一 现象
调用方A -> JSF -> 提供方B
大多数情况下,调用方耗时 和 提供方耗时 基本没有差别
个别情况下,调用方耗时 远高于 提供方耗时,大概5分钟20+次
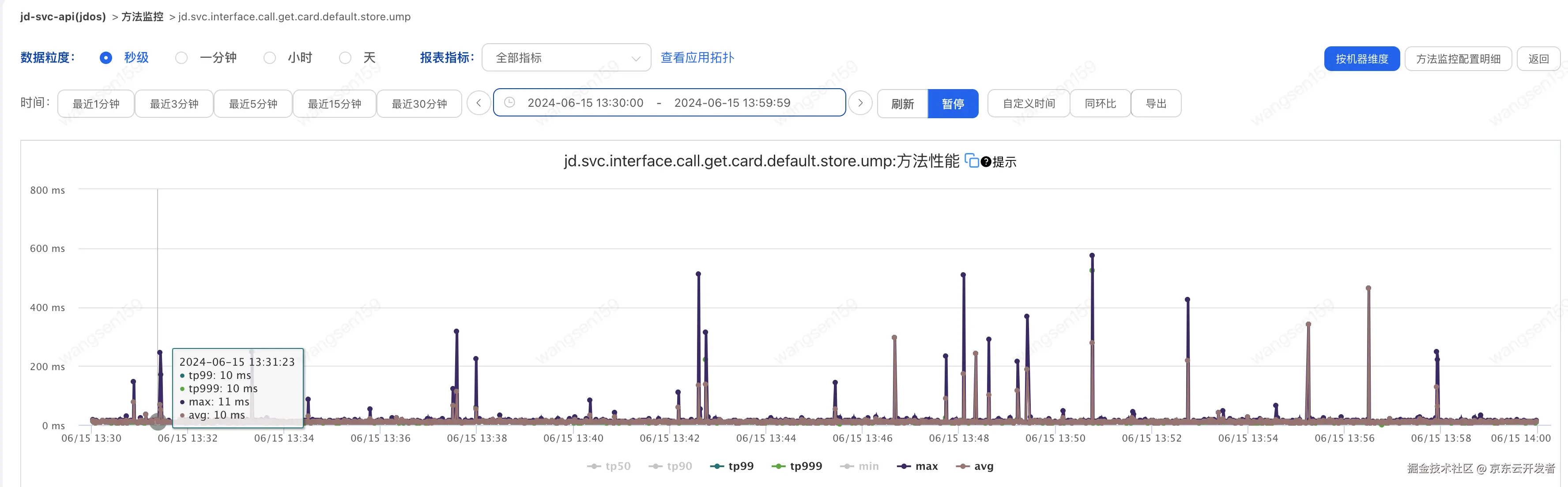
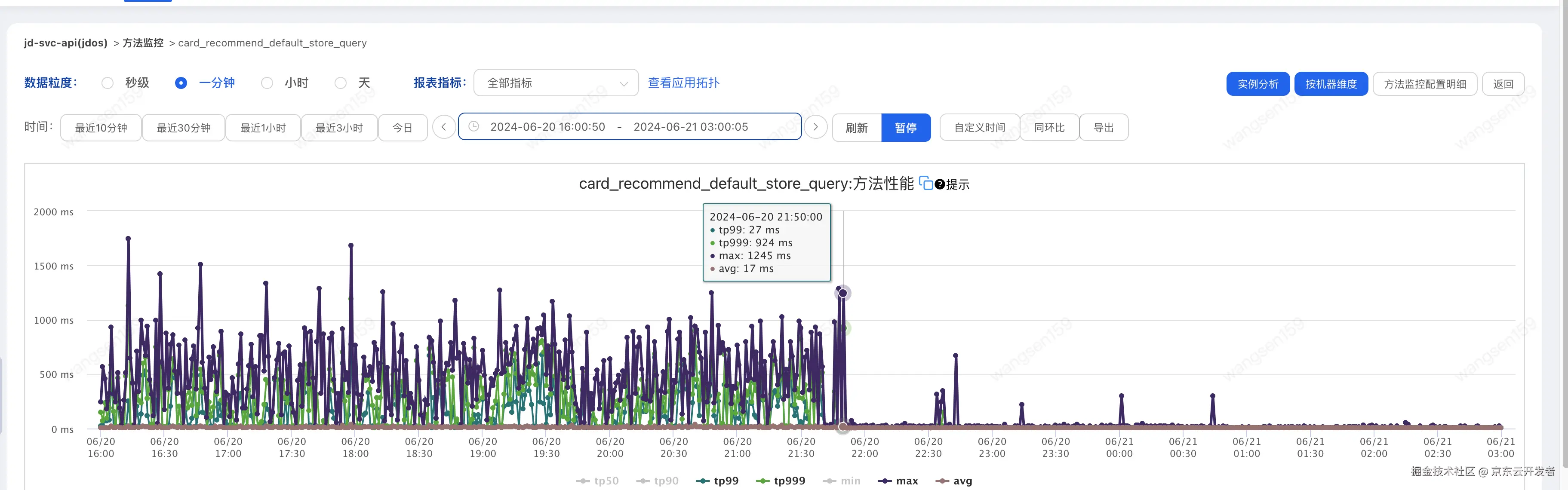
1.调用方A耗时如下图
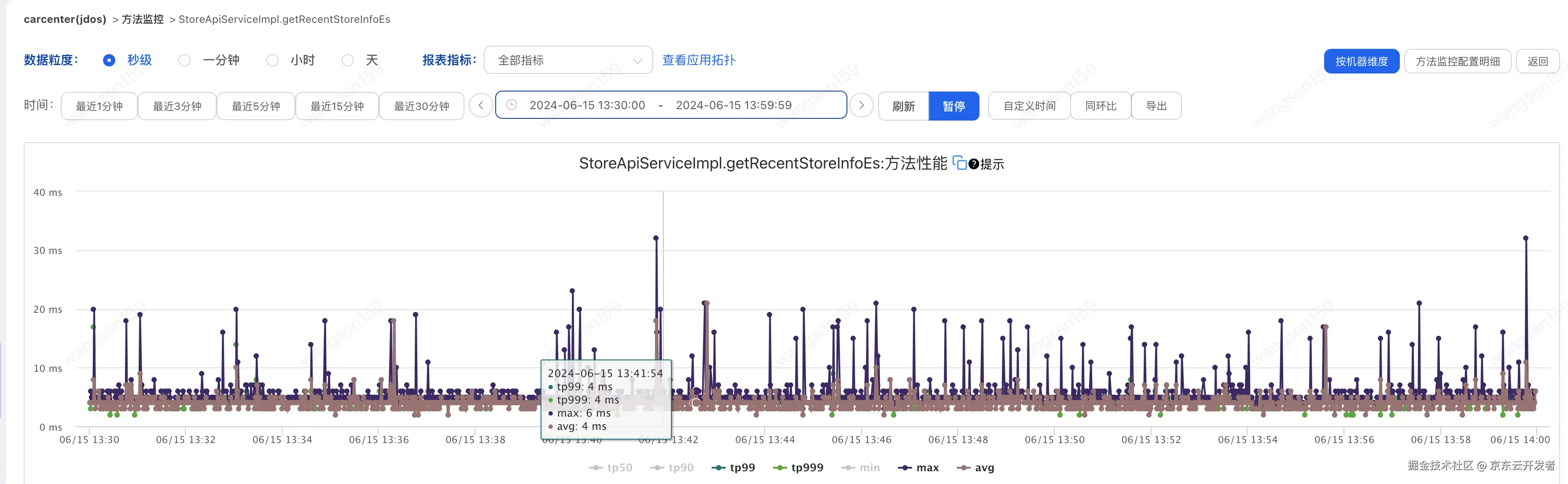
2.提供方B耗时如下图
3.调用方监控添加
在调用JSF接口前后加的监控,没有其他任何逻辑,包括日志打印
4.提供方监控添加
在代码最外层JSF接口加的监控,之外没有任何代码逻辑
5.耗时对比
| 时间段 | 调用方A平均耗时 | 提供方B平均耗时 | 调用方A最大耗时 | 提供方B最大耗时 | 调用方A超100ms数量 | 提供方B超100ms数量 |
|---|---|---|---|---|---|---|
| 2024-06-15 13:30:00 至 2024-06-15 13:59:59 | 大部分是低于60ms 有突刺 | 大部分不超过20 | 580ms | 32ms | 24次 | 0 |
二 排查思路
1.数据流转环节分析
调用方从请求到接收数据,除了提供方业务耗时,还有其他环节,分别是
1.调用方容器和宿主机
2.调用方->提供方经过的网络环节
3.提供方容器和宿主机的环节
4.提供方->调用方的网络环节
2.初步定位
容器和宿主机之间由于流量过大,处理压力大导致的瓶颈
网络波动
一步一步排除,先看网络
3.找证据
3.1 找监控
找到监控相关的技术同学,回答说没有网络的监控
于是找到了JDOS的同学,排查后提供了一种怀疑方向,如下图
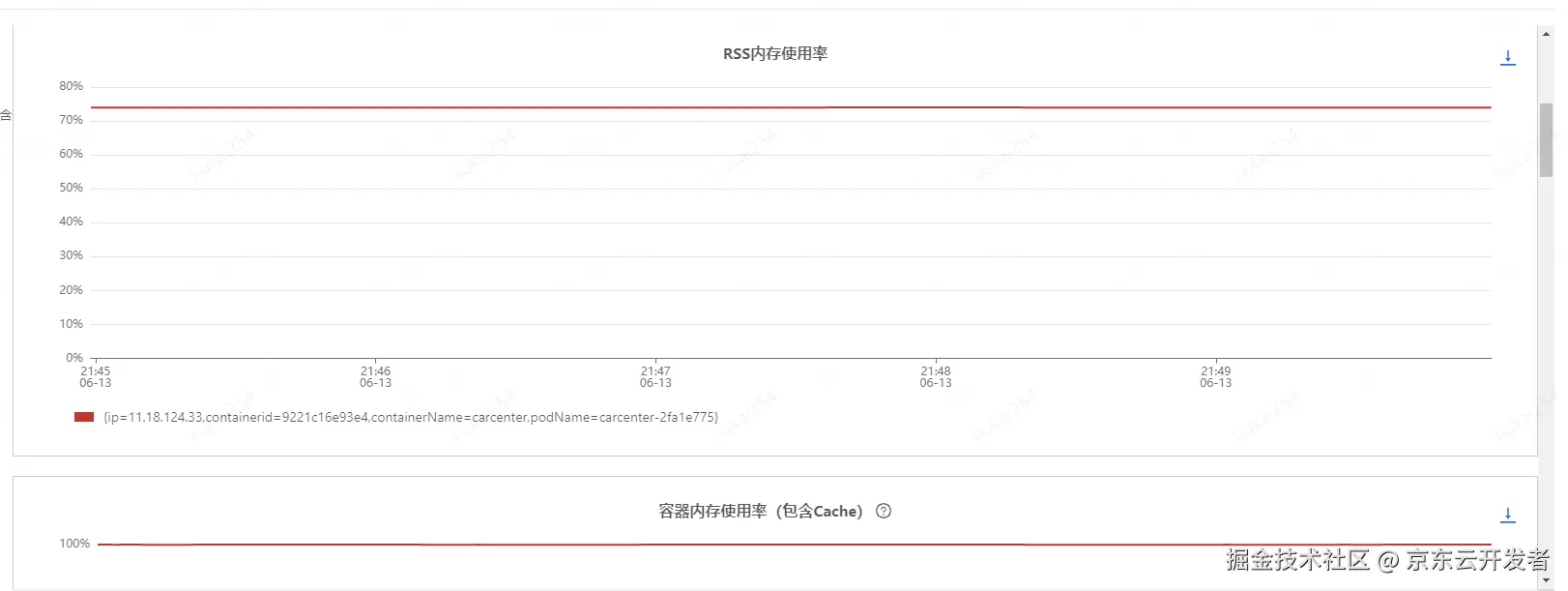
容器内存使用率(包含cache)基本一直保持在99%以上,建议先确定该指标的影响,并降低该指标
3.1.2 指标含义
指标定义文档解释如下
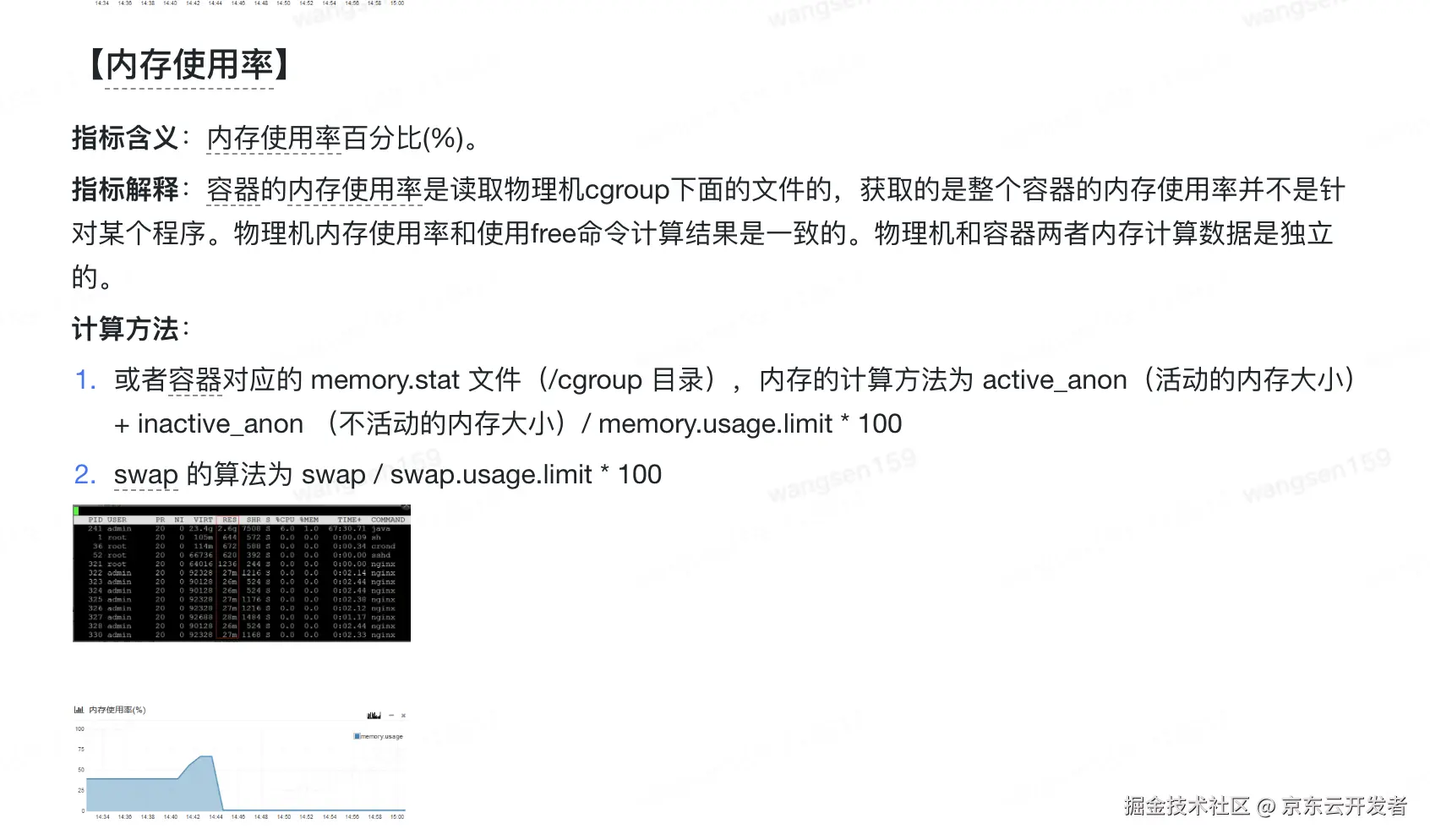
还是看不太懂指标的含义,懵B状态
提工单咨询,给出的解决方案如下

java应用,无ngix,还是懵,继续求助
最后得出结论:
这个之前在营销中心那边有遇到C++ 使用page cache 还有使用zgc的 需要参考一下cache这个指标,其他的场景 目前看 系统会在物理内存不够用的时候 释放cache;
这个是指有的c++应用底层接口直接使用了pagecache,java可以忽略
更详细解释:
内存那部分是这样的,每个容器的 Memory Cgroup 在统计每个控制组的内存使用时包含了两部分,RSS 和 Page Cache。
RSS 是每个进程实际占用的物理内存,它包括了进程的代码段内存,进程运行时需要的堆和栈的内存,这部分内存是进程运行所必须的。
Page Cache 是进程在运行中读写磁盘文件后,作为 Cache 而继续保留在内存中的,它的目的是为了提高磁盘文件的读写性能。(Java程序只要操作磁盘读写也会用到 page cache)
有时会看到这样一种情况:容器里的应用有很多文件读写,你会发现整个容器的内存使用量已经很接近 Memory Cgroup 的上限值了,但是在容器中我们接着再申请内存,还是可以申请出来,并且没有发生 OOM。那是因为容器中有部分是PageCache,当容器需要更多内存时,释放了PageCache,所以总大小并没有变化。
结论:对于java系统来说,容器内存使用率(包含cache)没有影响(cache会自动释放)
3.1.3 降低容器内存使用率(包含cache)
虽说没有影响,还是想办法降低试试效果(非常相信大佬)
看了其他几个java集群


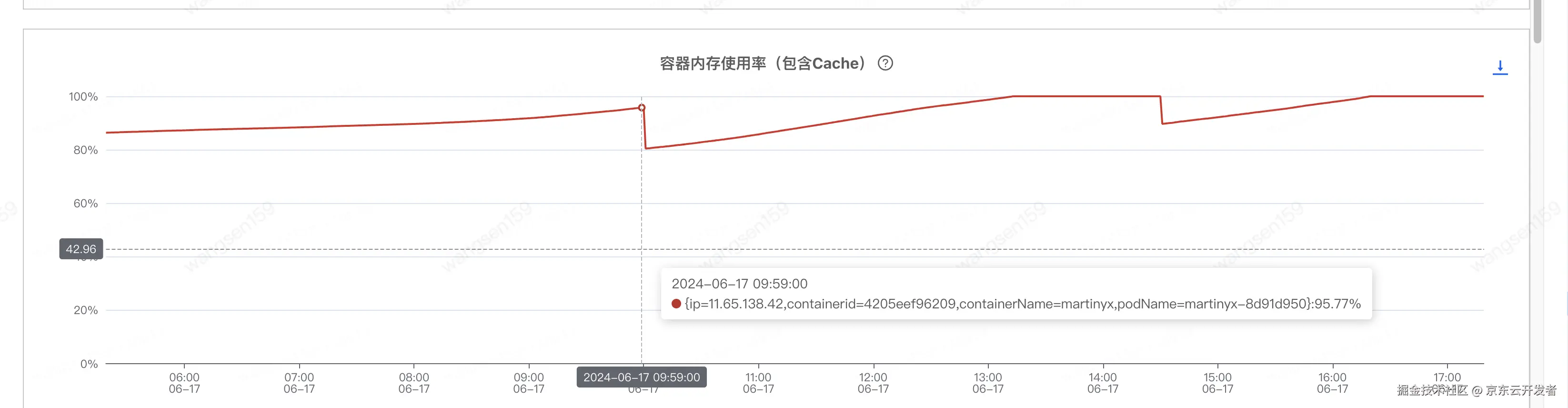
看到最后一个图,小小分析了下,发现三个小时会降低一波,正好和日志清除的时间间隔一致。
对提供方B清除日志后发现果然降低,如下
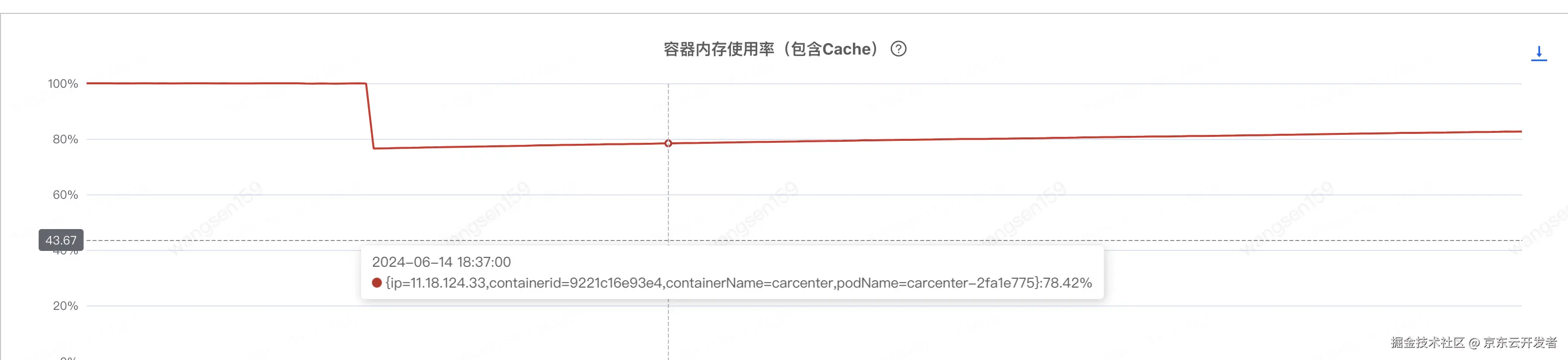
但是毛刺依然存在!!
3.2 容器处理性能瓶颈
扩容前,CPU和内存也处于正常水平
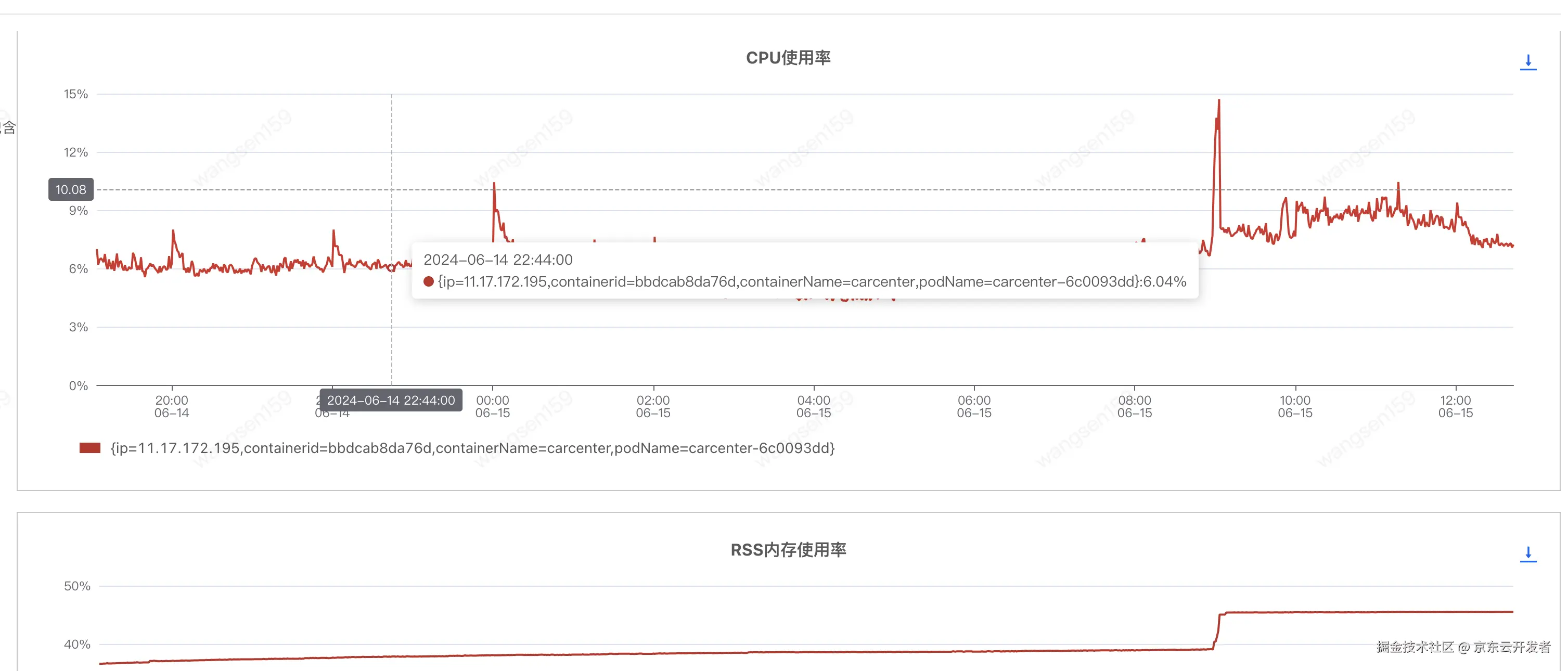
扩容后(汇天4台 -> 汇天8台),CPU和内存没啥太多变化
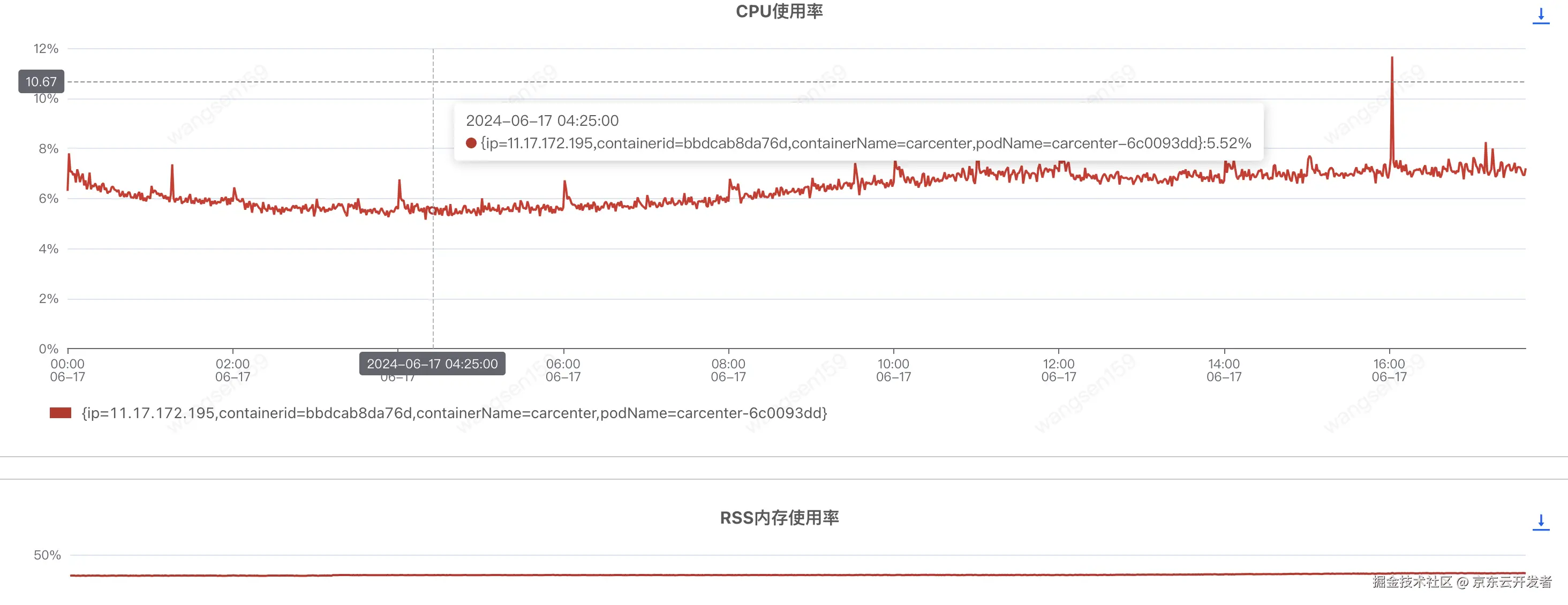
调用方耗时如下,基本没啥变化,头大
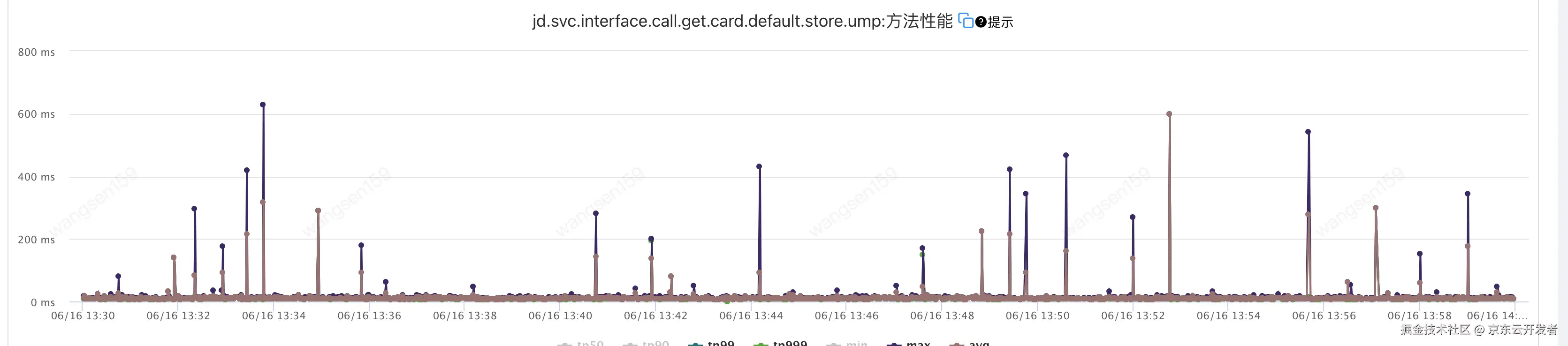
3.3 耗时分析
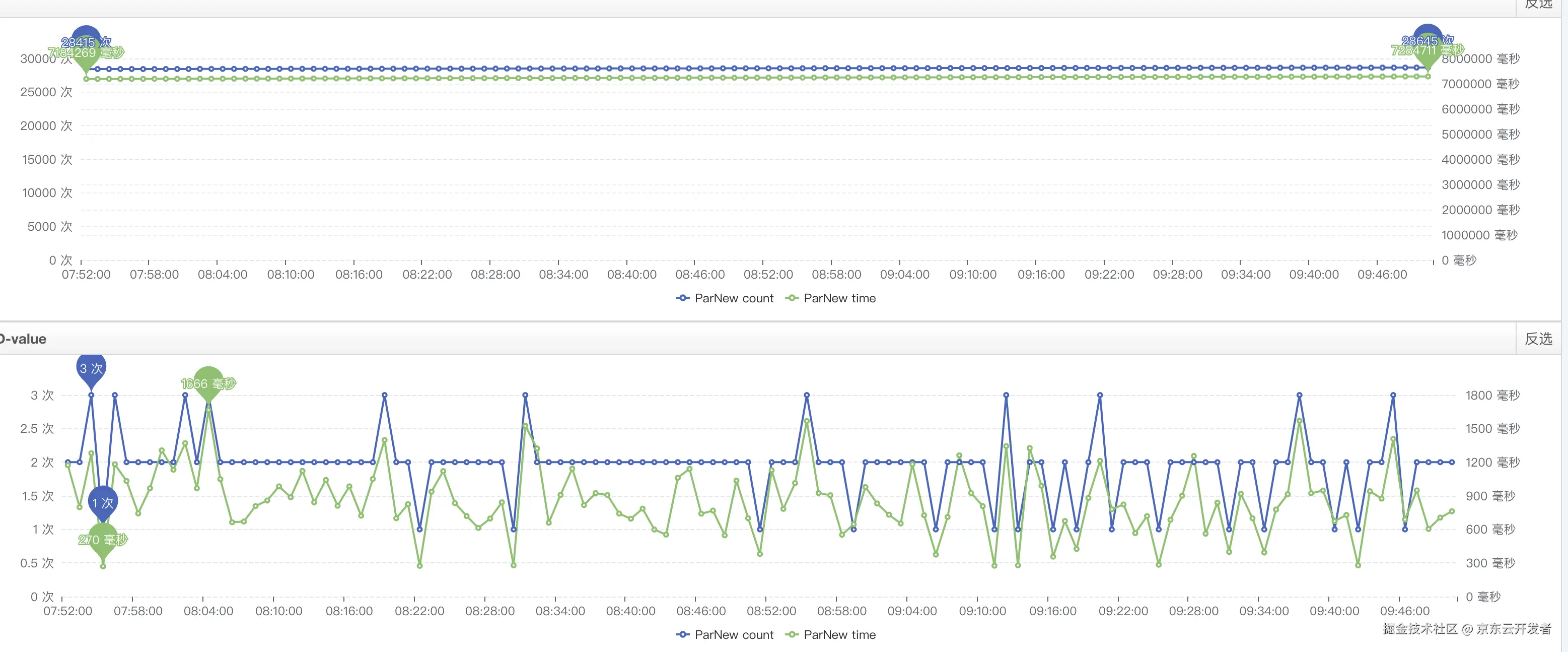
运维的同事帮忙分析了一波,给出年轻代GC耗时较高可能会影响耗时;如下
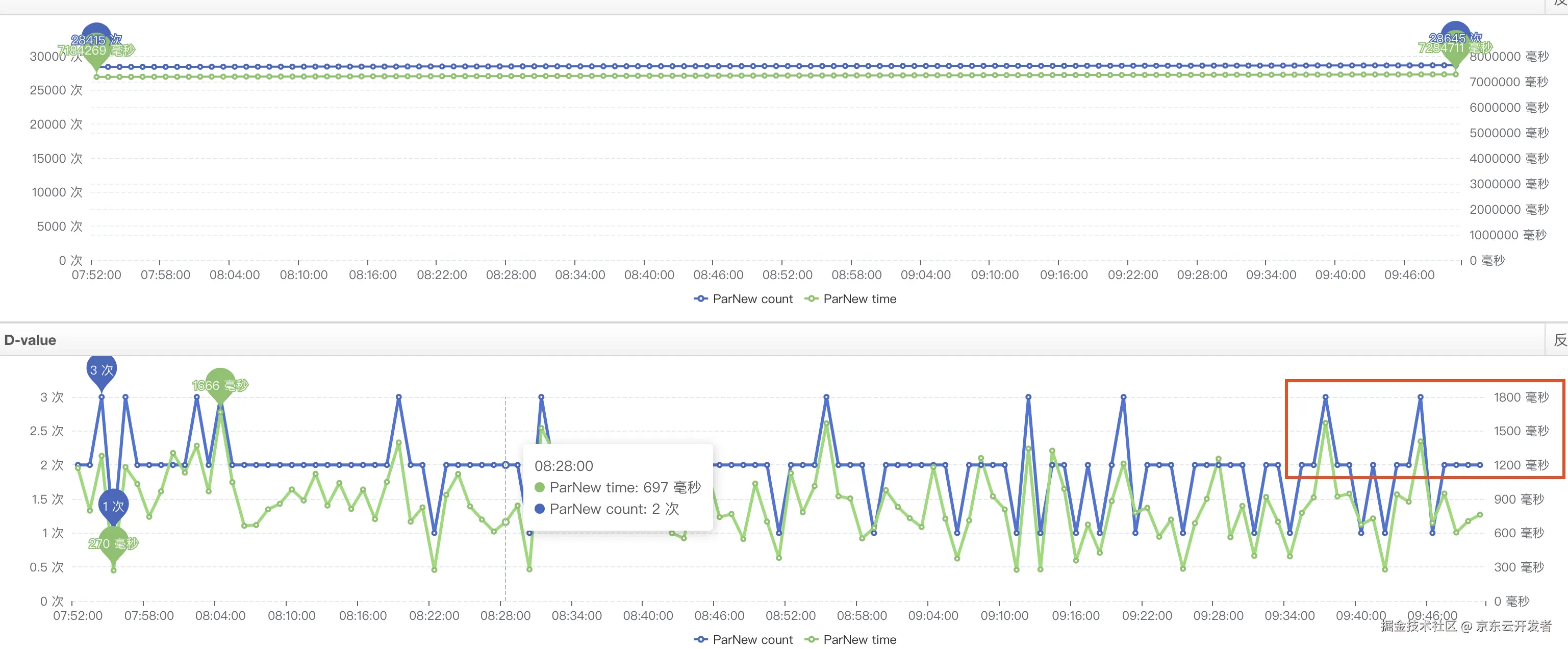
找了两个毛刺的数据,找到对应提供方的机器,查看那一分钟内有yanggc耗时(分钟的粒度),计算下来,调用方耗时比较接近 提供方耗时+提供方yanggc耗时,但是没有直接采取措施,主要一下原因
1.yanggc粒度比较粗,分钟级
2.一直认为FullGC会导致STW,增加耗时,yangGc不会有太大影响
3.只有一两次的数据分析,数据也没有那么准确
4.备战期间,线上机器封板,动起来比较麻烦,想找下其他原因,双管齐下
3.4 网络对抓 + PFinder
1.调用方多台机器,提供方也是多台机器,网络抓包要想抓全得N*M,比较费劲
2.PFinder也是随机抓包
3.毛刺也是随机产生的
想保证,抓到毛刺请求,且,PFinder有数据,采取如下对策
1.选择调用方的一台机器 X 提供方的一台机器,进行抓包
2.监控调用方的这台机器的UMP监控
3.调用方的UMP监控有毛刺时,查看是否有PFinder监控数据,如果没有则继续抓,有则停止
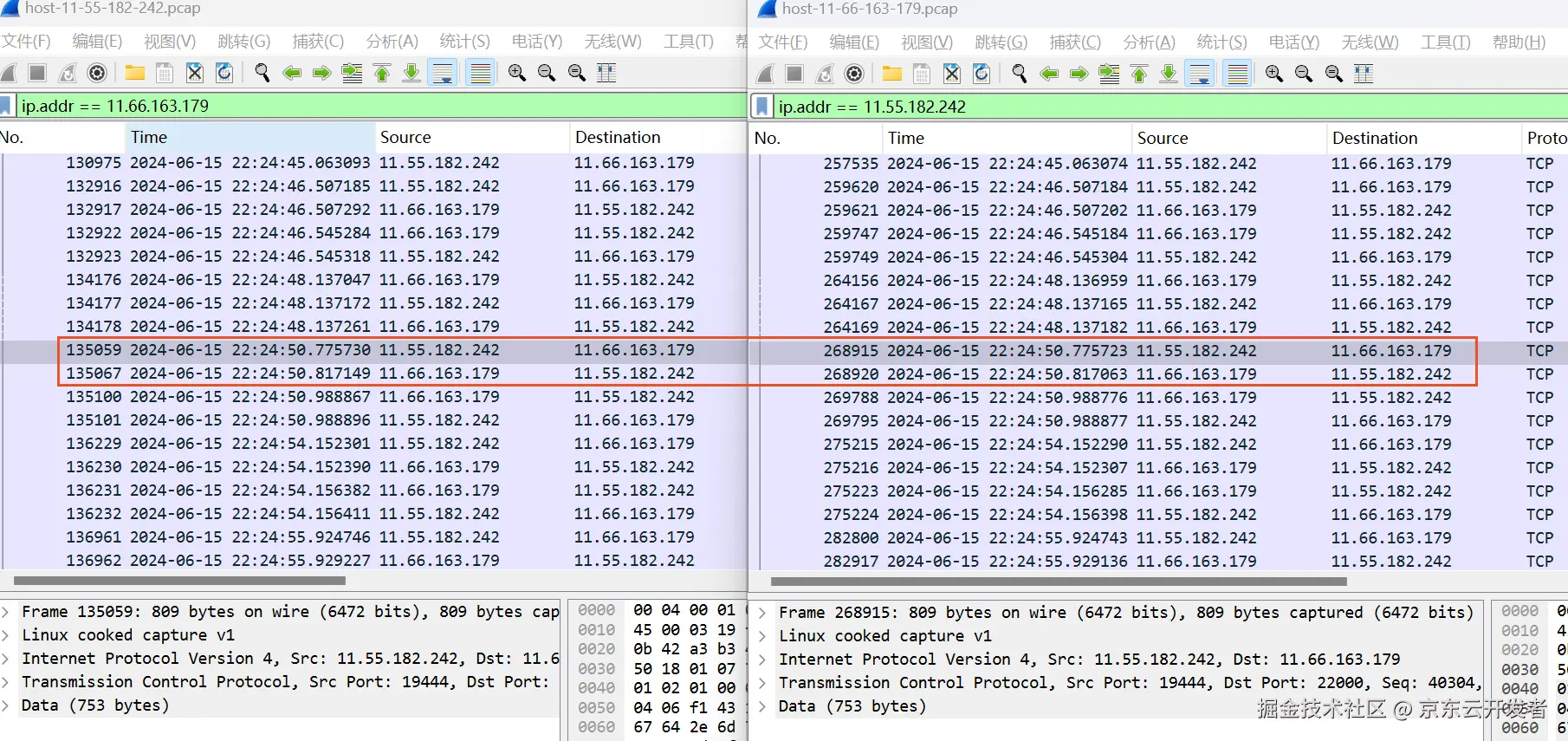
最后抓到了想要的数据
网络运维的同事帮忙对抓网络包,左边是调用方,右边是提供方,如下
调用方的PFinder的数据如下
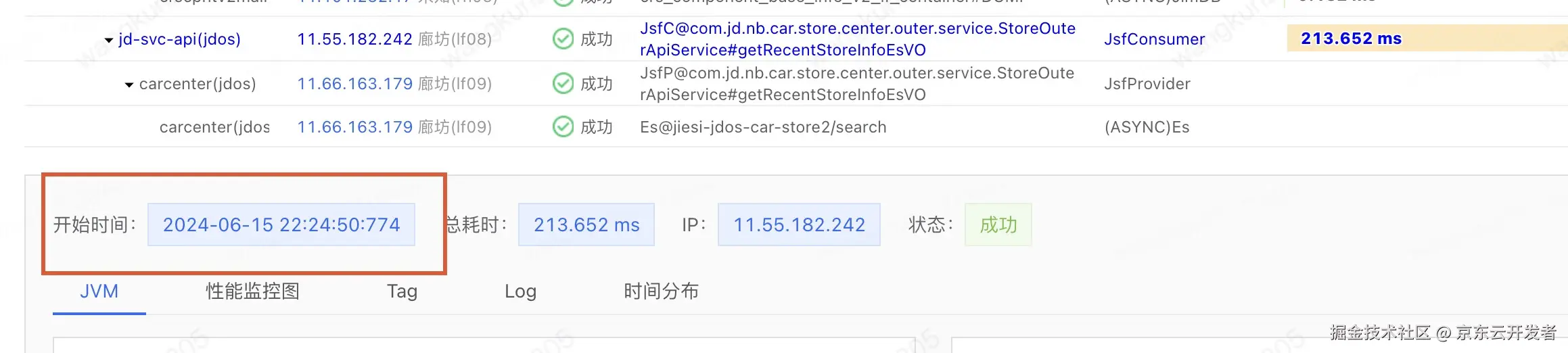
提供方代码开始PFinder的数据如下

数据分析后结论如下:
调用方22:24:50.775730 发出 22:24:50.988867收到 耗时213ms
提供方22:24:50.775723收到数据包,等到22:24:50.983才处理,22:24:50.988776处理结束回包
提供方等待208ms左右,实际处理4.55ms,加起来 213左右,和调用方耗时对应上了
网络抓包是从容器到容器的抓包
阻塞原因猜测:
1.容器瓶颈,处理不过来 - CPU、内存正常,且当天下午扩容一倍,没有明显好转
2.yanggc照成延迟 - 和运维同学张宪波大佬分析的不谋而合,且是有数据支撑的
4.处理
1.目的:降低yanggc耗时(没有FullGC)
2.当前:
3.方式:
1.增大堆内存(年轻代)
2.扩容(已经扩了一次,没有明显变化)
3.mq消费流量切到其他分组(一般先反序列化,根据参数过滤),减少新对象创建
4.结果:
调用方耗时如下
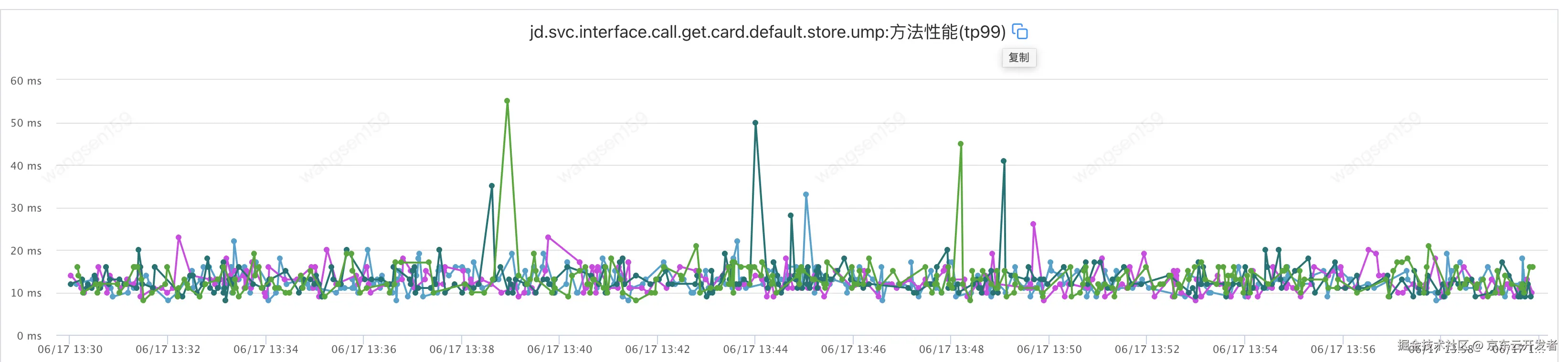
提供方耗时如下
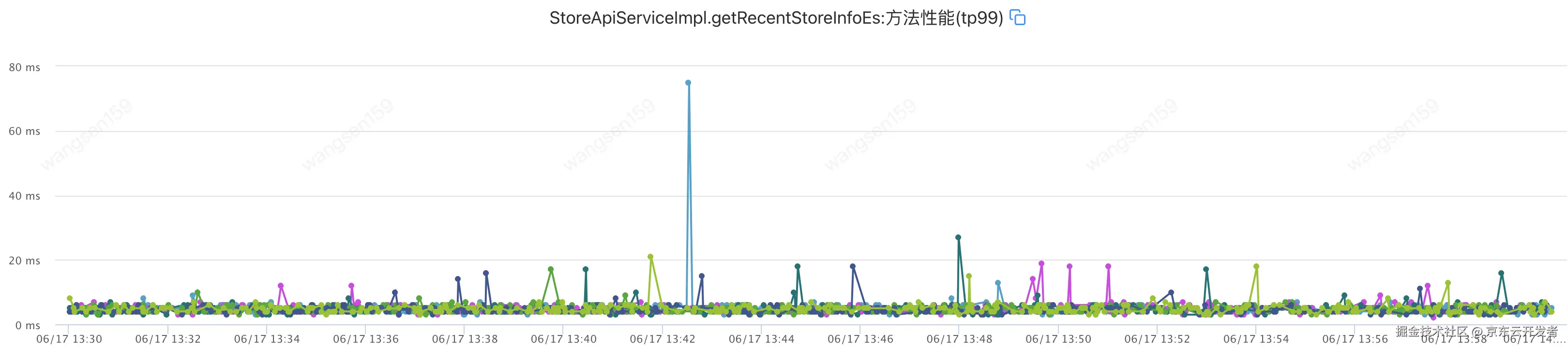
提供方yanggc
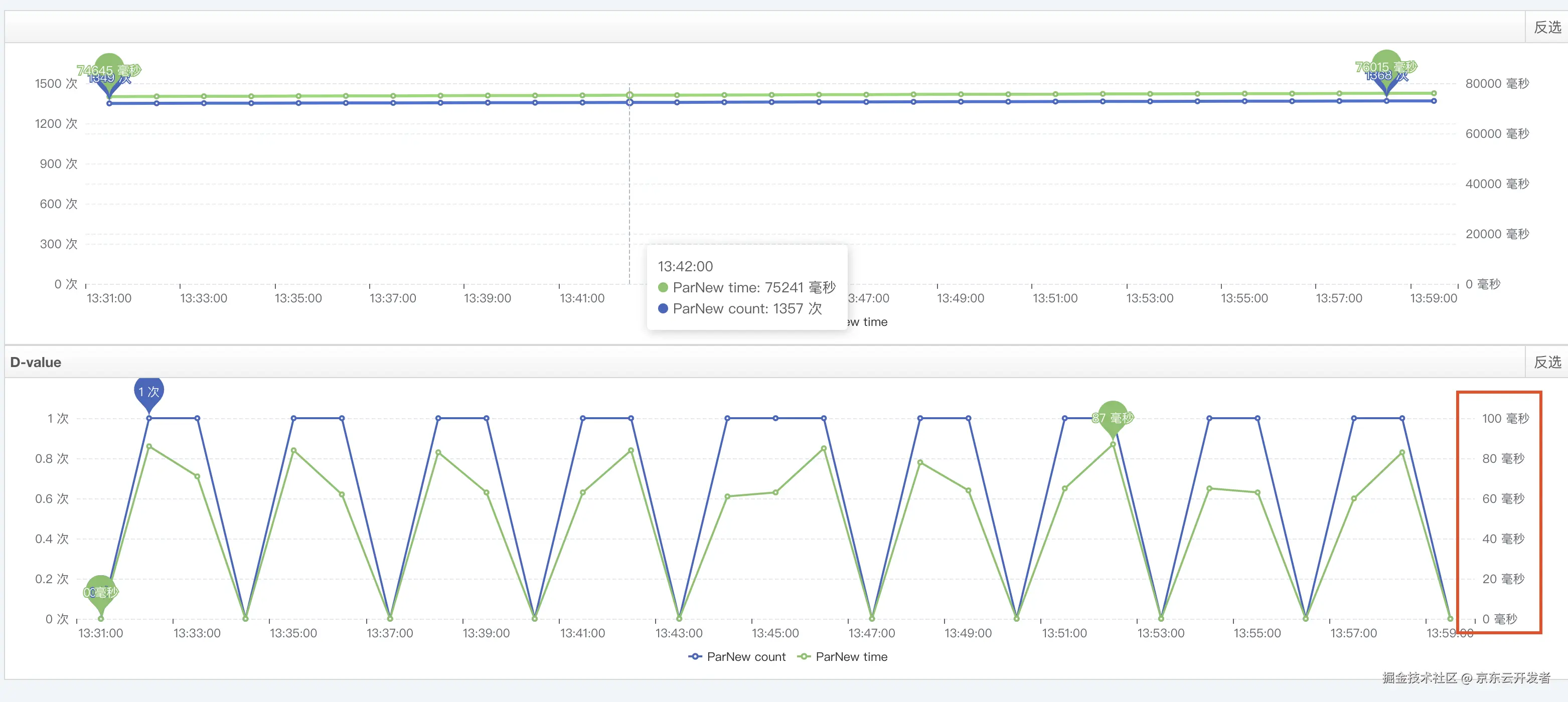
调整前后调用方耗时
最终提供方和调用方耗时不一致的问题得到解决