TL;DR
- 场景:解决去重/更新与按键求和两类常见"准实时明细表"需求。
- 结论:ReplacingMergeTree 用于按排序键去重/按版本取最新;SummingMergeTree 用于按排序键合并数值列之和,二者都在合并(merge)阶段生效,读即见最终结果需 SELECT ... FINAL。
- 产出:最小可跑示例(MRE)、OPTIMIZE/FINAL 使用时机、常见坑定位清单、回滚与数据修复脚本。

ReplacingMergeTree
简介
这个引擎是在MergeTree的基础上,添加了处理重复数据的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
特点
以下是扩写后的内容:
Repeater 去重机制详解
-
排序键作为唯一键
- 系统使用
ORDER BY子句中指定的列作为判断数据是否重复的唯一键。这些列的组合值相同时会被视为重复数据。 - 示例:如果设置
ORDER BY (user_id, event_time),那么具有相同用户ID和事件时间的数据将被视为重复。
- 系统使用
-
合并时触发的去重
- 去重操作仅在后台合并(Merge)数据文件时执行,不会在数据插入时立即处理。
- 这种设计避免了实时去重的性能开销,能够批量处理大量数据。
-
分区级别的去重范围
- 去重以数据分区(Partition)为单位进行,每个分区独立处理。
- 跨分区的重复数据不会被自动删除,例如上个月分区和本月分区可能存在重复数据。
- 应用场景:适合按时间分区的场景,保留历史分区数据完整性。
-
依赖预先排序的顺序
- 系统依赖数据已经按照
ORDER BY键预先排好顺序的特性来高效识别重复数据。 - 实现原理:利用已排序的数据可以线性扫描就能发现连续重复项,无需额外计算。
- 系统依赖数据已经按照
-
无版本号时的处理策略
- 如果没有配置版本号(ver)列:
- 保留重复项中的最后一行数据(按照物理存储顺序)
- 示例:对于3条重复记录A、B、C,最终保留C
- 如果没有配置版本号(ver)列:
-
有版本号时的处理策略
- 如果设置了版本号列:
- 系统会保留版本号最大的数据行
- 应用场景:可以实现乐观锁机制,例如用时间戳或版本号标记数据更新
- 示例:对于3条重复记录(ver=1)、(ver=3)、(ver=2),最终保留ver=3的记录
- 如果设置了版本号列:
案例
创建新表
sql
CREATE TABLE replace_table (
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, code)
PRIMARY KEY id;运行结果如下图所示: 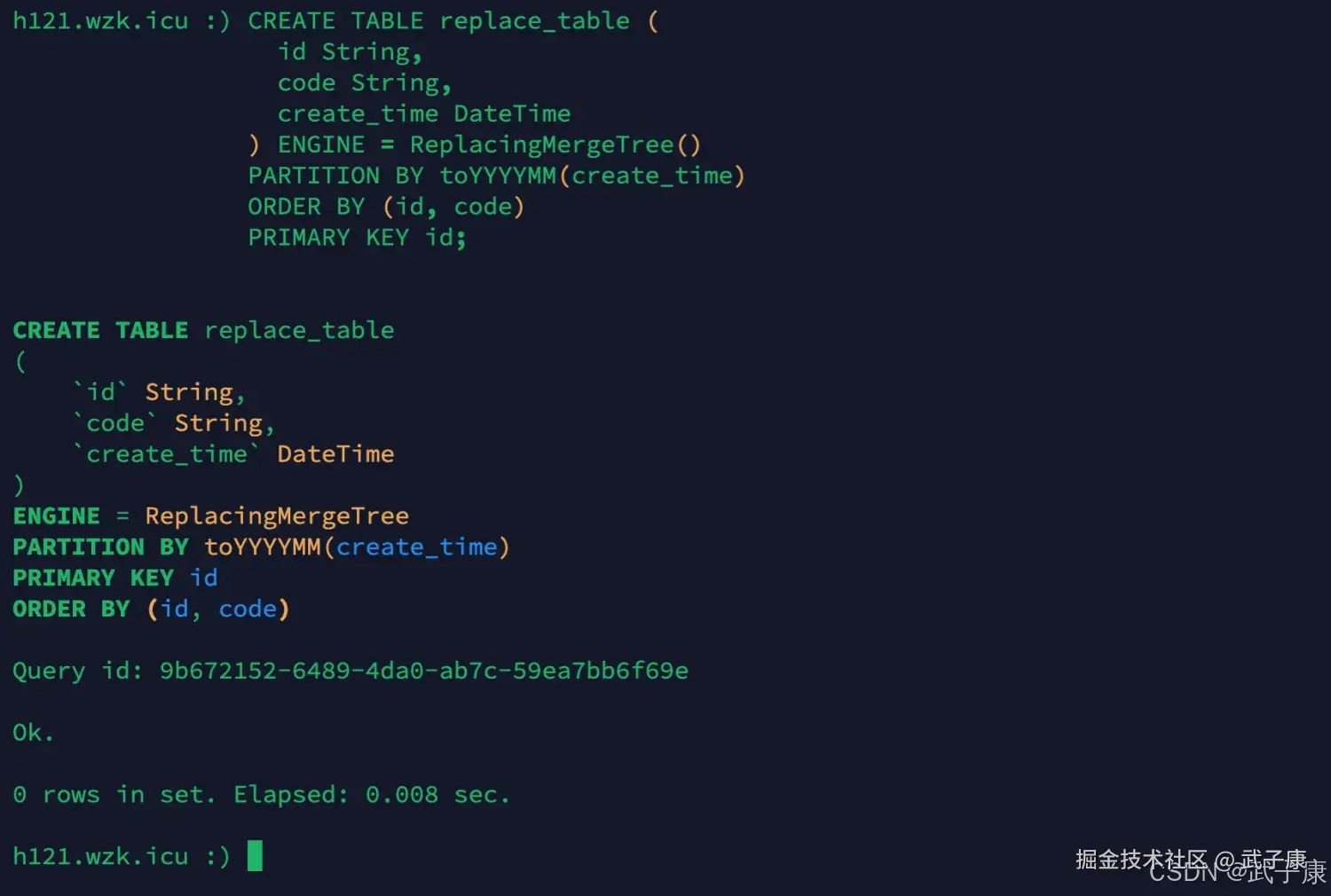
插入数据
sql
INSERT INTO replace_table VALUES ('A001', 'C1', '2024-08-01 08:00:00');
INSERT INTO replace_table VALUES ('A001', 'C1', '2024-08-02 08:00:00');
INSERT INTO replace_table VALUES ('A001', 'C8', '2024-08-03 08:00:00');
INSERT INTO replace_table VALUES ('A001', 'C9', '2024-08-04 08:00:00');
INSERT INTO replace_table VALUES ('A002', 'C2', '2024-08-05 08:00:00');
INSERT INTO replace_table VALUES ('A003', 'C3', '2024-08-06 08:00:00');运行结果如下所示: 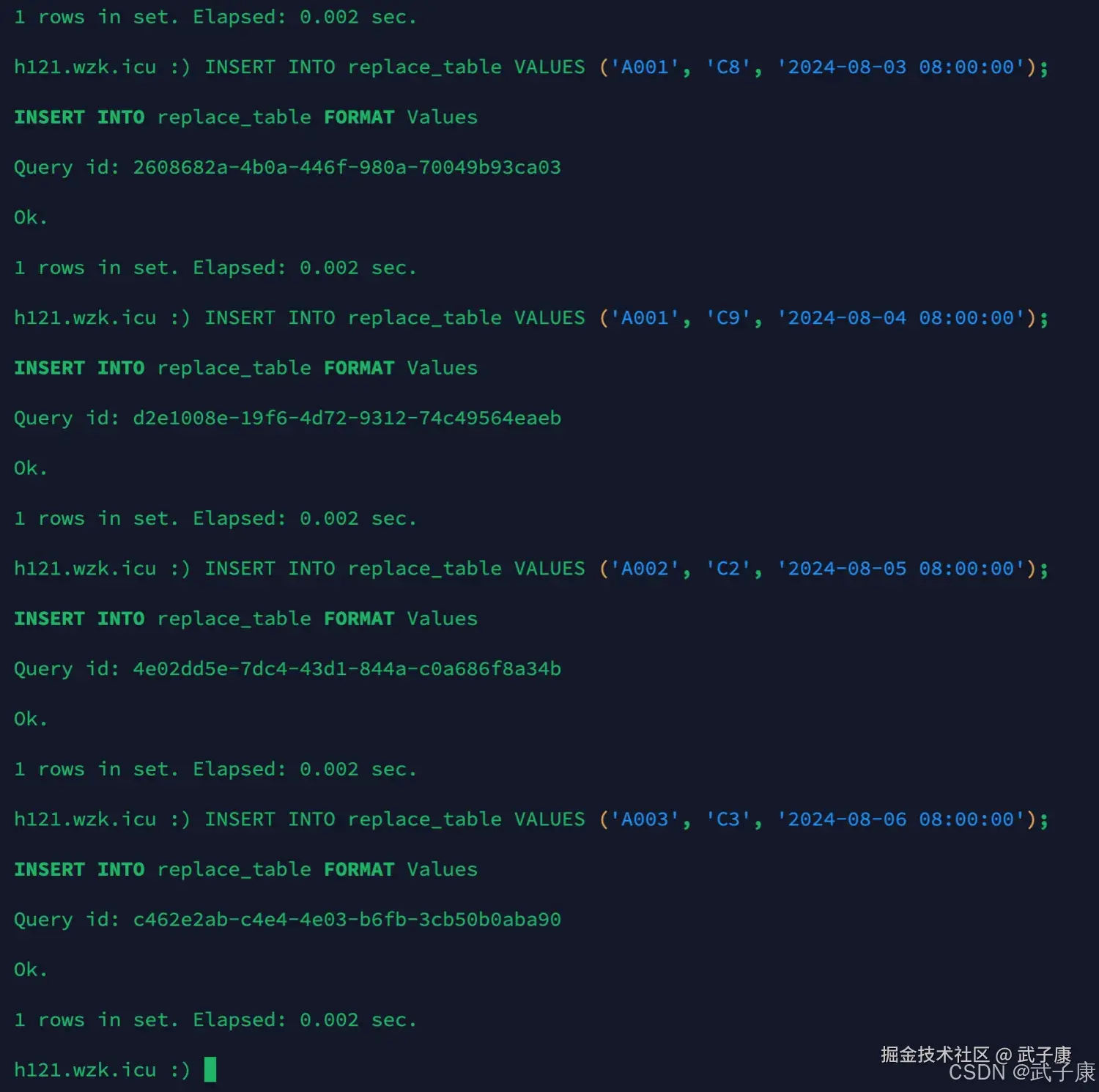
optimize
首先说一下,optimize的作用是:
- 合并数据块:ClickHouse是一个列式的数据库,它的数据是以数据块(parts)的形式存储在磁盘上,OPTIMIZE TABLE 语句通过较小的数据块来减少块的数量,从而提高查询性能和磁盘利用率。
- 删除标记的行:如果表中有被标记为删除的行,这些行将在优化过程中被真正删除,释放相应的空间。
- 分区管理:可以对表的指定分区进行优化,以减少分区内的碎片。
sql
SELECT
*
FROM
replace_table;运行结果如下图所示,通过观察,去重是根据ORDER BY来的,并非 PRIMARY KEY: 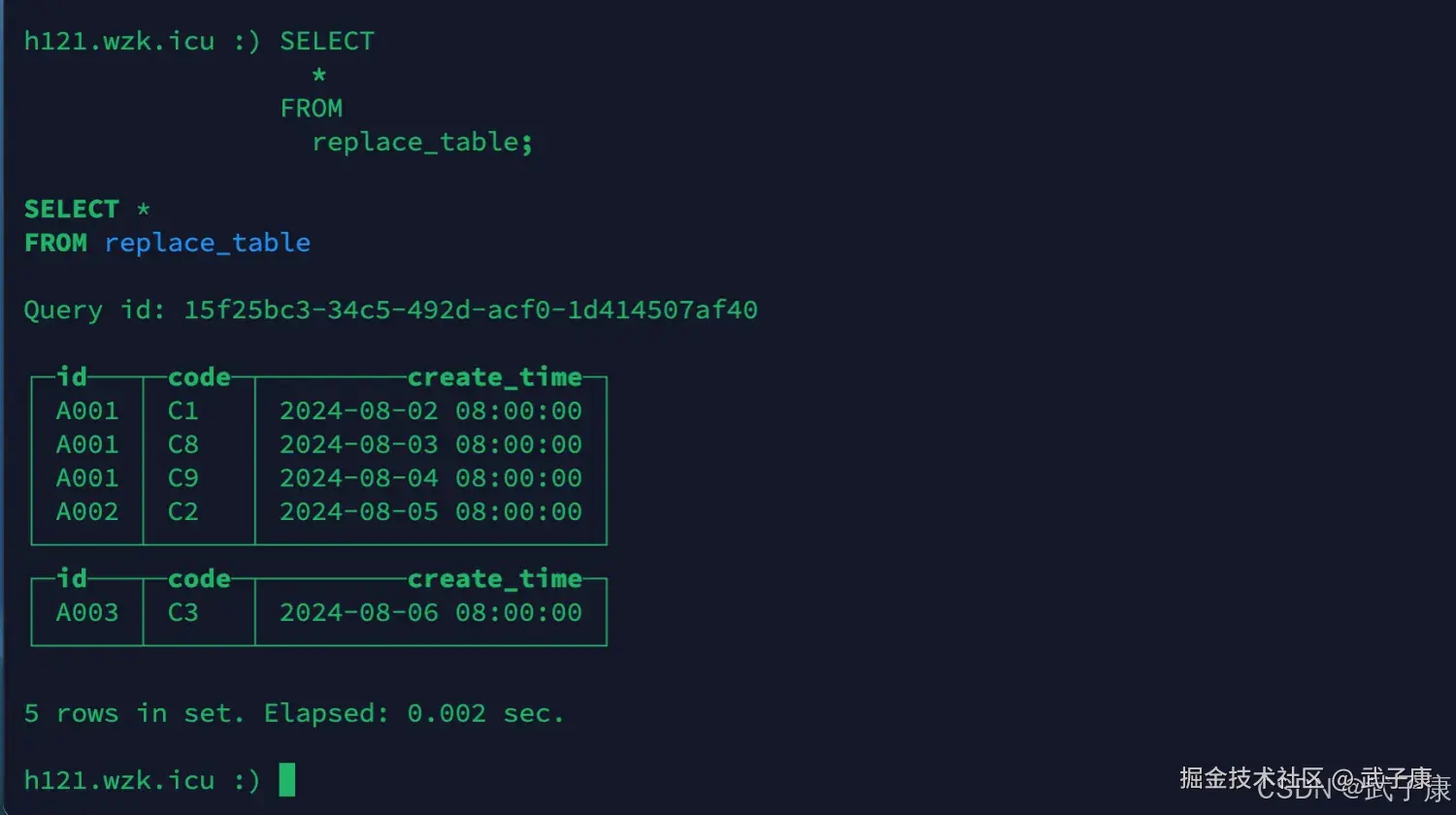
继续插入一条数据:
shell
INSERT INTO replace_table VALUES('A001', 'c1', '2024-01-01 08:00:00')执行结果如下所示: 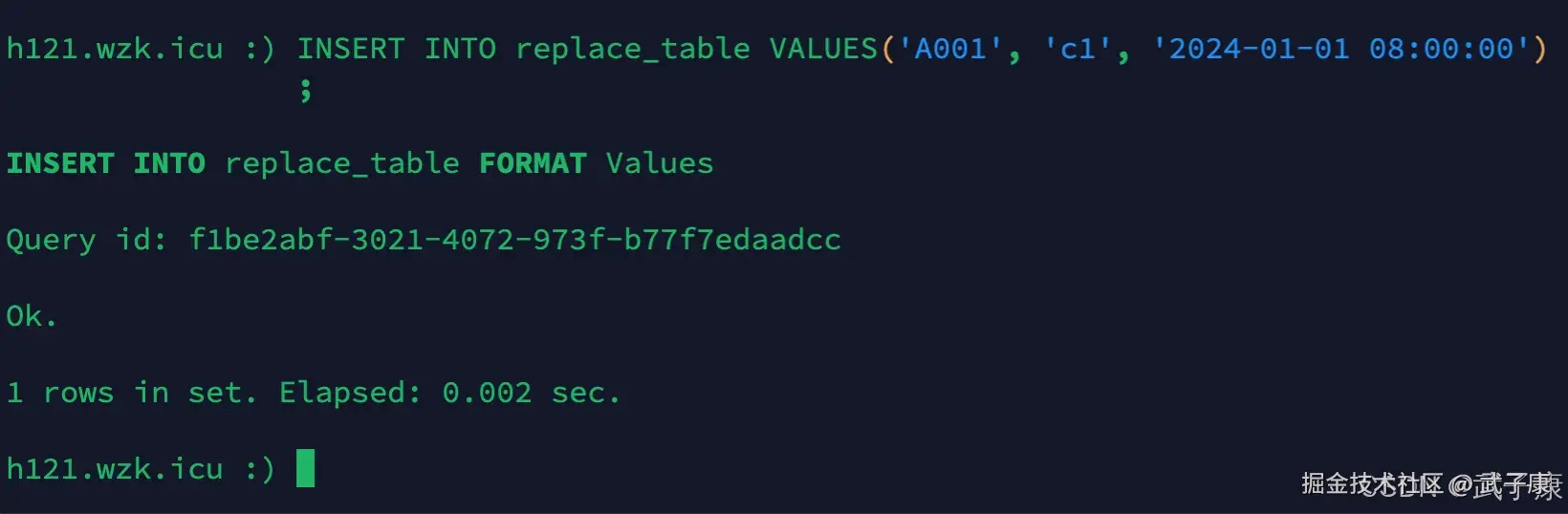 观察上图可以看出,不同分区的数据不会去重。
观察上图可以看出,不同分区的数据不会去重。
SummingMergeTree
简介
该引擎来自MergeTree,区别在于,当合并SummingMergeTree表的数据片段时,ClickHouse会把所有具有相同聚合数据的条件KEY的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。 如果聚合数据的条件KEY的组合方式使得单个键值对应于大量的行,则可以显著减少存储空间并加快数据查询的速度。对于不可加的列,会取一个最先出现的值。
特点
- 用ORDER BY排序键作为聚合数据的条件KEY
- 合并分区的时候触发汇总逻辑
- 以数据分区为单位聚合数据,不同分区的数据不会被汇总
- 如果在定义引擎时指定了Columns汇总列(非主键)则SUM汇总这些字段
- 如果没有指定,则汇总所有非主键的数值类型字段
- SUM汇总相同的聚合KEY的数据,依赖ORDER BY排序
- 同一分区的SUM汇总过程,非汇总字段的数据保留第一行取值
- 支持嵌套结构,但列字段名称必须以Map后缀结束
案例1
创建新表
sql
CREATE TABLE smt_table (
date Date,
name String,
a UInt16,
b UInt16
) ENGINE = SummingMergeTree(date, (date, name), 8192, (a));运行的结果如下图所示: 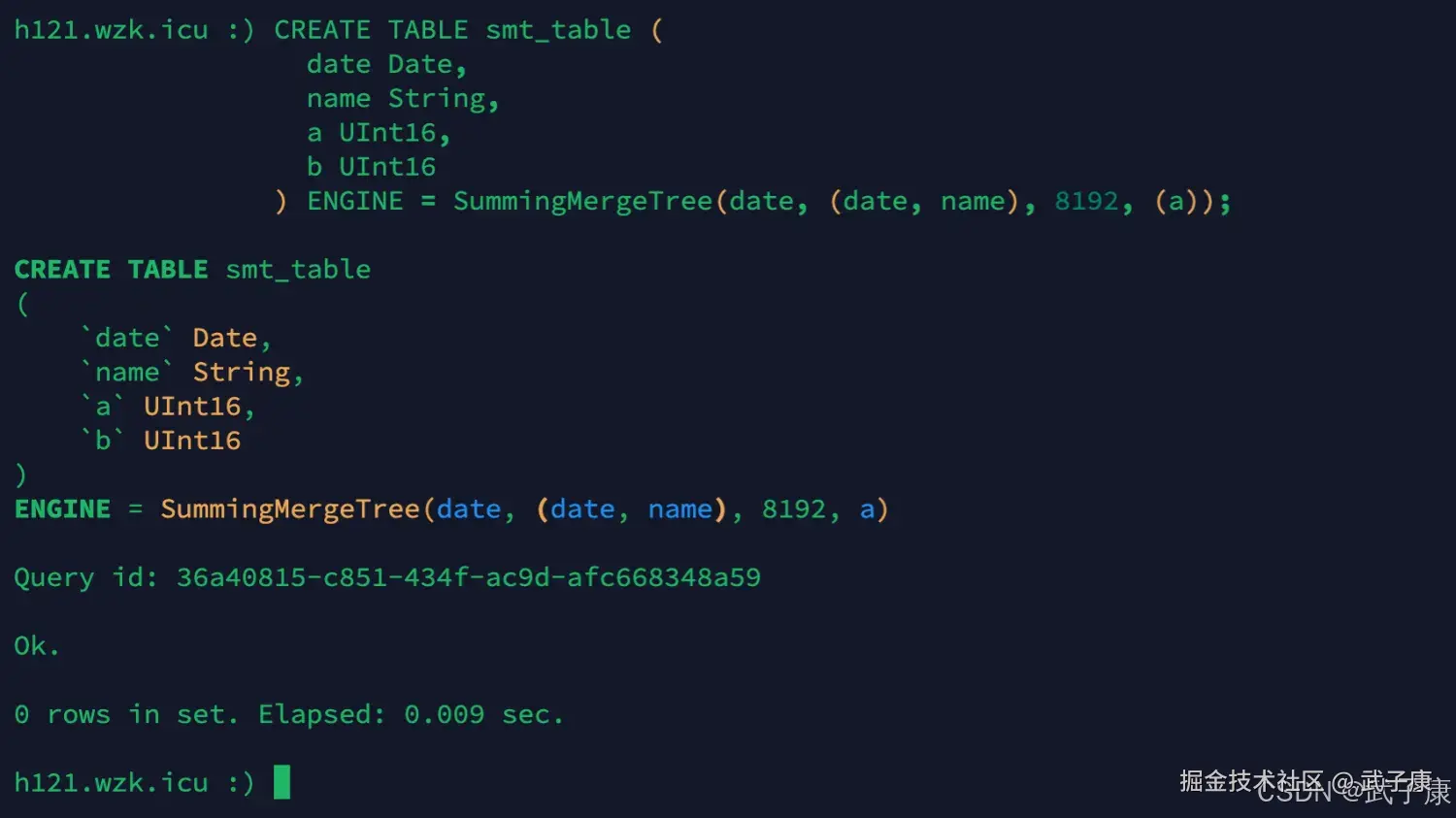
插入数据
sql
insert into smt_table (date, name, a, b) values ('2024-08-10', 'a', 1, 2);
insert into smt_table (date, name, a, b) values ('2024-08-10', 'b', 2, 1);
insert into smt_table (date, name, a, b) values ('2024-08-11', 'b', 3, 8);
insert into smt_table (date, name, a, b) values ('2024-08-11', 'b', 3, 8);
insert into smt_table (date, name, a, b) values ('2024-08-11', 'a', 3, 1);
insert into smt_table (date, name, a, b) values ('2024-08-12', 'c', 1, 3);运行结果如下所示: 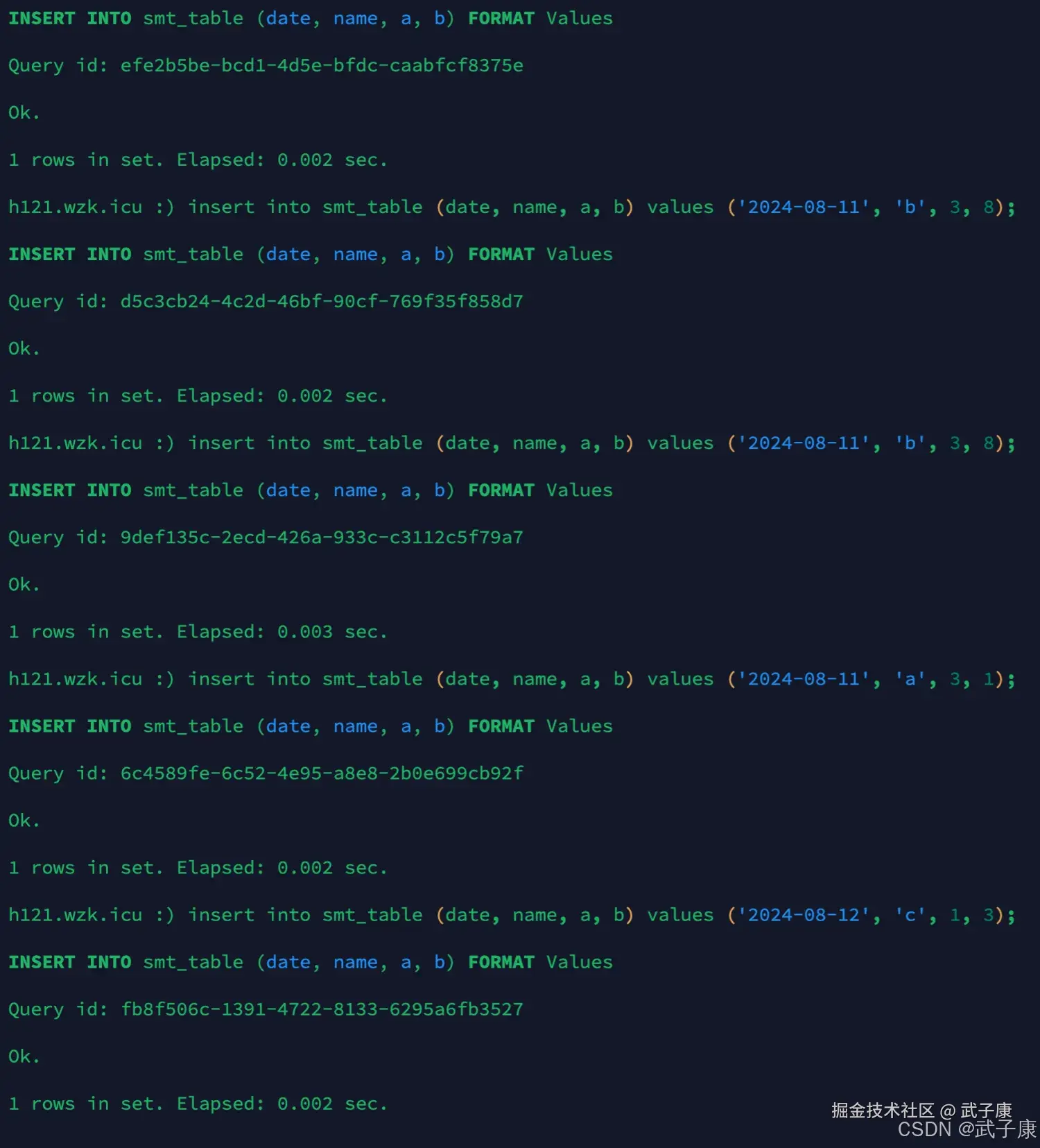
optimize
等待一段时间,或者手动 optimize table 来触发合并,再查询信息:
sql
OPTIMIZE TABLE smt_table;
SELECT
*
FROM
smt_table;执行结果如下图所示: 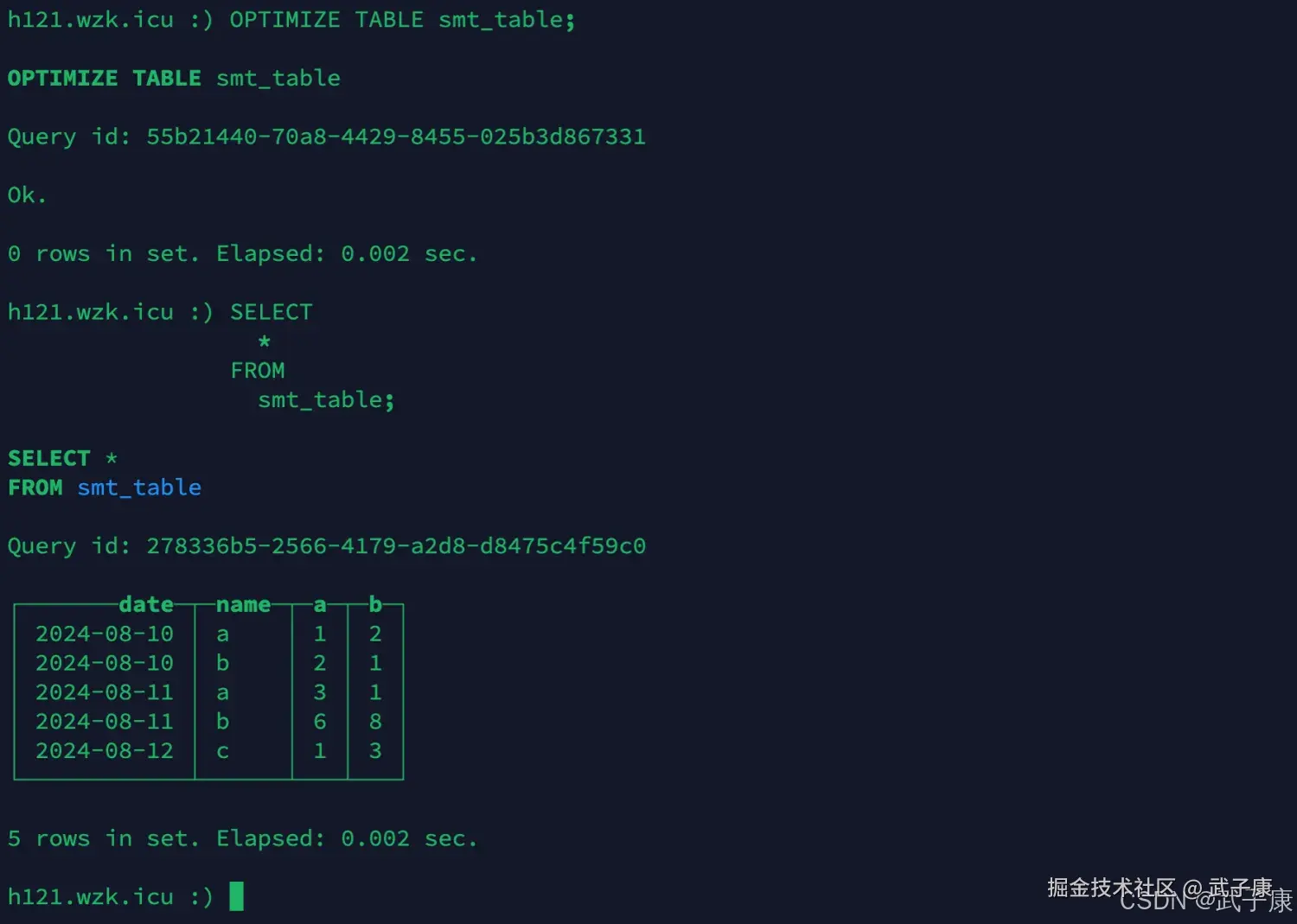
通过观察,我们会发现,2024-08-11, b 和 a 列合并相加了,b列取了8(因为b列为8的数据最先插入的)
案例2
创建新表
sql
CREATE TABLE summing_table(
id String,
city String,
v1 UInt32,
v2 Float64,
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, city);执行结果如下图: 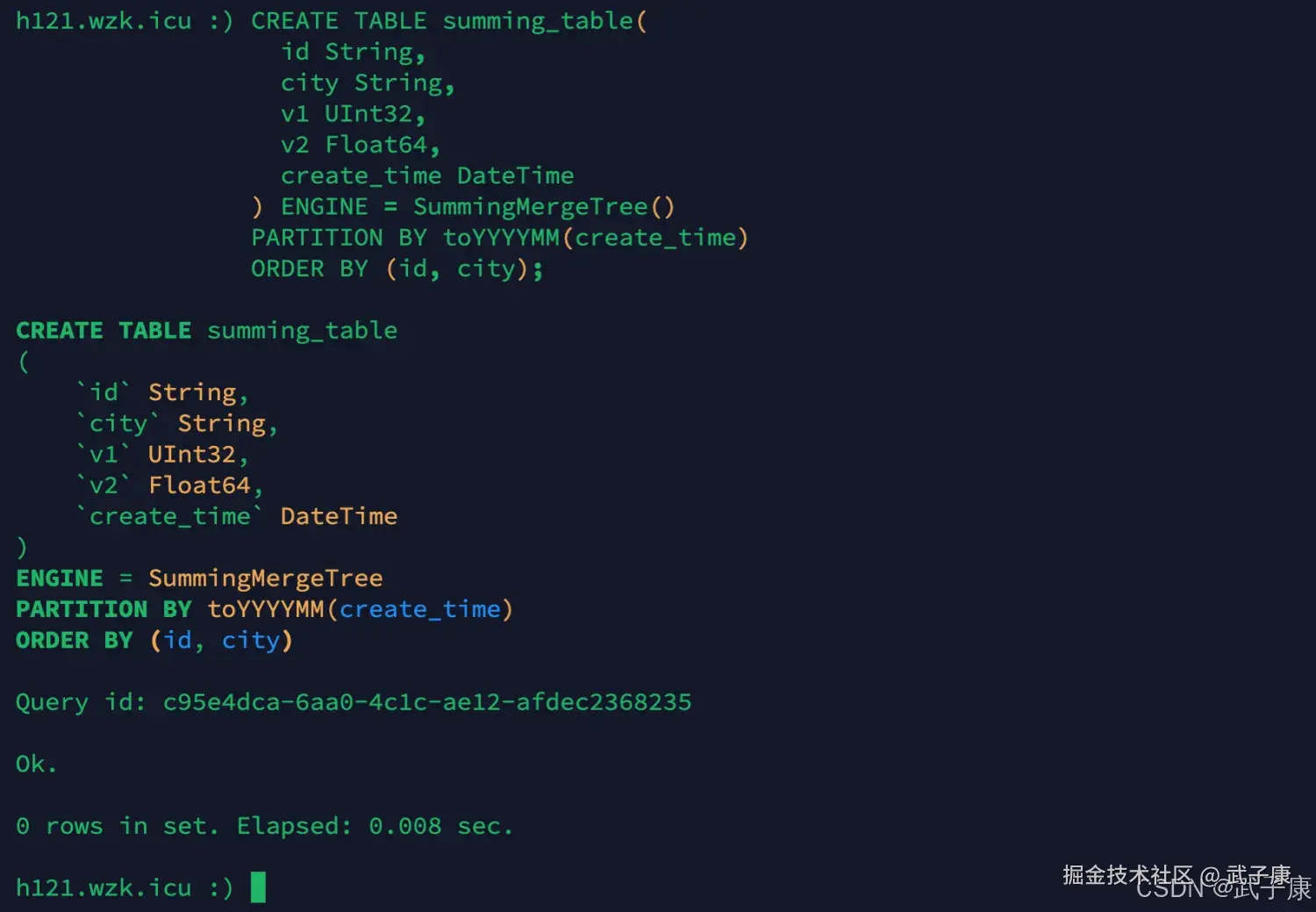
插入数据
sql
insert into table summing_table values('A000','beijing',10,20,'2024-08-20 08:00:00');
insert into table summing_table values('A000','beijing',20,30,'2024-08-30 08:00:00');
insert into table summing_table values('A000','shanghai',10,20,'2024-08-20 08:00:00');
insert into table summing_table values('A000','beijing',10,20,'2024-06-20 08:00:00');
insert into table summing_table values('A001','beijing',50,60,'2024-02-20 08:00:00');执行结果如下图所示: 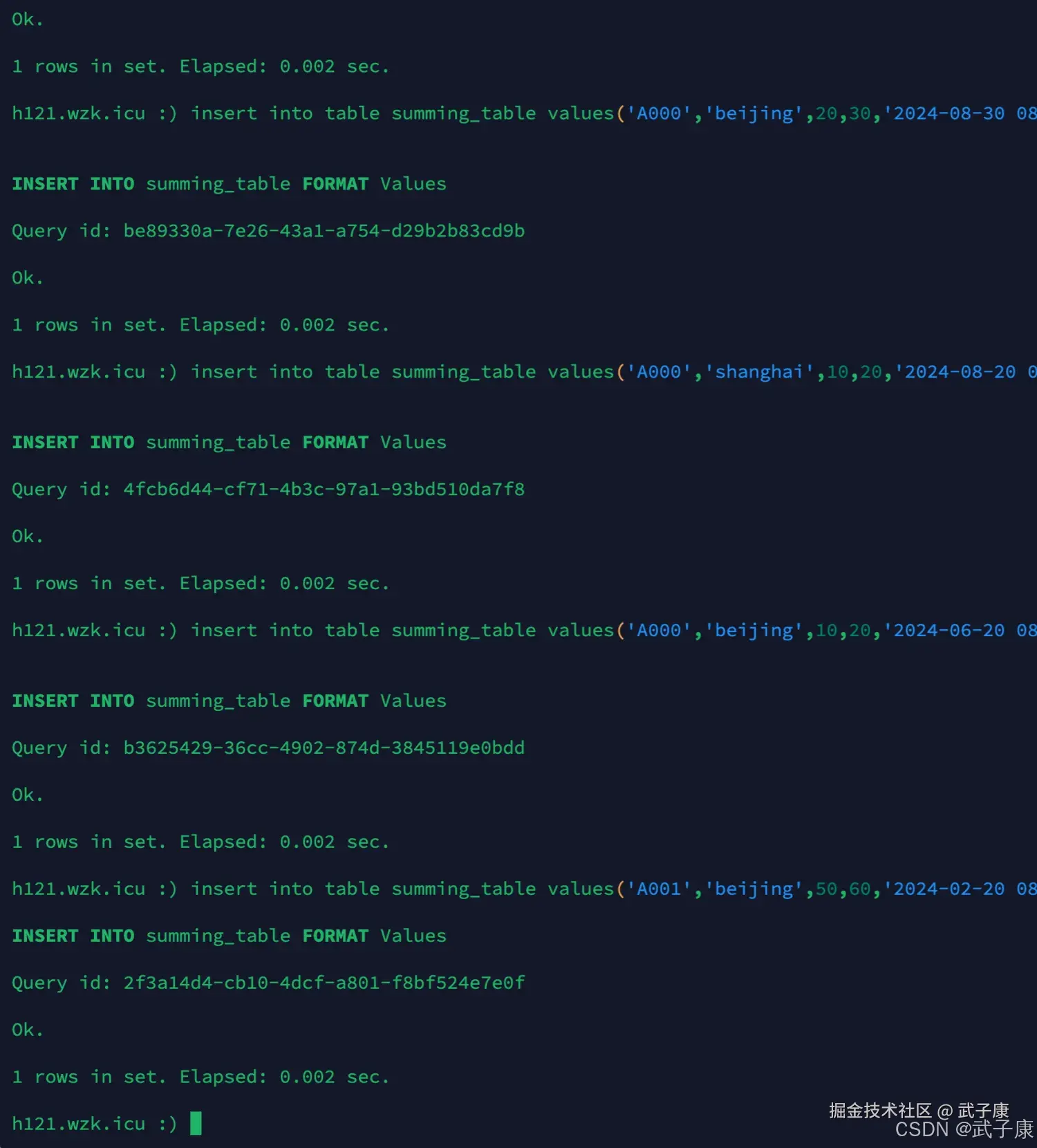
optimize
sql
OPTIMIZE TABLE summing_table;
SELECT
*
FROM
summing_table;执行结果如下图所示: 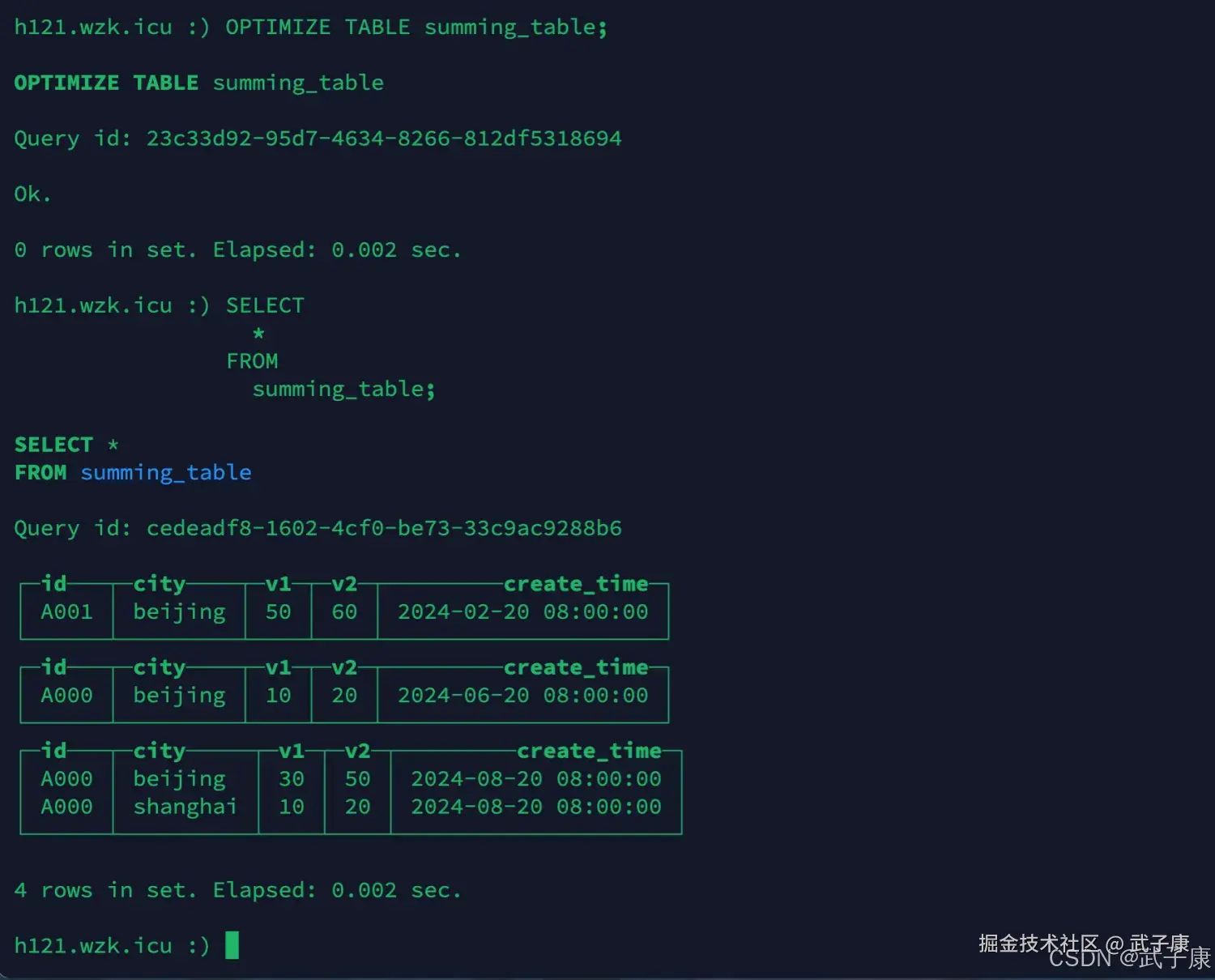 通过观察,根据ORDER BY排序键(id, city)作为聚合KEY,因为没有在建表时指定SummingMergeTree的SUM列,所以把所有非主键数值类型的列都进行了SUM处理。
通过观察,根据ORDER BY排序键(id, city)作为聚合KEY,因为没有在建表时指定SummingMergeTree的SUM列,所以把所有非主键数值类型的列都进行了SUM处理。
案例3
SummingMergeTree支持嵌套类型的字段,但列字段名称必须以Map后缀结束。
创建新表
sql
CREATE TABLE summing_table_nested(
id String,
nestMap Nested(
id UInt32,
key UInt32,
val UInt64
),
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id;执行的结果如下图所示: 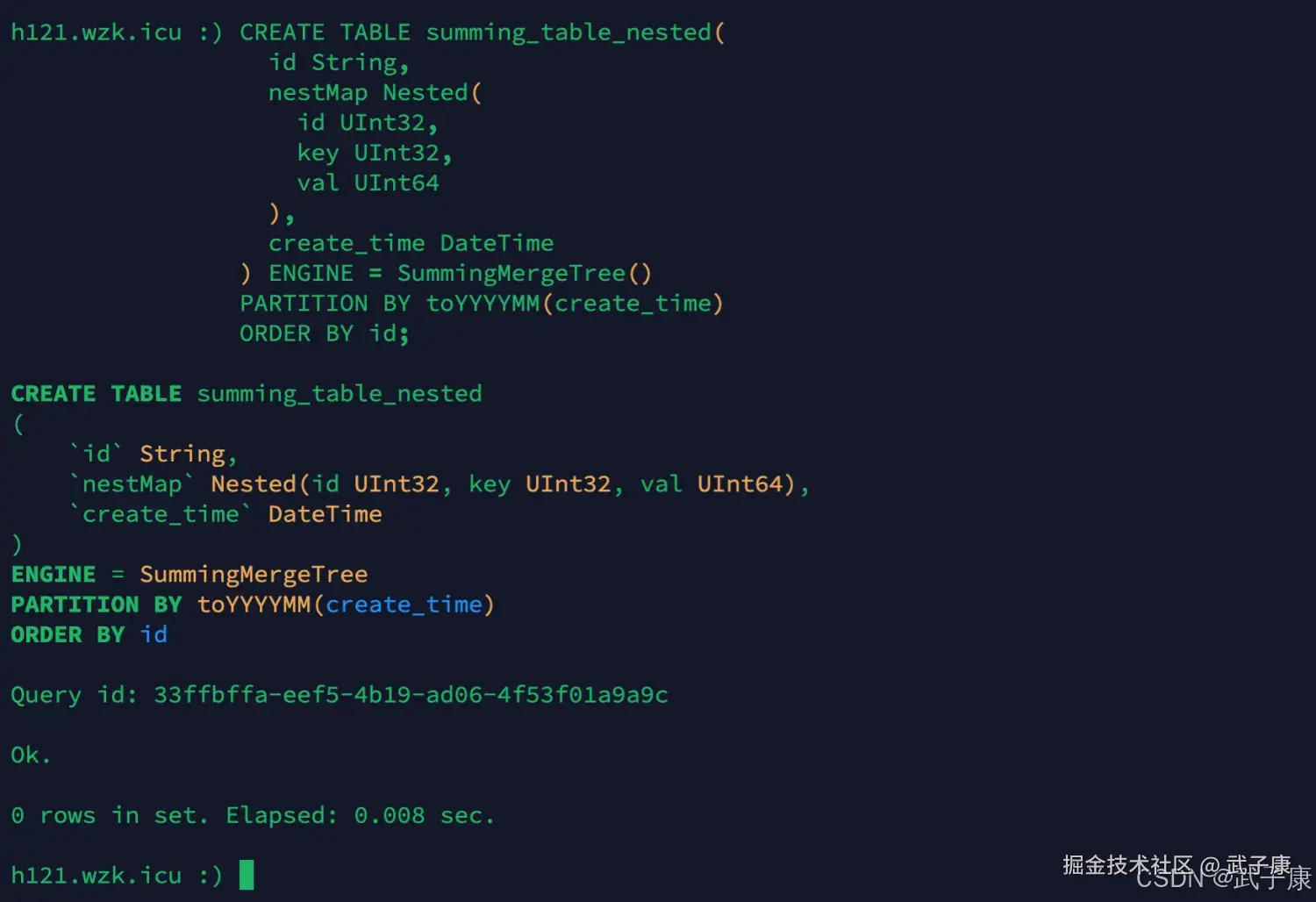
插入数据
sql
INSERT INTO summing_table_nested VALUES ('1', [101, 102], [201, 202], [1001, 1002], '2024-08-01 10:00:00');
INSERT INTO summing_table_nested VALUES ('2', [103, 104], [203, 204], [1003, 1004], '2024-08-01 10:00:00');
INSERT INTO summing_table_nested VALUES ('1', [105, 106], [205, 206], [1005, 1006], '2024-08-01 10:00:00');
INSERT INTO summing_table_nested VALUES ('2', [107, 108], [207, 208], [1007, 1008], '2024-08-02 10:00:00');
INSERT INTO summing_table_nested VALUES ('3', [109, 110], [209, 210], [1009, 1010], '2024-08-02 10:00:00');
INSERT INTO summing_table_nested VALUES ('4', [111, 112], [211, 212], [1011, 1012], '2024-08-02 10:00:00');执行过程如下图所示:  执行过程如下图所示:
执行过程如下图所示: 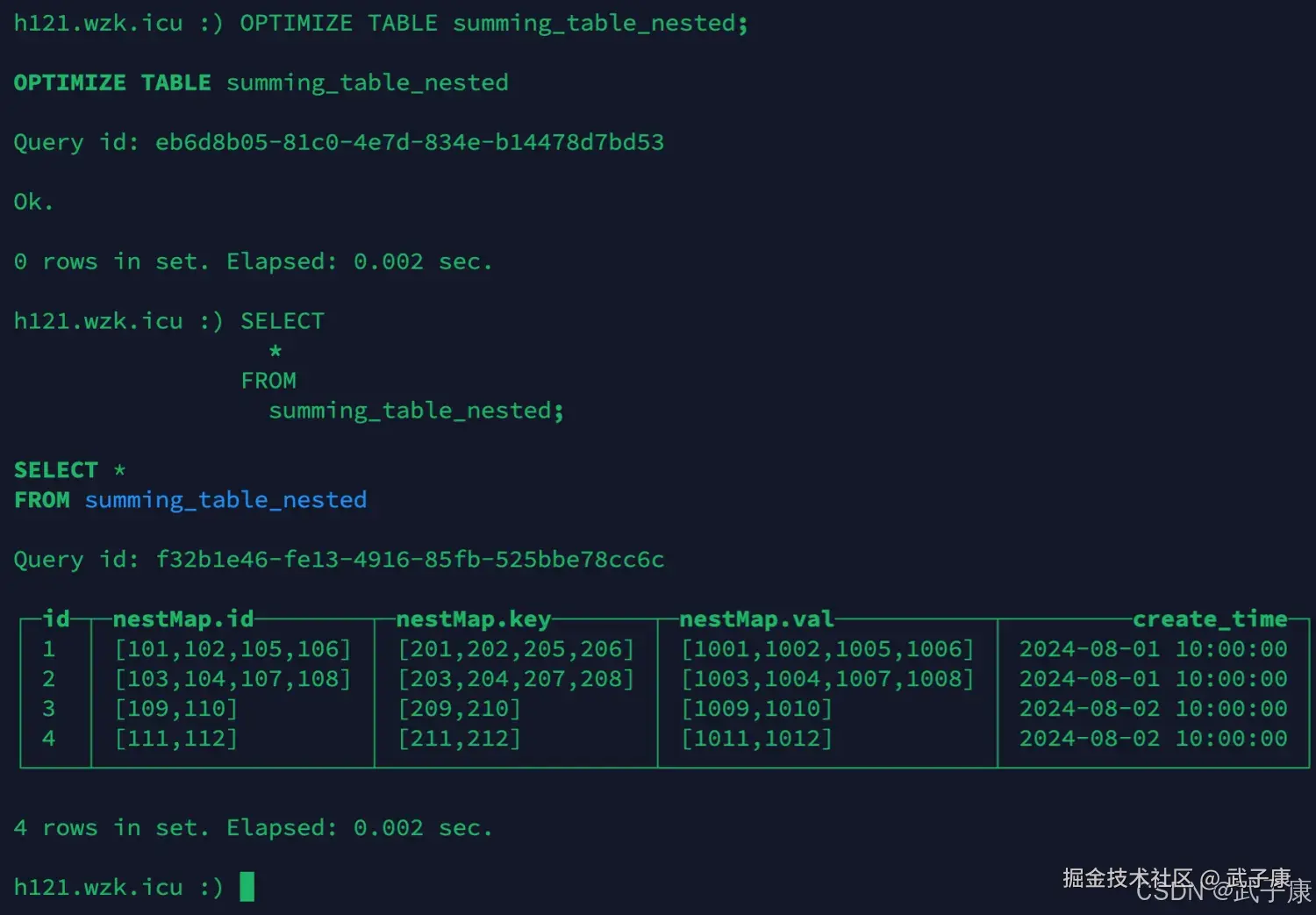 可以看到,我们插入了6条数据,但是查询到的只有4条,而且此外也进行计算的SUM处理。
可以看到,我们插入了6条数据,但是查询到的只有4条,而且此外也进行计算的SUM处理。
错误速查
| 症状 | 可能原因 | 定位手段 | 修复动作 |
|---|---|---|---|
| 去重/求和不生效 | 查询未加 FINAL 且后台未合并 | system.parts 查看活跃 parts | 等待合并/OPTIMIZE FINAL(离峰) |
| 去重跨月失败 | 分区切分导致 | 检查 PARTITION BY 键 | 调整分区策略/离线归并 |
| 非数值列值"随机" | Summing 保留首行值导致 | 复查结构 & 顺序 | 将该列移出或改为维度表 |
| OPTIMIZE 很慢 | 大分区或并发高 | 查看 I/O 与合并队列 | 控制并发/细化分区/分批优化 |
回滚与数据修复脚本
示例如下:
sql
-- 1) 误操作后回收旧分区(示例)
ALTER TABLE replace_table DETACH PARTITION 202408;
-- 导出/修复后再 ATTACH
-- 2) 统一重写:将明细重放到一张干净表,再原子切换
CREATE TABLE replace_table_fixed AS replace_table;
INSERT INTO replace_table_fixed SELECT * FROM replace_table FINAL; -- 得到去重后的明细
EXCHANGE TABLES replace_table AND replace_table_fixed; -- 原子切表(新版支持)FAQ
-
PRIMARY KEY 会参与去重吗? 不会。它只影响稀疏索引;去重/求和看 ORDER BY。
-
能跨分区去重/求和吗? 不能,需在离线层归并或改分区策略。
-
为什么 FINAL 很慢? 它会在线合并 parts;仅用于验证或小量报表。
-
Summing 对浮点安全吗? 普通的加法可能有精度误差;金融场景用 Decimal。
-
Replacing 的版本列怎么选? 用单调递增时间戳/版本号;不要用非单调字段。
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解