博客配套代码发布于github:05 LangChain 进阶
相关Agent专栏:Ai Agent教学
本系列所有博客均配套Gihub开源代码,开箱即用,仅需配置API_KEY。
如果该Agent教学系列帮到了你,欢迎给我个Star⭐,非常感谢!
知识点 :Agent 构建 (ReAct & Tool-Calling)|特化 Agent (create_sql_agent)|Agent 与 Memory 融合|高阶技巧 (缓存 & 流式)
前言:
上篇文章我们已经把llm、prompt、chain、memory四大模块啃了下来。但这时的它还有点笨:不会调用工具函数来工作。所以本篇我们就要聚焦于此------为它接入这个手:Agents。
(注:这两个概念务必不要弄混。Agent是ai界通用的对智能体的表达 ;而这里的Agents则是Langchain中的核心模块,代指Function callings,函数调用的思想)
除了主要讲述的Agents外,本篇还会加入一些Langchain的高阶技巧,进一步提升agent的灵活性。
一、ReAct 循环与@tool
其实在我们之前的文章Ai Agent 03 Function Calling实战:让AI真正"调用工具"完成任务中,我们就已经手动造过轮子 了,知道其原理与过程。Langchain的Agents模块的思路大体也是一致的,只是使用方法变更了下。
在开始学习Agents之前,我们需要先了解下俩Agents的关键零件:
1. 零件1:ReAct循环------agent的大脑
ReAct=Reason(推理/思考)+Action(行动)
这就是Agent内部思考的逻辑循环:
思考:LLM分析任务(我要查看天气)
行动:调用find_weather函数
观察:Langchain自动调用该工具函数并返回数据
思考:LLM观察到结果,并思考(我已经拿到数据,可以回答用户了)
行动:回复用户今天天气。
如果你想真正看到这个流程,推荐输出时,带上verbose=True,来看看ai内部的思考过程。
2. 零件二:工具------@tool
Agent的手和脚,用以定义Agent能做什么。
Langchain为我们封装了一个@tool装饰器,可以一键将任意Python函数封装为Agent可用的工具。
我们接下来用一段自定义代码感受下:
python
from langchain_core.tools import tool
@tool
def get_weather(location):
"""模拟获得天气信息"""
return f"{location}当前天气:23℃,晴,风力2级"
@tool
def get_user_name(user):
"""模拟获得用户名字"""
return f'用户名字是:{user}'
# 封装好我们要用的工具
tools = [get_weather,get_user_name]
print('工具箱已封装完毕!')这里有些关键点要注意一下:
当用@tool封装某个函数作为工具时,必须要用"""xx"""来为其添加描述信息。
这段描述信息可不是注释,而是这个工具的 "提示词" 。如果你不为它添加该提示词就为直接报错。
添加完后,llm就会根据该提示词来判断是否应该调用这个工具。
 成功打印后,我们接下来让llm真正调用这个工具。
成功打印后,我们接下来让llm真正调用这个工具。
二、通用Agent
当我们构建一个涵盖Agents(工具调用)模块的智能体时,我们就必须借助一些新的创建agent的函数了。create_xx_agent有几个不同的函数,这里我们只拿出两个最为常用的来讲。
create_tool_calling_agent:它返回结构化的tool_calls请求,最稳定并且准确。
组成顺序:
- LLM 2. Prompt 3. Tools(工具列表)
- create_tool_calling_agent:把上面三个组装成agent(大脑)
- AgentExecutor:Agent的执行器(身体),负责真正运行ReAct循环。
接着进行代码实操:
LLM配置照常,Prompt配置这里要注意下:
ini
# prompt配置
prompt = ChatPromptTemplate.from_messages([
("system","你是一个聪明的智能助手。当你遇到解决不了的问题时,会调用工具来解决问题。"),
("human","{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad") # 必加,Agent的思考过程
])当使用create_tool_calling_agent时,必须加上这行MessagePlaceholder(varibale_name="agent_scratchpad"),它代表一个临时记事本 ,会记录 整个ReAct流程(思考-动作-观察),并将整个思考过程再让llm看到,从而做出下步决策。
tools配置也跟之前差不多,这里重点要记一下agent与agent_executor的创建流程:
python
# tool配置
@tool
def get_weather(location):
"""模拟获得天气信息"""
return f"{location}当前天气:23℃,晴,风力2级"
@tool
def get_user_name(user):
"""模拟获得用户名字"""
return f'用户名字是:{user}'
tools = [get_weather,get_user_name]
# 创建Agent(大脑)
agent = create_tool_calling_agent(llm=llm,prompt=prompt,tools=tools)
# 创建AgentExecutor(执行器)--负责运行ReAct循环
agent_executor = AgentExecutor(agent=agent,tools=tools,verbose=True) # 开启verbose以看到ai思考链
# 运行
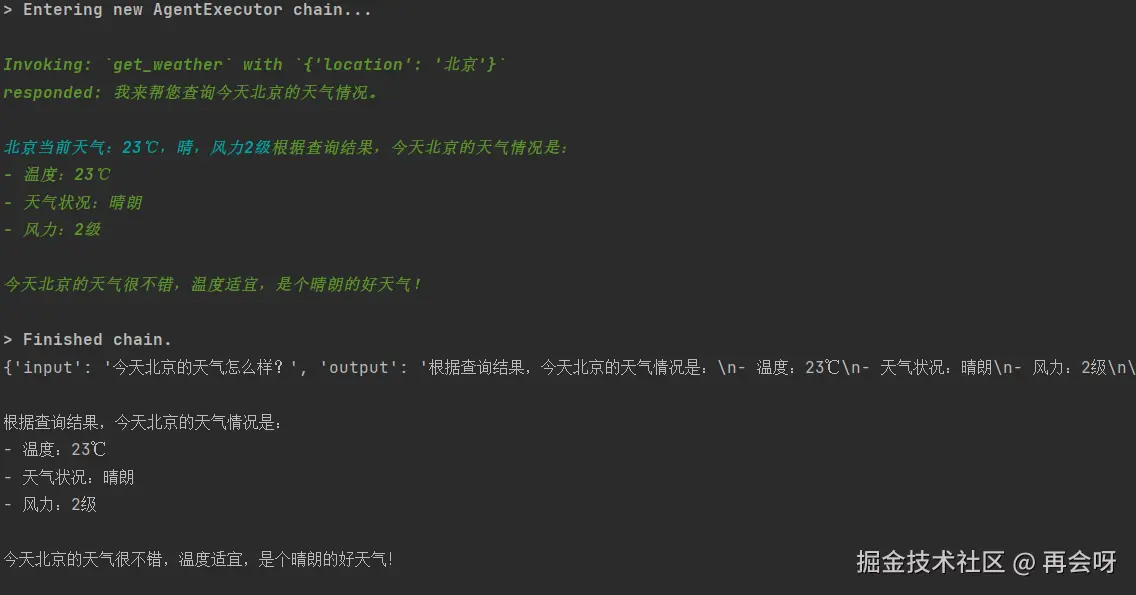
response = agent_executor.invoke({
'input':"今天北京的天气怎么样?"
})
print(response)
print()
print(response['output'])此处verbose=True即代表输出思考链。
整个输出流程就是:
llm -- prompt -- tools -- create_tool_calling_agent -- AgentExecutor
哎,你看这个agent = create_tool_calling_agent(llm=llm,prompt=prompt,tools=tools)
有没有感觉它很像当初的chain=llm|prompt|parser?但为什么这里甚至都没有用到chain?
因为这个重要模块已经被封装进create_tool_calling_agent里面了。
这个函数将Chain作为内部推理的核心环节,并在此基础上构建了一个支持记忆、工具调用和循环决策的智能体框架。
之前因为我们还不需要用到这个函数来使用Tools,所以当涉及Chain这个概念时还需要造下轮子,学下它怎么使用。
所以之后虽然我们不会再显式创建Chain,但实际上我们仍在沿用这种思想,这点可别忘掉。
输出结果:
输出成功。
这种通用Agent我们了解了,可以自由根据场景选择来自己DIY工具调用 ,是一个可扩展Agent框架。它足以应付我们绝大场景下的工具使用。但也有些场景用它来,得干很多脏活累活。这点Langchain也想到了,接下来介绍另一个特化Agent。
三、SQL专用Agent
领域专用 Agent 的封装要求极高:需场景广泛、接口标准、结构清晰。正因如此,真正合适的案例极少。
而 SQL 查询正是这样的完美范例 。
它高频、规范、结构明确,却重复繁琐。如果每次都手动构建工具链,效率将非常差。
create_sql_agent 正是为此而生------开箱即用,一键实现自然语言查数据库,大幅简化开发流程。
- 你不需要手动定义tools,只用给它一个db连接
- 它会自动"反思":先查表结构,再编写sql,执行sql,再根据结果回答
- 它的Prompt已经高度优化,能处理复杂的SQL逻辑。
代码编写如下:
ini
# 连接数据库 -- LangChain 使用 SQLAlchemy URI (连接方式)
db_uri = f'sqlite:///{db_file}'
db = SQLDatabase.from_uri(db_uri)
# 创建sqlAgent -- 一键完成,无需定义tools,仅告诉它使用openai-tools,即Tool Calling(工具调用)模式
agent_executor = create_sql_agent(
llm=llm,
db=db,
agent_type="openai-tools",
verbose=True
)
# 运行
response = agent_executor.invoke({"input":"告诉我Alice多大了?"})
print(response['output'])可以看出,我们仅配置了llm与db,其他啥都没干,就做好了sql_agent。
再来看看执行结果:
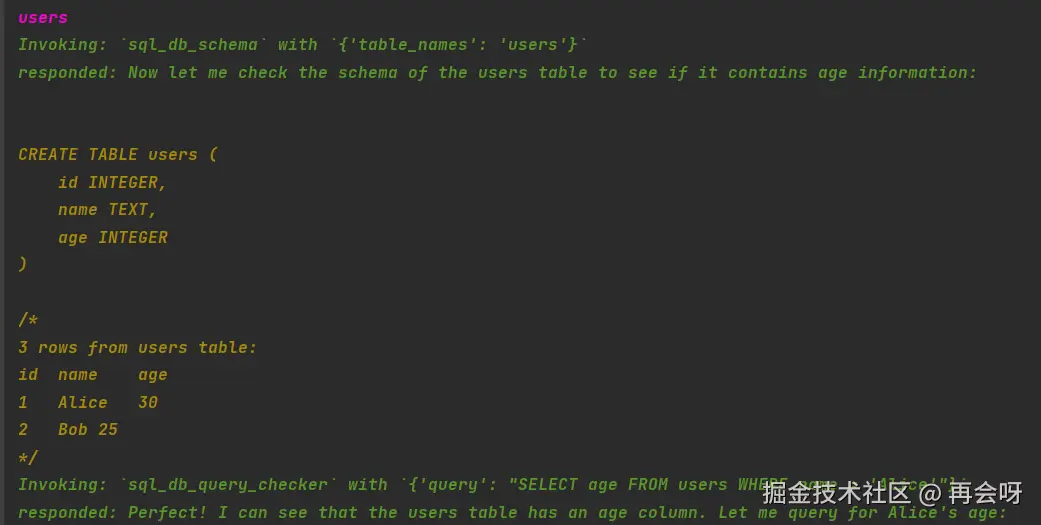
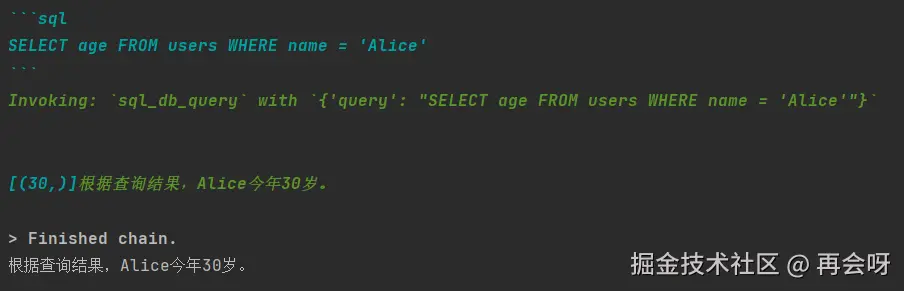
AI先是思考:我要查sql,再去表里编写对应sql语句。获得对应数据后,就会将查询结果输出。
四、融合工具与记忆
我们这篇文章05的Agent很智能,之前文章04的Chain有记忆。现在我们把二者合二为一,让它变得更高级。
就拿本模块的第二章的通用Agent为例,我们接着为其加入记忆功能。
ini
# 配置prompt(新增俩占位符 一个为对话历史记录,一个为agent的思考过程)
prompt = ChatPromptTemplate.from_messages([
('system','你是小智,一个帮助他人的智能助手。当你无法解答当前问题时,会调用工具来解决问题。'),
MessagesPlaceholder(variable_name="history"),
('human','{input}'),
MessagesPlaceholder(variable_name="agent_scratchpad")
])prompt这里就是俩占位符都需要,分别作为记忆 与工具查询使用。
python
# 配置tool
@tool
def get_weather(location):
"""模拟获得天气信息"""
return f"{location}当前天气:23℃,晴,风力2级"
tools = [get_weather]
# 配置agent
agent = create_tool_calling_agent(llm=llm,prompt=prompt,tools=tools)
# 配置AgentExecutor
agent_executor = AgentExecutor(agent=agent,tools=tools) # 这里没加verbose=True,想打印日志看思考链的可以自行打印tool配置如常。
到最终memory的位置,就由它来包裹所有其他的部件,当做一个长期存在的状态:
ini
# 记忆存储--包装agent_executor
store = {}
def get_session_history(session_id:str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
agent_with_memory = RunnableWithMessageHistory(
runnable=agent_executor,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="history"
)
ini
# 打印测试
session_id = 'user123'
if __name__ == '__main__':
while 1:
user_input = input('\n你:')
if user_input == 'quit':
print('拜拜~')
break
response = agent_with_memory.invoke(
{'input': user_input},
config={'configurable':{'session_id':session_id}}
)
print(f"AI:{response['output']}")测试结果:

很明显,此时的agent已经可以工具调用与持续记忆。
至此我们的Agents(工具调用代理)的知识点已基本掌握完毕。
五、高阶技巧:缓存&流式
我们所做的agent现在看起来已经非常不错了,但真正放到生产端还有俩致命问题:
其一、贵: 每次运行invoke都在烧钱;
其二、慢: 用户每次运行都必须等整个ReAct跑完才能得到想要的答案。
下面我们依次来解决这俩问题:
1. 缓存
想象这么个场景:
你写好了一个比较复杂的项目Agent,有七八个重要组件,你需要确定它们都能成功运行。于是你开始调试,调试了二三十次,确定满意没有问题了。接着一看llm的token调用:也花了二三十次的token钱...
所以我们就要引入缓存 这个概念:简单讲就是跳过llm调用 这一环节,优先保证其他所有模块测试没啥问题。等其他都完毕后再去掉缓存测试一遍llm调用,这样只用花费一次token调用的钱。
所以在开发测试时强烈推荐加入该功能。但真正在生产端环境必须去掉:毕竟它只是回答结果复用,没有任何智能。
使用方法也简单:
设置全局缓存
set_llm_cache(InMemoryCache())
scss
# 设置全局缓存
set_llm_cache(InMemoryCache())
# 第一次调用llm(会远程请求)
query = "用中文写一句关于猫的五言诗。"
start_time = time.time()
response1 = llm.invoke(query).content
print(f"第一次调用结果: {response1}")
print(f"第一次运行时间: {time.time() - start_time:.4f} 秒")
print('')
# 第二次调用llm(会命中缓存)
start_time = time.time()
response2 = llm.invoke(query).content
print(f"第二次调用结果: {response2}")
print(f"第二次运行时间 (已缓存): {time.time() - start_time:.4f} 秒")
# 清理
set_llm_cache(None) # 关闭缓存,以免影响后续实例
print('缓存清理完成')
如上,当缓存命中时几乎不费时,而且也不会调用token花钱。
但如果文件项目比较大时,这样一行的内存缓存还是有点不够用,推荐上个文件或者redis缓存。
2.流式
回想一下,当你在网页端用ai工具时,是否它们输出都是一点点排列给你看的?这就是流式输出,像流水一样。
而我们目前的输出必须得全部跑完才能返回看到答案,这明显不是我们想要的,接下来我们就为其加入流式输出:
ini
# 配置llm
llm = ChatOpenAI(
model="deepseek-chat",
api_key=api_key,
base_url="https://api.deepseek.com",
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()]
)这里llm注意下llm的配置:
streaming=True: 即允许流式输出;
callback=StreamingStdOutCallbackHandler(): 一个回调处理器,当LLM每生成一个token时,自动将其打印到终端上。
其他代码不用动,最后循环时稍微改一下:
ini
if __name__ == '__main__':
while 1:
user_input = input('\n你:')
if user_input == 'quit':
print('拜拜~')
break
# 用于标记"AI:"这个内容
# flush=True保证"AI:"立即输出,而不是等缓存区存满再输出
print("AI: ", end="", flush=True)
response = agent_with_memory.invoke(
{'input': user_input},
config={'configurable': {'session_id': session_id}}
)
print()这里已经不需要print了,因为我们之前搞callbacks已经做到生成token时自动打印到终端上。再print也只是重复输出。
同时之前我们的AI: 就需要单独列出来写一下,不能直接跟response一块输出了。

如图,流式输出成功。
六、总结
知识点概括 :Agent 构建 (ReAct & Tool-Calling)|特化 Agent (create_sql_agent)|Agent 与 Memory 融合|高阶技巧 (缓存 & 流式)
如果你能看到这里,那你真的很厉害了!
至此你已完成了整个Langchain 的学习。现有的工具已经完全足够你做90%+ 的智能体。
强烈建议在完成上述Langchain学习后,利用这些模块,自己试着做一个agent。难度也不高,把五大模块(llm,prompt,chain,memory,agnets)几个结合起来即可。
那么接下来就是另一个重头戏了:RAG
这玩意儿也是个狠角。当我们想接入数据库 ,真正超大文本量 ,正儿八经的企业级项目的时候,就必须引入这个模块的思想来做。比如企业自己的agent,要对接某些功能或数据库或本地文档时。
它的知识点与实战同样繁琐且复杂,但笔者仍会将其庖丁解牛式将其细分拆开,确保讲解透彻到位。收拾收拾,下篇进RAG接着干!