在大模型快速演进的今天,Java 开发者同样希望"开箱即用"地接入各类模型服务。Spring 官方推出的 Spring AI,已经为 Java / Spring Boot 应用提供了一套统一、优雅的 AI 抽象;而在国内模型生态中,如何更好地对接阿里云通义(Qwen)与灵积平台(DashScope),则是 Spring AI Alibaba 重点解决的问题。
本文基于仓库中的 spring_ai_alibaba-demo 子项目,从真实代码 出发,带你一起拆解:如何用 Spring AI + Spring AI Alibaba 的生态,在本地通过 Ollama 跑 Qwen3 模型,并逐步扩展到 RAG、工具调用和 Graph 工作流。
GitHub 项目地址:https://github.com/zhouByte-hub/java-ai/tree/main/spring_ai_alibaba-demo
欢迎 Star、Fork 和关注!文中所有代码都可以在该子项目中找到,更适合边读边跑。
面向读者:
- 已有 Spring Boot 基础,希望快速接入大模型的后端开发;
- 计划在本地或内网环境使用 Qwen3 等模型(通过 Ollama),但又希望未来平滑切到阿里云 DashScope;
- 想了解 Spring AI Alibaba 在 Graph、RAG、工具调用等场景中的作用和优势。
一、项目概览:Spring AI + Spring AI Alibaba 在这个 Demo 里的分工
spring_ai_alibaba-demo 是一个多模块示例工程,核心模块包括:
- 根模块
spring_ai_alibaba-demo:- 使用 Spring AI 的
spring-ai-starter-model-ollama接入本地 Ollama 服务; - 使用
spring-ai-starter-vector-store-pgvector集成 PostgreSQL + PgVector 做向量检索; - 通过
ChatModel/ChatClient演示基础对话、RAG、工具调用和记忆; - 通过依赖管理引入
spring-ai-alibaba-bom,为后续接入阿里云生态(包括 DashScope、Graph 等)奠定基础。
- 使用 Spring AI 的
- 子模块
alibaba-graph:- 使用
spring-ai-alibaba-graph-core演示基于大模型的有状态流程(StateGraph),依然以 Ollama 的 Qwen3 作为底层模型;
- 使用
- 子模块
alibaba-mcp-server/alibaba-mcp-client:- 使用 Spring AI 的 MCP 能力演示模型调用外部工具 / 资源的模式。
换句话说:
当前 Demo 没有直接连阿里云 DashScope ,而是选择在本地通过 Ollama 运行 Qwen3 模型 ;
但项目在依赖管理和结构设计上,已经完全站在 Spring AI Alibaba 生态 之上,随时可以切换到阿里云在线服务。
接下来,我们按"从简单到复杂"的顺序,依次看看各个模块是怎么搭建的。
二、依赖与环境:本地 Qwen3 + PgVector
先看根模块 spring_ai_alibaba-demo/pom.xml 中的关键部分:
xml
<properties>
<!-- 项目使用的 JDK 版本 -->
<java.version>17</java.version>
<!-- Spring AI Alibaba 相关依赖统一使用的版本 -->
<spring-ai-alibaba.version>1.1.0.0-M5</spring-ai-alibaba.version>
<!-- Spring AI 核心依赖统一使用的版本 -->
<spring-ai.version>1.1.0</spring-ai.version>
</properties>
<dependencies>
<!-- 基础 Web 能力:提供 Spring MVC / 内嵌容器等 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 通过 Spring AI 访问本地 Ollama 大模型服务 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- 向量数据库:Spring AI 对 PgVector 的封装 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
<!-- PostgreSQL JDBC 驱动,用于访问数据库 -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!-- Spring AI Alibaba 统一版本管理(国内生态相关依赖) -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Spring AI 官方 BOM(核心抽象与 Starter 的版本对齐) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>这里体现了几个核心设计理念:
- 通过 BOM (
spring-ai-alibaba-bom+spring-ai-bom)统一版本管理,避免各个 Starter 之间的版本地狱; - 实际运行时模型选择 Ollama,既方便本地开发调试,又可以在网络受限场景下顺畅运行;
- 未来如果要切到阿里云 DashScope,只需要:
- 打开已经写好的(但当前被注释掉的)
spring-ai-alibaba-starter-dashscope依赖; - 在配置文件里增加
spring.ai.dashscope.*对应配置,不需要改业务代码。
- 打开已经写好的(但当前被注释掉的)
环境配置:Ollama + Qwen3 + PgVector
spring_ai_alibaba-demo/src/main/resources/application.yaml 中:
yaml
server:
port: 8081 # 应用监听端口
servlet:
context-path: /alibaba-ai # 统一的服务前缀
spring:
ai:
ollama:
base-url: http://localhost:11434 # 本地 Ollama 服务地址
chat:
options:
model: qwen3:0.6b # 聊天用的 Qwen3 模型名称
temperature: 0.8 # 采样温度,越高回答越发散
embedding:
options:
model: qwen3-embedding:0.6b # 用于向量化的 embedding 模型
vectorstore:
pgvector:
dimensions: 1024 # 向量维度,需要与 embedding 模型输出一致
distance-type: cosine_distance # 相似度度量方式
initialize-schema: true # 启动时自动创建 PgVector 表结构
datasource:
url: jdbc:postgresql://<your-host>:5432/postgres?serverTimezone=Asia/Shanghai # PostgreSQL 连接串
username: postgres
password: **** # 建议通过环境变量或配置中心注入- Ollama 在本机 11434 端口提供服务,加载的是
qwen3:0.6b模型(本质上仍然是阿里云通义家族的模型,只是以本地方式运行); - Embedding 使用
qwen3-embedding:0.6b; - PgVector 存储维度设置为 1024,采用余弦相似度;
- 数据源配置指向 PostgreSQL,用于向量存储和(可选)对话记忆持久化。
三、基础对话:从 ChatModel 到 ChatClient
Demo 中提供了两种对话方式:直接使用 ChatModel,以及通过 ChatClient 封装后的高级用法。
3.1 使用 ChatModel 流式返回
ChatModelController:
java
@RestController
@RequestMapping("/chatModel")
public class ChatModelController {
// 注入由 Spring AI 自动装配的 Ollama ChatModel
private final ChatModel ollamaChatModel;
public ChatModelController(ChatModel ollamaChatModel) {
this.ollamaChatModel = ollamaChatModel;
}
@GetMapping("/chat")
public Flux<String> chat(@RequestParam("message") String message) {
// message:用户输入的自然语言问题
return ollamaChatModel.stream(new Prompt(message)) // 以流式方式调用大模型
.map(ChatResponse::getResult) // 提取每个增量响应的结果对象
.mapNotNull(result -> result.getOutput().getText()); // 只保留最终输出的文本内容
}
}ChatModel由spring-ai-starter-model-ollama自动装配,底层指向本地 Qwen3 模型;.stream(...)返回的是一个 响应式 Flux,可以在前端按 token/片段逐步渲染;- 控制器本身和普通 Spring Web 控制器没有本质差别,学习成本非常低。
3.2 使用 ChatClient 提升可用性
ChatClientController:
java
@RestController
@RequestMapping("/chatClient")
public class ChatClientController {
// 基于 ChatModel 封装的高级客户端,后续可以挂接 Adviser、工具等能力
private final ChatClient ollamaChatClient;
public ChatClientController(ChatClient ollamaChatClient) {
this.ollamaChatClient = ollamaChatClient;
}
@GetMapping("/chat")
public Flux<String> stream(@RequestParam("message") String message) {
// 使用最简单的 Prompt,直接将用户输入交给大模型,并以流式方式返回结果
return ollamaChatClient
.prompt(new Prompt(message)) // 构造 Prompt 对象
.stream() // 流式调用
.content(); // 提取文本内容
}
@GetMapping("/prompt")
public Flux<String> prompt() {
PromptTemplate template = PromptTemplate.builder()
.template("请用简短中文回答:{question}") // 模板中定义占位符 {question}
.variables(Map.of()) // 这里可以预先声明变量,也可以在 create 时传入
.build();
// 使用实际问题填充模板变量
Prompt prompt = template.create(Map.of("question", "Spring AI Alibaba 有什么特点?"));
return ollamaChatClient.prompt(prompt).stream().content();
}
}和 ChatModel 相比,ChatClient 的优势在于:
- 提供链式 API:
.prompt().call()/stream(),更易读; - 更容易挂接 Adviser(记忆、RAG、工具等),形成统一调用入口;
- 在需要多轮交互、上下文管理时更易扩展。
在 OllamaConfig 中,Demo 还展示了如何为 ChatClient 挂接记忆 Adviser,后面章节会展开。
四、对话记忆:内存版与可扩展版
实际业务中,一个"傻傻忘记前文"的大模型体验非常差。Demo 中给出了两种记忆实现方式。
4.1 简单内存记忆:SimpleMemories
java
@Component
public class SimpleMemories implements ChatMemory {
private static final Map<String, List<Message>> MEMORIES_CACHE = new HashMap<>();
@Override
public void add(String conversationId, List<Message> messages) {
// conversationId:会话标识;messages:本轮新增的消息列表
List<Message> memories = MEMORIES_CACHE.getOrDefault(conversationId, new ArrayList<>());
if (messages != null && !messages.isEmpty()) {
memories.addAll(messages);
}
MEMORIES_CACHE.put(conversationId, memories);
}
@Override
public List<Message> get(String conversationId) {
// 根据会话 ID 取出该会话的历史消息
return MEMORIES_CACHE.getOrDefault(conversationId, new ArrayList<>());
}
@Override
public void clear(String conversationId) {
// 清空某个会话的记忆
List<Message> messages = MEMORIES_CACHE.get(conversationId);
if (messages != null) {
messages.clear();
}
}
}- 通过
conversationId区分不同会话; - 适合 Demo、PoC 或对可靠性要求不高的场景;
- 结合
MessageChatMemoryAdvisor可以自动把历史消息注入到当前 Prompt 中。
4.2 Adviser 方式:MemoriesAdviser
java
@Component
public class MemoriesAdviser implements BaseAdvisor {
private static final Map<String, List<Message>> MEMORIES = new HashMap<>();
// 用于在 ChatClient 的上下文中标识当前会话 ID 的 key
private static final String CHAT_MEMORIES_SESSION_ID = "chat_memories_session_id";
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 从上下文中读取会话 ID,并取出其历史消息
String sessionId = request.context().get(CHAT_MEMORIES_SESSION_ID).toString();
List<Message> messages = MEMORIES.getOrDefault(sessionId, new ArrayList<>());
// 当前请求的消息放到历史消息后面,一起交给大模型
messages.addAll(request.prompt().getInstructions());
Prompt prompt = request.prompt().mutate().messages(messages).build();
return request.mutate().prompt(prompt).build();
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
// 把本次大模型回复写回到对应会话的记忆中
AssistantMessage output = response.chatResponse().getResult().getOutput();
String sessionId = response.context().get(CHAT_MEMORIES_SESSION_ID).toString();
List<Message> messages = MEMORIES.getOrDefault(sessionId, new ArrayList<>());
messages.add(output);
MEMORIES.put(sessionId, messages);
return response;
}
}- 在
before中把历史消息 + 当前消息拼成一个新的 Prompt; - 在
after中把模型回复写回内存; - 通过在
ChatClient构建时添加defaultAdvisors(memoriesAdvisor),即可对所有请求启用记忆能力。
进一步,你可以把 DataBaseChatMemoryRepository 补充完整,将消息写入数据库,实现持久化对话记忆。
五、RAG:Qwen3 + PgVector 的检索增强
RAG(Retrieval Augmented Generation)是典型的企业级能力,本 Demo 通过 RagChatClientController 进行演示。
5.1 向量入库:TokenTextSplitter + PgVectorStore
java
@RestController
@RequestMapping("/rag")
public class RagChatClientController {
private final ChatClient ragChatClient;
private final PgVectorStore pgVectorStore;
public RagChatClientController(ChatClient ragChatClient, PgVectorStore pgVectorStore) {
this.ragChatClient = ragChatClient;
this.pgVectorStore = pgVectorStore;
}
@GetMapping("/embedding")
public void embeddingContent(@RequestParam("message") String message) {
// message:待向量化的原始文本内容
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(50) // 每个分片的最大 token 数
.withKeepSeparator(true) // 是否保留分隔符(如换行符)
.withMaxNumChunks(1024) // 单次允许生成的最大分片数
.withMinChunkLengthToEmbed(20) // 小于该长度的分片不入库,避免噪声
.withMinChunkSizeChars(10) // 切分时的最小字符数,避免切得过碎
.build();
List<Document> docs = splitter.split(Document.builder().text(message).build()); // 将文本切分为多个 Document
pgVectorStore.add(docs); // 写入 PgVector 向量库
}
}TokenTextSplitter基于 token 切分文档,避免切得过碎或过长;PgVectorStore.add将切分后的文档写入 PostgreSQL + PgVector;- 真实项目中可把
/embedding换成异步批处理任务。
5.2 RAG 对话:RetrievalAugmentationAdvisor
java
@Configuration
public class VectorChatClientConfig {
@Bean("ragChatClient")
public ChatClient ragChatClient(ChatModel chatModel, VectorStore vectorStore) {
VectorStoreDocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore) // 具体使用的向量库实现,这里是 PgVector
.topK(3) // 每次检索返回相似度最高的前 3 条文档
.similarityThreshold(0.5) // 相似度阈值,小于该值的文档会被过滤掉
.build();
RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever) // 指定文档检索器
.order(0) // Adviser 执行顺序,越小越先执行
.build();
return ChatClient.builder(chatModel)
.defaultAdvisors(advisor) // 默认启用 RAG 能力
.build();
}
}RetrievalAugmentationAdvisor会在每次请求前,先到向量库检索相关文档;- 然后把检索结果作为"系统提示词"或"上下文"塞给 Qwen3 模型;
- 对你来说,只需调用
ragChatClient.prompt().user(question).call(),就能得到"带知识库"的回答。
六、工具调用:用 @Tool 让模型调用你的 Java 方法
在很多场景中,大模型需要调用业务系统的 API 才能完成任务。Spring AI 提供了 @Tool 注解,Demo 中的 ZoomTool 便是一个简单示例。
6.1 定义工具:ZoomTool
java
@Component
public class ZoomTool {
@Tool(description = "通过时区 ID 获取当前时间")
public String getTimeByZone(@ToolParam(description = "时区 ID,比如 Asia/Shanghai") String zone) {
// zone:时区 ID,示例:Asia/Shanghai、Europe/Berlin
ZoneId zoneId = ZoneId.of(zone);
ZonedDateTime now = ZonedDateTime.now(zoneId);
return DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").format(now); // 返回格式化后的时间字符串
}
}6.2 将工具挂到 ChatClient 上
java
@Configuration
public class ToolChatClientConfig {
@Bean("toolChatClient")
public ChatClient toolChatClient(ChatModel ollamaChatModel, ZoomTool zoomTool) {
// ollamaChatModel:底层使用的 Qwen3 模型;zoomTool:提供获取时间的业务工具
return ChatClient.builder(ollamaChatModel)
.defaultSystem(this.systemPrompt()) // 设置默认的系统提示词,统一咖啡馆背景
.defaultTools(zoomTool) // 将 ZoomTool 注册为可调用的工具
.build();
}
private String systemPrompt() {
Map<String, Object> vars = new HashMap<>();
vars.put("AMERICAN", "1-3"); // 美式咖啡制作时间(分钟)
vars.put("LATTE", "2"); // 拿铁咖啡制作时间(分钟)
vars.put("TIME_ZONE", "Asia/Shanghai"); // 默认时区 ID
SystemPromptTemplate tpl = SystemPromptTemplate.builder()
.template("欢迎光临 ZhouByte咖啡馆,... 默认时区:{TIME_ZONE}") // 系统提示词模板
.variables(vars) // 绑定上面的变量
.build();
return tpl.render(); // 渲染出包含具体变量值的系统提示词
}
}对应的 Controller:
java
@RestController
@RequestMapping("/tool")
public class ToolChatController {
private final ChatClient toolChatClient;
public ToolChatController(ChatClient toolChatClient) {
this.toolChatClient = toolChatClient;
}
@GetMapping("/chat")
public Flux<String> chat(@RequestParam("message") String message) {
return toolChatClient
.prompt() // 创建一次新的对话请求
.user(message) // 添加一条用户消息
.stream() // 流式调用大模型
.content(); // 只提取文本内容返回
}
}- 模型可以在需要时自动调用
getTimeByZone,返回指定时区时间; - 你只需要编写普通的 Java 方法,剩下的交给 Spring AI 的工具调用机制。
七、Alibaba Graph 子项目:有状态工作流编排
spring_ai_alibaba-demo/alibaba-graph 子项目使用 spring-ai-alibaba-graph-core 演示了如何构建大模型工作流。
7.1 定义 Graph:StateGraph + CompiledGraph
GraphConfig 中:
java
@Configuration
public class GraphConfig {
@Bean("quickStartGraph")
public CompiledGraph quickStartGraph() throws GraphStateException {
// "quickStartGraph":图名称;后面的 Map 用于定义状态 key 的合并策略
StateGraph graph = new StateGraph("quickStartGraph", () -> Map.of(
"input", new ReplaceStrategy(), // 多次写入时,后写入的值覆盖之前的值
"output", new ReplaceStrategy()
));
graph.addNode("node1", AsyncNodeAction.node_async(state -> {
// node1:设置初始 input 和 output
return Map.of("input", "graphConfig_addNode", "output", "graphConfig_output");
}));
graph.addNode("node2", AsyncNodeAction.node_async(state -> {
// node2:模拟业务处理,将 input 改为 ZhouByte
return Map.of("input", "ZhouByte", "output", "EMPTY");
}));
// 定义执行顺序:START -> node1 -> node2 -> END
graph.addEdge(StateGraph.START, "node1")
.addEdge("node1", "node2")
.addEdge("node2", StateGraph.END);
return graph.compile();
}
}StateGraph描述节点、边和状态合并策略;AsyncNodeAction封装每个节点的执行逻辑;compile()得到可执行的CompiledGraph。
7.2 调用 Graph:WebFlux + 流式输出
GraphController:
java
@RestController
@RequestMapping("/v1")
public class GraphController {
@Resource
private CompiledGraph quickStartGraph;
@GetMapping("/graph")
public Flux<String> startGraph() {
// 这里传入空的初始状态 Map,按定义好的 StateGraph 顺序执行
return quickStartGraph.stream(Map.of())
.map(NodeOutput::toString); // 将每个节点的输出对象转换为字符串返回
}
}- 使用 WebFlux +
Flux<NodeOutput>将节点执行结果流式返回; - 通过
RunnableConfig.builder().threadId(conversationId)还可以实现"带会话 ID 的工作流",类似有状态 Agent。
7.3 quickStartGraph 执行流程图
结合上面的 GraphConfig 和 GraphController,/v1/graph 接口整体执行流程可以用下面这张流程图来表示(以 GitHub 为例,可以直接渲染 Mermaid):
HTTP 请求:GET /alibaba-graph/v1/graph GraphController.startGraph() CompiledGraph.stream(Map.of()) StateGraph.START 节点 node1
input = graphConfig_addNode
output = graphConfig_output 节点 node2
input = ZhouByte
output = EMPTY StateGraph.END Flux 流式返回
- 从
GraphController.startGraph()开始,调用CompiledGraph.stream(Map.of())启动图的执行; - 图从
StateGraph.START出发,依次流经node1、node2,最终到达StateGraph.END; - 每个节点都会向全局状态写入
input/output等字段,并以Flux<NodeOutput>的形式逐步返回给调用方。
7.4 多条件分支 Graph 示例(addConditionalEdges)
在实际业务中,Graph 往往不只是线性顺序,还会根据状态进行分支判断。spring-ai-alibaba-graph-core 提供了 addConditionalEdges,可以基于当前 OverAllState 计算「条件标签」,再根据标签跳转到不同节点。
下面是一个简化的「评分决策」示例,根据 score 分数分别走向通过 / 复核 / 拒绝三条路径:
java
@Configuration
public class ConditionalGraphConfig {
@Bean("scoreDecisionGraph")
public CompiledGraph scoreDecisionGraph() throws GraphStateException {
StateGraph graph = new StateGraph("scoreDecisionGraph", () -> Map.of(
"score", new ReplaceStrategy(), // 保存当前评分
"result", new ReplaceStrategy() // 保存决策结果
));
// 读取或设置评分(示例中从 state 中读取,实际可由外部请求传入)
graph.addNode("checkScore", AsyncNodeAction.node_async(state -> {
Integer score = (Integer) state.value("score").orElse(75); // 默认 75 分
return Map.of("score", score);
}));
// 三个业务分支节点:通过 / 复核 / 拒绝
graph.addNode("pass", AsyncNodeAction.node_async(state ->
Map.of("result", "PASS")));
graph.addNode("review", AsyncNodeAction.node_async(state ->
Map.of("result", "REVIEW")));
graph.addNode("reject", AsyncNodeAction.node_async(state ->
Map.of("result", "REJECT")));
// 起点先进入评分检查节点
graph.addEdge(StateGraph.START, "checkScore");
// 多条件边:根据 score 返回不同的"标签",再由 mappings 决定下一跳节点
graph.addConditionalEdges("checkScore",
AsyncEdgeAction.edge_async(state -> {
int score = (Integer) state.value("score").orElse(0);
if (score >= 80) {
return "PASS";
}
if (score >= 60) {
return "REVIEW";
}
return "REJECT";
}),
Map.of(
"PASS", "pass",
"REVIEW", "review",
"REJECT", "reject"
)
);
// 三个结果节点最终都指向 END
graph.addEdge("pass", StateGraph.END);
graph.addEdge("review", StateGraph.END);
graph.addEdge("reject", StateGraph.END);
return graph.compile();
}
}这段代码中,addConditionalEdges 的三个参数含义是:
sourceId:条件边的源节点 ID,这里是"checkScore";AsyncEdgeAction:根据当前OverAllState计算条件标签,这里返回"PASS"/"REVIEW"/"REJECT";mappings:标签与目标节点 ID 的映射,例如"PASS" -> "pass",即当标签为"PASS"时跳到pass节点。
对应的执行流程,可以画成如下多分支流程图:
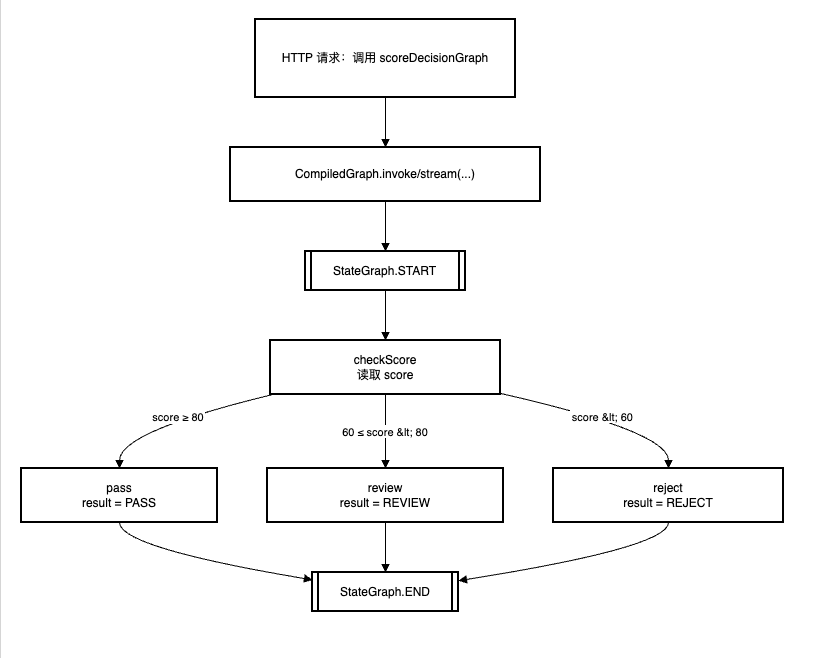
在真实项目中,你可以把 score 换成「风控评分」「召回结果命中情况」「用户画像标签」等任意业务信号,通过 addConditionalEdges 把复杂分支逻辑从代码 if/else 中抽离出来,统一放在 Graph 层管理。
在这个子项目中,Graph 本身是"流程层",可以在节点里调用 Spring AI / Spring AI Alibaba 的各种模型与工具,实现复杂的多步推理与业务编排。
八、如何从本地 Ollama 平滑切到阿里云 DashScope
虽然当前 Demo 主要跑在本地 Ollama 上,但由于使用了 Spring AI + Spring AI Alibaba 的统一抽象,切换到阿里云 DashScope 十分简单:
- 在
pom.xml中启用 DashScope Starter(示例中已给出注释代码):
xml
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0-M5</version>
</dependency>- 在配置文件中增加 DashScope 的配置(示例):
yaml
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY} # 从环境变量或配置中心读取 DashScope 的 API Key
endpoint: https://dashscope.aliyuncs.com
chat:
options:
model: qwen-plus # 使用的通义千问在线模型
temperature: 0.8 # 采样温度
max-tokens: 2048 # 单次回答的最大 token 数- 将原来的
ChatModel注入点从 Ollama 替换为 DashScope 对应的 Bean(通常只需要调整配置,不改业务代码)。
凭借 Spring AI 的抽象层,你可以:
- 开发阶段:本地跑 Qwen3(Ollama),成本低、调试快;
- 生产阶段:切到云上 DashScope(Qwen-Max / Qwen-Plus 等),享受更强算力和更高可用性;
- 中长期:在 Spring AI Alibaba 的生态内同时兼容多家国内模型厂商。
九、实践建议与最佳实践
-
配置管理
- API Key 使用环境变量或配置中心(Nacos、KMS 等),避免硬编码;
- Ollama、DashScope 的模型名称、温度等参数尽量抽到配置文件中。
-
错误处理与重试
- 针对网络异常、超时、限流等场景做兜底和重试策略;
- 对外暴露的接口统一封装错误返回,避免直接把底层错误抛给前端。
-
性能与成本
- 在高并发场景建议优先使用流式输出 + 前端增量渲染;
- RAG 中控制 TopK、相似度阈值和切分策略,避免向量库"爆炸"。
-
代码结构
- 将
ChatClient配置、Graph 配置等放在独立的config包中,业务层只关心接口调用; - 工具方法使用
@Tool暴露,便于模型统一管理和调用。
- 将
-
版本与升级
- Spring AI Alibaba 当前仍以 Milestone 版本为主(如
1.1.0.0-M5),升级前建议阅读 release notes; - 保持对
spring-ai-bom/spring-ai-alibaba-bom的依赖,让升级尽量在 BOM 层完成。
- Spring AI Alibaba 当前仍以 Milestone 版本为主(如
十、总结与展望
基于 spring_ai_alibaba-demo 子项目,我们实际体验了一次:
- 如何用 Spring AI + Spring AI Alibaba BOM 快速接入本地 Qwen3(Ollama);
- 如何在同一套抽象下串联起对话、记忆、RAG、工具调用;
- 如何通过
spring-ai-alibaba-graph-core构建基于大模型的有状态工作流; - 以及如何在不改业务代码的前提下,为未来切换到阿里云 DashScope 留出空间。
对 Spring 开发者来说,这套体系最大的价值在于:
- 统一抽象:不同模型供应商之间切换成本极低;
- 生态完善:兼容 Spring Boot、WebFlux、向量库、MCP、Graph 等丰富组件;
- 本地 + 云端双模:既能在本地快速迭代,又能无缝迁移到云上生产环境。
再次附上示例子项目 GitHub 地址,欢迎你亲手跑一跑代码、提 Issue、点 Star:
GitHub 项目地址:https://github.com/zhouByte-hub/java-ai/tree/main/spring_ai_alibaba-demo