langchain已于10月底发布了正式版的v1版本。本次我们主要讨论的是其中的两个比较容易混淆的组件。它们都带有runtime这个字眼。根据目前的情况来看,很多人会把这两个内容混淆了。
首先上官网的对于这两个组件的介绍。
Runtime:
- langchain : docs.langchain.com/oss/python/...
- langgraph : docs.langchain.com/oss/python/...
ToolRuntime:
其实是比较乱的,尤其是Runtime分散在langchain和langgraph两个文档中。
Runtime
首先介绍一下这个Runtime。 严格来说,这个Runtime是在langgraph 0.6版本就引入了的。但是在v1版本中langchain对其底层进行了重写,具体是agent模块采用langgraph进行编排。故Runtime也能够在langchain中使用,不过这个一般是用在middleware中的,因为这个是唯一一个能够让开发者灵活定义业务逻辑的地方。 Runtime总共有以下几个比较重要的属性:
- context
- store
- stream_writer
- previous
下面一个一个介绍,首先是这个大家都不太了解但是作用非常大的Context。
Context
Context 主要用于在图运行时传递静态数据,其核心定位是替代原有的 RunnableConfig 机制。在此之前要向图传递一些数据比较麻烦,常见的方案存在以下问题:
-
直接使用
state:不够优雅,因为state通常需要在后续图运行中被处理 -
使用 RunnableConfig的
configurable属性 :存在类型安全隐患。由于configurable是一个字典,在 Python 这种动态语言中:- 访问不存在的键会导致
KeyError,即使用get()方法避免异常,也会因为这个键值不存在而有别的问题。 - 获取到的值类型未知,缺乏编辑器的静态类型检查
- 无法设置默认值。
- 访问不存在的键会导致
Context 的优势
Runtime 本质是一个泛型类,使用 Runtime[Type] 的形式来标注特定类型的运行时实例。这里的 Type 通常是一个 Python 数据类(dataclass),代表的就是这个Context。即你可以认为是Runtime[Type[Context]],因为这是一个泛型,故编辑器可以靠这个推断类型。同时你也可以从这里知道,要定义一个Context其实就是写一个Python数据类(其实Pydantic的模型类应该是可以的,不过官网一直用的是数据类)。因为这是一个数据类,因此最终实例化的就是一个对象,而数据类实例对象的每个属性的类型编辑器是完全可以知道的这是数据类对象的特点。故可以有效的解决类型的问题。在后面的例子中,你会知道如何灵活的使用Context。
Store
store是用于存储持久化的内容的,即你compile一个graph时候可以选择性的传入的那个store。
stream_writer
stream_write则是在流式的时候传递一些自定义的响应数据的。这个时候需要设置stream_mode取值有"custom"。
Previous
这个属性用处不大,是记录上一个node运行的结果的。
ToolRuntime
阅读到这,相信很多读者会有一个问题,Runtime很强大,但是为啥官方还要定义一个ToolRuntime,它们两之间有啥区别? 回答这个问题的时候,我们先想一下这个Runtime直接用到tools中会有啥问题。第一个问题,没有办法获取state,因为它没有这个属性,第二个问题没有办法获取这个tool_call_id。故针对这些问题官方才搞了一个ToolRuntime,顾名思义,就是给tools中使用的。 这个ToolRuntime除了有上面所说的Context、Store、Stream_write以外还有两个比较重要的属性:
State
这个是langgraph中非常重要的概念,在node中呢,往往我们第一个参数就是这个state,而tools一般前面几个参数是给大模型准备的,有它们传递,在没有ToolRuntime的时候,要获取state很麻烦,要使用Inject注解获取。
ToolCallID
每个工具调用都会有对应的ID,在没有ToolRuntime的时候,要获取ToolCallID也很麻烦,要么是遍历state中的messages列表,要么是使用Inject注解获取。
同时如果你要同时获取这两个非常重要的内容,那么一般你需要写两个Inject,这样非常麻烦。于是在v1版本,官方给你加了个ToolRuntime。
使用示例
相信,读到这里你对这两个新的API已经有一定的了解了吧,于是我们开始一个示例,熟悉其使用方法。
当然,在阅读下面的示例的内容你需要注意2点
- 本次的示例使用的大模型是qwen,通过
langchain-dev-utils(tbice123123.github.io/langchain-d...)提供的方法接入。 - 请确保langgraph是最新的版本(1.0.2)否则会有ToolRuntime无法使用的问题,这个问题,官方已经解决(github.com/langchain-a...)
首先放一下核心的代码
python
import json
from typing import Literal
from dataclasses import dataclass
from langchain.tools import ToolRuntime, tool
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph.message import MessagesState
from langgraph.graph.state import StateGraph
from langgraph.prebuilt import ToolNode
from langgraph.runtime import Runtime
from langchain_dev_utils.chat_models import register_model_provider, load_chat_model
from dotenv import load_dotenv
from langgraph.types import Command
from langchain_dev_utils.tool_calling import has_tool_calling
load_dotenv()
register_model_provider(
"dashscope",
"openai-compatible",
)
class State(MessagesState):
pass
data = [
{"id": 1, "book_name": "《大模型应用开发》", "user_id": 1, "price": 100},
{"id": 2, "book_name": "《深度学习》", "user_id": 2, "price": 120},
{"id": 3, "book_name": "《综合人工智能》", "user_id": 3, "price": 200},
{"id": 4, "book_name": "《人工智能》", "user_id": 1, "price": 30},
{"id": 5, "book_name": "《小王子》", "user_id": 1, "price": 50},
]
@dataclass
class User:
user_id: int = 1
user_name: str = "张三"
@tool
def get_book_with_price_range(
low: int,
high: int,
runtime: ToolRuntime[User],
):
"""根据价格范围和用户id(无需提供)查询书籍"""
user_id = runtime.context.user_id
return json.dumps(
[
book
for book in data
if low <= book["price"] <= high and book["user_id"] == user_id
]
)
async def call_model(
state: State, runtime: Runtime[User]
) -> Command[Literal["tool_node", "__end__"]]:
model = load_chat_model("dashscope:qwen-flash").bind_tools(
tools=[get_book_with_price_range]
)
user = runtime.context.user_name
response = await model.ainvoke(
[
SystemMessage(
content=f"你是一个数据库管理员,可以针对用户**{user}**需求进行查询"
),
*state["messages"],
]
)
if has_tool_calling(response):
return Command(goto="tool_node", update={"messages": [response]})
return Command(goto="__end__", update={"messages": [response]})
tool_node = ToolNode([get_book_with_price_range])
graph = StateGraph(State, context_schema=User)
graph.add_node("call_model", call_model)
graph.add_node("tool_node", tool_node)
graph.set_entry_point("call_model")
graph.add_edge("tool_node", "call_model")
agent = graph.compile()
async def main():
response = await agent.ainvoke(
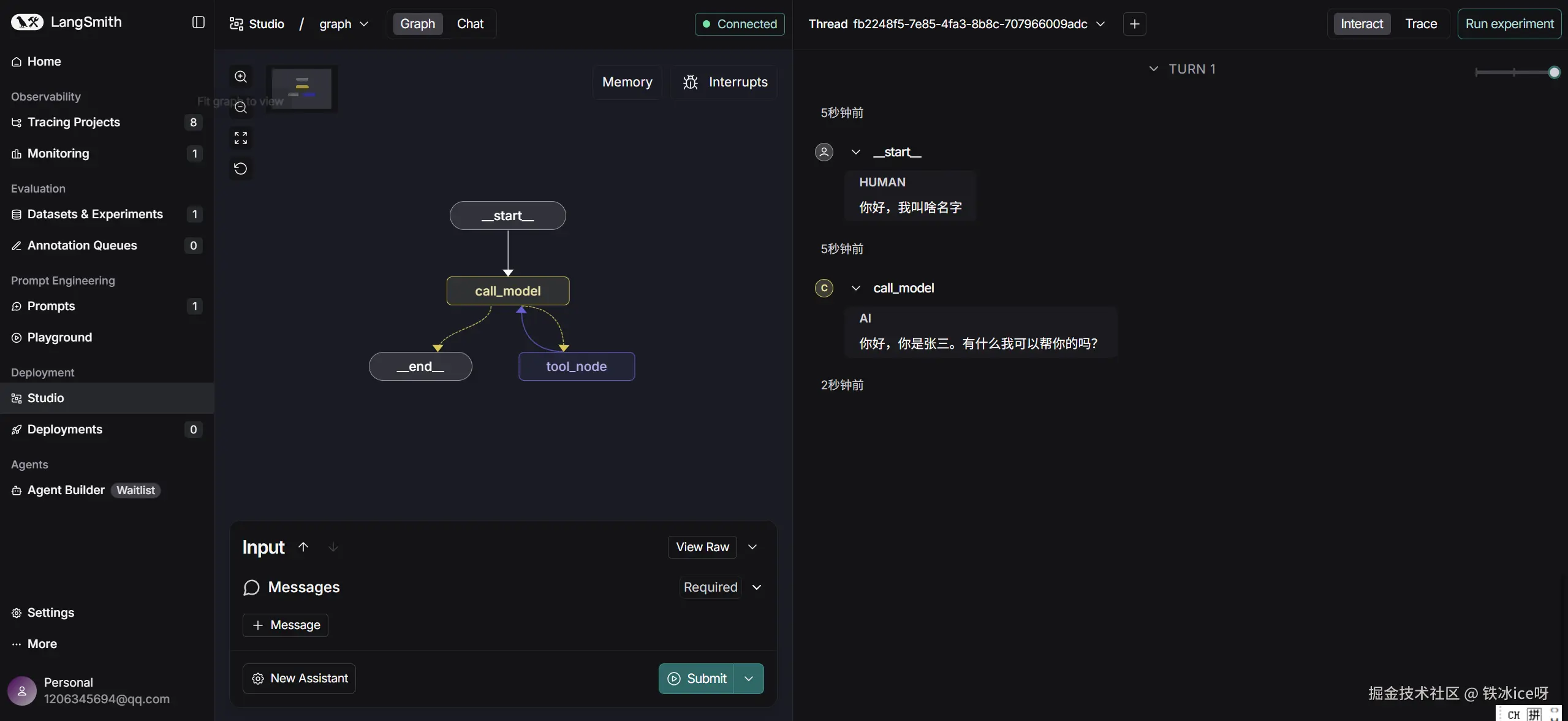
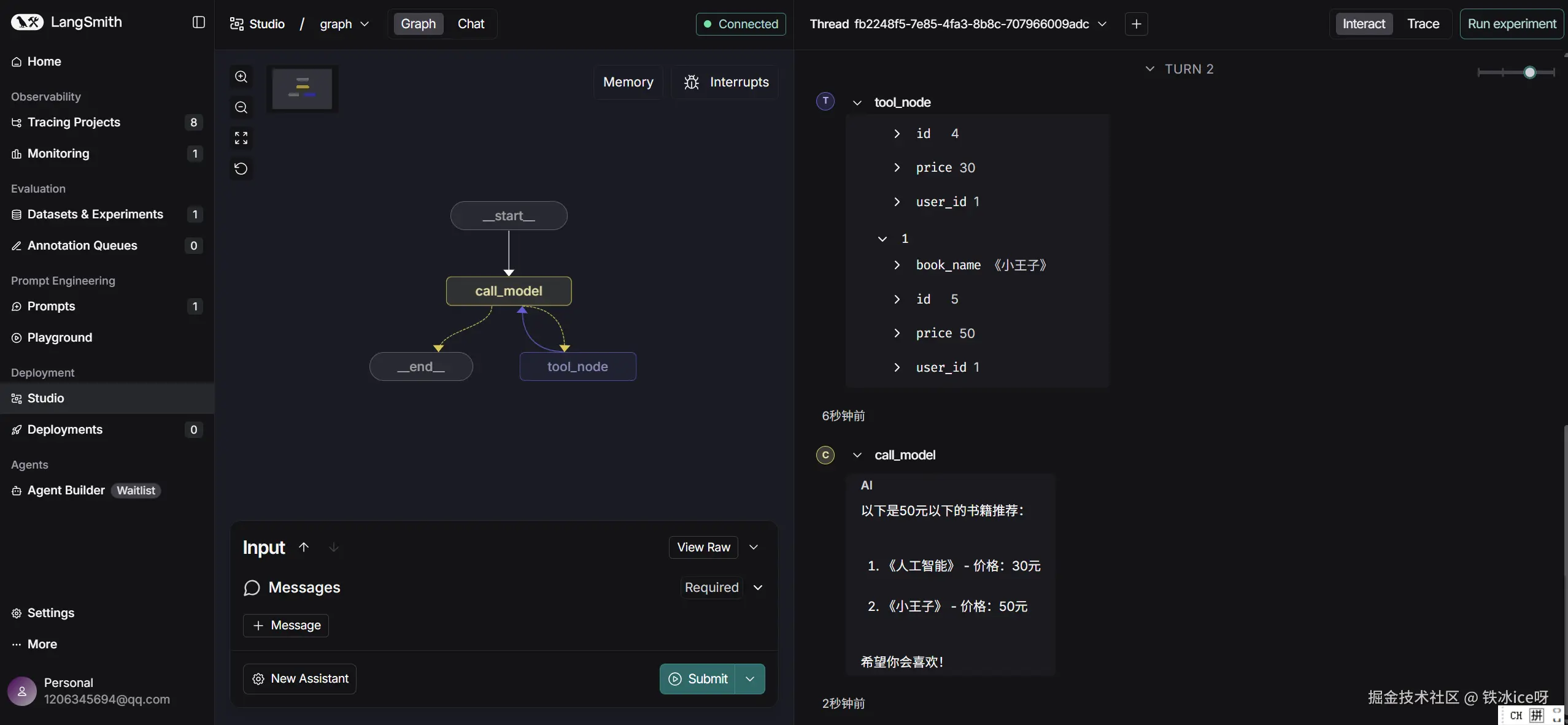
{"messages": [HumanMessage(content="我叫啥名字")]},
context=User(),
)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())对于上述代码你需要注意的是:
python
async def call_model(
state: State, runtime: Runtime[User]
) -> Command[Literal["tool_node", "__end__"]]:这里我们使用了Runtime,你可以看到这个是在节点中定义的,不过这里提醒一下,最好这个变量名称就叫做runtime,不要叫做别的。因为当我们叫做别的比如说run_time,编辑器会报错:
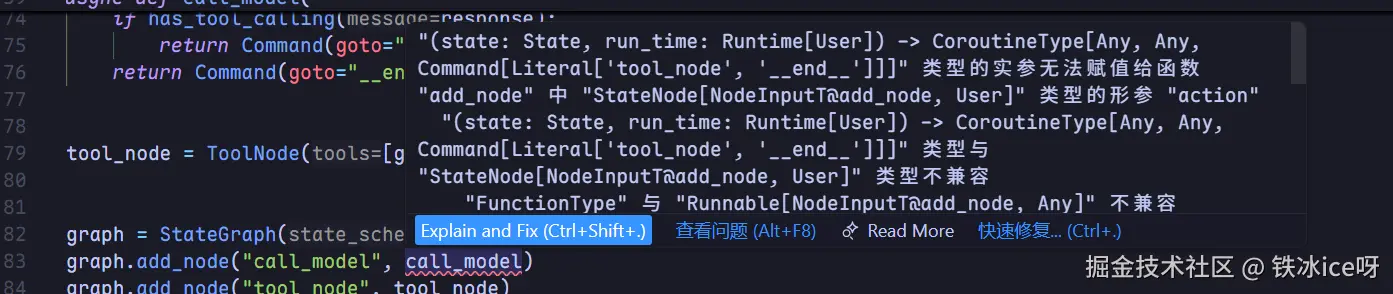
且你运行也会报错的。 TypeError: call_model() missing 1 required positional argument: 'run_time' During task with name 'call_model' and id 'b49d3528-71ac-c8c1-c2ab-9b43c7710af6' 当然具体为啥得仔细看源码,不过langgraph的源码比较复杂有点难看懂,所以建议最好就命名为runtime,你看官方文档也是这样写的。 不过类型报错的原因很好解释,因为这个node的类型是一个协议类。
python
class _NodeWithRuntime(Protocol[NodeInputT_contra, ContextT]):
def __call__(
self, state: NodeInputT_contra, *, runtime: Runtime[ContextT]
) -> Any: ...故一般第一个名称是state,第二个名称是runtime。
运行时候报错就很离谱,按理来说它是有识别具体类型的代码的。
同样对于ToolRuntime也尽可能的命名为runtime。
python
def get_book_with_price_range(
low: int,
high: int,
runtime: ToolRuntime[User],
):其实从源码来看好像它是可以识别类型的,但是确实定义为别的名字也会报错。
python
full_schema = tool.get_input_schema()
for name, type_ in get_all_basemodel_annotations(full_schema).items():
# Check if the parameter name is "runtime" (regardless of type)
if name == "runtime":
return name
# Check if the type itself is ToolRuntime (direct usage)
if _is_injection(type_, ToolRuntime):
return name
# Check if ToolRuntime is in Annotated args
injections = [
type_arg
for type_arg in get_args(type_)
if _is_injection(type_arg, ToolRuntime)
]
if len(injections) > 1:
msg = (
"A tool argument should not be annotated with ToolRuntime more than "
f"once. Received arg {name} with annotations {injections}."
)
raise ValueError(msg)
if len(injections) == 1:
return name第三点,就是默认值问题,这个例子我们使用了两个静态数据,user_name和user_id,user_name在node中被作为system_message传递进去,而user_id则是在工具中使用。 但是你可以发现的是我传递的是User()没有传入任何具体的名字和id,这个其实不是Context带来的好处,而是数据类本身的好处。 运行结果:


在langsmith studio中: