开篇词|"眼脑手"结合,搞定Spring框架底层原理
我是一名深耕软件开发行业30年的老兵。欢迎你跟我一起手写MiniSpring,一个mini版的Spring框架。
在正式开始学习之前,我先介绍下我自己。说起来,我与Java和Spring打交道也有二十几年了。1998年我就加入了Sun Microsystems的Java团队,担任J2EE研发工程师,并在那里了解了Java专家Rodd Johnson、James Gosling等人的思想,见识了这些行业大牛的功力。
我就像是一个跟随哥伦布船队的小船员,有幸亲眼见证了这段精彩的历史。而这些经验和知识也深深影响了我的职业生涯,目前我依然活跃在代码一线,对Java和Spring的热爱依旧不减。
而这些年我在编程的同时,也一直在坚持写作,先后出版了《认识编程》《Java编程十五讲》《三字经注解》几本书,同时也很荣幸地成为了机械工业出版社专家委员会委员。对编程和写作多年的坚持,让我在技术实践与内容分享方面逐渐形成了一个正向的循环,总是喜欢把自己在技术方面的心得和实践转化成系统的知识。为此,我先后开发了MiniSpring,MiniTomcat,MiniRedis,MiniLanguage等几款开源软件,就是希望将这些知识传递给更多的人。
希望我的讲解能为Java和Spring布道,对你有所帮助。我将从IoC容器开始,带你一步步深入,直到完成一个属于自己的MiniSpring。希望你坚持下去,迈上一个崭新的台阶,到了那时,定会体会到"胸中自有沟壑"的美妙境界。
为什么建议你学习Spring底层原理?
现在这个时代,信息过载,选择过多,技术领域中各种新技术新工具层出不穷,让初学者不知从哪里下手,甚至都不知道该不该学某些技术,产生了许多困惑。那么哪些技术是我们应该花时间花精力去好好琢磨的呢?
众所周知,Java诞生二十几年来,一直是业界的主流语言和平台。而Spring则是Java开发的事实平台,我们说用Java编程,其实是在Spring框架上编程。即便最近几年进化到用分布式架构如Spring Cloud进行开发,它的底层内核仍然是Spring框架。因此,作为专业程序员,深度理解Spring Framework是很必要和重要的。对Spring这个基础框架的理解,能让我们 以不变应万变,把握住技术快速流变中相对稳定的内核。
而我们平时的工作中,大部分的时间都是在调用工具包,快速搭建出客户所需要的应用程序,没有意识到需要了解底层原理。那为什么我们还要费力了解Spring的内部结构呢?对这个常见的困惑,我是这么看待的:站在应用程序的角度,不理解所用工具的原理,不太会影响你构建应用程序的进度。但是,理解了原理,你就知道了所以然, 工作过程中会更加高效准确地使用平台工具,提高应用程序的质量,如结构的扩展性和需求变化的适应性。
俗话说,下棋找高手,弄斧到班门。在学习Spring框架的过程中,分析程序结构,阅读源代码,还能让我们体会到世界顶级程序员作品的精妙之处。我们可能达不到他们那种高度和深度,但是通过学习、模仿,也能让我们的水平有本质的提升。
更进一步,我们自己在工作中, 了解了这些底层技术,就会有意识地去借鉴这些大师们的结构,让我们自己能承担更加困难、更加复杂的工作。 比如,当我们应对各种用户需求,编写增删改查等类似程序的时候,就可以回想一下,Spring框架中是如何管理用户业务,如何抽象出Bean这个概念,以及定义Bean的生命周期的,我们可以通过模仿这种技巧,提出业务表单的概念,定义它的生命周期,然后构造一个业务框架,让用户自定义表单,注册进框架,由框架自动管理运行它。现在,市面上很多成功的OA产品就来自这个简单的模仿。
当我们的工作到达了系统框架这个级别的时候,你就会时不时地想起那些大师的作品,如Spring框架、Tomcat、JDK、Redis等等,他们如何用简洁的模型、统一的技术栈,来处理千变万化的应用。他们的设计原则和模式,他们宏大的架构考量,他们的代码技巧,会给我们丰富的养分,带领我们走向专业之路。
如何高效地掌握Spring原理?
今天,我们在学习Spring的过程中,面对的一个问题是它已经是一个庞大而复杂的体系了,虽然它是开源的,代码之下了无秘密,但是面对源代码的汪洋大海,很多技术人经常会迷失其中,因一次次的挫败而导致最后只有望洋兴叹。但是回顾历史,Spring并不是生下来就是这么庞大的,它也是从小一步步长大的。作为后来者,我们的问题是只见到了长大后的Spring,没有了解到它是怎么成长起来的。失去了这个过程,就会让学习的路径变得很艰难。
其实Spring的发明者Rodd Johnson,开头的想法很简单,只是希望有一个简单的框架让程序员专注于自己的业务开发,通过框架的配置就能让不同业务单元组合在一起。这个想法其实在Sun公司Java团队提出的EJB中就有了充分的考虑。但是Rodd Johnson认为EJB过于庞大复杂,而且是侵入式的,会对上层程序员有很多限制,他对EJB进行了激烈地批评并决心构建一个小的框架,于是跟Java团队分道扬镳,这是我当时在Sun Java团队的时候发生的故事。之后的事情就是众所周知的历史了:Java团队的掌上明珠EJB被悉尼大学的Rod Johnson这个音乐学博士单枪匹马挑下马,最后完败于Spring。
因此,本课程采用快速迭代的开发模式,从一个最简单的程序开始,一步步堆积演化,每写一小段代码,都是一个可运行的程度。 在不断迭代中完善框架功能,最终实现Spring框架的核心:IOC、MVC、JDBC Template和AOP。 在一步步的迭代过程中,将Spring的底层原理融入代码中,一层层对照Spring框架的现有结构,让原理理解起来不再困难。
我们自己动手,尽量少用现成的包,以刀耕火种的方式写程序,这可以让我们彻底地理解底层原理。希望你能够从一开始就跟我一起动手,毕竟编程说到底是一个手艺活,就是动手去写,要坚持不断地练习,就能大有成效。
我自己也是经历了这么一个过程:开始只是使用框架平台,很快到了一个瓶颈;之后就开始阅读源码,了解原理解决困惑,但是仍然处于似懂非懂的状态;后来就尝试自己动手写Spring,遇到问题想破脑袋后翻查Spring的源代码,在一遍一遍地挫折借鉴中打通关节,终于有一天豁然开朗。
我们学习MiniSpring的目标是掌握Spring框架,所以我们不会自己独创什么概念和结构,而是老老实实按照Spring的结构模仿着手写。因此我们的目录结构、包名、类名接口名、继承体系、类中的主要方法名都是原封不动照搬Spring框架的。这是为了今后你一头扎进Spring框架的源代码中的时候不至于迷失方向,能很快地畅游于Spring的大海中。
课程设计
我们MiniSpring的课程大体上分成四大部分:IoC容器、MVC、JDBC Tempalte和AOP。
熟悉Spring框架的人也知道,这四大部分就是Spring框架的核心了。学好这些,今后你扩展到更多方面也会很容易。
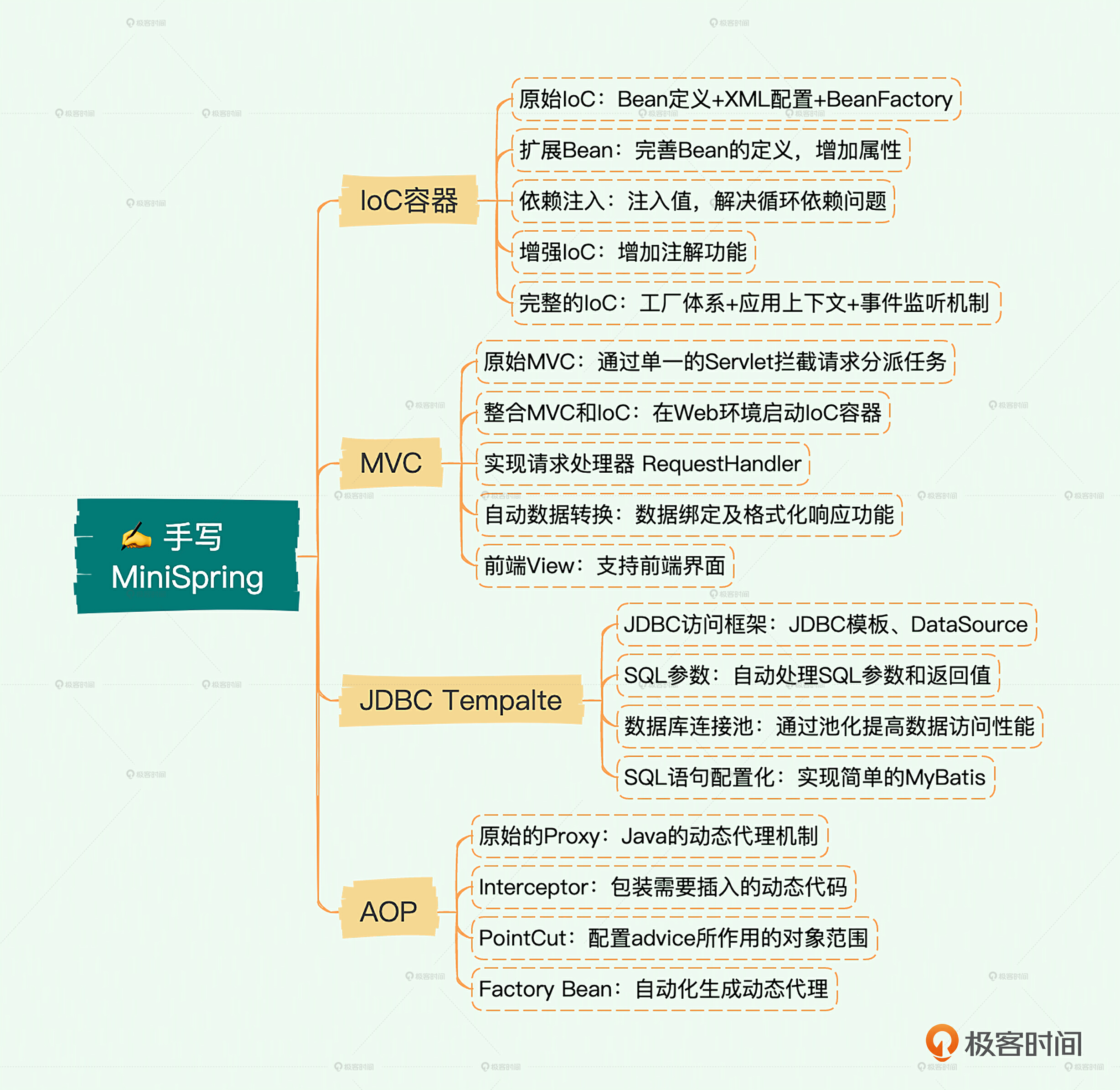
第一部分:IoC容器
IoC容器是Spring核心中的核心,Spring抽象出Bean这个概念,用一个容器管理所有的Bean,并解决上层应用的业务对象之间的耦合问题。后面所有的特性都依赖于Bean的概念和这个容器。因此即使我们简单地说Spring框架就是一个IoC容器也未尝不可。
这个部分我们会从一个极简容器开始,逐步扩展增强,最终实现一个完整的IoC容器,包含Spring框架对应的核心功能,实现Bean的管理。基于这个核心,逐步扩展到MiniSpring的其他特性。打好这个基础,后面的学习会事半功倍。
第二部分:MVC
MVC是Spring支持Web模式的程序结构,它是基于Servlet技术实现的。基本思路是利用Servlet机制,用一个单一的Servlet拦截所有请求,然后根据请求里面的的信息把任务分派给不同的业务类处理,实现原始的MVC结构。
在这一部分,我们还会将MVC与第一部分的IoC容器结合起来,构成一个更大、更完整的框架。在一步步的构造过程中,我们会重点讲解大师们怎么逐步拆解这个Servlet的功能,把专业的事情交给专门的部件去做,最后构建成一个完整的体系。
第三部分:JDBC Template
JDBC Tempalte是Spring对数据访问的一个实现,我们会重点分析Spring的实现方法,体现Rodd Johnson对简洁实用原则的把握。这一部分,我们会学习如何提取出一个JDBC访问的模板,来固化访问数据库的流程,怎么自动绑定参数值,简化上层应用程序。在此基础之上,我们还将了解到如何通过数据库连接池提高访问性能,以及模仿MyBatis将SQL语句配置到外部文件中。
通过这部分的学习,我们可以了解到,整个JDBC Template的实现都是运用了前面IoC管理Bean的方式,将数据的访问抽象成一个个Bean,注入到系统中。由此,更能深刻体会到IoC容器的功用。
第四部分:AOP
AOP是Spring框架中实践面向切面编程的探索。面向对象和面向切面,两者一纵一横,编织成完整的程序结构。在这一部分,我们将了解到Spring AOP所采用的一个实现方式:JDK动态代理。我们会学习动态代理的原理,以及如何用这个技术动态插入业务逻辑,实现切面的特性。
最后我们将再一次看到AOP与IoC的结合,使用BeanPostProcessor自动生成动态代理。这时你就会体会到,我前面说的"IoC是Spring框架核心中的核心"。
在这一步一步的演化过程中,我们对Spring的模仿逐渐成型。我坚持一个原则,就是每一步都是可以运行的,都会有看得见的收获,你不需要辛辛苦苦等到最后才能看到成果。当然,自己动手模仿Spring,是一个难度较大的工作,风景虽好,但过程也是充满艰辛的,最后的果实属于不断探索的人。任何一个技术领域都是这样,不断练习,反复琢磨,最后才能站在山顶。
《诗经》有云:"有匪君子,如切如磋,如琢如磨"。虽然中途会遇到困难,但我希望你可以坚持学习,站到山顶,跟我一起领略Spring的风采!
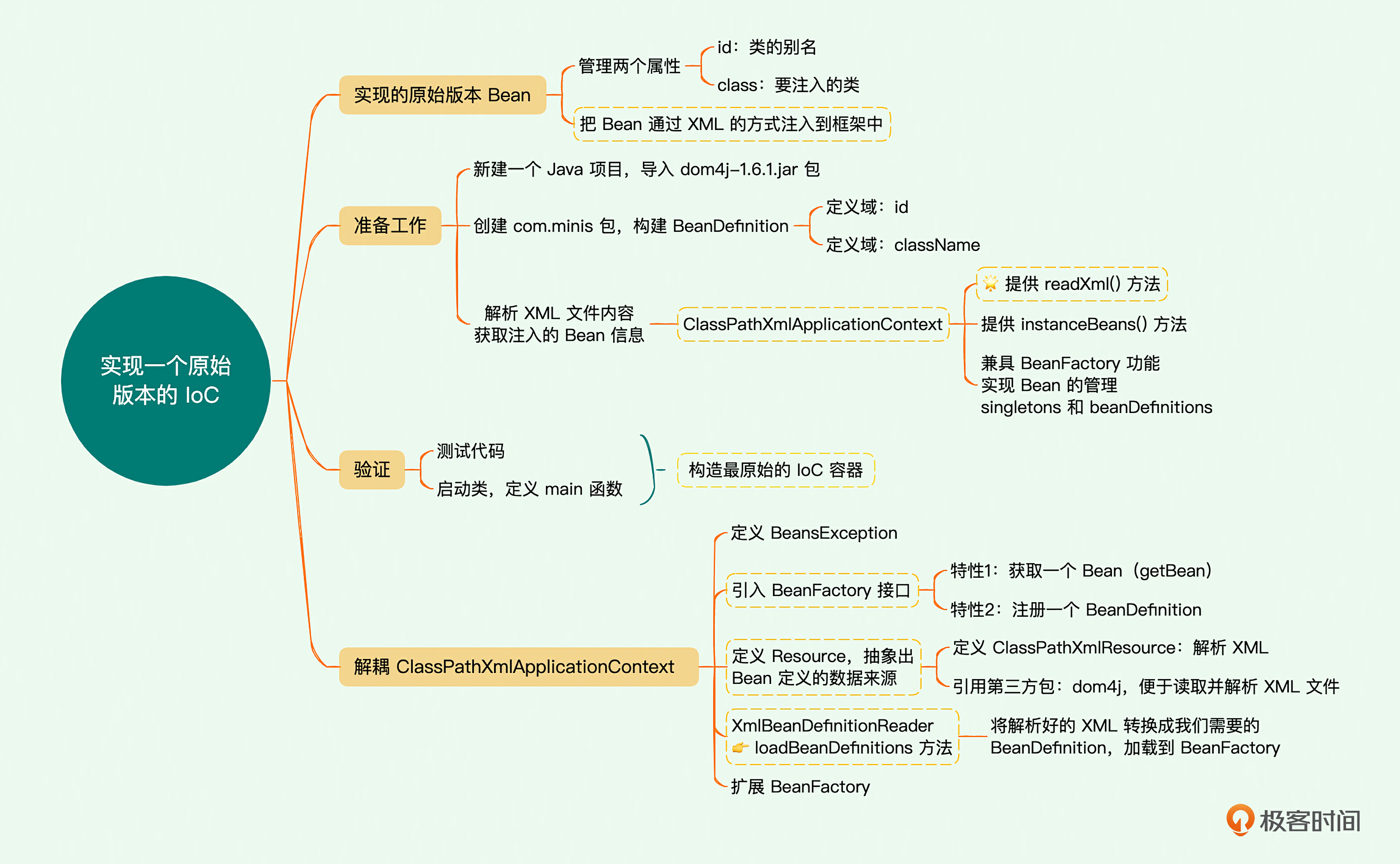
01|原始IoC:如何通过BeanFactory实现原始版本的IoC容器?
IoC容器
如果你使用过Spring或者了解Spring框架,肯定会对IoC容器有所耳闻。它的意思是使用Bean容器管理一个个的Bean,最简单的Bean就是一个Java的业务对象。在Java中,创建一个对象最简单的方法就是使用 new 关键字。IoC容器,也就是 BeanFactory,存在的意义就是将创建对象与使用对象的业务代码解耦,让业务开发人员无需关注底层对象(Bean)的构建和生命周期管理,专注于业务开发。
那我们可以先想一想,怎样实现Bean的管理呢?我建议你不要直接去参考Spring的实现,那是大树长成之后的模样,复杂而庞大,令人生畏。
作为一颗种子,它其实可以非常原始、非常简单。实际上我们只需要几个简单的部件:我们用一个部件来对应Bean内存的映像,一个定义在外面的Bean在内存中总是需要有一个映像的;一个XML reader 负责从外部XML文件获取Bean的配置,也就是说这些Bean是怎么声明的,我们可以写在一个外部文件里,然后我们用XML reader从外部文件中读取进来;我们还需要一个反射部件,负责加载Bean Class并且创建这个实例;创建实例之后,我们用一个Map来保存Bean的实例;最后我们提供一个getBean() 方法供外部使用。我们这个IoC容器就做好了。
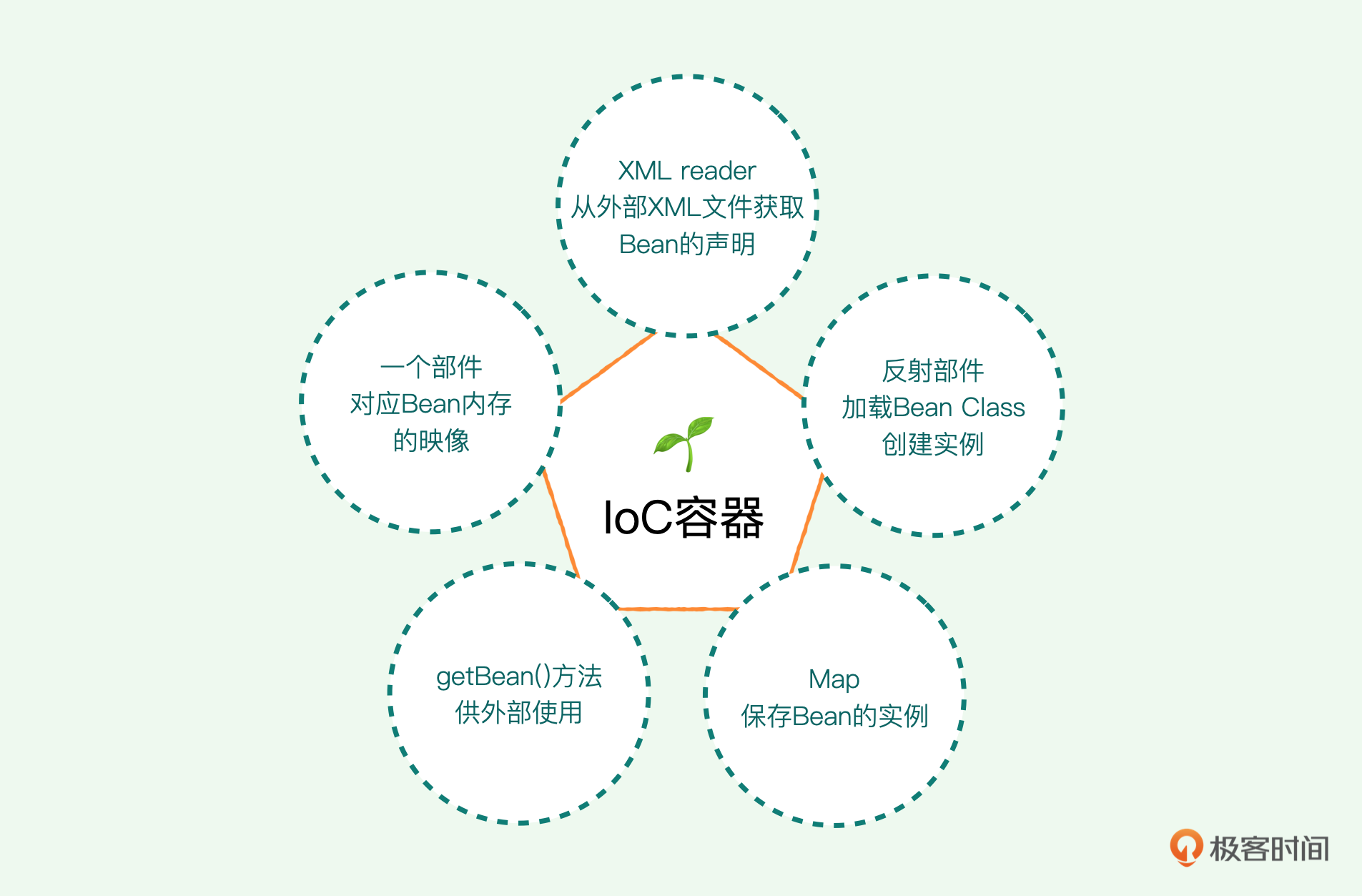
好,接下来我们一步步来构造。
实现一个原始版本的IoC容器
对于现在要着手实现的原始版本Bean,我们先只管理两个属性: id与class。其中,class表示要注入的类,而id则是给这个要注入的类一个别名,它可以简化记忆的成本。我们要做的是把Bean通过XML的方式注入到框架中,你可以看一下XML的配置。
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id = "xxxid" class = "com.minis.xxxclass"></bean>
</beans>接下来我们要做一些准备工作。首先,新建一个Java项目,导入dom4j-1.6.1.jar包。这里导入的dom4j包封装了许多操作XML文件的方法,有助于我们快速处理XML文件中的各种属性,这样就不需要我们自己再写一个XML的解析工具了,同时它也为我们后续处理依托于XML注入的Bean提供了便利。
另外要说明的是,我们写MiniSpring是为了学习Spring框架,所以我们会尽量少地去依赖第三方包,多自己动手,以原始社会刀耕火种的方式写程序,这可以让我们彻底地理解底层原理。希望你能够跟我一起动手,毕竟编程说到底是一个手艺活,要想提高编程水平,唯一的方法就是动手去写。只要不断学,不断想,不断做,就能大有成效。
构建BeanDefinition
好了,在有了第一个Java项目后,我们创建com.minis包,我们所有的程序都是放在这个包下的。在这个包下构建第一个类,对应Bean的定义,命名为BeanDefinition。我们在这个类里面定义两个最简单的域:id与className。你可以看一下相关代码。
java
public class BeanDefinition {
private String id;
private String className;
public BeanDefinition(String id, String className) {
this.id = id;
this.className = className;
}
//省略getter和setter可以看到,这段代码为这样一个Bean提供了全参数的构造方法,也提供了基本的getter和setter方法,方便我们获取域的值以及对域里的值赋值。
实现ClassPathXmlApplicationContext
接下来,我们假定已经存在一个用于注入Bean的XML文件。那我们要做的自然是,按照一定的规则将这个XML文件的内容解析出来,获取Bean的配置信息。我们的第二个类ClassPathXmlApplicationContext就可以做到这一点。通过这个类的名字也可以看出,它的作用是解析某个路径下的XML来构建应用上下文。让我们来看看如何初步实现这个类。
java
public class ClassPathXmlApplicationContext {
private List<BeanDefinition> beanDefinitions = new ArrayList<>();
private Map<String, Object> singletons = new HashMap<>();
//构造器获取外部配置,解析出Bean的定义,形成内存映像
public ClassPathXmlApplicationContext(String fileName) {
this.readXml(fileName);
this.instanceBeans();
}
private void readXml(String fileName) {
SAXReader saxReader = new SAXReader();
try {
URL xmlPath = this.getClass().getClassLoader().getResource(fileName);
Document document = saxReader.read(xmlPath);
Element rootElement = document.getRootElement();
//对配置文件中的每一个<bean>,进行处理
for (Element element : (List<Element>) rootElement.elements()) {
//获取Bean的基本信息
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID,
beanClassName);
//将Bean的定义存放到beanDefinitions
beanDefinitions.add(beanDefinition);
}
}
}
//利用反射创建Bean实例,并存储在singletons中
private void instanceBeans() {
for (BeanDefinition beanDefinition : beanDefinitions) {
try {
singletons.put(beanDefinition.getId(),
Class.forName(beanDefinition.getClassName()).newInstance());
}
}
}
//这是对外的一个方法,让外部程序从容器中获取Bean实例,会逐步演化成核心方法
public Object getBean(String beanName) {
return singletons.get(beanName);
}
}由上面这一段代码可以看出,ClassPathXmlApplicationContext定义了唯一的构造函数,构造函数里会做两件事:一是提供一个readXml()方法,通过传入的文件路径,也就是XML文件的全路径名,来获取XML内的信息,二是提供一个instanceBeans()方法,根据读取到的信息实例化Bean。接下来让我们看看,readXml和instanceBeans这两个方法分别做了什么。
首先来看readXML,这也是我们解析Bean的核心方法,因为配置在XML内的Bean信息都是文本信息,需要解析之后变成内存结构才能注入到容器中。该方法最开始创建了SAXReader对象,这个对象是dom4j包内提供的。随后,它通过传入的fileName,也就是定义的XML名字,获取根元素,也就是XML里最外层的标签。然后它循环遍历标签中的属性,通过 element.attributeValue("id") 和 element.attributeValue("class") 拿到配置信息,接着用这些配置信息构建BeanDefinition对象,然后把BeanDefinition对象加入到BeanDefinitions列表中,这个地方就保存了所有Bean的定义。
接下来,我们看看instanceBeans方法实现的功能:实例化一个Bean。因为BeanDefinitions存储的BeanDefinition的class只是一个类的全名,所以我们现在需要将这个名字转换成一个具体的类。我们可以通过Java里的反射机制,也就是Class.forName将一个类的名字转化成一个实际存在的类,转成这个类之后,我们把它放到singletons这个Map里,构建 ID 与实际类的映射关系。
到这里,我们就把XML文件中的Bean信息注入到了容器中。你可能会问,我到现在都没看到BeanFactory呀,是不是还没实现完?
其实不是的,目前的ClassPathXmlApplicationContext兼具了BeanFactory的功能,它通过singletons和beanDefinitions初步实现了Bean的管理,其实这也是Spring本身的做法。后面我会进一步扩展的时候,会分离这两部分功能,来剥离出一个独立的BeanFactory。
验证功能
现在,我们已经实现了第一个管理Bean的容器,但还要验证一下我们的功能是不是真的实现了。下面我们就编写一下测试代码。在com.minis目录下,新增test包。你可以看一下相关的测试代码。
java
public interface AService {
void sayHello();
}这里,我们定义了一个sayHello接口,该接口的实现是在控制台打印出"a service 1 say hello"这句话。
java
public class AServiceImpl implements AService {
public void sayHello() {
System.out.println("a service 1 say hello");
}
}我们将XML文件命名为beans.xml,注入AServiceImpl类,起个别名,为aservice。
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id = "aservice" class = "com.minis.test.AServiceImpl"></bean>
</beans>除了测试代码,我们还需要启动类,定义main函数。
java
public class Test1 {
public static void main(String[] args) {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("beans.xml");
AService aService = (AService) ctx.getBean("aservice");
aService.sayHello();
}
}在启动函数中可以看到,我们构建了ClassPathXmlApplicationContext,传入文件名为"beans.xml",也就是我们在测试代码中定义的XML文件名。随后我们通过getBean方法,获取注入到singletons里的这个类AService。aService在这儿是AService接口类型,其底层实现是AServiceImpl,这样再调用AServiceImpl类中的sayHello方法,就可以在控制台打印出"a service 1 say hello"这一句话。
到这里,我们已经成功地构造了一个最简单的程序: 最原始的IoC容器。在这个过程中我们引入了BeanDefinition的概念,也实现了一个应用的上下文ClassPathXmlApplicationContext,从外部的XML文件中获取文件信息。只用了很少的步骤就实现了IoC容器对Bean的管理,后续就不再需要我们手动地初始化这些Java对象了。
解耦ClassPathXmlApplicationContext
但是我们也可以看到,这时的 ClassPathXmlApplicationContext 承担了太多的功能,这并不符合我们常说的对象单一功能的原则。因此,我们需要做的优化扩展工作也就呼之欲出了:分解这个类,主要工作就是两个部分,一是提出一个最基础的核心容器,二是把XML这些外部配置信息的访问单独剥离出去,现在我们只有XML这一种方式,但是之后还有可能配置到Web或数据库文件里,拆解出去之后也便于扩展。
为了看起来更像Spring,我们以Spring的目录结构为范本,重新构造一下我们的项目代码结构。
java
com.minis.beans;
com.minis.context;
com.minis.core;
com.minis.test;定义BeansException
在正式开始解耦工作之前,我们先定义属于我们自己的异常处理类:BeansException。我们来看看异常处理类该如何定义。
java
public class BeansException extends Exception {
public BeansException(String msg) {
super(msg);
}
}可以看到,现在的异常处理类比较简单,它是直接调用父类(Exception)处理并抛出异常。有了这个基础的BeansException之后,后续我们可以根据实际情况对这个类进行拓展。
定义 BeanFactory
首先要拆出一个基础的容器来,刚才我们反复提到了 BeanFactory 这个词,现在我们正式引入BeanFactory这个接口,先让这个接口拥有两个特性:一是获取一个Bean(getBean),二是注册一个BeanDefinition(registerBeanDefinition)。你可以看一下它们的定义。
java
public interface BeanFactory {
Object getBean(String beanName) throws BeansException;
void registerBeanDefinition(BeanDefinition beanDefinition);
}定义Resource
刚刚我们将BeanFactory的概念进行了抽象定义。接下来我们要定义Resource这个概念,我们把外部的配置信息都当成Resource(资源)来进行抽象,你可以看下相关接口。
java
public interface Resource extends Iterator<Object> {
}定义ClassPathXmlResource
目前我们的数据来源比较单一,读取的都是XML文件配置,但是有了Resource这个接口后面我们就可以扩展,从数据库还有Web网络上面拿信息。现在有BeanFactory了,有Resource接口了,拆解这两部分的接口也都有了。接下来就可以来实现了。
现在我们读取并解析XML文件配置是在ClassPathXmlApplicationContext类中完成的,所以我们下一步的解耦工作就是定义ClassPathXmlResource,将解析XML的工作交给它完成。
java
public class ClassPathXmlResource implements Resource {
Document document;
Element rootElement;
Iterator<Element> elementIterator;
public ClassPathXmlResource(String fileName) {
SAXReader saxReader = new SAXReader();
URL xmlPath = this.getClass().getClassLoader().getResource(fileName);
//将配置文件装载进来,生成一个迭代器,可以用于遍历
try {
this.document = saxReader.read(xmlPath);
this.rootElement = document.getRootElement();
this.elementIterator = this.rootElement.elementIterator();
}
}
public boolean hasNext() {
return this.elementIterator.hasNext();
}
public Object next() {
return this.elementIterator.next();
}
}操作XML文件格式都是dom4j帮我们做的。
注:dom4j这个外部jar包方便我们读取并解析XML文件内容,将XML的标签以及参数转换成Java的对象。当然我们也可以自行写代码来解析文件,但是为了简化代码,避免重复造轮子,这里我们选择直接引用第三方包。
XmlBeanDefinitionReader
现在我们已经解析好了XML文件,但解析好的XML如何转换成我们需要的BeanDefinition呢?这时XmlBeanDefinitionReader就派上用场了。
java
public class XmlBeanDefinitionReader {
BeanFactory beanFactory;
public XmlBeanDefinitionReader(BeanFactory beanFactory) {
this.beanFactory = beanFactory;
}
public void loadBeanDefinitions(Resource resource) {
while (resource.hasNext()) {
Element element = (Element) resource.next();
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID, beanClassName);
this.beanFactory.registerBeanDefinition(beanDefinition);
}
}
}可以看到,在XmlBeanDefinitionReader中,有一个loadBeanDefinitions方法会把解析的XML内容转换成BeanDefinition,并加载到BeanFactory中。
BeanFactory功能扩展
首先,定义一个简单的BeanFactory实现类SimpleBeanFactory。
java
public class SimpleBeanFactory implements BeanFactory {
private List<BeanDefinition> beanDefinitions = new ArrayList<>();
private List<String> beanNames = new ArrayList<>();
private Map<String, Object> singletons = new HashMap<>();
public SimpleBeanFactory() {
}
//getBean,容器的核心方法
public Object getBean(String beanName) throws BeansException {
//先尝试直接拿Bean实例
Object singleton = singletons.get(beanName);
//如果此时还没有这个Bean的实例,则获取它的定义来创建实例
if (singleton == null) {
int i = beanNames.indexOf(beanName);
if (i == -1) {
throw new BeansException();
} else {
//获取Bean的定义
BeanDefinition beanDefinition = beanDefinitions.get(i);
try {
singleton = Class.forName(beanDefinition.getClassName()).newInstance();
}
//注册Bean实例
singletons.put(beanDefinition.getId(), singleton);
}
}
return singleton;
}
public void registerBeanDefinition(BeanDefinition beanDefinition) {
this.beanDefinitions.add(beanDefinition);
this.beanNames.add(beanDefinition.getId());
}
}由SimpleBeanFactory的实现不难看出,这就是把ClassPathXmlApplicationContext中有关BeanDefinition实例化以及加载到内存中的相关内容提取出来了。提取完之后ClassPathXmlApplicationContext就是一个"空壳子"了,一部分交给了BeanFactory,一部分又交给了Resource和Reader。这时候它又该如何发挥"集成者"的功能呢?我们看看它现在是什么样子的。
java
public class ClassPathXmlApplicationContext implements BeanFactory {
BeanFactory beanFactory;
//context负责整合容器的启动过程,读外部配置,解析Bean定义,创建BeanFactory
public ClassPathXmlApplicationContext(String fileName) {
Resource resource = new ClassPathXmlResource(fileName);
BeanFactory beanFactory = new SimpleBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions(resource);
this.beanFactory = beanFactory;
}
//context再对外提供一个getBean,底下就是调用的BeanFactory对应的方法
public Object getBean(String beanName) throws BeansException {
return this.beanFactory.getBean(beanName);
}
public void registerBeanDefinition(BeanDefinition beanDefinition) {
this.beanFactory.registerBeanDefinition(beanDefinition);
}
}可以看到,当前的ClassPathXmlApplicationContext在实例化的过程中做了三件事。
- 解析XML文件中的内容。
- 加载解析的内容,构建BeanDefinition。
- 读取BeanDefinition的配置信息,实例化Bean,然后把它注入到BeanFactory容器中。
通过上面几个步骤,我们把XML中的配置转换成Bean对象,并把它交由BeanFactory容器去管理,这些功能都实现了。虽然功能与原始版本相比没有发生任何变化,但这种 一个类只做一件事的思想 是值得我们在编写代码的过程中借鉴的。
小结
好了,这节课就讲到这里。通过简简单单几个类,我们就初步构建起了MiniSpring的核心部分:Bean和IoC。
可以看到,通过这节课的构建,我们在业务程序中不需要再手动new一个业务类,只要把它交由框架容器去管理就可以获取我们所需的对象。另外还支持了Resource和BeanFactory,用Resource定义Bean的数据来源,让BeanFactory负责Bean的容器化管理。通过功能解耦,容器的结构会更加清晰明了,我们阅读起来也更加方便。当然最重要的是,这可以方便我们今后对容器进行扩展,适配更多的场景。
以前看似高深的Spring核心概念之一的IoC,就这样被我们拆解成了最简单的概念。它虽然原始,但已经具备了基本的功能,是一颗可以生长发育的种子。我们后面把其他功能一步步添加上去,这个可用的小种子就能发育成一棵大树。
完整源代码参见 https://github.com/YaleGuo/minis
课后题
学完这节课,我也给你留一道思考题。IoC的字面含义是"控制反转",那么它究竟"反转"了什么?又是怎么体现在代码中的?
02|扩展Bean:如何配置constructor、property和init-method?
上节课,我们初步实现了一个MiniSpring框架,它很原始也很简单。我们实现了一个BeanFactory,作为一个容器对Bean进行管理,我们还定义了数据源接口Resource,可以将多种数据源注入Bean。
这节课,我们继续增强IoC容器,我们要做的主要有3点。
- 增加单例Bean的接口定义,然后把所有的Bean默认为单例模式。
- 预留事件监听的接口,方便后续进一步解耦代码逻辑。
- 扩展BeanDefinition,添加一些属性,现在它只有id和class两个属性,我们要进一步地丰富它。
构建单例的Bean
首先我们来看看如何构建单例的Bean,并对该Bean进行管理。
单例(Singleton)是指某个类在整个系统内只有唯一的对象实例。只要能达到这个目的,采用什么技术手段都是可以的。常用的实现单例的方式有不下五种,因为我们构建单例的目的是深入理解Spring框架,所以我们会按照Spring的实现方式来做。
为了和Spring框架内的方法名保持一致,我们把BeanFactory接口中定义的registryBeanDefinition方法修改为registryBean,参数修改为beanName与obj。其中,obj为Object类,指代与beanName对应的Bean的信息。你可以看下修改后的BeanFactory。
java
public interface BeanFactory {
Object getBean(String beanName) throws BeansException;
Boolean containsBean(String name);
void registerBean(String beanName, Object obj);
}既然要管理单例Bean,接下来我们就定义一下SingletonBeanRegistry,将管理单例Bean的方法规范好。
java
public interface SingletonBeanRegistry {
void registerSingleton(String beanName, Object singletonObject);
Object getSingleton(String beanName);
boolean containsSingleton(String beanName);
String[] getSingletonNames();
}你看这个类的名称上带有Registry字样,所以让人一眼就能知道这里面存储的就是Bean。从代码可以看到里面的方法 名称简单直接,分别对应单例的注册、获取、判断是否存在,以及获取所有的单例Bean等操作。
接口已经定义好了,接下来我们定义一个默认的实现类。这也是从Spring里学的方法,它作为一个框架并不会把代码写死,所以这里面的很多实现类都是默认的,默认是什么意思呢?就是我们可以去替换,不用这些默认的类也是可以的。我们就按照同样的方法,来为我们的默认实现类取个名字DefaultSingletonBeanRegistry。
java
public class DefaultSingletonBeanRegistry implements SingletonBeanRegistry {
//容器中存放所有bean的名称的列表
protected List<String> beanNames = new ArrayList<>();
//容器中存放所有bean实例的map
protected Map<String, Object> singletons = new ConcurrentHashMap<>(256);
public void registerSingleton(String beanName, Object singletonObject) {
synchronized (this.singletons) {
this.singletons.put(beanName, singletonObject);
this.beanNames.add(beanName);
}
}
public Object getSingleton(String beanName) {
return this.singletons.get(beanName);
}
public boolean containsSingleton(String beanName) {
return this.singletons.containsKey(beanName);
}
public String[] getSingletonNames() {
return (String[]) this.beanNames.toArray();
}
protected void removeSingleton(String beanName) {
synchronized (this.singletons) {
this.beanNames.remove(beanName);
this.singletons.remove(beanName);
}
}
}我们在默认的这个类中,定义了beanNames列表和singletons的映射关系,beanNames用于存储所有单例Bean的别名,singletons则存储Bean名称和实现类的映射关系。
这段代码中要留意的是,我们将 singletons 定义为了一个ConcurrentHashMap,而且在实现 registrySingleton 时前面加了一个关键字synchronized。这一切都是为了确保在多线程并发的情况下,我们仍然能安全地实现对单例Bean的管理,无论是单线程还是多线程,我们整个系统里面这个Bean总是唯一的、单例的。
还记得我们有SimpleBeanFactory这样一个简单的BeanFactory实现类吗?接下来我们修改这个类,让它继承上一步创建的DefaultSingletonBeanRegistry,确保我们通过SimpleBeanFactory创建的Bean默认就是单例的,这也和Spring本身的处理方式一致。
java
public class SimpleBeanFactory extends DefaultSingletonBeanRegistry implements BeanFactory {
private Map<String, BeanDefinition> beanDefinitions = new ConcurrentHashMap<>(256);
public SimpleBeanFactory() {
}
//getBean,容器的核心方法
public Object getBean(String beanName) throws BeansException {
//先尝试直接拿bean实例
Object singleton = this.getSingleton(beanName);
//如果此时还没有这个bean的实例,则获取它的定义来创建实例
if (singleton == null) {
//获取bean的定义
BeanDefinition beanDefinition = beanDefinitions.get(beanName);
if (beanDefinition == null) {
throw new BeansException("No bean.");
}
try {
singleton = Class.forName(beanDefinition.getClassName()).newInstance();
}
//新注册这个bean实例
this.registerSingleton(beanName, singleton);
}
return singleton;
}
public void registerBeanDefinition(BeanDefinition beanDefinition) {
this.beanDefinitions.put(beanDefinition.getId(), beanDefinition);
}
public Boolean containsBean(String name) {
return containsSingleton(name);
}
public void registerBean(String beanName, Object obj) {
this.registerSingleton(beanName, obj);
}
}我们对 SimpleBeanFactory 的主要改动是增加了对containsBean和registerBean的实现。通过代码可以看出,这两处实现都是对单例Bean的操作。
这部分还有两个类需要调整:ClassPathXmlApplicationContext和XmlBeanDefinitionReader。其中ClassPathXmlApplicationContext里增加了对containsBean和registerBean的实现。
java
public Boolean containsBean(String name) {
return this.beanFactory.containsBean(name);
}
public void registerBean(String beanName, Object obj) {
this.beanFactory.registerBean(beanName, obj);
}XmlBeanDefinitionReader调整后如下:
java
public class XmlBeanDefinitionReader {
SimpleBeanFactory simpleBeanFactory;
public XmlBeanDefinitionReader(SimpleBeanFactory simpleBeanFactory) {
this.simpleBeanFactory = simpleBeanFactory;
}
public void loadBeanDefinitions(Resource resource) {
while (resource.hasNext()) {
Element element = (Element) resource.next();
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID, beanClassName);
this.simpleBeanFactory.registerBeanDefinition(beanDefinition);
}
}
}增加事件监听
构建好单例Bean之后,为了监控容器的启动状态,我们要增加事件监听。
我们先定义一下ApplicationEvent和ApplicationEventPublisher。通过名字可以看出,一个是用于监听应用的事件,另一个则是发布事件。
- ApplicationEventPublisher的实现
java
public interface ApplicationEventPublisher {
void publishEvent(ApplicationEvent event);
}- ApplicationEvent的实现
java
public class ApplicationEvent extends EventObject {
private static final long serialVersionUID = 1L;
public ApplicationEvent(Object arg0) {
super(arg0);
}
}可以看出,ApplicationEvent继承了Java工具包内的EventObject,我们是在Java的事件监听的基础上进行了简单的封装。虽然目前还没有任何实现,但这为我们后续使用观察者模式解耦代码提供了入口。
到此为止,我们进一步增强了IoC容器,还引入了两个新概念: 单例Bean和事件监听。 其中,事件监听这部分目前只预留了入口,方便我们后续扩展。而单例Bean则是Spring框架默认的实现,我们提供了相关实现方法,并考虑到多线程高并发的场景,引入了ConcurrentHashMap来存储Bean信息。
到这一步,我们容器就变成了管理单例Bean的容器了。下面我们做一点准备工作,为后面对这些Bean注入属性值做铺垫。
注入
Spring中有三种属性注入的方式,分别是 Field注入、Setter注入和构造器(Constructor)注入。 Field注入是指我们给Bean里面某个变量赋值。Setter注入是提供了一个setter方法,调用setXXX()来注入值。constructor就是在构造器/构造函数里传入参数来进行注入。Field注入我们后面会实现,这节课我们先探讨Setter注入和构造器注入两种方式。
配置Setter注入
首先我们来看下配置,在XML文件中我们是怎么声明使用Setter注入方式的。
xml
<beans>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<property type="String" name="property1" value="Hello World!"/>
</bean>
</beans>由上面的示例可以看出,我们在 <bean> 标签下引入了 <property> 标签,它又包含了type、name和value,分别对应属性类型、属性名称以及赋值。你可以看一下这个Bean的代码。
java
public class AServiceImpl {
private String property1;
public void setProperty1(String property1) {
this.property1 = property1;
}
}配置构造器注入
接下来我们再看看怎么声明构造器注入,同样是在XML里配置。
xml
<beans>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<constructor-arg type="String" name="name" value="abc"/>
<constructor-arg type="int" name="level" value="3"/>
</bean>
</beans>可以看到,与Setter注入类似,我们只是把 <property> 标签换成了 <constructor-args> 标签。
java
public class AServiceImpl {
private String name;
private int level;
public AServiceImpl(String name, int level) {
this.name = name;
this.level = level;
}
}由上述两种方式可以看出, 注入操作的本质,就是给Bean的各个属性进行赋值。 具体方式取决于实际情况,哪一种更便捷就可以选择哪一种。如果采用构造器注入的方式满足不了对域的赋值,也可以将构造器注入和Setter注入搭配使用。
xml
<beans>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<constructor-arg type="String" name="name" value="abc"/>
<constructor-arg type="int" name="level" value="3"/>
<property type="String" name="property1" value="Someone says"/>
<property type="String" name="property2" value="Hello World!"/>
</bean>
</beans>现在我们已经明确了 <property> 和 <constructor-args> 标签的定义,但是只有外部的XML文件配置定义肯定是不行的,还要去实现。这就是我们接下来需要完成的工作。
实现属性类
与这个定义相关,我们要配置对应的属性类,分别命名为ArgumentValue和PropertyValue。
java
public class ArgumentValue {
private Object value;
private String type;
private String name;
public ArgumentValue(Object value, String type) {
this.value = value;
this.type = type;
}
public ArgumentValue(Object value, String type, String name) {
this.value = value;
this.type = type;
this.name = name;
}
//省略getter和setter
}
java
public class PropertyValue {
private final String name;
private final Object value;
public PropertyValue(String name, Object value) {
this.name = name;
this.value = value;
}
//省略getter
}我们看Value这个词,后面不带"s"就表示他只是针对的某一个属性或者某一个参数,但一个Bean里面有很多属性、很多参数,所以我们就需要一个带"s"的集合类。 在Spring中也是这样的,所以我们参考Spring的方法,提供了ArgumentValues和PropertyValues两个类,封装、 增加、获取、判断等操作方法,简化调用。既给外面提供单个的参数/属性的对象,也提供集合对象。
- ArgumentValues类
java
public class ArgumentValues {
private final Map<Integer, ArgumentValue> indexedArgumentValues = new HashMap<>(0);
private final List<ArgumentValue> genericArgumentValues = new LinkedList<>();
public ArgumentValues() {
}
private void addArgumentValue(Integer key, ArgumentValue newValue) {
this.indexedArgumentValues.put(key, newValue);
}
public boolean hasIndexedArgumentValue(int index) {
return this.indexedArgumentValues.containsKey(index);
}
public ArgumentValue getIndexedArgumentValue(int index) {
return this.indexedArgumentValues.get(index);
}
public void addGenericArgumentValue(Object value, String type) {
this.genericArgumentValues.add(new ArgumentValue(value, type));
}
private void addGenericArgumentValue(ArgumentValue newValue) {
if (newValue.getName() != null) {
for (Iterator<ArgumentValue> it = this.genericArgumentValues.iterator(); it.hasNext(); ) {
ArgumentValue currentValue = it.next();
if (newValue.getName().equals(currentValue.getName())) {
it.remove();
}
}
}
this.genericArgumentValues.add(newValue);
}
public ArgumentValue getGenericArgumentValue(String requiredName) {
for (ArgumentValue valueHolder : this.genericArgumentValues) {
if (valueHolder.getName() != null
&& (requiredName == null || !valueHolder.getName().equals(requiredName))) {
continue;
}
return valueHolder;
}
return null;
}
public int getArgumentCount() {
return this.genericArgumentValues.size();
}
public boolean isEmpty() {
return this.genericArgumentValues.isEmpty();
}
}- PropertyValues类
java
public class PropertyValues {
private final List<PropertyValue> propertyValueList;
public PropertyValues() {
this.propertyValueList = new ArrayList<>(0);
}
public List<PropertyValue> getPropertyValueList() {
return this.propertyValueList;
}
public int size() {
return this.propertyValueList.size();
}
public void addPropertyValue(PropertyValue pv) {
this.propertyValueList.add(pv);
}
public void addPropertyValue(String propertyName, Object propertyValue) {
addPropertyValue(new PropertyValue(propertyName, propertyValue));
}
public void removePropertyValue(PropertyValue pv) {
this.propertyValueList.remove(pv);
}
public void removePropertyValue(String propertyName) {
this.propertyValueList.remove(getPropertyValue(propertyName));
}
public PropertyValue[] getPropertyValues() {
return this.propertyValueList.toArray(new PropertyValue[this.propertyValueList.size()]);
}
public PropertyValue getPropertyValue(String propertyName) {
for (PropertyValue pv : this.propertyValueList) {
if (pv.getName().equals(propertyName)) {
return pv;
}
}
return null;
}
public Object get(String propertyName) {
PropertyValue pv = getPropertyValue(propertyName);
return pv != null ? pv.getValue() : null;
}
public boolean contains(String propertyName) {
return getPropertyValue(propertyName) != null;
}
public boolean isEmpty() {
return this.propertyValueList.isEmpty();
}
}上面这些代码整体还是比较简单的,根据各个封装方法的名称,也基本能明确它们的用途,这里就不再赘述了。对于构造器注入和Setter注入两种方式,这里我们只是初步定义相关类,做一点准备,后面我们将实现具体解析以及注入的过程。
接下来,我们还要做两件事。
- 扩展BeanDefinition的属性,在原有id与name两个属性的基础上,新增lazyInit、dependsOn、initMethodName等属性。
- 继续扩展BeanFactory接口,增强对Bean的处理能力。
扩展BeanDefinition
我们先给BeanDefinition和BeanFactory增加新的接口,新增接口基本上是适配BeanDefinition新增属性的。
我们给BeanDefinition类添加了哪些属性呢?一起来看下。
java
public class BeanDefinition {
String SCOPE_SINGLETON = "singleton";
String SCOPE_PROTOTYPE = "prototype";
private boolean lazyInit = false;
private String[] dependsOn;
private ArgumentValues constructorArgumentValues;
private PropertyValues propertyValues;
private String initMethodName;
private volatile Object beanClass;
private String id;
private String className;
private String scope = SCOPE_SINGLETON;
public BeanDefinition(String id, String className) {
this.id = id;
this.className = className;
}
//省略getter和setter
}从上面代码可以看出,之前我们只有id和className属性,现在增加了scope属性,表示bean是单例模式还是原型模式,还增加了lazyInit属性,表示Bean要不要在加载的时候初始化,以及初始化方法initMethodName的声明,当一个Bean构造好并实例化之后是否要让框架调用初始化方法。还有dependsOn属性记录Bean之间的依赖关系,最后还有构造器参数和property列表。
集中存放BeanDefinition
接下来,我们新增BeanDefinitionRegistry接口。它类似于一个存放BeanDefinition的仓库,可以存放、移除、获取及判断BeanDefinition对象。所以,我们初步定义四个接口对应这四个功能,分别是register、remove、get、contains。
java
public interface BeanDefinitionRegistry {
void registerBeanDefinition(String name, BeanDefinition bd);
void removeBeanDefinition(String name);
BeanDefinition getBeanDefinition(String name);
boolean containsBeanDefinition(String name);
}随后调整BeanFactory,新增Singleton、Prototype的判断,获取Bean的类型。
java
public interface BeanFactory {
Object getBean(String name) throws BeansException;
boolean containsBean(String name);
boolean isSingleton(String name);
boolean isPrototype(String name);
Class<?> getType(String name);
}通过代码可以看到,我们让SimpleBeanFactory实现了BeanDefinitionRegistry,这样SimpleBeanFactory既是一个工厂同时也是一个仓库,你可以看下调整后的部分代码。
java
public class SimpleBeanFactory extends DefaultSingletonBeanRegistry implements BeanFactory, BeanDefinitionRegistry {
private Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
private List<String> beanDefinitionNames = new ArrayList<>();
public void registerBeanDefinition(String name, BeanDefinition beanDefinition) {
this.beanDefinitionMap.put(name, beanDefinition);
this.beanDefinitionNames.add(name);
if (!beanDefinition.isLazyInit()) {
try {
getBean(name);
} catch (BeansException e) {
}
}
}
public void removeBeanDefinition(String name) {
this.beanDefinitionMap.remove(name);
this.beanDefinitionNames.remove(name);
this.removeSingleton(name);
}
public BeanDefinition getBeanDefinition(String name) {
return this.beanDefinitionMap.get(name);
}
public boolean containsBeanDefinition(String name) {
return this.beanDefinitionMap.containsKey(name);
}
public boolean isSingleton(String name) {
return this.beanDefinitionMap.get(name).isSingleton();
}
public boolean isPrototype(String name) {
return this.beanDefinitionMap.get(name).isPrototype();
}
public Class<?> getType(String name) {
return this.beanDefinitionMap.get(name).getClass();
}
}修改完BeanFactory这个核心之后,上层对应的 ClassPathXmlApplicationContext部分作为外部集成包装也需要修改。
java
public class ClassPathXmlApplicationContext implements BeanFactory, ApplicationEventPublisher {
public void publishEvent(ApplicationEvent event) {
}
public boolean isSingleton(String name) {
return false;
}
public boolean isPrototype(String name) {
return false;
}
public Class<?> getType(String name) {
return null;
}
}小结
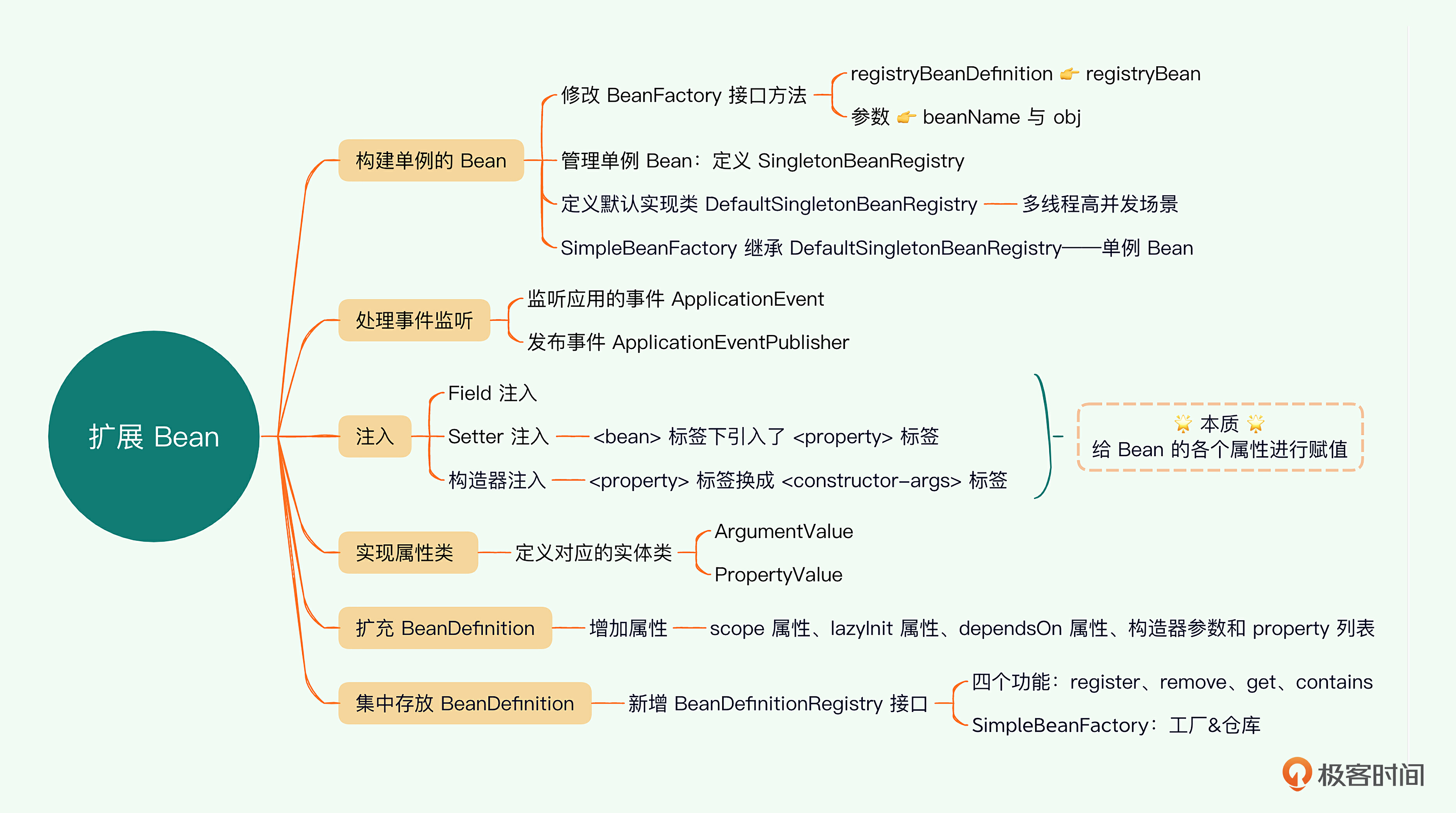
这节课,我们模仿Spring构造了单例Bean,还增加了容器事件监听处理,完善了BeanDefinition的属性。此外,参照Spring的实现,我们增加了一些有用的特性,例如lazyInit,initMethodName等等,BeanFactory也做了相应的修改。同时,我们还提前为构造器注入、Setter注入提供了基本的实例类,这为后面实现上述两种依赖注入方式提供了基础。
通过对上一节课原始IoC容器的扩展和丰富,它已经越来越像Spring框架了。
完整源代码参见 https://github.com/YaleGuo/minis
课后题
学完这节课,我也给你留一道思考题。你认为构造器注入和Setter注入有什么异同?它们各自的优缺点是什么?
03|依赖注入:如何给Bean注入值并解决循环依赖问题?
上节课,我们定义了在XML配置文件中使用setter注入和构造器注入的配置方式,但同时也留下了一个悬念:这些配置是如何生效的呢?
值的注入
要理清这个问题,我们要先来看看 Spring是如何解析 <property> 和 <constructor-arg> 标签。
我们以下面的XML配置为基准进行学习。
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<constructor-arg type="String" name="name" value="abc"/>
<constructor-arg type="int" name="level" value="3"/>
<property type="String" name="property1" value="Someone says"/>
<property type="String" name="property2" value="Hello World!"/>
</bean>
</beans>和上面的配置属性对应,在测试类AServiceImpl中,要有相应的name、level、property1、property2字段来建立映射关系,这些实现体现在构造函数以及settter、getter等方法中。
java
public class AServiceImpl implements AService {
private String name;
private int level;
private String property1;
private String property2;
public AServiceImpl() {
}
public AServiceImpl(String name, int level) {
this.name = name;
this.level = level;
System.out.println(this.name + "," + this.level);
}
public void sayHello() {
System.out.println(this.property1 + "," + this.property2);
}
// 在此省略property1和property2的setter、getter方法
}接着,简化ArgumentValues类,移除暂时未用到的方法。
java
public class ArgumentValues {
private final List<ArgumentValue> argumentValueList = new ArrayList<>();
public ArgumentValues() {
}
public void addArgumentValue(ArgumentValue argumentValue) {
this.argumentValueList.add(argumentValue);
}
public ArgumentValue getIndexedArgumentValue(int index) {
ArgumentValue argumentValue = this.argumentValueList.get(index);
return argumentValue;
}
public int getArgumentCount() {
return (this.argumentValueList.size());
}
public boolean isEmpty() {
return (this.argumentValueList.isEmpty());
}
}做完准备工作之后,我们重点来看核心工作:解析 <property> 和 <constructor-arg> 两个标签。我们要在XmlBeanDefinitionReader类中处理这两个标签。
java
public void loadBeanDefinitions(Resource resource) {
while (resource.hasNext()) {
Element element = (Element) resource.next();
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID, beanClassName);
//处理属性
List<Element> propertyElements = element.elements("property");
PropertyValues PVS = new PropertyValues();
for (Element e : propertyElements) {
String pType = e.attributeValue("type");
String pName = e.attributeValue("name");
String pValue = e.attributeValue("value");
PVS.addPropertyValue(new PropertyValue(pType, pName, pValue));
}
beanDefinition.setPropertyValues(PVS);
//处理构造器参数
List<Element> constructorElements = element.elements("constructor- arg"); ArgumentValues AVS = new ArgumentValues();
for (Element e : constructorElements) {
String aType = e.attributeValue("type");
String aName = e.attributeValue("name");
String aValue = e.attributeValue("value");
AVS.addArgumentValue(new ArgumentValue(aType, aName, aValue));
}
beanDefinition.setConstructorArgumentValues(AVS);
this.simpleBeanFactory.registerBeanDefinition(beanID, beanDefinition);
}
}
}从上述代码可以看出,程序在加载Bean的定义时要获取 <property> 和 <constructor-arg>,只要循环处理它们对应标签的属性:type、name、value即可。随后,我们通过addPropertyValue和addArgumentValue两个方法就能将注入的配置读取进内存。
那么,将这些配置的值读取进内存之后,我们怎么把它作为Bean的属性注入进去呢?这要求我们在创建Bean的时候就要做相应的处理,给属性赋值。针对XML配置的Value值,我们要按照数据类型分别将它们解析为字符串、整型、浮点型等基本类型。在SimpleBeanFactory类中,调整核心的createBean方法,我们修改一下。
java
private Object createBean(BeanDefinition beanDefinition) {
Class<?> clz = null;
Object obj = null;
Constructor<?> con = null;
try {
clz = Class.forName(beanDefinition.getClassName());
// 处理构造器参数
ArgumentValues argumentValues = beanDefinition.getConstructorArgumentValues();
//如果有参数
if (!argumentValues.isEmpty()) {
Class<?>[] paramTypes = new Class<?>
[argumentValues.getArgumentCount()];
Object[] paramValues = new Object[argumentValues.getArgumentCount()];
//对每一个参数,分数据类型分别处理
for (int i = 0; i < argumentValues.getArgumentCount(); i++) {
ArgumentValue argumentValue = argumentValues.getIndexedArgumentValue(i);
if ("String".equals(argumentValue.getType()) || "java.lang.String".equals(argumentValue.getType())) {
paramTypes[i] = String.class;
paramValues[i] = argumentValue.getValue();
} else if ("Integer".equals(argumentValue.getType()) || "java.lang.Integer".equals(argumentValue.getType())) {
paramTypes[i] = Integer.class;
paramValues[i] = Integer.valueOf((String) argumentValue.getValue());
} else if ("int".equals(argumentValue.getType())) {
paramTypes[i] = int.class;
paramValues[i] = Integer.valueOf((String) argumentValue.getValue());
} else { //默认为string
paramTypes[i] = String.class;
paramValues[i] = argumentValue.getValue();
}
}
try {
//按照特定构造器创建实例
con = clz.getConstructor(paramTypes);
obj = con.newInstance(paramValues);
}
} else { //如果没有参数,直接创建实例
obj = clz.newInstance();
}
} catch (Exception e) {
}
// 处理属性
PropertyValues propertyValues = beanDefinition.getPropertyValues();
if (!propertyValues.isEmpty()) {
for (int i = 0; i < propertyValues.size(); i++) {
//对每一个属性,分数据类型分别处理
PropertyValue propertyValue = propertyValues.getPropertyValueList().get(i);
String pType = propertyValue.getType();
String pName = propertyValue.getName();
Object pValue = propertyValue.getValue();
Class<?>[] paramTypes = new Class<?>[1];
if ("String".equals(pType) || "java.lang.String".equals(pType)) {
paramTypes[0] = String.class;
} else if ("Integer".equals(pType) || "java.lang.Integer".equals(pType)) {
paramTypes[0] = Integer.class;
} else if ("int".equals(pType)) {
paramTypes[0] = int.class;
} else { // 默认为string
paramTypes[0] = String.class;
}
Object[] paramValues = new Object[1];
paramValues[0] = pValue;
//按照setXxxx规范查找setter方法,调用setter方法设置属性
String methodName = "set" + pName.substring(0, 1).toUpperCase() + pName.substring(1);
Method method = null;
try {
method = clz.getMethod(methodName, paramTypes);
} try {
method.invoke(obj, paramValues);
}
}
}
return obj;
}我们这里的代码主要可以分成两个部分:一部分是处理constructor的里面的参数,另外一部分是处理各个property的属性。现在程序的代码是写在一起的,后面我们还会抽出单独的方法。
如何处理constructor?
首先,获取XML配置中的属性值,这个时候它们都是通用的Object类型,我们需要根据type字段的定义判断不同Value所属的类型,作为一个原始的实现这里我们只提供了String、Integer 和 int三种类型的判断。最终通过反射构造对象,将配置的属性值注入到了Bean对象中,实现构造器注入。
如何处理property?
和处理constructor相同,我们依然要通过type字段确定Value的归属类型。但不同之处在于,判断好归属类型后,我们还要手动构造setter方法,通过反射将属性值注入到setter方法之中。通过这种方式来实现对属性的赋值。
可以看出,其实代码的核心是通过Java的反射机制调用构造器及setter方法,在调用过程中根据具体的类型把属性值作为一个参数赋值进去。这也是所有的框架在实现IoC时的思路。 反射技术是IoC容器赖以工作的基础。
到这里,我们就完成了对XML配置的解析,实现了Spring中Bean的构造器注入与setter注入方式。回到我们开头的问题:配置文件中的属性设置是如何生效的?到这里我们就有答案了,就是 通过反射给Bean里面的属性赋值,就意味着配置文件生效了。
这里,我还想带你理清一个小的概念问题。在实现过程中,我们经常会用到依赖注入和IoC这两个术语,初学者很容易被这两个术语弄糊涂。其实,一开始只有IoC,也就是控制反转,但是这个术语让人很难快速理解,我们不知道反转了什么东西。但是通过之前的实现过程,我们就可以理解这个词了。
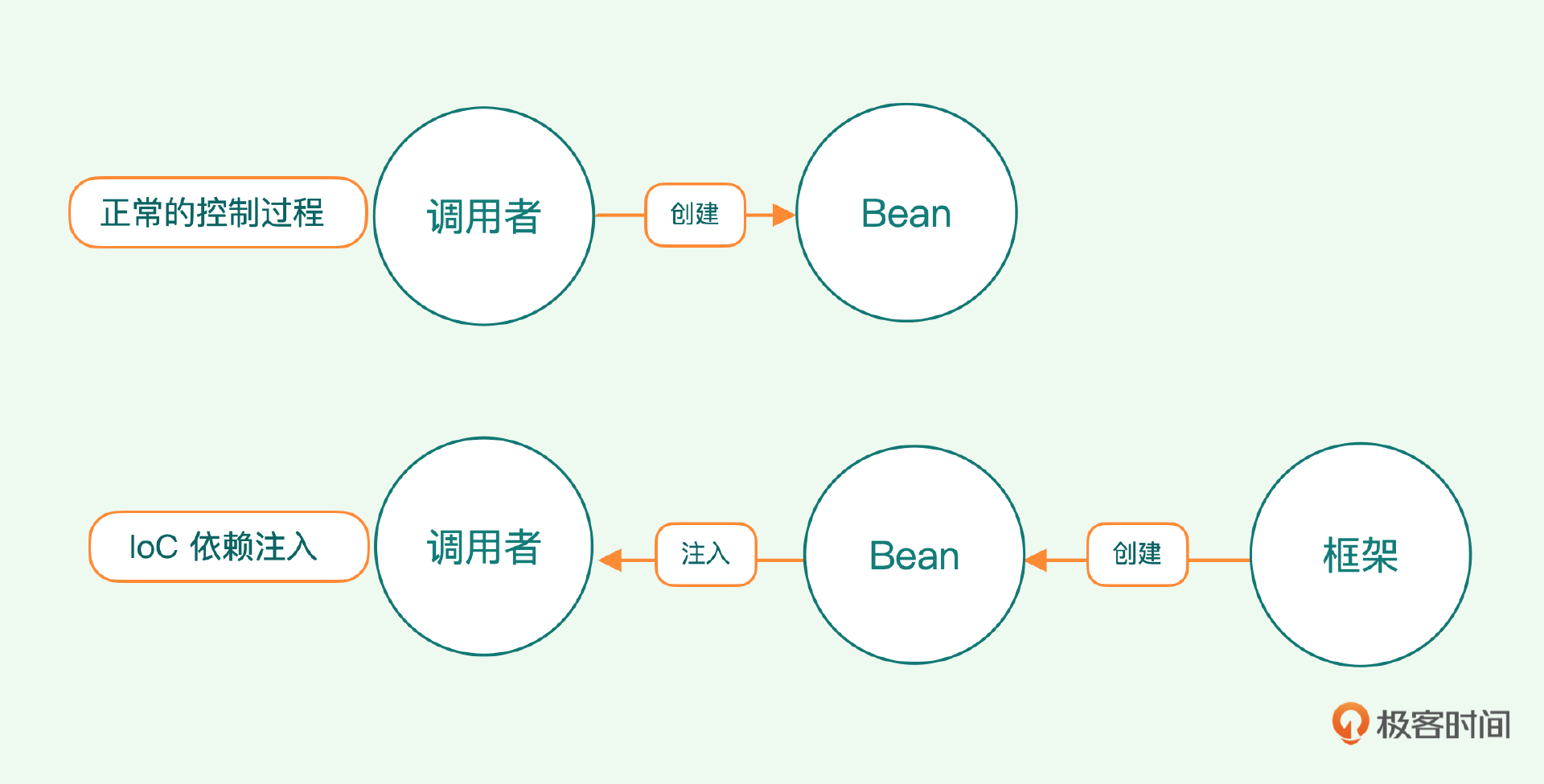
一个"正常"的控制过程是由调用者直接创建Bean,但是IoC的过程正好相反,是由框架来创建Bean,然后注入给调用者,这与"正常"的过程是反的,控制反转就是这个意思。但是总的来说,这个术语还是过于隐晦,引发了很长一段时间的争议,直到传奇程序员Martin Fowler一锤定音,将其更名为"依赖注入",一切才尘埃落定,"依赖注入"从此成为大家最常使用的术语。
Bean之间的依赖问题
现在我们进一步考虑一个问题。在注入属性值的时候,如果这个属性本身是一个对象怎么办呢?这就是Bean之间的依赖问题了。
这个场景在我们进行代码开发时还是非常常见的。比如,操作MySQL数据库的时候,经常需要引入Mapper类,而Mapper类本质上也是在IoC容器在启动时加载的一个Bean对象。
或许有人会说,我们就按照前面的配置方式,在type里配置需要配置Bean的绝对包路径,name里对应Bean的属性,不就好了吗?但这样还是会存在一个问题, 如何用Value这样一个简单的值表示某个对象中所有的域呢?
为此,Spring做了一个很巧妙的事情,它在标签里增加了 ref属性(引用),这个属性就记录了需要引用的另外一个Bean,这就方便多了。你可以参考下面的配置文件。
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id="basebaseservice" class="com.minis.test.BaseBaseService">
<property type="com.minis.test.AServiceImpl" name="as" ref="aservice" />
</bean>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<constructor-arg type="String" name="name" value="abc"/>
<constructor-arg type="int" name="level" value="3"/>
<property type="String" name="property1" value="Someone says"/>
<property type="String" name="property2" value="Hello World!"/>
<property type="com.minis.test.BaseService" name="ref1" ref="baseservice"/>
</bean>
<bean id="baseservice" class="com.minis.test.BaseService">
<property type="com.minis.test.BaseBaseService" name="bbs" ref="basebaseservice" />
</bean>
</beans>在上面的XML配置文件中,我们配置了一个Bean,ID命名为baseservice,随后在aservice bean的标签中设置ref="baseservice",也就是说我们希望此处注入的是一个Bean而不是一个简单的值。所以在对应的AServiceImpl里,也得有类型为BaseService的域ref1。
java
public class AServiceImpl implements AService {
private String name;
private int level;
private String property1;
private String property2;
private BaseService ref1;
public AServiceImpl() {
}
public AServiceImpl(String name, int level) {
this.name = name;
this.level = level;
System.out.println(this.name + "," + this.level);
}
public void sayHello() {
System.out.println(this.property1 + "," + this.property2);
}
// 在此省略property1和property2的setter、getter方法
}既然添加了ref属性,接下来我们很自然地会想到,要解析这个属性。下面我们就来解析一下ref,看看Spring是如何将配置的Bean注入到另外一个Bean中的。
我们为PropertyValue.java程序增加isRef字段,它可以判断属性是引用类型还是普通的值类型,我们看下修改后的代码。
java
public class PropertyValue {
private final String type;
private final String name;
private final Object value;
private final boolean isRef;
public PropertyValue(String type, String name, Object value, boolean isRef) {
this.type = type;
this.name = name;
this.value = value;
this.isRef = isRef;
}
}在这里我们调整了PropertyValue的构造函数,增加了isRef参数。
接下来我们看看如何解析ref属性,我们还是在XmlBeanDefinitionReader类中来处理。
java
public void loadBeanDefinitions(Resource resource) {
while (resource.hasNext()) {
Element element = (Element) resource.next();
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID, beanClassName);
// handle constructor
List<Element> constructorElements = element.elements("constructor- arg");
ArgumentValues AVS = new ArgumentValues();
for (Element e : constructorElements) {
String aType = e.attributeValue("type");
String aName = e.attributeValue("name");
String aValue = e.attributeValue("value");
AVS.addArgumentValue(new ArgumentValue(aType, aName, aValue));
}
beanDefinition.setConstructorArgumentValues(AVS);
// handle properties
List<Element> propertyElements = element.elements("property");
PropertyValues PVS = new PropertyValues();
List<String> refs = new ArrayList<>();
for (Element e : propertyElements) {
String pType = e.attributeValue("type");
String pName = e.attributeValue("name");
String pValue = e.attributeValue("value");
String pRef = e.attributeValue("ref");
String pV = "";
boolean isRef = false;
if (pValue != null && !pValue.equals("")) {
isRef = false;
pV = pValue;
} else if (pRef != null && !pRef.equals("")) {
isRef = true;
pV = pRef;
refs.add(pRef);
}
PVS.addPropertyValue(new PropertyValue(pType, pName, pV, isRef));
}
beanDefinition.setPropertyValues(PVS);
String[] refArray = refs.toArray(new String[0]);
beanDefinition.setDependsOn(refArray);
this.simpleBeanFactory.registerBeanDefinition(beanID, beanDefinition);
}
}由上述代码可以看出,程序解析 <property> 标签后,获取了ref的参数,同时有针对性地设置了isRef的值,把它添加到了PropertyValues内,最后程序调用setDependsOn方法,它记录了某一个Bean引用的其他Bean。这样,我们引用ref的配置就定义好了。
然后,我们改造一下以前的createBean()方法,抽取出一个单独处理属性的方法。
java
private Object createBean(BeanDefinition bd) {
... ...
handleProperties(bd, clz, obj);
return obj;
}
private void handleProperties(BeanDefinition bd, Class<?> clz, Object obj) {
// 处理属性
System.out.println("handle properties for bean : " + bd.getId());
PropertyValues propertyValues = bd.getPropertyValues();
//如果有属性
if (!propertyValues.isEmpty()) {
for (int i = 0; i < propertyValues.size(); i++) {
PropertyValue propertyValue = propertyValues.getPropertyValueList().get(i);
String pName = propertyValue.getName();
String pType = propertyValue.getType();
Object pValue = propertyValue.getValue();
boolean isRef = propertyValue.getIsRef();
Class<?>[] paramTypes = new Class<?>[1];
Object[] paramValues = new Object[1];
if (!isRef) { //如果不是ref,只是普通属性
//对每一个属性,分数据类型分别处理
if ("String".equals(pType) || "java.lang.String".equals(pType)) {
paramTypes[0] = String.class;
} else if ("Integer".equals(pType) || "java.lang.Integer".equals(pType)) {
paramTypes[0] = Integer.class;
} else if ("int".equals(pType)) {
paramTypes[0] = int.class;
} else {
paramTypes[0] = String.class;
}
paramValues[0] = pValue;
} else { //is ref, create the dependent beans
try {
paramTypes[0] = Class.forName(pType);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
try {
//再次调用getBean创建ref的bean实例
paramValues[0] = getBean((String) pValue);
}
}
//按照setXxxx规范查找setter方法,调用setter方法设置属性
String methodName = "set" + pName.substring(0, 1).toUpperCase() + pName.substring(1);
Method method = null;
try {
method = clz.getMethod(methodName, paramTypes);
} try {
method.invoke(obj, paramValues);
}
}
}
}这里的重点是处理ref的这几行代码。
java
//is ref, create the dependent beans
paramTypes[0] = Class.forName(pType);
paramValues[0] = getBean((String)pValue);这段代码实现的思路就是,对ref所指向的另一个Bean再次调用getBean()方法,这个方法会获取到另一个Bean实例,这样就实现了另一个Bean的注入。
这样一来,如果有多级引用,就会形成一个多级的getBean()调用链。由于在调用getBean()的时候会判断容器中是否包含了bean instance,没有的话会立即创建,所以XML配置文件中声明Bean的先后次序是任意的。
循环依赖问题
这又引出了另一个问题,在某个Bean需要注入另一个Bean的时候,如果那个Bean还不存在,该怎么办?
请你想象一个场景,Spring扫描到了ABean,在解析它并设置内部属性时,发现某个属性是另一个BBean,而此时Spring内部还不存在BBean的实例。这就要求Spring在创建ABean的过程中,能够再去创建一个BBean,继续推衍下去,BBean可能又会依赖第三个CBean。事情还可能进一步复杂化,如果CBean又反过来依赖ABean,就会形成循环依赖。
在逻辑上,我们好像陷入了一个死结,我们必须想办法打破这个循环。我们来看看Spring是如何解决这个问题的。
请你回顾一下创建Bean的过程。我们根据Bean的定义配置生成了BeanDefinition,然后根据定义加载Bean类,再进行实例化,最后在Bean中注入属性。
从这个过程中可以看出,在注入属性之前,其实这个Bean的实例已经生成出来了,只不过此时的实例还不是一个完整的实例,它还有很多属性没有值,可以说是一个早期的毛胚实例。而我们现在讨论的Bean之间的依赖是在属性注入这一阶段,因此我们可以在实例化与属性注入这两个阶段之间增加一个环节,确保给Bean注入属性的时候,Spring内部已经准备好了Bean的实例。
Spring的做法是在BeanFactory中引入一个结构: earlySingletonObjects,这里面存放的就是早期的毛胚实例。创建Bean实例的时候,不用等到所有步骤完成,而是可以在属性还没有注入之前,就把早期的毛胚实例先保存起来,供属性注入时使用。
这时再回到我们的复杂依赖场景,ABean依赖BBean,BBean又依赖CBean,而CBean反过来还要依赖ABean。现在,我们可以这样实现依赖注入。
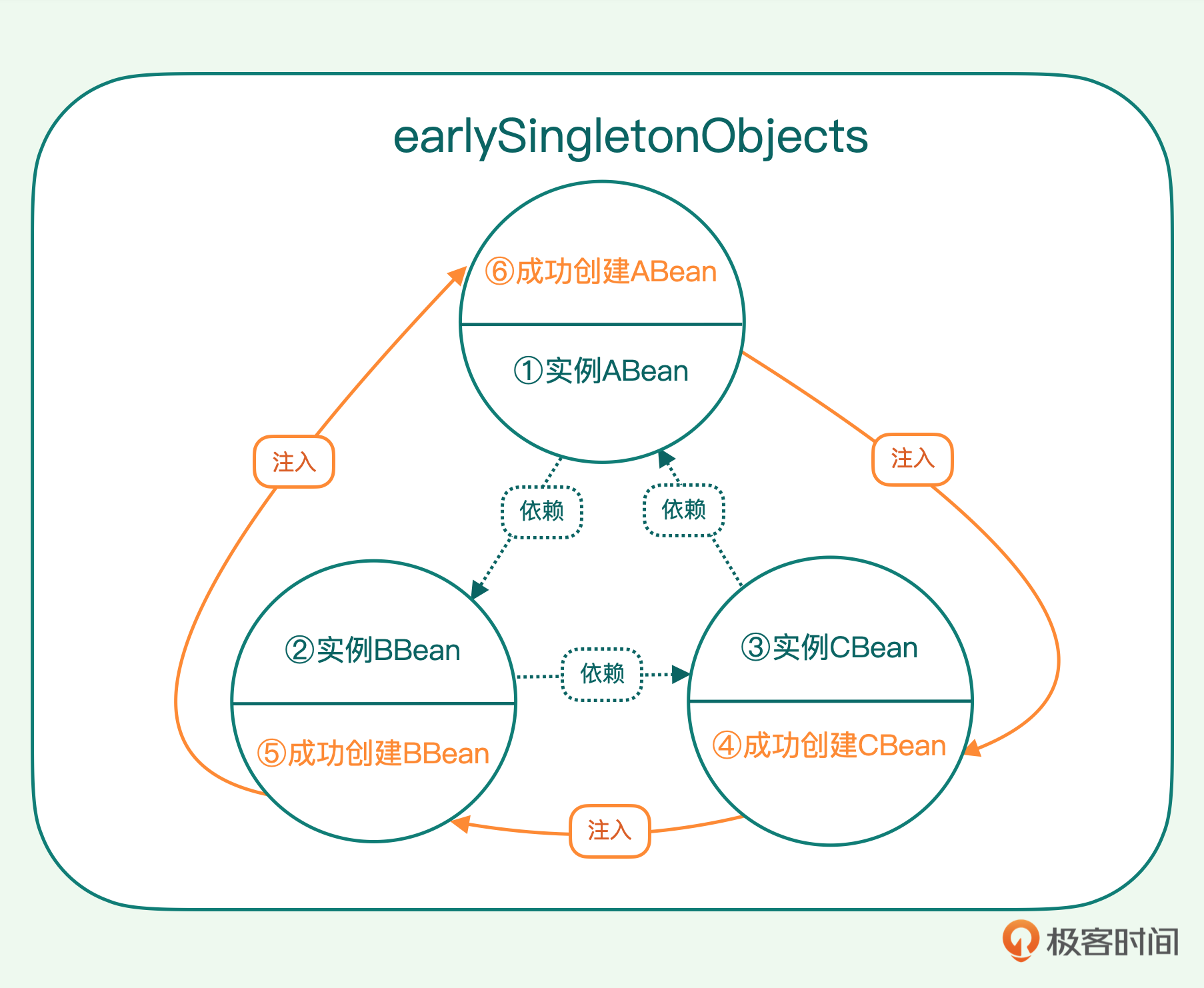
第一步,先实例化ABean,此时它是早期的不完整毛胚实例,好多属性还没被赋值,将实例放置到earlySingletonObjects中备用。然后给ABean注入属性,这个时候发现它还要依赖BBean。
第二步,实例化BBean,它也是早期的不完整毛胚实例,我们也将实例放到earlySingletonObjects中备用。然后再给BBean注入属性,又发现它依赖CBean。
第三步,实例化CBean,此时它仍然是早期的不完整的实例,同样将实例放置到earlySingletonObjects中备用,然后再给CBean属性赋值,这个时候又发现它反过来还要依赖ABean。
第四步,我们从earlySingletonObjects结构中找到ABean的早期毛胚实例,取出来给CBean注入属性,这意味着这时CBean所用的ABean实例是那个早期的毛胚实例。这样就先创建好了CBean。
第五步,程序控制流回到第二步,完成BBean的属性注入。
第六步,程序控制流回到第一步,完成ABean的属性注入。至此,所有的Bean就都创建完了。
通过上述过程可以知道,这一系列的Bean是纠缠在一起创建的,我们不能简单地先后独立创建它们,而是要作为一个整体来创建。
相应的程序代码,反映在getBean(), createBean() 和 doCreateBean()中。
java
@Override
public Object getBean(String beanName) throws BeansException {
//先尝试直接从容器中获取bean实例
Object singleton = this.getSingleton(beanName);
if (singleton == null) {
//如果没有实例,则尝试从毛胚实例中获取
singleton = this.earlySingletonObjects.get(beanName);
if (singleton == null) {
//如果连毛胚都没有,则创建bean实例并注册
BeanDefinition beanDefinition = beanDefinitionMap.get(beanName);
singleton = createBean(beanDefinition);
this.registerSingleton(beanName, singleton);
// 预留beanpostprocessor位置
// step 1: postProcessBeforeInitialization
// step 2: afterPropertiesSet
// step 3: init-method
// step 4: postProcessAfterInitialization
}
}
return singleton;
}
private Object createBean(BeanDefinition beanDefinition) {
Class<?> clz = null;
//创建毛胚bean实例
Object obj = doCreateBean(beanDefinition);
//存放到毛胚实例缓存中
this.earlySingletonObjects.put(beanDefinition.getId(), obj);
try {
clz = Class.forName(beanDefinition.getClassName());
}
//处理属性
handleProperties(beanDefinition, clz, obj);
return obj;
}
//doCreateBean创建毛胚实例,仅仅调用构造方法,没有进行属性处理
private Object doCreateBean(BeanDefinition bd) {
Class<?> clz = null;
Object obj = null;
Constructor<?> con = null;
try {
clz = Class.forName(bd.getClassName());
//handle constructor
ArgumentValues argumentValues = bd.getConstructorArgumentValues();
if (!argumentValues.isEmpty()) {
Class<?>[] paramTypes = new Class<?>[argumentValues.getArgumentCount()];
Object[] paramValues = new Object[argumentValues.getArgumentCount()];
for (int i = 0; i < argumentValues.getArgumentCount(); i++) {
ArgumentValue argumentValue = argumentValues.getIndexedArgumentValue(i);
if ("String".equals(argumentValue.getType()) || "java.lang.String".equals(argumentValue.getType())) {
paramTypes[i] = String.class;
paramValues[i] = argumentValue.getValue();
} else if ("Integer".equals(argumentValue.getType()) || "java.lang.Integer".equals(argumentValue.getType())) {
paramTypes[i] = Integer.class;
paramValues[i] = Integer.valueOf((String) argumentValue.getValue());
} else if ("int".equals(argumentValue.getType())) {
paramTypes[i] = int.class;
paramValues[i] = Integer.valueOf((String) argumentValue.getValue()).intValue();
} else {
paramTypes[i] = String.class;
paramValues[i] = argumentValue.getValue();
}
}
try {
con = clz.getConstructor(paramTypes);
obj = con.newInstance(paramValues);
}
} else {
obj = clz.newInstance();
}
}
System.out.println(bd.getId() + " bean created. " + bd.getClassName() + " : " + obj.toString());
return obj;
}createBean()方法中调用了一个 doCreateBean(bd)方法,专门负责创建早期的毛胚实例。毛胚实例创建好后会放在earlySingletonObjects结构中,然后createBean()方法再调用handleProperties()补齐这些property的值。
在getBean()方法中,首先要判断有没有已经创建好的bean,有的话直接取出来,如果没有就检查earlySingletonObjects中有没有相应的毛胚Bean,有的话直接取出来,没有的话就去创建,并且会根据Bean之间的依赖关系把相关的Bean全部创建好。
很多资料把这个过程叫做bean的"三级缓存",这个术语来自于Spring源代码中的程序注释。实际上我们弄清楚了这个getBean()的过程后就会知道这段注释并不是很恰当。只不过这是Spring发明人自己写下的注释,大家也都这么称呼而已。
包装方法refresh()
可以看出,在Spring体系中,Bean是结合在一起同时创建完毕的。为了减少它内部的复杂性,Spring对外提供了一个很重要的包装方法: refresh()。具体的包装方法也很简单,就是对所有的Bean调用了一次getBean(),利用getBean()方法中的createBean()创建Bean实例,就可以只用一个方法把容器中所有的Bean的实例创建出来了。
我们先在SimpleBeanFactory中实现一个最简化的refresh()方法。
java
public void refresh() {
for (String beanName : beanDefinitionNames) {
try {
getBean(beanName);
}
}
}然后我们改造ClassPathXmlApplicationContext,配合我们上一步增加的refresh()方法使用,你可以看下相应的代码。
java
public class ClassPathXmlApplicationContext implements BeanFactory, ApplicationEventPublisher {
SimpleBeanFactory beanFactory;
public ClassPathXmlApplicationContext(String fileName) {
this(fileName, true);
}
public ClassPathXmlApplicationContext(String fileName, boolean isRefresh) {
Resource resource = new ClassPathXmlResource(fileName);
SimpleBeanFactory simpleBeanFactory = new SimpleBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(simpleBeanFactory);
reader.loadBeanDefinitions(resource);
this.beanFactory = simpleBeanFactory;
if (isRefresh) {
this.beanFactory.refresh();
}
}
// 省略方法实现
}到这里,我们的ClassPAthXmlApplicationContext用一个refresh() 就将整个IoC容器激活了,运行起来,加载所有配置好的Bean。
你可以试着构建一下的测试代码。
java
public class BaseBaseService {
private AServiceImpl as;
// 省略 getter、setter方法
}
java
public class BaseService {
private BaseBaseService bbs;
// 省略 getter、setter方法
}
java
public class AServiceImpl implements AService {
private String name;
private int level;
private String property1;
private String property2;
private BaseService ref1;
// 省略 getter、setter方法
}相应的XML配置如下:
java
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<constructor-arg type="String" name="name" value="abc"/>
<constructor-arg type="int" name="level" value="3"/>
<property type="String" name="property1" value="Someone says"/>
<property type="String" name="property2" value="Hello World!"/>
<property type="com.minis.test.BaseService" name="ref1" ref="baseservice"/>
</bean>
<bean id="basebaseservice" class="com.minis.test.BaseBaseService">
<property type="com.minis.test.AServiceImpl" name="as" ref="aservice" />
</bean>
<bean id="baseservice" class="com.minis.test.BaseService">
<property type="com.minis.test.BaseBaseService" name="bbs" ref="basebaseservice" />
</bean>
</beans>然后运行测试程序,可以看到我们自己的IoC容器运行起来了。
小结
这节课,我们紧接着上一节课对XML配置的解析,实现了Spring中Bean的构造器注入与setter注入两种方式。
在将属性注入Bean的过程中,我们还增加了ref属性,它可以在一个Bean对象中引入另外的Bean对象。我们还通过引入"毛胚Bean"的概念解决了循环依赖的问题。
我们还为容器增加了refresh()方法,这个方法包装了容器启动的各个步骤,从Bean工厂的创建到Bean对象的实例化和初始化,再到完成Spring容器加载,一切Bean的处理都能在这里完成,可以说是Spring中的核心方法了。
完整源代码参见 https://github.com/YaleGuo/minis
课后题
学完这节课内容,我也给你留一道思考题。你认为能不能在一个Bean的构造器中注入另一个Bean?
04|增强IoC容器:如何让我们的Spring支持注解?
上节课我们通过一系列的操作使XML使配置文件生效,然后实现了Spring中Bean的构造器注入与setter注入,通过引入"早期毛胚Bean"的概念解决了循环依赖的问题,我们还为容器增加了Spring中的一个核心方法refresh(),作为整个容器启动的入口。现在我们的容器已经初具模型了,那如何让它变得更强大,从种子长成一株幼苗呢?
这节课我们就来实现一个增强版的IoC容器,支持通过注解的方式进行依赖注入。注解是我们在编程中常用的技术,可以减少配置文件的内容,便于管理的同时还能提高开发效率。所以这节课我们将 实现Autowired注解,并用这个方式进行依赖注入。
目录结构
我们手写MiniSpring的目的是更好地学习Spring。因此,我们会时不时回头来整理整个项目的目录结构,和Spring保持一致。
现在我们先参考Spring框架的结构,来调整我们的项目结构,在beans目录下新增factory目录,factory目录中则新增xml、support、config与annotation四个目录。
├── beans
│ └── factory
│ ├── xml
│ └── support
│ └── config
│ └── annotation接下来将之前所写的类文件移动至新增目录下,你可以看一下移动后的结构。
factory ------ BeanFactory.java
factory.xml ------ XmlBeanDefinitionReader.java
factory.support ------ DefaultSingletonBeanRegistry.java、
BeanDefinitionRegistry.java、SimpleBeanFactory.java
factory.config ------ SingletonBeanRegistry.java、ConstructorArgumentValues.java、
ConstructorArgumentValue.java、BeanDefinition.java
// 注:
// ConstructorArgumentValues由ArgumentValues改名而来
// ConstructorArgumentValue由ArgumentValue改名而来熟悉了这个项目结构后,你再回头去看Spring框架的结构,会发现它们是一样的,不光目录一样,文件名也是一样的,类中的主要方法名和属性名也是一样的。我这么做的目的是便于你之后自己继续学习。
注解支持
如果你用过Spring的话,对Autowired注解想必不陌生,这也是常用的依赖注入的方式,在需要注入的对象上增加@Autowired注解就可以了,你可以参考下面这个例子。
java
public class Test {
@Autowired
private TestAutowired testAutowired;
}这种方式的好处在于,不再需要显式地在XML配置文件中使用ref属性,指定需要依赖的对象,直接在代码中加上这个注解,就能起到同样的依赖注入效果。但是你要知道,计算机运行程序是机械式的,并没有魔法,加的这一行注解不会自我解释,必须有另一个程序去解释它,否则注解就变成了注释。
那么,问题就来了, 我们要在哪一段程序、哪个时机去解释这个注解呢?
简单分析一下,这个注解是作用在一个实例变量上的,为了生效,我们首先必须创建好这个对象,也就是在createBean时机之后。
回顾前面几节课的内容,我们通过一个refresh()方法包装了整个Bean的创建过程,我们能看到在创建Bean实例之后,要进行初始化工作,refresh()方法内预留了postProcessBeforeInitialization、init-method与postProcessAfterInitialization的位置,根据它们的名称也能看出是在初始化前、中、后分别对Bean进行处理。这里就是很好的时机。
接下来我们一起看看这些功能是如何实现的。
在这个预留的位置,我们可以考虑调用一个Bean处理器Processor,由处理器来解释注解。我们首先来定义BeanPostProcessor,它内部的两个方法分别用于Bean初始化之前和之后。
- Bean初始化之前
java
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
}- Bean初始化之后
java
public interface BeanPostProcessor {
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}接下来我们定义Autowired注解,很简单,你可以参考一下。
java
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Autowired {
}根据这个定义可以知道,Autowired修饰成员变量(属性),并且在运行时生效。
为了实现@Autowired这个注解,我们很自然地会想到,利用反射获取所有标注了Autowired注解的成员变量,把它初始化成一个Bean,然后注入属性。结合前面我们定义的BeanPostProcessor接口,我们来定义Autowired的处理类AutowiredAnnotationBeanPostProcessor。
java
public class AutowiredAnnotationBeanPostProcessor implements BeanPostProcessor {
private AutowireCapableBeanFactory beanFactory;
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
Object result = bean;
Class<?> clazz = bean.getClass();
Field[] fields = clazz.getDeclaredFields();
if (fields != null) {
//对每一个属性进行判断,如果带有@Autowired注解则进行处理
for (Field field : fields) {
boolean isAutowired = field.isAnnotationPresent(Autowired.class);
if (isAutowired) {
//根据属性名查找同名的bean
String fieldName = field.getName();
Object autowiredObj = this.getBeanFactory().getBean(fieldName);
//设置属性值,完成注入
try {
field.setAccessible(true);
field.set(bean, autowiredObj);
System.out.println("autowire " + fieldName + " for bean " + beanName);
}
}
}
}
return result;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return null;
}
public AutowireCapableBeanFactory getBeanFactory() {
return beanFactory;
}
public void setBeanFactory(AutowireCapableBeanFactory beanFactory) {
this.beanFactory = beanFactory;
}
}其实,核心代码就只有几行。
java
boolean isAutowired = field.isAnnotationPresent(Autowired.class);
if(isAutowired) {
String fieldName = field.getName();
Object autowiredObj = this.getBeanFactory().getBean(fieldName);
field.setAccessible(true);
field.set(bean, autowiredObj);
}判断类里面的每一个属性是不是带有Autowired注解,如果有,就根据属性名获取Bean。从这里我们可以看出,属性名字很关键,我们就是靠它来获取和创建的Bean。有了Bean之后,我们通过反射设置属性值,完成依赖注入。
新的BeanFactory
在这里我们引入了AutowireCapableBeanFactory,这个BeanFactory就是专为Autowired注入的Bean准备的。
在此之前我们已经定义了BeanFactory接口,以及一个SimpleBeanFactory的实现类。现在我们又需要引入另外一个BeanFactory------ AutowireCapableBeanFactory。基于代码复用、解耦的原则,我们可以对通用部分代码进行抽象,抽象出一个AbstractBeanFactory类。
目前,我们可以把refresh()、getBean()、registerBeanDefinition()等方法提取到抽象类,因为我们提供了默认实现,确保这些方法即使不再被其他BeanFactory实现也能正常生效。改动比较大,所以这里我贴出完整的类代码,下面就是AbstractBeanFactory的完整实现。
java
public abstract class AbstractBeanFactory extends DefaultSingletonBeanRegistry implements BeanFactory, BeanDefinitionRegistry {
private Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
private List<String> beanDefinitionNames = new ArrayList<>();
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
public AbstractBeanFactory() {
}
public void refresh() {
for (String beanName : beanDefinitionNames) {
try {
getBean(beanName);
}
}
}
@Override
public Object getBean(String beanName) throws BeansException {
//先尝试直接从容器中获取bean实例
Object singleton = this.getSingleton(beanName);
if (singleton == null) {
//如果没有实例,则尝试从毛胚实例中获取
singleton = this.earlySingletonObjects.get(beanName);
if (singleton == null) {
//如果连毛胚都没有,则创建bean实例并注册
System.out.println("get bean null -------------- " + beanName);
BeanDefinition beanDefinition = beanDefinitionMap.get(beanName);
singleton = createBean(beanDefinition);
this.registerBean(beanName, singleton);
// 进行beanpostprocessor处理
// step 1: postProcessBeforeInitialization
applyBeanPostProcessorBeforeInitialization(singleton, beanName);
// step 2: init-method
if (beanDefinition.getInitMethodName() != null && !beanDefinition.equals("")) {
invokeInitMethod(beanDefinition, singleton);
}
// step 3: postProcessAfterInitialization
applyBeanPostProcessorAfterInitialization(singleton, beanName);
}
}
return singleton;
}
private void invokeInitMethod(BeanDefinition beanDefinition, Object obj) {
Class<?> clz = beanDefinition.getClass();
Method method = null;
try {
method = clz.getMethod(beanDefinition.getInitMethodName());
} try {
method.invoke(obj);
}
}
@Override
public Boolean containsBean(String name) {
return containsSingleton(name);
}
public void registerBean(String beanName, Object obj) {
this.registerSingleton(beanName, obj);
}
@Override
public void registerBeanDefinition(String name, BeanDefinition beanDefinition) {
this.beanDefinitionMap.put(name, beanDefinition);
this.beanDefinitionNames.add(name);
if (!beanDefinition.isLazyInit()) {
try {
getBean(name);
}
}
}
@Override
public void removeBeanDefinition(String name) {
this.beanDefinitionMap.remove(name);
this.beanDefinitionNames.remove(name);
this.removeSingleton(name);
}
@Override
public BeanDefinition getBeanDefinition(String name) {
return this.beanDefinitionMap.get(name);
}
@Override
public boolean containsBeanDefinition(String name) {
return this.beanDefinitionMap.containsKey(name);
}
@Override
public boolean isSingleton(String name) {
return this.beanDefinitionMap.get(name).isSingleton();
}
@Override
public boolean isPrototype(String name) {
return this.beanDefinitionMap.get(name).isPrototype();
}
@Override
public Class<?> getType(String name) {
return this.beanDefinitionMap.get(name).getClass();
}
private Object createBean(BeanDefinition beanDefinition) {
Class<?> clz = null;
//创建毛胚bean实例
Object obj = doCreateBean(beanDefinition);
//存放到毛胚实例缓存中
this.earlySingletonObjects.put(beanDefinition.getId(), obj);
try {
clz = Class.forName(beanDefinition.getClassName());
}
//完善bean,主要是处理属性
populateBean(beanDefinition, clz, obj);
return obj;
}
//doCreateBean创建毛胚实例,仅仅调用构造方法,没有进行属性处理
private Object doCreateBean(BeanDefinition beanDefinition) {
Class<?> clz = null;
Object obj = null;
Constructor<?> con = null;
try {
clz = Class.forName(beanDefinition.getClassName());
// handle constructor
ConstructorArgumentValues constructorArgumentValues = beanDefinition.getConstructorArgumentValues();
if (!constructorArgumentValues.isEmpty()) {
Class<?>[] paramTypes = new Class<?>
[constructorArgumentValues.getArgumentCount()];
Object[] paramValues = new Object[constructorArgumentValues.getArgumentCount()];
for (int i = 0; i < constructorArgumentValues.getArgumentCount(); i++) {
ConstructorArgumentValue constructorArgumentValue = constructorArgumentValues.getIndexedArgumentValue(i);
if ("String".equals(constructorArgumentValue.getType()) || "java.lang.String".equals(constructorArgumentValue.getType())) {
paramTypes[i] = String.class;
paramValues[i] = constructorArgumentValue.getValue();
} else if ("Integer".equals(constructorArgumentValue.getType()) || "java.lang.Integer".equals(constructorArgumentValue.getType())) {
paramTypes[i] = Integer.class;
paramValues[i] = Integer.valueOf((String) constructorArgumentValue.getValue());
} else if ("int".equals(constructorArgumentValue.getType())) {
paramTypes[i] = int.class;
paramValues[i] = Integer.valueOf((String) constructorArgumentValue.getValue());
} else {
paramTypes[i] = String.class;
paramValues[i] = constructorArgumentValue.getValue();
}
}
try {
con = clz.getConstructor(paramTypes);
obj = con.newInstance(paramValues);
}
}
}
System.out.println(beanDefinition.getId() + " bean created. " + beanDefinition.getClassName() + " : " + obj.toString());
return obj;
}
private void populateBean(BeanDefinition beanDefinition, Class<?> clz, Object obj) {
handleProperties(beanDefinition, clz, obj);
}
private void handleProperties(BeanDefinition beanDefinition, Class<?> clz, Object obj) {
// handle properties
System.out.println("handle properties for bean : " + beanDefinition.getId());
PropertyValues propertyValues = beanDefinition.getPropertyValues();
//如果有属性
if (!propertyValues.isEmpty()) {
for (int i = 0; i < propertyValues.size(); i++) {
PropertyValue propertyValue = propertyValues.getPropertyValueList().get(i);
String pType = propertyValue.getType();
String pName = propertyValue.getName();
Object pValue = propertyValue.getValue();
boolean isRef = propertyValue.getIsRef();
Class<?>[] paramTypes = new Class<?>[1];
Object[] paramValues = new Object[1];
if (!isRef) { //如果不是ref,只是普通属性
//对每一个属性,分数据类型分别处理
if ("String".equals(pType) || "java.lang.String".equals(pType)) {
paramTypes[0] = String.class;
} else if ("Integer".equals(pType) || "java.lang.Integer".equals(pType)) {
paramTypes[i] = Integer.class;
} else if ("int".equals(pType)) {
paramTypes[i] = int.class;
} else {
paramTypes[i] = String.class;
}
paramValues[0] = pValue;
} else {//is ref, create the dependent beans
try {
paramTypes[0] = Class.forName(pType);
} try {//再次调用getBean创建ref的bean实例
paramValues[0] = getBean((String) pValue);
}
}
//按照setXxxx规范查找setter方法,调用setter方法设置属性
String methodName = "set" + pName.substring(0, 1).toUpperCase() + pName.substring(1);
Method method = null;
try {
method = clz.getMethod(methodName, paramTypes);
} try {
method.invoke(obj, paramValues);
}
}
}
}
abstract public Object applyBeanPostProcessorBeforeInitialization(Object existingBean, String beanName) throws BeansException;
abstract public Object applyBeanPostProcessorAfterInitialization(Object existingBean, String beanName) throws BeansException;
}上面的代码较长,但仔细一看可以发现绝大多数是我们原本已经实现的方法,只是移动到了AbstractBeanFactory这个抽象类之中。最关键的代码是getBean()中的这一段。
java
BeanDefinition beanDefinition = beanDefinitionMap.get(beanName);
singleton = createBean(beanDefinition);
this.registerBean(beanName, singleton);
// beanpostprocessor
// step 1: postProcessBeforeInitialization
applyBeanPostProcessorBeforeInitialization(singleton, beanName);
// step 2: init-method
if (beanDefinition.getInitMethodName() != null && !beanDefinition.equals("")) {
invokeInitMethod(beanDefinition, singleton);
}
// step 3: postProcessAfterInitialization
applyBeanPostProcessorAfterInitialization(singleton, beanName);先获取Bean的定义,然后创建Bean实例,再进行Bean的后处理并初始化。在这个抽象类里,我们需要关注两个核心的改动。
- 定义了抽象方法applyBeanPostProcessorBeforeInitialization与applyBeanPostProcessorAfterInitialization,由名字可以看出,分别是在Bean处理类初始化之前和之后执行的方法。这两个方法交给具体的继承类去实现。
- 在getBean()方法中,在以前预留的位置,实现了对Bean初始化前、初始化和初始化后的处理。
java
// step 1: postProcessBeforeInitialization
applyBeanPostProcessorBeforeInitialization(singleton, beanName);
// step 2: init-method
if (beanDefinition.getInitMethodName() != null && !beanDefinition.equals("")) {
invokeInitMethod(beanDefinition, singleton);
}
// step 3: postProcessAfterInitialization
applyBeanPostProcessorAfterInitialization(singleton, beanName);现在已经抽象出了一个AbstractBeanFactory,接下来我们看看具体的AutowireCapableBeanFactory是如何实现的。
java
public class AutowireCapableBeanFactory extends AbstractBeanFactory {
private final List<AutowiredAnnotationBeanPostProcessor> beanPostProcessors = new ArrayList<>();
public void addBeanPostProcessor(AutowiredAnnotationBeanPostProcessor beanPostProcessor) {
this.beanPostProcessors.remove(beanPostProcessor);
this.beanPostProcessors.add(beanPostProcessor);
}
public int getBeanPostProcessorCount() {
return this.beanPostProcessors.size();
}
public List<AutowiredAnnotationBeanPostProcessor> getBeanPostProcessors() {
return this.beanPostProcessors;
}
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName) throws BeansException {
Object result = existingBean;
for (AutowiredAnnotationBeanPostProcessor beanProcessor : getBeanPostProcessors()) {
beanProcessor.setBeanFactory(this);
result = beanProcessor.postProcessBeforeInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
result = beanProcessor.postProcessAfterInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
}从代码里也可以看出,它实现起来并不复杂,用一个列表beanPostProcessors记录所有的Bean处理器,这样可以按照需求注册若干个不同用途的处理器,然后调用处理器。
java
for (AutowiredAnnotationBeanPostProcessor beanProcessor : getBeanPostProcessors()) {
beanProcessor.setBeanFactory(this);
result = beanProcessor.postProcessBeforeInitialization(result, beanName);
}代码一目了然,就是对每个Bean处理器,调用方法postProcessBeforeInitialization。
最后则是调整ClassPathXmlApplicationContext,引入的成员变量由SimpleBeanFactory改为新建的AutowireCapableBeanFactory,并在构造函数里增加上下文刷新逻辑。
java
public ClassPathXmlApplicationContext(String fileName, boolean isRefresh) {
Resource resource = new ClassPathXmlResource(fileName);
AutowireCapableBeanFactory beanFactory = new AutowireCapableBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions(resource);
this.beanFactory = beanFactory;
if (isRefresh) {
try {
refresh();
}
}
}
public List<BeanFactoryPostProcessor> getBeanFactoryPostProcessors() {
return this.beanFactoryPostProcessors;
}
public void addBeanFactoryPostProcessor(BeanFactoryPostProcessor postProcessor) {
this.beanFactoryPostProcessors.add(postProcessor);
}
public void refresh() throws BeansException, IllegalStateException {
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(this.beanFactory);
// Initialize other special beans in specific context subclasses.
onRefresh();
}
private void registerBeanPostProcessors(AutowireCapableBeanFactory beanFactory) {
beanFactory.addBeanPostProcessor(new AutowiredAnnotationBeanPostProcessor());
}
private void onRefresh() {
this.beanFactory.refresh();
}新的refresh()方法,会先注册BeanPostProcessor,这样BeanFactory里就有解释注解的处理器了,然后在getBean()的过程中使用它。
最后,我们来回顾一下完整的过程。
- 启动ClassPathXmlApplicationContext容器,执行refresh()。
- 在refresh执行过程中,调用registerBeanPostProcessors(),往BeanFactory里注册Bean处理器,如AutowiredAnnotationBeanPostProcessor。
- 执行onRefresh(), 执行AbstractBeanFactory的refresh()方法。
- AbstractBeanFactory的refresh()获取所有Bean的定义,执行getBean()创建Bean实例。
- getBean()创建完Bean实例后,调用Bean处理器并初始化。
java
applyBeanPostProcessorBeforeInitialization(singleton, beanName);
invokeInitMethod(beanDefinition, singleton);
applyBeanPostProcessorAfterInitialization(singleton, beanName);- applyBeanPostProcessorBeforeInitialization由具体的BeanFactory,如AutowireCapableBeanFactory,来实现,这个实现也很简单,就是对BeanFactory里已经注册好的所有Bean处理器调用相关方法。
java
beanProcessor.postProcessBeforeInitialization(result, beanName);
beanProcessor.postProcessAfterInitialization(result, beanName);- 我们事先准备好的AutowiredAnnotationBeanPostProcessor方法里面会解释Bean中的Autowired注解。
测试注解
到这里,支持注解的工作就完成了,接下来就是测试Autowired注解了。在这里我们做两个改动。
- 在测试类中增加Autowired注解。
java
package com.minis.test;
import com.minis.beans.factory.annotation.Autowired;
public class BaseService {
@Autowired
private BaseBaseService bbs;
public BaseBaseService getBbs() {
return bbs;
}
public void setBbs(BaseBaseService bbs) {
this.bbs = bbs;
}
public BaseService() {
}
public void sayHello() {
System.out.println("Base Service says Hello");
bbs.sayHello();
}
}- 注释XML配置文件中关于循环依赖的配置。
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id="bbs" class="com.minis.test.BaseBaseService">
<property type="com.minis.test.AServiceImpl" name="as" ref="aservice" />
</bean>
<bean id="aservice" class="com.minis.test.AServiceImpl">
<constructor-arg type="String" name="name" value="abc"/>
<constructor-arg type="int" name="level" value="3"/>
<property type="String" name="property1" value="Someone says"/>
<property type="String" name="property2" value="Hello World!"/>
<property type="com.minis.test.BaseService" name="ref1" ref="baseservice"/>
</bean>
<bean id="baseservice" class="com.minis.test.BaseService">
<!-- <property type="com.minis.test.BaseBaseService" name="bbs"
ref="basebaseservice" />-->
</bean>
</beans>小结
这节课我们丰富了原来的框架,支持了注解,让它更有模有样了。
注解是现代最受程序员欢迎的特性,我们通过Autowired这个注解实现了Bean的注入,这样程序员不用再在XML配置文件中手动配置property,而是在类中声明property的时候直接加上注解即可,框架使用的机制是名称匹配,这也是Spring所支持的一种匹配方式。
接着我们提取了BeanFactory接口,定义了一个抽象的AbstractBeanFactory。通过这个抽象类,将Bean工厂需要做的事情的框架搭建出来,然后在具体实现类中完善细节。这种程序结构称为interface-abstract class-class(接口抽象类),是一种做框架时常用的设计模式。

我们自己手写MiniSpring,不仅仅是要学习一个功能如何实现,还要学习大师的做法,模仿他们的代码和设计,练习得多了就能像专业程序员一样地写代码了。
完整源代码参见 https://github.com/YaleGuo/minis
课后题
学完这节课,我也给你留一道思考题。我们实现了Autowired注解,在现有框架中能否支持多个注解?
05|实现完整的IoC容器:构建工厂体系并添加容器事件
前面我们已经实现了IoC的核心部分,骨架已经有了,那怎么让这个IoC丰满起来呢?这就需要实现更多的功能,让我们的IoC更加完备。所以这节课我们将通过建立BeanFactory体系,添加容器事件等一系列操作,进一步完善IoC的功能。
实现一个完整的IoC容器
为了让我们的MiniSpring更加专业一点,也更像Spring一点,我们将实现3个功能点。
- 进一步增强扩展性,新增4个接口。
- ListableBeanFactory
- ConfigurableBeanFactory
- ConfigurableListableBeanFactory
- EnvironmentCapable
- 实现DefaultListableBeanFactory,该类就是Spring IoC的引擎。
- 改造ApplicationContext。
下面我们就一条条来看。
增强扩展性
首先我们来增强BeanFactory的扩展性,使它具有不同的特性。
我们以前定义的AutowireCapableBeanFactory就是在通用的BeanFactory的基础上添加了Autowired注解特性。比如可以将Factory内部管理的Bean作为一个集合来对待,获取Bean的数量,得到所有Bean的名字,按照某个类型获取Bean列表等等。这个特性就定义在ListableBeanFactory中。
java
public interface ListableBeanFactory extends BeanFactory {
boolean containsBeanDefinition(String beanName);
int getBeanDefinitionCount();
String[] getBeanDefinitionNames();
String[] getBeanNamesForType(Class<?> type);
<T> Map<String, T> getBeansOfType(Class<T> type) throws BeansException;
}我们还可以将维护Bean之间的依赖关系以及支持Bean处理器也看作一个独立的特性,这个特性定义在ConfigurableBeanFactory接口中。
java
public interface ConfigurableBeanFactory extends BeanFactory, SingletonBeanRegistry {
String SCOPE_SINGLETON = "singleton";
String SCOPE_PROTOTYPE = "prototype";
void addBeanPostProcessor(BeanPostProcessor beanPostProcessor);
int getBeanPostProcessorCount();
void registerDependentBean(String beanName, String dependentBeanName);
String[] getDependentBeans(String beanName);
String[] getDependenciesForBean(String beanName);
}然后还可以集成,用一个ConfigurableListableBeanFactory接口把AutowireCapableBeanFactory、ListableBeanFactory和ConfigurableBeanFactory合并在一起。
java
package com.minis.beans.factory.config;
import com.minis.beans.factory.ListableBeanFactory;
public interface ConfigurableListableBeanFactory
extends ListableBeanFactory, AutowireCapableBeanFactory,
ConfigurableBeanFactory {
}由上述接口定义的方法可以看出,这些接口都给通用的BeanFactory与BeanDefinition新增了众多处理方法,用来增强各种特性。
在Java语言的设计中,一个Interface代表的是一种特性或者能力,我们把这些特性或能力一个个抽取出来,各自独立互不干扰。如果一个具体的类,想具备某些特性或者能力,就去实现这些interface,随意组合。这是一种良好的设计原则,叫 interface segregation(接口隔离原则)。这条原则在Spring框架中用得很多,你可以注意一下。
由于ConfigurableListableBeanFactory继承了AutowireCapableBeanFactory,所以我们需要调整之前定义的AutowireCapableBeanFactory,由class改为interface。
java
public interface AutowireCapableBeanFactory extends BeanFactory {
int AUTOWIRE_NO = 0;
int AUTOWIRE_BY_NAME = 1;
int AUTOWIRE_BY_TYPE = 2;
Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName) throws BeansException;
Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) throws BeansException;
}新增抽象类AbstractAutowireCapableBeanFactory替代原有的实现类。
java
public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory implements AutowireCapableBeanFactory {
private final List<BeanPostProcessor> beanPostProcessors = new ArrayList<BeanPostProcessor>();
public void addBeanPostProcessor(BeanPostProcessor beanPostProcessor) {
this.beanPostProcessors.remove(beanPostProcessor);
this.beanPostProcessors.add(beanPostProcessor);
}
public int getBeanPostProcessorCount() {
return this.beanPostProcessors.size();
}
public List<BeanPostProcessor> getBeanPostProcessors() {
return this.beanPostProcessors;
}
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName) throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
beanProcessor.setBeanFactory(this);
result = beanProcessor.postProcessBeforeInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
result = beanProcessor.postProcessAfterInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
}上述代码与之前的实现类一致,在此不多赘述。
环境
除了扩充BeanFactory体系,我们还打算给容器增加一些环境因素,使一些容器整体所需要的属性有个地方存储访问。
在core目录下新建env目录,增加PropertyResolver.java、EnvironmentCapable.java、Environment.java三个接口类。EnvironmentCapable主要用于获取Environment实例,Environment则继承PropertyResoulver接口,用于获取属性。所有的ApplicationContext都实现了Environment接口。
Environment.java 接口
java
public interface Environment extends PropertyResolver {
String[] getActiveProfiles();
String[] getDefaultProfiles();
boolean acceptsProfiles(String... profiles);
}EnvironmentCapable.java 接口
java
public interface EnvironmentCapable {
Environment getEnvironment();
}PropertyResolver.java 接口
java
public interface PropertyResolver {
boolean containsProperty(String key);
String getProperty(String key);
String getProperty(String key, String defaultValue);
<T> T getProperty(String key, Class<T> targetType);
<T> T getProperty(String key, Class<T> targetType, T defaultValue);
<T> Class<T> getPropertyAsClass(String key, Class<T> targetType);
String getRequiredProperty(String key) throws IllegalStateException;
<T> T getRequiredProperty(String key, Class<T> targetType) throws IllegalStateException;
String resolvePlaceholders(String text);
String resolveRequiredPlaceholders(String text) throws IllegalArgumentException;
}IoC引擎
接下来我们看看IoC引擎------DefaultListableBeanFactory的实现。
java
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactory implements ConfigurableListableBeanFactory {
public int getBeanDefinitionCount() {
return this.beanDefinitionMap.size();
}
public String[] getBeanDefinitionNames() {
return (String[]) this.beanDefinitionNames.toArray();
}
public String[] getBeanNamesForType(Class<?> type) {
List<String> result = new ArrayList<>();
for (String beanName : this.beanDefinitionNames) {
boolean matchFound = false;
BeanDefinition mbd = this.getBeanDefinition(beanName);
Class<?> classToMatch = mbd.getClass();
if (type.isAssignableFrom(classToMatch)) {
matchFound = true;
} else {
matchFound = false;
}
if (matchFound) {
result.add(beanName);
}
}
return (String[]) result.toArray();
}
@SuppressWarnings("unchecked")
@Override
public <T> Map<String, T> getBeansOfType(Class<T> type) throws BeansException {
String[] beanNames = getBeanNamesForType(type);
Map<String, T> result = new LinkedHashMap<>(beanNames.length);
for (String beanName : beanNames) {
Object beanInstance = getBean(beanName);
result.put(beanName, (T) beanInstance);
}
return result;
}
}从上述代码中,似乎看不出这个类是如何成为IoC引擎的,因为它的实现都是很简单地获取各种属性的方法。它成为引擎的秘诀在于 它继承了其他BeanFactory类来实现Bean的创建管理功能。从代码可以看出它继承了AbstractAutowireCapableBeanFactory并实现了 ConfigurableListableBeanFactory接口。
参看Spring框架的这一部分,整个继承体系图。
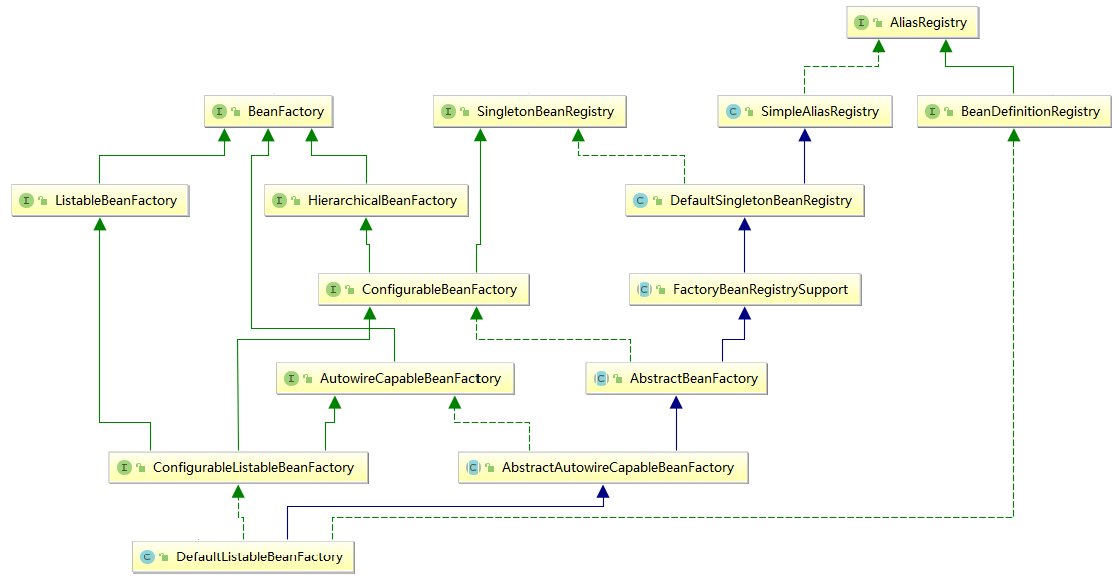
可以看出,我们的MiniSpring跟Spring框架设计得几乎是一模一样。当然,这是我们有意为之,我们手写MiniSpring就是为了深入理解Spring。
当ClassPathXmlApplicationContext这个Spring核心启动类运行时,注入了DefaultListableBeanFactory,为整个Spring框架做了默认实现,这样就完成了框架内部的逻辑闭环。
事件
接着我们来完善事件的发布与监听,包括ApplicationEvent、ApplicationListener、ApplicationEventPublisher以及ContextRefreshEvent,事件一经发布就能让监听者监听到。
ApplicationEvent
java
public class ApplicationEvent extends EventObject {
private static final long serialVersionUID = 1L;
protected String msg = null;
public ApplicationEvent(Object arg0) {
super(arg0);
this.msg = arg0.toString();
}
}ApplicationListener
java
public class ApplicationListener implements EventListener {
void onApplicationEvent(ApplicationEvent event) {
System.out.println(event.toString());
}
}ContextRefreshEvent
java
public class ContextRefreshEvent extends ApplicationEvent {
private static final long serialVersionUID = 1L;
public ContextRefreshEvent(Object arg0) {
super(arg0);
}
public String toString() {
return this.msg;
}
}ApplicationEventPublisher
java
public interface ApplicationEventPublisher {
void publishEvent(ApplicationEvent event);
void addApplicationListener(ApplicationListener listener);
}可以看出,框架的EventPublisher,本质是对JDK事件类的封装。接口已经定义好了,接下来我们实现一个最简单的事件发布者SimpleApplicationEventPublisher。
java
public class SimpleApplicationEventPublisher implements ApplicationEventPublisher {
List<ApplicationListener> listeners = new ArrayList<>();
@Override
public void publishEvent(ApplicationEvent event) {
for (ApplicationListener listener : listeners) {
listener.onApplicationEvent(event);
}
}
@Override
public void addApplicationListener(ApplicationListener listener) {
this.listeners.add(listener);
}
}这个事件发布监听机制就可以为后面ApplicationContext的使用服务了。
完整的ApplicationContext
最后,我们来完善ApplicationContext,并把它作为公共接口,所有的上下文都实现自
ApplicationContext,支持上下文环境和事件发布。
java
public interface ApplicationContext
extends EnvironmentCapable, ListableBeanFactory, ConfigurableBeanFactory,
ApplicationEventPublisher {
}我们计划做4件事。
- 抽取ApplicationContext接口,实现更多有关上下文的内容。
- 支持事件的发布与监听。
- 新增AbstractApplicationContext,规范刷新上下文refresh方法的步骤规范,且将每一步骤进行抽象,提供默认实现类,同时支持自定义。
- 完成刷新之后发布事件。
首先我们来增加ApplicationContext接口的内容,丰富它的功能。
java
public interface ApplicationContext
extends EnvironmentCapable, ListableBeanFactory,
ConfigurableBeanFactory, ApplicationEventPublisher {
String getApplicationName();
long getStartupDate();
ConfigurableListableBeanFactory getBeanFactory() throws
IllegalStateException;
void setEnvironment(Environment environment);
Environment getEnvironment();
void addBeanFactoryPostProcessor(BeanFactoryPostProcessor postProcessor);
void refresh() throws BeansException, IllegalStateException;
void close();
boolean isActive();
}还是按照以前的模式,先定义接口,然后用一个抽象类搭建框架,最后提供一个具体实现类进行默认实现。Spring的这个interface-abstract-class模式是值得我们学习的,它极大地增强了框架的扩展性。
我们重点看看AbstractApplicationContext的实现。因为现在我们只做到了从XML里读取配置,用来获取应用的上下文信息,但实际Spring框架里不只支持这一种方式。但无论哪种方式,究其本质都是对应用上下文的处理,所以我们来抽象ApplicationContext的公共部分。
java
public abstract class AbstractApplicationContext implements ApplicationContext {
private Environment environment;
private final List<BeanFactoryPostProcessor> beanFactoryPostProcessors = new ArrayList<>();
private long startupDate;
private final AtomicBoolean active = new AtomicBoolean();
private final AtomicBoolean closed = new AtomicBoolean();
private ApplicationEventPublisher applicationEventPublisher;
@Override
public Object getBean(String beanName) throws BeansException {
return getBeanFactory().getBean(beanName);
}
public List<BeanFactoryPostProcessor> getBeanFactoryPostProcessors() {
return this.beanFactoryPostProcessors;
}
public void refresh() throws BeansException, IllegalStateException {
postProcessBeanFactory(getBeanFactory());
registerBeanPostProcessors(getBeanFactory());
initApplicationEventPublisher();
onRefresh();
registerListeners();
finishRefresh();
}
abstract void registerListeners();
abstract void initApplicationEventPublisher();
abstract void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory);
abstract void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory);
abstract void onRefresh();
abstract void finishRefresh();
@Override
public String getApplicationName() {
return "";
}
@Override
public long getStartupDate() {
return this.startupDate;
}
@Override
public abstract ConfigurableListableBeanFactory getBeanFactory() throws IllegalStateException;
@Override
public void addBeanFactoryPostProcessor(BeanFactoryPostProcessor postProcessor) {
this.beanFactoryPostProcessors.add(postProcessor);
}
@Override
public void close() {
}
@Override
public boolean isActive() {
return true;
}
//省略包装beanfactory的方法
}上面这段代码的核心是refresh()方法的定义,而这个方法又由下面这几个步骤组成。
java
abstract void registerListeners();
abstract void initApplicationEventPublisher();
abstract void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory);
abstract void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory);
abstract void onRefresh();
abstract void finishRefresh();看名字就比较容易理解,首先是注册监听者,接下来初始化事件发布者,随后处理Bean以及对Bean的状态进行一些操作,最后是将初始化完毕的Bean进行应用上下文刷新以及完成刷新后进行自定义操作。因为这些方法都有abstract修饰,允许把这些步骤交给用户自定义处理,因此极大地增强了扩展性。
我们现在已经拥有了一个ClassPathXmlApplicationContext,我们以这个类为例,看看如何实现上面的几个步骤。ClassPathXmlApplicationContext代码改造如下:
java
public class ClassPathXmlApplicationContext extends AbstractApplicationContext {
DefaultListableBeanFactory beanFactory;
private final List<BeanFactoryPostProcessor> beanFactoryPostProcessors = new ArrayList<>();
public ClassPathXmlApplicationContext(String fileName) {
this(fileName, true);
}
public ClassPathXmlApplicationContext(String fileName, boolean isRefresh) {
Resource resource = new ClassPathXmlResource(fileName);
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions(resource);
this.beanFactory = beanFactory;
if (isRefresh) {
try {
refresh();
}
}
}
@Override
void registerListeners() {
ApplicationListener listener = new ApplicationListener();
this.getApplicationEventPublisher().addApplicationListener(listener);
}
@Override
void initApplicationEventPublisher() {
ApplicationEventPublisher aep = new SimpleApplicationEventPublisher();
this.setApplicationEventPublisher(aep);
}
@Override
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
}
@Override
public void publishEvent(ApplicationEvent event) {
this.getApplicationEventPublisher().publishEvent(event);
}
@Override
public void addApplicationListener(ApplicationListener listener) {
this.getApplicationEventPublisher().addApplicationListener(listener);
}
public void addBeanFactoryPostProcessor(BeanFactoryPostProcessor postProcessor) {
this.beanFactoryPostProcessors.add(postProcessor);
}
@Override
void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory) {
this.beanFactory.addBeanPostProcessor(new AutowiredAnnotationBeanPostProcessor());
}
@Override
void onRefresh() {
this.beanFactory.refresh();
}
@Override
public ConfigurableListableBeanFactory getBeanFactory() throws IllegalStateException {
return this.beanFactory;
}
@Override
void finishRefresh() {
publishEvent(new ContextRefreshEvent("Context Refreshed..."));
}
}上述代码分别实现了几个抽象方法,就很高效地把ClassPathXmlApplicationContext类融入到了ApplicationContext框架里了。Spring的这个设计模式值得我们学习,采用抽象类的方式来解耦,为用户提供了极大的扩展性的便利,这也是Spring框架强大的原因之一。Spring能集成MyBatis、MySQL、Redis等框架,少不了设计模式在背后支持。
至此,我们的IoC容器就完成了,它很简单,但是这个容器麻雀虽小五脏俱全,关键是为我们深入理解Spring框架提供了很好的解剖样本。
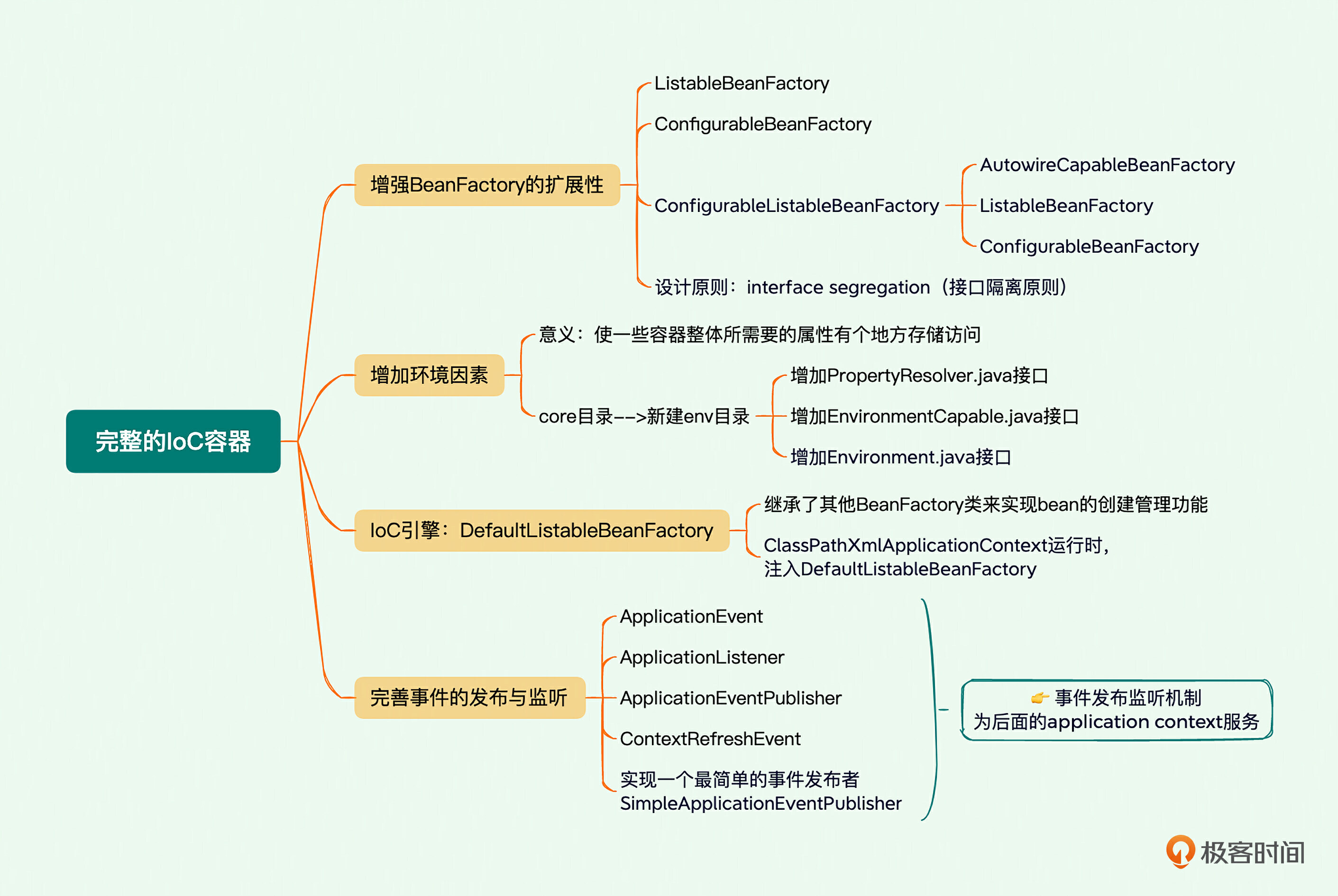
小结
经过这节课的学习,我们初步构造了一个完整的IoC容器,目前它的功能包括4项。
-
识别配置文件中的Bean定义,创建Bean,并放入容器中进行管理。
-
支持配置方式或者注解方式进行Bean的依赖注入。
-
构建了BeanFactory体系。
-
容器应用上下文和事件发布。
对照Spring框架,上述几点就是Spring IoC的核心。通过这个容器,我们构建应用程序的时候,将业务逻辑封装在Bean中,把对Bean的创建管理交给框架,即所谓的"控制反转",应用程序与框架程序互动,共同运行完整程序。
实现这些概念和特性的手段和具体代码,我们都有意模仿了Spring,它们的结构和名字都是一样的,所以你回头阅读Spring框架本身代码的时候,会觉得很熟悉,学习曲线平滑。我们沿着大师的脚步往前走,不断参照大师的作品,吸收大师的养分培育自己,让我们的MiniSpring一步步成长为一棵大树。
完整源代码参见 https://github.com/YaleGuo/minis
课后题
学完这节课,我也给你留一道思考题。我们的容器以单例模式管理所有的Bean,那么怎么应对多线程环境?
06|再回首:如何实现一个IoC容器?
第一阶段的学习完成啦,你是不是自己也实现出了一个简单可用的IoC容器呢?如果已经完成了,欢迎你把你的实现代码放到评论区,我们一起交流讨论。
我们这一章学的IoC(Inversion of Control)是我们整个MiniSpring框架的基石,也是框架中最核心的一个特性,为了让你更好地掌握这节课的内容,我们对这一整章的内容做一个重点回顾。
IoC重点回顾
IoC是面向对象编程里的一个重要原则,目的是从程序里移出原有的控制权,把控制权交给了容器。IoC容器是一个中心化的地方,负责管理对象,也就是Bean的创建、销毁、依赖注入等操作,让程序变得更加灵活、可扩展、易于维护。
在使用IoC容器时,我们需要先配置容器,包括注册需要管理的对象、配置对象之间的依赖关系以及对象的生命周期等。然后,IoC容器会根据这些配置来动态地创建对象,并把它们注入到需要它们的位置上。当我们使用IoC容器时,需要将对象的配置信息告诉IoC容器,这个过程叫做依赖注入(DI),而IoC容器就是实现依赖注入的工具。因此,理解IoC容器就是理解它是如何管理对象,如何实现DI的过程。
举个例子来说,我们有一个程序需要使用A对象,这个A对象依赖于一个B对象。我们可以把A对象和B对象的创建、配置工作都交给IoC容器来处理。这样,当程序需要使用A对象的时候,IoC容器会自动创建A对象,并将依赖的B对象注入到A对象中,最后返回给程序使用。
我们在课程中是如何一步步实现IoC容器的呢?
我们先是抽象出了Bean的定义,用一个XML进行配置,然后通过一个简单的Factory读取配置,创建bean的实例。这个极简容器只有一两个类,但是实现了bean的读取,这是原始的种子。
然后再扩展Bean,给Bean增加一些属性,如constructor、property和init-method。此时的属性值还是普通数据类型,没有对象。然后我们将属性值扩展到引用另一个Bean,实现依赖注入,同时解决了循环依赖问题。之后通过BeanPostProcessor机制让容器支持注解。
最后我们将BeanFactory扩展成一个体系,并增加应用上下文和容器事件侦听机制,完成一个完整的IoC容器。
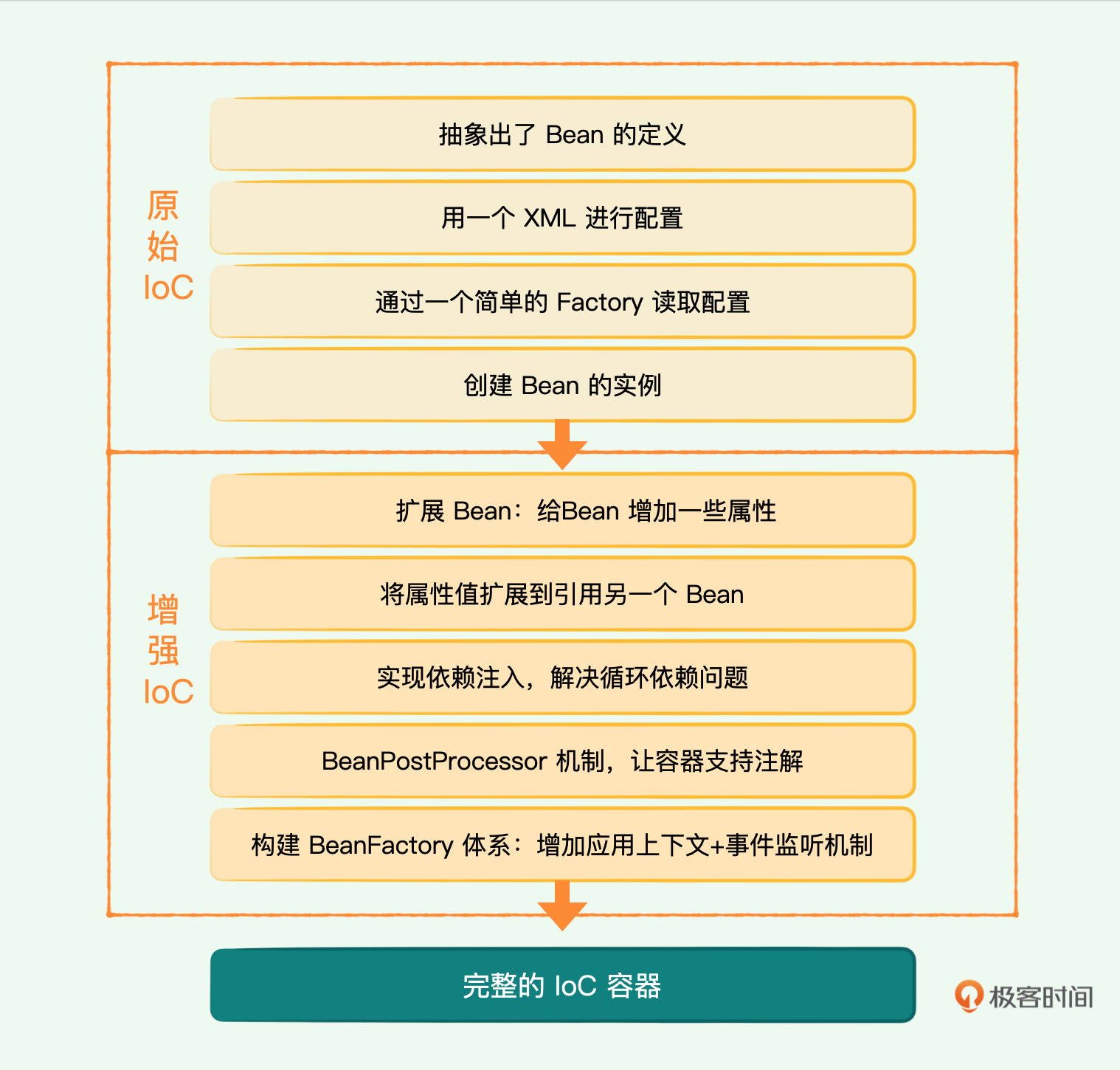
你可以根据这些内容再好好回顾一下这个过程。另外每节课后我都留了一道思考题,你是不是认真做了呢?如果没做的话,我建议你做完再来看答案。
01|原始IoC:如何通过BeanFactory实现原始版本的IoC容器?
思考题
IoC的字面含义是"控制反转",那么它究竟"反转"了什么?又是怎么体现在代码中的?
参考答案
在传统的程序设计中,当需要一个对象时,我们通常使用new操作符手动创建一个对象,并且在创建对象时需要手动管理对象所依赖的其他对象。但是,在IoC控制反转中,这个过程被翻转了过来,对象的创建和依赖关系的管理被转移到了IoC容器中。
具体来说,在IoC容器中,对象的创建和依赖关系的管理大体分为两个过程。
- 对象实例化:IoC容器负责创建需要使用的对象实例。这意味着如果一个对象需要使用其他对象,IoC容器会自动处理这些对象的创建,并且将它们注入到需要它们的对象中。
- 依赖注入:IoC容器负责把其他对象注入到需要使用这些依赖对象的对象中。这意味着我们不需要显式地在代码中声明依赖关系,IoC容器会自动将依赖注入到对象中,从而解耦了对象之间的关系。
这些过程大大简化了对象创建和依赖关系的管理,使代码更加易于维护和扩展。下面是一个简单的Java代码示例,展示了IoC控制反转在代码中的体现。
java
public class UserController {
private UserService userService; // 对象不用手动创建,由容器负责创建
public void setUserService(UserService userService) { // 不用手动管理依赖关系,由容器注入
this.userService = userService;
}
public void getUser() {
userService.getUser();
}
}在上面的示例中,UserController依赖于UserService,但是它并没有手动创建UserService对象,而是通过IoC容器自动注入。这种方式使得代码更加简洁,同时也简化了对象之间的依赖关系。
02|扩展Bean:如何配置constructor、property和init-method?
思考题
你认为通过构造器注入和通过Setter注入有什么异同?它们各自的优缺点是什么?
参考答案
先来说说它们之间的相同之处吧,首先它们都是为了把依赖的对象传递给类或对象,从而在运行时减少或消除对象之间的依赖关系,它们都可以用来注入复杂对象和多个依赖对象。此外Setter注入和构造器注入都可以用来缩小类与依赖对象之间的耦合度,让代码更加灵活、易于维护。
但同时它们之间之间也存在很多的差异。我把它们各自的优缺点整理成了一张表格放到了下面,你可以参考。
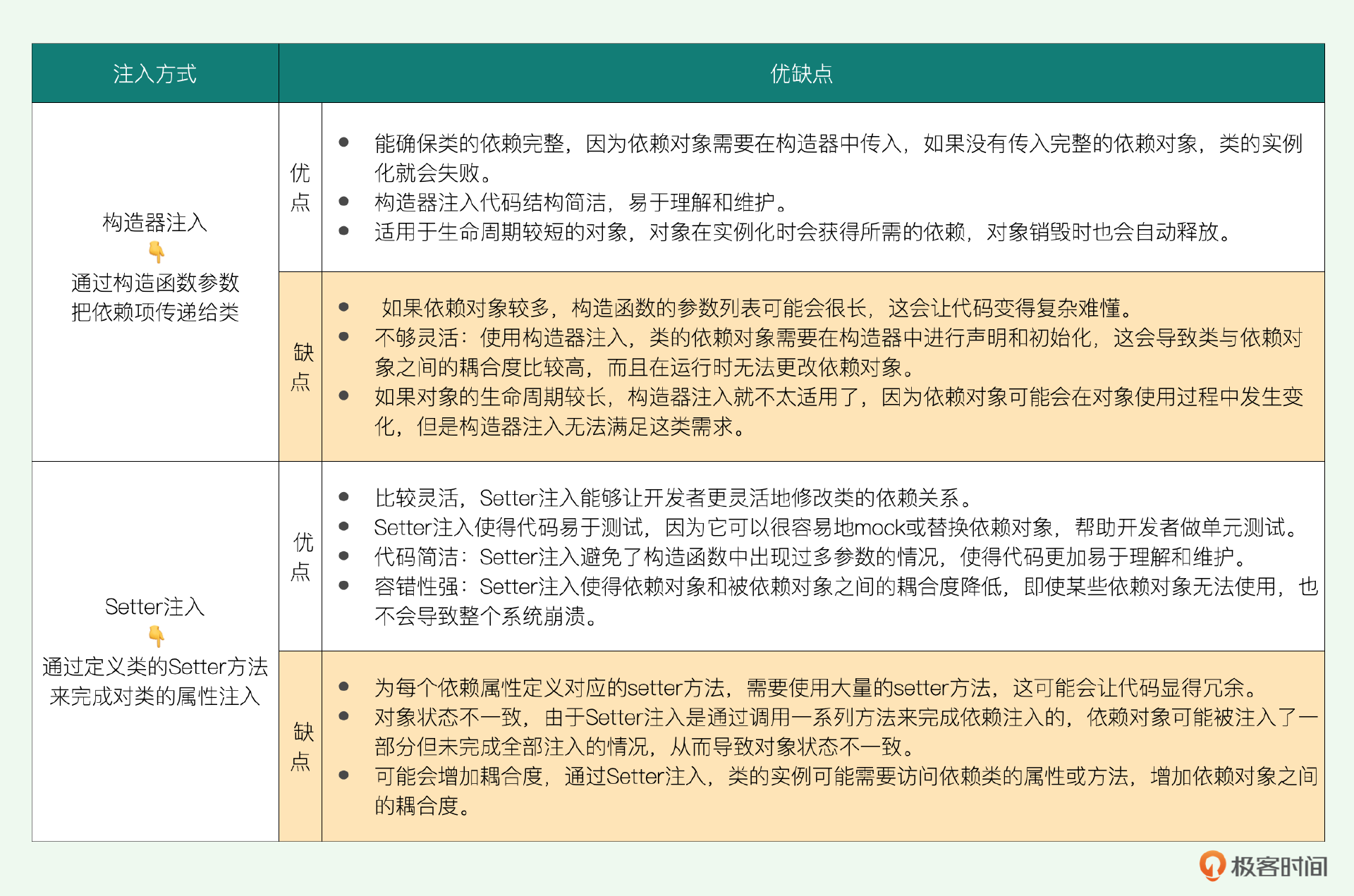
两者之间的优劣,人们有不同的观点,存在持久的争议。Spring团队本身的观点也在变,早期版本他们推荐使用Setter注入,Spring5之后推荐使用构造器注入。当然,我们跟随Spring团队,现在也是建议用构造器注入。
03|依赖注入:如何给Bean注入值并解决循环依赖问题?
思考题
你认为能不能在一个Bean的构造器中注入另一个Bean?
参考答案
可以在一个Bean的构造器中注入另一个Bean。具体的做法就是通过构造器注入或者通过构造器注解方式注入。
方式一:构造器注入
在一个Bean的构造器中注入另一个Bean,可以使用构造器注入的方式。例如:
java
public class ABean {
private final BBean Bbean;
public ABean(BeanB Bbean) {
this.Bbean = Bbean;
}
// ...
}
public class BBean {
// ...
}可以看到,上述代码中的 ABean 类的构造器使用了 BBean 类的实例作为参数进行构造的方式,通过这样的方式可以将 BBean 实例注入到 ABean 中。
方式二:构造器注解方式注入
在Spring中,我们也可以通过在Bean的构造器上增加注解来注入另一个Bean,例如:
java
public class ABean {
private final BBean Bbean;
@Autowired
public ABean(BBean Bbean) {
this.Bbean = Bbean;
}
// ...
}
public class BBean {
// ...
}在上述代码中,ABean 中的构造器使用了 @Autowired 注解,这个注解可以将 BBean 注入到 ABean 中。
通过这两种方式,我们都可以在一个Bean的构造器中注入另一个Bean,需要根据具体情况来选择合适的方式。通常情况下,通过构造器注入是更优的选择,可以确保依赖项的完全初始化,避免对象状态的污染。
对MiniSpring来讲,只需要做一点改造,在用反射调用Constructor的过程中处理参数的时候增加Bean类型的判断,然后对这个构造器参数再调用一次getBean()就可以了。
当然,我们要注意了。构造器注入是在Bean实例化过程中起作用的,一个Bean没有实例化完成的时候就去实例化另一个Bean,这个时候连"早期的毛胚Bean"都没有,因此解决不了循环依赖的问题。
04|增强IoC容器:如何让我们的Spring支持注解?
思考题
我们实现了Autowired注解,在现有框架中能否支持多个注解?
参考答案
如果这些注解是不同作用的,那么在现有架构中是可以支持多个注解并存的。比如要给某个属性上添加一个@Require注解,表示这个属性不能为空,我们来看下实现的思路。
MiniSpring中,对注解的解释是通过BeanPostProcessor来完成的。我们增加一个RequireAnnotationBeanPostProcessor类,在它的postProcessAfterInitialization()方法中解释这个注解,判断是不是为空,如果为空则抛出BeanException。
然后改写ClassPathXmlApplicationContext类中的registerBeanPostProcessors()方法,将这个新定义的beanpostprocessor注册进去。
java
beanFactory.addBeanPostProcessor(new
RequireAnnotationBeanPostProcessor());这样,在getBean()方法中就会在init-method被调用后用到这个RequireAnnotationBeanPostProcessor。
05|实现完整的IoC容器:构建工厂体系并添加容器事件
思考题
我们的容器以单例模式管理所有的bean,那么怎么应对多线程环境?
参考答案
第二节课我们曾经提到过这个问题。这里我们来概括一下。
我们将 singletons 定义为了一个ConcurrentHashMap,而且在实现 registrySingleton 时前面加了一个关键字synchronized。这一切都是为了确保在多线程并发的情况下,我们仍然能安全地实现对单例Bean的管理,无论是单线程还是多线程,我们整个系统里面这个Bean总是唯一的、单例的。------内容来自第 2 课
在单例模式下,容器管理所有的 Bean 时,多线程环境下可能存在线程安全问题。为了避免这种问题,我们可以采取一些措施。
- 避免共享数据
在单例模式下,所有的 Bean 都是单例的,如果 Bean 中维护了共享数据,那么就可能出现线程安全问题。为了避免共享数据带来的问题,我们可以采用一些方法来避免数据共享。例如,在 Bean 中尽量使用方法局部变量而不是成员变量,并且保证方法中不修改成员变量。
- 使用线程安全的数据结构
在单例模式下,如果需要使用一些共享数据的数据结构,建议使用线程安全的数据结构,比如 ConcurrentHashMap 代替 HashMap,使用 CopyOnWriteArrayList 代替 ArrayList 等。这些线程安全的数据结构能够确保在多线程环境下安全地进行并发读写操作。
- 同步
在单例模式下,如果需要操作共享数据,并且不能使用线程安全的数据结构,那么就需要使用同步机制。可以通过 synchronized 关键字来实现同步,也可以使用一些更高级的同步机制,例如 ReentrantLock、ReadWriteLock 等。
需要注意的是,使用同步机制可能会影响系统性能,并且容易出现死锁等问题,所以需要合理使用。
- 使用ThreadLocal
如果我们需要在多线程环境下共享某些数据,但是又想保证数据的线程安全性,可以使用 ThreadLocal 来实现。ThreadLocal 可以保证每个线程都拥有自己独立的数据副本,从而避免多个线程对同一数据进行竞争。
综上所述,在单例模式下,为了避免多线程环境下的线程安全问题,我们需要做好线程安全的设计工作,避免共享数据,选用线程安全的数据结构,正确使用同步机制,以及使用ThreadLocal等方法保证数据的线程安全性。