本文为个人阅读
GPT3,部分内容注解,由于GPT3原文篇幅较长,且GPT3无有效开源信息这里就不再一一粘贴,仅对原文部分内容做注解,仅供参考
详情参考原文链接
语言模型是少样本学习器(Language Models are Few-Shot Learners)
文章目录
- [语言模型是少样本学习器(Language Models are Few-Shot Learners)](#语言模型是少样本学习器(Language Models are Few-Shot Learners))
- [GPT3 精简阅读](#GPT3 精简阅读)
- [GPT3 原文精选注解](#GPT3 原文精选注解)
-
- 摘要(Abstract)
- [1 引言(Introduction)](#1 引言(Introduction))
- [2 方法(Approach)](#2 方法(Approach))
-
- [2.1 模型和架构(Model and Architectures)](#2.1 模型和架构(Model and Architectures))
- [2.2 训练数据集(Training Dataset)](#2.2 训练数据集(Training Dataset))
- [2.3 训练过程(Training Process)](#2.3 训练过程(Training Process))
- [2.4 评估(Evaluation)](#2.4 评估(Evaluation))
GPT3 精简阅读
GPT3 精简阅读
GPT3 核心方法
基础架构
GPT-3采用与GPT-2相同的Transformer decoder-only架构,但有关键改进:
模型公式表示:
GPT-3 ( x ) = TransformerDecoder ( x ; θ ) \text{GPT-3}(x) = \text{TransformerDecoder}(x; \theta) GPT-3(x)=TransformerDecoder(x;θ)
其中:
- 使用改进的初始化 、预归一化(Pre-normalization) 和可逆标记化
- 采用交替密集和局部带状稀疏注意力模式(类似Sparse Transformer)
- 统一上下文窗口: n c t x = 2048 n_{ctx} = 2048 nctx=2048 tokens
关键架构参数:
- 前馈层维度: d f f = 4 × d m o d e l d_{ff} = 4 \times d_{model} dff=4×dmodel
- 参数总量:从125M到175B,跨越3个数量级
- 最大模型GPT-3 175B:96层, d m o d e l = 12288 d_{model}=12288 dmodel=12288,96个注意力头
训练目标与损失函数
自回归语言建模目标:
L ( θ ) = − ∑ i = 1 n log P ( x i ∣ x < i ; θ ) L(\theta) = -\sum_{i=1}^{n} \log P(x_i | x_{<i}; \theta) L(θ)=−i=1∑nlogP(xi∣x<i;θ)
其中 x < i x_{<i} x<i表示位置 i i i之前的所有token。
训练策略特点:
- 无任务特定的微调阶段
- 纯粹依赖预训练时的通用语言建模
- 批量大小随模型规模调整:0.5M → 3.2M tokens
- 学习率随模型增大递减: 6.0 × 10 − 4 6.0 \times 10^{-4} 6.0×10−4 → 0.6 × 10 − 4 0.6 \times 10^{-4} 0.6×10−4
上下文学习机制
GPT-3的核心创新是上下文学习(In-context Learning) :
数学表示:
P ( y ∣ x ) = P ( y ∣ D 1 , D 2 , . . . , D k , x ; θ ) P(y|x) = P(y|D_1, D_2, ..., D_k, x; \theta) P(y∣x)=P(y∣D1,D2,...,Dk,x;θ)
其中:
- D i = ( x i , y i ) D_i = (x_i, y_i) Di=(xi,yi):第 i i i个演示示例
- k k k:示例数量(0表示零样本,1表示单样本,2-100表示少样本)
- θ \theta θ:预训练的模型参数(推理时固定)
三种学习设置:
- 零样本(Zero-shot) :
P ( y ∣ x ) = P ( y ∣ instruction , x ; θ ) P(y|x) = P(y|\\text{instruction}, x; \theta) P(y∣x)=P(y∣instruction,x;θ)
- 单样本(One-shot) :
P ( y ∣ x ) = P ( y ∣ instruction , ( x 1 , y 1 ) , x ; θ ) P(y|x) = P(y|\\text{instruction}, (x_1, y_1), x; \theta) P(y∣x)=P(y∣instruction,(x1,y1),x;θ)
- 少样本(Few-shot) :
P ( y ∣ x ) = P ( y ∣ instruction , ( x 1 , y 1 ) , . . . , ( x k , y k ) , x ; θ ) P(y|x) = P(y|\\text{instruction}, (x_1, y_1), ..., (x_k, y_k), x; \theta) P(y∣x)=P(y∣instruction,(x1,y1),...,(xk,yk),x;θ)
GPT系列模型全面对比
架构演进对比
| 特性 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 基础架构 | Transformer Decoder | Transformer Decoder | Transformer Decoder + Sparse Attention |
| 参数规模 | 117M | 1.5B (最大) | 175B (最大) |
| 层数 | 12 | 48 (最大) | 96 (最大) |
| 隐藏维度 | 768 | 1600 (最大) | 12288 (最大) |
| 注意力头数 | 12 | 25 (最大) | 96 (最大) |
| 上下文长度 | 512 tokens | 1024 tokens | 2048 tokens |
| 词表大小 | 40,478 | 50,257 | 50,257 |
| 位置编码 | 可学习 | 可学习 | 可学习 |
训练数据对比
| 模型 | 数据集 | 数据量 | 特点 |
|---|---|---|---|
| GPT-1 | BookCorpus | 5GB (~800M tokens) | 单一高质量文本源 |
| GPT-2 | WebText | 40GB (~10B tokens) | Reddit高质量链接过滤 |
| GPT-3 | 混合数据集 | 570GB (~300B tokens训练) | Common Crawl(60%) + WebText2(22%) + Books(16%) + Wikipedia(3%) |
训练方法对比
| 方面 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 预训练方法 | 无监督语言建模 | 无监督语言建模 | 无监督语言建模 |
| 微调策略 | 必需,任务特定微调 | 零样本迁移 | 上下文学习(无需微调) |
| 下游任务适配 | 需要梯度更新 | 任务描述+直接推理 | Few-shot演示+推理 |
| 参数更新 | 预训练+微调都更新 | 仅预训练更新 | 仅预训练更新 |
| 计算成本 | 低(小模型) | 中等 | 极高(3.14×10²³ FLOPs) |
性能表现对比
| 任务类型 | GPT-1 | GPT-2 | GPT-3 (Few-shot) |
|---|---|---|---|
| 语言建模(PPL) | ~35 | ~10.6 | ~3.0 |
| 问答任务 | 需微调,~70% | Zero-shot ~55% | Few-shot ~85% |
| 翻译任务 | 不支持 | 初步能力 | 接近监督SOTA |
| 常识推理 | 需微调 | ~50-60% | ~70-80% |
| 算术运算 | 不支持 | 基本不支持 | 2位数100%,3位数~80% |
开源状况对比
| 项目 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 模型权重 | ✅ 完全开源 | ✅ 分阶段开源(最终全部) | ❌ 闭源 |
| 代码实现 | ✅ 开源 | ✅ 开源 | ❌ 闭源 |
| 训练数据 | ✅ 公开 | ⚠️ 部分公开 | ❌ 不公开 |
| API访问 | - | - | ✅ 商业API |
| 复现难度 | 低 | 中 | 极高(成本>$4.6M) |
| 社区贡献 | 活跃 | 非常活跃 | 仅通过API使用 |
技术创新对比
| 创新点 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 主要贡献 | 预训练+微调范式 | 零样本任务迁移 | 上下文学习能力 |
| 规模化探索 | 首次验证 | 10倍扩展 | 100倍扩展 |
| 任务通用性 | 低(需微调) | 中等 | 高(无需微调) |
| 涌现能力 | 无 | 初步显现 | 显著涌现 |
| 提示工程 | 不适用 | 简单任务描述 | 复杂提示设计 |
计算资源对比
| 资源需求 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 训练硬件 | 8× P100 GPU | 256× V100 GPU | 1000× V100 GPU |
| 训练时间 | ~1个月 | ~1-2个月 | ~1个月(大规模并行) |
| 训练成本 | ~$1-5万 | ~$25-50万 | ~$460万 |
| 推理需求 | 单GPU可行 | 单GPU可行(1.5B) | 多GPU必需(175B) |
| 内存占用 | ~500MB | ~6GB | ~350GB |
GPT-3 关键突破
规模效应定律
GPT-3验证了神经语言模型的缩放定律(Scaling Laws) :
L ( N ) = ( N c / N ) α N L(N) = (N_c/N)^{\alpha_N} L(N)=(Nc/N)αN
其中:
- L L L:测试损失
- N N N:模型参数数量
- N c N_c Nc:临界参数量
- α N ≈ 0.076 \alpha_N \approx 0.076 αN≈0.076:缩放指数
少样本学习性能公式
性能与示例数量的关系近似为:
Accuracy ( k ) = Accuracy 0 + β log ( 1 + k ) \text{Accuracy}(k) = \text{Accuracy}_0 + \beta \log(1 + k) Accuracy(k)=Accuracy0+βlog(1+k)
其中:
- k k k:上下文中的示例数
- Accuracy 0 \text{Accuracy}_0 Accuracy0:零样本基准性能
- β \beta β:学习效率系数(随模型规模增大)
总结与展望
GPT-3的核心贡献在于:
- 范式转变:从"预训练-微调"到"预训练-提示"
- 规模突破:证明了规模本身可以带来质的飞跃
- 能力涌现:大规模模型展现出小模型不具备的上下文学习能力
- 实用价值:无需任务特定数据即可达到实用性能
局限性:
- 计算成本极高
- 缺乏可解释性
- 存在偏见和安全问题
- 事实准确性无法保证
未来方向:
- 更高效的架构设计
- 指令微调(Instruction Tuning)
- 人类反馈强化学习(RLHF)
- 多模态扩展
GPT3 原文精选注解
摘要(Abstract)
最近的工作已经证明,通过在大型文本语料库上进行预训练,然后在特定任务上进行微调,可以在许多NLP 任务和基准测试上取得显著的进展。虽然在架构上通常是任务无关的,但这种方法仍然需要数千或数万个示例的任务特定微调数据集。相比之下,人类通常只需要几个示例或简单的指令就能执行新的语言任务------这是当前NLP 系统仍然难以做到的。在这里,我们展示了扩大语言模型的规模可以极大地改善任务无关的少样本性能,有时甚至可以达到与先前最先进的微调方法相匹配的竞争力。具体来说,我们训练了GPT-3 ,这是一个具有1750亿参数的自回归语言模型,比之前任何非稀疏语言模型大10倍,并在少样本设置下测试其性能。对于所有任务,GPT-3 的应用不需要任何梯度更新或微调,任务和少样本演示纯粹通过与模型的文本交互来指定。GPT-3 在许多NLP 数据集上取得了强劲的性能,包括翻译、问答和完形填空任务,以及需要即时推理或领域适应的几项任务,如解读单词、在句子中使用新词或执行3位数算术。同时,我们也确定了一些GPT-3 的少样本学习仍然存在困难的数据集,以及一些GPT-3 面临与在大型网络语料库上训练相关的方法论问题的数据集。最后,我们发现GPT-3 可以生成人类评估者难以区分是由人类撰写的新闻文章样本。我们讨论了这一发现和GPT-3总体上的更广泛社会影响。
这段摘要总结了GPT-3论文的核心贡献和发现:
核心要点
1. 研究背景与问题
- 当前NLP范式:预训练+微调需要大量任务特定数据(数千到数万示例)
- 人类能力对比:人类仅需几个示例或简单指令就能学习新任务
- 现有系统局限:当前NLP系统难以实现这种少样本学习能力
2. 主要贡献
- 模型规模:GPT-3拥有1750亿参数,比之前非稀疏模型大10倍
- 学习方式:无需梯度更新或微调,仅通过文本交互实现任务学习
- 少样本性能:显著改善任务无关的少样本学习,有时可匹敌最先进的微调方法
3. 性能表现
优势领域:
- 传统NLP任务:翻译、问答、完形填空
- 即时推理任务:解读单词、使用新词、3位数算术
局限性:
- 某些数据集上少样本学习仍有困难
- 存在大规模网络语料库训练带来的方法论问题
4. 重要发现
- GPT-3生成的新闻文章难以与人类撰写的区分
- 引发了关于更广泛社会影响的讨论
关键创新
这项工作的革命性在于证明了规模本身就是一种能力------通过大幅增加模型参数,可以实现接近人类的少样本学习能力,从而减少对任务特定训练数据的依赖。
1 引言(Introduction)
近年来,NLP 系统中出现了一种趋势,即以越来越灵活和任务无关的方式应用预训练语言表示进行下游迁移。首先,使用词向量 MCCD13, PSM14 学习单层表示并输入到任务特定架构中,然后使用具有多层表示和上下文状态的RNN 来形成更强的表示 DL15, MBXS17, PNZtY18 (尽管仍应用于任务特定架构),最近预训练的循环或transformer 语言模型 VSP+17 被直接微调,完全消除了对任务特定架构的需求 RNSS18, DCLT18, HR18 。
这最后一种范式在许多具有挑战性的NLP 任务上取得了实质性进展,如阅读理解、问答、文本蕴含和许多其他任务,并基于新的架构和算法继续推进 RSR+19, LOG+19, YDY+19, LCG+19 。然而,这种方法的一个主要限制是,虽然架构是任务无关的,但仍然需要任务特定的数据集和任务特定的微调:要在期望的任务上获得强大的性能,通常需要在该任务特定的数千到数十万个示例的数据集上进行微调。消除这种限制是可取的,原因有几个。
NLP技术演进路线
第一阶段:词向量时代
- 使用词向量学习单层表示,需要任务特定架构
第二阶段:上下文表示
- RNN提供多层表示和上下文状态,但仍需任务特定架构
第三阶段:预训练微调范式
- 预训练语言模型直接微调,消除任务特定架构需求
- 在阅读理解、问答、文本蕴含等任务取得突破
【局限1-实用性限制】首先,从实际角度来看,每个新任务都需要大量标记示例的数据集限制了语言模型的适用性。存在非常广泛的可能有用的语言任务,包括从纠正语法到生成抽象概念的示例,再到批评短篇小说的任何内容。对于许多这些任务,收集大型监督训练数据集是困难的,特别是当必须为每个新任务重复该过程时。
【局限2-泛化性问题】其次,利用训练数据中虚假相关性的潜力从根本上随着模型的表达能力和训练分布的狭窄性而增长。这可能会给预训练加微调范式带来问题,其中模型被设计得很大以在预训练期间吸收信息,但随后在非常狭窄的任务分布上进行微调。例如, HLW+20 观察到,更大的模型不一定在分布外具有更好的泛化能力。有证据表明,在这种范式下实现的泛化可能很差,因为模型对训练分布过于特定,无法很好地泛化到其外部 YdC+19, MPL19 。因此,微调模型在特定基准上的性能,即使名义上达到人类水平,也可能夸大了底层任务的实际性能 GSL+18, NK19 。
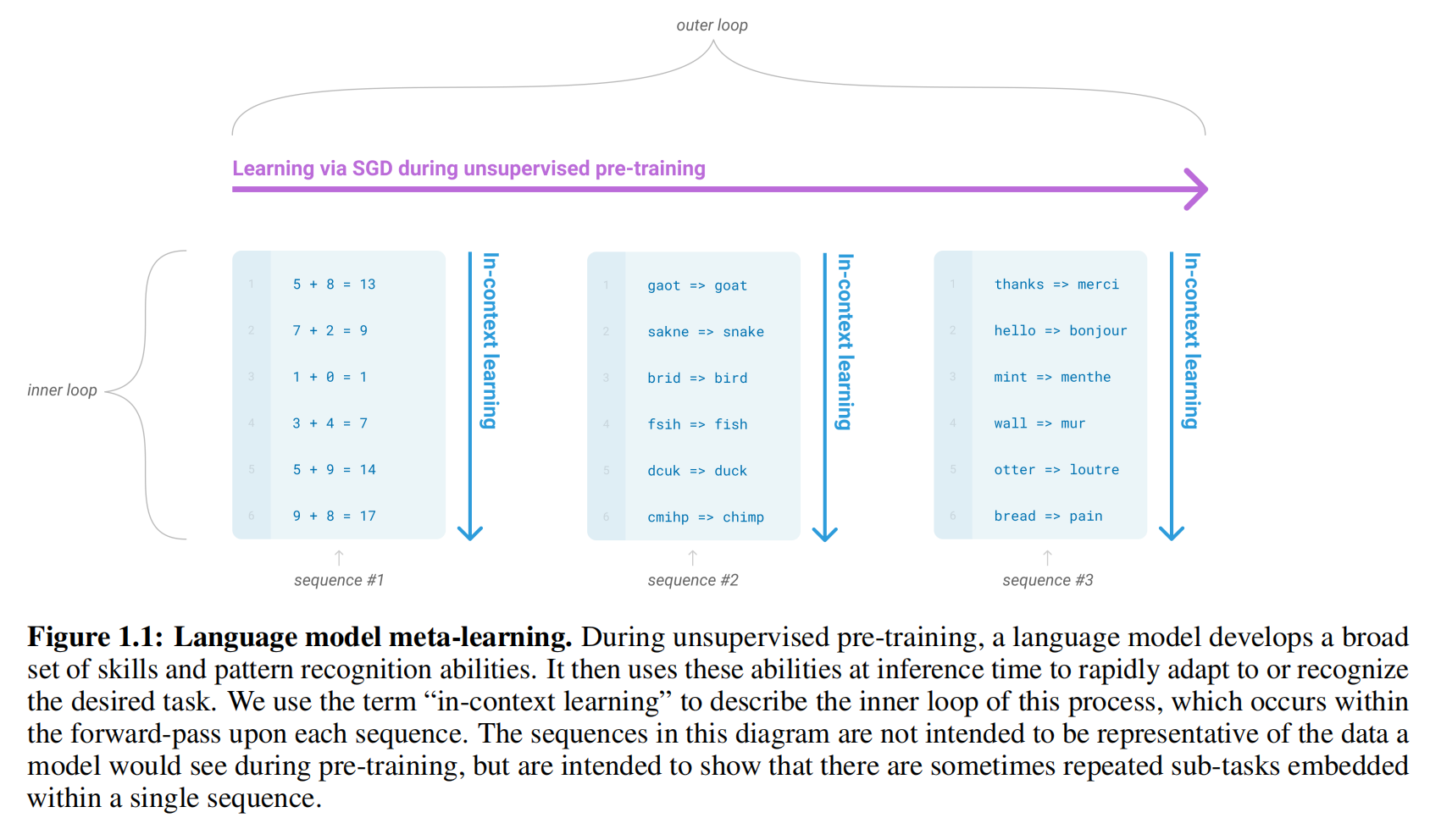
图1.1:语言模型元学习(Language model meta-learning) 。在无监督预训练期间,语言模型开发了一套广泛的技能和模式识别能力。然后它在推理时使用这些能力快速适应或识别所需的任务。我们使用术语"上下文学习(in-context learning)"来描述这个过程的内部循环,当从前向传递中的每个序列中得出的数据表示时发生。序列 #1 (sequence #1)、序列**#2 (sequence #2)、序列#3**(sequence #3)图中的序列旨在显示在单个序列中有时会出现重复的子任务。
图1.1 语言模型元学习机制解读
核心概念结构
双循环架构
- 外循环(outer loop) :无监督预训练阶段,通过SGD学习广泛能力
- 内循环(inner loop) :推理时的上下文学习,在单次前向传递中适应任务
学习过程示意
预训练阶段(紫色箭头)
通过SGD在海量无监督数据上学习,模型获得:
- 模式识别能力
- 多任务隐含知识
- 语言理解基础
三类任务示例
序列#1 - 算术任务
- 5 + 8 = 13
- 7 + 2 = 9
- 1 + 0 = 1
- 3 + 4 = 7
- 5 + 9 = 14
- 9 + 8 = 17
序列#2 - 单词解读
- gaot => goat
- sakne => snake
- brid => bird
- fsih => fish
- dcuk => duck
- cmihp => chimp
序列#3 - 翻译任务
- thanks => merci
- hello => bonjour
- mint => menthe
- wall => mur
- otter => loutre
- bread => pain
关键洞察
1. 任务的隐含学习
- 模型在预训练时遇到各种重复的子任务模式
- 无需显式标注,任务结构自然嵌入在文本序列中
- 同一序列可能包含多个相似的子任务实例
2. 上下文学习机制
- 推理时通过前几个示例识别任务模式
- 无需梯度更新即可完成新实例
- 利用预训练获得的模式识别能力
3. 元学习的涌现
- 外循环(预训练):学习如何学习
- 内循环(推理):应用学习能力解决具体任务
- 关键:大规模预训练使模型具备了"理解任务结构"的元能力
创新意义
这张图揭示了GPT-3的核心创新:将传统的"预训练-微调"范式转变为"预训练-上下文学习"范式。模型不是为特定任务调整参数,而是学会从上下文中理解和执行任务,这更接近人类的学习方式。
==【局限3- 与人类学习的差距】==第三,人类不需要大型监督数据集来学习大多数语言任务------自然语言中的简短指令(例如"请告诉我这句话描述的是快乐还是悲伤的事情")或最多一些演示(例如"这里有两个人表现勇敢的例子;请给出勇敢的第三个例子")通常足以使人类能够以至少合理的能力水平执行新任务。除了指出我们当前NLP 技术的概念限制外,这种适应性还具有实际优势------它允许人类无缝地混合或切换许多任务和技能,例如在冗长的对话期间执行加法。为了广泛有用,我们希望有一天我们的NLP系统具有同样的流畅性和通用性。
解决这些问题的一个潜在途径是元学习(meta-learning)¹------在语言模型的上下文中,这意味着模型在训练时开发了一套广泛的技能和模式识别能力,然后在推理时使用这些能力快速适应或识别所需的任务(如图1.1 所示)。最近的工作 RWC+19 尝试通过我们所谓的"上下文学习(in-context learning)"来做到这一点,使用预训练语言模型的文本输入作为任务规范的一种形式:模型以自然语言指令和/或任务的几个演示为条件,然后期望通过预测接下来的内容来完成任务的更多实例。
虽然它已经显示出一些初步的希望,但这种方法的结果仍然远不如微调------例如 RWC+19 在Natural Questions 上只达到4%,即使它的55 F1 CoQa结果现在也比最先进水平落后35分以上。元学习显然需要大幅改进才能成为解决语言任务的实用方法。
==【规模化假设】==语言建模中的另一个最新趋势可能提供了前进的道路。近年来,transformer 语言模型的容量大幅增加,从1亿参数 RNSS18 到3亿参数 DCLT18 ,到15亿参数 RWC+19 ,到80亿参数 SPP+19 ,110亿参数 RSR+19 ,最后到170亿参数 Tur20 。每次增加都带来了文本合成和/或下游NLP 任务的改进,有证据表明对数损失(log loss)与许多下游任务密切相关,遵循随规模改进的平滑趋势 KMH+20 。由于上下文学习涉及在模型参数内吸收许多技能和任务,因此上下文学习能力可能会随着规模显示出类似的强劲增长是合理的。
这段引言部分梳理了NLP领域的发展脉络和GPT-3的研究动机:
当前范式的三大局限
1. 实用性限制
- 每个新任务需要数千到数十万标注样本
- 许多任务难以收集大规模监督数据
- 限制了语言模型的广泛应用
2. 泛化性问题
- 大模型+窄分布微调容易过拟合
- 利用虚假相关性风险增加
- 分布外泛化能力不佳
- 基准性能可能夸大实际能力
3. 与人类学习的差距
- 人类:仅需简短指令或几个示例即可学习新任务
- 机器:需要大量标注数据
- 人类能力:灵活切换和混合多种任务
解决方案探索
元学习与上下文学习
- 训练时获得广泛技能和模式识别能力
- 推理时快速适应新任务
- 通过文本交互指定任务,无需梯度更新
- 现有尝试效果有限(如GPT-2)
规模化假设
- 模型参数呈指数级增长:1亿→3亿→15亿→80亿→110亿→170亿
- 对数损失随规模平滑改进
- 推测:更大规模可能带来更强的上下文学习能力
核心洞察
这段引言揭示了一个关键转变:从"为每个任务收集数据并微调"到"构建具有通用学习能力的大模型",这正是GPT-3要验证的核心假设------规模可以带来涌现的少样本学习能力。
==【术语体系】==¹在语言模型的上下文中,这有时被称为"零样本迁移(zero-shot transfer)",但这个术语可能有歧义:该方法在不执行梯度更新的意义上是"零样本(zero-shot)"的,但它通常涉及在推理时向模型提供演示,因此并不是真正从零个示例中学习。为避免这种混淆,我们使用术语"元学习(meta-learning)"来捕获通用方法的内循环/外循环结构,并使用术语"上下文学习(in-context learning)"来指代元学习的内循环。我们根据推理时提供的演示数量,进一步将描述专门化为"零样本(zero-shot)"、"单样本(one-shot)"或"少样本(few-shot)"。这些术语旨在对模型是否在推理时从头学习新任务或仅识别训练期间看到的模式这一问题保持不可知------这是我们稍后在论文中讨论的一个重要问题,但"元学习(meta-learning)"旨在涵盖两种可能性,并简单地描述内-外循环结构。
==【实验设计总结】==在本文中,我们通过训练一个1750亿参数的自回归语言模型(我们称之为GPT-3 )并测量其上下文学习能力来测试这一假设。具体来说,我们在二十多个NLP 数据集以及几个旨在测试对训练集中不太可能直接包含的任务快速适应的新任务上评估GPT-3 。对于每个任务,我们在3种条件下评估GPT-3 :(a)"少样本学习(few-shot learning)",或上下文学习,我们允许尽可能多的演示以适应模型的上下文窗口(通常为10到100个),(b)"单样本学习(one-shot learning)",我们只允许一个演示,以及(c)"零样本(zero-shot)"学习,不允许演示,只给模型自然语言的指令。GPT-3原则上也可以在传统的微调设置中进行评估,但我们将此留给未来的工作。
术语体系与实验设计总结
术语澄清的必要性
"零样本迁移"的歧义
- 传统理解:不使用梯度更新(✓)
- 实际情况:推理时仍可能提供演示(≠真正零示例)
- 需要更精确的术语体系
GPT-3的术语框架
层次化概念
- 元学习(Meta-learning)
- 最高层概念,描述整体学习框架
- 包含外循环(预训练)和内循环(推理时适应)
- 不预设学习机制(新学习vs模式识别)
- 上下文学习(In-context learning)
- 元学习的内循环部分
- 通过文本交互实现任务理解
- 无需参数更新
- 三种具体设置
- 零样本:仅自然语言指令
- 单样本:一个演示示例
- 少样本:10-100个示例(受上下文窗口限制)
实验设计核心
模型规模
- 1750亿参数的自回归语言模型
- 测试"规模→能力"假设
评估维度
- 20+个标准NLP数据集
- 新设计的泛化任务
- 三种学习设置的系统对比
- 不包括传统微调(留作未来工作)
关键哲学立场
保持开放性
- 不预判是"真正学习"还是"模式匹配"
- 术语设计保持理论中立
- 重点关注实证表现
核心创新
这个术语体系的建立不仅是为了准确描述,更重要的是定义了一种新的AI能力评估范式------从"需要多少训练数据"转向"需要多少演示示例",这是向更通用AI迈进的重要一步。
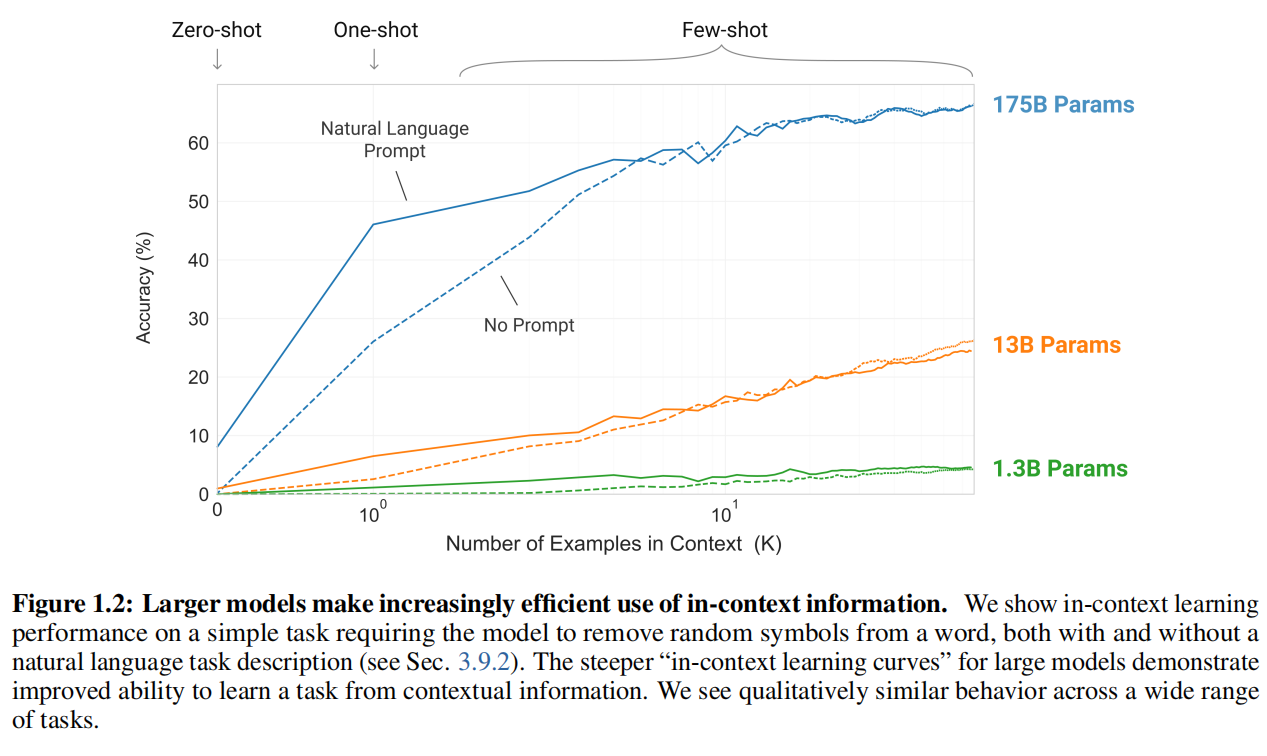
图1.2:更大的模型越来越有效地利用上下文信息(Larger models make increasingly efficient use of in-context information)。我们展示了一个简单任务的上下文学习性能,该任务要求模型从单词中删除随机符号,既有自然语言任务描述,也没有(参见第3.9.2节)。大型模型更陡峭的"上下文学习曲线(in-context learning curves)"展示了从上下文信息学习任务的改进能力。我们在广泛的任务中看到了质量上相似的行为。
图1.2 规模效应与上下文学习能力分析
实验任务
- 简单的符号删除任务:从含有随机符号的单词中恢复原词
- 测试模型理解任务并泛化的能力
关键变量对比
1. 模型规模效应
- 175B参数(蓝色) :性能最佳,学习曲线最陡峭
- 13B参数(橙色) :中等改进
- 1.3B参数(绿色) :几乎无改进能力
2. 提示词的影响
- 实线(有自然语言提示) :性能显著更好
- 虚线(无提示) :性能较差
- 提示词对大模型的帮助更明显
3. 示例数量的影响(K)
- 横轴:上下文中的示例数(对数刻度,0-100)
- 零样本(K=0)→ 单样本(K=1)→ 少样本(K=10-100)
- 大模型在少样本区间改进最显著
核心发现
规模带来的质变
- 小模型(1.3B) :即使给100个示例也几乎无法学习
- 中模型(13B) :有限的学习能力,改进缓慢
- 大模型(175B) :强大的上下文学习能力,快速改进
"学习曲线陡峭度"的意义
- 陡峭=高效利用示例信息
- 175B模型展现出质的飞跃
- 暗示存在能力涌现的阈值
提示词的放大效应
- 自然语言描述帮助模型理解任务意图
- 大模型更好地利用语言指令
- 体现了语言理解与任务执行的协同
理论意义
1. 验证核心假设
- 规模确实带来更强的上下文学习能力
- 不是简单的线性提升,而是能力的涌现
2. 实用启示
- 175B规模可能接近某个关键阈值
- 少量示例(10-50个)即可达到较好性能
- 自然语言指令的重要性
3. 普适性
- 论文指出"在广泛任务上看到类似行为"
- 暗示这不是特定任务现象,而是通用能力
结论
这张图提供了 "规模即能力" 假设的直接证据:当模型足够大时,它不仅是更好的模式匹配器,而是获得了真正的从上下文中学习新任务的能力,这是向通用人工智能迈进的关键一步。
图1.2 说明了我们研究的条件,并展示了一个简单任务的少样本学习,该任务要求模型从单词中删除无关符号。模型性能随着自然语言任务描述的添加和模型上下文中的示例数量K而提高。少样本学习也随着模型大小而显着改善。虽然这种情况下的结果特别引人注目,但对于我们研究的大多数任务,模型大小和上下文示例数量的一般趋势都成立。我们强调,这些"学习"曲线不涉及梯度更新或微调,只是增加作为条件给出的演示数量。
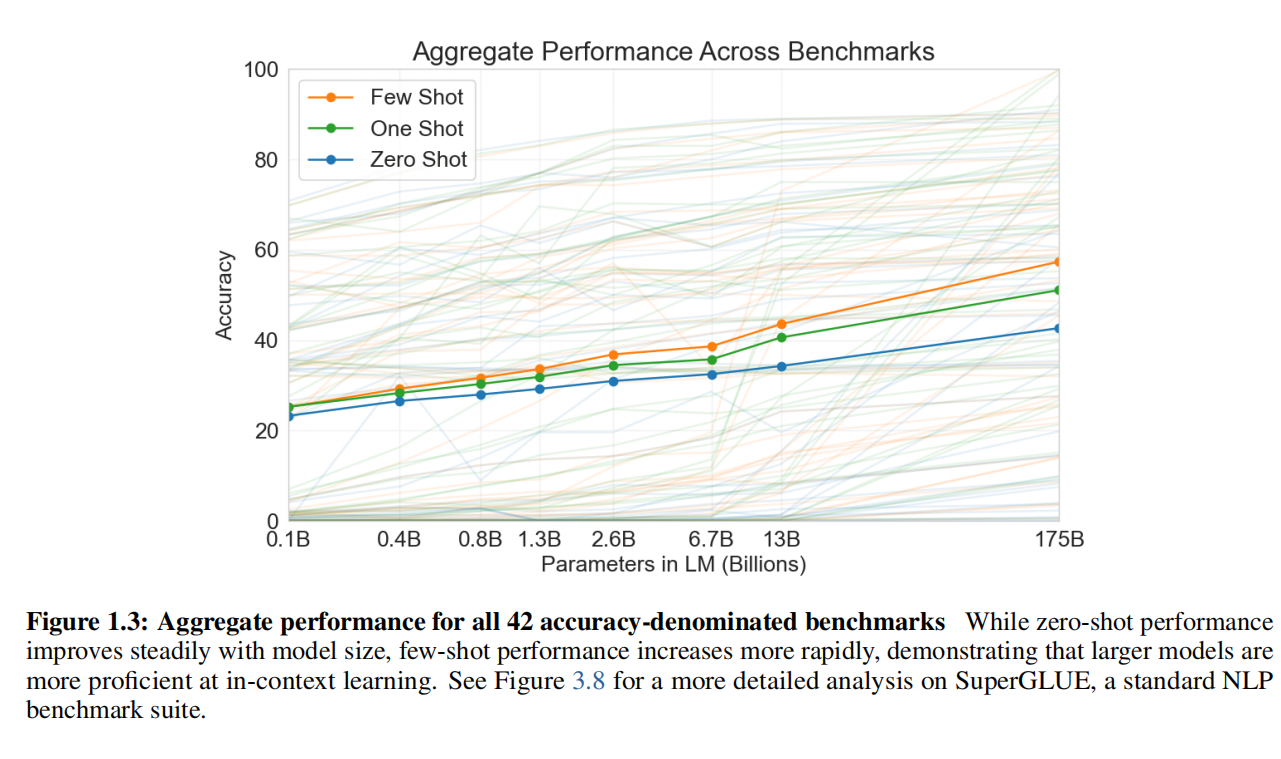
图1.3:所有42个以准确率为基准的基准测试的总体性能(Aggregate performance for all 42 accuracy-denominated benchmarks) 。虽然零样本性能随着模型大小稳步提高,但少样本性能增长更快,表明更大的模型在上下文学习方面更熟练。有关SuperGLUE (标准NLP 基准套件)的更详细分析,请参见图3.8。
图1.3 42个基准测试的综合性能分析
实验设置
- 评估范围:42个以准确率为指标的NLP基准测试
- 模型规模:0.1B到175B参数(横轴为对数刻度)
- 三种学习设置的系统性对比
性能趋势分析
1. 整体缩放规律
- 所有设置下性能都随规模提升
- 呈现平滑的对数增长趋势
- 未见明显的性能饱和
2. 三种设置的表现差异
- 少样本(橙色) :性能最佳,增长最快
- 单样本(绿色) :中等性能,稳定增长
- 零样本(蓝色) :基础性能,增长最缓
3. 关键性能指标
- 175B模型:
- 少样本:~57%
- 单样本:~51%
- 零样本:~43%
- 性能差距随规模扩大
重要发现
"剪刀差"现象
- 小模型(<1B):三种设置性能接近
- 大模型(>10B):差距显著拉大
- 175B时差距达到最大(约14个百分点)
少样本学习的加速效应
- 少样本曲线斜率最大
- 表明大模型更善于利用示例信息
- 验证了"大模型是更好的元学习器"假设
背景分布的意义
- 淡色线条:各个具体任务的性能
- 展示了任务间的巨大差异
- 有些任务接近100%,有些接近0%
- 平均值具有代表性
理论启示
1. 规模效应的普适性
- 跨42个不同任务的一致趋势
- 证明这不是特定任务的偶然现象
- 支持通用能力的涌现
2. 学习效率的质变
- 大模型不仅性能更好
- 更重要的是学习效率更高
- 从示例中提取信息的能力增强
3. 零样本的潜力
- 即使零样本也有稳定提升
- 175B达到43%已相当可观
- 暗示纯语言理解能力的增强
实践意义
1. 投资回报
- 规模投入带来的性能提升是可预测的
- 少样本设置下收益最大
2. 应用策略
- 实际应用中优先使用少样本
- 即使几个示例也能显著提升性能
3. 未来展望
- 曲线未见平台期
- 更大规模可能带来更多惊喜
核心结论
这张图提供了规模化定律在实际任务上的全面验证 :不仅是单个任务的成功,而是跨领域的普遍规律。更重要的是,它揭示了大模型在学习效率上的根本优势------这正是通向AGI的关键特征。
总的来说,在NLP 任务上,GPT-3 在零样本和单样本设置中取得了有希望的结果,在少样本设置中有时与最先进水平(尽管最先进水平由微调模型保持)具有竞争力,甚至偶尔超过它。例如,GPT-3 在零样本设置中在CoQA 上达到81.5 F1,在单样本设置中达到84.0 F1,在少样本设置中达到85.0 F1。类似地,GPT-3 在零样本设置中在TriviaQA上达到64.3%的准确率,在单样本设置中达到68.0%,在少样本设置中达到71.2%,最后一个是相对于在相同闭卷设置中运行的微调模型的最先进水平。
GPT-3还在旨在测试快速适应或即时推理的任务上展示了单样本和少样本熟练程度,包括解读单词、执行算术以及在仅看到一次定义后在句子中使用新词。
我们还进行了"数据污染(data contamination)"的系统研究------在Common Crawl 等数据集上训练高容量模型时,这是一个日益严重的问题,这些数据集可能包含测试数据集的内容,因为这些内容经常存在于网络上。在本文中,我们开发了系统工具来测量数据污染并量化其扭曲效应。尽管我们发现数据污染对GPT-3在大多数数据集上的性能影响很小,但我们确实确定了一些可能会夸大结果的数据集,我们要么不报告这些数据集的结果,要么根据严重程度用星号标注它们。
除了上述所有内容之外,我们还训练了一系列较小的模型(从1.25亿参数到130亿参数),以便在零样本、单样本和少样本设置中将它们的性能与GPT-3进行比较。总的来说,对于大多数任务,我们发现在所有三种设置中模型容量的缩放相对平滑;一个值得注意的模式是,零样本、单样本和少样本性能之间的差距通常随着模型容量的增长而增长,这可能表明更大的模型是更熟练的元学习器。
最后,鉴于GPT-3 展示的广泛能力,我们讨论了关于偏见、公平性和更广泛社会影响的担忧,并尝试对GPT-3在这方面的特征进行初步分析。
本文的其余部分组织如下。在第2节中,我们描述了训练GPT-3 和评估它的方法和方法。第3节在零样本、单样本和少样本设置中展示了全部任务的结果。第4节讨论数据污染(训练-测试重叠)问题。第5节讨论GPT-3的局限性。第6节讨论更广泛的影响。第7节回顾相关工作,第8节总结。
GPT-3主要成果与研究贡献总结
核心性能突破
1. 基准测试表现
- CoQA(阅读理解)
- 零样本:81.5 F1
- 单样本:84.0 F1
- 少样本:85.0 F1
- TriviaQA(问答)
- 零样本:64.3%
- 单样本:68.0%
- 少样本:71.2%(达到SOTA水平)
2. 关键成就
- 少样本性能接近或超越微调SOTA
- 无需任何梯度更新或任务特定训练
- 展示了真正的任务适应能力
创新能力展示
即时学习任务
- 解读打乱的单词
- 执行算术运算
- 一次定义后使用新词
- 证明了超越模式匹配的推理能力
方法论贡献
1. 数据污染研究
- 问题认识:网络规模训练集可能包含测试数据
- 系统方法:开发工具检测和量化污染
- 透明处理:标注或排除受影响数据集
- 研究诚信:确保结果的可信度
2. 规模化研究
- 模型梯度:1.25亿→130亿→1750亿参数
- 系统对比:全面评估不同规模的表现
- 平滑缩放:验证性能提升的可预测性
关键发现
元学习能力的涌现
- 零/单/少样本性能差距随规模扩大
- 大模型展现更强的示例利用能力
- 支持"规模→元学习能力"假设
社会责任考量
- 主动讨论偏见和公平性问题
- 分析潜在社会影响
- 体现负责任的AI研究态度
论文结构
- 引言(背景与动机)
- 方法(模型与训练)
- 结果(全面评估)
- 数据污染分析
- 局限性讨论
- 社会影响
- 相关工作
- 结论
核心价值
1. 范式转变
- 从"大量数据微调"到"少量示例学习"
- 更接近人类学习方式
- 降低AI应用门槛
2. 科学严谨
- 系统的多尺度实验
- 透明的局限性讨论
- 负责任的影响评估
3. 实践意义
- 减少标注数据需求
- 提高模型通用性
- 加速AI民主化
总体评价
GPT-3不仅是一个更大的语言模型,更代表了AI能力范式的根本转变------从专门训练到通用学习,从数据密集到示例高效,标志着向真正的通用人工智能迈出的重要一步。
2 方法(Approach)

图2.1:零样本、单样本和少样本,与传统微调的对比(Zero-shot, one-shot and few-shot, contrasted with traditional fine-tuning) 。上面的面板显示了使用语言模型执行任务的四种方法------微调是传统方法,而我们在这项工作中研究的零样本、单样本和少样本要求模型仅在测试时通过前向传递执行任务。我们通常在少样本设置中向模型展示几十个示例。所有任务描述、示例和提示的确切措辞可以在附录G中找到。
图2.1 深度解读:GPT-3的四种学习范式对比
图示结构分析
这张图清晰地展示了GPT-3探索的三种上下文学习设置 与传统微调方法的对比,通过英译法翻译任务作为示例。
左侧:上下文学习(GPT-3采用)
1. 零样本学习(Zero-shot)
特征:
- 仅提供自然语言任务描述
- 无需任何示例
- 无梯度更新
工作流程:
python输入:[任务描述: "Translate English to French:"] + [待翻译文本: "cheese =>"] 输出:模型直接预测优势:
- 最大便利性
- 无需准备示例数据
- 最接近人类直觉理解
劣势:
- 性能相对较低
- 任务理解可能有歧义
2. 单样本学习(One-shot)
特征:
- 任务描述 + 1个示例
- 模型通过单个示例理解任务模式
- 无梯度更新
工作流程:
python输入: [任务描述: "Translate English to French:"] [示例: "sea otter => loutre de mer"] [待翻译: "cheese =>"] 输出:基于示例模式预测优势:
- 最接近人类学习方式(看一个例子就懂)
- 显著提升任务理解准确性
3. 少样本学习(Few-shot)
特征:
- 任务描述 + 多个示例(2-100个)
- 模型从多个示例中归纳任务规律
- 无梯度更新
工作流程:
python输入: [任务描述: "Translate English to French:"] [示例1: "sea otter => loutre de mer"] [示例2: "peppermint => menthe poivrée"] [示例3: "plush giraffe => girafe peluche"] [待翻译: "cheese =>"] 输出:基于多示例模式预测优势:
- 性能最佳,接近微调水平
- 任务理解最准确
- 仍保持灵活性
右侧:传统微调(GPT-3不采用)
微调方法(Fine-tuning)
特征:
- 需要大量标注数据
- 多次梯度更新
- 改变模型参数
工作流程:
python训练阶段: [示例1] → 梯度更新 ↓ [示例2] → 梯度更新 ↓ ... [示例N] → 梯度更新 ↓ 推理阶段: [输入: "cheese =>"] → 输出传统优势:
- 特定任务性能最优
- 充分适应任务分布
GPT-3避免微调的原因:
- 需要大量任务特定数据
- 每个新任务都需重新训练
- 容易过拟合
- 失去通用性
核心对比维度
维度 零样本 单样本 少样本 微调 示例需求 0 1 2-100 数千-数万 梯度更新 ❌ ❌ ❌ ✅ 参数改变 ❌ ❌ ❌ ✅ 任务适应速度 即时 即时 即时 需训练时间 灵活性 最高 高 高 低 性能水平 基础 中等 接近最优 最优
关键洞察
1. 范式革命
- 从学习到理解:GPT-3不是"学习"任务,而是"理解"任务
- 从训练到推理:将适应能力从训练时转移到推理时
2. 效率提升
- 数据效率:从需要数千示例降至0-100个
- 计算效率:无需任何梯度计算和参数更新
- 时间效率:即时适应新任务
3. 能力本质
这张图揭示了GPT-3的核心能力:
- 模式识别:从极少示例中识别任务模式
- 类比推理:将示例模式应用到新输入
- 语言理解:通过自然语言理解任务意图
实践意义
对AI应用的影响
- 降低门槛:无需ML专业知识即可使用
- 快速原型:即时测试新任务
- 成本降低:无需标注大量数据
提示工程的诞生
这张图实际上标志着"提示工程(Prompt Engineering)"的诞生:
- 任务描述的措辞方式
- 示例的选择和排序
- 输入输出格式的设计
总结
图2.1不仅是方法对比,更是AI范式转变的里程碑:
- 证明了大规模预训练模型具备强大的任务适应能力
- 开创了无需微调的通用AI应用模式
- 为后续的ChatGPT、GPT-4等模型奠定了基础
这种"通过示例理解任务"的能力,正是人类智能的关键特征之一,GPT-3首次在人工系统中大规模实现了这一能力。
图2.1使用将英语翻译成法语的示例显示了四种方法。在本文中,我们关注零样本、单样本和少样本,目的不是将它们作为竞争替代方案进行比较,而是作为提供特定基准性能和样本效率之间不同权衡的不同问题设置。我们特别强调少样本结果,因为其中许多结果仅略落后于最先进的微调模型。然而,最终,单样本,甚至有时是零样本,似乎是与人类性能最公平的比较,并且是未来工作的重要目标。
我们的基本预训练方法,包括模型、数据和训练,与 RWC+19 中描述的过程相似,只是相对直接地扩大了模型大小、数据集大小和多样性以及训练长度。我们使用上下文学习的方式也与 RWC+19 相似,但在这项工作中,我们系统地探索了上下文内学习的不同设置。因此,我们通过明确定义和对比我们将评估GPT-3 的不同设置或原则上可以评估GPT-3 的不同设置来开始本节。这些设置可以看作是在它们倾向于依赖多少任务特定数据的谱系上。具体来说,我们至少可以在这个谱系上识别四个点(参见图2.1的说明):
-
微调(Fine-Tuning,FT) 近年来一直是最常见的方法,涉及通过在特定于所需任务的监督数据集上训练来更新预训练模型的权重。通常使用数千到数十万个标记示例。微调的主要优势是在许多基准测试上具有强大的性能。主要缺点是每个任务都需要新的大型数据集,可能出现分布外泛化不佳 MPL19 ,以及利用训练数据的虚假特征的潜力 GSL+18, NK19 ,可能导致与人类性能的不公平比较。在这项工作中,我们不对GPT-3 进行微调,因为我们的重点是任务无关的性能,但GPT-3原则上可以进行微调,这是未来工作的一个有希望的方向。
-
少样本(Few-Shot,FS) 是我们在本工作中将使用的术语,指的是在推理时给模型提供任务的几个演示作为条件 RWC+19 ,但不允许权重更新的设置。如图2.1 所示,对于典型的数据集,一个示例有一个上下文和一个期望的完成(例如一个英语句子和法语翻译),少样本通过给出K 个上下文和完成的示例,然后是一个最终的上下文示例,期望模型提供完成。我们通常将K 设置在10到100的范围内,因为这是可以适应模型上下文窗口的示例数量(nctx = 2048 )。少样本的主要优点是大大减少了对任务特定数据的需求,并减少了从大型但狭窄的微调数据集学习过于狭窄分布的可能性。主要缺点是到目前为止,这种方法的结果远不如最先进的微调模型。此外,仍然需要少量的任务特定数据。如名称所示,这里描述的语言模型的少样本学习与ML 中其他上下文中使用的少样本学习相关 HYC01, VBL+16 ------两者都涉及基于广泛的任务分布(在这种情况下隐含在预训练数据中)进行学习,然后快速适应新任务。
-
单样本(One-Shot,1S) 与少样本相同,除了只允许一个演示,以及任务的自然语言描述,如图1 所示。区分单样本与少样本和零样本(如下)的原因是它最接近某些任务传达给人类的方式。例如,在人工服务(例如Mechanical Turk)上要求人类生成数据集时,通常会给出任务的一个演示。
-
零样本(Zero-Shot,0S) 与单样本相同,除了不允许演示,模型只被给予描述任务的自然语言指令。这种方法提供了最大的便利性、鲁棒性的潜力以及避免虚假相关性(除非它们在大型预训练数据语料库中非常广泛地出现),但也是最具挑战性的设置。在某些情况下,即使对于人类来说,在没有先前示例的情况下理解任务的格式也可能很困难,因此这种设置在某些情况下是"不公平的困难"。例如,如果有人被要求"制作200米短跑世界纪录表",这个请求可能是模糊的,因为可能不清楚表格应该具有什么格式或应该包含什么(即使经过仔细澄清,准确理解所需的内容也可能很困难)。然而,对于至少某些设置,零样本最接近人类执行任务的方式------例如,在图2.1中的翻译示例中,人类可能仅从文本指令就知道该做什么。
下面的第2.1-2.3节分别给出了我们的模型、训练数据和训练过程的详细信息。第2.4节讨论了我们如何进行少样本、单样本和零样本评估的细节。
GPT-3方法论:四种学习范式的系统对比
研究延续与创新
- 基础:延续GPT-2的预训练方法
- 创新:系统探索不同的上下文学习设置
- 核心:从任务特定数据依赖的角度定义学习范式
四种学习范式详解
1. 微调(Fine-Tuning, FT)
方法:更新预训练模型权重
数据需求:数千到数十万标注样本
优势:
- 基准测试性能最强
- 当前主流方法
劣势:
- 每个任务需要大量新数据
- 分布外泛化差
- 易学习虚假相关性
- 与人类比较不公平
GPT-3策略:本文不采用,聚焦任务无关性能
2. 少样本(Few-Shot, FS)
方法:推理时提供K个示例(10-100个)
约束:无权重更新,受上下文窗口限制(2048 tokens)
优势:
- 大幅减少数据需求
- 避免过拟合窄分布
劣势:
- 目前性能不如微调SOTA
- 仍需少量任务数据
理论联系:与ML中的少样本学习概念相关
3. 单样本(One-Shot, 1S)
- 方法:仅一个演示+自然语言描述
- 动机:最接近人类任务传达方式
- 场景:类似众包平台的任务说明
- 特点:平衡了指导性和挑战性
4. 零样本(Zero-Shot, 0S)
方法:仅自然语言指令,无演示
优势:
- 最大便利性
- 最强鲁棒性
- 避免虚假相关
挑战:
- 最困难的设置
- 有时"不公平地困难"
- 任务理解可能有歧义
意义:最接近人类直觉理解
核心设计理念
1. 数据依赖谱系
python多 ← 数据需求 → 少 微调 → 少样本 → 单样本 → 零样本2. 权衡关系
- 性能 vs 数据效率
- 专门化 vs 通用性
- 确定性 vs 灵活性
3. 评估哲学
- 不是竞争关系,而是不同的问题设置
- 每种方法有其适用场景
- 重点关注少样本(接近微调性能)
- 长远目标是零/单样本(更接近人类)
实例说明(英译法)
- 微调:大量英法对训练
- 少样本:几十个翻译示例
- 单样本:一个翻译示例
- 零样本:"Translate English to French:"
研究聚焦
- 本文专注:零样本、单样本、少样本
- 不包括:传统微调(留作未来工作)
- 核心问题:任务无关的泛化能力
理论意义
1. 范式转变
- 从"为任务训练模型"到"模型理解任务"
- 从参数更新到上下文理解
2. 人机对比
- 单样本/零样本更接近人类学习
- 为公平比较提供基准
3. 实用价值
- 降低AI应用门槛
- 提高模型灵活性
- 减少计算资源需求
总结
这个方法论框架不仅定义了评估标准,更重要的是重新定义了"学习"在AI中的含义------从修改参数到理解指令,标志着向更智能、更通用的AI系统迈进。
2.1 模型和架构(Model and Architectures)
我们使用与GPT-2 RWC+19 相同的模型和架构,包括其中描述的修改后的初始化、预归一化和可逆标记化,除了我们在transformer 的层中使用交替的密集和局部带状稀疏注意力模式,类似于Sparse Transformer CGRS19 。为了研究ML 性能对模型大小的依赖性,我们训练了8种不同大小的模型,范围跨越三个数量级,从1.25亿参数到1750亿参数,最后一个是我们称为GPT-3 的模型。先前的工作 KMH+20 表明,有足够的训练数据,验证损失的缩放应该大致是大小的平滑幂律函数;训练许多不同大小的模型使我们能够测试这一假设,既适用于验证损失,也适用于下游语言任务。
表2.1 显示了我们8个模型的大小和架构。这里nparams 是可训练参数的总数,nlayers 是层的总数,dmodel 是每个瓶颈层中的单元数(我们总是将前馈层的大小设为瓶颈层的四倍,dff = 4 * dmodel ),dhead 是每个注意力头的维度。所有模型都使用nctx = 2048 个标记的上下文窗口。我们沿深度和宽度维度在GPU 之间划分模型,以最小化节点之间的数据传输。每个模型的精确架构参数是基于计算效率和跨GPU 的模型布局中的负载平衡来选择的。先前的工作 KMH+20 表明,在相当宽的范围内,验证损失对这些参数不是很敏感。
表2.1:我们训练的模型的大小、架构和学习超参数(批量大小以标记为单位,学习率)(Sizes, architectures, and learning hyper-parameters) 。所有模型都训练了总共3000亿个token。
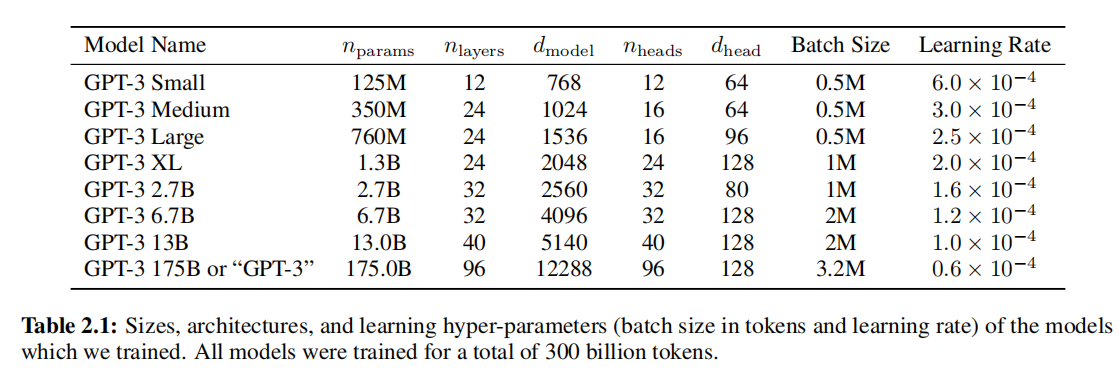
| 模型名称(Model Name) | nparams | nlayers | dmodel | nheads | dhead | 批量大小(Batch Size) | 学习率(Learning Rate) |
|---|---|---|---|---|---|---|---|
| GPT-3 Small | 125M | 12 | 768 | 12 | 64 | 0.5M | 6.0 × 10⁻⁴ |
| GPT-3 Medium | 350M | 24 | 1024 | 16 | 64 | 0.5M | 3.0 × 10⁻⁴ |
| GPT-3 Large | 760M | 24 | 1536 | 16 | 96 | 0.5M | 2.5 × 10⁻⁴ |
| GPT-3 XL | 1.3B | 24 | 2048 | 24 | 128 | 1M | 2.0 × 10⁻⁴ |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 | 80 | 1M | 1.6 × 10⁻⁴ |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 | 128 | 2M | 1.2 × 10⁻⁴ |
| GPT-3 13B | 13.0B | 40 | 5140 | 40 | 128 | 2M | 1.0 × 10⁻⁴ |
| GPT-3 175B或"GPT-3" | 175.0B | 96 | 12288 | 96 | 128 | 3.2M | 0.6 × 10⁻⁴ |
GPT-3模型架构与规模设计
技术基础
- 继承GPT-2架构:修改初始化、预归一化、可逆标记化
- 创新:交替密集和局部带状稀疏注意力(类似Sparse Transformer)
- 上下文窗口:统一2048 tokens
模型规模梯度
- 范围:125M → 175B参数(跨越3个数量级)
- 数量:8个不同规模模型
- 目的:验证性能-规模的幂律关系
架构参数解析
关键维度
- nparams:总参数量
- nlayers:Transformer层数(12→96)
- dmodel:隐藏层维度(768→12288)
- nheads:注意力头数(12→96)
- dhead:每个注意力头维度(64→128)
- 前馈层:dff = 4 × dmodel(固定比例)
训练配置规律
批量大小
- 小模型(<1B):0.5M tokens
- 中模型(1-3B):1M tokens
- 大模型(>3B):2M tokens
- GPT-3 175B:3.2M tokens
学习率
- 规律:随模型增大而递减
- 范围:6.0×10⁻⁴ → 0.6×10⁻⁴
- 体现"大模型需要更小学习率"原则
设计哲学
1. 计算优化
- 深度和宽度维度的GPU并行
- 最小化节点间数据传输
- 负载均衡考虑
2. 参数鲁棒性
- 研究表明验证损失对具体参数不敏感
- 允许基于硬件优化的灵活配置
3. 统一训练
- 所有模型训练3000亿tokens
- 保证公平比较
关键发现
规模效应验证【Scaling - Law】
- 175B是当时最大的非稀疏语言模型
- 层数和宽度同步增长
- 批量大小与模型规模正相关
核心创新
这个架构设计不仅是简单放大,而是系统性地探索了规模化的最优路径,为后续大模型研究提供了重要参考基准。
2.2 训练数据集(Training Dataset)
语言模型的数据集已经迅速扩展,最终形成了Common Crawl 数据集² RSR+19 ,包含近一万亿个单词。这个数据集的大小足以训练我们最大的模型,而不会在同一序列上更新两次。然而,我们发现未过滤或轻度过滤的Common Crawl 版本的质量往往低于更精心策划的数据集。因此,我们采取了3个步骤来提高数据集的平均质量:(1)我们下载并过滤了一个基于与一系列高质量参考语料库相似性的CommonCrawl 版本,(2)我们在文档级别执行模糊去重,在数据集内部和跨数据集,以防止冗余并保持我们的保留验证集的完整性,作为过拟合的准确测量,以及(3)我们还向训练组合中添加了已知的高质量参考语料库,以增强CommonCrawl并增加其多样性。
前两点(Common Crawl 的处理)的详细信息在附录A 中描述。对于第三点,我们添加了几个精心策划的高质量数据集,包括扩展版本的WebText 数据集 RWC+19 ,通过在更长的时间段内抓取链接收集,并首次在 KMH+20 中描述,两个基于互联网的书籍语料库(Books1 和Books2 )和英语Wikipedia。
表2.2 显示了我们用于训练的数据集的最终混合。CommonCrawl 数据是从涵盖2016年至2019年的41个月度CommonCrawl 分片下载的,在过滤前构成45TB的压缩纯文本,过滤后为570GB,大致相当于4000亿个字节对编码标记。请注意,在训练期间,数据集不是按其大小比例采样的,而是我们认为质量更高的数据集被更频繁地采样,因此CommonCrawl 和Books2数据集在训练期间采样不到一次,但其他数据集采样2-3次。这本质上接受了少量的过拟合,以换取更高质量的训练数据。
²https://commoncrawl.org/the-data/
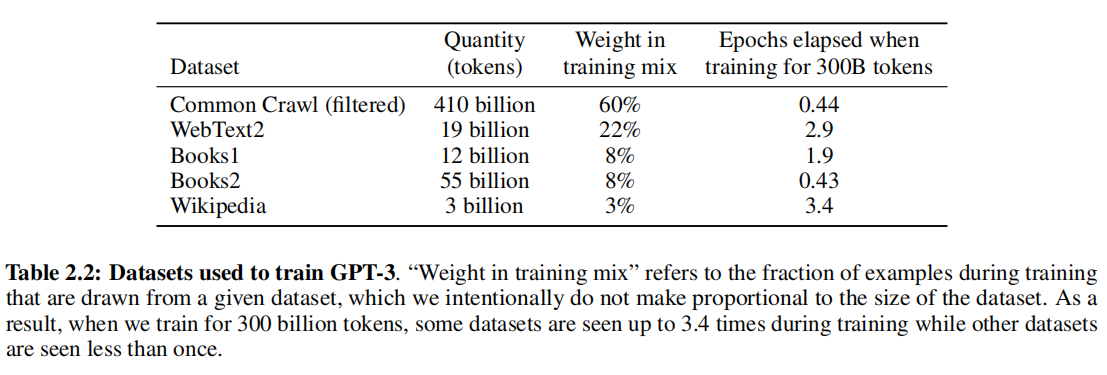
表2.2:用于训练GPT-3的数据集(Datasets used to train GPT-3) 。"训练混合中的权重(Weight in training mix)"是指训练期间从给定数据集中抽取的示例的比例,我们故意不使其与数据集的大小成比例。因此,当我们训练3000亿个标记时,一些数据集在训练期间被看到多达3.4次,而其他数据集被看到不到一次。
| 数据集(Dataset) | 数量(标记)(Quantity (tokens)) | 训练混合中的权重(Weight in training mix) | 训练3000亿标记时经过的轮数(Epochs elapsed when training for 300B tokens) |
|---|---|---|---|
| Common Crawl(过滤后) | 4100亿 | 60% | 0.44 |
| WebText2 | 190亿 | 22% | 2.9 |
| Books1 | 120亿 | 8% | 1.9 |
| Books2 | 550亿 | 8% | 0.43 |
| Wikipedia | 30亿 | 3% | 3.4 |
在广泛的互联网数据上预训练的语言模型的一个主要方法论问题,特别是具有记忆大量内容能力的大型模型,是下游任务可能受到污染,因为它们的测试或开发集在预训练期间无意中被看到。为了减少这种污染,我们搜索并尝试删除与本文研究的所有基准的开发和测试集的任何重叠。不幸的是,过滤中的一个错误导致我们忽略了一些重叠,并且由于训练成本,重新训练模型是不可行的。在第4节中,我们描述了剩余重叠的影响,在未来的工作中,我们将更积极地消除数据污染。
GPT-3训练数据集策略与质量控制
数据规模与挑战
- Common Crawl规模:近1万亿词,足够训练175B模型不重复
- 质量问题:原始Common Crawl质量低于精心策划的数据集
- 核心矛盾:规模vs质量的权衡
三步质量提升策略
1. 智能过滤
- 基于高质量参考语料库的相似性过滤
- 从45TB压缩文本→570GB(过滤后)
- 约4000亿BPE tokens
2. 模糊去重
- 文档级别去重
- 跨数据集去重
- 保护验证集完整性
3. 高质量数据增强
- WebText2(扩展版)
- Books1 & Books2(互联网书籍)
- Wikipedia(英文维基)
数据集组成与采样策略
数据集 规模 训练权重 实际轮数 Common Crawl 4100亿 60% 0.44轮 WebText2 190亿 22% 2.9轮 Books1 120亿 8% 1.9轮 Books2 550亿 8% 0.43轮 Wikipedia 30亿 3% 3.4轮 关键设计决策
非比例采样原则
- 质量优先于数量
- 高质量数据(WebText2、Wikipedia)过采样2-3次
- 大规模数据(Common Crawl、Books2)欠采样<1次
- 接受轻微过拟合换取质量
数据污染问题
挑战识别
- 测试集可能存在于训练数据中
- 大模型记忆能力强,污染影响更大
处理措施
- 主动搜索并删除测试集重叠
- 承认过滤bug导致的遗漏
- 第4节专门分析污染影响
- 体现研究透明度
创新点与价值
1. 质量控制框架
- 从源头(过滤)到过程(去重)到结果(混合)
- 系统性的数据质量工程
2. 采样策略创新
- 打破"大数据集=多采样"的惯例
- 基于质量的动态权重分配
3. 科学严谨性
- 主动识别数据污染风险
- 透明报告方法论缺陷
- 为后续研究提供经验
实践启示
数据质量>数据数量
- 570GB高质量数据训练175B模型
- 证明了数据效率的可能性
多样性的重要性
- 5个不同来源的数据集
- 覆盖网页、书籍、百科等多种文本类型
总结
GPT-3的数据策略展示了 "智能数据工程" 的范例:不是简单堆砌数据,而是通过精心的过滤、去重和混合策略,在规模和质量之间找到最优平衡,这对后续大模型训练具有重要参考价值。
2.3 训练过程(Training Process)
如 KMH+20, MKAT18 中所发现的,较大的模型通常可以使用较大的批量大小,但需要较小的学习率。我们在训练期间测量梯度噪声尺度,并使用它来指导我们的批量大小选择 MKAT18 。表2.1 显示了我们使用的参数设置。为了训练较大的模型而不耗尽内存,我们在每个矩阵乘法内使用模型并行性,并在网络层之间使用模型并行性。所有模型都在Microsoft 提供的高带宽集群的一部分上的V100 GPU 上训练。训练过程和超参数设置的详细信息在附录B中描述。
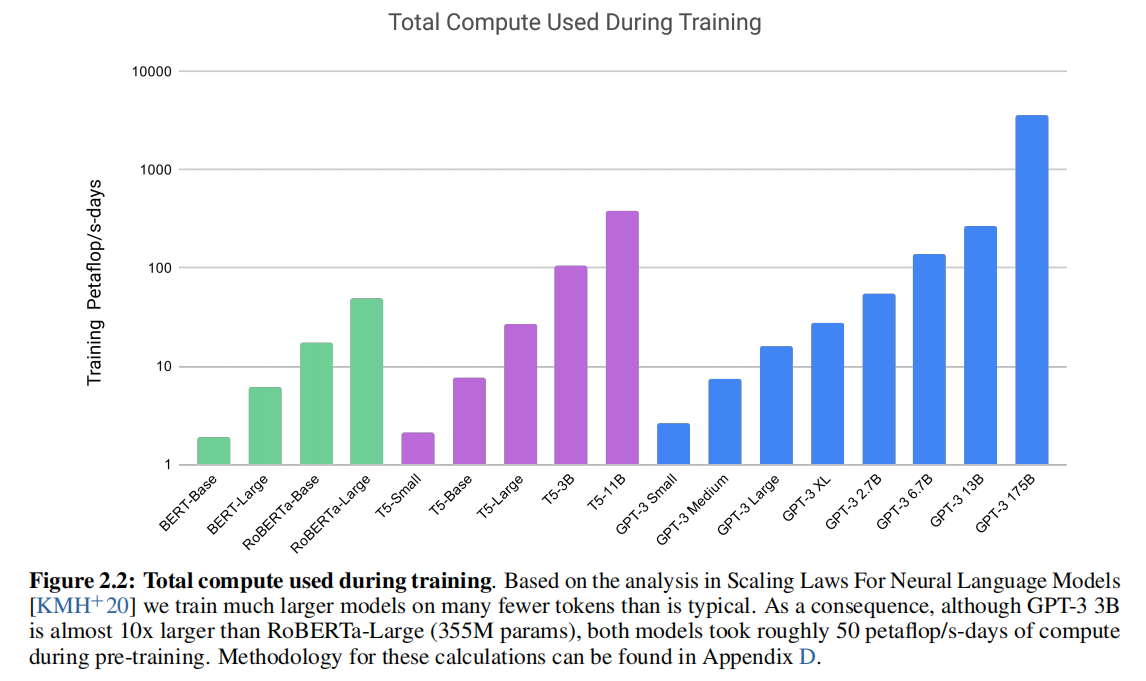
图2.2:训练期间使用的总计算量(Total compute used during training) 。基于 KMH+20 《神经语言模型的缩放定律》中的分析,我们在比典型情况少得多的标记上训练更大的模型。因此,尽管GPT-3 3B 几乎比RoBERTa-Large (3.55亿参数)大10倍,但两个模型在预训练期间都使用了大约50 petaflop/s-days的计算。这些计算的方法可以在附录D中找到。
2.3 训练过程总结
核心训练策略
超参数原则
- 大模型→大批量、小学习率
- 使用梯度噪声尺度指导批量大小选择
- 参数设置见表2.1(批量0.5M-3.2M,学习率6.0×10⁻⁴-0.6×10⁻⁴)
并行化策略
- 矩阵内并行:单个矩阵乘法的并行计算
- 层间并行:网络层之间的模型并行
- 解决大模型内存限制问题
硬件基础
- V100 GPU集群
- Microsoft提供的高带宽基础设施
- 详细配置见附录B
计算效率洞察(图2.2)
- 创新训练哲学:大模型+少标记 vs 小模型+多标记
- 实例对比:
- GPT-3 3B(10倍大)≈ RoBERTa-Large 计算量
- 都约50 petaflop/s-days
- 启示:通过模型规模换取数据效率
2.4 评估(Evaluation)
对于少样本学习,我们通过从该任务的训练集中随机抽取K 个示例作为条件来评估评估集中的每个示例,用1或2个换行符分隔,具体取决于任务。对于LAMBADA 和Storycloze ,没有可用的监督训练集,因此我们从开发集中抽取条件示例并在测试集上进行评估。对于Winograd (原始版本,不是SuperGLUE版本),只有一个数据集,因此我们直接从中抽取条件示例。
K 可以是从0到模型上下文窗口允许的最大值之间的任何值,对于所有模型,nctx = 2048 ,通常适合10到100个示例。较大的K 值通常但并不总是更好,因此当有单独的开发和测试集可用时,我们在开发集上试验几个K 值,然后在测试集上运行最佳值。对于某些任务(参见附录G ),我们除了演示之外(或对于K = 0,代替演示)还使用自然语言提示。
在涉及从几个选项中选择一个正确完成的任务(多项选择)上,我们提供K 个上下文加正确完成的示例,然后是一个仅上下文的示例,并比较每个完成的LM 似然。对于大多数任务,我们比较每个标记的似然(以标准化长度),然而在少数数据集(ARC 、OpenBookQA 和RACE )上,通过计算P(completion|context)/P(completion|answer context) 来标准化每个完成的无条件概率,我们在开发集上获得了额外的好处,其中answer context是字符串"Answer: "或"A: ",用于提示完成应该是答案但在其他方面是通用的。
在涉及二元分类的任务上,我们给选项提供更具语义意义的名称(例如"True"或"False"而不是0或1),然后像多项选择一样处理任务;我们有时也会像 RSR+19 所做的那样构建任务(详见附录G)。
在具有自由形式完成的任务上,我们使用与 RSR+19 相同的参数进行束搜索:束宽度为4,长度惩罚α = 0.6 。我们使用F1 相似性得分、BLEU或精确匹配来评分模型,具体取决于手头数据集的标准。
当公开可用时,最终结果在测试集上报告,针对每个模型大小和学习设置(零样本、单样本和少样本)。当测试集是私有的时,我们的模型通常太大而无法适应测试服务器,因此我们报告开发集上的结果。我们确实在少数数据集(SuperGLUE 、TriviaQA 、PiQa)上提交到测试服务器,在这些数据集上我们能够使提交工作,我们只提交200B少样本结果,并报告其他所有内容的开发集结果。
2.4 评估方法总结
少样本学习设置
示例采样
- 从训练集随机抽取K个示例
- 分隔符:1-2个换行符
- 特殊情况:
- LAMBADA/Storycloze:从开发集抽取
- Winograd:直接从数据集抽取
K值选择
- 范围:0到上下文窗口最大值(2048 tokens)
- 典型值:10-100个示例
- 策略:开发集调优,测试集评估
- 可选:自然语言提示辅助
任务类型处理
1. 多项选择任务
- 方法:比较各选项的LM似然
- 标准化:
- 默认:per-token似然(长度归一化)
- 特殊(ARC等):P(completion|context)/P(completion|answer context)
2. 二元分类任务
- 语义化标签:"True/False"替代"0/1"
- 当作多项选择处理
- 可选框架参考RSR+19
3. 自由生成任务
- 束搜索:宽度4,长度惩罚α=0.6
- 评分指标:
- F1相似性
- BLEU分数
- 精确匹配
结果报告策略
- 优先测试集:公开可用时
- 开发集替代:模型太大无法提交时
- 选择性提交:SuperGLUE、TriviaQA、PiQa仅提交175B少样本结果
方法论价值
训练创新
- 计算效率优化:规模vs数据的权衡
- 工程实践:大规模并行化方案
评估严谨
- 多样化任务处理方案
- 统一而灵活的评估框架
- 透明的结果报告策略
总体意义
这套训练和评估方法不仅实现了175B模型的成功训练,更重要的是建立了大模型时代的方法论标准,为后续研究提供了可复制的技术路线。
本文为个人阅读
GPT3,部分内容注解,由于GPT3原文篇幅较长,且GPT3无有效开源信息这里就不再一一粘贴,仅对原文部分内容做注解,仅供参考
详情参考原文链接原文链接:https://arxiv.org/pdf/2005.14165