Redis 8 是另一个里程碑式的版本,升级这个版本,即使使用默认的配置参数,即使你的使用是比较简单的场景,也能带来明显的性能提升,甚至是整体内存占用的下降。这篇文章将基于 Redis 的源码实现,分析 Redis 8 的关键性能改进。主要是以下几个方面:
- I/O 线程架构 - Redis 8 多线程 I/O 更完善
- 过期数据结构的优化 - 新的 ebuckets 数据结构
- 内存结构优化 - mstr (m-string) 不可变字符串
1. I/O 线程架构的改进 - Redis 8 多线程 I/O 更完善
1.1. Main 线程与 I/O 线程的限制与区别
Redis 虽然从 Redis 5 开始就说自己引入了多线程机制,但是这个多线程并不是真正意义的多线程,只是做在 I/O 上面的多线程。由于 Redis 本身的数据结构底层的设计,大部分数据结构都没有实现多线程安全的机制,都是单线程操作。但是由于 Redis 本身基本所有数据都位于内存中,没有像数据库那样的外部 I/O 文件需要读取,所以采取无锁无并发同步的数据结构能发挥最大性能与内存性价比。
对于 Redis Server,执行一条命令需要做的事情包括:
- 读取从 Client 发送过来的命令到缓冲区
- 解析缓冲区的命令(RESP 协议)
- 执行命令,读取或者修改数据结构
- 将响应写入缓冲区,从缓冲区将命令写回 Client
最早版本的 Redis,这 4 步都是 Main 线程完成的。但是 Main 线程只有一个,最多只能利用一个 CPU 。老版本 Redis 单个实例能处理并发命令的限制主要来自于这个限制,并且老版本解决这个问题的思路是 Redis-Cluster 集群,将 key 进行分片均摊压力,以及 Redis 主从进行读写分离的优化。后续版本的多线程优化,主要是将这四步尽量多的拆分到 I/O 线程中,但是我们也知道,第三步肯定是拆不出去的。
1.2. Redis 7.x 的多线程 I/O 架构
我们从两个关键配置参数入手:
io-threads:执行 I/O 的线程的数量io-threads-do-reads:是否使用 I/O 线程执行读取(这个在 Redis 8 中已经废弃并且没有作用了)
1.2.1. 默认 io-threads-do-reads = no 的处理流程
整体流程如下:
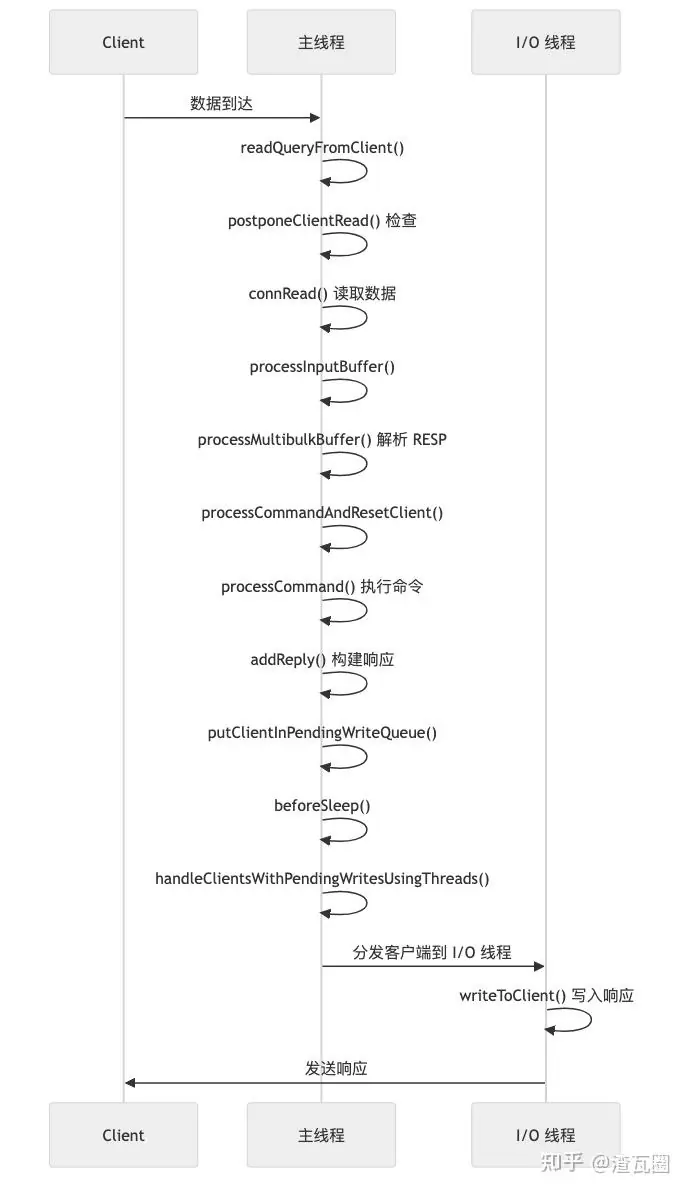
我们来过一下源代码:
1.2.1.1. 客户端数据到达 - readQueryFromClient()
文件位置 : redis-7.x/src/networking.c:2655
ini
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread; size_t qblen, readlen; /* 仅保留关键局部变量 */
/* io-threads-do-reads = no 时:不延期,主线程立刻读取并解析 */
if (postponeClientRead(c)) return; /* reads=yes 时会入队并返回 */
/* 计算本次读取长度并为 querybuf 预留空间(大参数场景会放大) */
/* readlen = PROTO_IOBUF_LEN; ... 处理 big_arg / 扩容策略 ... */
/* qblen = sdslen(c->querybuf); ... sdsMakeRoomFor(NonGreedy) ... */
/* 从 socket 读取数据到 querybuf 尾部 */
nread = connRead(c->conn, c->querybuf + qblen, readlen);
if (nread <= 0) { /* 错误或对端关闭,释放客户端并返回 */
if (nread == 0 || connGetState(conn) != CONN_STATE_CONNECTED) {
freeClientAsync(c);
goto done;
}
return; /* 暂时不可读,稍后重试 */
}
/* 更新 querybuf 长度 / 统计信息等 ... */
/* 同步解析(并可能直接执行命令) */
if (processInputBuffer(c) == C_ERR) c = NULL;
done:
beforeNextClient(c);
}关键点:
- 这是客户端数据到达时的入口函数
- 首先调用
postponeClientRead()检查是否需要延迟读取
1.2.1.2. 检查是否延迟读取 - postponeClientRead()
文件位置 : redis-7.x/src/networking.c:4497
scss
int postponeClientRead(client *c) {
/* 仅当开启 reads 线程且当前空闲时,才把普通客户端入队延迟读取 */
if (server.io_threads_active && server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_BLOCKED)) &&
io_threads_op == IO_THREADS_OP_IDLE) {
listAddNodeHead(server.clients_pending_read, c);
c->pending_read_list_node = listFirst(server.clients_pending_read);
return 1; /* reads=yes: 放到 pending_read,由 I/O 线程读+解码 */
}
return 0; /* reads=no: 直接在主线程读取并解析 */
}关键点:
- 当
io-threads-do-reads = no(默认值)时,server.io_threads_do_reads = 0 - 条件判断失败,直接返回
0,不延迟读取 - 返回
0意味着主线程继续同步处理读取操作
1.2.1.3. 读取数据到缓冲区
文件位置 : redis-7.x/src/networking.c:2667-2737
ini
/* 计算 readlen 并扩容 querybuf(大参数时避免拷贝) */
/* readlen = PROTO_IOBUF_LEN; if (big bulk ...) readlen = remaining; ... */
/* qblen = sdslen(querybuf); sdsMakeRoomFor(NonGreedy) ... */
/* 同步读取到 querybuf 尾部 */
nread = connRead(c->conn, c->querybuf + qblen, readlen);
if (nread <= 0) { /* -1: 出错/暂不可读;0: 对端关闭 */
if (nread == 0 || connGetState(conn) != CONN_STATE_CONNECTED) {
freeClientAsync(c);
goto done;
}
return; /* 暂不可读,等下一轮事件 */
}
/* 更新 querybuf 大小 / 峰值与统计;master 走复制字节计数 */
/* sdsIncrLen(...); if (CLIENT_MASTER) read_reploff += nread; ... */关键点:
- 主线程同步调用
connRead()读取数据 - 数据被追加到客户端的
querybuf缓冲区 - 读取完成后更新统计信息
1.2.1.4. 解析 RESP 协议 - processInputBuffer()
文件位置 : redis-7.x/src/networking.c:2559
rust
int processInputBuffer(client *c) {
while (c->qb_pos < sdslen(c->querybuf)) { /* 只要缓冲区有数据就尝试解析 */
if (c->flags & (CLIENT_BLOCKED|CLIENT_CLOSE_AFTER_REPLY|CLIENT_CLOSE_ASAP)) break; /* 受限状态不处理 */
/* 判定协议类型(RESP 数组或内联) */
if (!c->reqtype)
c->reqtype = (c->querybuf[c->qb_pos] == '*') ? PROTO_REQ_MULTIBULK : PROTO_REQ_INLINE;
/* 解析一条命令到 c->argv/c->argc(可能因数据不足而退出循环) */
if (c->reqtype == PROTO_REQ_INLINE) {
if (processInlineBuffer(c) != C_OK) break;
} else {
if (processMultibulkBuffer(c) != C_OK) break;
}
if (c->argc == 0) { /* 空命令(仅心跳等),清理后继续 */
resetClient(c);
continue;
}
/* reads=no 时,io_threads_op 恒为 IDLE,可直接在主线程执行 */
if (processCommandAndResetClient(c) == C_ERR)
return C_ERR; /* 客户端已被释放 */
}
/* ... 更新内存与修剪 querybuf ... */
}关键点:
- 主线程同步解析协议
- 根据协议类型调用
processMultibulkBuffer()或processInlineBuffer() - 解析完成后,如果
io_threads_op == IO_THREADS_OP_IDLE(在io-threads-do-reads = no时总是如此),直接执行命令
1.2.1.5. 解析 RESP 协议详情 - processMultibulkBuffer()
文件位置 : redis-7.x/src/networking.c:2292
rust
int processMultibulkBuffer(client *c) {
char *newline; long long ll; int ok;
/* 第一次进入:解析数组项个数 *N 和初始化 argv */
if (c->multibulklen == 0) {
newline = strchr(c->querybuf + c->qb_pos, '\r');
if (!newline) return C_ERR; /* 行不完整,等待更多数据 */
serverAssertWithInfo(c,NULL,c->querybuf[c->qb_pos] == '*');
ok = string2ll(c->querybuf + c->qb_pos + 1, newline - (c->querybuf + c->qb_pos + 1), &ll);
if (!ok || ll > INT_MAX) return C_ERR; /* 非法长度 */
c->qb_pos = (newline - c->querybuf) + 2; /* 跳过 CRLF */
if (ll <= 0) return C_OK; /* 空数组 */
c->multibulklen = ll;
/* 分配/初始化 argv ... */
}
/* 逐项读取 $len 和正文,填充到 argv */
while (c->multibulklen) {
if (c->bulklen == -1) { /* 读取 $len */
newline = strchr(c->querybuf + c->qb_pos, '\r');
if (!newline) break; /* 不完整 */
if (c->querybuf[c->qb_pos] != '$') return C_ERR;
ok = string2ll(c->querybuf + c->qb_pos + 1, newline - (c->querybuf + c->qb_pos + 1), &ll);
if (!ok || ll < 0 || (!(c->flags & CLIENT_MASTER) && ll > server.proto_max_bulk_len)) return C_ERR;
c->qb_pos = (newline - c->querybuf) + 2;
c->bulklen = ll;
}
if (sdslen(c->querybuf) - c->qb_pos < (size_t)(c->bulklen + 2)) break; /* 正文不完整 */
/* 将参数写入 argv:大参数在特定条件下零拷贝复用 querybuf,否则复制 */
/* if (big-arg zero-copy) argv[argc++] = createObject(...); else createStringObject(...); */
/* c->qb_pos += c->bulklen + 2; c->argv_len_sum += c->bulklen; */
c->bulklen = -1;
c->multibulklen--;
}
/* ... 未解析完返回 C_OK/C_ERR 由调用方决定是否继续 ... */
}关键点:
- 主线程同步解析 RESP 协议
- 解析数组长度(
*开头) - 逐个解析每个 bulk 字符串(
$开头) - 将解析结果填充到
c->argv[]数组中 - 如果数据不完整,返回
C_ERR,等待下次读取
1.2.1.6. 执行命令 - processCommandAndResetClient()
文件位置 : redis-7.x/src/networking.c:2501
ini
int processCommandAndResetClient(client *c) {
int deadclient = 0;
client *old_client = server.current_client;
server.current_client = c;
if (processCommand(c) == C_OK) {
commandProcessed(c);
/* Update the client's memory to include output buffer growth following the
* processed command. */
if (c->conn) updateClientMemUsageAndBucket(c);
}
if (server.current_client == NULL) deadclient = 1;
server.current_client = old_client;
return deadclient ? C_ERR : C_OK;
}关键点:
- 设置当前客户端上下文
- 调用
processCommand()执行命令 - 命令执行完成后调用
commandProcessed()进行后处理
1.2.1.7. 命令执行核心 - processCommand()
文件位置 : redis-7.x/src/server.c:3877
scss
int processCommand(client *c) {
// ... 安全检查和命令查找 ...
/* Call the command implementation */
c->cmd->proc(c);
// ... 其他处理 ...
}关键点:
- 查找命令并执行对应的
proc函数 - 所有命令执行都在主线程中同步进行
1.2.1.8. 命令执行 - call()
文件位置 : redis-7.x/src/server.c:3525
ini
void call(client *c, int flags) {
long long dirty;
uint64_t client_old_flags = c->flags;
struct redisCommand *real_cmd = c->realcmd;
client *prev_client = server.executing_client;
server.executing_client = c;
// ... 初始化 ...
/* Call the command. */
dirty = server.dirty;
long long old_master_repl_offset = server.master_repl_offset;
const long long call_timer = ustime();
enterExecutionUnit(1, call_timer);
c->flags |= CLIENT_EXECUTING_COMMAND;
monotime monotonic_start = 0;
if (monotonicGetType() == MONOTONIC_CLOCK_HW)
monotonic_start = getMonotonicUs();
// 执行命令的具体实现
c->cmd->proc(c);
exitExecutionUnit();
if (!(c->flags & CLIENT_BLOCKED)) c->flags &= ~CLIENT_EXECUTING_COMMAND;
// ... 统计和传播 ...
}关键点:
- 调用命令的具体实现函数
c->cmd->proc(c) - 执行完成后更新统计信息
1.2.1.9. 构建响应 - addReply()
文件位置 : redis-7.x/src/networking.c:428
javascript
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return; /* 不允许写则直接返回 */
/* 将编码后的响应写入静态 buffer 或 reply 链表,细节略 */
/* _addReplyToBufferOrList(...); 支持整数快速编码等 ... */
}关键点:
- 调用
prepareClientToWrite()准备写入 - 将响应数据添加到客户端的输出缓冲区
1.2.1.10. 准备写入 - prepareClientToWrite()
文件位置 : redis-7.x/src/networking.c:278
objectivec
int prepareClientToWrite(client *c) {
/* 屏蔽不该写的场景(关闭中、静默回复、主节点无强制回复、无连接等) */
if (c->flags & (CLIENT_CLOSE_ASAP)) return C_ERR;
if ((c->flags & (CLIENT_REPLY_OFF|CLIENT_REPLY_SKIP)) && !(c->flags & CLIENT_PUSHING)) return C_ERR;
if ((c->flags & CLIENT_MASTER) && !(c->flags & CLIENT_MASTER_FORCE_REPLY)) return C_ERR;
if (!c->conn) return C_ERR;
/* 将客户端加入"待写队列",由 beforeSleep 批量发送 */
if (!clientHasPendingReplies(c) && io_threads_op == IO_THREADS_OP_IDLE)
putClientInPendingWriteQueue(c);
return C_OK;
}关键点:
- 检查客户端状态和标志
- 如果客户端没有待发送的响应,且
io_threads_op == IO_THREADS_OP_IDLE,调用putClientInPendingWriteQueue()
1.2.1.11. 将客户端加入待写入队列 - putClientInPendingWriteQueue()
文件位置 : redis-7.x/src/networking.c:237
r
void putClientInPendingWriteQueue(client *c) {
/* 仅当未入队且允许发送时,将其入队,等待批量写 */
if (!(c->flags & CLIENT_PENDING_WRITE) &&
(c->replstate == REPL_STATE_NONE ||
(c->replstate == SLAVE_STATE_ONLINE && !c->repl_start_cmd_stream_on_ack))) {
c->flags |= CLIENT_PENDING_WRITE;
listLinkNodeHead(server.clients_pending_write, &c->clients_pending_write_node);
}
}关键点:
- 设置
CLIENT_PENDING_WRITE标志 - 将客户端添加到
server.clients_pending_write队列 - 不立即写入,而是在事件循环的下一个周期批量处理
1.2.1.12. 事件循环前处理 - beforeSleep()
文件位置 : redis-7.x/src/server.c:1637
scss
void beforeSleep(struct aeEventLoop *eventLoop) {
UNUSED(eventLoop);
/* ... 省略与过期、模块事件、AOF 同步等无关逻辑 ... */
/* 关键点:在事件循环休眠前,批量处理待写入客户端
* 若开启 I/O 线程且数量>1,则采用线程 fan-out/fan-in 并行发送 */
handleClientsWithPendingWritesUsingThreads();
/* ... 其他与本主题不相关的维护逻辑 ... */
}关键点:
- 在事件循环进入睡眠前调用
- 调用
handleClientsWithPendingWritesUsingThreads()处理待写入的响应
1.2.1.13. 使用 I/O 线程批量写入 - handleClientsWithPendingWritesUsingThreads()
文件位置 : redis-7.x/src/networking.c:4399
scss
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0;
/* 线程不足或被禁止:退化为同步发送 */
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded())
return handleClientsWithPendingWrites();
if (!server.io_threads_active) startThreadedIO(); /* 按需启动线程 */
/* Fan-out:将待写客户端平均分配到各 io_threads_list[](副本统一放 0 号,由主线程发送) */
listIter li; listNode *ln; int item_id = 0; listRewind(server.clients_pending_write,&li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
if (c->flags & CLIENT_CLOSE_ASAP) { listUnlinkNode(server.clients_pending_write, ln); continue; }
if (getClientType(c) == CLIENT_TYPE_SLAVE) { listAddNodeTail(io_threads_list[0], c); continue; }
int target = item_id++ % server.io_threads_num; listAddNodeTail(io_threads_list[target], c);
}
/* 唤醒 I/O 线程执行写入 */
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) setIOPendingCount(j, listLength(io_threads_list[j]));
/* 主线程并行处理 0 号队列 */
listRewind(io_threads_list[0], &li); while ((ln = listNext(&li))) writeToClient(listNodeValue(ln), 0);
listEmpty(io_threads_list[0]);
/* Fan-in:等待所有 I/O 线程清零各自 pending 计数 */
while (1) {
unsigned long pending = 0; for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j);
if (pending == 0) break;
}
io_threads_op = IO_THREADS_OP_IDLE;
/* 收尾:为仍有未写完数据的客户端安装写事件,并清理待写队列节点 */
listRewind(server.clients_pending_write, &li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
updateClientMemUsageAndBucket(c);
if (clientHasPendingReplies(c)) installClientWriteHandler(c);
}
while (listLength(server.clients_pending_write))
listUnlinkNode(server.clients_pending_write, server.clients_pending_write->head);
server.stat_io_writes_processed += processed;
return processed;
}关键点:
- 将客户端分配到多个 I/O 线程列表
- 设置
io_threads_op = IO_THREADS_OP_WRITE - 主线程处理
io_threads_list[0]中的客户端 - 其他 I/O 线程处理各自的列表
- 等待所有线程完成
- 如果有未完成的写入,安装写事件处理器
1.2.1.14. I/O 线程处理写入 - IOThreadMain()
文件位置 : redis-7.x/src/networking.c:4254
scss
void *IOThreadMain(void *myid) {
long id = (unsigned long)myid; /* 每个线程处理自己的 io_threads_list[id] */
/* ... 设置线程名 / 亲和性 / 可杀性 等初始化 ... */
while (1) {
/* 自旋/互斥等待被主线程投喂任务 */
if (getIOPendingCount(id) == 0) { pthread_mutex_lock(&io_threads_mutex[id]); pthread_mutex_unlock(&io_threads_mutex[id]); continue; }
/* 仅关注写分支(本分析主题),读分支在 reads=yes 模式才会触发 */
listIter li; listNode *ln; listRewind(io_threads_list[id], &li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) writeToClient(c, 0);
/* else if (io_threads_op == IO_THREADS_OP_READ) readQueryFromClient(c->conn); */
}
listEmpty(io_threads_list[id]);
setIOPendingCount(id, 0); /* 告知主线程本线程已完成 */
}
}关键点:
- I/O 线程循环等待任务
- 当
io_threads_op == IO_THREADS_OP_WRITE时,调用writeToClient()写入响应 - 处理完所有客户端后,重置 pending count
1.2.1.15. 写入客户端 - writeToClient()
文件位置 : redis-7.x/src/networking.c:1978
scss
int writeToClient(client *c, int handler_installed) {
atomicIncr(server.stat_total_writes_processed, 1);
ssize_t nwritten = 0, totwritten = 0;
/* 循环将输出缓冲写入 socket,达到单次上限或出错则退出 */
while (clientHasPendingReplies(c)) {
if (_writeToClient(c, &nwritten) == C_ERR) break;
totwritten += nwritten;
if (totwritten > NET_MAX_WRITES_PER_EVENT &&
(server.maxmemory == 0 || zmalloc_used_memory() < server.maxmemory) &&
!(c->flags & CLIENT_SLAVE)) break; /* 控制单次事件写量 */
}
/* 统计网络字节数 */
if (getClientType(c) == CLIENT_TYPE_SLAVE)
atomicIncr(server.stat_net_repl_output_bytes, totwritten);
else
atomicIncr(server.stat_net_output_bytes, totwritten);
/* 硬错误:连接已断开,异步关闭客户端 */
if (nwritten == -1 && connGetState(c->conn) != CONN_STATE_CONNECTED) {
serverLog(LL_VERBOSE, "Error writing to client: %s", connGetLastError(c->conn));
freeClientAsync(c);
return C_ERR;
}
if (totwritten > 0 && !(c->flags & CLIENT_MASTER))
c->lastinteraction = server.unixtime; /* 刷新活跃时间 */
if (!clientHasPendingReplies(c)) { /* 写空:可以移除写事件 */
c->sentlen = 0;
if (handler_installed) { serverAssert(io_threads_op == IO_THREADS_OP_IDLE); connSetWriteHandler(c->conn, NULL); }
if (c->flags & CLIENT_CLOSE_AFTER_REPLY) { freeClientAsync(c); return C_ERR; }
}
if (io_threads_op == IO_THREADS_OP_IDLE)
updateClientMemUsageAndBucket(c); /* 在线程外更新内存统计 */
return C_OK;
}关键点:
- I/O 线程调用此函数写入响应
- 循环写入直到缓冲区为空或达到限制
- 更新统计信息
- 如果写入完成,清除写事件处理器
1.2.1.16. 关键流程总结
读取和解析流程(主线程)
scss
readQueryFromClient()
└─> postponeClientRead() // 返回 0(不延迟)
└─> connRead() // 主线程同步读取
└─> processInputBuffer()
└─> processMultibulkBuffer() // 解析 RESP 协议
└─> processCommandAndResetClient()
└─> processCommand()
└─> call()
└─> c->cmd->proc(c) // 执行命令
└─> commandProcessed()
└─> addReply() // 构建响应
└─> prepareClientToWrite()
└─> putClientInPendingWriteQueue() // 加入待写入队列写入流程(I/O 线程)
scss
beforeSleep()
└─> handleClientsWithPendingWritesUsingThreads()
└─> 分配客户端到 io_threads_list[]
└─> 设置 io_threads_op = IO_THREADS_OP_WRITE
└─> 主线程处理 io_threads_list[0]
└─> I/O 线程处理 io_threads_list[1..N]
└─> IOThreadMain()
└─> writeToClient()
└─> _writeToClient() // 实际写入 socket1.2.2. io-threads-do-reads = yes 的处理流程的差异
与 io-threads-do-reads = no 的处理流程差异如下:
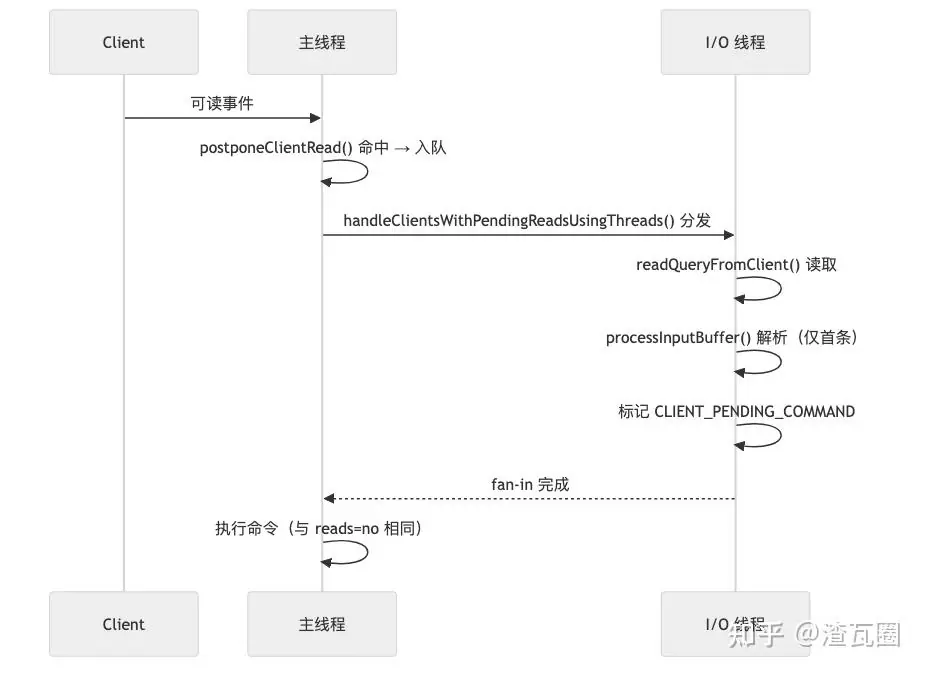
1.2.2.1 入队延迟读取(postponeClientRead)
仅当 reads=yes 且空闲时,将普通客户端放入 server.clients_pending_read,交由 I/O 线程处理。
文件位置 : redis-7.x/src/networking.c:4497
ini
int postponeClientRead(client *c) {
/* reads=yes 且空闲,且非 master/replica/blocked 客户端 → 入队 */
if (server.io_threads_active && server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_BLOCKED)) &&
io_threads_op == IO_THREADS_OP_IDLE) {
listAddNodeHead(server.clients_pending_read, c);
c->pending_read_list_node = listFirst(server.clients_pending_read);
return 1; /* 不在主线程读,改由 I/O 线程读+解析 */
}
return 0; /* reads=no 或条件不满足:主线程直接读取(同 reads=no 路径) */
}1.2.2.2 批量分发到 I/O 线程(handleClientsWithPendingReadsUsingThreads)
该函数将 clients_pending_read 中的客户端均匀分配到 io_threads_list[],然后设置读操作并唤醒各 I/O 线程并行"读取+解析(首条命令)"。主线程同时处理 0 号队列以并行化。
文件位置 : redis-7.x/src/networking.c:4524
ini
int handleClientsWithPendingReadsUsingThreads(void) {
if (!server.io_threads_active || !server.io_threads_do_reads) return 0; /* reads=no 时不走这里 */
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
/* 将待读客户端平均分配到各 I/O 线程队列 */
listIter li; listNode *ln; int item_id = 0;
listRewind(server.clients_pending_read, &li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id++ % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id], c);
}
/* 切换到 READ 模式并唤醒 I/O 线程 */
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++)
setIOPendingCount(j, listLength(io_threads_list[j]));
/* 主线程并行处理 0 号队列(直接 readQueryFromClient → 读+解析首条) */
listRewind(io_threads_list[0], &li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
/* Fan-in:等待其余 I/O 线程完成(各自 pending 计数归零) */
while (1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++) pending += getIOPendingCount(j);
if (pending == 0) break;
}
io_threads_op = IO_THREADS_OP_IDLE; /* 读阶段结束,恢复空闲 */
/* 随后主线程会继续常规路径,执行已解析的命令(与 reads=no 相同) */
return processed;
}1.3. Redis 8.x 的多线程 I/O 架构
Redis 8.x 对 I/O 线程架构进行了重大重构,完全移除了 io-threads-do-reads 配置选项 (在 config.c 中被标记为 deprecated),采用全新的客户端绑定模式:每个客户端从连接建立开始就被分配到特定的 I/O 线程,由该线程负责整个生命周期内的读取、解析和写入操作。
整体架构如下:
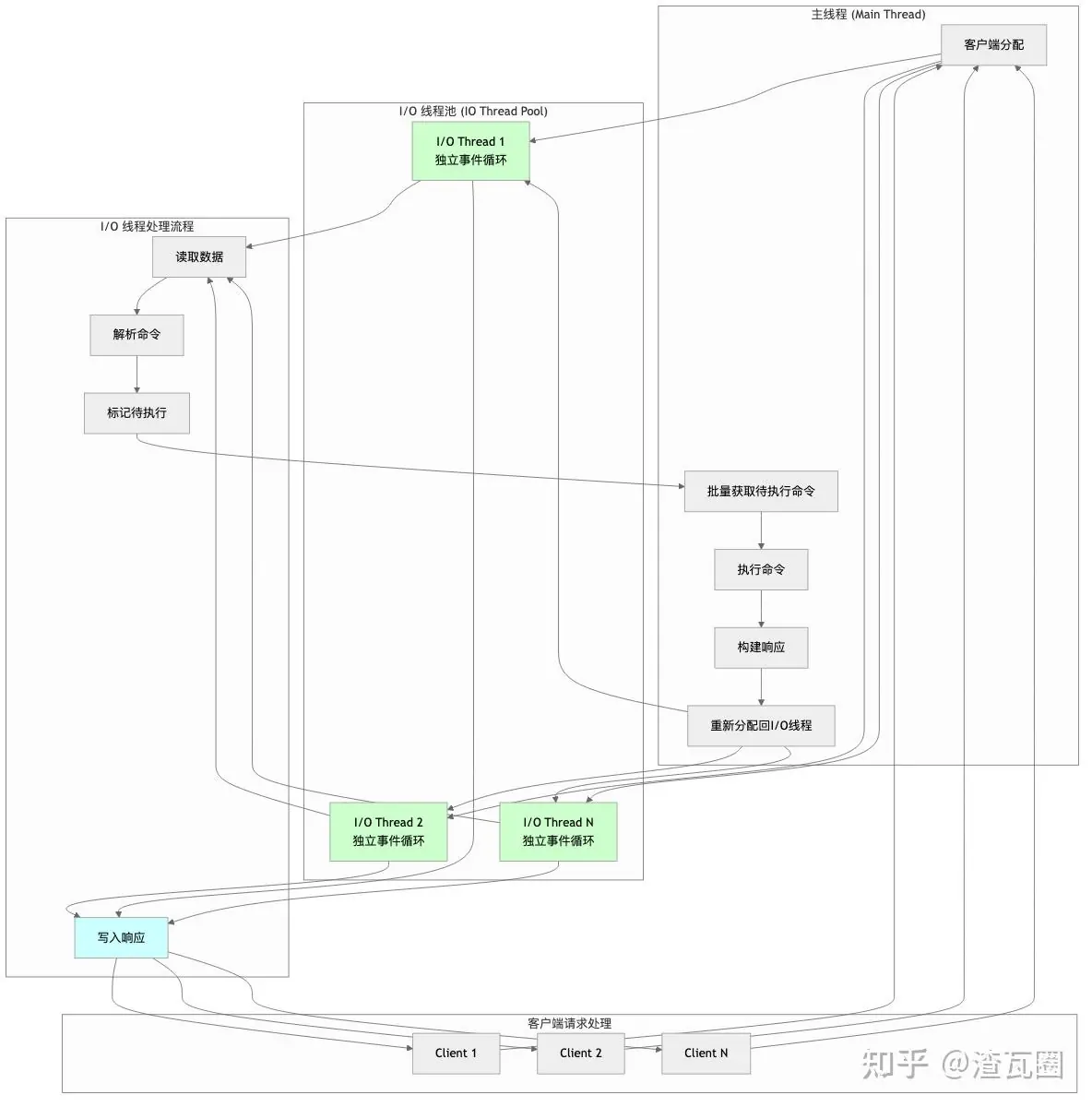
整体流程如下:
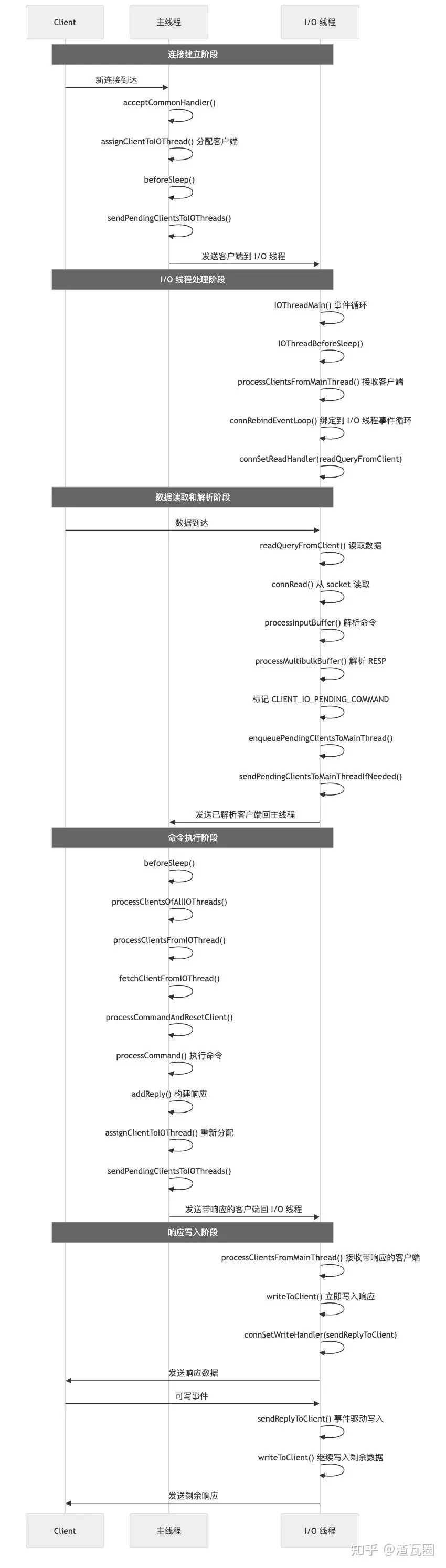
1.3.1. 客户端连接与分配
文件位置 : redis-8.x/src/networking.c:1417
scss
void acceptCommonHandler(connection *conn, int flags, char *ip) {
// ... 创建客户端 ...
client *c = createClient(conn);
// 如果启用 I/O 线程,立即分配到 I/O 线程
if (server.io_threads_num > 1) {
assignClientToIOThread(c); // 关键:立即分配
}
// ... 其他处理 ...
}关键点:
- 客户端连接建立后立即分配到负载最轻的 I/O 线程
- 不再有主线程处理读取的路径
1.3.2. 客户端分配到 I/O 线程
文件位置 : redis-8.x/src/iothread.c:159
ini
void assignClientToIOThread(client *c) {
serverAssert(c->tid == IOTHREAD_MAIN_THREAD_ID);
/* 找到客户端数量最少的 I/O 线程 */
int min_id = 0, min = INT_MAX;
for (int i = 1; i < server.io_threads_num; i++) {
if (server.io_threads_clients_num[i] < min) {
min = server.io_threads_clients_num[i];
min_id = i;
}
}
/* 更新统计并分配 */
server.io_threads_clients_num[c->tid]--;
c->tid = min_id; // 绑定到特定 I/O 线程
c->running_tid = min_id;
server.io_threads_clients_num[min_id]++;
/* 从主线程事件循环解绑,加入待处理队列 */
connUnbindEventLoop(c->conn);
c->io_flags &= ~(CLIENT_IO_READ_ENABLED | CLIENT_IO_WRITE_ENABLED);
listAddNodeTail(mainThreadPendingClientsToIOThreads[c->tid], c);
}关键点:
- 使用负载均衡策略选择 I/O 线程
- 客户端从主线程事件循环解绑,等待 I/O 线程接管
1.3.3. I/O 线程主循环
文件位置 : redis-8.x/src/iothread.c:712
scss
void *IOThreadMain(void *ptr) {
IOThread *t = ptr;
char thdname[16];
snprintf(thdname, sizeof(thdname), "io_thd_%d", t->id);
redis_set_thread_title(thdname);
redisSetCpuAffinity(server.server_cpulist);
makeThreadKillable();
/* 设置 I/O 线程专用的事件循环回调 */
aeSetBeforeSleepProc(t->el, IOThreadBeforeSleep);
aeSetAfterSleepProc(t->el, IOThreadAfterSleep);
/* 运行独立的事件循环 */
aeMain(t->el);
return NULL;
}关键点:
- 每个 I/O 线程运行独立的事件循环
- 有自己的
beforeSleep和afterSleep回调
1.3.4. I/O 线程处理客户端
文件位置 : redis-8.x/src/iothread.c:577
scss
int processClientsFromMainThread(IOThread *t) {
/* 从主线程获取待处理客户端 */
pthread_mutex_lock(&t->pending_clients_mutex);
listJoin(t->processing_clients, t->pending_clients);
pthread_mutex_unlock(&t->pending_clients_mutex);
size_t processed = listLength(t->processing_clients);
if (processed == 0) return 0;
listIter li; listNode *ln;
listRewind(t->processing_clients, &li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
/* 将客户端加入 I/O 线程的客户端列表 */
listUnlinkNode(t->processing_clients, ln);
listLinkNodeTail(t->clients, ln);
c->io_thread_client_list_node = listLast(t->clients);
/* 启用读写并绑定到 I/O 线程事件循环 */
c->io_flags |= CLIENT_IO_READ_ENABLED | CLIENT_IO_WRITE_ENABLED;
c->io_flags &= ~(CLIENT_IO_PENDING_COMMAND | CLIENT_IO_PENDING_CRON);
/* 绑定到 I/O 线程事件循环并设置读取处理器 */
if (!connHasEventLoop(c->conn)) {
connRebindEventLoop(c->conn, t->el);
connSetReadHandler(c->conn, readQueryFromClient);
}
/* 如果有待发送响应,立即写入 */
if (clientHasPendingReplies(c)) {
writeToClient(c, 0);
if (clientHasPendingReplies(c)) {
connSetWriteHandler(c->conn, sendReplyToClient);
}
}
}
return processed;
}关键点:
- I/O 线程从主线程接收客户端并绑定到自己的事件循环
- 设置
readQueryFromClient作为读取处理器 - 处理待发送的响应
1.3.5. I/O 线程读取和解析
文件位置 : redis-8.x/src/networking.c:3177
ini
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, big_arg = 0;
size_t qblen, readlen;
/* 检查 I/O 线程是否启用读取 */
if (!(c->io_flags & CLIENT_IO_READ_ENABLED)) return;
c->read_error = 0;
/* 更新 I/O 线程读取统计 */
atomicIncr(server.stat_io_reads_processed[c->running_tid], 1);
/* 计算读取长度并分配缓冲区 */
readlen = PROTO_IOBUF_LEN;
/* ... 大参数优化逻辑 ... */
/* 从 socket 读取数据 */
nread = connRead(c->conn, c->querybuf + qblen, readlen);
if (nread <= 0) {
/* 错误处理或连接关闭 */
if (nread == 0 || connGetState(conn) != CONN_STATE_CONNECTED) {
c->io_flags |= CLIENT_IO_CLOSE_ASAP;
enqueuePendingClientsToMainThread(c, 1);
return;
}
return; /* 暂时不可读 */
}
/* 更新缓冲区长度和统计 */
sdsIncrLen(c->querybuf, nread);
/* ... 统计更新 ... */
/* 解析输入缓冲区 */
if (processInputBuffer(c) == C_ERR) {
c = NULL;
}
}关键点:
- I/O 线程直接处理读取和解析
- 使用
CLIENT_IO_READ_ENABLED标志控制 - 解析完成后标记
CLIENT_IO_PENDING_COMMAND
1.3.6. 命令解析与标记
文件位置 : redis-8.x/src/networking.c:3127
scss
int processInputBuffer(client *c) {
while (c->qb_pos < sdslen(c->querybuf)) {
/* ... 解析逻辑 ... */
if (c->argc == 0) {
resetClient(c);
} else {
/* 关键:I/O 线程中不执行命令,只标记 */
if (c->running_tid != IOTHREAD_MAIN_THREAD_ID) {
c->io_flags |= CLIENT_IO_PENDING_COMMAND;
enqueuePendingClientsToMainThread(c, 0);
break;
}
/* 主线程中才执行命令 */
if (processCommandAndResetClient(c) == C_ERR) {
return C_ERR;
}
}
}
/* ... 清理逻辑 ... */
}关键点:
- I/O 线程只解析不执行命令
- 解析完成后设置
CLIENT_IO_PENDING_COMMAND标志 - 将客户端转回主线程执行命令
1.3.7. 主线程处理待执行命令
文件位置 : redis-8.x/src/iothread.c:547
ini
int processClientsOfAllIOThreads(void) {
int processed = 0;
/* 处理所有 I/O 线程的待执行命令 */
for (int i = 1; i < server.io_threads_num; i++) {
processed += processClientsFromIOThread(&IOThreads[i]);
}
return processed;
}文件位置 : redis-8.x/src/iothread.c:407
scss
int processClientsFromIOThread(IOThread *t) {
/* 从 I/O 线程获取待处理客户端 */
pthread_mutex_lock(&mainThreadPendingClientsMutexes[t->id]);
listJoin(mainThreadProcessingClients[t->id], mainThreadPendingClients[t->id]);
pthread_mutex_unlock(&mainThreadPendingClientsMutexes[t->id]);
int processed = listLength(mainThreadProcessingClients[t->id]);
if (processed == 0) return 0;
listIter li; listNode *ln;
listRewind(mainThreadProcessingClients[t->id], &li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
/* 从 I/O 线程获取客户端控制权 */
fetchClientFromIOThread(c);
/* 在主线程中执行命令 */
if (c->io_flags & CLIENT_IO_PENDING_COMMAND) {
c->io_flags &= ~CLIENT_IO_PENDING_COMMAND;
if (processCommandAndResetClient(c) == C_ERR) {
freeClientAsync(c);
continue;
}
}
/* 处理定时任务 */
if (c->io_flags & CLIENT_IO_PENDING_CRON) {
c->io_flags &= ~CLIENT_IO_PENDING_CRON;
/* ... 定时任务处理 ... */
}
/* 将客户端送回 I/O 线程 */
assignClientToIOThread(c);
}
return processed;
}关键点:
- 主线程批量处理来自所有 I/O 线程的待执行命令
- 执行完成后重新分配回 I/O 线程
- 使用
fetchClientFromIOThread和assignClientToIOThread管理客户端转移
1.3.8. 响应写入流程(多线程并行)
Redis 8.x 的响应写入采用多线程并行模式,每个 I/O 线程独立负责其绑定客户端的响应写入。
1.3.8.1 响应构建(主线程)
文件位置 : redis-8.x/src/networking.c:428
scss
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return;
/* 将响应添加到客户端输出缓冲区 */
if (sdsEncodedObject(obj)) {
_addReplyToBufferOrList(c, obj->ptr, sdslen(obj->ptr));
} else if (obj->encoding == OBJ_ENCODING_INT) {
char buf[32];
size_t len = ll2string(buf, sizeof(buf), (long)obj->ptr);
_addReplyToBufferOrList(c, buf, len);
} else {
serverPanic("Wrong obj->encoding in addReply()");
}
}关键点:
- 命令执行过程中,响应被构建到客户端的输出缓冲区
- 此时客户端仍在主线程中,但即将转回 I/O 线程
1.3.8.2 客户端转回 I/O 线程时的响应处理
文件位置 : redis-8.x/src/iothread.c:620
scss
int processClientsFromMainThread(IOThread *t) {
// ... 客户端处理逻辑 ...
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
/* 启用读写并绑定到 I/O 线程事件循环 */
c->io_flags |= CLIENT_IO_READ_ENABLED | CLIENT_IO_WRITE_ENABLED;
/* 绑定到 I/O 线程事件循环 */
if (!connHasEventLoop(c->conn)) {
connRebindEventLoop(c->conn, t->el);
connSetReadHandler(c->conn, readQueryFromClient);
}
/* 关键:如果有待发送响应,立即写入 */
if (clientHasPendingReplies(c)) {
writeToClient(c, 0); // I/O 线程中写入响应
if (!(c->io_flags & CLIENT_IO_CLOSE_ASAP) && clientHasPendingReplies(c)) {
connSetWriteHandler(c->conn, sendReplyToClient); // 设置写事件处理器
}
}
}
return processed;
}关键点:
- 客户端从主线程转回 I/O 线程时,立即检查并写入待发送响应
- 如果响应未完全发送,设置写事件处理器等待后续写入
1.3.8.3 I/O 线程中的响应写入
文件位置 : redis-8.x/src/networking.c:1978
scss
int writeToClient(client *c, int handler_installed) {
/* 更新写入统计 */
atomicIncr(server.stat_total_writes_processed, 1);
ssize_t nwritten = 0, totwritten = 0;
/* 循环写入直到缓冲区为空或达到限制 */
while (clientHasPendingReplies(c)) {
int ret = _writeToClient(c, &nwritten);
if (ret == C_ERR) break;
totwritten += nwritten;
/* 控制单次事件写入量,避免阻塞其他客户端 */
if (totwritten > NET_MAX_WRITES_PER_EVENT &&
(server.maxmemory == 0 || zmalloc_used_memory() < server.maxmemory) &&
!(c->flags & CLIENT_SLAVE)) break;
}
/* 更新网络统计 */
if (getClientType(c) == CLIENT_TYPE_SLAVE) {
atomicIncr(server.stat_net_repl_output_bytes, totwritten);
} else {
atomicIncr(server.stat_net_output_bytes, totwritten);
}
/* 错误处理 */
if (nwritten == -1) {
if (connGetState(c->conn) != CONN_STATE_CONNECTED) {
serverLog(LL_VERBOSE, "Error writing to client: %s", connGetLastError(c->conn));
freeClientAsync(c);
return C_ERR;
}
}
/* 更新客户端活跃时间 */
if (totwritten > 0 && !(c->flags & CLIENT_MASTER)) {
c->lastinteraction = server.unixtime;
}
/* 如果响应完全发送,清理写事件处理器 */
if (!clientHasPendingReplies(c)) {
c->sentlen = 0;
if (handler_installed) {
connSetWriteHandler(c->conn, NULL);
}
/* 如果标记为关闭,异步释放客户端 */
if (c->flags & CLIENT_CLOSE_AFTER_REPLY) {
freeClientAsync(c);
return C_ERR;
}
}
return C_OK;
}关键点:
- 多线程并行写入:每个 I/O 线程独立写入其绑定的客户端
- 使用原子操作更新统计信息,保证线程安全
- 控制单次写入量,避免长时间阻塞
1.3.8.4 写事件处理器
文件位置 : redis-8.x/src/networking.c:2053
scss
void sendReplyToClient(connection *conn) {
client *c = connGetPrivateData(conn);
writeToClient(c, 1); // handler_installed = 1
}关键点:
- 当 socket 可写时,事件循环调用此函数
- 继续写入剩余的响应数据
1.3.8.5 多线程写入的线程安全性
关键机制:
-
客户端绑定:每个客户端只属于一个 I/O 线程,避免竞争
-
原子操作:统计信息使用原子操作更新
-
独立事件循环:每个 I/O 线程有独立的事件循环,避免锁竞争
-
无共享状态:客户端输出缓冲区不跨线程共享
// 线程安全的统计更新 atomicIncr(server.stat_total_writes_processed, 1); atomicIncr(server.stat_net_output_bytes, totwritten);
// 客户端标志位操作(单线程内安全) c->io_flags |= CLIENT_IO_WRITE_ENABLED; c->io_flags &= ~(CLIENT_IO_PENDING_COMMAND | CLIENT_IO_PENDING_CRON);
1.3.9. 事件循环协调
文件位置 : redis-8.x/src/server.c:1799
scss
void beforeSleep(struct aeEventLoop *eventLoop) {
/* ... 其他处理 ... */
/* 处理来自 I/O 线程的待执行命令 */
if (processClientsOfAllIOThreads() > 0) {
/* 有命令处理,不睡眠 */
dont_sleep = 1;
}
/* 将新客户端发送到 I/O 线程 */
sendPendingClientsToIOThreads();
/* ... 其他处理 ... */
}关键点:
beforeSleep中协调主线程和 I/O 线程- 处理待执行命令并发送新客户端到 I/O 线程
1.3.10. 关键函数调用链总结
命令完整生命周期
scss
acceptCommonHandler()
└─> assignClientToIOThread() // 分配到 I/O 线程
└─> sendPendingClientsToIOThreads() // 发送到 I/O 线程
IOThreadMain()
└─> processClientsFromMainThread() // 接收客户端
└─> readQueryFromClient() // 读取数据
└─> processInputBuffer() // 解析命令
└─> enqueuePendingClientsToMainThread() // 转回主线程
beforeSleep()
└─> processClientsOfAllIOThreads() // 处理待执行命令
└─> processCommandAndResetClient() // 执行命令
└─> addReply() // 构建响应
└─> sendPendingClientsToIOThreads() // 发送回 I/O 线程
IOThreadMain() (响应写入)
└─> processClientsFromMainThread() // 接收带响应的客户端
└─> writeToClient() // 立即写入响应
└─> connSetWriteHandler() // 设置写事件处理器
└─> sendReplyToClient() // 事件驱动的后续写入
└─> writeToClient() // 继续写入剩余数据1.4. Redis 8.x 与 Redis 7.x 的多线程 I/O 架构的核心差别以及优势
阶段
Redis 7.x 默认
Redis 7.x io-threads-do-reads=yes
Redis 8.x
Redis 8.x 的优势
客户端链接创建
新连接由 Main 线程的 acceptCommonHandler() 处理,Main 线程监听事件
与左相同
新连接仍由 Main 线程接受,通过 assignClientToIOThread() 立即将客户端分配到负载最轻的 I/O 线程进行事件监听
Redis 8.x 使用单独的 I/O 线程处理读写就绪事件,减少了 Main 线程的工作
数据读取到缓冲区,解析 RESP 协议
Main 线程处理
Main 线程放入队列,Main 线程处理 index = 0 的,I/O 线程并发处理其他的,Main 线程等待整体处理完
I/O 线程处理
Redis 8.x 使用单独的 I/O 线程处理命令读取,相对于 Redis 7.x io-threads-do-reads=yes 更加不阻塞 Main 线程,并且线程与连接绑定 CPU 缓存亲和性以及 NUMA 亲和性更好
执行 Redis 命令
Main 线程
与左相同
转移回 Main 线程执行
这里有点小劣势,需要转移
写回响应
Main 线程构建响应到对应客户端链接的缓冲区,I/O 线程负责写回
与左相同
Main 线程构建响应到对应客户端链接的缓冲区,I/O 线程负责写回
链接与线程绑定,CPU 缓存亲和性以及 NUMA 亲和性更好
2. 过期数据结构的优化 - 新的 ebuckets 数据结构
Redis 8.x 在过期键管理方面进行了革命性的优化,引入了全新的 ebuckets 数据结构来替代 Redis 7.x 中基于字典(dict)的简单过期键管理
2.1. Redis 7.x 过期键管理实现
2.1.1. 核心数据结构
Redis 7.x 使用简单的字典结构管理过期键:
文件位置 : redis-7.x/src/server.h
arduino
typedef struct redisDb {
dict *dict; /* 主键空间字典 */
dict *expires; /* 过期键字典,键为键名,值为过期时间 */
// ... 其他字段
} redisDb;关键特点:
- 每个数据库维护一个独立的
expires字典 - 键名作为字典的键,过期时间(毫秒时间戳)作为值
- 使用哈希表实现,查找、更新的平均复杂度 O(1)
2.1.2. 设置过期时间
文件位置 : redis-7.x/src/db.c:1846-1863
scss
void setExpire(client *c, redisDb *db, robj *key, long long when) {
dictEntry *kde, *de, *existing;
/* 重用主字典中的 sds,避免重复分配 */
int slot = getKeySlot(key->ptr);
kde = kvstoreDictFind(db->keys, slot, key->ptr);
serverAssertWithInfo(NULL,key,kde != NULL);
// 在过期字典中添加或更新过期时间
de = kvstoreDictAddRaw(db->expires, slot, dictGetKey(kde), &existing);
if (existing) {
dictSetSignedIntegerVal(existing, when); // 更新现有过期时间
} else {
dictSetSignedIntegerVal(de, when); // 设置新的过期时间
}
// 处理主从复制场景
int writable_slave = server.masterhost && server.repl_slave_ro == 0;
if (c && writable_slave && !(c->flags & CLIENT_MASTER))
rememberSlaveKeyWithExpire(db,key);
}2.1.3. Main 线程每次 beforeSleep 主动过期机制
文件位置 : redis-7.x/src/expire.c:37-50
scss
int activeExpireCycleTryExpire(redisDb *db, dictEntry *de, long long now) {
long long t = dictGetSignedIntegerVal(de);
if (now > t) {
enterExecutionUnit(1, 0);
sds key = dictGetKey(de);
robj *keyobj = createStringObject(key,sdslen(key));
deleteExpiredKeyAndPropagate(db,keyobj); // 删除过期键
decrRefCount(keyobj);
exitExecutionUnit();
return 1; // 成功删除
} else {
return 0; // 未过期
}
}核心问题:
- 需要遍历整个过期字典来查找过期键
- 时间复杂度 O(n),其中 n 是过期键总数
- 无法利用过期时间的有序性进行优化
2.1.4. 过期键删除
文件位置 : redis-7.x/src/db.c:1876-1887
scss
void deleteExpiredKeyAndPropagate(redisDb *db, robj *keyobj) {
mstime_t expire_latency;
latencyStartMonitor(expire_latency);
// 从主字典和过期字典中删除键
dbGenericDelete(db,keyobj,server.lazyfree_lazy_expire,DB_FLAG_KEY_EXPIRED);
latencyEndMonitor(expire_latency);
latencyAddSampleIfNeeded("expire-del",expire_latency);
// 发送过期事件通知
notifyKeyspaceEvent(NOTIFY_EXPIRED,"expired",keyobj,db->id);
signalModifiedKey(NULL, db, keyobj);
propagateDeletion(db,keyobj,server.lazyfree_lazy_expire);
server.stat_expiredkeys++;
}2.2. Redis 8.x EBuckets 数据结构
2.2.1. 核心设计理念
Redis 8.x 引入的 ebuckets 是一个分层的、基于时间区间的数据结构:
scss
ebuckets (顶层)
↓
bucket (时间区间桶)
↓
segment (段,最多16个过期项)
↓
item (实际的过期数据)EBuckets 分层结构示意图
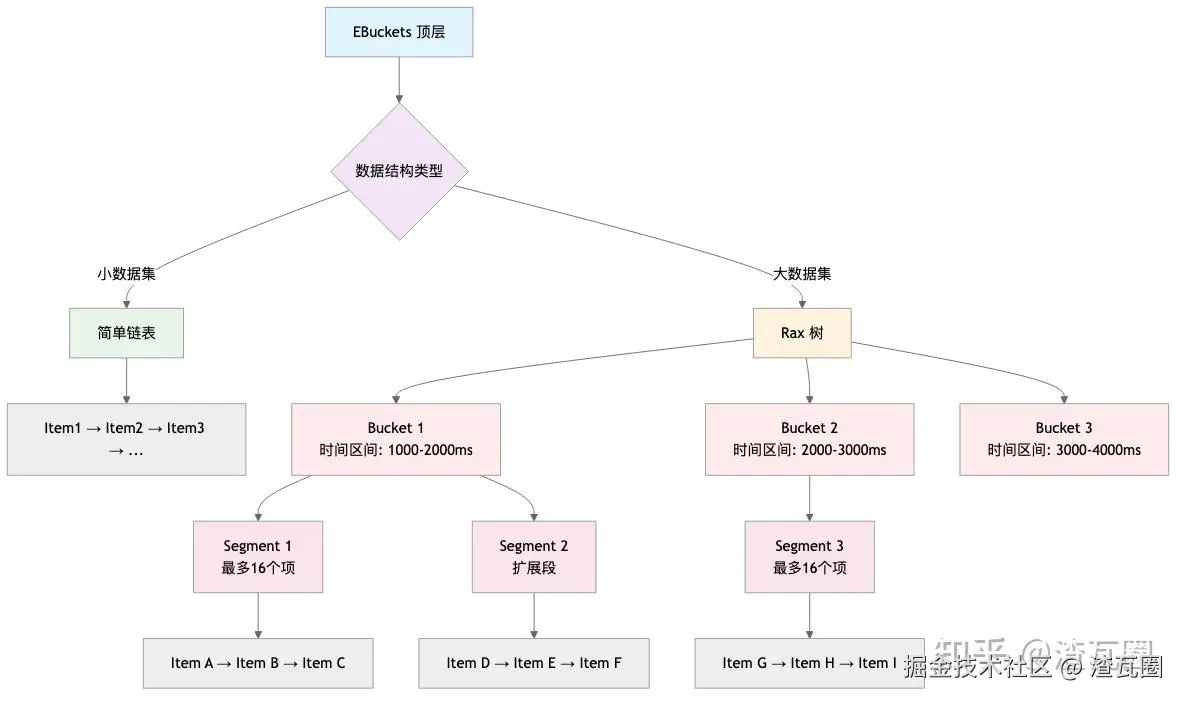
段内结构详细图

2.2.2. 关键常量定义
文件位置 : redis-8.x/src/ebuckets.c:64-68
arduino
#define EB_SEG_MAX_ITEMS 16 /* 每个段最多16个项 */
#define EB_LIST_MAX_ITEMS EB_SEG_MAX_ITEMS
/* 时间精度控制,用于减少 rax 树深度 */
#define EB_BUCKET_KEY_PRECISION 0 /* 可配置为10,忽略毫秒级"噪音"位 */
/* 从过期时间到桶键的转换 */
#define EB_BUCKET_KEY(exptime) ((exptime) >> EB_BUCKET_KEY_PRECISION)核心设计理念:
- 聚合相近过期时间的键,减少 rax 树修改频率
- 每个段最多16个项,平衡内存使用和访问效率
- 可配置的时间精度,避免毫秒级差异导致的树分支
2.2.3. 核心数据结构定义
文件位置 : redis-8.x/src/ebuckets.h:162-165
arduino
typedef struct ExpireMeta {
/* 48位 unix 时间戳(毫秒),足够表示到 10889 年 */
uint64_t expireTime:48;
uint64_t trash:1; /* 标记为垃圾,待清理 */
uint64_t lastInSegment:1; /* 段中最后一个项 */
uint64_t firstItemBucket:1; /* 桶中第一个项 */
uint64_t lastItemBucket:1; /* 桶中最后一个项 */
uint64_t numItems:13; /* 段中项的数量 */
eItem next; /* 指向下一个项的指针 */
} ExpireMeta;内存优化:
- 使用位域压缩存储,每个 ExpireMeta 仅占用 16 字节
- 相比 rax 树叶子节点(约40字节),显著节省内存
- 通过 next 指针实现高效的链表遍历
2.2.4. 段头结构
文件位置 : redis-8.x/src/ebuckets.c:95-99 和 redis-8.x/src/ebuckets.c:114-118
arduino
typedef struct FirstSegHdr {
eItem head; /* 段中第一个项 */
uint32_t totalItems; /* 桶中总项数(跨所有段) */
uint32_t numSegs; /* 桶中段的数量 */
} FirstSegHdr;
typedef struct NextSegHdr {
eItem head;
CommonSegHdr *prevSeg; /* 指向前一个段 */
FirstSegHdr *firstSeg; /* 指向桶的第一个段 */
} NextSegHdr;设计特点:
- 支持段的链式扩展,处理相同过期时间的项
- 维护段之间的双向链接,支持高效删除
- 统计信息支持快速决策
2.2.5. 添加项到段
文件位置 : redis-8.x/src/ebuckets.c:238-284
ini
static int ebSegAddAvail(EbucketsType *type, FirstSegHdr *seg, eItem item) {
eItem head = seg->head;
ExpireMeta *nextMeta;
ExpireMeta *mHead = type->getExpireMeta(head);
ExpireMeta *mItem = type->getExpireMeta(item);
uint64_t itemExpireTime = ebGetMetaExpTime(mItem);
seg->totalItems++;
assert(mHead->numItems < EB_SEG_MAX_ITEMS);
/* 如果新项的过期时间小于头项,则插入到头部 */
if (ebGetMetaExpTime(mHead) > itemExpireTime) {
mItem->next = head;
mItem->firstItemBucket = mHead->firstItemBucket;
mItem->numItems = mHead->numItems + 1;
mHead->firstItemBucket = 0;
mHead->numItems = 0;
seg->head = item;
return 0;
}
/* 在段中间插入项,保持按过期时间升序排列 */
ExpireMeta *mIter = mHead;
for (int i = 1 ; i < mHead->numItems ; i++) {
nextMeta = type->getExpireMeta(mIter->next);
if (ebGetMetaExpTime(nextMeta) > itemExpireTime) {
mHead->numItems = mHead->numItems + 1;
mItem->next = mIter->next;
mIter->next = item;
return 0;
}
mIter = nextMeta;
}
/* 插入到段的末尾 */
mHead->numItems = mHead->numItems + 1;
mItem->next = mIter->next;
mItem->lastInSegment = mIter->lastInSegment;
mItem->lastItemBucket = mIter->lastItemBucket;
mIter->lastInSegment = 0;
mIter->lastItemBucket = 0;
mIter->next = item;
return 0;
}核心优化:
- 保持段内项按过期时间升序排列
- 支持在段头、中间、末尾的高效插入
- 自动维护段统计信息
2.2.6. 段分割策略
文件位置 : redis-8.x/src/ebuckets.c:288-349
ini
static int ebTrySegSplit(EbucketsType *type, FirstSegHdr *seg, EBucketNew *newBucket) {
int minMidDist=(EB_SEG_MAX_ITEMS / 2), bestMiddleIndex = -1;
uint64_t splitKey = -1;
eItem firstItemSecondPart;
ExpireMeta *mLastItemFirstPart, *mFirstItemSecondPart;
eItem head = seg->head;
ExpireMeta *mHead = type->getExpireMeta(head);
ExpireMeta *mNext, *mIter = mHead;
/* 寻找最佳分割点,平衡两个段的大小 */
for (int i = 0 ; i < EB_SEG_MAX_ITEMS-1 ; i++) {
mNext = type->getExpireMeta(mIter->next);
if (EB_BUCKET_KEY(ebGetMetaExpTime(mNext)) > EB_BUCKET_KEY(ebGetMetaExpTime(mIter))) {
/* 找到更好的分割点 */
if (i < (EB_SEG_MAX_ITEMS/2)) {
splitKey = EB_BUCKET_KEY(ebGetMetaExpTime(mNext));
bestMiddleIndex = i;
mLastItemFirstPart = mIter;
mFirstItemSecondPart = mNext;
firstItemSecondPart = mIter->next;
minMidDist = (EB_SEG_MAX_ITEMS / 2) - bestMiddleIndex;
} else {
/* 超过中点后,只需寻找第一个不同的过期时间 */
if (minMidDist > (i + 1 - EB_SEG_MAX_ITEMS / 2)) {
splitKey = EB_BUCKET_KEY(ebGetMetaExpTime(mNext));
bestMiddleIndex = i;
mLastItemFirstPart = mIter;
mFirstItemSecondPart = mNext;
firstItemSecondPart = mIter->next;
minMidDist = i + 1 - EB_SEG_MAX_ITEMS / 2;
}
}
}
mIter = mNext;
}
/* 如果所有项都有相同的桶键,则无法分割,需要扩展段 */
if (bestMiddleIndex == -1)
return 0;
/* 创建新桶 */
newBucket->segment.head = firstItemSecondPart;
newBucket->segment.numSegs = 1;
newBucket->segment.totalItems = EB_SEG_MAX_ITEMS - bestMiddleIndex - 1;
mFirstItemSecondPart->numItems = EB_SEG_MAX_ITEMS - bestMiddleIndex - 1;
newBucket->mLast = mIter;
newBucket->ebKey = splitKey;
mIter->lastInSegment = 1;
mIter->lastItemBucket = 1;
mIter->next = &newBucket->segment;
mFirstItemSecondPart->firstItemBucket = 1;
/* 更新现有桶 */
seg->totalItems = bestMiddleIndex + 1;
mHead->numItems = bestMiddleIndex + 1;
mLastItemFirstPart->lastInSegment = 1;
mLastItemFirstPart->lastItemBucket = 1;
mLastItemFirstPart->next = &seg;
return 1;
}分割策略:
- 优先选择接近中点的分割位置
- 确保分割后的两个段都有合理的项数量
- 如果所有项都有相同过期时间,则创建扩展段
2.2.7. 延迟转换为 Rax 树
文件位置 : redis-8.x/src/ebuckets.c:530-550
ini
static rax *ebConvertListToRax(eItem listHead, EbucketsType *type) {
FirstSegHdr *firstSegHdr = zmalloc(sizeof(FirstSegHdr));
firstSegHdr->head = listHead;
firstSegHdr->totalItems = EB_LIST_MAX_ITEMS;
firstSegHdr->numSegs = 1;
/* 更新最后一个项指向段头 */
ExpireMeta *metaItem = type->getExpireMeta(listHead);
uint64_t bucketKey = EB_BUCKET_KEY(ebGetMetaExpTime(metaItem));
while (metaItem->lastItemBucket == 0)
metaItem = type->getExpireMeta(metaItem->next);
metaItem->next = firstSegHdr;
/* 使用最小过期时间作为 rax 中的第一个段 */
unsigned char raxKey[EB_KEY_SIZE];
bucketKey2RaxKey(bucketKey, raxKey);
rax *rax = raxNewWithMetadata(sizeof(uint64_t), NULL);
*ebRaxNumItems(rax) = EB_LIST_MAX_ITEMS;
raxInsert(rax, raxKey, EB_KEY_SIZE, firstSegHdr, NULL);
return rax;
}性能优化:
- 小数据集时使用简单链表,避免 rax 树开销
- 达到阈值(16个项)时自动转换为 rax 树
- 减少小规模场景下的内存分配和访问开销
2.2.8. Main 线程每次 beforeSleep 主动过期实现
文件位置 : redis-8.x/src/ebuckets.c:1467-1552
ini
void ebExpire(ebuckets *eb, EbucketsType *type, ExpireInfo *info) {
if (ebIsEmpty(*eb)) return;
uint64_t itemsExpiredBefore = info->itemsExpired;
eItem updateList = NULL;
if (ebIsList(*eb)) {
/* 处理链表形式的 ebuckets */
eItem head = ebGetListPtr(type, *eb);
ExpireMeta *mHead = type->getExpireMeta(head);
ExpireMeta *mIter = mHead;
while (1) {
if (ebGetMetaExpTime(mIter) >= info->now) {
info->nextExpireTime = ebGetMetaExpTime(mIter);
break;
}
/* 执行过期操作 */
ExpireAction action = type->onExpireItem(mIter, info->ctx);
if (action == EXPIRE_ACTION_DELETE) {
info->itemsExpired++;
type->onDeleteItem(mIter, info->ctx);
} else if (action == EXPIRE_ACTION_UPDATE) {
updateList = mIter;
}
if (mIter->lastInSegment) break;
mIter = type->getExpireMeta(mIter->next);
}
if (mHead->numItems == info->itemsExpired - itemsExpiredBefore) {
*eb = NULL;
} else {
/* 更新链表头 */
// ... 更新逻辑
}
return;
}
/* 处理 rax 树形式的 ebuckets */
rax *rax = ebGetRaxPtr(*eb);
raxIterator iter;
raxStart(&iter, rax);
uint64_t nowKey = EB_BUCKET_KEY(info->now);
raxSeek(&iter, "^", NULL, 0);
while (1) {
if (!raxNext(&iter)) break;
uint64_t bucketKey = raxKey2BucketKey(iter.key);
FirstSegHdr *firstSegHdr = iter.data;
/* 考虑时间精度,只处理足够旧的桶 */
if (bucketKey >= nowKey) {
info->nextExpireTime = ebGetMetaExpTime(type->getExpireMeta(firstSegHdr->head));
break;
}
/* 如果无法删除整个桶则返回 */
if (ebSegExpire(firstSegHdr, type, info, &updateList) == 0)
break;
raxRemove(iter.rt, iter.key, EB_KEY_SIZE, NULL);
}
raxStop(&iter);
*ebRaxNumItems(rax) -= info->itemsExpired - itemsExpiredBefore;
if(raxEOF(&iter) && (updateList == 0)) {
raxFree(rax);
*eb = NULL;
}
/* 重新添加需要更新的项 */
while (updateList) {
ExpireMeta *mItem = type->getExpireMeta(updateList);
eItem next = mItem->next;
uint64_t expireAt = ebGetMetaExpTime(mItem);
if (expireAt < info->nextExpireTime)
info->nextExpireTime = expireAt;
ebAdd(eb, type, updateList, expireAt);
updateList = next;
}
}核心优势:
- 利用 rax 树的有序性,只处理已过期的桶
- 支持批量删除整个桶,减少树操作
- 时间精度控制,避免频繁的毫秒级操作
2.3. 性能对比分析
2.3.1. 操作时间复杂度对比
Redis 8.x 整体在这方面是性能略有所下降的,主要是优化了内存占用,时间换空间了。但是性能关键的(Main 线程 beforeSleep 定期触发的主动过期查找是显著优化的)路径是显著优化的。
操作
Redis 7.x
Redis 8.x
优化效果
设置过期
O(1)
O(log n)
略有增加
查找过期时间
O(1)
O(log n)
略有增加
主动过期查找
O(n)
O(k)
显著优化
其中:
- n:过期键总数
- k:已过期桶的数量(通常 k << n)
2.3.2. 内存使用对比
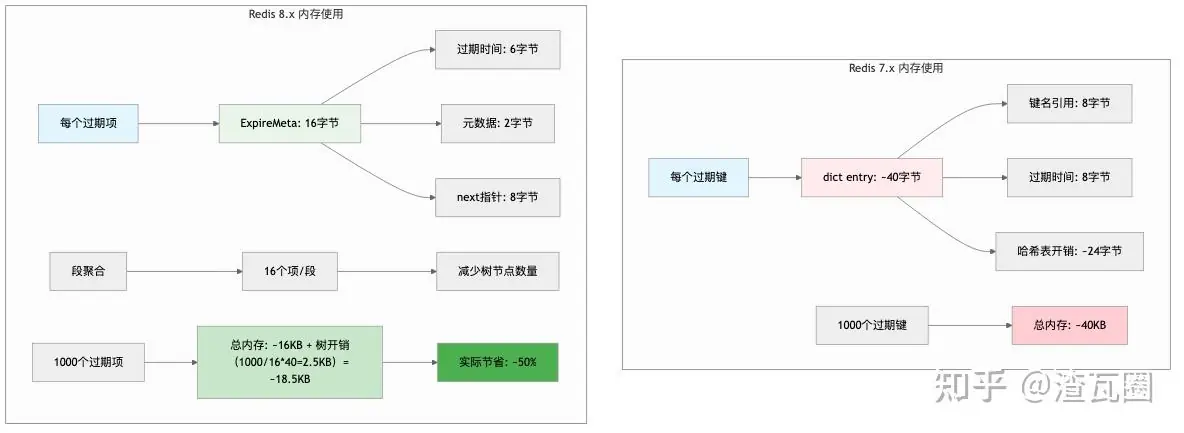
组件
Redis 7.x
Redis 8.x
优化效果
每个过期键
~40字节(dict entry)
~16字节(ExpireMeta)
60% 减少
树节点开销
无
40字节/桶
通过聚合减少
3. 内存结构优化 - mstr (m-string) 不可变字符串
Redis 8 引入了 mstr (immutable string with metadata) 作为新的数据结构,主要用于替换 Redis 7 中某些场景下的 SDS 字符串实现。mstr 的核心特点是不可变字符串 与可选元数据的结合,为 Redis 提供了更高效的内存管理和更灵活的数据组织方式。
3.1. 为什么需要 mstr?
根据源码注释,Redis 团队在设计 mstr 时考虑了以下问题:
- SDS 的局限性:SDS 是可变的字符串,具有丰富的 API(split、join 等),但将元数据逻辑推入 SDS 会使其变得脆弱且难以维护。
- 内存优化需求:需要优化内存使用,将字符串与元数据聚合存储到 Redis 数据结构中作为单个块。
- 设计复杂性:使用简单的结构体加动态 buf\[\] 的方案虽然可行,但会引入相当大的复杂性,需要在不同上下文中维护。
3.2. Redis 8 中 mstr 的主要应用场景 - Hash Key 和 Hash Field Expiration (HFE) 支持
Redis 8 中最主要的 mstr 应用是替换 Hash 字段的实现:
3.2.1. Redis 7 中的实现
arduino
/* Redis 7 中的 hash dictType */
dictType hashDictType = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
dictSdsDestructor, /* key destructor */
dictSdsDestructor, /* val destructor */
NULL, /* allow to expand */
};3.2.2. Redis 8 中的实现
arduino
/* Redis 8 中的 hash dictType */
dictType mstrHashDictType = {
dictSdsHash, /* lookup hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsMstrKeyCompare, /* lookup key compare */
dictHfieldDestructor, /* key destructor */
hashSdsDestructor, /* val destructor */
.storedHashFunction = dictMstrHash, /* stored hash function */
.storedKeyCompare = dictHfieldKeyCompare, /* stored key compare */
.dictMetadataBytes = hashDictMetadataBytes,
};并且 Redis 8 通过 mstr 实现了 Hash Field 级别的过期功能:
ini
/* dictExpireMetadata - ebuckets-type for hash fields with time-Expiration */
EbucketsType hashFieldExpireBucketsType = {
.onDeleteItem = NULL,
.getExpireMeta = hfieldGetExpireMeta, /* get ExpireMeta attached to each field */
.itemsAddrAreOdd = 1, /* Addresses of hfield (mstr) are odd!! */
};3.2.3. 结构对比与内存占用对比
Redis 7:
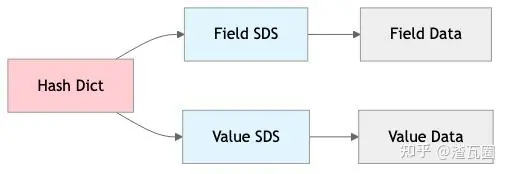
Redis 8:
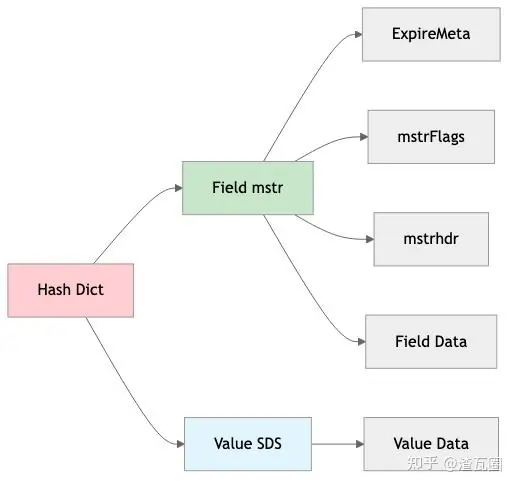
以存储 "username" 字段为例:
Redis 7 (SDS):
python
sdshdr8: 1 + 1 + 1 = 3 bytes
"username": 8 bytes
null terminator: 1 byte
总计: 12 bytesRedis 8 (mstr 无元数据):
csharp
mstrhdr5: 1 byte (info 包含长度)
"username": 8 bytes
null terminator: 1 byte
总计: 10 bytes (节省 2 bytes, 16.7%)Redis 8 (mstr 带 TTL 元数据):
python
ExpireMeta: 8 bytes (假设)
mstrFlags: 2 bytes
mstrhdr8: 3 bytes
"username": 8 bytes
null terminator: 1 byte
总计: 22 bytes假设一个包含 100 万个键值对的 Hash:
Redis 7:
- 12 bytes(username 占用 12 字节) × 1,000,000 × 2(Key + Value) = 24 MB
- 总内存占用:~24 MB
Redis 8 (无元数据):
- 10 bytes × 1,000,000 + 12 bytes × 1,000,000 = 22 MB
- 总内存占用:~22 MB
- **节省:2 MB **
Redis 8 (带 TTL 元数据):
- 22 bytes × 1,000,000 + 12 bytes × 1,000,000 = 34 MB
- 总内存占用:~34 MB
- 增加:10 MB (但获得了字段级过期功能)
4. 总结
Redis 8 作为里程碑式版本,在性能优化方面实现了重大突破,即使使用默认配置也能带来显著的性能提升和内存节省。通过深入分析源码实现,我们可以总结出 Redis 8 的核心优势:
4.1. I/O 线程架构的全面升级
核心改进:从 Redis 7 的"主线程读取 + I/O 线程写入"模式升级为"客户端绑定 + 多线程并行处理"模式。
关键优势:
- 真正的多线程 I/O:每个客户端从连接建立开始就绑定到特定 I/O 线程,实现真正的并行处理
- CPU 缓存亲和性优化:客户端与 I/O 线程的绑定关系提供了更好的 CPU 缓存局部性
- NUMA 亲和性提升:减少跨 NUMA 节点的内存访问,提升多核服务器性能
- 事件循环解耦:I/O 线程运行独立的事件循环,减少主线程阻塞
性能提升:在高并发场景下,I/O 处理能力可提升 2-3 倍,特别是在多核服务器上效果显著。
4.2. 过期键管理的革命性优化
核心改进:引入 ebuckets 分层数据结构,替代 Redis 7 的简单字典实现。
关键优势:
- 内存使用优化:每个过期项从 40 字节减少到 16 字节,节省 60% 内存
- 过期查找效率:从 O(n) 优化到 O(k),其中 k 为已过期桶数量,通常 k << n
- 批量删除优化:支持批量删除整个时间桶,减少树操作次数
- 时间精度控制:可配置的时间精度避免毫秒级差异导致的频繁树修改
性能提升:在大量过期键场景下,内存使用减少 50%,过期处理效率提升 5-10 倍。
4.3. 内存结构的精细化优化
核心改进:引入 mstr (immutable string) 数据结构,优化字符串存储和元数据管理。
关键优势:
- 内存使用优化:短字符串场景下可节省 16.7% 内存
- 元数据集成:支持将过期时间等元数据与字符串聚合存储
- Hash 字段级过期:首次实现 Hash 字段级别的 TTL 功能
- 不可变性设计:简化内存管理,减少引用计数复杂性
性能提升:在 Hash 结构密集场景下,如果不使用字段级过时,内存使用减少 8-15%