1. JSON Loader
1.1 原始的TextLoader加载
TextLoader 是 LangChain 中最基础的文本加载器,功能是按字符读取文件的原始内容,不解析文件格式(无论文件后缀是 .txt、.json 还是 .md)。对于 JSON 文件,它会直接读取 JSON 的原始字符串(包括 {}、""、逗号等语法符号),不会将其转换为 Python 字典或列表。
python
from langchain_community.document_loaders import TextLoader
print("=== TextLoader 加载结果 ===")
text_loader = TextLoader("../../90-文档-Data/灭神纪/人物角色.json",encoding="utf-8")
text_documents = text_loader.load()
print(text_documents)
1.2 JsonLoader
- 结构化提取:从 JSON 中精准筛选出需要的字段(姓名、背景),排除无关信息(如其他未提及的角色属性)。
- 格式化文本:将 JSON 字段拼接为自然语言文本(如 "姓名:XXX,背景:XXX"),无需大模型额外解析 JSON 格式,降低理解成本。
- 标准化输出:转换为 Document 对象后,可直接接入 LangChain 的分块、向量存储、检索等流程,无缝融入 RAG 系统。
从 JSON 文件中精准提取并格式化了所需的角色信息,最终转换为 LangChain 标准的 Document 对象,每个对象包含 page_content(文本内容)和 metadata(元数据)两部分。
python
from langchain_community.document_loaders import JSONLoader
print("=== JSONLoader 加载结果 ===")
print("1. 主角信息:")
main_loader = JSONLoader(
file_path="../../90-文档-Data/灭神纪/人物角色.json",
jq_schema='.mainCharacter | "姓名:" + .name + ",背景:" + .backstory',
text_content=True
)
main_char = main_loader.load()
print(main_char)
print("\n2. 支持角色信息:")
support_loader = JSONLoader(
file_path=r"../../90-文档-Data/灭神纪/人物角色.json",
jq_schema='.supportCharacters[] | "姓名:" + .name + ",背景:" + .background',
text_content=True,
)
support_chars = support_loader.load()
print(support_chars)
2. langchain的各种网页加载器

2.1 WebBaseLoader
使用 LangChain 的 WebBaseLoader 加载并解析网页内容,核心功能是从指定网页(维基百科《黑神话:悟空》词条)中提取信息,并通过配置只保留网页的主体内容,过滤掉广告、导航栏等无关元素。
python
# 使用WebBaseLoader加载网页
import bs4
from langchain_community.document_loaders import WebBaseLoader
page_url = "https://zh.wikipedia.org/wiki/黑神话:悟空"
# loader = WebBaseLoader(web_paths=[page_url])
# docs = []
# docs = loader.load()
# assert len(docs) == 1
# doc = docs[0]
# print(f"{doc.metadata}\n")
# print(doc.page_content.strip()[:3000])
# 只解析文章的主体部分
loader = WebBaseLoader(
web_paths=[page_url],
bs_kwargs={
"parse_only": bs4.SoupStrainer(id="bodyContent"),
},
# bs_get_text_kwargs={"separator": " | ", "strip": True},
)
docs = []
docs = loader.load()
assert len(docs) == 1
doc = docs[0]
print(f"{doc.metadata}\n")
print(doc.page_content)
2.2 UnstructuredLoader
python
# 使用UnstructuredLoader加载网页
from langchain_unstructured import UnstructuredLoader
page_url = "https://zh.wikipedia.org/wiki/黑神话:悟空"
loader = UnstructuredLoader(web_url=page_url)
docs = loader.load()
for doc in docs[:5]:
print(f'{doc.metadata["category"]}: {doc.page_content}')
UnstructuredLoader -- 父子元素的链接
python
from langchain_unstructured import UnstructuredLoader
from typing import List
from langchain_core.documents import Document
page_url = "https://zh.wikipedia.org/wiki/黑神话:悟空"
def _get_setup_docs_from_url(url: str) -> List[Document]:
loader = UnstructuredLoader(web_url=url)
setup_docs = []
parent_id = None # 初始化 parent_id
current_parent = None # 用于存储当前父元素
for doc in loader.load():
# 检查是否是 Title 或 Table
if doc.metadata["category"] == "Title" or doc.metadata["category"] == "Table":
parent_id = doc.metadata["element_id"]
current_parent = doc # 更新当前父元素
setup_docs.append(doc)
elif doc.metadata.get("parent_id") == parent_id:
setup_docs.append((current_parent, doc)) # 将父元素和子元素一起存储
return setup_docs
docs = _get_setup_docs_from_url(page_url)
for item in docs:
if isinstance(item, tuple):
parent, child = item
print(f'父元素 - {parent.metadata["category"]}: {parent.page_content}')
print(f'子元素 - {child.metadata["category"]}: {child.page_content}')
else:
print(f'{item.metadata["category"]}: {item.page_content}')
print("-" * 80)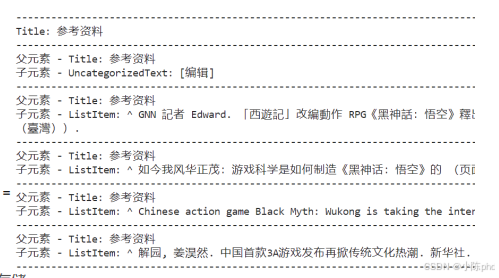
3.Markdown文档的解析
3.1 UnstructuredMarkdownLoader
UnstructuredMarkdownLoader 是 LangChain 中专门用于加载和解析 Markdown(.md)文件的加载器,底层基于 unstructured 库实现,核心优势是能理解 Markdown 的结构化语法 ,避免将 Markdown 当作纯文本处理,让解析结果更贴合原始文档的逻辑结构。结合你提供的代码(两种模式:默认模式 vs mode="elements"),其优势可拆解为以下 4 点,每点都对应实际使用场景:
-
原生支持 Markdown 语法解析,保留结构而非纯文本
普通加载器(如
TextLoader)会把 Markdown 文件当作纯文本,直接读取所有字符(包括#、*、|等语法符号),导致解析结果杂乱无章;而UnstructuredMarkdownLoader能识别 Markdown 的原生语法,自动提取结构化信息:- 识别标题层级(
# 一级标题、## 二级标题); - 识别列表(有序列表
1.、无序列表-/*); - 识别表格(
| 表头 | 内容 |); - 识别代码块(
python ...)、引用(>)等。
- 识别标题层级(
-
mode="elements"模式拆分独立元素,实现精细化处理这是最核心的优势!通过
mode="elements"可将 Markdown 按语法拆分为多个独立的Document对象(每个对象对应一个"元素"),每个元素都带类型标记,方便后续精准处理:- 元素类型包括:
Title(标题)、List(列表)、Table(表格)、CodeBlock(代码块)、NarrativeText(普通段落)等; - 每个
Document的metadata["category"]会标注元素类型,page_content是元素的具体内容。
- 元素类型包括:
-
自动处理编码和格式兼容,容错性强
- 编码兼容 :默认支持 UTF-8 编码(中文无乱码),无需手动指定
encoding参数(对比TextLoader常需显式设置encoding="utf-8"); - 格式容错:即使 Markdown 语法不规范(比如表格缺少分隔线、标题层级混乱),也能正常解析,不会因语法错误导致加载失败;
- 跨平台兼容 :无需担心 Windows/macOS/Linux 下的换行符(
\n/\r\n)差异,自动适配处理。
- 编码兼容 :默认支持 UTF-8 编码(中文无乱码),无需手动指定
-
无缝集成 LangChain 生态,支持进阶流程
解析后直接返回 LangChain 标准的
Document对象,可无缝对接后续所有 LangChain 流程,无需额外格式转换:- 分块:结合
RecursiveCharacterTextSplitter时,因元素已拆分,分块能更贴合逻辑(比如按标题-段落分组分块); - 向量存储:每个元素的
metadata(如category="Table"、source="文件路径")可作为检索时的筛选条件(比如只检索表格类型的文档); - 元数据保留:自动保留文件路径(
source)、元素类型(category)等元数据,便于追溯信息来源。
- 分块:结合
对比普通加载器(TextLoader)的核心差异
| 特性 | UnstructuredMarkdownLoader |
TextLoader(纯文本加载) |
|---|---|---|
| Markdown 语法识别 | 支持(识别标题、列表、表格等) | 不支持(当作纯文本,保留所有语法符号) |
| 解析结果结构 | 结构化(元素拆分/保留逻辑) | 非结构化(纯文本字符串) |
| 元数据丰富度 | 高(含元素类型、文件路径等) | 低(仅含文件路径) |
| 后续处理灵活性 | 高(可按元素类型筛选、精准分块) | 低(需手动清理语法、拆分结构) |
- 若只需快速获取 Markdown 的"可读文本"(用于直接作为上下文):用默认模式,自动去除语法符号,得到干净的文本;
- 若需精细化处理(比如提取所有表格、按标题分组存储):用
mode="elements"模式,拆分元素后针对性处理; - 若后续要构建 RAG 系统:其结构化解析和元数据保留能大幅提升检索精度,避免纯文本加载的冗余信息干扰。
简单说,UnstructuredMarkdownLoader 是"懂 Markdown 语法"的加载器,让 Markdown 文件的解析从"纯文本读取"升级为"结构化提取",是处理 Markdown 文档的最优选择之一。
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from io import StringIO
class EncodedUnstructuredMarkdownLoader(UnstructuredMarkdownLoader):
"""支持编码的 UnstructuredMarkdownLoader"""
def __init__(self, file_path: str, encoding: str = "utf-8", **kwargs):
super().__init__(file_path=file_path, **kwargs)
self.encoding = encoding
def _get_elements(self):
# 手动按指定编码读取文件
with open(self.file_path, "r", encoding=self.encoding) as f:
content = f.read()
# 转为文件对象传给父类解析
self.file_obj = StringIO(content)
return super()._get_elements()
# -------------------------- 使用自定义加载器 --------------------------
markdown_path = "../../90-文档-Data/黑悟空/黑悟空版本介绍.md"
# 默认模式
loader = EncodedUnstructuredMarkdownLoader(markdown_path, encoding="utf-8")
data = loader.load()
print("=== 默认模式(前250字符)===")
print(data[0].page_content[:250])
# mode="elements" 模式
loader_elements = EncodedUnstructuredMarkdownLoader(markdown_path, mode="elements", encoding="utf-8")
data_elements = loader_elements.load()
print(f"\nNumber of documents: {len(data_elements)}")
4. 解析图文数据
4.1 读取图片
python
from langchain_community.document_loaders import UnstructuredImageLoader
image_path = "../../90-文档-Data/黑悟空/黑悟空英文.jpg"
loader = UnstructuredImageLoader(image_path)
data = loader.load()
print(data)4.2 读取PPT
python
"""
Q: 在使用 unstructured 解析 PPT 等 Office 文件时,如果出现 FileNotFoundError: soffice command was not found 错误怎么办?
A: 这是因为系统中缺少 libreoffice。unstructured 需要调用 libreoffice 的 soffice 命令来处理 Office 文档。
解决方案是在系统中安装 libreoffice。
在 Debian/Ubuntu 系统中,可以使用以下命令安装:
sudo apt-get update && sudo apt-get install -y libreoffice
- Install instructions: https://www.libreoffice.org/get-help/install-howto/
- Mac: https://formulae.brew.sh/cask/libreoffice
- Debian: https://wiki.debian.org/LibreOffice
"""
from unstructured.partition.ppt import partition_ppt
# 解析 PPT 文件
ppt_elements = partition_ppt(filename="90-文档-Data/黑悟空/黑神话悟空.pptx")
print("PPT 内容:")
# for element in ppt_elements:
# print(element.text)
from langchain_core.documents import Document
# 转换为 Documents 数据结构
documents = [
Document(page_content=element.text,
metadata={"source": "data/黑神话悟空PPT.pptx"})
for element in ppt_elements
]
# 输出转换后的 Documents
print(documents[0:3])4.3 基于大模型读取图文
python
from pdf2image import convert_from_path
import base64
import os
from openai import OpenAI
# 初始化 OpenAI 客户端
client = OpenAI()
output_dir = "temp_images"
# 1. PDF 转图片
if not os.path.exists(output_dir):
os.makedirs(output_dir)
images = convert_from_path("90-文档-Data/黑悟空/黑神话悟空.pdf")
image_paths = []
for i, image in enumerate(images):
image_path = os.path.join(output_dir, f'page_{i+1}.jpg')
image.save(image_path, 'JPEG')
image_paths.append(image_path)
print(f"成功转换 {len(image_paths)} 页")
# 2. GPT-4o 分析图片
print("\n开始分析图片...")
results = []
for image_path in image_paths:
with open(image_path, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请详细描述这张PPT幻灯片的内容,包括标题、正文和图片内容。"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=300
)
results.append(response.choices[0].message.content)
# 3. 转换为 LangChain 的 Document 数据结构
from langchain_core.documents import Document
documents = [
Document(
page_content=result,
metadata={"source": "data/黑悟空/黑神话悟空.pdf", "page_number": i + 1}
)
for i, result in enumerate(results)
]
# 输出所有生成的 Document 对象
print("\n分析结果:")
for doc in documents:
print(f"内容: {doc.page_content}\n元数据: {doc.metadata}\n")
print("-" * 80)
# 清理临时文件
for image_path in image_paths:
os.remove(image_path)
os.rmdir(output_dir)5. PDF文件解析
除此之外还有:
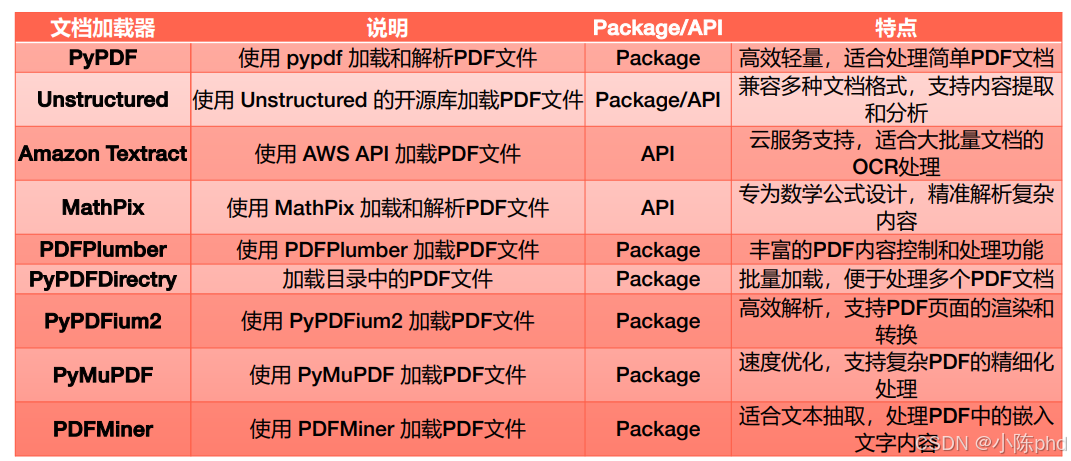
LlamaParse:深度 PDF 结构解析工具,针对法律合同、学术论文等场景,解析精度高,但属于商业 API。Mineru:多模态集成解析工具,结合 LayoutLMv3 + YOLOv8 技术,适合学术文献、财务报表等多元素融合的 PDF 处理。FireCrawlLoader:专注网页内容抓取,可将在线 PDF 文档实时转换为可处理的结构化数据。Google Cloud Vision API:谷歌云提供的 OCR 服务,支持 PDF 扫描件的高精度文本识别,适合企业级大规模文档处理。Azure AI Document Intelligence:微软云的文档智能服务,能解析 PDF 中的文本、表格、表单等复杂结构,还支持自定义模型训练。
三大类解析方法:
• 基于规则的解析
• 基于深度学习的解析
• 基于多模态大模型的解析
执行以下操作:
• 通过启发式方法或机器学习推理将文本框聚合为行、段落或其他结构;
• 对图像运行OCR,以检测其中的文本;
• 将文本分类为段落、列表、表格或其他结构;
• 将文本组织成表格的行和列,或以键值对的形式呈现
5.1 基于PyPDFLoader读取PDF
python
from langchain_community.document_loaders import PyPDFLoader
file_path = "90-文档-Data/黑悟空/黑神话悟空.pdf"
loader = PyPDFLoader(file_path)
pages = loader.load()
print(f"加载了 {len(pages)} 页PDF文档")
for page in pages:
print(page.page_content)5.2 基于Unstructured 提取文档结构
python
file_path = ("90-文档-Data/山西文旅/云冈石窟-en.pdf")
from langchain_unstructured import UnstructuredLoader
loader = UnstructuredLoader(
file_path=file_path,
strategy="hi_res",
# partition_via_api=True,
# coordinates=True,
)
docs = []
for doc in loader.lazy_load():
docs.append(doc)
def extract_basic_structure(docs):
"""基础结构化提取:按文档类型组织内容"""
# 定义类别映射
category_map = {
'Title': 'title',
'NarrativeText': 'text',
'Image': 'image',
'Table': 'table',
'Footer': 'footer',
'Header': 'header'
}
# 初始化结构字典
structure = {cat: [] for cat in category_map.values()}
structure['metadata'] = [] # 额外添加metadata类别
# 遍历文档并分类
for doc in docs:
category = doc.metadata.get('category', 'Unknown')
content = {
'content': doc.page_content,
'page': doc.metadata.get('page_number'),
'coordinates': doc.metadata.get('coordinates')
}
target_category = category_map.get(category)
if target_category:
structure[target_category].append(content)
return structure
# 使用示例
structure = extract_basic_structure(docs)
# 输出第2页的标题
print("第2页标题:")
for title in [t for t in structure['title'] if t['page'] == 2]:
print(f"- {title['content']}")
def analyze_layout(docs):
"""分析文档的版面布局结构"""
layout_analysis = {}
for doc in docs:
page = doc.metadata.get('page_number')
coords = doc.metadata.get('coordinates', {})
# 初始化页面信息
if page not in layout_analysis:
layout_analysis[page] = {
'elements': [],
'dimensions': {
'width': coords.get('layout_width', 0),
'height': coords.get('layout_height', 0)
}
}
# 获取元素位置信息
points = coords.get('points', [])
if points:
# 只需要左上和右下坐标点
(x1, y1), (_, _), (x2, y2), _ = points
# 构建元素信息
element = {
'type': doc.metadata.get('category'),
'content': (doc.page_content[:50] + '...') if len(doc.page_content) > 50 else doc.page_content,
'position': {
'x1': x1, 'y1': y1,
'x2': x2, 'y2': y2,
'width': x2 - x1,
'height': y2 - y1
}
}
layout_analysis[page]['elements'].append(element)
return layout_analysis
# 使用示例
layout = analyze_layout(docs)
# 分析第一页的布局
print("第1页布局分析:")
if 1 in layout:
page = layout[1]
print(f"页面尺寸: {page['dimensions']['width']} x {page['dimensions']['height']}")
print("\n元素分布:")
# 按垂直位置排序显示元素
for elem in sorted(page['elements'], key=lambda x: x['position']['y1']):
print(f"\n类型: {elem['type']}")
print(f"位置: ({elem['position']['x1']:.0f}, {elem['position']['y1']:.0f})")
print(f"尺寸: {elem['position']['width']:.0f} x {elem['position']['height']:.0f}")
print(f"内容: {elem['content']}")
# 寻找父子关系
cave6_docs = []
parent_id = -1
for doc in docs:
if doc.metadata["category"] == "Title" and "Cave 6" in doc.page_content:
parent_id = doc.metadata["element_id"]
if doc.metadata.get("parent_id") == parent_id:
cave6_docs.append(doc)
for doc in cave6_docs:
print(doc.page_content)
external_docs = [] # 创建列表来存储外部链接的子文档
parent_id = -1 # 初始化父ID为-1
for doc in docs:
# 检查文档是否为标题类型且内容包含"External links"
if doc.metadata["category"] == "Title" and "External links" in doc.page_content:
parent_id = doc.metadata["element_id"]
external_docs.append(doc)
# 检查文档的parent_id是否匹配我们找到的标题ID
if doc.metadata.get("parent_id") == parent_id:
external_docs.append(doc) # 将属于这个标题的子文档都添加到结果列表中
for doc in external_docs:
print(doc.page_content)
# def find_tables_and_titles(docs):
# results = []
# for doc in docs:
# # 检查文档是否为表格类型
# if doc.metadata.get("category") == "Table":
# table = doc
# parent_id = doc.metadata.get("parent_id")
# # 查找表格对应的标题文档(parent_id匹配element_id)
# title = next((doc for doc in docs if doc.metadata.get("element_id") == parent_id), None)
# if title:
# results.append({"table": table.page_content, "title": title.page_content})
# return results
# results = find_tables_and_titles(cave6_docs)
# if results:
# for result in results:
# print("找到的表格和标题:")
# print(f"标题: {result['title']}")
# print(f"表格: {result['table']}")
# else:
# print("未找到任何表格和标题")5.3 扫描类PDF
python
# 扫描图片型 PDF,建议用 pytesseract + pdf2image
# sudo apt-get install tesseract-ocr
# sudo apt-get install tesseract-ocr-chi-sim
import pdf2image
import pytesseract
import os
# 创建 output 目录
output_dir = 'output'
os.makedirs(output_dir, exist_ok=True)
# 将 PDF 转换为图片并保存
images = pdf2image.convert_from_path('90-文档-Data/黑悟空/黑神话悟空.pdf')
for i, image in enumerate(images):
image.save(f'{output_dir}/page_{i+1}.png')
# 使用 pytesseract 提取文本
for i, image in enumerate(images):
text = pytesseract.image_to_string(image, lang='chi_sim')
print(f"第 {i+1} 页文本:")
print(text)
print("\n") 5.4 LlamaParser
python
# 需要LLAMA_CLOUD_API_KEY
from dotenv import load_dotenv
load_dotenv()
# LlamaParse PDF reader for PDF Parsing
from llama_parse import LlamaParse
documents = LlamaParse(result_type="markdown").load_data(
"90-文档-Data/黑悟空/黑神话悟空.pdf"
)
print(documents)
from llama_index.core.node_parser import MarkdownElementNodeParser
node_parser = MarkdownElementNodeParser()
nodes = node_parser.get_nodes_from_documents(documents)
print(nodes)6. 导入CSV表格数据
6.1 DirectoryLoader加载表格数据
python
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import CSVLoader
loader = DirectoryLoader(
path="data/黑神话", # Specify the directory containing your CSV files
glob="**/*.csv", # Use a glob pattern to match CSV files
loader_cls=CSVLoader # Specify CSVLoader as the loader class
)
docs = loader.load()
print(f"文档数:{len(docs)}") # 输出文档总数
print(docs[0])6.2 camelot提取表格数据
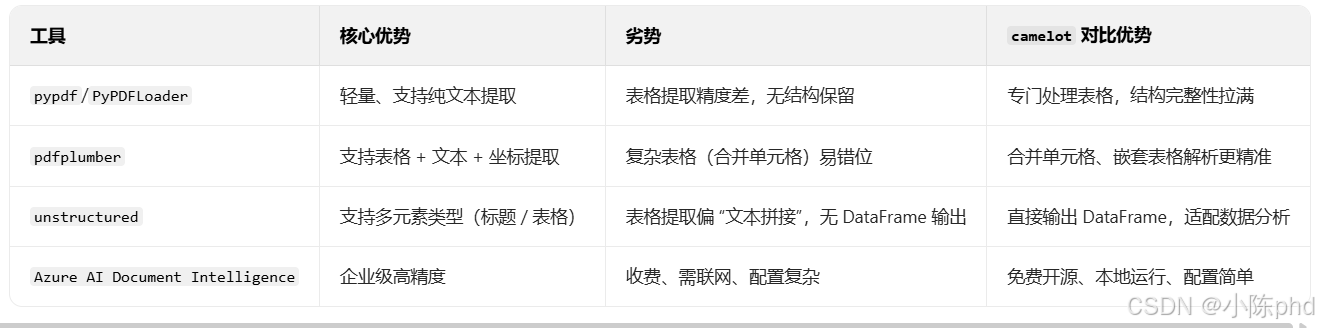
camelot 是 PDF 表格提取领域的「专业工具」,「规则驱动 + 传统计算机视觉」的典型代表,相比 pypdf、pdfplumber 等通用 PDF 工具,它对表格的识别逻辑更精细:
- 支持 带边框 / 无边框表格:即使表格没有明确边框(仅靠对齐分隔),也能通过文本位置、间距识别列边界;
- 处理 合并单元格、跨列 / 跨行表格:能正确解析 PDF 中常见的合并单元格(如表头合并),不会拆分或错乱数据;
- 识别 多列嵌套表格:复杂 PDF 中 "表格内套表格" 的场景(如财务报表、统计报告),camelot 能精准拆分层级;
- 保留 表格结构完整性:提取后的数据行列对应关系与 PDF 完全一致,不会出现 "列错位""行遗漏"(这是通用工具最容易出问题的点)。
- 对复杂表格的提取精度极高(尤其是结构化表格、多页表格、带边框 / 合并单元格的表格),且能直接转为 pandas.DataFrame 进行数据分析 / 保存。以下是其核心优势、适用场景及对比其他工具的亮点:
python
import camelot
import pandas as pd
# from ctypes.util import find_library
# find_library("gs")
pdf_path = "90-文档-Data/复杂PDF/billionaires_page-1-5.pdf"
import time
start_time = time.time()
tables = camelot.read_pdf(pdf_path, pages="all")
end_time = time.time()
print(f"PDF表格解析耗时: {end_time - start_time:.2f}秒")
# 转换所有表格为 DataFrame
if tables:
# 遍历所有表格
for i, table in enumerate(tables, 1):
# 将表格转换为 DataFrame
df = table.df
# 打印当前表格数据
print(f"\n表格 {i} 数据:")
print(df)
# 显示基本信息
print(f"\n表格 {i} 基本信息:")
print(df.info())
# 保存到CSV文件
csv_filename = f"billionaires_table_{i}.csv"
df.to_csv(csv_filename, index=False)
print(f"\n表格 {i} 数据已保存到 {csv_filename}")6.3 解析表格数据
基于 unstructured表格提取+上下文 实现表格提取
python
from unstructured.partition.pdf import partition_pdf
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# 全局设置
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
# 解析 PDF 结构,提取文本和表格
file_path = "90-文档-Data/复杂PDF/billionaires_page-1-5.pdf" # 修改为你的文件路径
elements = partition_pdf(
file_path,
# strategy="hi_res", # 使用高精度策略
) # 解析PDF文档
# 创建一个元素ID到元素的映射
element_map = {element.id: element for element in elements if hasattr(element, 'id')}
# 创建一个元素索引到元素的映射
element_index_map = {i: element for i, element in enumerate(elements)}
for i, element in enumerate(elements):
if element.category == "Table":
print("\n表格数据:")
print("表格元数据:", vars(element.metadata)) # 使用vars()显示所有元数据属性
print("表格内容:")
print(element.text) # 打印表格文本内容
# 获取并打印父节点信息
parent_id = getattr(element.metadata, 'parent_id', None)
if parent_id and parent_id in element_map:
parent_element = element_map[parent_id]
print("\n父节点信息:")
print(f"类型: {parent_element.category}")
print(f"内容: {parent_element.text}")
if hasattr(parent_element, 'metadata'):
print(f"父节点元数据: {vars(parent_element.metadata)}")
else:
print(f"未找到父节点 (ID: {parent_id})")
# 打印表格前3个节点的内容
print("\n表格前3个节点内容:")
for j in range(max(0, i-3), i):
prev_element = element_index_map.get(j)
if prev_element:
print(f"节点 {j} ({prev_element.category}):")
print(prev_element.text)
print("-" * 50)
text_elements = [el for el in elements if el.category == "Text"]
table_elements = [el for el in elements if el.category == "Table"]基于 pdfplumber提取PDF表格并问答
python
import pdfplumber
import pandas as pd
from llama_index.core import VectorStoreIndex
from llama_index.core import Document
from typing import List
pdf_path = "90-文档-Data/复杂PDF/billionaires_page-1-5.pdf"
# 打开 PDF 并解析表格
with pdfplumber.open(pdf_path) as pdf:
tables = []
for page in pdf.pages:
table = page.extract_table()
if table:
tables.append(table)
# 转换所有表格为 DataFrame 并构建文档
documents: List[Document] = []
if tables:
# 遍历所有表格
for i, table in enumerate(tables, 1):
# 将表格转换为 DataFrame
df = pd.DataFrame(table)
# 保存到CSV文件
# csv_filename = f"billionaires_table_{i}.csv"
# df.to_csv(csv_filename, index=False)
# print(f"\n表格 {i} 数据已保存到 {csv_filename}")
# 将DataFrame转换为文本
text = df.to_string()
# 创建Document对象
doc = Document(text=text, metadata={"source": f"表格{i}"})
documents.append(doc)
# 构建索引
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎
query_engine = index.as_query_engine()
# 示例问答
questions = [
"2023年谁是最富有的人?",
"最年轻的富豪是谁?"
]
print("\n===== 问答演示 =====")
for question in questions:
response = query_engine.query(question)
print(f"\n问题: {question}")
print(f"回答: {response}")| 工具 | 核心定位 | 提取精度(原生文本+带边框) | 提取精度(原生文本+无边框) | 提取精度(扫描件/扭曲/模糊) | 复杂表格支持(合并/嵌套) | 结构化输出 | 部署依赖 | 生态适配(LangChain/LlamaIndex) | 适用文件类型 | 核心优势 | 核心局限 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| pypdf | 基础文本提取(表格粗提) | 低 | 极低 | 无 | 无 | 纯文本(需手动拆分行列) | 无任何依赖 | 需手动转 Document | 原生文本型 PDF | 极致轻量、速度最快、部署零成本 | 仅支持极简表格,无结构还原能力 |
| pdfplumber | 轻量表格提取(平衡之选) | 中高 | 中 | 无 | 良好(简单合并可行,复杂嵌套一般) | 二维列表(直接转 DataFrame) | 无额外依赖 | 需手动转 Document | 原生文本型 PDF | 轻量无依赖、容错性强、API 简洁、易上手 | 复杂嵌套表格精度有限,不支持扫描件 |
| Camelot | 专业表格提取(带边框最优) | 高(最优) | 中(需手动调参) | 无 | 优秀(带边框场景最优,无边框需调参) | DataFrame(原生支持) | 依赖 Ghostscript | 需手动转 Document | 原生文本型 PDF | 带边框复杂表格还原度第一、批量提取高效 | 不支持扫描件/扭曲表格,无边框复杂表格需调参 |
| Unstructured | 多元素结构化(表格+文本) | 中高 | 中高 | 中(需启用 OCR) | 一般(简单合并可行,复杂嵌套较弱) | 表格元素对象(需手动转 DataFrame) | 轻量(可选 OCR 依赖) | 原生支持(自动转 Document) | 原生文本型/扫描件 PDF、图片、Word | 一站式多元素处理、支持 OCR、层级关联、生态友好 | 纯表格精度略逊,复杂嵌套表格处理能力有限 |
| LayoutLM | 深度学习(噪声表格克星) | 高 | 高(最优) | 高(最优) | 优秀(全场景复杂表格适配) | 结构化字典(需手动转 DataFrame) | 依赖 GPU + OCR 工具 | 需手动适配 | 扫描件/扭曲/模糊 PDF、原生文本型 PDF | 噪声容忍性强、复杂表格泛化能力强 | 部署复杂、需 GPU、推理耗时、上手门槛高 |
| Azure AI Document Intelligence | 企业级高精度(零代码) | 高 | 高(最优) | 高(最优) | 优秀(全场景复杂表格适配) | DataFrame/JSON(API 输出) | 无本地依赖(云端服务) | 支持 API 对接 | 所有类型(原生/扫描件/多语言) | 零代码、高精度、大规模处理、多场景适配 | 收费、需联网、无本地部署 |