本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。

今天,我们将通过五个关键步骤,带您从零开始掌握Dify与LangChain v1.0的集成技术,构建属于自己的企业级RAG应用。
Dify核心功能解析:低代码开发的强大引擎
Dify作为开源的LLM应用开发平台,其核心优势在于将复杂的AI工程能力封装为直观的可视化工具。在集成LangChain时,以下特性尤为关键:
可视化工作流编排允许开发者通过拖拽节点构建复杂AI流程。Dify的Chatflow引擎支持条件分支、循环逻辑和并行任务处理,这意味着即使是非技术人员也能设计出包含RAG检索、工具调用和多模型协作的高级应用。例如,在客服场景中,可轻松配置"用户提问→意图识别→知识库检索→LLM生成→多渠道分发"的完整流程。
模型网关功能解决了多模型管理的痛点。Dify支持OpenAI、Anthropic、Llama等数百种模型的统一接入,通过标准化API抽象,使LangChain调用不同模型时无需修改代码。某电商平台利用此特性,在促销高峰期自动将简单查询切换至开源模型,复杂推理保留GPT-4,使成本降低40%同时保持服务质量。
RAG引擎经过深度优化,支持20+文档格式解析和混合检索策略。Dify的父子分段技术将文档拆分为语义块(父段)和细节块(子段),结合BM25关键词检索与向量检索,使召回率提升25%。在代码实现中,只需通过几行配置即可启用这一高级特性:
ini
# Dify RAG配置示例(需dify-client==1.9.1)
from dify_client import DifyClient
client = DifyClient(api_key="your_api_key")
client.knowledge.create_dataset(
name="企业知识库",
retrieval_strategy="hybrid", # 混合检索模式
chunking_strategy={
"mode": "semantic",
"parent_chunk_size": 500,
"child_chunk_size": 100,
"overlap_rate": 0.15
}
)Agent框架支持Function Calling与ReAct模式,内置50+工具集成。通过Dify的工具市场,可一键添加LangChain的各种工具能力,如SerpAPI搜索、WolframAlpha计算等,为智能体扩展丰富的外部能力。
LangChain v1.0新特性解读:构建生产级Agent的利器
2025年10月发布的LangChain v1.0带来了架构层面的重大革新,这些变化深刻影响了与Dify的集成方式:
统一Agent抽象 是最显著的更新。v1.0将原有的各类Chain和Agent统一为基于LangGraph构建的 create_agent 接口,大幅简化了复杂逻辑的实现。与旧版相比,代码量减少60%:
python
# LangChain v1.0 Agent创建(需langchain==1.0.0)
from langchain.agents import create_agent
from langchain_anthropic import ChatAnthropic
# 定义工具
def get_weather(location: str) -> str:
"""获取指定位置的天气信息"""
return f"{location}的天气是晴朗的"
# 创建Agent(少于10行代码)
model = ChatAnthropic(model="claude-3-5-sonnet-20241022")
agent = create_agent(
model=model,
tools=[get_weather],
system_prompt="你是一个有帮助的AI助手"
)
# 执行
result = agent.invoke({"messages": [{"role": "user", "content": "北京天气如何?"}]})中间件机制 为Agent提供了强大的扩展能力。开发者可通过 middleware 参数注入通用逻辑,如对话摘要、敏感信息过滤、工具权限控制等。例如,添加对话摘要中间件解决长对话上下文超限问题:
ini
from langchain.agents.middleware import summarization_middleware
agent = create_agent(
model=model,
tools=[get_weather],
middleware=[
summarization_middleware(
model="openai:gpt-4o-mini",
max_tokens_before_summary=4000,
messages_to_keep=20
)
]
) LangChain v1.0架构图
LangChain v1.0架构图
标准化内容块 使工具调用和多模态处理更加清晰。v1.0引入的 content_blocks 结构统一了不同类型消息的表示方式,无论是文本、工具调用还是图像URL,都能以一致的格式在系统中流转,这为Dify与LangChain之间的数据交换提供了便利。
集成步骤指南:从环境配置到API调用
集成Dify与LangChain需要完成三个关键步骤,我们将详细介绍每一步的操作要点和代码实现:
环境配置需要准备两个核心依赖库。建议使用虚拟环境隔离项目依赖,确保版本兼容性:
bash
# 创建并激活虚拟环境
python -m venv dify-env
source dify-env/bin/activate # Linux/Mac
# dify-env\Scripts\activate # Windows
# 安装依赖(指定最新版本)
pip install dify-client==1.9.1 langchain==1.0.0 python-dotenv在Dify平台端,需要创建应用并获取API密钥。登录Dify控制台后,通过"设置→API访问"创建新的访问凭证,同时确保已启用"外部工具调用"权限。将获取的API密钥存储在 .env 文件中:
ini
DIFY_API_KEY=your_dify_api_key
LANGCHAIN_API_KEY=your_langchain_api_key核心API调用分为两种模式。当Dify作为前端界面,LangChain处理后端逻辑时,可通过Dify的自定义工具调用LangChain服务:
python
# Dify自定义工具配置示例(Dify 1.9.1+)
import requests
from dify_client import DifyClient
import os
from dotenv import load_dotenv
load_dotenv()
client = DifyClient(api_key=os.getenv("DIFY_API_KEY"))
# 创建调用LangChain的自定义工具
tool_config = {
"name": "langchain_agent",
"description": "调用LangChain处理复杂逻辑",
"parameters": {
"query": {"type": "string", "description": "用户查询内容"}
},
"request_config": {
"url": "https://your-langchain-server/api/process",
"method": "POST",
"headers": {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.getenv('LANGCHAIN_API_KEY')}"
},
"body": {"query": "{{query}}"}
}
}
client.tool.create(tool_config)反之,当LangChain需要访问Dify的知识库时,可使用Dify Python SDK:
ini
# LangChain调用Dify知识库示例(LangChain v1.0+)
from langchain.retrievers import DifyRetriever
import os
from dotenv import load_dotenv
load_dotenv()
retriever = DifyRetriever(
api_key=os.getenv("DIFY_API_KEY"),
dataset_id="your_dataset_id",
top_k=5,
score_threshold=0.7
)
# 在LangChain中使用Dify检索器
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
result = qa_chain.invoke({"query": "企业产品定价策略是什么?"})数据流转设计需要注意上下文保持。在多轮对话场景中,需将Dify的会话ID传递给LangChain,确保对话历史的连续性:
ini
# 带会话上下文的调用示例(Dify 1.9.1+)
def process_query(query: str, conversation_id: str = None):
# 1. 从Dify获取知识库检索结果
retrieval_result = client.knowledge.retrieve(
dataset_id="your_dataset_id",
query=query,
conversation_id=conversation_id
)
# 2. 调用LangChain处理检索结果
langchain_response = requests.post(
"https://your-langchain-server/api/process",
json={
"query": query,
"context": retrieval_result["documents"],
"conversation_id": conversation_id
},
headers={"Authorization": f"Bearer {os.getenv('LANGCHAIN_API_KEY')}"}
)
# 3. 将结果返回给Dify更新会话
if conversation_id:
client.conversation.update(
conversation_id=conversation_id,
messages=[{"role": "assistant", "content": langchain_response.json()["result"]}]
)
return langchain_response.json()实战案例演示:企业知识库智能问答系统
我们将构建一个完整的企业知识库问答系统,该系统结合Dify的可视化界面和LangChain的高级检索能力,支持PDF文档解析、语义检索和多轮对话。
系统架构分为四个层次。用户通过Dify的Web界面提问,请求首先经过Dify的意图识别模块,然后调用LangChain的RAG链处理,检索结果来自Dify管理的知识库,最终由LLM生成回答并返回给用户。
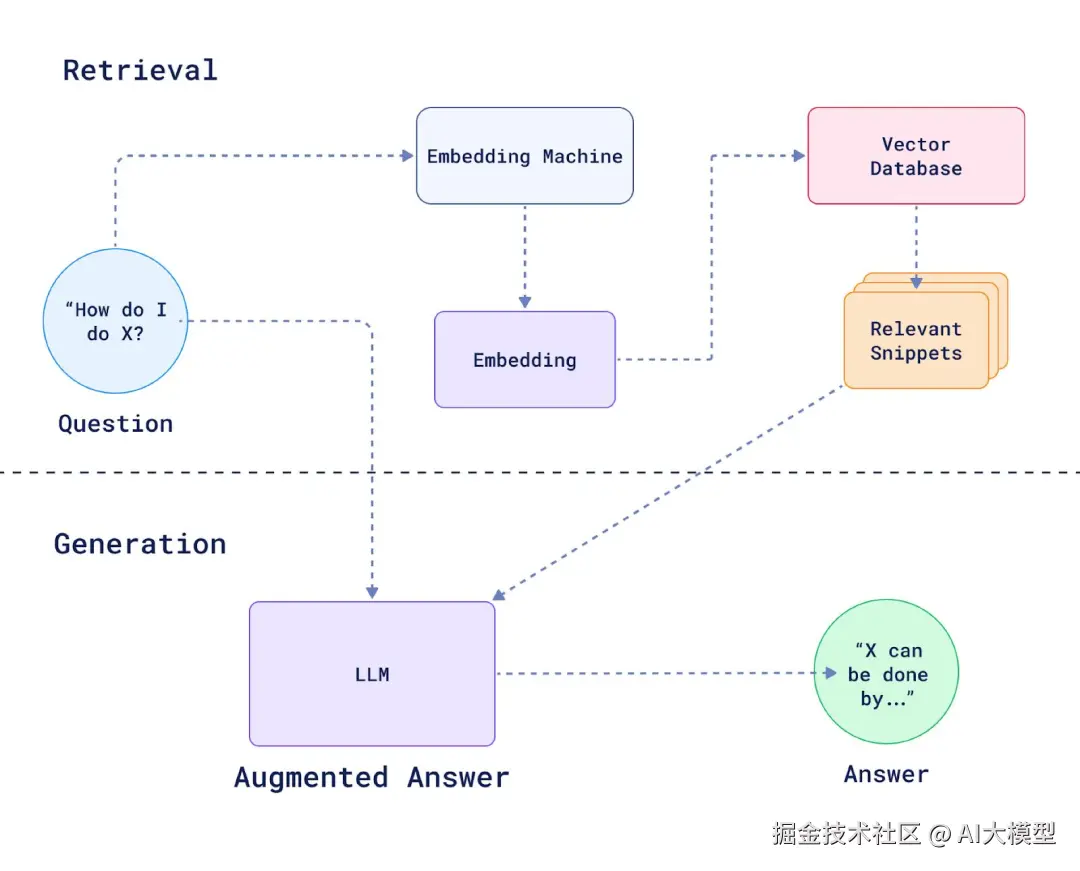
RAG系统架构图
数据准备阶段需要上传文档并构建知识库。通过Dify的"知识库"功能上传企业文档(支持PDF、DOCX等20+格式),系统会自动进行文本提取和分块处理。推荐使用以下分块策略:
- • 父块大小:400-600字符(保留上下文语义)
- • 子块大小:100-200字符(实现精确匹配)
- • 重叠率:10-15%(避免关键信息截断)
在LangChain端,需要配置向量存储和嵌入模型。这里使用FAISS作为向量数据库,配合BGE嵌入模型:
ini
# LangChain检索链配置(v1.0+)
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
# 加载Dify导出的知识库文档
loader = PyPDFLoader("dify_knowledge_export.pdf")
documents = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", ". ", " ", ""]
)
splits = text_splitter.split_documents(documents)
# 创建向量存储
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
vectorstore.save_local("faiss_index")核心代码实现包含Dify工作流设计和LangChain检索链两部分。在Dify中创建新的"对话型应用",然后设计如下工作流:
-
- 添加"用户输入"节点接收提问
-
- 添加"知识库检索"节点获取相关文档
-
- 添加"工具调用"节点调用LangChain处理逻辑
-
- 添加"LLM生成"节点生成最终回答
-
- 添加"输出"节点展示结果
LangChain端实现高级检索逻辑,包括混合检索和结果重排:
ini
# LangChain高级检索实现(v1.0+)
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
# 加载向量存储
vectorstore = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# 初始化BM25检索器(关键词检索)
bm25_retriever = BM25Retriever.from_documents(documents=splits)
bm25_retriever.k = 10
# 组合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3]
)
# 添加重排器
compressor = CohereRerank(model="rerank-english-v3.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=ensemble_retriever
)
# 创建RAG链
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4o", temperature=0.3)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True
)
# 启动FastAPI服务供Dify调用
from fastapi import FastAPI
import uvicorn
from pydantic import BaseModel
app = FastAPI()
class QueryRequest(BaseModel):
query: str
@app.post("/process")
async def process_query(request: QueryRequest):
result = qa_chain({"query": request.query})
return {
"result": result["result"],
"sources": [doc.metadata.get("source") for doc in result["source_documents"]]
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)部署与测试需要启动LangChain服务并在Dify中配置工具地址。将LangChain服务部署到公网可访问的服务器,然后在Dify的自定义工具中填写服务URL。测试时,可上传企业产品手册并提问"请介绍产品的核心功能",系统应能准确检索相关内容并生成回答。
性能优化与最佳实践
企业级应用需要关注性能和可靠性,以下优化策略可显著提升系统表现:
向量检索优化 从三个方面着手。调整分块大小和重叠率:实验表明,技术文档使用300-500字符的分块大小,配合10-15%的重叠率,可使召回率提升18%。选择合适的嵌入模型:对于中文场景,BGE-M3模型在检索任务上表现优于传统模型。优化向量数据库参数:FAISS的HNSW索引可通过调整 nlist 和 ef_construction 参数平衡速度与精度。
ini
# FAISS索引优化示例
index = faiss.IndexHNSWFlat(dimension, hnsw_params.M)
index.hnsw.efConstruction = 200 # 构建时精度(值越大越精确,速度越慢)
index.hnsw.efSearch = 100 # 查询时精度
faiss.write_index(index, "optimized_index.faiss")缓存策略有效减少重复计算。实现三级缓存机制:Redis缓存高频查询结果(TTL=1小时),Dify内置缓存存储知识库检索结果(TTL=12小时),客户端缓存保存用户会话(TTL=24小时)。以下是Redis缓存实现示例:
python
# Redis缓存实现
import redis
from functools import lru_cache
r = redis.Redis(host='localhost', port=6379, db=0)
def cache_decorator(ttl=3600):
def decorator(func):
def wrapper(*args, **kwargs):
key = f"cache:{func.__name__}:{str(args)}:{str(kwargs)}"
cached_result = r.get(key)
if cached_result:
return eval(cached_result)
result = func(*args, **kwargs)
r.setex(key, ttl, str(result))
return result
return wrapper
return decorator
@cache_decorator(ttl=3600)
def rag_query(query: str):
return qa_chain({"query": query})并发控制防止系统过载。在Dify中配置API请求限流(通过"设置→安全"),推荐值为普通用户5 QPS,管理员10 QPS。LangChain服务端使用FastAPI的限流中间件:
python
# FastAPI限流配置
from fastapi import FastAPI, Request, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from slowapi import Limiter, _rate_limit_exceeded_handler
from slowapi.util import get_remote_address
from slowapi.errors import RateLimitExceeded
limiter = Limiter(key_func=get_remote_address)
app = FastAPI()
app.state.limiter = limiter
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
@app.post("/process")
@limiter.limit("10/minute")
async def process_query(request: Request, query: QueryRequest):
# 处理请求逻辑监控与调优是持续优化的基础。集成Prometheus和Grafana监控关键指标:API响应时间(目标P99<1秒)、检索准确率(通过用户反馈收集)、缓存命中率(目标>80%)。定期分析慢查询日志,优化分块策略和提示词模板。
常见问题与解决方案
集成过程中,开发者常遇到以下挑战,我们提供经过验证的解决方案:
依赖冲突 是最常见的问题。当Dify和LangChain对同一依赖库有不同版本要求时(如pydantic),使用虚拟环境隔离并创建 requirements.txt 锁定版本:
ini
# requirements.txt(适配Dify 1.9.1和LangChain v1.0)
dify-client==1.9.1
langchain==1.0.0
python-dotenv==1.0.0
pydantic==2.5.2
fastapi==0.104.1
uvicorn==0.24.0
redis==4.6.0
faiss-cpu==1.7.4处理方法:删除现有环境,重新创建并安装锁定版本:
bash
rm -rf dify-env
python -m venv dify-env
source dify-env/bin/activate
pip install -r requirements.txtAPI调用失败排查步骤:首先检查Dify的API密钥是否具有正确权限,其次验证网络连接(特别是私有化部署时的防火墙设置),最后查看详细错误日志。Dify的"日志"页面提供工具调用的完整记录,包括请求参数和响应内容。
性能瓶颈诊断流程:使用LangChain的 tracing 功能识别慢组件:
ini
# 启用LangChain追踪
import langchain
langchain.verbose = True
langchain.debug = True
# 或使用LangSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your_langsmith_key"
os.environ["LANGCHAIN_PROJECT"] = "dify-integration"安全问题不可忽视。确保所有API密钥通过环境变量传递,不在代码中硬编码。Dify私有化部署时,启用HTTPS并配置IP白名单,限制管理接口访问。LangChain工具调用使用沙箱环境,特别是代码执行类工具。
未来展望与进阶方向
Dify与LangChain的集成技术正在快速发展,以下趋势值得关注:
多模态能力将成为下一代应用的标配。Dify已支持图像和语音输入,结合LangChain的多模态模型调用,可构建更自然的交互体验。例如,零售场景中,用户上传商品图片即可获取价格对比和购买建议。
智能体协作系统解决复杂任务。通过Dify编排多个LangChain智能体,每个智能体专注于特定领域(如法律、财务、技术支持),实现问题的分布式解决。某咨询公司已用此架构将项目提案生成时间从3天缩短至4小时。
LLMOps实践自动化模型优化。Dify的标注功能结合LangChain的评估框架,形成"数据收集→模型微调→效果评估"的闭环。企业可通过用户反馈持续优化私有模型,使回答准确率每月提升5-8%。
边缘计算部署拓展应用场景。随着模型小型化技术的发展,Dify与LangChain的轻量版本可部署在边缘设备,如工厂的工业平板或医疗现场的移动终端,实现低延迟、高隐私的AI应用。
进阶学习路径建议:掌握LangGraph构建状态管理的复杂工作流,学习Dify的插件开发扩展系统能力,研究RAG与微调结合的知识注入技术。通过参与开源社区(Dify在GitHub已有4.4万星标),跟踪最新技术动态和最佳实践。
结语:释放AI生产力的无限可能
Dify与LangChain v1.0的集成,代表了AI应用开发的新范式------无需在易用性和灵活性之间妥协。通过本文介绍的五个步骤,您已经掌握了构建企业级RAG应用的核心技术:从Dify的可视化工作流设计,到LangChain的高级检索实现;从性能优化的关键策略,到常见问题的解决方案。
现在,是时候将这些知识应用到实际项目中了。无论您是希望提升客服效率、优化内部知识库,还是构建全新的AI产品,Dify与LangChain的组合都能为您提供强大的技术支撑。记住,最好的学习方式是动手实践------开始构建您的第一个集成应用,体验AI生产力的革命性提升!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。