GPT-3 技术报告
原文《Language Models are Few-Shot Learners》, 22 Jul 2020
1. 摘要
1.1 NLP发展路径
-
早期: 静态词向量(Word2Vec, GloVe 等) → 输入到任务专用架构。
-
中期: RNN + 上下文表示,效果更强,但依旧要任务专用架构。
-
近期: 预训练Transformer / LM → 在下游任务上 微调,完全去掉任务专用架构。
1.2 现有模型局限
-
数据问题 :
- 每个任务都要成千上万的标注数据。
- 部分任务难以收集数据。
-
泛化能力差:
- 模型越大,越容易在窄分布上学到虚假相关性。
- 微调后的模型常常对分布外数据泛化不好。
- 在 benchmark 上表现"人类水平",但可能并不能真实泛化到任务本身。
- 与人类的差距:
- 人类不需要大规模标注数据。
- 人类只要一条自然语言指令,或者少量示例,就能学会任务。
1.3 研究动机
1.3.1 元学习
-
Meta-learning(元学习):Learning to learn,这里是在预训练中扩大预训练模型参数及数据规模,去掉对下游大规模标注数据和微调的依赖,学到一套通用的模式识别与技能。
-
In-context learning:在推理时(不更新参数),模型能通过指令上下文学习,模型利用输入序列里的任务说明/示例,快速适应任务,类似直接根据提示或少量示例完成Meta-learning(元学习)任务。
-
No prompt: 输入没有提示具体任务
py
输入:我喜欢猫。
输出:??? - Zero-shot:输入提示具体任务,但不给回答样例
py
输入:Translate Chinese to English: 我喜欢猫。
输出:I like cats.- One-shot / Few-shot:输入提示具体任务,给出1个或多个的回答样例
py
输入:
Translate Chinese to English: 你好 -> Hello
Translate Chinese to English: 我喜欢猫 -> ?
输出:
I like cats.本文概念:
-
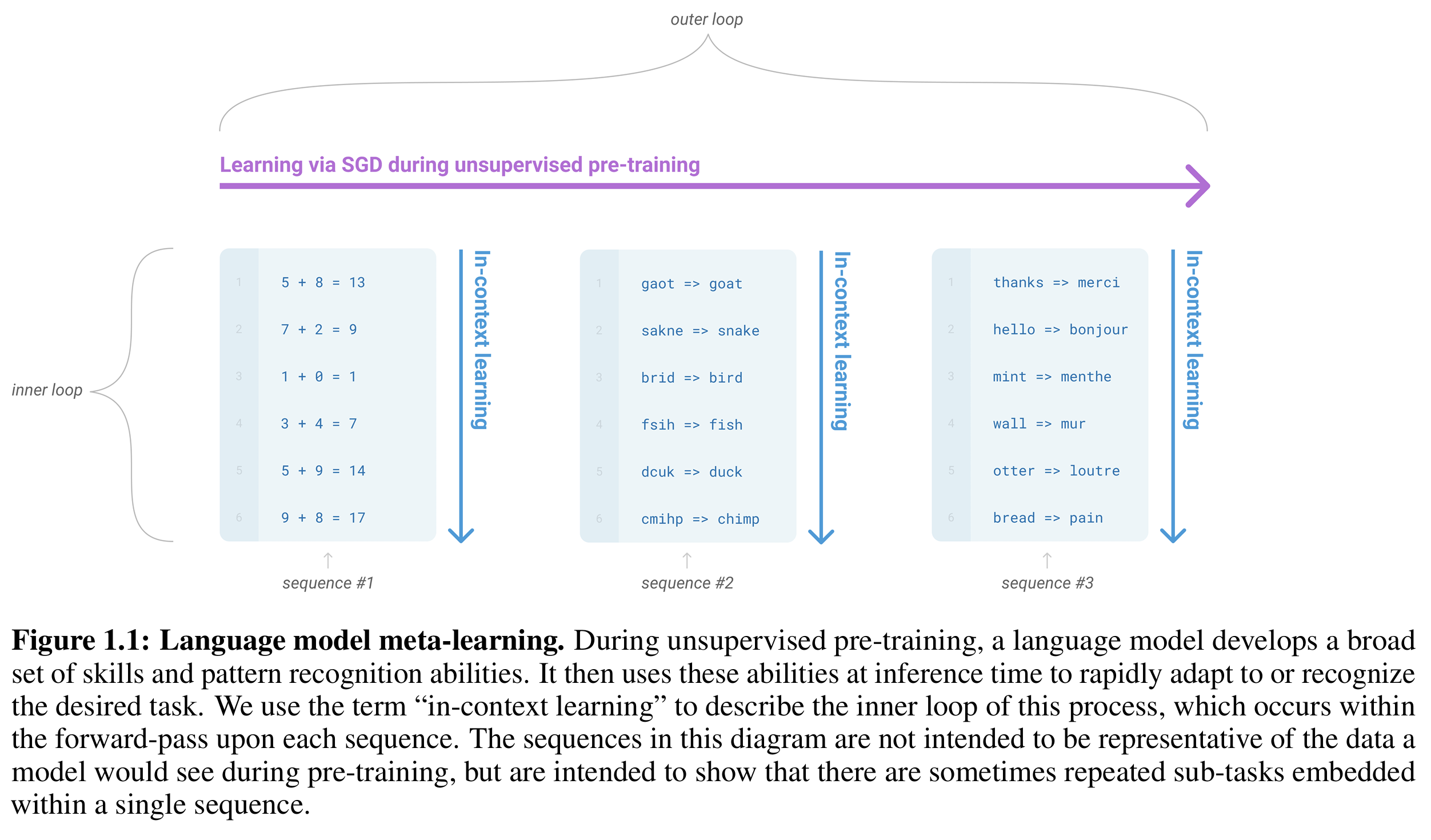
Outer loop 外循环(Unsupervised Pre-training): 语言模型在海量的文本数据上进行无监督预训练。在这个阶段,它不是学习某个特定任务(比如翻译或问答),而是发展出一套通用的、广泛的技能和模式识别能力(例如语法结构、世界知识、推理能力)。这相当于给大脑积累了大量的经验和工具。
-
Inner loop 内循环(In-Context Learning / Inference): 在模型被部署(推理)时,用户通过在输入序列中提供任务描述、示例或演示,模型就能立即适应或识别所需的任务,而无需进行传统的权重更新(即不进行微调/Fine-tuning)。这相当于大脑遇到新问题时,可以直接利用已有的工具和经验去解决,而不用重新学习。
如图1.1所示:
1.3.2 模型参数
模型参数越大,其"in-context learning curve" 越陡峭,说明更高效地从上下文信息中提取任务规律。
输入如下:
Task: Remove random symbols from the word. # natural language prompt
a#pp$le → apple
ba@n!ana → banana
gr@pe#s →如图1.2所示,无论给不给出任务描述(Task),大模型的上下文理解性能都随着参数增大而提升。
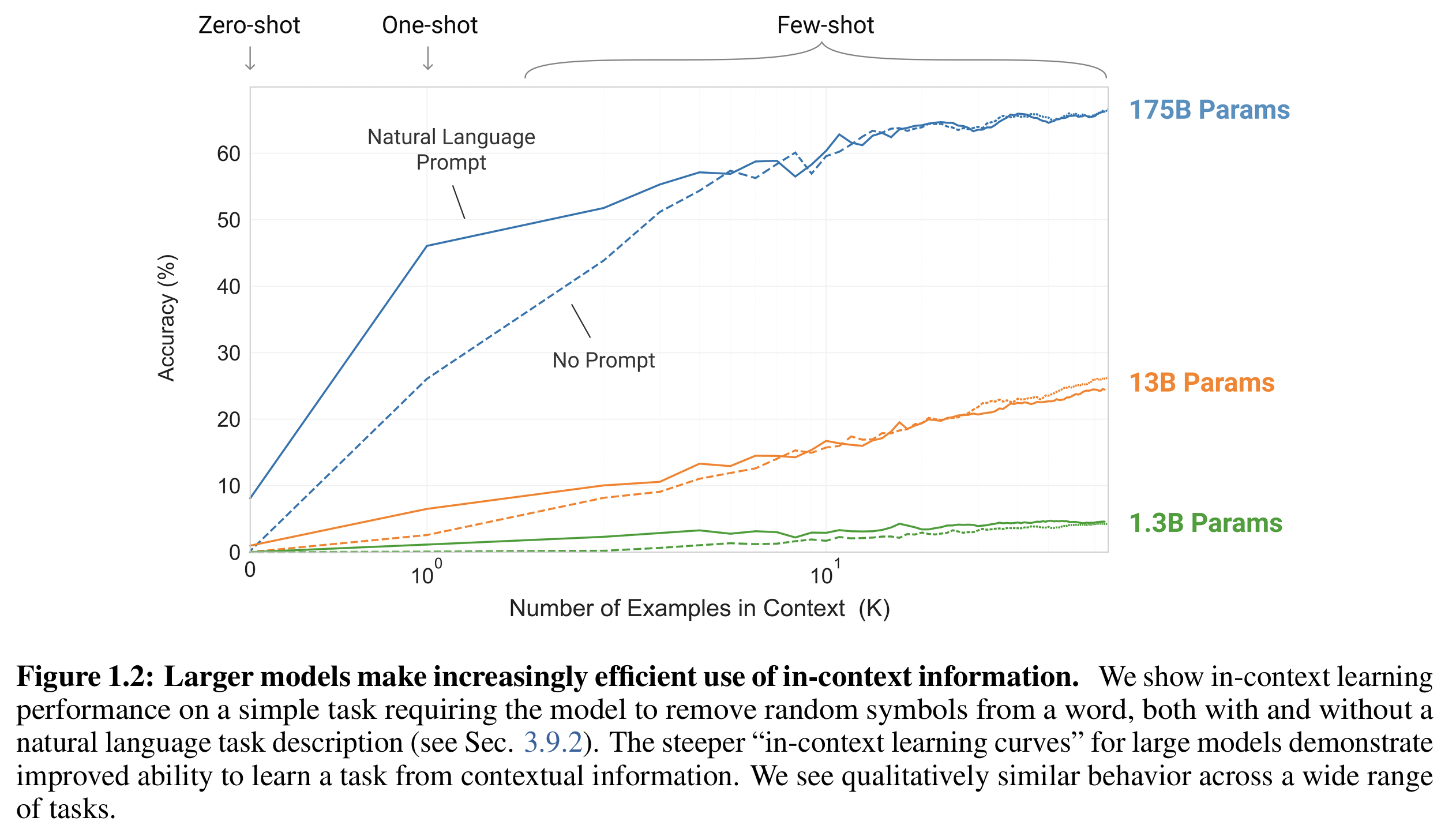
图1.3则是在42个不同benchmark的评测(基准),模型参数规模的增大(横轴), 模型的推理准确性提升
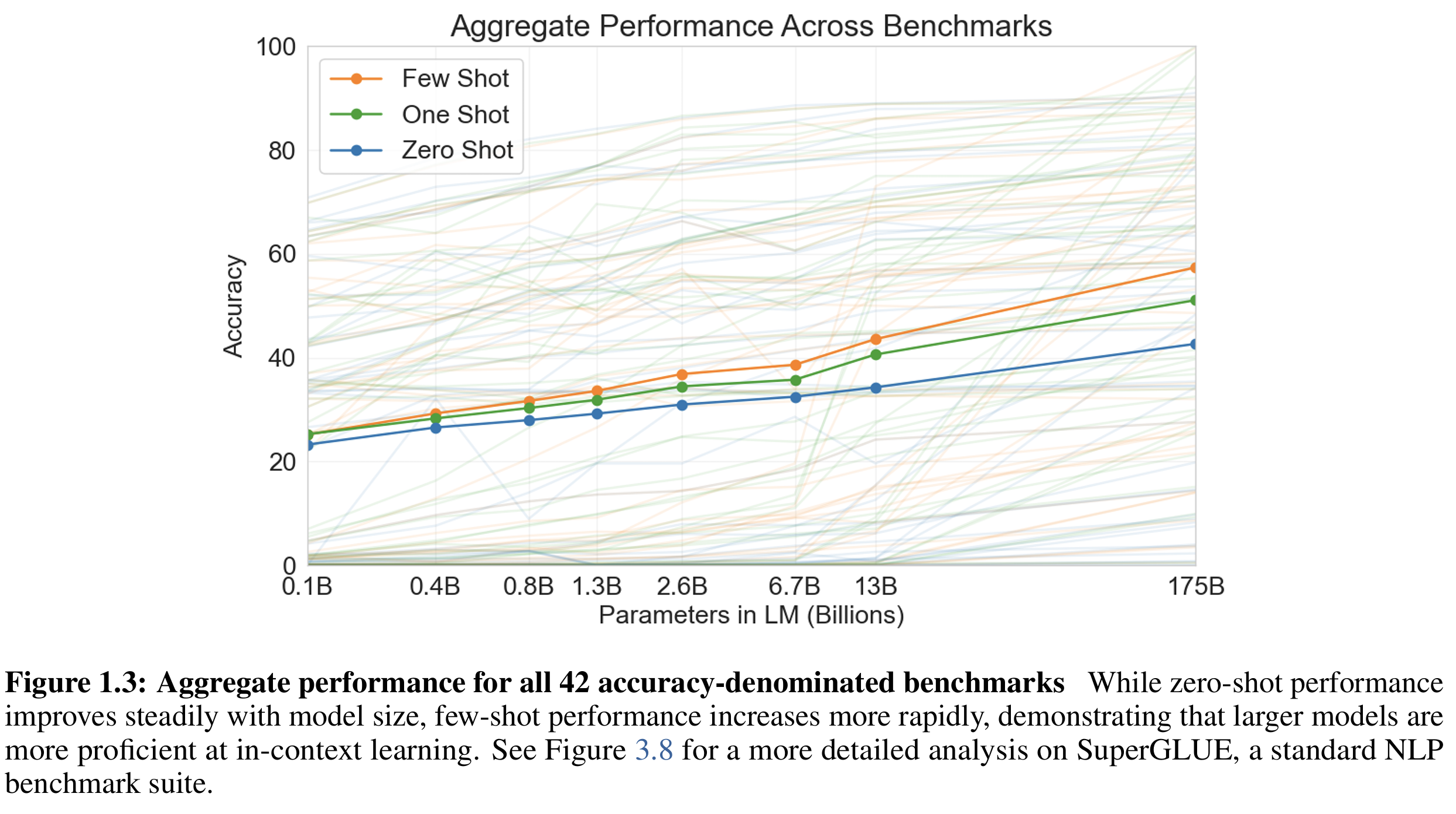
实验的结论:
- 零样本学习(Zero-Shot Performance): 仅提供任务描述,不提供任何示例,性能随着模型规模的增大而稳步提高。
- 少样本学习(Few-Shot Performance): 提供任务描述,并在输入中包含少量示例(即语境信息),性能随着模型规模的增大而更快速地提高(Increases More Rapidly),能在输入中看懂任务示例并泛化。
2.方法
GPT-3 的训练方法与 GPT-2 (最大1.5B) 类似,只是在模型规模、数据量、训练时长上进行了系统性扩大(scaling up)。
GPT-3 的创新在于,在 Fine-Tuning 之外开辟了 In-Context Learning(Few-Shot 和 One-Shot)这条道路,证明了通过缩放模型规模,可以使模型在不更新权重的情况下,仅凭语境信息就能有效地适应新任务,从而大大降低对昂贵、大量标签数据的依赖。
2.1 方法总结
-
Fine-Tuning (FT) - 微调
- 机制: 使用带标签的监督数据集来更新预训练模型参数。
- 数据量: 根据模型参数规模而定,通常需要数百到数万的带标签数据。
- 优点: 在大多数基准测试上能取得最优性能(State-of-the-Art)。
- 缺点:
- 高成本: 每个新任务都需要一个带标签数据集。
- 泛化性差: 可能对预训练模型分布外(out-of-distribution,ood)数据表现不佳。
- 意义: GPT-3 不使用微调,其重点是任务无关(task-agnostic)的推理性能,但原则上 GPT-3 可以被微调。
-
Few-Shot (FS) - 少样本学习
- 机制: GPT-3 重点研究部分。模型在推理时被赋予 K 个任务演示(即给出少量示例)作为语境(Context)提示,但更新模型权重。
- 数据量 (K):模型上下文窗口(nctx = 2048 tokens)的容纳范围内, K 通常为10 到 100 。
- 数据形式: 输入序列包含 K 对"语境+期望的完成"(例如:English → French),然后是一个新的"语境",要求模型给出完成。
- 优点:
- 大幅减少对任务特定数据的需求。
- 减少了模型从狭窄的微调数据集中学习到过度狭隘分布的风险。
- 缺点: 到目前为止,性能通常不如最先进的微调模型,并且仍需要少量任务特定数据。
-
One-Shot (1S) - 单样本学习
- 机制: 与少样本类似,但只允许提供一个任务演示示例,以及任务的自然语言描述。
- 目的: 这种设置最接近人类被告知新任务的方式(例如,在众包平台(如 Mechanical Turk)上,通常只给一个例子来解释任务)。
- 意义: 区分单样本是为了强调在没有示例的情况下,仅通过自然语言描述来传达任务的内容或格式有时是很困难的。
-
Zero-Shot (ZS) - 零样本学习 (无数据依赖)
- 机制: 模型在推理时只提供任务的自然语言描述,不提供任何示例(Context, Task)。
- 优势:
- 零样本提供了最大的便利性、潜在的鲁棒性。
- 尽管有挑战,被认为是最公平的人类性能比较基准,是未来研究的重要目标。
- 意义: 这是对模型通用知识和指令遵循能力的纯粹测试。是最具挑战性的设置("most challenging setting"),某些情况下,即使是人类也难以在没有示例的情况下理解任务的格式(format)或内容(content)。
区别如图:

2.2 模型结构
2.2.1 模块
基本沿用 GPT-2 的 Transformer-decoder 模型, 包括:
- 单向自注意力(causal attention)
- 层归一化(pre-normalization, 放在输入端)
- 可逆分词器(byte-level BPE)
- 位置编码 (learned positional embedding)
注意力机制改进: 密集(dense attention)和局部带状稀疏(locally banded sparse attention)的注意力交替实现,类似于 Sparse Transformer,以减少计算复杂度,提升长上下文计算效率。
2.2.2 参数规模
8 个不同规模的模型,具体如表2:
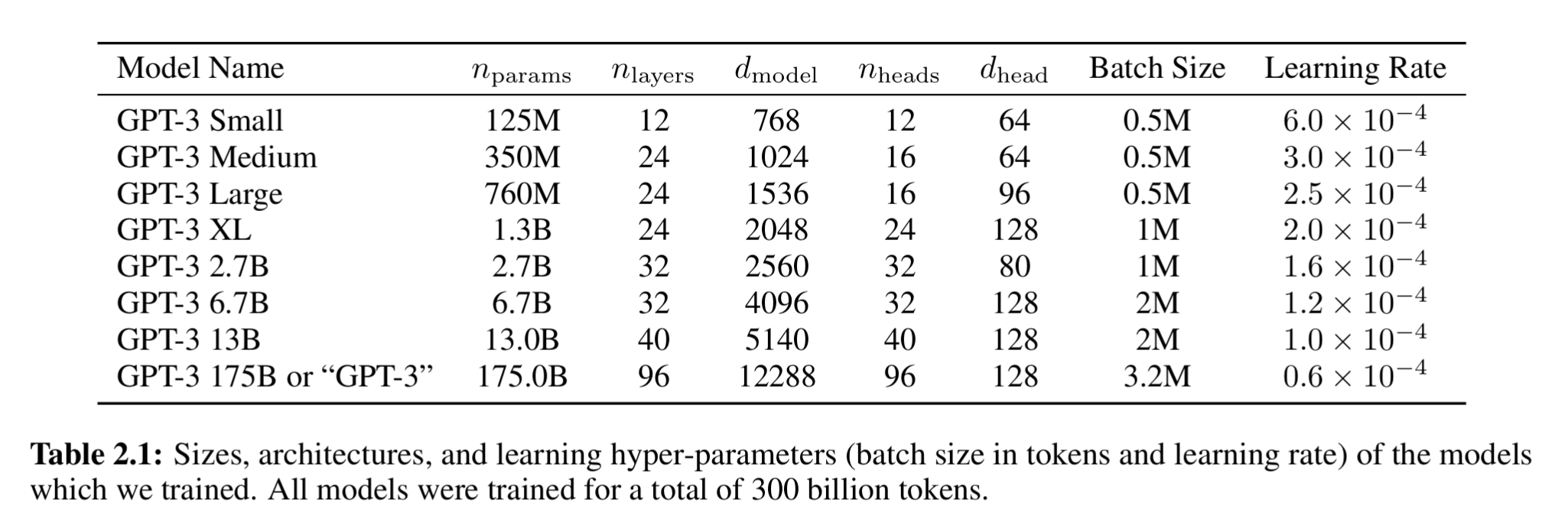
相比GPT-2的最大参数1.5B,跨越三个数量级,从 1.25 亿到 1750 亿。其中,最大的 1750 亿参数的模型被称为 GPT-3。
- 参数解析:
py
n_params = [0.125B, 175B] # 模型可训练参数总量(trainable parameters) ,其与 n_layers * d_model^2成正比
n_layers = [12, 96] # Transformer Block 的层数, 即 self-attention + FFN 的堆叠数量
d_model = [768, 12288] # 瓶颈层(Bottleneck Layer)维度,通常指 Transformer Block 中自注意力(Self-Attention)的维度,包含其线性层的输入/输出/隐藏 三个 维度。
n_heads = # 注意力头数, 通常 d_model =n_heads × d_head
d_head = d_model / n_heads # 每个注意力头的维度(Dimension of each attention head)
nctx = 2048 # context window 上下文窗口, 最大输入tokens, 若文档太短就将多个文档拼接成一个 2048-token 长序列;不额外遮掩 (mask),只用 end-of-text token (<eot>) 来分隔,让模型能学到"句子间无关联"的语义分割;
FNN = 4×d_model #前馈层(Feedforward Layer)的隐藏单元数, 其通常为2层FC, 维度为 [d_model, 4×d_model] (论文明确指出,它始终是瓶颈层大小的四倍)。2.2.3 训练参数
-
BatchSize
-
小 Batch Size 方差较大,模型容量有限,计算出的梯度偏差大(方差)。高学习率可以帮助缓解方差过大,快速探索参数空间。
-
大 Batch Size 方差减小,模型容量更多,梯度方向更接近真实梯度。使用高学习率会导致训练发散或震荡(尤其在 LayerNorm 和 Attention 的深层堆叠下),错过最优解。
-
GPT3: 起始 batch 很小(32K tokens);逐步线性增大到完整 batch(0.5M ~ 3.2M tokens,取决于模型大小);增长阶段持续 4--12B tokens。小 batch 有助于早期学习稳定;随着模型熟化,增大 batch 可以提高计算效率和收敛速度,本质上是一种「渐进式 batch scaling」。
- Adam 优化器:
- β₁ = 0.9:控制一阶动量(梯度平均的平滑度);
- β₂ = 0.95:控制二阶动量(梯度方差的平滑度,);
- ε = 1e⁻⁸:防止除零;
- Gradient clipping (Norm)= 1.0:将所有梯度的 L2 范数限制在 1.0 以内,防止梯度爆炸。
GPT-3 的β₂ 取 0.95 而非常见的 0.999。原因是 β₂ 越大,二阶动量更新越慢,而大模型中梯度分布变化较大,因此用 0.95 让优化器"响应更快",改善早期training的收敛性。
-
学习率调度(Learning Rate Schedule)
-
Warmup phase(前 0.375B tokens)
- 学习率从 0 线性上升到目标峰值;
- 在早期阶段需要较大学习率快速适应; 防止初期梯度不稳定或 LayerNorm 崩溃;
-
Cosine decay phase
- 从LR峰值目标开始,随训练进程余弦衰减;
- 当训练到 260B tokens 时,学习率降到 原始值的 10%;
- 余弦衰减(cosine annealing)可让下降过程平滑、无突变,保证模型从"探索"阶段过渡到"收敛"阶段
-
Tail phase:
- 之后继续以 10% 的学习率 训练到总 300B tokens。
- 后期保持较小LR步长进行 fine-tuning 式微调。
-
-
正则化(Regularization)
- 权重衰减系数较小, weight decay=0.1;
- 给参数增加轻微惩罚,防止过大权值;对语言模型主要是防止过拟合和过度自信输出。
-
数据: 所有模型都训练 300B tokens,以验证"Scaling Law"是否成立:
模型越大 → 验证集 loss 越平滑下降(power-law规律)。
-
模型并行化(model parallelism)
微软提供的高带宽v100-gpu服务器集群
-
pipeline parallelism: 把 Transformer 层在不同 GPU 间分配。例如前 20 层在 GPU1,后 20 层在 GPU2。
-
width dimension: 单层的矩阵运算(如大矩阵乘法)分拆到多个 GPU。→ 称为 tensor parallelism 或 intra-layer model parallelism。
-
即在 GPU 集群中按"深度 + 宽度"分割网络结构,最大化显存利用、最小化通信,是 Megatron-LM 与 DeepSpeed 的并行策略雏形。
- 参数规则
模型的层数、头数、维度等参数并不是"精确调优"得到的,而是保证训练资源高效利用的前提进行设置。
根据《Scaling Laws for Neural Language Models (KMH+20)》的结论:
* 模型大小、训练数据量、计算量之间呈 平滑的幂律关系;
* 在"合理范围"内,调整超参并不会对 验证集损失 产生明显变化 (例如 不同 n_heads / d_head 配置)。- 总结
- 刚开始(warmup 阶段前 3.75 亿 tokens):学习率从 0 线性上升;
- 到达 峰值 (lr_max);
- 之后使用余弦函数平滑下降;
- 最终下降到 0.1 × lr_max;
- 最后(260B--300B tokens)继续保持该较低学习率。
3. 数据
数据集的多样性和质量对模型的泛化能力至关重要。
GPT-3的训练数据集:数据量足够大,保证每个序列几乎不会重复出现;
3.1 数据预处理
采用构建、过滤和混合来预处理数据集,原则是质量优先于数量:
步骤 细节 内在联系/目标
- 过滤 Common Crawl 根据一系列高质量参考语料库(WebText2, Books1/2, Wikipedia-En)的相似性对 Common Crawl 进行过滤。初始 45TB 文本被过滤后仅剩 570GB(约 4000 亿 BPE tokens)。 质量控制:消除低质量、重复或非结构化的网页内容。目标是让 Common Crawl 部分更像 WebText 等高质量数据。
- 模糊去重 (Fuzzy Deduplication) 在文档级别(数据集内部和跨数据集)进行去重。 防止冗余和评估完整性:防止模型多次学习相同信息,保护验证集(held-out validation set)的完整性,确保准确衡量模型过拟合程度。
- 混合高质量语料 在训练数据混合中加入已知的、精心策划的高质量数据集(WebText2, Books1/2, Wikipedia-En)。 增加多样性和质量:弥补 Common Crawl 过滤后仍可能存在的质量不足,并确保模型接触到多种类型的权威性文本(书籍、百科知识)。
3.2 数据采样策略
训练数据采样迭代次数:
- 高质量语料(WebText2、Books1)被重复采样 2--3 次;
- Common Crawl 及 Books2 则低于 1 次。
具体分配见表2.2:
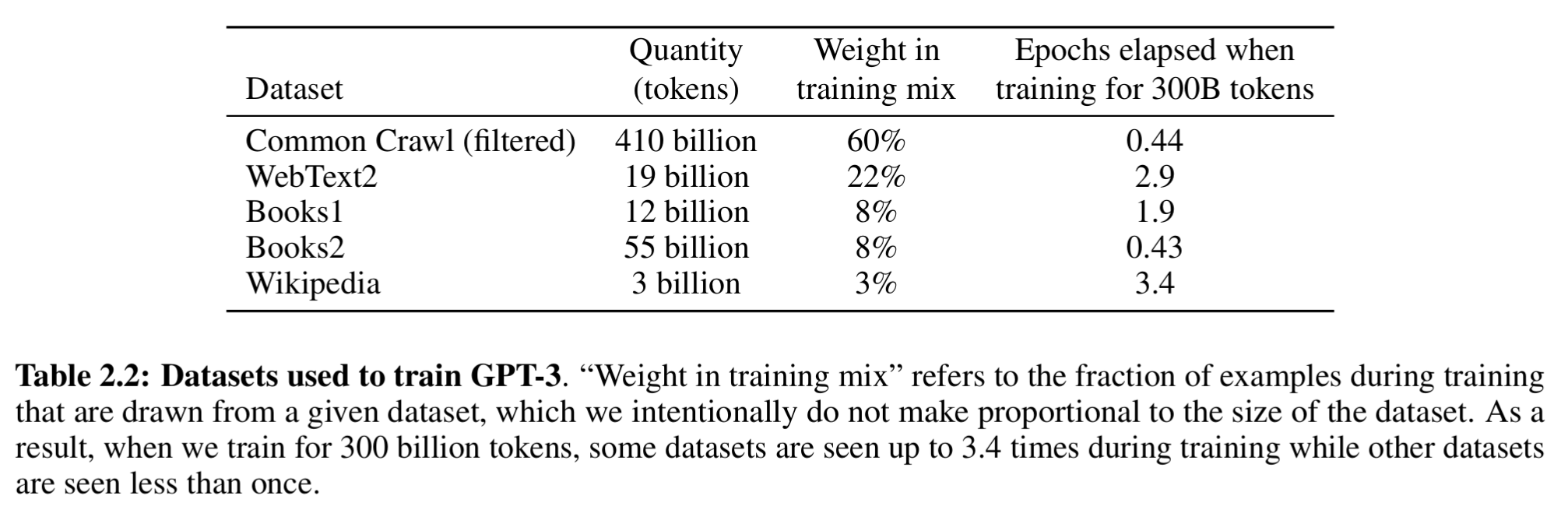
该策略目的:
接受少量过拟合风险,以换取更高的语料质量。确保模型接触更多高质量文本,提高泛化能力。
4.计算量分析
4.1 模型总计算量
- FLOP = FLoating-point OPeration,浮点运算次数(加减乘除等算术运算)。
| 单位 | 含义 |
|---|---|
| 1 FLOP | 计算器完成1次浮点运算次数 |
| 1 GFLOP | 10^9 FLOPs ≈ 一秒钟完成十亿次浮点运算 |
| 1 TFLOP | 10^12 FLOPs ≈ 一秒钟完成万亿次浮点运算,顶级游戏显卡每秒运算能力 |
| 1 PFLOP | 10^15 FLOPs ≈ 一秒钟完成千万亿次浮点运算,超级计算机每秒运算能力 |
- PF-days = 1 PFLOP(Petaflop) 计算机连续运行一天(24小时, 86400秒)所完成的计算量。
换算公式:
1 PF-day =10^15 FLOPs/sec × 86400 sec = 8.64 × 10^19 FLOPs
50 PF-days 意味着训练模型所需的总计算量等于一台 1 Petaflop/s 计算机连续运行 50 天的总计算量,而GPT-3 175B 训练消耗 3,640 PF-days。
各模型消耗的对比如图2.2:
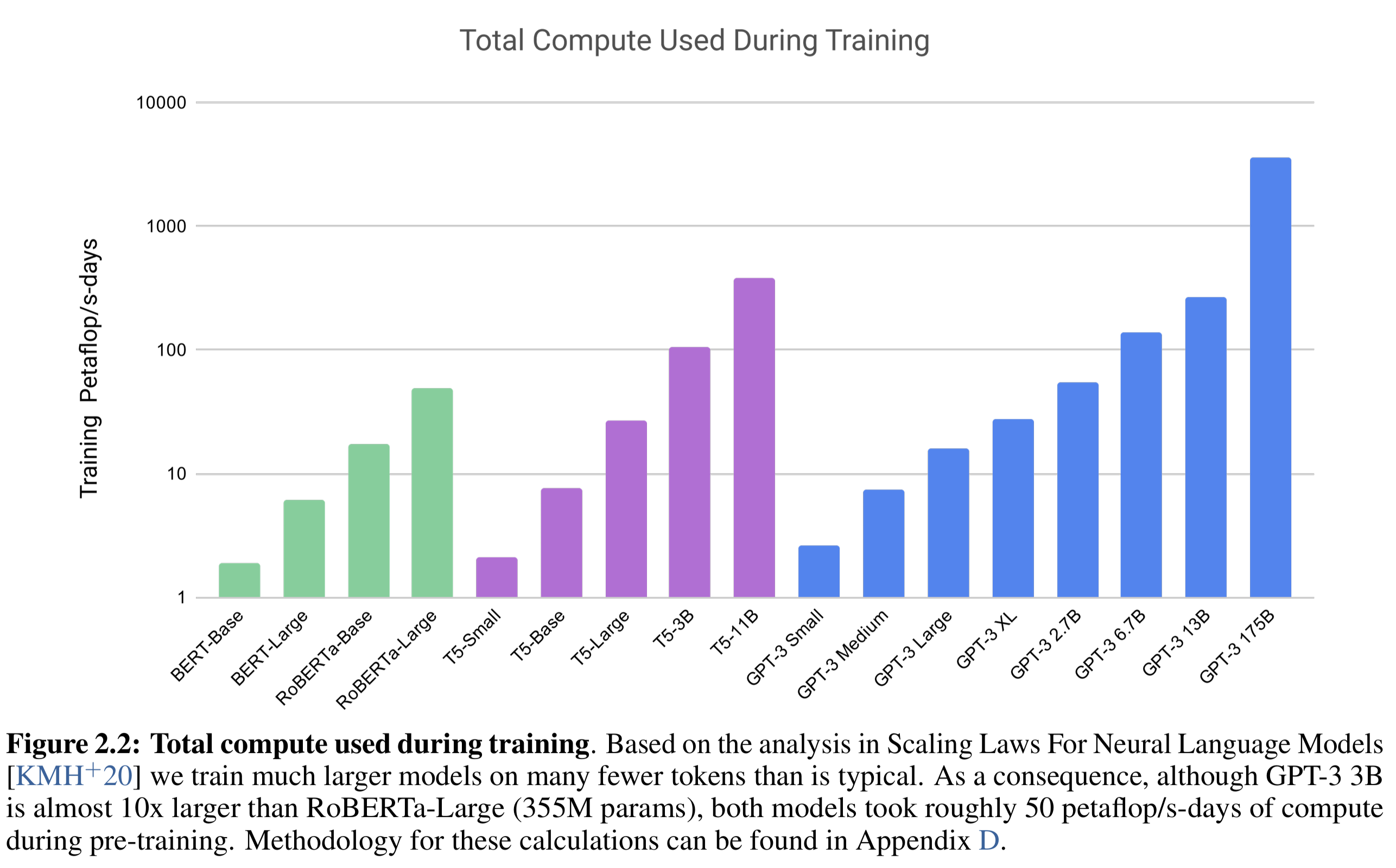
图2.2的具体数据参见表D.1:
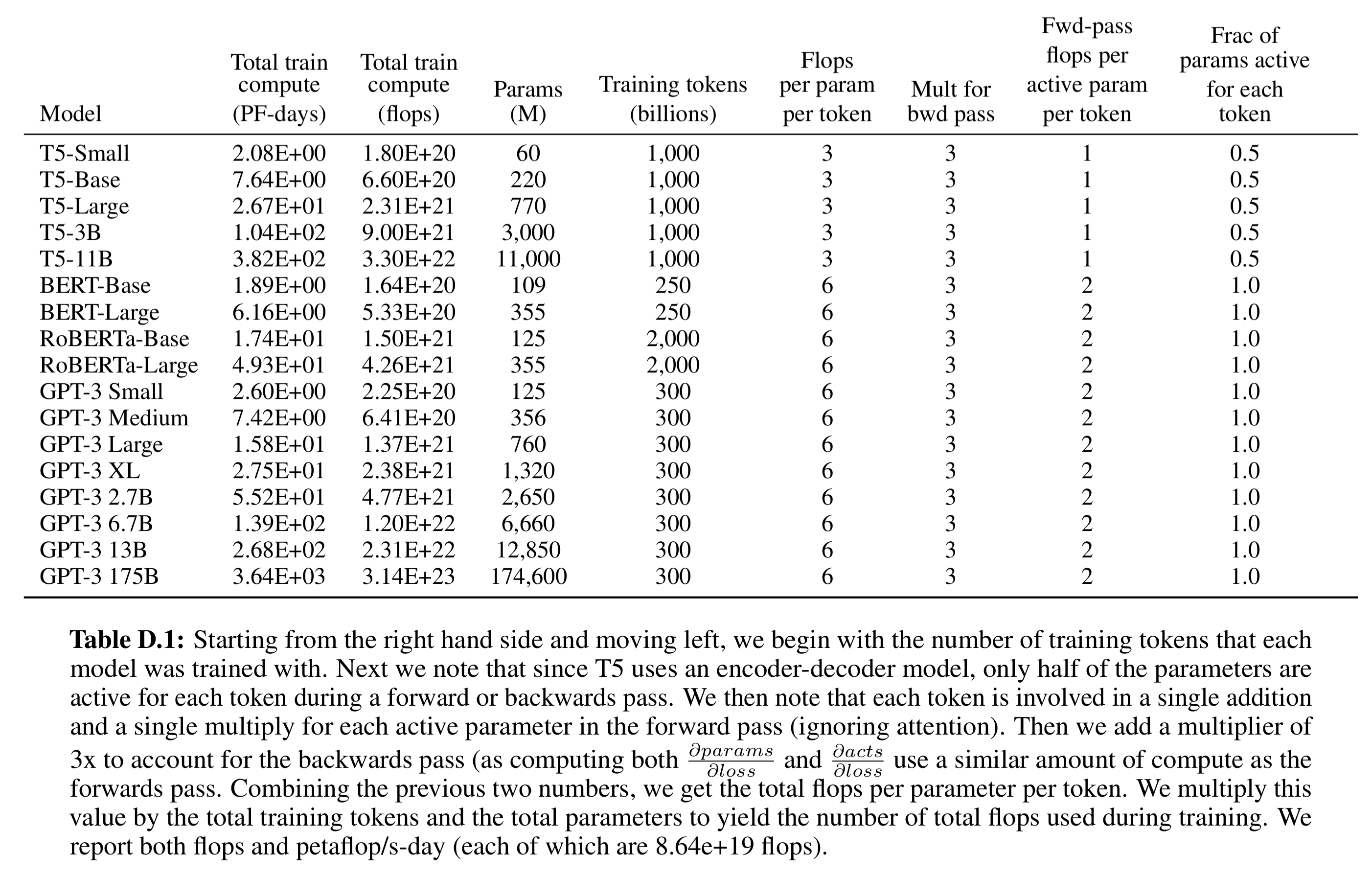
- 表格单位解析:
| 字段 | 含义 |
|---|---|
| Totaltrain compute (PF-days) | 训练所需总算力,单位 petaflop/s-day |
| Totaltrain compute (flops) | 训练总浮点运算次数 |
| Params (M) | 模型参数数量(百万) |
| Training tokens (B) | 训练 token 数量(十亿) |
| Flops per param per token | 每个参数每个 token 的 FLOPs(不计 backward multiplier) |
| Fwd-pass flops per active param per token | 每个 token 的前向计算 FLOPs(忽略 attention) 矩阵乘法中的一次乘 + 一次加 |
| Mult for bwd pass | backward pass 的 FLOPs multiplier, 代表反向传播中计算参数梯度和激活梯度所需额外计算 |
| Frac of params active for each token | 前向/反向时活跃参数比例(encoder-decoder 模型 T5=0.5,其余=1) |
4.2 幂律关系(power law)
Figure 3.1 为多模型训练曲线, 展示8 个前述模型(从0.125B 到 175B 参数)以及 6 个更小模型的训练表现。
训练性能(以验证集交叉熵 loss 表示)与计算量呈 幂律关系。
即便参数规模扩展两个数量级,依然保持幂律趋势,仅有微小偏离。
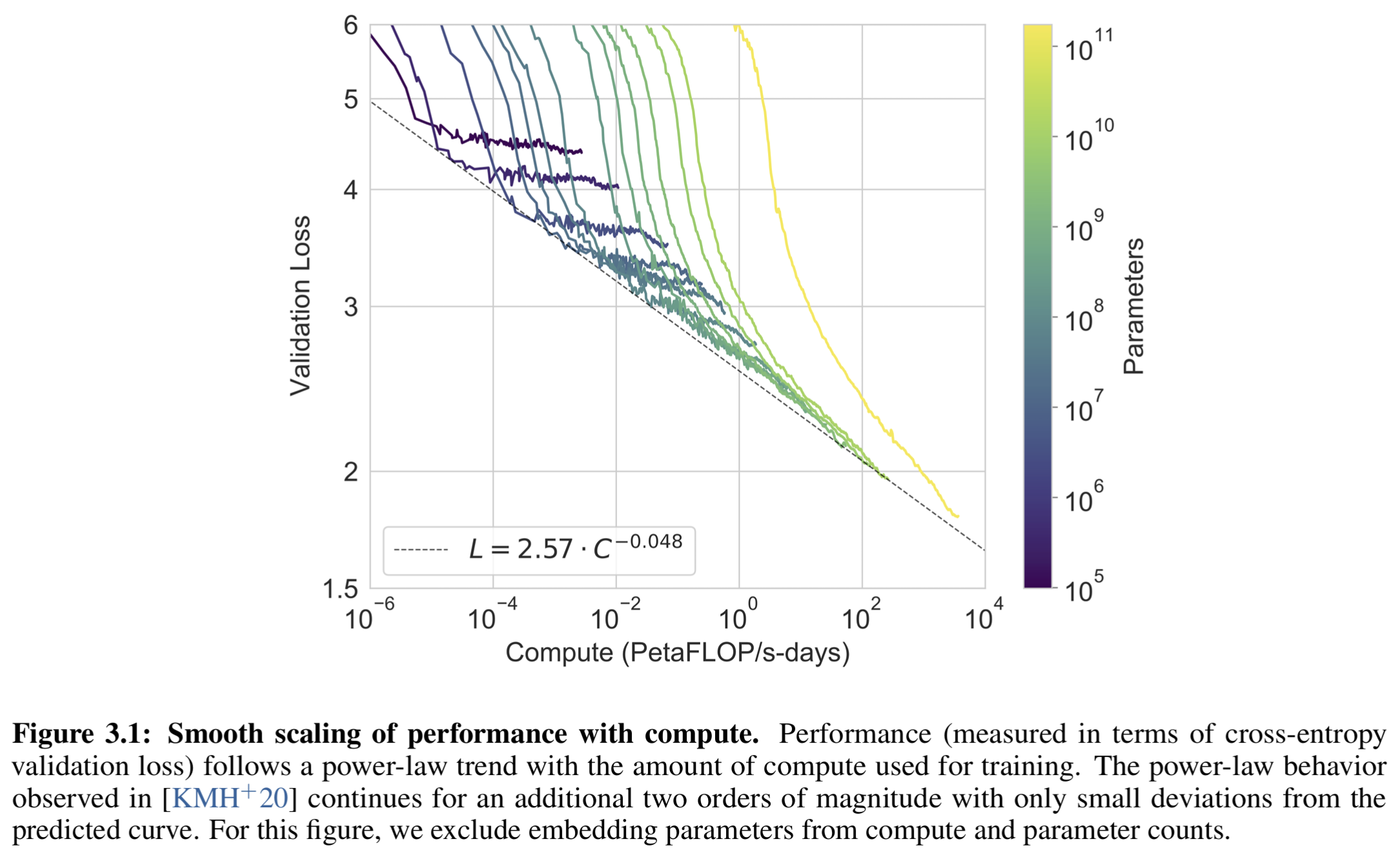
有效性验证,作者担心性能提升是否仅仅是"拟合数据细节"。
- 为此,通过多种自然语言任务验证:cross-entropy loss 的下降 → 各类任务性能一致提升。
任务分组与评测逻辑(Sections 3.1--3.9) - 按任务类型分为 9 大类(语言建模、问答、翻译、推理、阅读理解、SuperGLUE、NLI、创造性任务等)。
- 每个任务都在 few-shot / one-shot / zero-shot 三种设定下测试。
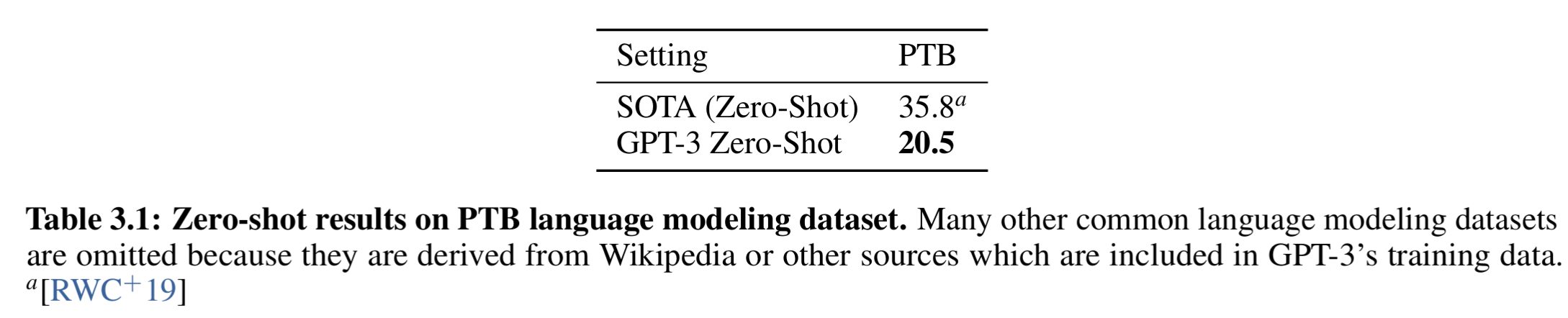
- 最后附表 3.1 展示了 PTB(Penn Treebank)上 GPT-3 的 zero-shot 结果。
- 有效性验证
- cross-entropy loss的下降,能否使得多类自然语言任务性能一致提升,
- 作者按任务类型分为 9 大类进行测试(语言建模、问答、翻译、推理、阅读理解、SuperGLUE、NLI、创造性任务等)。
- 每个任务都在 few-shot / one-shot / zero-shot 三种设定下测试,测试结果放在后文。
5.模型评测- 评价指标
GPT-3 的评估核心是少样本学习 (Few-Shot Learning)能力,即模型在不进行梯度更新的情况下,通过上下文学习 (In-Context Learning) 来执行多类NLP任务的能力,即K-shot learning。
- 生成任务→ Exact Match (EM) / F1 / BLEU /
- 分类任务→ LM likelihood (per-token likelihood)
5.1 生成任务
| 指标 | 对应目标 | 对顺序敏感吗 | 对长度敏感吗 | 使用场景 |
|---|---|---|---|---|
| EM | 完全匹配,要求最严格 | 是 | 是 | QA、填空 |
| F1 | 内容覆盖,允许词语顺序和少量差异 | 否 | 否(归一化) | QA、摘要、关键词 |
| BLEU | N-gram 匹配 & 流畅度:评估句子结构和内容重叠 | 局部敏感 | 是(brevity penalty) | 翻译、生成文本 |
5.1.1 Exact Match (EM)
最严格指标,要求预测文本与参考答案的token完全一致。
EM={1,if pred=gold0,otherwise \text{EM} = \begin{cases} 1, & \text{if } \text{pred} = \text{gold} \\ 0, & \text{otherwise} \end{cases} EM={1,0,if pred=goldotherwise
-
对语序、标点、大小写敏感(可预处理 normalize 后计算)。
-
适合 QA、填空等严格任务。
-
示例:
- Gold:
"New York City" - Pred:
"New York City"→ EM = 1 - Pred:
"NYC"→ EM = 0 - Pred:
"New York"→ EM = 0
- Gold:
5.1.2 F1
评测内容覆盖率(预测文本与参考答案在 token 上的交集),不评测顺序,。
- Precision 精确率:
Precision=∣predicted tokens∩gold tokens∣∣predicted tokens∣\text{Precision} = \frac{|\text{predicted tokens} \cap \text{gold tokens}|}{|\text{predicted tokens}|}Precision=∣predicted tokens∣∣predicted tokens∩gold tokens∣
- Recall 召回率:
Recall=∣predicted tokens∩gold tokens∣∣gold tokens∣\text{Recall} = \frac{|\text{predicted tokens} \cap \text{gold tokens}|}{|\text{gold tokens}|}Recall=∣gold tokens∣∣predicted tokens∩gold tokens∣
- F1 计算:
F1=2⋅Precision⋅RecallPrecision+Recall\text{F1} = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}F1=Precision+Recall2⋅Precision⋅Recall
- 示例:
- Gold:
"New York City"→ tokens =["New", "York", "City"] - Pred:
"City of New York"→ tokens =["City", "of", "New", "York"] - Intersection =
["New", "York", "City"]→ Precision = 3/4 = 0.75, Recall = 3/3 = 1 → F1 ≈ 0.857
- Gold:
5.1.3 BLEU
N-gram: 是指文本中连续的 N 个 token 或单词序列,捕捉文本的局部顺序和结构
假设Sentence = "The quick brown fox jumps." 其N-gram示例如下表:
| N 值 | 名称 | 定义(提取的 N-grams 集合) | 意义 |
|---|---|---|---|
| N=1 | Unigram(⼀元) | {"The", "quick", "brown", "fox", "jumps"} | 衡量词语的独立频率和内容充分性。 |
| N=2 | Bigram(⼆元) | {"The quick", "quick brown", "brown fox", "fox jumps"} | 衡量相邻词语的搭配和局部流畅性。 |
| N=3 | Trigram(三元) | {"The quick brown", "quick brown fox", "brown fox jumps"} | 衡量更长的短语结构和连贯性。 |
| N=4 | 4-gram(四元) | {"The quick brown fox", "quick brown fox jumps"} | 捕捉较长短语的出现频率,尤其用于 BLEU 评分。 |
BLEU 指标是 计算预测文本与参考文本的 N-gram 重叠率 来评价生成文本质量。
- N-gram precision
pn=∑ngram∈predmin(countpred(ngram),countref(ngram))∑ngram∈predcountpred(ngram)p_n = \frac{\sum_{\text{ngram} \in \text{pred}} \min(\text{count}{\text{pred}}(\text{ngram}), \text{count}{\text{ref}}(\text{ngram}))}{\sum_{\text{ngram} \in \text{pred}} \text{count}_{\text{pred}}(\text{ngram})}pn=∑ngram∈predcountpred(ngram)∑ngram∈predmin(countpred(ngram),countref(ngram))
- 几何平均 + brevity penalty:
BLEU=BP⋅exp(∑n=1Nwnlogpn)\text{BLEU} = \text{BP} \cdot \exp \Big( \sum_{n=1}^N w_n \log p_n \Big)BLEU=BP⋅exp(n=1∑Nwnlogpn)
其中:
- ( w_n ) = 权重,一般均分(如 N=4,w_n=0.25)
- BP = brevity penalty,避免生成太短:
BP={1,c>re1−r/c,c≤r\text{BP} =\begin{cases} 1, & c > r \\ e^{1-r/c}, & c \le r\end{cases} BP={1,e1−r/c,c>rc≤r
-
(c) = 预测文本长度,(r) = 参考文本长度
-
BLEU特点:
- 强调局部 N-gram 重叠,同时考虑长度和流畅度。
- 对文本顺序敏感(至少局部 N-gram)。
- 常用于机器翻译、摘要生成、长文本生成任务。
-
BLEU-1 简化示例:
- Gold:
"New York City"→ tokens =["New", "York", "City"] - Pred:
"City of New York"→ tokens =["City", "of", "New", "York"] - 1-gram intersection = 3 → p1 = 3/4 = 0.75
- 假设 BP = 1 → BLEU-1 = 0.75
- Gold:
注意:BLEU不能代替人工对深层语义、逻辑和文化适用性的评估。
5.2 分类任务
由于语言模型只生成候选文本,因此,将分类任务(句子情感分类、真假判断、多选题)评价统一转换为 语言生成任务,再通过 LM likelihood计算。
具体而言,在 GPT-3 few-shot 分类任务评估中,通过语言模型计算每个候选答案的 per-token log-likelihood,选择其最大值作为模型输出,实现统一的语言建模评分机制,大体可以分为3步:
- 步骤1:输入: 文本 + 问题 prompt + 候选答案集合:
context=Input text / Question / Prompt\text{context} = \text{Input text / Question / Prompt}context=Input text / Question / Prompt
输出:
A={candidate labels}(e.g., Positive, Negative) A = \{\text{candidate labels}\} \quad (\text{e.g., Positive, Negative}) A={candidate labels}(e.g., Positive, Negative)
模型生成的其他 token 或额外符号不参与评分,只评价候选答案集合
- 步骤2:计算候选答案生成概率
对每个候选答案 (ai∈A)(a_i \in A)(ai∈A),计算其语言模型条件概率:
P(ai∣context)=∏t=1LiP(wt(i)∣context,w<t(i))P(a_i \mid \text{context}) = \prod_{t=1}^{L_i} P(w_t^{(i)} \mid \text{context}, w_{<t}^{(i)})P(ai∣context)=t=1∏LiP(wt(i)∣context,w<t(i))
LiL_iLi = 答案 aia_iai 的 token 数 ; wt(i)w_t^{(i)}wt(i) = 输出答案的第 t 个 token
- 步骤3:对数似然与 per-token normalization
为了避免长答案被惩罚,取对数并做长度归一化:
per-token log-likelihood(ai)=1Li∑t=1LilogP(wt(i)∣context,w<t(i))\text{per-token log-likelihood}(a_i) = \frac{1}{L_i} \sum_{t=1}^{L_i} \log P(w_t^{(i)} \mid \text{context}, w_{<t}^{(i)})per-token log-likelihood(ai)=Li1t=1∑LilogP(wt(i)∣context,w<t(i))
per-token log-likelihood 值最大的候选答案作为模型预测(即得分最高)
6.基准任务
6.1 语言建模 (Language Modeling) - PTB
-
宾州树库 (Penn Treebank, PTB)
- 发布机构:University of Pennsylvania
- 任务类型:语言模型(Language Modeling, LM)
- 数据来源:Wall Street Journal(新闻文本)
-
规模
- 训练集:≈ 929k tokens
- 验证集:≈ 73k tokens
- 测试集:≈ 82k tokens
- 总计:约 1.1M tokens (约 1 百万词)
-
特点:
- 词表规模仅约 10k
- 数据"干净",几乎无语料污染(无 Wikipedia 或网络文本)
- 常用于验证语言模型的纯粹性与泛化能力
-
树库定义:是一种解析后的文本语料库,通过树状结构标注句子的句法(syntactic)或语义(semantic)结构。树结构源于句子成分的组合性表示,与"解析语料"(parsed corpus)类似。
-
构建基础:词性标注(part-of-speech tags)语料,添加语义等信息。方法包括全手动(linguists annotate)、半自动(parser assign + human correct)。难度取决于标注细节和语料广度,常需团队数年完成。
-
起源: 由语言学家Geoffrey Leech于1980年代发明,类比于种子库或血库。20世纪90年代初的构建推动了计算语言学从经验数据中获益。
-
价值:将抽象语言结构转化为可量化的、可操作的资源,平衡效率与精确性,对AI、语言研究和教育具有持久意义。
-
评价方式: 困惑度 (Perplexity, PPL): 最小化困惑度与最小化交叉熵损失等价。
- 衡量模型对测试集数据的不确定性 (困惑程度),困惑度越低,模型对文本的预测越有信心,性能越好。
- 计算方式是类似似然函数的倒数, M = 测试集中的总词元数:
PPL(W)=P(w1,w2,...,wM)−1M PPL(W)= P(w_1, w_2, ..., w_M)^{-\frac{1}{M}} PPL(W)=P(w1,w2,...,wM)−M1 - 在实际计算中,通常使用对数似然 来避免浮点数下溢,并利用条件概率的链式法则。模型计算的是平均对数似然 的指数(或以 2 为底的指数):
PPL(W)=2−1M∑i=1Mlog2P(wi∣w1,...,wi−1)\text{PPL}(W) = 2^{-\frac{1}{M} \sum_{i=1}^{M} \log_2 P(w_i|w_1, \dots, w_{i-1})}PPL(W)=2−M1∑i=1Mlog2P(wi∣w1,...,wi−1)- P(wi∣w1,...,wi−1)P(w_i|w_1, \dots, w_{i-1})P(wi∣w1,...,wi−1):语言模型预测第 iii 个词元 wiw_iwi 的条件概率,基于其前面的所有词元。
- ∑i=1Mlog2P(... )\sum_{i=1}^{M} \log_2 P(\dots)∑i=1Mlog2P(...):代表整个测试集序列的对数似然 ;1M∑i=1M...\frac{1}{M} \sum_{i=1}^{M} \dotsM1∑i=1M...:代表平均对数似然。
- 在 222 为底的情况下,困惑度实际上与交叉熵损失 (Cross-Entropy Loss, H) 呈指数关系:
PPL(W)=2H(W)\text{PPL}(W) = 2^{H(W)}PPL(W)=2H(W) - 原始似然值是一个极小的数,难以直观比较, 困惑度提供了一个更容易理解的直觉数值:
- GPT-3 在 PTB 数据集上将 PPL 降至 20.5, 如表 3.1
即在每个位置预测下一个词时,其不确定性相当于平均有 20.5 个词语的可能性是均等的。
表3.1中对比的SOTA方法是 GPT2: 《Language models are unsupervised multitask learners》, 2019.
6.2 文本理解-LAMBADA
LAMBADA(Language Modeling Broadened to Account for Discourse Aspects)旨在通过词预测任务评估计算模型的文本理解能力(预测叙述性文本片段的最后一个词)。
LAMBADA的输入段落,在人类阅读后能轻松猜出最后一个词,但仅看到最后一句时无法准确预测。这要求模型超越局部上下文依赖,具备追踪长距离语篇上下文能力。 LAMBADA涵盖多种语言现象(如指代消解、语义连贯性等),而提出时(2016年)的先进语言模型(如RNN、LSTM等)在该数据集上的准确率均低于1%。
因此,LAMBADA被提出作为一个挑战性基准,旨在激励开发能够真正理解广泛语境的自然语言处理(NLP)模型。
- 出处:来自论文 《The LAMBADA dataset: Word prediction requiring a broad discourse context》, Paperno et al., ACL, 2016
- 背景:2016年是深度学习在NLP领域快速发展的时期,模型(如RNN、LSTM)擅长局部上下文建模,但长距离依赖和语篇级理解仍是难点。LAMBADA填补了这一评估空白。
- 创新性:通过对比人类(高成功率)与机器(低准确率)的表现,突出模型在语篇理解上的局限性。
- 任务类型:长距离依赖预测,测试模型是否能整合整个段落的语义和语篇信息。
- 任务定义:预测一段上下文中最后一个词(必须理解整段文本语义)
- 数据来源:BookCorpus(小说文本)
- 版本:English, German, Spanish, French, and Italian.
- 规模:
- 训练集:≈ 1.6M passages
- 验证集:≈ 5k
- 测试集:≈ 5k
- 总 token 数:约 200M 量级(含上下文)
- GPT-3 测评
- 评测设置:Zero-shot / Few-shot / One-shot
- 关键发现:
- Few-shot 格式化(如"填空题"提示)显著提高准确率(从 76% → 86%)
- 证实大模型能在无参数更新的前提下通过 In-Context Learning 调整策略
-
few-shot案例:
Alice was friends with Bob. Alice went to visit her friend ___.
Bob.George bought some baseball equipment, a ball, a glove, and a ___.
bat.Now complete the following:
John asked Mary for a cup of ___.
openAI的预处理版本:
- 性能结果:
- Zero-Shot 零样本设置:
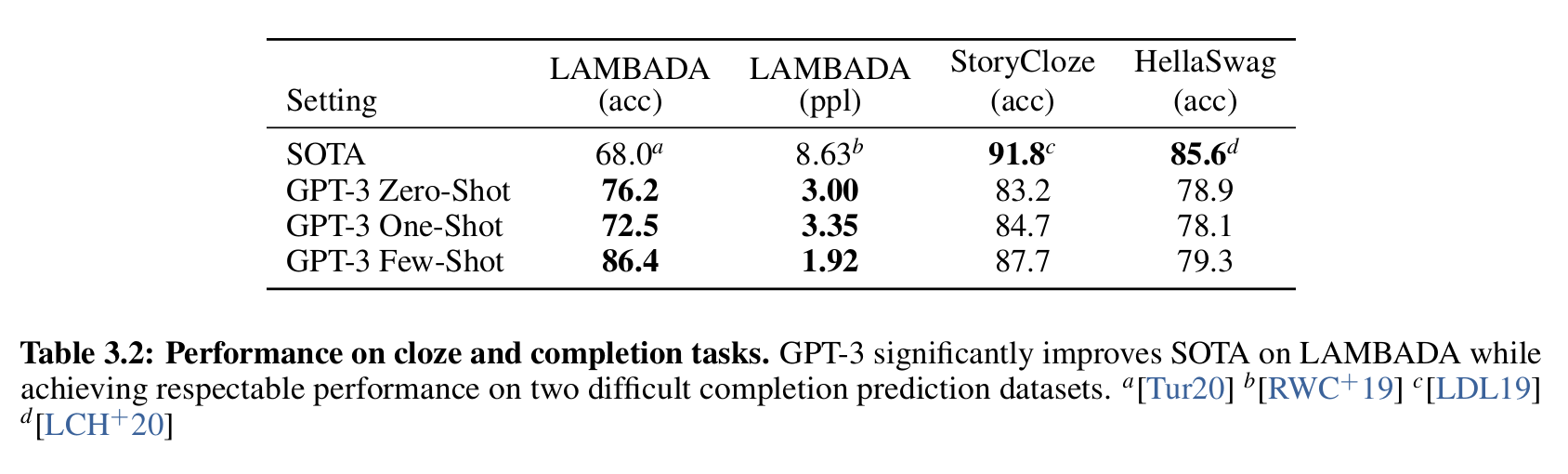
- 结果: GPT-3 实现了 76% 的准确率。
- 提升: 比此前的 SOTA(可能为 68.0%,即表格中Tur20的结果)提高了 8%。
- 这直接反驳了"继续扩大硬件和数据规模已不是发展方向"的论点。
- Few-Shot 少样本设置:
- 结果: GPT-3 实现了 86.4% 的准确率。
- 提升: 比此前的 SOTA 提高了 超过 18%。
- One-shot 异常:
- 一次示例不足以让模型掌握"填空模式",反而比 zero-shot 更差;
- 推测:模型需要多个例子才能捕捉任务模式。
- Zero-Shot 零样本设置:
数值如表3.2, 其中a是 2020的Turing-NLG,b是2019的GPT2, c是2019的Bert, d是2020的《Adversarial training for large neural language models》。
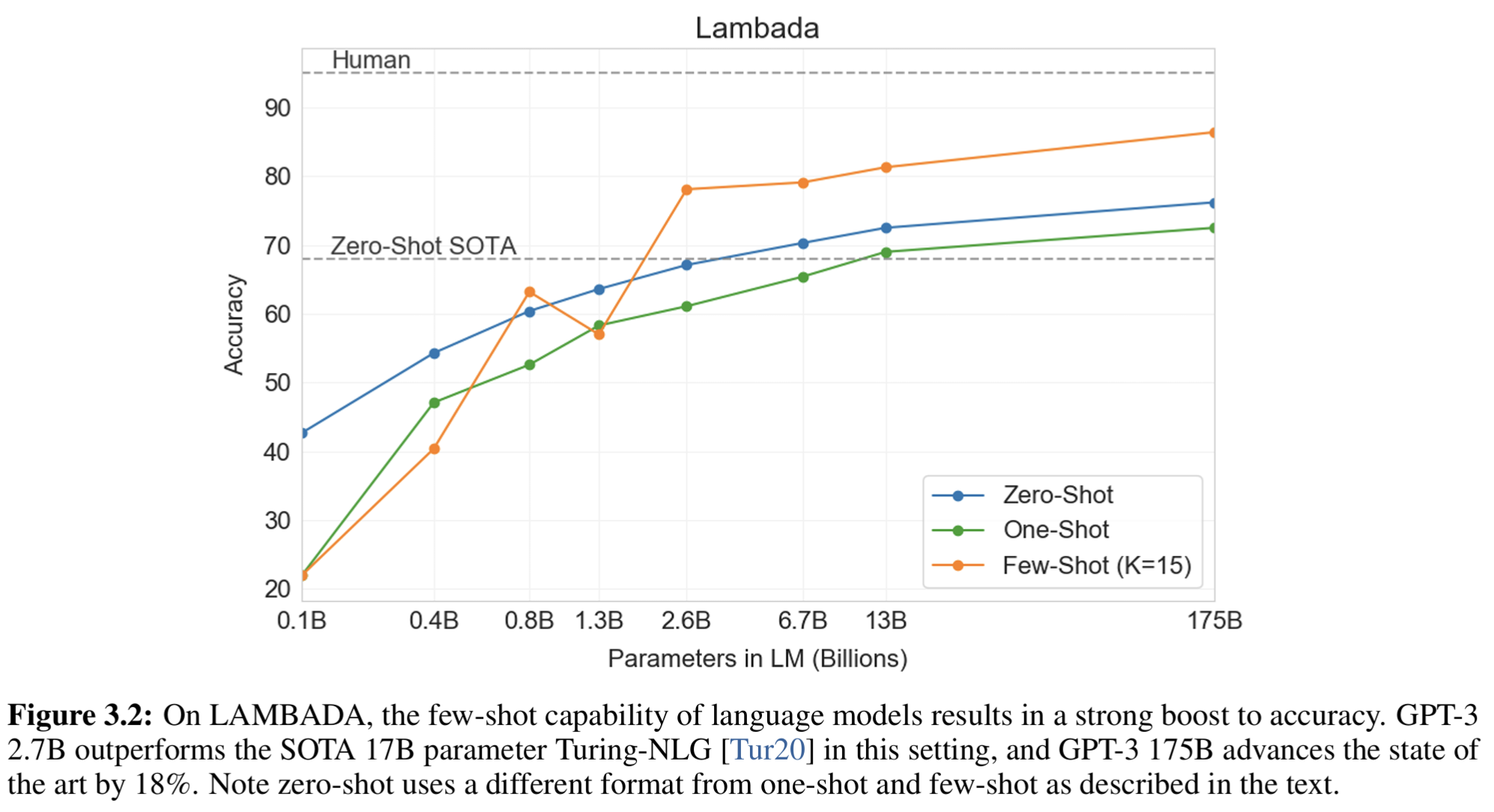
在少样本(few-shot)设置下,GPT-3 2.7B 的模型性能甚至超过了 17B 参数的 SOTA 模型 Turing-NLG,如图3.2所示:
6.3 HellaSwag (commonsense reasoning)
- 提出者:论文<<HellaSwag: Can a Machine Really Finish Your Sentence?>>, ACL, Zellers et al., 2019
- 提出动机:虽然 BERT 等模型在许多任务上表现超强,但模型很可能在利用统计模式,而非真正理解语义或因果推理。通过设计 HellaSwag数据集,创建"人类轻松解决,但模型难以区分"的选择题(4选1),证明模型在特定问题内准确率仍远低于人类,"人类的推理水平"不能泛化。
- 数据类型:通过 adversarial filtering 剔除被语言模型轻易判断的样本,留下强调语义一致性与世界常识的推理的常识推理样本(Adversarial Commonsense Inference)
- 数据结构:给定一个前提(如短视频或故事情节),从4个候选中选择1个最佳续写句子。
- 规模:
- 训练集:39,905
- 验证集:10,042
- 测试集:10,003
- 总计:≈ 60k instances
- 数据来源:ActivityNet Captions (Youtube视频描述) + WikiHow (操作说明)
- 数据特点:对于人类来说极容易(人类准确率 > 95%),但对自动模型极具挑战性(模型准确率在当时 < 48%)
- 评测设置:Zero-shot / One-shot / Few-shot
- GPT-3 测评
- 对比基准:
- 微调模型(RoBERTa, BERT-Large)
- GPT-3 Zero-shot
- 结果: GPT-3(175B)Few-shot 在不微调的情况下接近微调 SOTA, 具备"常识推理 /语境理解"能力
- 对比基准:
-
HellaSwag特点:
- 人类几乎不会被迷惑;
- 模型表现显著下降, 成功"揭穿"了模型的浅层模式依赖;
- 数据集成为检验常识推理能力的"金标准"。
-
GPT3 在HellaSwag上的评测表现:
| 模型类型 | 规模 | 训练方式 | 准确率 (%) |
|---|---|---|---|
| 人类 | -- | -- | 95.6 |
| GPT-3 | 175B | Few-shot (无微调) | 79.3 |
| GPT-2 (fine-tuned) | 1.5B | 单任务微调 | 75.4 |
| ALUM | 多任务微调 | SOTA | 85.6 |
6.3.1 HellaSwag 数据构造方法:Adversarial Filtering(对抗过滤)
在传统的 多选常识推理任务(如 StoryCloze、SWAG)中,研究者通常这样构建数据集:
1.给定一个 上下文段落 (如一段故事、说明书、视频描述);
2.人工编写一个"正确的结尾";
3.再由人工或GPT生成若干"错误结尾"。
这些"错误结尾"往往过于"假",语言风格、句法结构、词汇分布与正确句子差异明显。
因此,语言模型甚至不用理解语义或常识,只需学到一些表层特征(如词频、语法概率、词汇分布)就能选出正确答案。
这会造成:
1.模型"看似聪明",但实则没理解内容 ;
2.任务评测失真,无法反映真实的推理或理解能力。
Adversarial Filtering (AF)机制,灵感来自对抗训练(adversarial training)与迭代难例挖掘(hard example mining),通过一个不断更新的"判别模型 (discriminator)",来自动筛选那些最能"欺骗模型"的错误选项,使得最终保留下来的错误答案对于模型来说最难区分。
具体是找到"硬负例"。
错误候选类型 判别结果 动作
明显错误的选项 判别器很容易将其识别为错误。 丢弃。 这种选项对测试 LLM 意义不大。
对判别器"极具迷惑性"的选项 (硬负例) 判别器错误地将其分类为正确,或者正确分类的概率非常低(即模型对它的困惑度极高)。 保留。 这些是模型最容易被误导的选项。
6.3.2 Adversarial Filtering流程(迭代式)
- Step 1:初始样本与候选生成
**每条样本包含:**一个 上下文 (context) ;一个 正确续写 (gold ending) ;三个经过对抗过滤挑选的 错误续写 (adversarial negatives)。
样本生成:给定一个上下文(如故事片段、视频说明),我们有一个正确的结尾 c+c^+c+。
接着,用自动化生成模型(如 GPT、LSTM LM)生成大量候选错误结尾:
{c1−,c2−,...,cM−}\{ c_1^-, c_2^-, \dots, c_M^- \}{c1−,c2−,...,cM−}
这些错误结尾最初可能包含明显的语法或语义错误。
- Step 2:训练判别模型(Discriminator)
训练一个判别器 DθD_\thetaDθ,用于区分"正确结尾"与"错误结尾":
Dθ(c∣context)→0,1D_\theta(c \mid \text{context}) \rightarrow 0, 1Dθ(c∣context)→0,1
表示句子 ccc 是"正确"结尾的概率。
- Step 3:对抗过滤(Filtering)
对于每个上下文,计算所有候选错误选项的得分:
si=Dθ(ci−∣context)s_i = D_\theta(c_i^- \mid \text{context})si=Dθ(ci−∣context)
保留那些 最接近正确答案 的错误选项(即 sis_isi 值较高的负例):
Select top-K hard negatives {ci1−,ci2−,...,ciK−}\text{Select top-}K\ \text{hard negatives } \{ c_{i_1}^-, c_{i_2}^-, \dots, c_{i_K}^- \}Select top-K hard negatives {ci1−,ci2−,...,ciK−}
这些样本对判别器来说"是错误分类的",代表"模型最难分辨的错误选项"。
- Step 4:更新判别模型
重新训练判别器 DθD_\thetaDθ ------这次使用上一轮过滤得到的 更难的错误样本 。
目的是让模型逐步提升"辨别难例"的能力。
重复步骤 3--4,直到模型不再能轻易区分正负例,或性能收敛。
最终生成的数据集包含的错误选项具有以下特性:
- 对语言模型来说"表面上很合理";
- 但语义、常识或因果上仍是错误的;
- 对人类来说极易判断,但模型需要深入理解才能识别。
HellaSwag论文当前模型准确率如下:
| 评测模型 | 准确率 (%) |
|---|---|
| 随机选 | 25 |
| BERT | ~48 |
| GPT | ~45 |
| 人类 | 95.6 |
- 示例:
py
Context:
He puts the ingredients into a bowl and begins to mix them together.
Option A: He bakes it for 20 minutes and serves it hot. ✅
Option B: He watches TV and then eats his dinner.
Option C: He leaves the room to get his phone.
Option D: He talks to his friend on the phone.模型常被 B/C/D 迷惑,因为它们语法合理、语义连贯,但缺乏因果衔接。
具体解释如下:
选项 内容连贯性 (Coherence) 模型困惑度 PPL (直观)** 理由分析 (人类常识)
A (正确) ✅ 高。 搅拌原料后,下一步是烹饪、烘焙或服务。 低 (PPL ≈ 5-10)。 逻辑上最顺畅的路径。 常识路径: 搅拌是烘焙/烹饪的中间步骤,"bakes" 是最符合动作序列的连贯结局。
B(硬负例) 中低。 搅拌和看电视、吃饭之间没有直接逻辑关系。 中 (PPL ≈ 20-30)。 模型可能会被 "eats his dinner" 迷惑,认为"吃饭"是合理的结局。 干扰因素: "dinner" 是食物相关的词汇,但跳过了关键的烹饪步骤,逻辑不连贯。
C 极低。 离开房间拿手机与搅拌原料的行为是随机切换。 中高 (PPL ≈ 50+)。 行为切换随机性高,但语法正确。 纯随机行为: 这是最常见的 HellaSwag 干扰项,语法正确,但与手头的任务无关。
D 低。 仍在房间中,增加了社交元素。 高 (PPL ≈ 40-50)。 仅空间连贯。 与上下文弱相关(行为不延续烹饪),有一定"合理性",可能混淆模型 → 硬负例。- 数据字段
| 字段名 | 含义 | 示例 | 说明 |
|---|---|---|---|
| activity_label | 动作/情景类别标签 | "Baking cookies" |
来自 ActivityNet Captions 的动作主题,用于指明该场景的主题。不是要预测的标签,只是辅助信息。 |
| ctx_a | 上下文第一部分(前文A) | "A female chef in white uniform shows a stack of baking pans in a large kitchen presenting them." |
描述动作或场景的开头。通常为一句或半句。 |
| ctx_b | 上下文第二部分(前文B) | "the pans" |
继续扩展前文的动作,形成一个完整的语境。 |
| ending_options | 候选续写选项(共4个) | 四条不同结尾句子 | 其中 1 条为真实的(ground truth),其余 3 条由语言模型生成的"假但语法正确"的干扰项。 |
| label | 正确答案的索引(0--3) | 0 |
表示哪一个选项是合理的结尾。 |
| gold_source(有时出现) | 标记正确选项的来源 | "human" 或 "adversarial" |
指示该正确结尾来自人类标注或模型对抗生成。 |
| split | 数据集划分 | "train", "val", "test" |
标记样本所属划分。 |
- HF示例

6.4 Arithmetic 算术
"一个只经过语言建模训练的大模型,能否自然地掌握算术逻辑,而无需针对算术专门微调?"
实验构建了一组 10 个合成的基础算术测试(synthetic arithmetic tasks),覆盖:
- 不同位数的加减法
- 两位数乘法
- 混合运算(带括号的组合运算)
具体如下:
| 缩写 | 含义 | 示例 | 取数范围 |
|---|---|---|---|
| 2D+ | 二位加法 | 48 + 76 = 124 | [0, 100) |
| 2D− | 二位减法 | 34 − 53 = −19 | [0, 100) |
| 3D+ | 三位加法 | 512 + 376 = 888 | [0, 1000) |
| 3D− | 三位减法 | 842 − 629 = 213 | [0, 1000) |
| 4D+ | 四位加法 | 1234 + 4765 = 5999 | [0, 10,000) |
| 4D− | 四位减法 | 9348 − 5291 = 4057 | [0, 10,000) |
| 5D+ | 五位加法 | 12345 + 67890 = 80235 | [0, 100,000) |
| 5D− | 五位减法 | 98765 − 12345 = 86420 | [0, 100,000) |
| 2Dx | 二位乘法 | 24 × 42 = 1008 | [0, 100) |
| 1DC | 一位复合运算 | 6 + (4 × 8) = 38 | [0, 10) |
HF示例:
测试性能如下: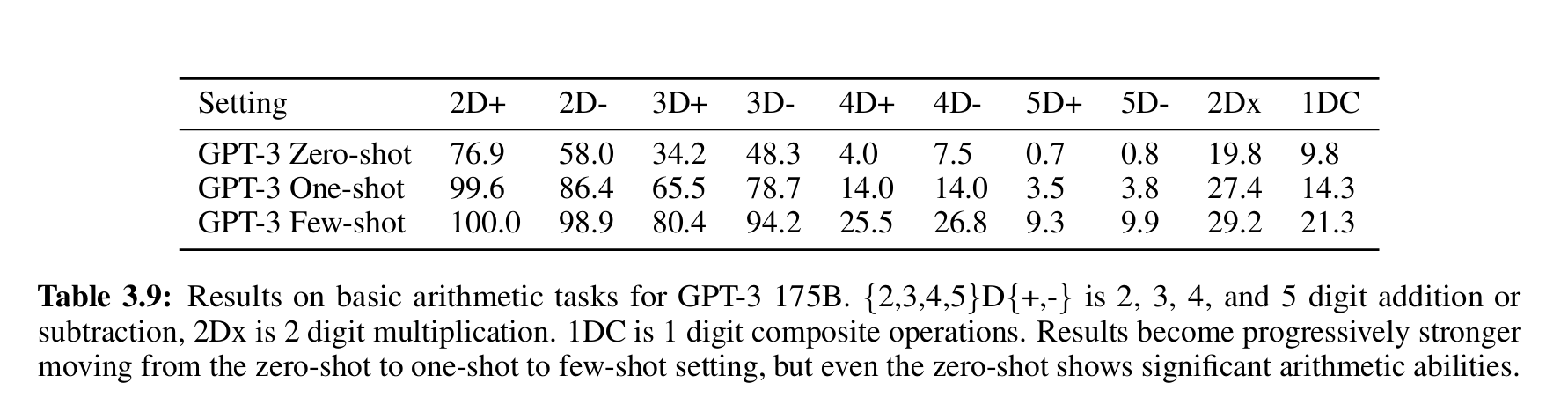
总结:
- 两位数加减法:几乎完美 (≈100%);
- 三位数:仍能保持较高准确率;
- 四/五位数:显著下降,但仍非随机;
- 乘法与复合运算:虽低,但表明模型确实在"尝试计算";
- 从 zero → one → few-shot,性能持续提升;
- 表明提示学习(in-context learning) 能显著帮助模型掌握算术模式。
发现:
- 模型会出现如"忘记进位""多加一位"等错误;这与人类早期学习算术时的错误类型一致;
- 推测 GPT-3 内部确实在模拟算术步骤,不是随机生成。
图 3.10 展示了不同模型(从 125M → 350M → 13B → 175B)的算术能力:
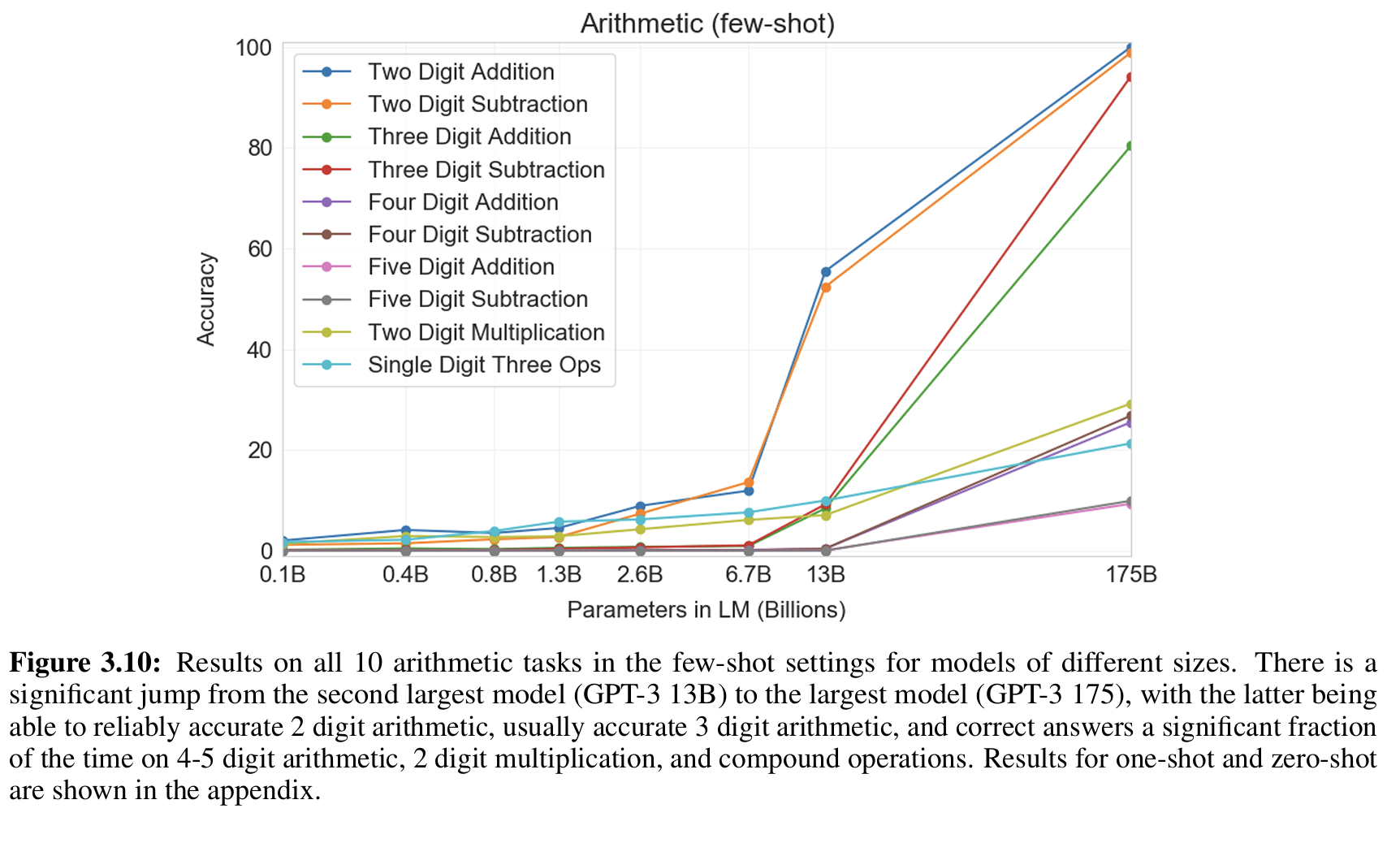
- 小模型几乎全错;
- 13B 只能做到一半正确;
- 175B 才能接近完美完成两位运算,并在三位、四位上保持显著优势。
算术是一种系统性推理,需要足够参数容量来存储进位逻辑与序列关系;这说明 scaling law 不仅提升语言流畅性,也增强"结构推理能力"。
6.5 SuperGLUE
GLUE(General Language Understanding Evaluation)的升级版。曾是最主流的语言理解评测基准,推动了 BERT、RoBERTa 等模型的出现。到 2019 年,许多模型在 GLUE 上已经超过人类平均水平(如 RoBERTa、T5 等)。为了进一步挑战模型的理解能力,研究者发布了 SuperGLUE ------一个更难、更综合、更贴近真实语言推理的任务集。
- 任务集合
| 缩写 | 全称 | 任务类型 | 简要说明 |
|---|---|---|---|
| BoolQ | Boolean Questions | QA(问答) | 根据一段文本回答是/否问题。 |
| CB | CommitmentBank | NLI(自然语言推理) | 判断假设是否由文本蕴含、矛盾或中立。 |
| COPA | Choice of Plausible Alternatives | 因果推理 | 给定一句话,选择更合理的因果解释。 |
| MultiRC | Multi-Sentence Reading Comprehension | 阅读理解 | 根据多句上下文回答多选问题。 |
| ReCoRD | Reading Comprehension with Commonsense Reasoning | 常识阅读理解 | 在阅读理解中加入常识性推理。 |
| RTE | Recognizing Textual Entailment | 文本蕴含 | 判断两句话是否为"蕴含/矛盾/无关"。 |
| WiC | Word-in-Context | 词义消歧 | 判断同一词在两个句子中是否具有相同含义。 |
| WSC | Winograd Schema Challenge | 共指消解 | 判断代词所指的真实对象(测试常识推理)。 |
- 对比
| 对比维度 | GLUE | SuperGLUE |
|---|---|---|
| 发布时间 | 2018 | 2019 |
| 难度 | 中等 | 高 |
| 任务数量 | 9 | 8 |
| 输出形式 | 分类 + 回归 | 分类 |
| 任务语义多样性 | 基础理解(语法、情感、句对、NLI) | 深层推理(常识、因果、多句、词义消歧) |
| 语言推理深度 | 表层匹配 | 深层逻辑与常识 |
| 是否包含多句推理 | 少(MNLI) | 多(MultiRC, ReCoRD) |
| 常识需求 | 弱 | 强 |
| 指标类型 | Accuracy / F1 / Corr | Accuracy / F1 / EM |
| 人类表现基线 | 约 87% | 约 90%,模型尚未全面超越人类 |
6.6 SAT Analogies
数据集:374 道 SAT 类比题(来源 TLBS03)。
类比题要求模型理解 词义、关系及抽象推理,不同于日常文本生成。
难度较高,因为它超出了模型典型训练分布(即自然语言文本),更接近逻辑推理任务。
py
audacious : boldness :: ?
(a) sanctimonious : hypocrisy # 正确
(b) anonymous : identity
(c) remorseful : misdeed
(d) deleterious : result
(e) impressionable : temptation选择对单词对的关系与原始单词对相同。
Figure 3.12(论文中图示)显示:随着模型参数增加,性能显著提升。
GPT-3 175B 在 few-shot 设置上比 13B 提升超过 10%。
小模型没有明显的 in-context 学习能力,而大模型能够有效利用示例来提升性能。
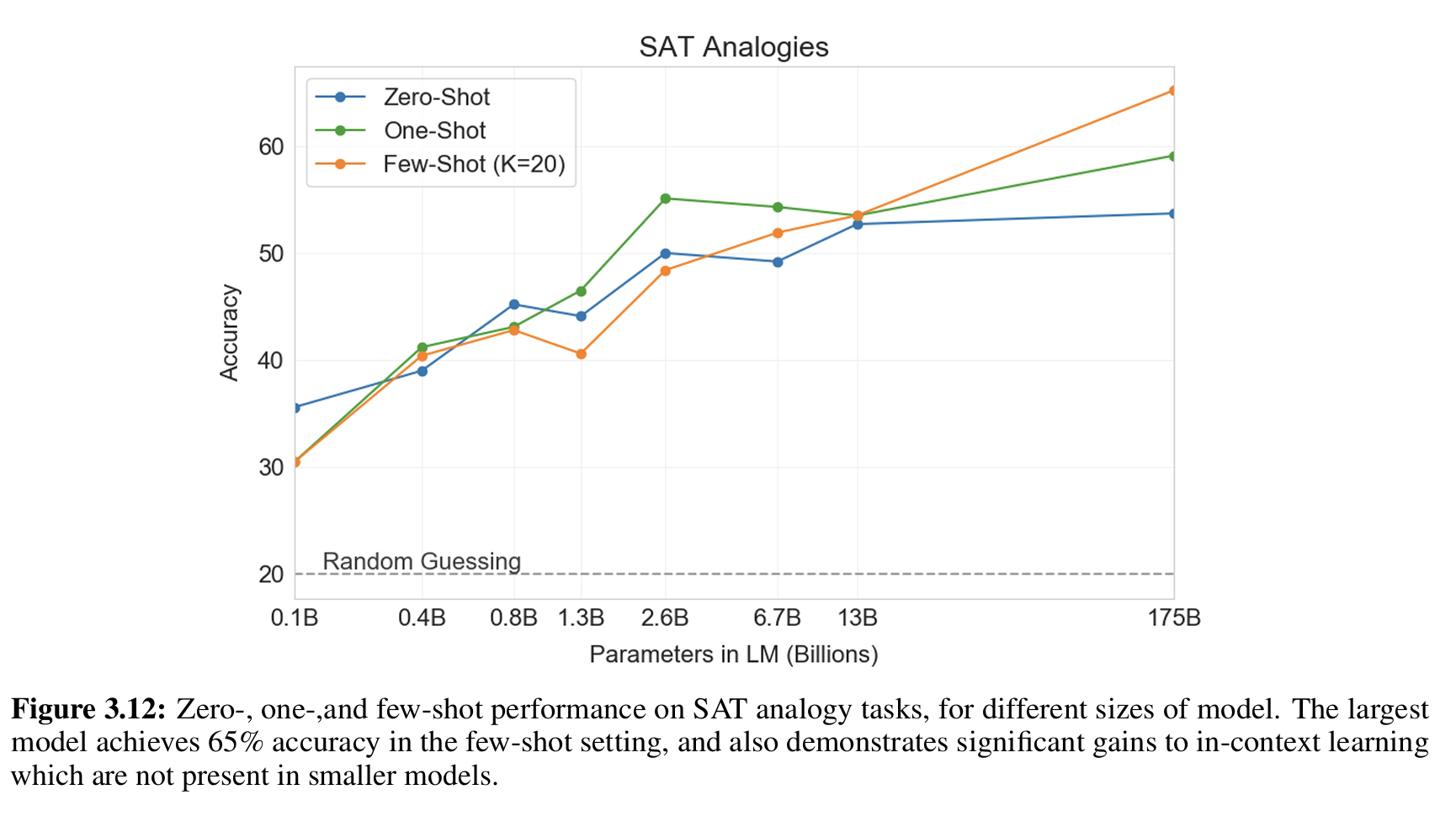
- 结果&结论
| Setting | GPT-3 Accuracy | 说明 |
|---|---|---|
| Few-shot | 65.2% | 提供几个示例题(in-context learning) |
| One-shot | 59.1% | 提供一个示例题 |
| Zero-shot | 53.7% | 没有示例题,直接回答 |
| 人类平均分 | 57% | 美国大学申请者平均表现 |
| 随机猜测 | 20% | 5 个选项的随机猜测概率 |
- GPT-3 能够处理逻辑类任务,不仅仅是自然语言生成。
- Few-shot in-context learning 对模型表现提升显著。
- 模型规模大才能有效掌握类比推理模式。
在 SAT 类比题上,GPT-3 在 few-shot 下 超越人类平均水平,显示其潜在的抽象推理能力。
6.7 StoryCloze
StoryCloze(全称 Story Cloze Test)是 GPT-3 的一个 语言理解与常识推理 benchmark,主要用于衡量模型的 常识性叙事推理(commonsense narrative reasoning)。
基于更早的 ROCStories 数据集(由约 98,000 个短故事组成,每个故事 5 句),而 StoryCloze 是它的一个评测子集:
Q=给出一个 4 句故事开头, A = 2 个候选结尾句,模型需要判断哪个结尾更合理(二选一)。
Q:
1. John went to the kitchen.
2. He wanted to make breakfast.
3. He got some eggs and a pan.
4. He turned on the stove.
A:
(A) The eggs burned because he forgot them on the stove. ✅(合理)
(B) The eggs started flying around the room. ❌(不合理)- 性能水平
| 模型 | 参数规模 | 评测设置 | Accuracy (%) |
|---|---|---|---|
| GPT-3 13B | Few-shot | ≈ 81 | |
| GPT-3 175B | Few-shot | ≈ 87.7 | |
| 人类水平 | - | - | ≈ 100 |
6.8 总体评价
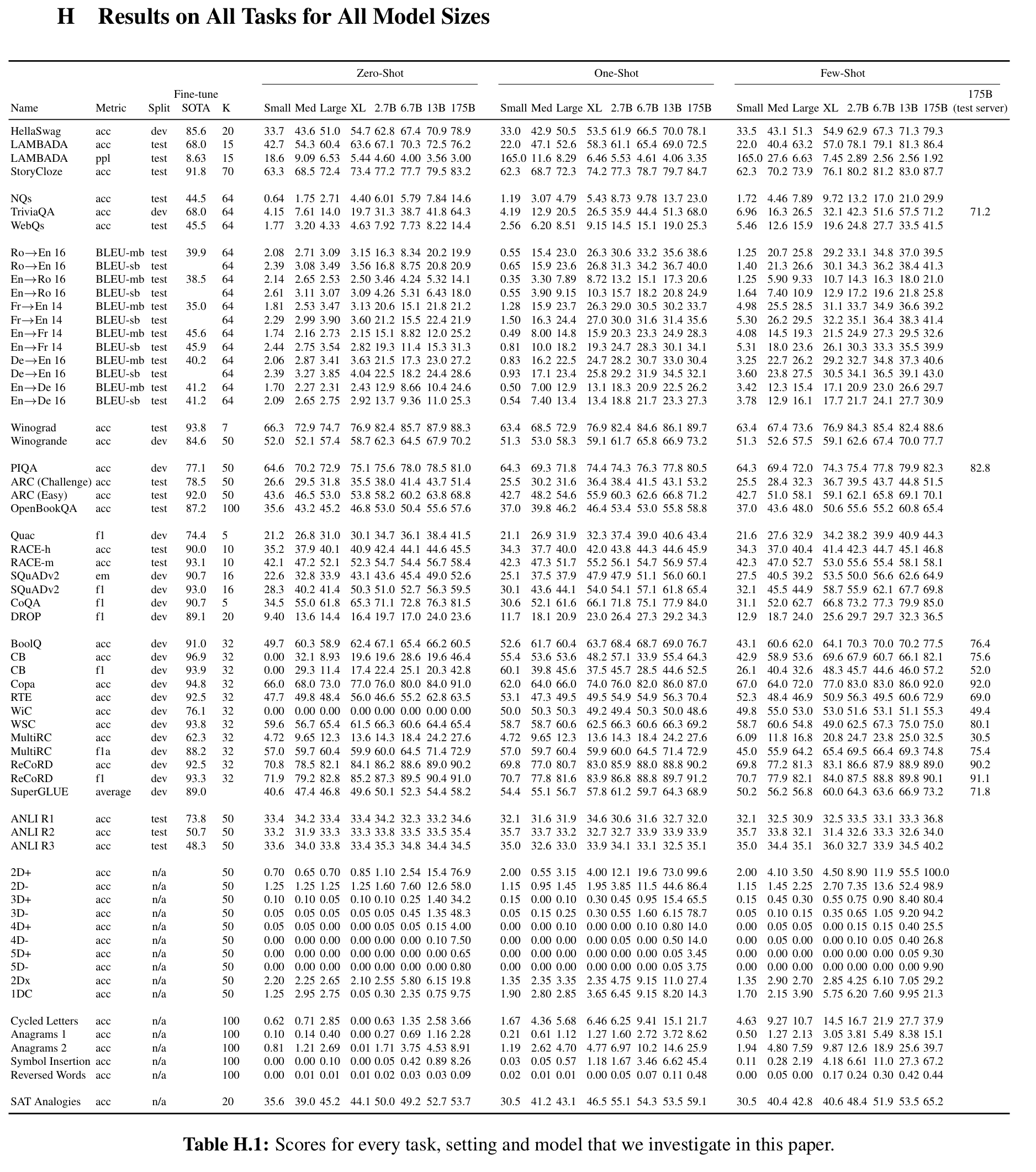
指标如表H.1:
7.模型偏见
模型的偏见原因来自训练数据,主要受西方文化影响。
报告通过三种实验方法(职业-性别概率、代词消解、词共现分析)多维度验证了 GPT-3 存在性别偏见,同时指出模型规模增大可以在某些任务中缓解偏见。
部分偏见如下:
| 偏见类型 | 示例 | 表现形式 | GPT-3 反映 |
|---|---|---|---|
| 事实性偏见(factual bias) | 只描述主流宗教、忽略小宗教 | 信息覆盖度不均 | 部分存在 |
| 语义偏见(semantic bias) | 词汇如 "terrorist" 频繁与 Islam 共现 | 语义负面化 | 显著存在 |
| 文化偏见(cultural framing bias) | 西方语料中"穆斯林=安全威胁" | 模型输出倾向再现这种语义关联 | 反映出社会语料偏差 |