最近项目开发中遇到类似如下图所示的功能。上半部分是树形选择器,能够通过上面的"全选"切换树形选项的全选和取消全选。下半部分是表格,需要根据树形选择器勾选的数据实时生成表格数据。每个项目下都包含用户列表选项数据,可以单条设置每个项目的用户,也可以批量设置所有项目的用户。而批量设置用户的选项需要实时根据表格数据的变化动态计算。
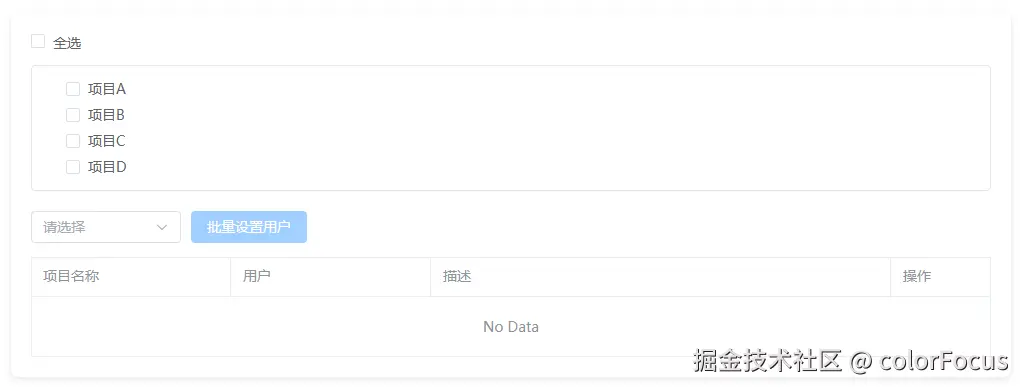
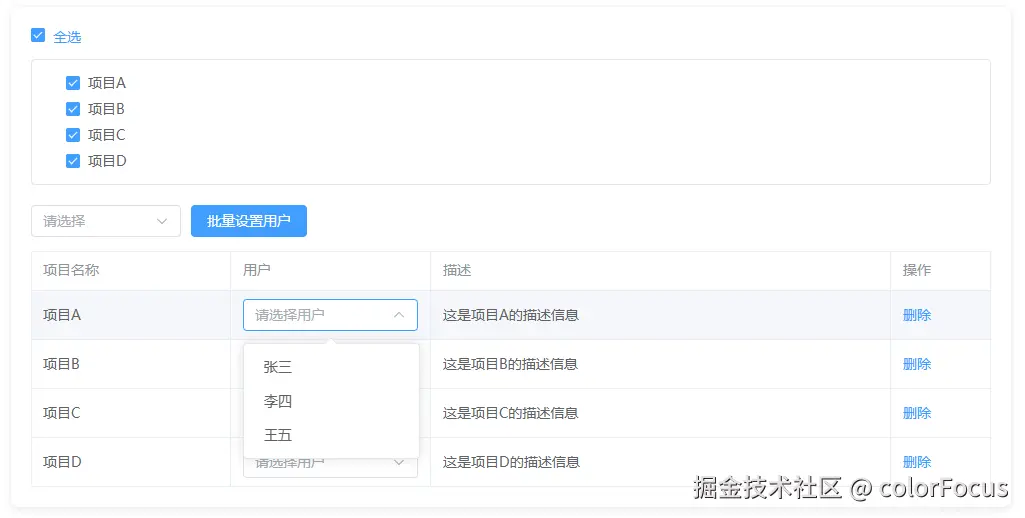
当树形选择器单条数据勾选,或者全选的选项非常少时,造成的表格数据变化以及后续的批量用户选项计算的工作量很小。但是如果全选操作的数据达到几十条、上百条时,每条被勾选的树形选项都会触发一次树形选择器的check-change事件,其中都会对应变化表格的数据以及批量设置用户选项的重新计算。
但对于全选批量处理的情况,我们没有必要对于每一次树形选项的勾选造成的表格数据变化都重新计算批量设置用户的选项。我们可以等所有选项变化对应的表格数据的变化都更新完成,再一次性的统一计算批量设置用户的选项。
功能实现
在"全选"change事件的事件处理函数handleCheckAllChange中,首先将"批量处理数据"标识isBatchUpdating设置为true,然后通过树形选择器的setCheckedKeys方法勾选或者取消勾选所有的树形选项。
js
// 处理全选变化
function handleCheckAllChange(isChecked) {
// 设置批量处理数据标识
isBatchUpdating = true;
if (isChecked) {
const allKeys = treeData.value.map((item) => item.id);
treeRef.value.setCheckedKeys(allKeys);
} else {
treeRef.value.setCheckedKeys([]);
}
}每个树形选项的状态变化都会触发一次树形选择器的check-change事件。在该事件的处理函数中首选会根据isBatchUpdating标识进行判断,如果当前在批量处理数据状态,则先将数据统一缓存在batchData数组中;否则对单条树形选项的勾选去对应生成新的表格数据或者删除已有的表格数据。
js
// 处理树形选择变化
function handleTreeCheckChange(node, isChecked) {
// 当通过全选批量处理数据值,先将数据缓存,整体更新完表格数据后,再一次计算批量设置用户选项
if (isBatchUpdating) {
batchData.push(node);
batchData.isChecked = isChecked;
return;
}
if (isChecked) {
addTableData(node);
} else {
delTableData(node);
}
// 更新全选checkbox状态
updateCheckAll();
}表格数据的变化会通过watch监听去更新"批量设置用户"选项的重新计算,此外也可以通过计算属性computed来生成"批量设置用户"选项。
js
// 监听表格变化,实时计算能够批量设置的用户选项
let watchHandle = watch(
tableData,
() => {
updateBatchUserOpts();
},
{
immediate: true,
deep: true,
}
);当批量处理数据batchData生成结束,我们就可以继续去统一处理表格数据的更新以及"批量设置用户"选项的生成。
这部分功能需要在上面的"全选"逻辑之后进行,但是在执行setCheckedKeys勾选树形选项后,会触发树形选项的check-change。我们需要在所有的树形选项的check-change同步逻辑结束之后再在"全选"的事件回调函数handleCheckAllChange中进行后续的逻辑。
此时我们需要借助"事件循环"中的概念,使用"微循环"使得后续逻辑能够在所有的同步任务执行完成之后进行,可以通过Promise.then来实现。
此外在统一进行表格数据处理前,需要停止对表格数据的watch监听,等表格更新完成再恢复对表格数据的监听。
js
// 处理全选变化
function handleCheckAllChange(isChecked) {
// 设置批量处理数据标识
isBatchUpdating = true;
if (isChecked) {
const allKeys = treeData.value.map((item) => item.id);
treeRef.value.setCheckedKeys(allKeys);
} else {
treeRef.value.setCheckedKeys([]);
}
// 微循环后延迟处理
Promise.resolve().then(() => {
// 取消表格数据监听
watchHandle.pause();
// 批量更新表格数据
for (const node of batchData) {
if (batchData.isChecked) {
addTableData(node);
} else {
delTableData(node);
}
}
// 更新批量设置用户选项
updateBatchUserOpts();
// 恢复表格数据监听
watchHandle.resume();
// 重置批量处理数据标识和缓存
isBatchUpdating = false;
delete batchData.isChecked;
batchData = [];
});
}总结:
当需要批量处理数据导致大数据量计算时会非常影响性能,此时可以先将数据缓存起来,然后通过Promise.then"微循环"延迟统一处理数据,能够提升处理性能。