概述
Keepalived是一个基于VRRP协议 (虚拟冗余路由协议)来实现的LVS服务 高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息(心跳检测,heartbeat)给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
Keepalived的作用是检测服务器的状态,如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中。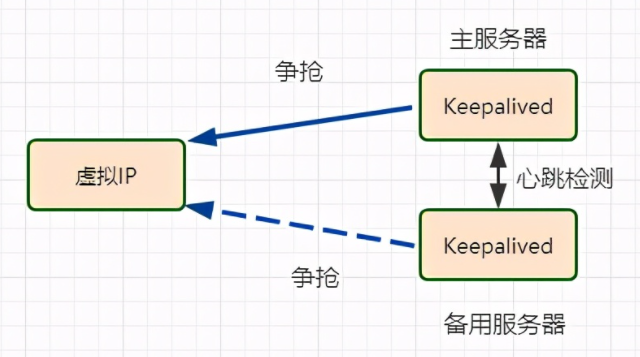
一、keepalived安装
[root@web1 ~]# yum install -y epel-release
[root@web1 ~]# yum install keepalived nginx配置并启动
[root@web2 keepalived]# echo web2 > /usr/share/nginx/html/index.html
[root@web2 keepalived]# systemctl enable --now keepalived.service nginx.service 验证
[root@web1 keepalived]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:c8:dc:33 brd ff:ff:ff:ff:ff:ff
inet 192.168.115.111/24 brd 192.168.115.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.115.250/32 scope global ens33
##停掉master查看backup
[root@web1 keepalived]# systemctl stop keepalived.service
[root@web2 keepalived]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:8a:4a:79 brd ff:ff:ff:ff:ff:ff
inet 192.168.115.112/24 brd 192.168.115.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.115.250/32 scope global ens33二、配置文件
global_defs {
notification_email { #指定keepalived在发生切换时需要发送email到的对象,一行一个
sysadmin@fire.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #指定发件人
smtp_server localhost #指定smtp服务器地址
smtp_connect_timeout 30 #指定smtp连接超时时间
router_id LVS_DEVEL #运行keepalived机器的一个标识
}
vrrp_sync_group VG_1{ #监控多个网段的实例
group {
inside_network #实例名
outside_network
}
notify_master /path/xx.sh #指定当切换到master时,执行的脚本
notify_backup /path/xx.sh #指定当切换到backup时,执行的脚本
notify_fault "path/xx.sh VG_1" #故障时执行的脚本
notify /path/xx.sh
smtp_alert #使用global_defs中提供的邮件地址和smtp服务器发送邮件通知
}Keepalived在转换状态时会依照状态来呼叫:
-
当进入Master状态时会呼叫notify_master
-
当进入Backup状态时会呼叫notify_backup
-
当发现异常情况时进入Fault状态呼叫notify_fault
vrrp_instance inside_network {
state BACKUP #指定那个为master,那个为backup,如果设置了nopreempt这个值不起作用,主备靠priority决定
interface eth0 #设置实例绑定的网卡 VRRP心跳包从哪块网卡发出
dont_track_primary #忽略vrrp的interface错误(默认不设置)
track_interface{ #设置额外的监控,里面那个网卡出现问题都会切换
eth1
eth2
}
mcast_src_ip #发送多播包的地址,如果不设置默认使用绑定网卡的primary ip
garp_master_delay #在切换到master状态后,延迟进行gratuitous ARP请求
virtual_router_id 50 #VPID标记 相同VRID的LVS属于同一组,根据优先级选举出一个主
priority 99 #优先级,高优先级竞选为master
advert_int 10 #检查间隔,默认1秒 VRRP心跳包(报文)的发送周期,单位为s 组播信息发送间隔,两个节点设置必须一样(实际并不一定完全是10秒,测试结果是小于10秒的随机值)
nopreempt #设置为不抢占 注:这个配置只能设置在backup主机上,而且这个主机优先级要比另外一台高首先nopreemt必须在state为BACKUP的节点上才生效(因为是BACKUP节点决定是否来成为MASTER的),其次要实现类似于关闭auto failback的功能需要将所有节点的state都设置为BACKUP,或者将master节点的priority设置的比BACKUP低。我个人推荐使用将所有节点的state都设置成BACKUP并且都加上nopreempt选项,这样就完成了关于autofailback功能,当想手动将某节点切换为MASTER时只需去掉该节点的nopreempt选项并且将priority改的比其他节点大,然后重新加载配置文件即可(等MASTER切过来之后再将配置文件改回去再reload一下)。
preempt_delay #抢占延时,默认5分钟
debug #debug级别
authentication { #设置认证
auth_type PASS #认证方式
auth_pass 111111 #认证密码(密码只识别前8位)
}
virtual_ipaddress { #设置vip
192.168.202.200
}
}
virtual_server 192.168.202.200 23 {
delay_loop 6 #健康检查时间间隔(实际并不一定完全是6秒,测试结果是小于6秒的随机值?)
lb_algo rr #lvs调度算法rr|wrr|lc|wlc|lblc|sh|dh
lb_kind DR #负载均衡转发规则NAT|DR|TUN
persistence_timeout 5 #会话保持时间
protocol TCP #使用的协议
persistence_granularity <NETMASK> #lvs会话保持粒度
virtualhost <string> #检查的web服务器的虚拟主机(host:头)
sorry_server<IPADDR> <port> #备用机,所有realserver失效后启用
real_server 192.168.200.5 23 {
weight 1 #默认为1,0为失效
inhibit_on_failure #在服务器健康检查失效时,将其设为0,而不是直接从ipvs中删除
notify_up <string> | <quoted-string> #在检测到server up后执行脚本
notify_down <string> | <quoted-string> #在检测到server down后执行脚本
TCP_CHECK {
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 3 #重连间隔时间
connect_port 23 #健康检查的端口的端口
bindto <ip> #检查的IP地址
}
HTTP_GET | SSL_GET{
url{ #检查url,可以指定多个
path /
digest <string> #检查后的摘要信息
status_code 200 #检查的返回状态码,301 302
}
connect_port <port>
bindto <IPADD>
connect_timeout 5
nb_get_retry 3
delay_before_retry 2
}
SMTP_CHECK{
host{
connect_ip <IP ADDRESS>
connect_port <port> #默认检查25端口
bindto <IP ADDRESS>
}
connect_timeout 5
retry 3
delay_before_retry 2
helo_name <string> | <quoted-string> #smtp helo请求命令参数,可选
}
MISC_CHECK{
misc_path <string> | <quoted-string> #外部脚本路径
misc_timeout #脚本执行超时时间
misc_dynamic #如设置该项,则退出状态码会用来动态调整服务器的权重,返回0 正常,不修改;返回1,检查失败,权重改为0;返回2-255,正常,权重设置为:返回状态码-2
}}
三、 其他配置项说明
keepalived 的核心就是将IPVS配置成高可用,生成ipvs规则来完成负载均衡效果。
-
virtual server (虚拟服务)的定义:
-
virtual_server IP port #定义虚拟主机IP地址及其端口
-
virtual_server fwmark int #ipvs的防火墙打标,实现基于防火墙的负载均衡集群
-
virtual_server group string #将多个虚拟服务器定义成组,将组定义成虚拟服务
-
lb_algo{rr|wrr|lc|wlc|lblc|lblcr} #定义LVS的调度算法
-
lb_kind {NAT|DR|TUN} #定义LVS的模型
-
presitence_timeout #定义支持持久连接的时长
-
protocol TCP #规则所能支持的协议
-
sorry_server #如果所有real_server都出现故障了,利用此返回信息
四、名词解释
虚拟路由器: 由一个Master路由器和多个Backup路由器组成。主机将虚拟路由器当作默认网关;
VRID :虚拟路由器的标识。有相同VRID的一组路由器构成一个虚拟路由器;
Master路由器:虚拟路由器中承担报文转发任务的路由器;
Backup路由器 :Master路由器出现故障时,能够代替Master路由器工作的路由器;
虚拟IP 地址:虚拟路由器的IP 地址。一个虚拟路由器可以拥有一个或多个IP地址;
IP地址拥有者: 接口IP地址与虚拟IP地址相同的路由器被称为IP地址拥有者;
虚拟MAC地址: 一个虚拟路由器拥有一个虚拟MAC地址。通常情况下,虚拟路由器回应ARP请求使用的是虚拟MAC地址,只有虚拟路由器做特殊配置的时候,才回应接口的真实MAC地址;
优先级 :VRRP根据优先级来确定虚拟路由器中每台路由器的地位;
非抢占方式 :如果Backup路由器工作在非抢占方式下,则只要Master路由器没有出现故障,Backup路由器即使随后被配置了更高的优先级也不会成为Master路由器;
抢占方式:如果Backup路由器工作在抢占方式下,当它收到VRRP报文后,会将自己的优先级与通告报文中的优先级进行比较。如果自己的优先级比当前的Master路由器的优先级高,就会主动抢占成为Master路由器;否则,将保持Backup状态
五、高阶使用
1、介绍
Keeaplived 主要有两种应用场景,一个是通过配置keepalived结合ipvs做到负载均衡(LVS+Keepalived) 。另一个是通过自身健康检查、资源接管功能做高可用(双机热备),实现故障转移。
以下内容主要针对Keepalived+MySQL双主实现双机热备为根据,主要讲解keepalived的状态转换通知功能,利用此功能可有效加强对MySQL数据库监控。
2、keepalived主要作用
keepalived采用VRRP(virtual router redundancy protocol),虚拟路由冗余协议,以软件的形式实现服务器热备功能。通常情况下是将两台linux服务器组成一个热备组(master-backup),同一时间热备组内只有一台主服务器(master)提供服务,同时master会虚拟出一个共用IP地址(VIP),这个VIP只存在master上并对外提供服务。如果keepalived检测到master宕机或服务故障,备服务器(backup)会自动接管VIP成为master,keepalived并将master从热备组移除,当master恢复后,会自动加入到热备组,默认再抢占成为master,起到故障转移功能。
3、工作在三层、四层和七层原理
Layer3: 工作在三层时,keepalived会定期向热备组中的服务器发送一个ICMP数据包,来判断某台服务器是否故障,如果故障则将这台服务器从热备组移除。
Layer4: 工作在四层时,keepalived以TCP端口的状态判断服务器是否故障,比如检测mysql 3306端口,如果故障则将这台服务器从热备组移除。
! Configuration File for keepalived
global_defs {
notification_email {
example@163.com
}
notification_email_from example@example.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MYSQL_HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 50
nopreempt #当主down时,备接管,主恢复,不自动接管
priority 100
advert_int 1
authentication {
auth_type PASS
ahth_pass 123
}
virtual_ipaddress {
192.168.1.200 #虚拟IP地址
}
virtual_server 192.168.1.200 3306 {
delay_loop 6
# lb_algo rr
# lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 192.168.1.201 3306 { #监控本机3306端口
weight 1
notify_down /etc/keepalived/kill_keepalived.sh #检测3306端口为down状态就执行此脚本(只有keepalived关闭,VIP才漂移 )
TCP_CHECK { #健康状态检测方式,可针对业务需求调整(TTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK)
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
#MISC_CHECK { ## 使用 MISC_CHECK 方式自定义脚本做健康检查
# misc_path "/etc/keepalived/check.sh" ## 检测脚本
# misc_timeout 10 ## 执行脚本的超时时间
# misc_dynamic ## 根据退出状态码动态调整服务器的权重
# }
}
}
Layer7 :工作在七层时,keepalived根据用户设定的策略判断服务器上的程序是否正常运行,如果故障则将这台服务器从热备组移除。
! Configuration File for keepalived
global_defs {
notification_email {
example@163.com
}
notification_email_from example@example.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MYSQL_HA
}
vrrp_script check_nginx {
script /etc/keepalived/check_nginx.sh #检测脚本
interval 2 #执行间隔时间
}
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 50
nopreempt #当主down时,备接管,主恢复,不自动接管
priority 100
advert_int 1
authentication {
auth_type PASS
ahth_pass 123
}
virtual_ipaddress {
192.168.1.200 #虚拟IP地址
}
track_script { #在实例中引用脚本
check_nginx
}
}
脚本内容如下:
# cat /etc/keepalived/check_nginx.sh
Count1=`netstat -antp |grep -v grep |grep nginx |wc -l`
if [ $Count1 -eq 0 ]; then
/usr/local/nginx/sbin/nginx
sleep 2
Count2=`netstat -antp |grep -v grep |grep nginx |wc -l`
if [ $Count2 -eq 0 ]; then
service keepalived stop
else
exit 0
fi
else
exit 0
fi
#也可以简单如下:
#!/bin/bash
[[ `ps -C nginx --no-header |wc -l` -eq 0 ]] && exit 1 || exit 0
# 如果没有nginx进程 返回错误状态1
#if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
# echo "$(date) nginx pid not found">>/etc/keepalived/keepalived.log
# #killall keepalived
#fi
#在keepalived主机中,运行如下脚本,用来检测本机的nginx进行状态
vim start_keepalived.sh
#!/bin/bash
while true
do
if pgrep nginx &> /dev/null;then
systemctl start keepalived
fi
sleep 3
done
#mysql 检测脚本如下:
#!/bin/bash
[[ `ps -C mysqld --no-header |wc -l` -eq 0 ]] && exit 1 || exit 0
# 如果没有nginx进程 返回错误状态1
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
echo "$(date) nginx pid not found">>/etc/keepalived/keepalived.log
killall keepalived
fi
4、健康状态检测方式
4.1 HTTP服务状态检测
HTTP_GET或SSL_GET { url { path /index.html #检测url,可写多个 digest 24326582a86bee478bac72d5af25089e #检测效验码 #digest效验码获取方法:genhash -s IP -p 80 -u http://IP/index.html status_code 200 #检测返回http状态码 } connect_port 80 #连接端口 connect_timeout 3 #连接超时时间 nb_get_retry 3 #重试次数 delay_before_retry 2 #连接间隔时间 }
4.2 TCP端口状态检测(使用TCP端口服务基本上都可以使用)
TCP_CHECK { connect_port 80 #健康检测端口,默认为real_server后跟端口 connect_timeout 5 nb_get_retry 3 delay_before_retry 3 }
4.3 邮件服务器SMTP检测
SMTP_CHECK { #健康检测邮件服务器smtp host { connect_ip connect_port } connect_timeout 5 retry 2 delay_before_retry 3 hello_name "mail.domain.com" }
4.4 用户自定义脚本检测real_server服务状态
MISC_CHECK { misc_path /script.sh #指定外部程序或脚本位置 misc_timeout 3 #执行脚本超时时间 !misc_dynamic #不动态调整服务器权重(weight),如果启用将通过退出状态码动态调整real_server权重值 # misc_dynamic ## 根据退出状态码动态调整服务器的权重 }
5、状态转换通知功能
keepalived主配置邮件通知功能,默认当real_server宕机或者恢复时才会发出邮件。有时我们更想知道keepalived的主服务器故障切换后,VIP是否顺利漂移到备服务器,MySQL服务器是否正常?那写个监控脚本吧,可以,但没必要,因为keepalived具备状态检测功能,所以我们直接使用就行了。
主配置默认邮件通知配置模板如下: global_defs # Block id { notification_email # To: { admin@example1.com ... } # From: from address that will be in header notification_email_from admin@example.com smtp_server 127.0.0.1 # IP smtp_connect_timeout 30 # integer, seconds router_id my_hostname # string identifying the machine, # (doesn't have to be hostname).
5.1 实例状态通知
a) notify_master :节点变为master时执行
b) notify_backup : 节点变为backup时执行
c) notify_fault : 节点变为故障时执行
5.2 虚拟服务器检测通知
a) notify_up : 虚拟服务器up时执行
b) notify_down : 虚拟服务器down时执行
示例: ! Configuration File for keepalived global_defs { notification_email { example@163.com } notification_email_from example@example.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id MYSQL_HA } vrrp_instance VI_1 { state BACKUP interface eth1 virtual_router_id 50 nopreempt #当主down时,备接管,主恢复,不自动接管 priority 100 advert_int 1 authentication { auth_type PASS ahth_pass 123 } virtual_ipaddress { 192.168.1.200 } notify_master /etc/keepalived/to_master.sh notify_backup /etc/keepalived/to_backup.sh notify_fault /etc/keepalived/to_fault.sh } virtual_server 192.168.1.200 3306 { delay_loop 6 persistence_timeout 50 protocol TCP real_server 192.168.1.201 3306 { weight 1 notify_up /etc/keepalived/mysql_up.sh notify_down /etc/keepalived/mysql_down.sh TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } }
状态参数后可以是bash命令,也可以是shell脚本,内容根据自己需求定义,以上示例中所涉及状态脚本如下:
-
当服务器改变为主时执行此脚本
yum install -y sendmail mailx
systemctl enabled --now sendmailcat to_master.sh
#!/bin/bash Date=$(date +%F" "%T) IP=$(ifconfig eth0 |grep "inet addr" |cut -d":" -f2 |awk '{print $1}') Mail="z13516052620@163.com" echo "$Date $IP change to master." |mail -s "Master-Backup Change Status" $Mail
2.当服务器改变为备时执行此脚本
# cat to_backup.sh
#!/bin/bash
Date=$(date +%F" "%T)
IP=$(ifconfig eth0 |grep "inet addr" |cut -d":" -f2 |awk '{print $1}')
Mail="baojingtongzhi@163.com"
echo "$Date $IP change to backup." |mail -s "Master-Backup Change Status" $Mail3.当服务器改变为故障时执行此脚本
# cat to_fault.sh
#!/bin/bash
Date=$(date +%F" "%T)
IP=$(ifconfig eth0 |grep "inet addr" |cut -d":" -f2 |awk '{print $1}')
Mail="baojingtongzhi@163.com"
echo "$Date $IP change to fault." |mail -s "Master-Backup Change Status" $Mail 4.当检测TCP端口3306为不可用时,执行此脚本,杀死keepalived,实现切换
# cat mysql_down.sh
#!/bin/bash
Date=$(date +%F" "%T)
IP=$(ifconfig eth0 |grep "inet addr" |cut -d":" -f2 |awk '{print $1}')
Mail="baojingtongzhi@163.com"
pkill keepalived
echo "$Date $IP The mysql service failure,kill keepalived." |mail -s "Master-Backup MySQL Monitor" $Mail5.当检测TCP端口3306可用时,执行此脚本
# cat mysql_up.sh
#!/bin/bash
Date=$(date +%F" "%T)
IP=$(ifconfig eth0 |grep "inet addr" |cut -d":" -f2 |awk '{print $1}')
Mail="baojingtongzhi@163.com"
echo "$Date $IP The mysql service is recovery." |mail -s "Master-Backup MySQL Monitor" $Mail六、项目实际中配置
检测nginx配置
global_defs {
router_id master
enable_script_security
}
vrrp_script check_nginx {
script /etc/keepalived/check_nginx.sh
interval 1
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface eth2
virtual_router_id 201
priority 100
advert_int 3
authentication {
auth_type PASS
auth_pass 1114
}
track_script {
check_nginx
}
virtual_ipaddress {
10.239.167.8
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 202
priority 100
advert_int 3
authentication {
auth_type PASS
auth_pass 1114
}
track_script {
check_nginx
}
virtual_ipaddress {
10.1.19.105
}
}2
! Configuration File for keepalived
global_defs {
router_id LVS_HTTP
script_user root
}
#vrrp_script check_keepalived {
# script "/etc/keepalived/check_keepalived.sh"
# interval 2
# weight 3
#}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 21
nopreempt
priority 130
advert_int 3
authentication {
auth_type PASS
auth_pass 1111
}
#track_script {
# check_keepalived
#}
virtual_ipaddress {
10.1.13.27/24
}
#notify_master "/etc/keepalived/master.sh ethxx" #切换主执行
#notify_backup "/etc/keepalived/slave.sh eth0" ##切换备执行
#notify_stop "/etc/keepalived/stop.sh eth0" ##
}
virtual_server 10.1.13.27 26000 { #设置虚拟服务器的 IP 和端口,用空格隔开
delay_loop 6 #设置运行情况检查时间,单位是秒
# lb_algo rr #负载调度算法(轮询)
# lb_kind DR #负载均衡机制(NAT、TUN、DR)
persistence_timeout 50 #会话保持时间(秒)
protocol TCP #转发协议类型
real_server 10.1.13.136 26000 { #配置服务节点
weight 90 #配置服务节点的权重
notify_down /etc/keepalived/failoverdb.sh #虚拟服务故障响应脚本
TCP_CHECK { #使用TCP_CHECK方式进行健康检查
connect_timeout 10 #10秒无响应即超时
delay_before_retry 3 #重试间隔时间
}
#MISC_CHECK { ## 使用 MISC_CHECK 方式自定义脚本做健康检查
# misc_path "/etc/keepalived/check.sh" ## 检测脚本
# misc_timeout 10 ## 执行脚本的超时时间
# misc_dynamic ## 根据退出状态码动态调整服务器的权重
# }
}
}