一个数字,是下一条要执行的Java字节码指令的地址。通过这个数字Java能顺利执行下一跳
-
栈
🤔这里的栈和包括下面提到的堆跟数据结构的栈和堆不一样! 在计算机中,同一个术语中,可能有不同的含义,所以当面试的时候问道栈和堆,要分清楚是数据结构的还是JVM的还是操作系统的栈和堆。
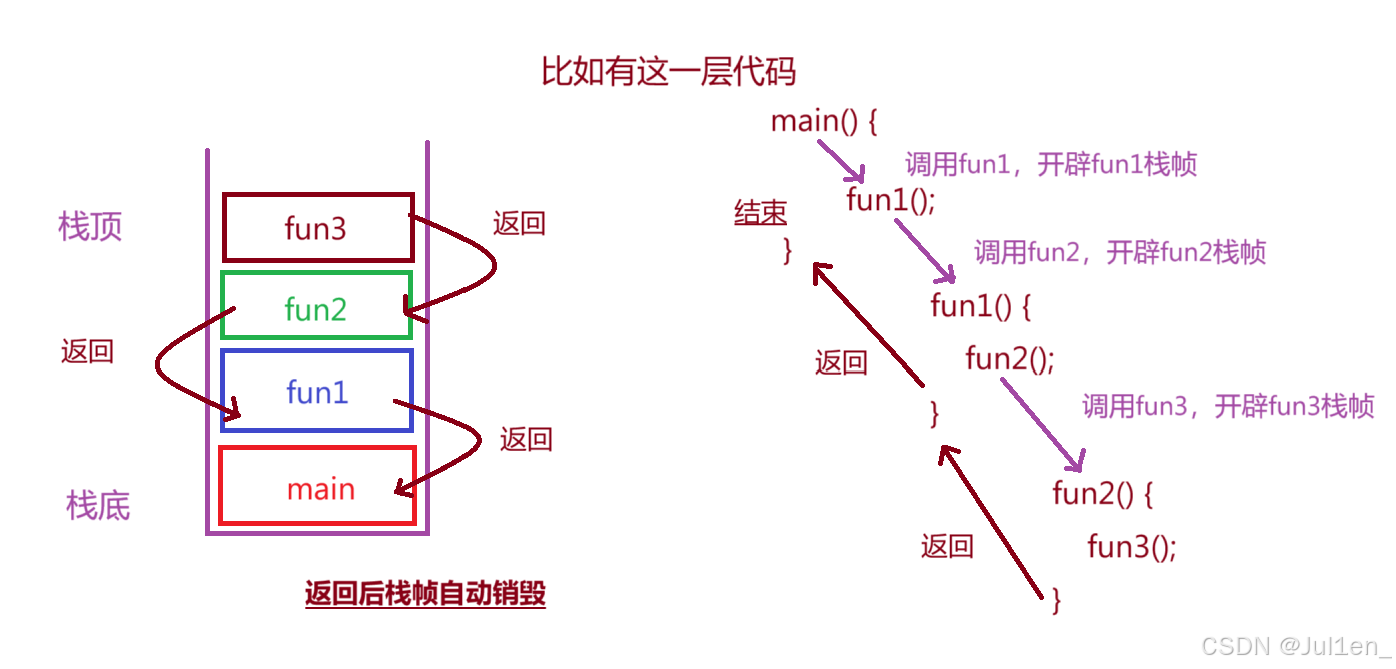
这里的栈也是 "后进先出" 的结构,维护了方法调用的关系,每调用一次方法就开辟一个栈帧,方法执行完就自动消除(底层是main方法------Java的方法入口从main开始)
栈帧里保存了
- 调用方法的实参
- 方法内部的局部变量
- 方法结束后要返回的上层方法的位置
- 返回值等等
JVM的栈分为虚拟机栈和本地方法栈
-
虚拟机栈------给Java程序使用的栈,写的程序基本都在这里
-
本地方法栈------给C++代码使用的,因为JVM的底层是通过C++实现的,Java中写的代码,通过一层一层调用,最终就回到C++的范围了
如在JVM类中的方法,有++native++ 修饰的,就是C++实现的方法

-
堆
这是JVM中最大的区域,主要保存着对象的实例、数组
在运行的过程中,对象随时都有可能在创建和销毁,销毁的过程中也会产生性能消耗。而且有些对象实例存留时间长,有些短,对销毁的机制产生了挑战性。为了缓解这个问题,在堆区分出了新生区和老年区,这点在JVM的垃圾回收中会提到,这里做一个简单的了解
-
元数据区 / 元空间
只存 "类的信息"(Class、方法、常量池、元数据)
💯不会存储具体的数值(比如 "这个类中有个static int x"),但x的值是放到堆里(或者是特定的数据区)
JVM运行时,在需要时会加载
.class文件,并读取到内存中,在这过程中,还需要通过特定的结构来表示,即 "类对象",将类的信息存入元空间如:Class、方法、常量池、元数据在运行过程中:
- 创建对象时,在堆中分配实例
- 调用方法时,在栈中开辟栈帧
- 类对象和静态变量(经static修饰的属性)都常驻元数据区
以上的内存区域,针对程序计数器和栈,都是存在多份的(每一个Java线程都会有自己的程序计数器和栈)
而堆和元数据区只有一份了,一个Java进程中只有一份了,这就能解释为什么在一个线程中new一个对象,是可以被另一个线程直接使用的。
内存溢出问题
有些情况下会导致内存溢出问题,主要分为栈溢出和堆溢出
- 栈溢出:栈帧太多了------比如写递归方法的时候结束条件有错误,导致无限递归,创建了太大的局部变量
- 堆溢出:new的对象太多了,需要排查是在哪个地方哪个对象被创建的太多了
JVM的类加载机制
类加载机制就是描述对**++把++ ** ++.class++ ++文件,读取到内存中,构建出 "类对象"++ 的过程
类加载机制中分为两部分,分别是类加载的流程 与 双亲委派模型(严格意义上其实是单亲,只有一个父亲)
类加载的流程
那什么时候才会加载某个类呢?
此处采用的是 "懒汉" 思想,需要使用的时候才加载,场景有
- new 这个类的实例
- 调用这个类的静态方法 / 访问静态成员
- 针对子类的加载,也会出发父类的加载
💫类加载是单例的,每个类的类对象,在一个JVM进程中,也是单例的
Q:如何理解类加载是单例的?
-
类加载是单例的
当某一个类被使用到的时候,JVM会通过类加载器
ClassLoader去加载.class文件,并创建唯一的类对象(以Class<Test>举例),然后放入元数据区中,描述了这个类的结构信息(方法、字段、常量池等)这个过程只会执行一次,此后不管是多个线程、创建多少个对象、在多少地方用到
Test,都是拿Class<Test>这个类对象复用,只存在一个类元信息对象(Class<Test>这个**++类实例++**)追问:那如果我用多线程
new多几个出来的对象呢,他们的地址一样吗?new操作其实是根据这个唯一的类实例对象作为 "模板",在堆区分配一块实例内存,然后初始化。所以如果使用多线程去new多次对象,每个线程得到的实例对象的地址都不同,但他们的 "类模板" 都来自同一个Class<Test>~
它们之间的关系如表格所示
类加载阶段 实例创建阶段 造出"模具" ( Class<Test>)用模具反复"生产"对象 ( new Test())只有一个 可以有很多 位于方法区 位于堆内存 线程共享 各实例独立 -
每个类的类对象在一个JVM进程中也是单例的
当一个类被加载到JVM中,JVM会给他创建一个对应的
Class对象,放在堆中。这个类对象可以用来- 代表该类的运行时类型信息
- 用来支持反射(如
MyClass.class,obj.getClass())
同一个类加载器加载的同一个类,只对应一个唯一的
Class 对象javaClass<?> c1 = Test.class; Class<?> c2 = new Test().getClass(); System.out.println(c1 == c2); // true ✅
-
加载
就是把
.class文件找到,并且读取文件的数据到内存中 -
验证
根据从文件读到的二进制内容,验证是否为合法的格式,Java有一套
.class文件的结构规范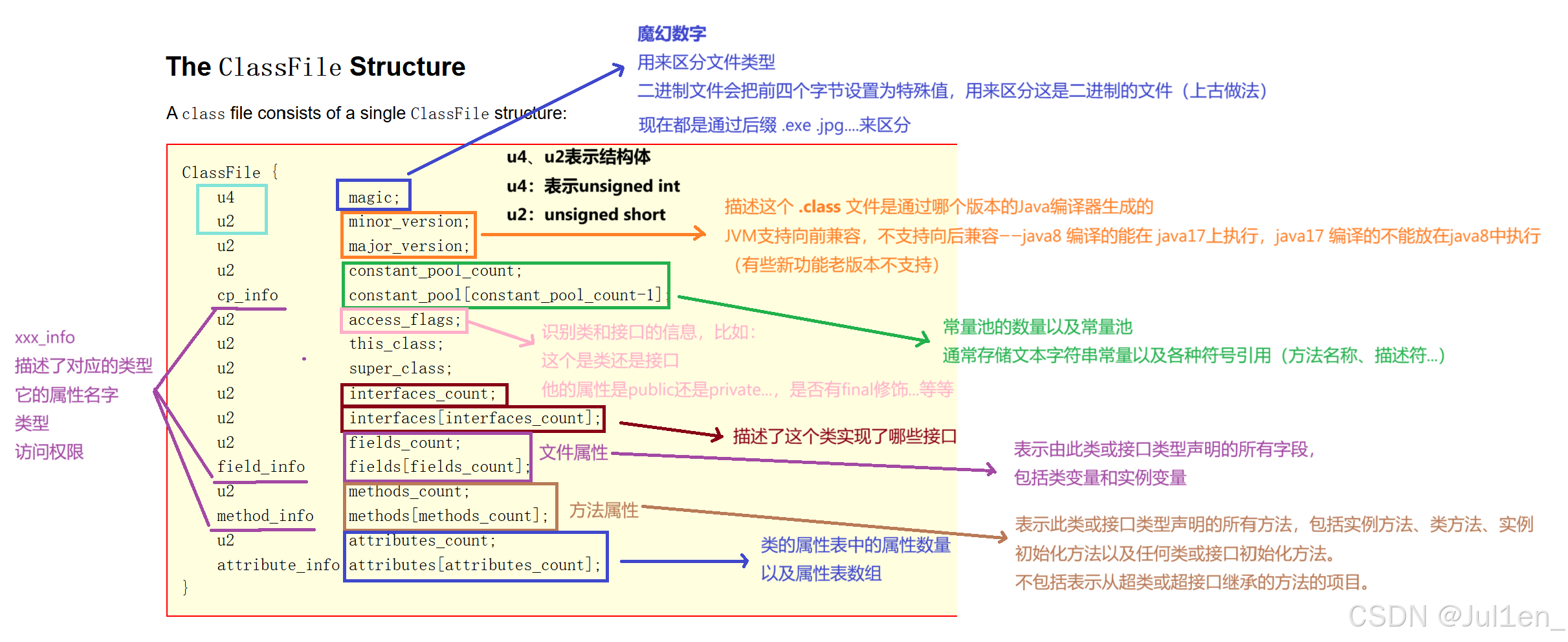
-
准备
给要创建的类对象分配空间。JVM 在加载类时,会在元数据区 中分配存储类元信息的空间,同时在堆 中创建一个代表这个类的
Class对象。Java默认把新申请的未初始化的内存,全部都置为 0(默认初始化)
此时如果尝试获得static成员(因为static成员的结构信息最先被放入元数据区,静态变量比实例变量先初始化),类刚刚加载,还没执行成员的静态初始化的时候,得到的值就是 0
-
字符串常量初始化
针对字符串常量进行初始化,把当前
.class的字符串常量放到内存中。放到内存中,故字符串就有了起始地址。运行时当某个变量引用到这个字符串常量时,就把地址取出来,赋值到对应的变量 -
类对象初始化
针对类对象进行初始化,包括类的静态成员、静态代码块、父类加载等等...
双亲委派模型
双亲委派模型出现在类加载的第一步,用来找.class文件,它涉及到一个模块------ "类加载器"
在JVM中,默认包含了三个类加载器
- BootstrapClassLoader ------ 负责加载 Java 标准库中的类
- ExtensionClassLoader ------ 负责加载 Java 扩展库中的类
- ApplicationClassLoader ------ 负责加载第三方库,以及你当前项目中的

所以优先级是先加载标准库的,其次是扩展库,最后才是第三方库
所以如果自己包装了个java.lang.String类的话,是不会加载你自己的类的,因为同名的String类已经在标准库中加载了,不会执行到 ApplicationClassLoader
JVM的垃圾回收 GC
垃圾回收问题主要是应对内存泄漏的问题
不同的语言针对内存泄漏的问题都有不同的解决方法,像 C++ 引入了智能指针的机制,能一定解决内存泄露的问题( C++ RAII 机制 ) ,但 C++ 为了追求性能极致化,所以是没有引入GC的。而 Java 就专门引入了 垃圾回收 的机制,更好的应对内存泄露
那 Java 主要针对 JVM 的哪一部分回收内存呢?
-
程序计数器吗? 它只记录了一个数字,不需要。栈?内存会随着栈帧的销毁而自动释放,不需要。元数据区?类对象通常只需要加载,不需要卸载,所以也不需要。
-
故 GC 的主战场在堆上,堆上存放的是许多的对象
GC 回收的基本单位是对象,不是以字节为单位。一个对象要么整个释放,要么不释放,不会出现释放一半的情况,所以如果对象有使用一半的情况都不会被释放。
GC 回收一般分为两步
找出谁是垃圾(不再使用的对象)
那判断谁是垃圾对象有两种解决方法
1.
#### 引用计数
它的原理是给每个对象在身上安排一个空间,这个空间存储一个整数,表示这个对象被引用的次数,围绕这个对象进行 "引用 / 复制" 都会更新这个计数,当计数为 0 时,就能释放了。
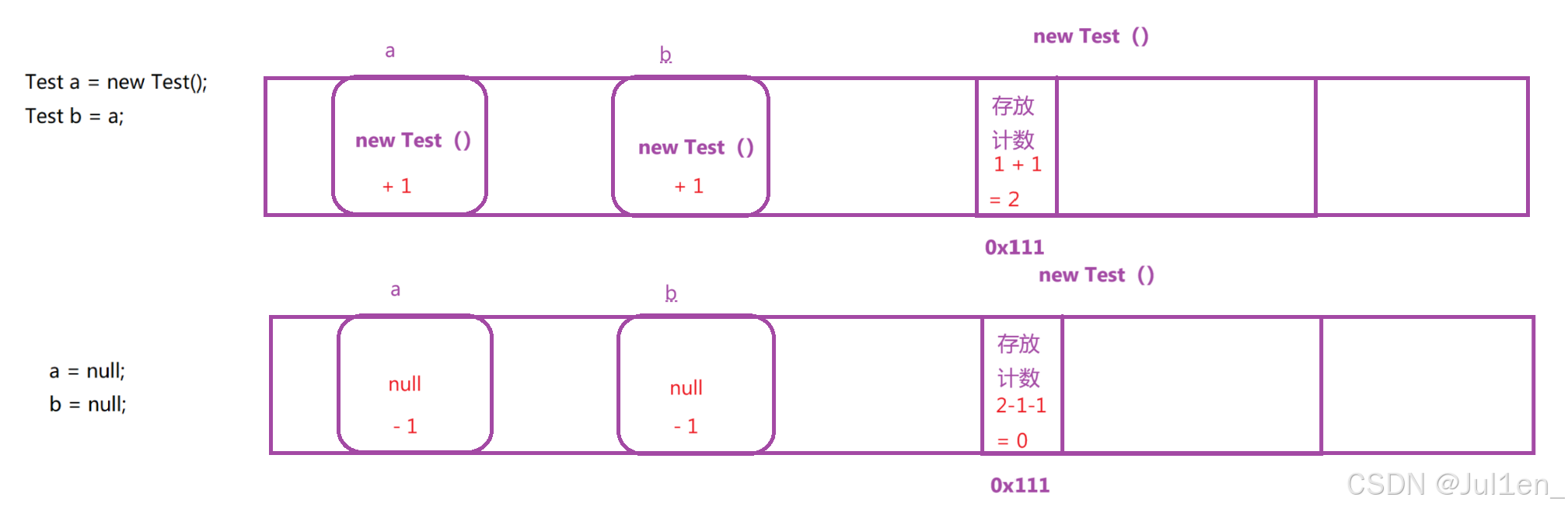
但是引用计数方案也会存在两个缺点
* **消耗更多的内存空间**
🤔Q:有人不理解,开辟一个存储数字的空间也用不到几个字节的空间,为什么就消耗更多的内存空间呢?
A:如果对象很大,那这点小空间确实可以忽略不计。但如果对象本身就很小,只有 4 个字节,如果计数器使用 2 个字节,那就占据了对象的 50% 了,这样的对象数量可能会很多,累积起来就会占据非常多的内存空间。
* **产生循环引用,可能会产生误判**
这个是最重要的,因为垃圾回收是 "宁可放过也不可杀错" ,销毁错了对象后果会非常严重,而循环引用可能就会出现这样的情况
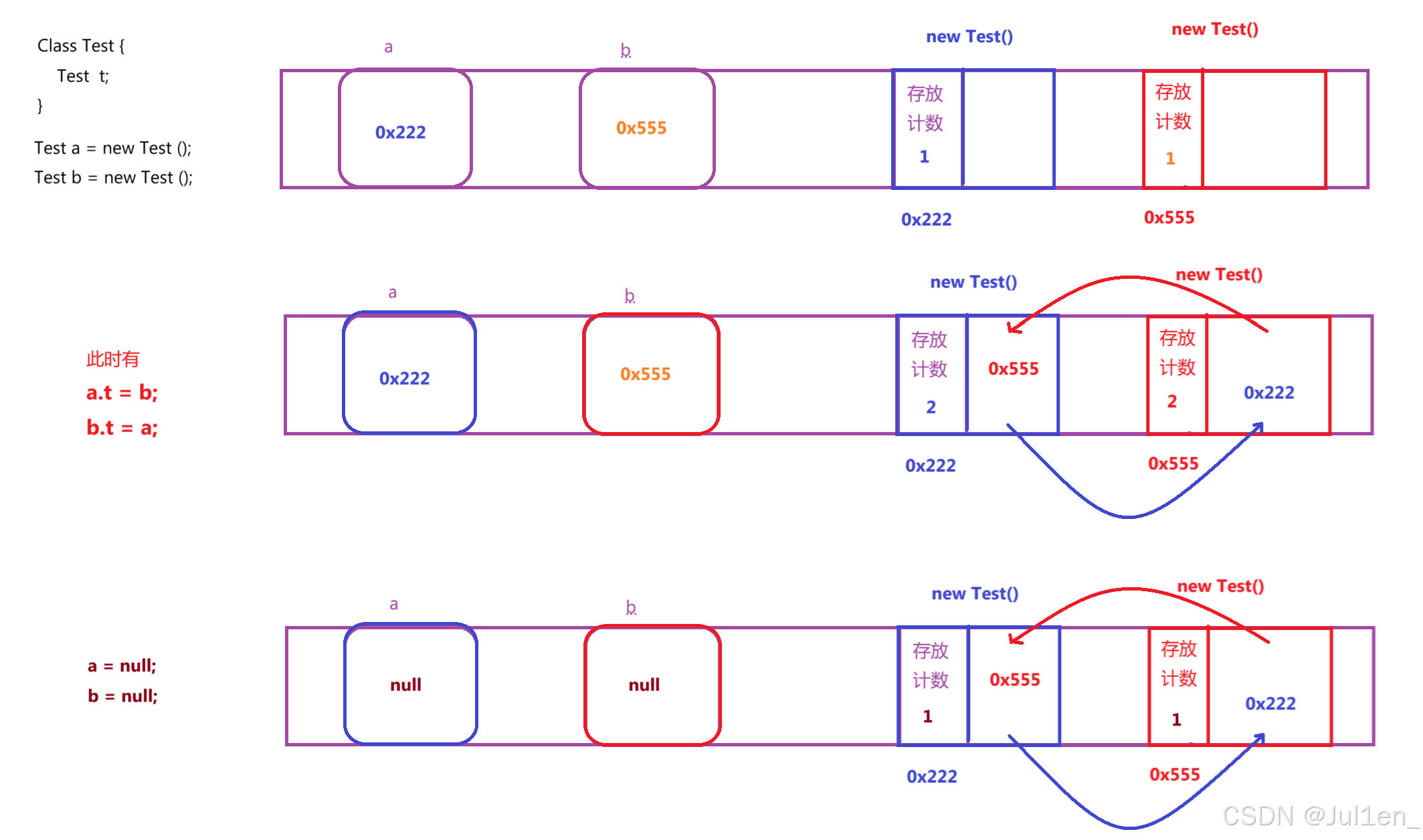
此处这两对象的引用计数都不为 0,都无法释放,但是这两对象都无法被使用了,有点像死锁的感觉。
针对这个问题,Python / PHP 同时也引入了环路检测的机制,识别出上述的循环引用,那有没有其他的方案呢?有的有的! #### 可达性分析
可达性就避免了这种循环引用的问题,它的原理是遍历 "对象树",因为在 Java 代码中,一系列的对象都存在着一定的关联性 =\> 类似于树形的结构。
从树根节点出发,尝试尽可能地遍历这个 "对象树"(可能会有多个),遍历过程中经过了对象都被标记成 "可达",另一方面,JVM 也知道自身有哪些对象,除去这些,剩下的都是 "不可达",就能当作垃圾回收了。
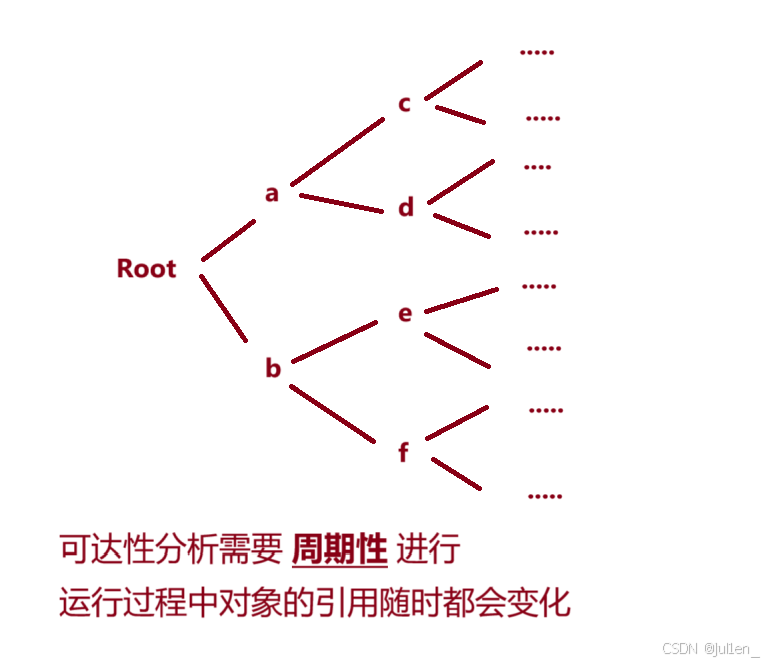
上面说到对象树可能有很多个,Java 中用 GCRoots来表示多个对象树根,它通常指
* 栈上的局部变量
栈有很多个,栈里的栈帧也有很多,栈帧里的局部变量也有很多,每个局部变量都是一个 root
* 常量池引用指向的对象
这里通常有字符串常量、Integer值等,JVM会把 -128 \~ 127 这个范围的数字提前创建好 Integer 对象
* 全部的引用类型的静态成员
内置类型的静态成员不需要,再往下没法引用其他的值了\~
像这样遍历整个树是比较消耗 cpu 的算力的,但是节省了内存空间,属于是 **++时间换空间++**所以通过引用识别 / 可达性分析的方式,从 GCRoots 出发,尽可能遍历,标记可达对象,剩下的就是不可达
2.
释放对应的内存
如何释放内存呢?也有几个方案
1.
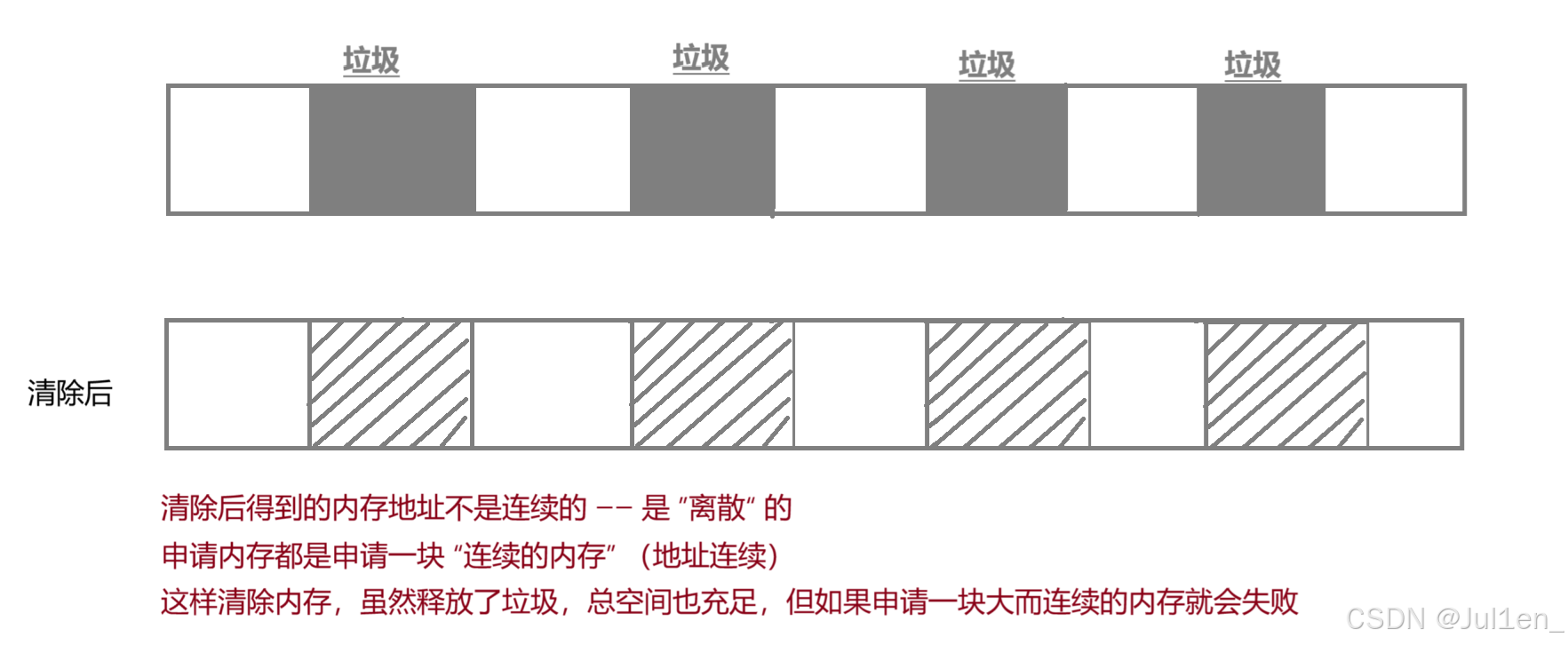
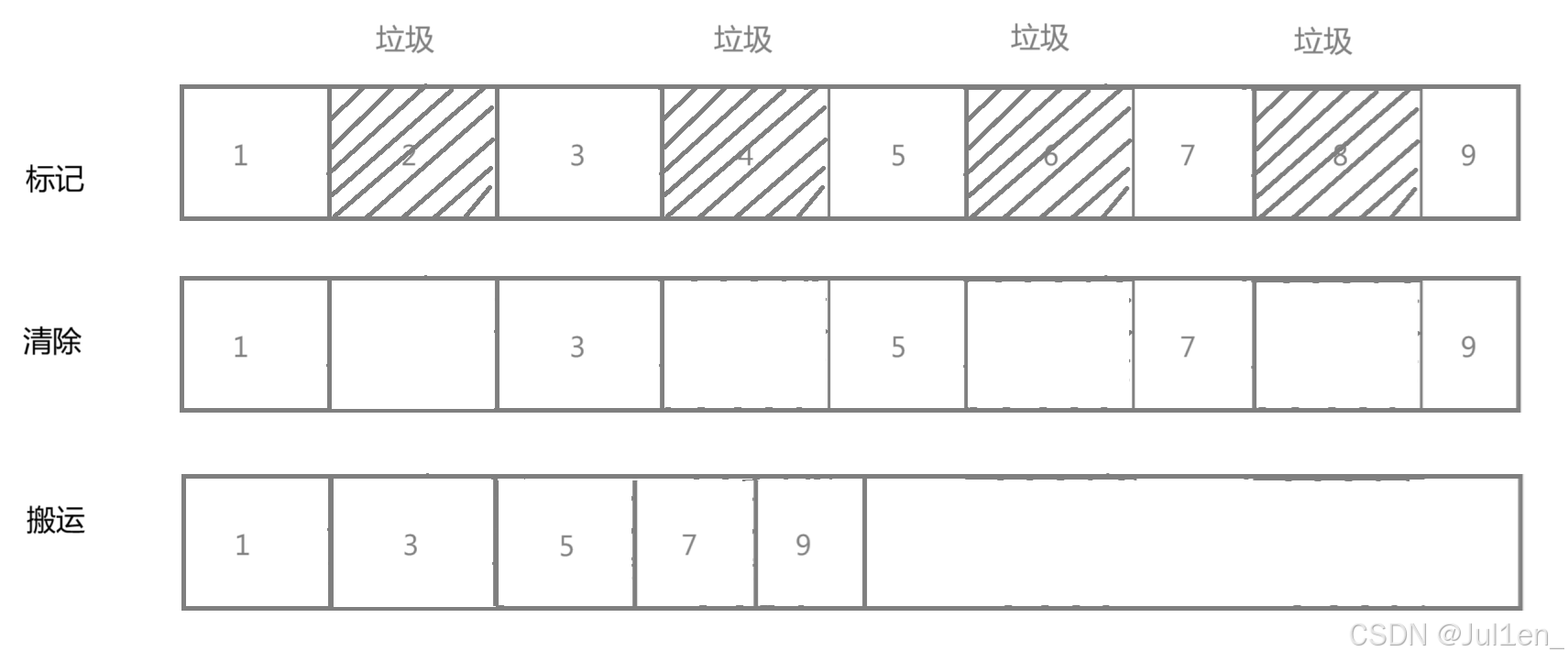
#### 标记清除
把标记出的垃圾直接释放掉,但得到的内存是离散的
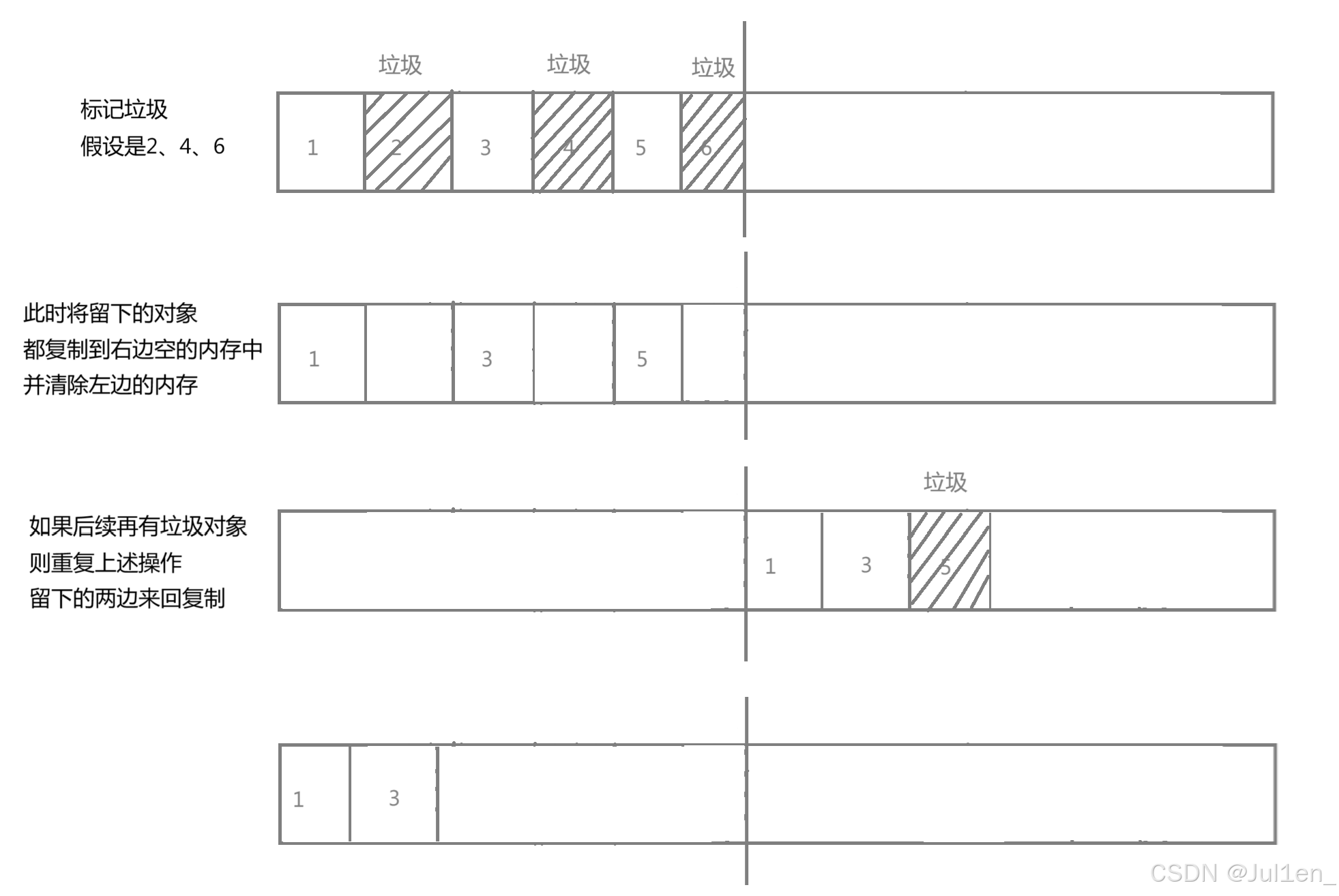
 #### 复制算法
能够有效解决内存碎片化问题,但是空间利用率很低,因为需要开辟相同大小的内存
 #### 标记整理
这种方法虽然能有效解决空间利用率的问题,但是因为需要每次删除后都搬运对象,消耗的资源也很多
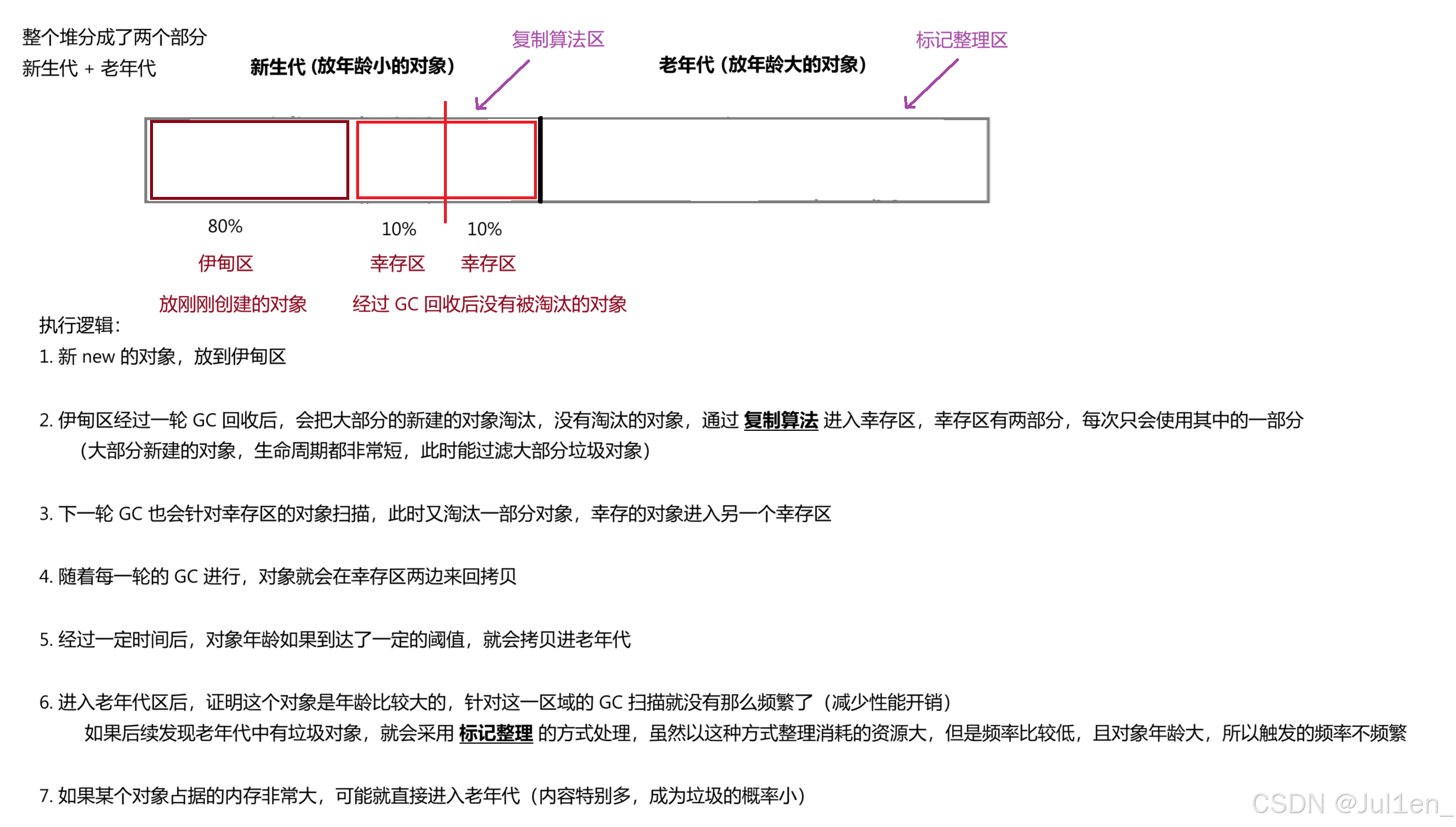
 #### 分代回收
对于 Java 的实际情况来说,是综合了以上的方案,根据不同对象的情况 / 特点,采取不同的方案,这里描述不同对象的情况 / 特点,通常用 "年龄" 来描述,这里的年龄指的是对象 "存活" 的时间。
如果一个对象经过了多轮 GC 扫描都还没有被清除,那就说明这个对象年龄是比较大的。根据规律来看,"年龄" 越大,继续 "存活" 的概率越大。
分代回收是综合了以上三种方案而做出的方案,结构如图所示
以上的分代回收机制严格来说只是一个 "简化版", 代表着一种思想方法,其中还有更加复杂深入的机制。因为 GC 回收不只是考虑效率,有时还需要考虑回收会不会对业务代码有影响。
希望看到这里对你有所帮助,如有错误欢迎指出,祝愿各位身体健康~~(∠・ω< )⌒★