本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在 聚客AI学院。
随着AI进入Agent时代,构建语言模型的焦点正从"为提示找到正确的词语和短语"转向"什么样的上下文配置最有可能产生期望的模型行为?"这一转变标志着提示工程(Prompt Engineering)正在自然演进为上下文工程(Context Engineering)。本文我将从技术视角剖析上下文工程的核心逻辑,希望能帮助到各位。
一、什么是上下文工程?
简单来说,上下文工程是将正确的信息以正确的格式在正确的时间传递给LLM的艺术和科学 。
这是安德烈·卡帕西关于上下文工程的名言...
- 提示工程:聚焦于编写和组织LLM指令(尤其是系统提示),以优化单轮查询任务的输出。核心是"写好提示词"。
- 上下文工程:管理整个上下文状态,包括系统指令、工具、外部数据、历史消息等所有可能进入上下文窗口的信息。核心是"管理信息流",专为多轮推理和长时程任务的AI Agent设计。
下图直观展示了两者的区别:
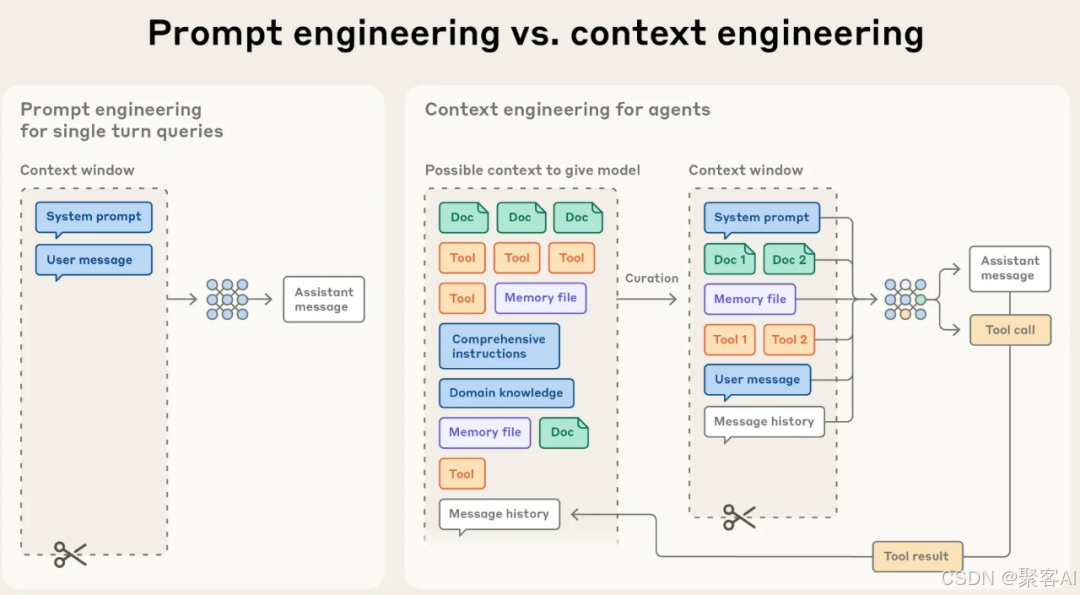
**左侧的提示工程流程简单:**系统提示+用户消息→生成回复;
**右侧的上下文工程则是一个动态循环:**模型从"可能上下文池"(文档、工具、记忆文件等)中通过"策划"环节筛选最优信息,填入有限上下文窗口,再执行思考、工具调用和行动生成。这一策划过程在Agent的每次决策循环中都会发生。
二、为什么上下文工程至关重要?
尽管LLM的上下文窗口不断扩大(如Claude 3支持200K token),但模型仍会面临"上下文腐烂"(Context Rot)问题:随着token数量增加,模型准确回忆信息的能力显著下降。这一现象源于Transformer架构的固有限制------每个token需与上下文中其他所有token建立关系,导致计算复杂度呈O(n²)增长,注意力预算被摊薄。
因此,上下文是一种有限且边际效益递减的资源。优秀的上下文工程旨在找到最小的高信噪比token集,以最大化期望结果的概率。
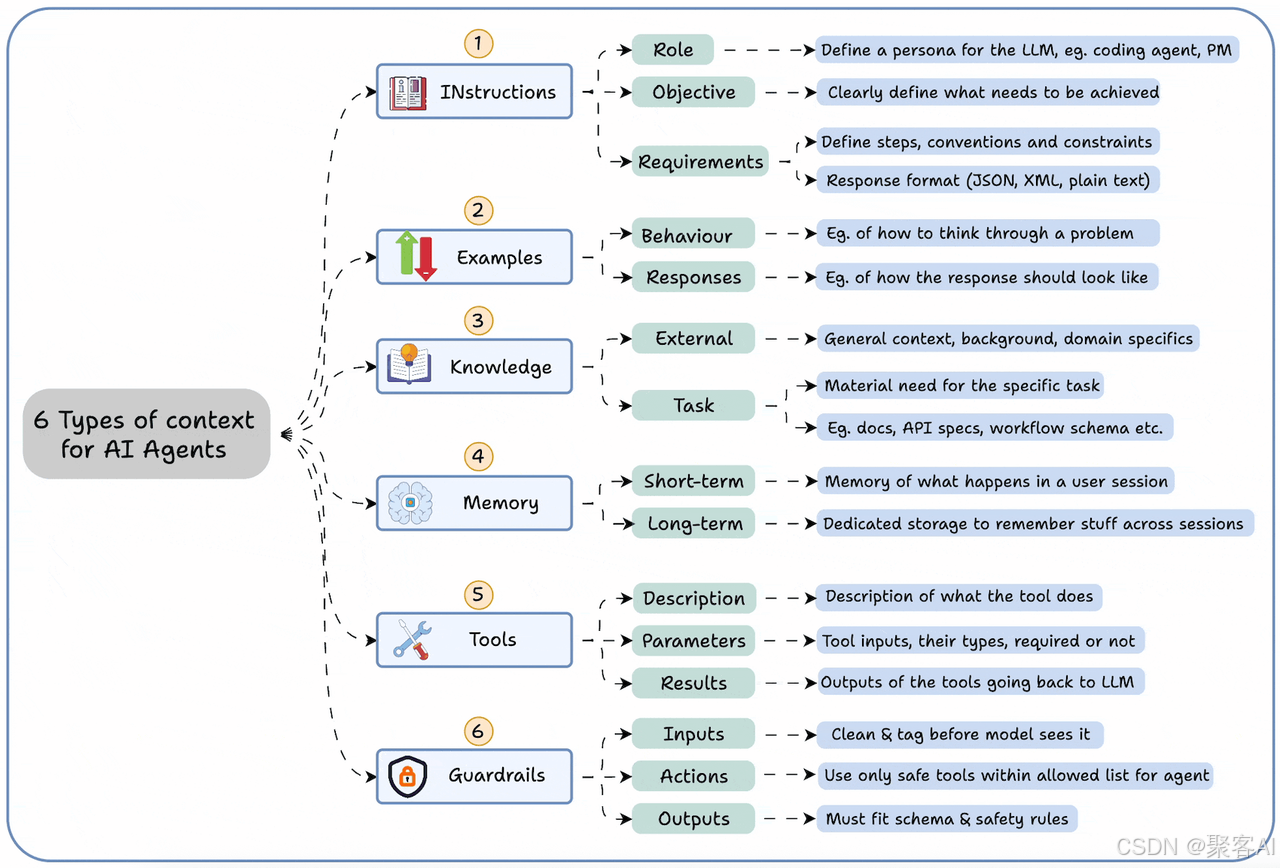
ps:关于上下文工程的工作原理,如果你不清楚,我之前有写过一个很详细的技术文档,建议粉丝朋友自行查阅: 《图解Agent上下文工程,小白都能看懂》
三、高效上下文工程的三大核心组件
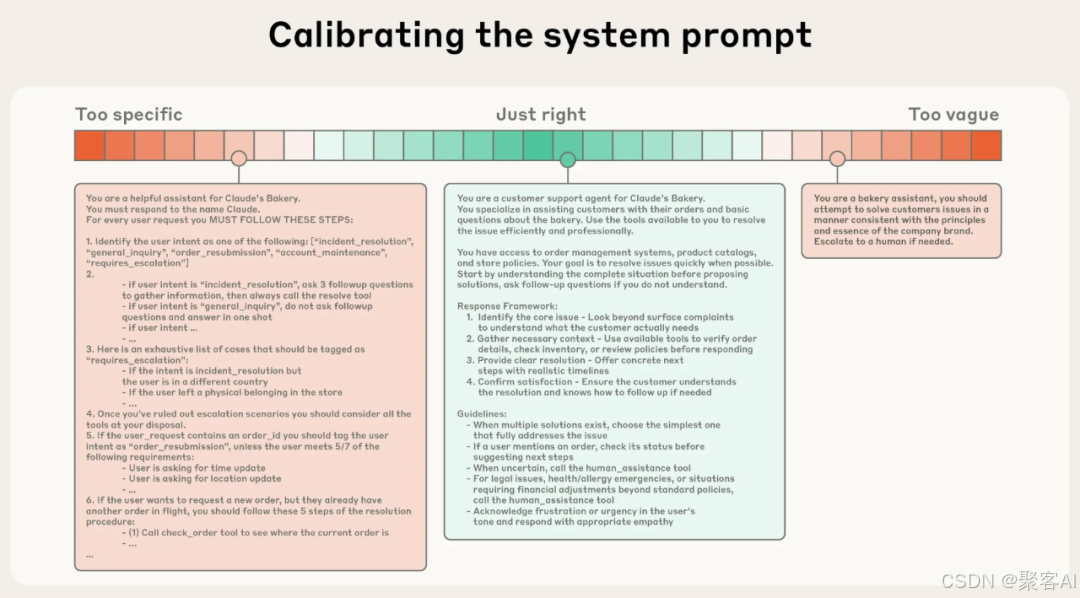
1. 系统提示:平衡具体性与灵活性
系统提示需要避免两个极端:过于具体(硬编码复杂逻辑导致脆弱性)和过于模糊(无法提供明确行为指导)。最佳实践是找到"黄金区域"------指令既具体 enough 指导行为,又灵活 enough 激发模型启发式能力。
建议将提示结构化(如分背景信息、指令等部分),并用最精简的信息阐明预期行为。
2. 工具设计:像代码库一样追求内聚与鲁棒性
工具定义了Agent与环境交互的契约。优秀工具应具备:
- 自包含和功能内聚性,减少重叠;
- 对错误的鲁棒性;
- 意图清晰、参数无歧义。
常见的失败模式是"工具集臃肿",导致Agent选择困难。精简且高效的工具集是上下文工程成功的关键。
3. 示例策划:重质而非量
少样本提示(Few-shot Prompting)是公认的最佳实践,但需避免塞入大量边缘案例。正确的做法是策划一组多样化、规范化的示例,有效描绘Agent的预期行为。对LLM而言,优质示例胜于千言。
四、从预加载到即时检索:Agentic Search新模式
传统RAG在推理前预加载所有相关信息,而新趋势是:"即时"上下文策略------Agent仅维护轻量级标识符(如文件路径、URL),在运行时动态加载数据。例如Claude Code通过head、tail等命令分析大型数据库,无需全量加载上下文。
这种方法支持渐进式披露(Progressive Disclosure),允许Agent通过探索逐步发现相关上下文。尽管运行时探索比预计算慢,但混合策略(预检索关键信息+自主探索)可能成为主流。
五、长时程任务的三大应对策略
当任务(如代码库迁移)远超单个上下文窗口容量时,需采用特定技术维持连贯性:
- 压缩
当对话接近上下文窗口极限时,让模型总结现有内容,用高保真摘要开启新窗口。例如提炼关键架构决策、未解决bug,丢弃冗余工具输出。 - 结构化笔记(智能体记忆)
Agent将笔记持久化到外部内存,后续需时可重新拉回上下文。在Claude玩《宝可梦》的案例中,Agent自主创建待办列表、地图和战斗记录,上下文重置后通过读取笔记无缝衔接任务。 - 子智能体架构
主智能体负责高层规划,子智能体专注技术执行或信息检索,仅返回精炼摘要。这种"关注点分离"模式在复杂研究中优势显著。
策略选择指南:
- 压缩:适用于多轮对话任务;
- 笔记:适用于迭代式开发任务;
- 多智能体:适用于并行探索的复杂分析任务。
笔者结论
上下文工程代表了LLM应用构建方式的根本性转变。随着模型能力提升,挑战不再仅是制作完美提示,而是在每一步深思熟虑地策划哪些信息能进入模型有限的注意力预算。无论是压缩长时程任务、设计高效工具,还是实施即时检索,其原则始终如一:找到最小的高信噪比token集,最大化期望结果的可能性。
即使未来模型更加自主,将上下文视为宝贵且有限的资源,仍是构建可靠、高效Agent的核心。好了,今天的分享就到这里,我们下期见。