更多内容关注 Agent 专栏:Agent 专栏
面试解析 Agent 理论 + 实践(Spring AI Alibaba)
本节将会介绍 Agent 的四种基础设计模式:反思、工具调用、任务规划和多智能体协作。
在案例部分,会基于这四种设计模式,实现一个面试解析 Agent,在给定用户查询问题之后,Agent 可以进行规划,列出任务清单之后逐项执行,保证输出内容的可解释性。
为什么要学习 Agent 设计模式?
Agent 本质是让 LLM 从"回答问题"变为"解决问题",而设计模式则可以增强 Agent "解决问题"的能力。
如果仅仅依赖提示词来获取 LLM 的输出,可能并不能直接获取我们期望的数据,例如 DeepResearch(深度研究),我们如果直接向 LLM 输入问题, LLM 直接通过推理得到输出,这是一个单步骤的过程,输出的内容仅仅依赖于 LLM 本身的能力,无法实现 DeepResearch 期望的效果。
而 Agent 设计模式赋予了 LLM 规划、反思、工具使用、多智能体协作等能力,使输出的内容不再仅仅依赖于 LLM 自身,通过这些设计模式使 LLM 具备结构化处理的能力,从而增强 LLM 的输出能力。
设计模式一:反思
反思是一种提升 Agent 输出质量的策略,即让 Agent 完成初步回答之后,对决策的结果重新进行评估,以改进后续行为。
反思机制可以通过多种方式实现:
- 自我反思:同一个 Agent 生成内容之后,再以审查者的角度找出不足,并反馈进行重试。
- 引入评估 Agent:构建多智能体系统,引入评估 Agent 来对当前 Agent 输出的内容进行评估,再修改完善。
- 借助外部校验工具:前两种方式是基于 Agent 进行评估,无法进行严格的评估,例如可以借助 JSON 反序列化工具来判断是否输出了期望的 JSON 格式。
反思机制往往会在循环结构中进行使用,通过不断反思来完善 Agent 输出内容,注意设定循环次数上限。
设计模式二:工具调用
工具调用提供了 LLM 与外部环境连接的能力,在工具调用的加持下,使 LLM 的能力不再局限于对话框内的内容生成,而是可以作为"决策大脑",主动执行任务。
在工具调用方面,我们希望有越来越多的工具供选择和调用,因此出现了 MCP。MCP 统一了 LLM 与外部工具交互的协议规范,大家都基于这一规范实现对应的工具,极大降低了工具调用时的沟通和学习成本。
设计模式三:任务规划
任务规划使 Agent 在面对复杂任务时,先思考生成任务清单,之后按照任务清单逐个执行任务。
通过实现生成计划,可以提高 Agent 行为的可解释性,并且可以加入人类反馈,对生成的计划进行调整,使执行过程可控且透明。
Agent 在企业落地中的稳定性表现很重要,LLM 是基于"概率"的内容生成模型,概率意味着不稳定,如果想要对 Agent 进行落地,则必须基于通过各种"工程手段"提高 LLM 输出内容的稳定性,不稳定的系统对企业意味着灾难。
设计模式四:多智能体协作
多智能体协作即搭建由多个智能体组成的系统,每个智能体负责更细分领域的任务。
单个智能体的水平扩展能力有限,单智能体的能力不会随着长下文长度的增加、可调用工具数量的增多而变强,多智能体协作正是解决这一限制的手段。
同时在多智能体中,可以让单个智能体针对某个子任务不断进行优化,性能表现优于负责多个任务的单智能体。
面试解析 Agent
完整代码位于:https://github.com/1020325258/spring-ai-alibaba-tutorial/tree/master/04-AnalysisAgent
接下来,会实现一个面试解析 Agent,主要包含下图中的三个节点:
- planner:目标是进行任务规划,思考为了生成问题的解析文档,需要提前搜集哪些内容,列出任务清单。
- plan_accept:对 planner 节点输出的任务规划进行评估,决定是否接受该计划,如果不接受则重新路由至 Planner 生成计划。
- search_node:如果接受计划,则根据计划中的每个步骤进行搜索。
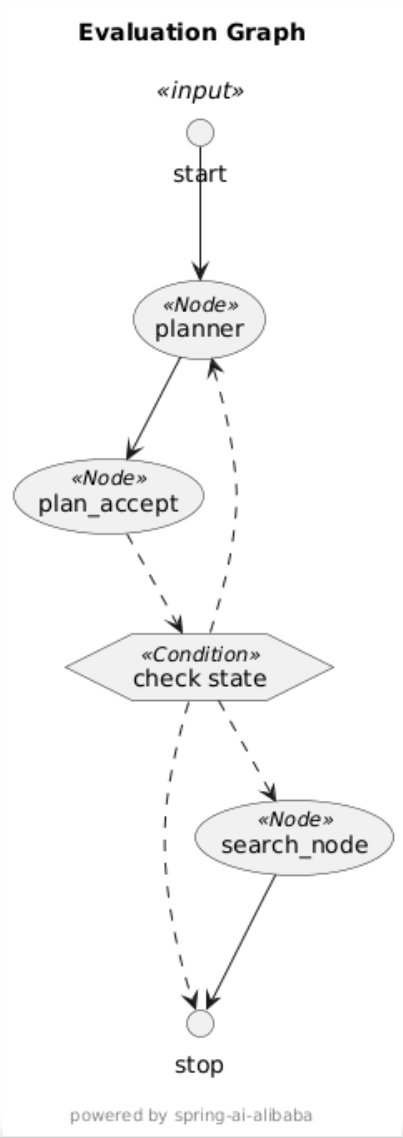
Planner
任务规划节点,通过提示词引导 LLM 根据用户提问的问题进行任务规划,确保可以在信息收集阶段收集到足够的信息,保证最终生成内容的深度与广度。
其中,提示词中增加了任务规划的步骤上限,避免步骤太多导致搜索时间过长。如果出现步骤太少的情况,你也可以自己改造提示词,增加最小步骤数避免步骤太少导致信息不足。
这里列举出 Planner 节点的部分提示词:
Markdown
你是一名专业的 **面试解析规划师(Interview Answer Planner)**。
你的任务是组织由一个或多个智能 Agent 组成的团队,生成针对某个面试题的解析内容。
最终目标是生成一份详尽、完整的解析文档,因此你必须在信息收集阶段确保内容的广度与深度兼备。
信息不足、覆盖面狭窄、或者仅停留在表面层次都将导致最终生成内容质量不足。
## 任务说明
你需要将研究主题拆分为多个子主题,并且在必要时扩展用户问题的研究范围和深度,以确保生成内容的充分性。
文档应包含以下核心要素:
- **题意分析**:准确理解考察点和潜在陷阱
- **标准答案**:清晰、专业、分层次地回答问题
- **扩展思路**:展示候选人可体现加分项的思考路径
- **面试官意图**:说明此题的考核目的与能力映射
- **答题策略**:给出高分回答技巧与注意事项
因此,在生成最终解析文档之前,
你必须首先规划一个完整的 **信息收集与内容生成步骤计划**。
## 信息质量与数量标准
成功的 planner 必须同时满足以下三点:
1. **全面覆盖**
- 信息必须覆盖题目的所有维度;
- 包含多个角度的分析(技术、逻辑、抽象、决策);
- 同时考虑候选人与面试官的视角。
2. **足够深度**
- 不允许表面化或模板化的解释;
- 需要包含底层原理、机制、例子与对比分析;
- 明确阐述答案背后的逻辑与推理链条。
3. **信息量充足**
- "刚好够用"的信息量是不合格的;
- 必须确保资料丰富、解释细致;
- 包含常见错误、变体题、延伸问题等附加内容。
## ⚙️ 计划约束(Step Constraints)
- **最多 {{ max_step_num }} 步**;
- 每步内容必须具体且有产出目标;
- 允许将相关主题合并为同一步;
- 保证深度与广度兼顾。
## 📦 输出格式(Output Format)
直接输出原始 JSON(不要使用代码块标识符),结构如下:
```ts
interface Step {
need_web_search: boolean; // 是否需要外部搜索
title: string; // 步骤标题
description: string; // 要收集或处理的具体内容
step_type: "research" | "processing"; // 步骤类型
}
interface Plan {
has_enough_context: boolean; // 是否已有足够上下文
thought: string; // 复述用户问题
title: string; // 计划标题
steps: Step[]; // 步骤列表
}Planner 生成的任务规划使用 JSON 格式进行结构化输出,保证 Graph 中的下一个节点可以清楚了解任务以及每个步骤的细节。
通过 {``{ max_step_num}}来限制最大步骤数,之后在创建 ChatClient 时不提前设定系统提示词,而是在运行时,动态获取 max_step_num 变量来替换提示词中的 {``{ max_step_num }}占位符,提示词变量替换代码如下:
Java
public static Message getPlannerMessage(OverAllState state) throws IOException {
// 读取 resources/prompts 下的 md 文件
ClassPathResource resource = new ClassPathResource("prompts/planner.md");
String template = StreamUtils.copyToString(resource.getInputStream(), StandardCharsets.UTF_8);
// 替换 {{ CURRENT_TIME }} 占位符
String systemPrompt = template.replace("{{ CURRENT_TIME }}", LocalDateTime.now().toString());
// 替换 {{ max_step_num }} 占位符
systemPrompt = systemPrompt.replace("{{ max_step_num }}", state.value(StateKeyEnum.MAX_STEP_NUM.getKey(), 3).toString());
// 创建系统提示词
SystemMessage systemMessage = new SystemMessage(systemPrompt);
return systemMessage;
}运行时,创建好系统提示词之后,将提示词作为 List<Message> 传递给大模型即可,如下:
Java
List<Message> messages = new ArrayList<>();
// 添加系统提示词
messages.add(PromptTemplateUtil.getPlannerMessage(state));
// 调用 LLM
String content = plannerAgent.prompt().messages(messages).call().content();PlanAccept
PlanAccept 节点用于评估计划是否符合要求,这里通过反序列化的方式验证 Planner 输出内容是否符合 JSON 格式。
PlanAccept 节点如果反序列化失败,则重新路由至 Planner 节点生成计划,并记录迭代次数,达到上限则就直接路由至 END 节点,避免死循环。
PlanAccept 节点核心代码如下:
Java
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
Map<String, Object> result = new HashMap<>();
String plannerContent = state.value(StateKeyEnum.PLANNER_CONTENT.getKey(), "");
BeanOutputConverter<Plan> converter = new BeanOutputConverter<>(new ParameterizedTypeReference<Plan>() {});
try {
// 反序列化计划
Plan plan = converter.convert(plannerContent);
Boolean autoAcceptPlan = state.value(StateKeyEnum.AUTO_ACCEPT_PLAN.getKey(), true);
if (autoAcceptPlan) {
// 将计划存入 State
result.put(StateKeyEnum.PLAN.getKey(), plan);
result.put(StateKeyEnum.PLAN_ACCEPT_NEXT_NODE.getKey(), "search_node");
logger.info("Plan auto accept: {}", plan);
} else {
// todo 增加人员反馈节点
}
} catch (Exception e) {
// todo 给 Planner 重新制定计划
logger.info("planner convert error", e);
// 生成计划迭代次数
Integer iterationNum = state.value(StateKeyEnum.PLAN_ITERATION_NUM.getKey(), 0);
if (iterationNum > 3) {
// 如果超出迭代次数上限,则直接流转至结束节点
result.put(StateKeyEnum.PLAN_ACCEPT_NEXT_NODE.getKey(), StateGraph.END);
} else {
// 如果没超出,则继续尝试生成计划生成计划迭代次数 + 1
result.put(StateKeyEnum.PLAN_ITERATION_NUM.getKey(), iterationNum + 1);
// 重新跳回至 planner 节点生成计划
result.put(StateKeyEnum.PLAN_ACCEPT_NEXT_NODE.getKey(), "planner");
}
}
return result;
}SearchNode
SearchNode 得到执行计划之后,根据执行计划中的步骤 Step 开始搜集信息。
搜索工具采用百炼平台提供的 MCP 工具,这里我们自己定义 McpService,因为百炼平台的 MCP Server 使用时,需要在 header 中加入鉴权 token,在 04 节介绍过,如果 SpringAIAlibaba 想要集成百炼的 MCP 工具,就需要重写对应的源码并覆盖,这样会带来一个问题就是如果 SpringAIAlibaba 之后迭代我们重写的类的话,我们也需要同步进行迭代。
而且,SpringAIAlibaba 将 MCP 的底层连接和工具调用全部封装起来,使用时内部黑盒不便于我们学习和理解。
基于上述原因,选择手动连接 MCP Server,如下:
Java
public McpService() {
// 初始化与 McpServer 的 SSE 传输通道
this.transport = new WebFluxSseClientTransport(
WebClient.builder().defaultHeader("Authorization", "Bearer " + System.getenv("AI_DASHSCOPE_API_KEY"))
.baseUrl("https://dashscope.aliyuncs.com"), new ObjectMapper(), "/api/v1/mcps/zhipu-websearch/sse");
// 初始化 McpClient
this.mcpSyncClient = McpClient.sync(transport).build();
// 初始化与 MCP Server 的连接
mcpSyncClient.initialize();
}初始化好连接之后,就可以通过 mcpSyncClient 根据 name 调用对应的工具了。
SearchNode 中通过 McpService 搜集好相关的信息,发送给 LLM 进行最终的汇总和内容生成,如下:
Java
public Map<String, Object> apply(OverAllState state) throws Exception {
Map<String, Object> result = new HashMap<>();
// 获取节点执行计划
Plan plan = state.value(StateKeyEnum.PLAN.getKey(), Plan.class).orElse(null);
List<Message> messages = new ArrayList<>();
for (Plan.Step step : plan.getSteps()) {
if (!Plan.StepType.RESEARCH.equals(step.getStepType())) {
continue;
}
String title = step.getQuery();
List<SearchResult> searchResults = mcpService.query(title);
messages.add(new UserMessage(
"搜索结果:" + searchResults.stream().map(r -> {
return String.format("查询问题: %s\n内容: %s\n链接: %s\n", r.getTitle(), r.getContent(), r.getLink());
}).collect(Collectors.joining("\n\n"))));
}
String searchContent = searchAgent.prompt().messages(messages)
.call()
.content();
logger.info("SearchNode 输出结果: {}", searchContent);
result.put(StateKeyEnum.SEARCH_CONTENT.getKey(), searchContent);
return result;
}这里将搜索到的结果放入到 List<Message> 作为上下文发送给 LLM,这里我是用的模型是 qwen3-max,官方给出模型的输入上下文长度是 256K,最大输入长度是 **252K,**也就是 252000 个 token,按照 1 token = 1.5 个汉字来算,模型一次可以接受 378000 个汉字,约等于 378 页 Word 文档。
所以,这里直接将搜索结果发送给 qwen3-max 是没有问题的,如果模型的输入上下文比较小,可以限制计划的步骤以及 McpService 中搜索的结果来减少输入上下文。
总结
本节介绍了 Agent 的四种基础设计模式,来自于吴恩达 2024 年 3 月发表的演讲,这四种设计模式是最基础的设计模式,除了这些还有很多其他方式可以提升 Agent 的性能,例如在 Jina DeepResearch 中,会使用 <xml> 定义提示词,并且对查询进行重写,查询的重写非常重要,可以从更多角度获取潜在的答案,并且在 RAG 搜索中,可以基于查询重写得到更适合 BM25 算法的关键词,以收集到更多有用的内容。
推荐阅读(AI DeepResearch 文章):https://zhuanlan.zhihu.com/p/26560000573Jina
除了理论部分,在实践部分也基于 Spring AI Alibaba 实现了一个面试解析 Agent 了,实现了任务规划、任务评估、网页搜索,并基于收集到的内容生成一份完整的解析文档。