前言
前阵子,网站访问量有些高,因为业务原因,我们的站点有一个统一的出口反向代理服务器,部署在了云服务器上,可以实时查看网络情况。有一次,我问及带宽负载情况的时候,相关负责人突然来了个控制台给出的网络连接数要"除以6"才是实际请求数,给我CPU干懵了一下,回头想想这也是有道理的,但又有些片面,所以想趁着金秋10月的最后一天,简单聊聊这个问题。
在做网站监控、流量分析、容量规划,甚至安全防护时,我们常常会看到两个"看起来很直观"的指标:
- TCP 连接数
- 独立 IP 访问数
很多人会下意识地认为:"连接数多 = 用户多"、"独立 IP 数 = 用户数"。但现实远比这复杂。今天我们就来聊聊:到底该怎么理解这些指标?又该如何更准确地估算真实用户数量?
一、TCP 连接数 ≠ 用户数
先看一下具体的现象
这里,我试着访问一个我们线上的站点,用作演示
- 开始之前,先ping一下域名,确定我们请求的域名公网ip是什么(注意,前提是服务器允许ping,为了测试,可以先临时放开一下)
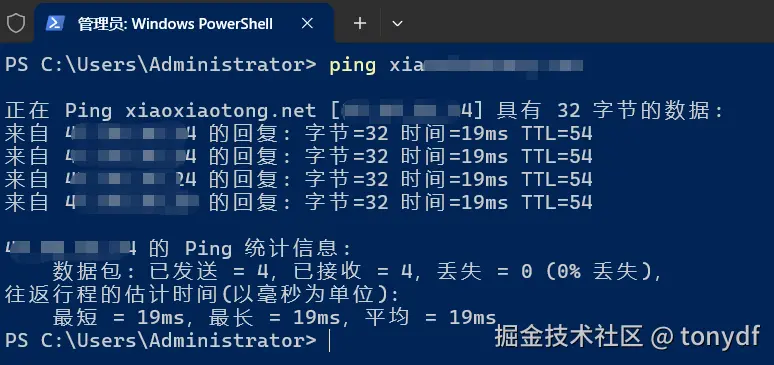
- 然后通过netstat命令看一下目前和当前服务器ip有没有建立tcp连接
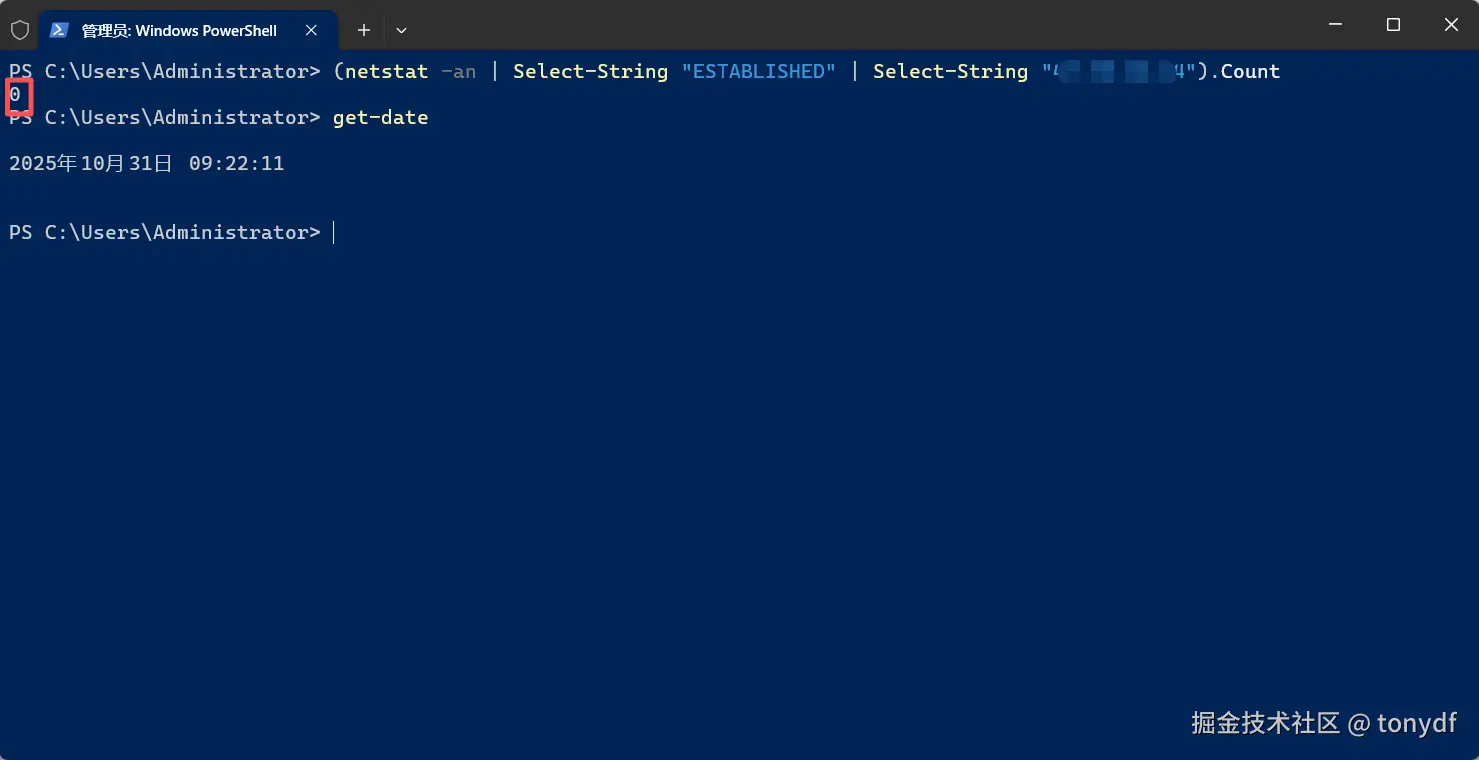
- 接着,打开浏览器访问站点后,再次重复上面命令,可以看到建立了6个tcp连接
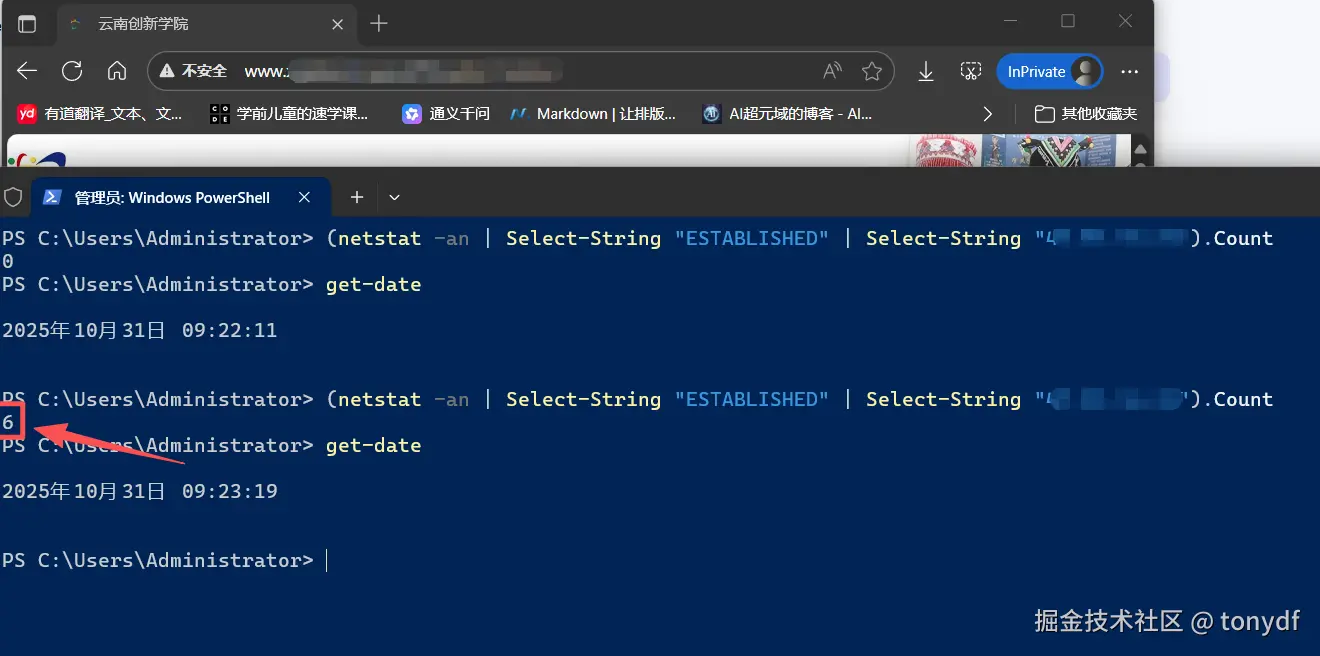
- 过一段时间(看服务器设定的超时时长是多少,一般就是一分钟左右)再重复命令,再看看,这时看到建立的TCP连接数又变成0了
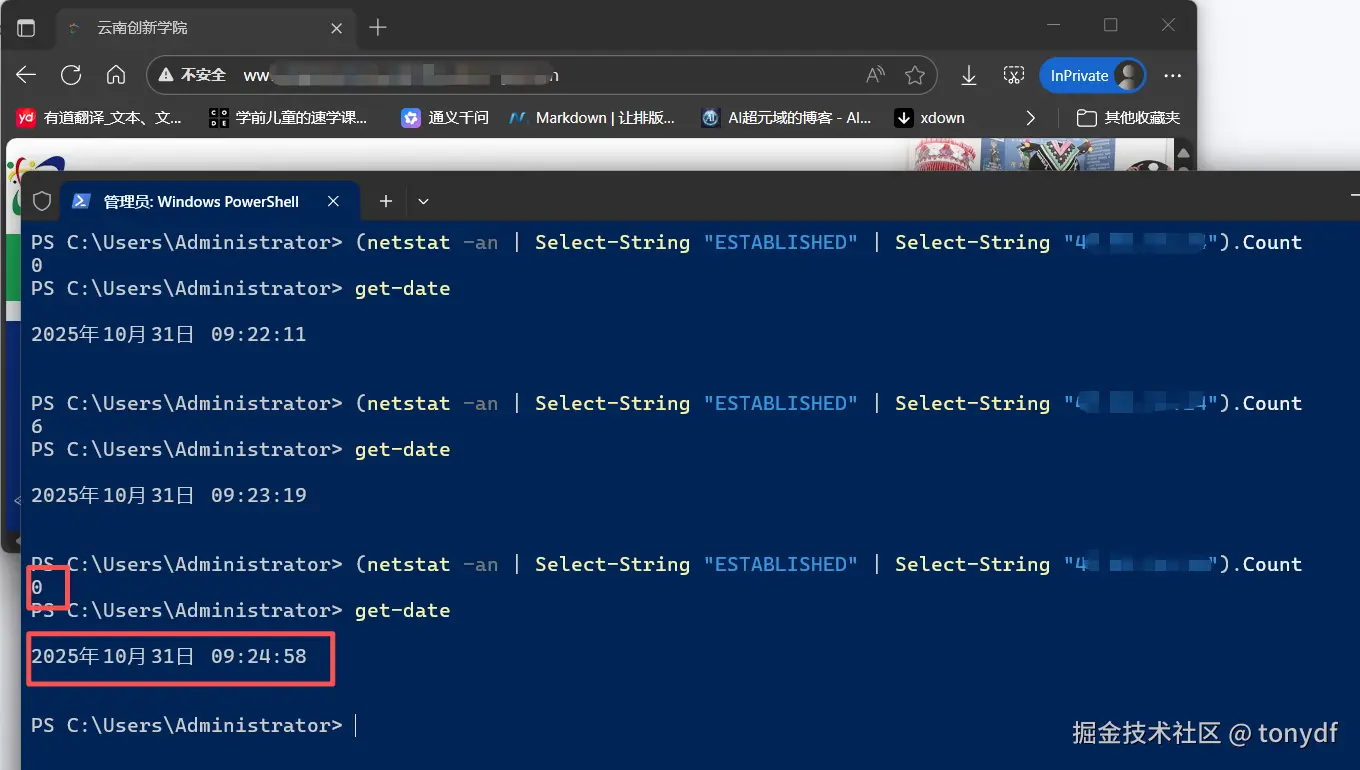
- 如果是视频类的网站,我要长时间的观看视频,此时要加载ts类型的视频分片文件,同时上报一些数据,这时再观察连接数只剩2个了(一个是加载视频,hls协议的视频是类似轮询的方式,分片缓存到本地,另一个则是一些数据上报的服务)
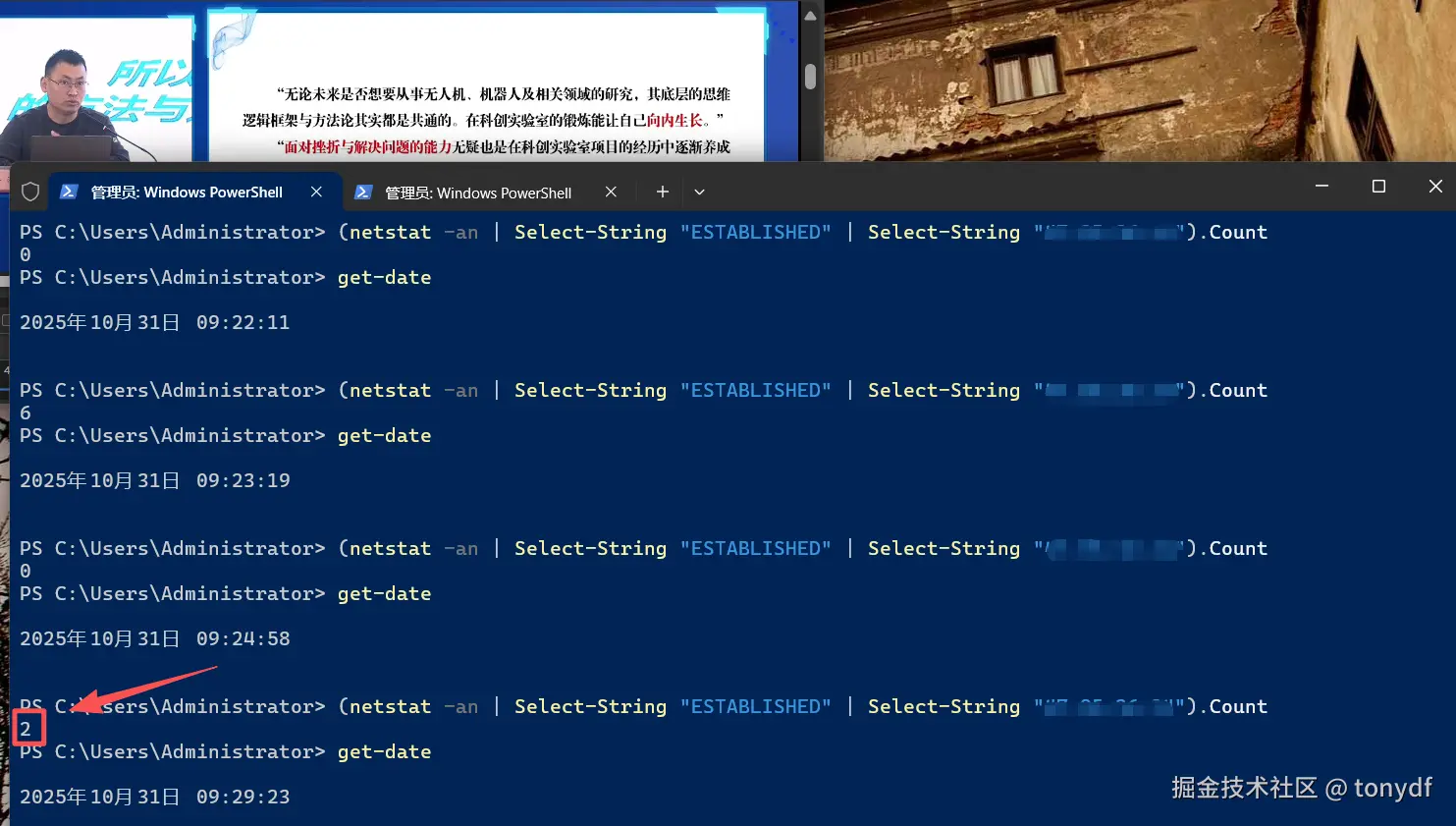
初看现象:连接数先多后少
上面的现象是,当我在本地用浏览器打开网站时,打开控制台用netstat查看 TCP 连接,发现一开始有 6 个甚至更多的 ESTABLISHED 连接;但过一会儿,归0了,但此时网页还是开着的,然后再打开一个视频资源,连接数先是又变成了6个,再过一小会儿稳定到2个。
这是为什么,咱捞点干的哈~
- 资源并行加载:现代浏览器为了加快页面加载速度,会对同一个域名并发建立多个 TCP 连接(HTTP/1.1 下通常最多 6 个,因此网站开始访问的时候客户端尽可能多的建立TCP连接能加速访问,当然服务器可能压力大点,这也是为什么要把大部分静态资源分离到CDN等的原因)。
- 连接复用与 Keep-Alive:资源加载完成后,连接可能被保持一段时间(keep-alive),但若无新请求,会自动关闭。(笔者相信,仍然有大部分传统网站还没有利用这个keep-alive特性,这是真正不需要改代码,而能加速网站访问速度的好手段)
- HTTP/2 和 HTTP/3 的普及:它们支持多路复用(multiplexing),多个资源可在单个连接上传输,因此连接数大幅减少。
那连接数能反映用户数吗?
不能直接等同。原因包括:
- 一个用户可能开多个标签页 → 多个连接;
- 移动端网络切换频繁 → 连接反复重建;
- WebSocket、SSE 等长连接场景 → 一个用户长期占一个连接;
- 爬虫、自动化脚本也会建立连接,但不是"人"。
常见误区:"监控平台显示 600 个连接,所以有 100 个用户(600 ÷ 6)。"
实际情况:如果服务已全面启用 HTTP/2,600 个连接可能对应 600 个真实用户!
结论:连接数可以反映系统负载和并发压力,但不能直接换算成用户数。尤其"除以6"这种经验法则,在今天已严重过时!
二、独立 IP 数 ≠ 用户数
另一个常被误用的指标是"独立 IP 访问数"。很多后台监控会统计"今天有多少个不同 IP 访问了网站",并称之为"独立访客"。
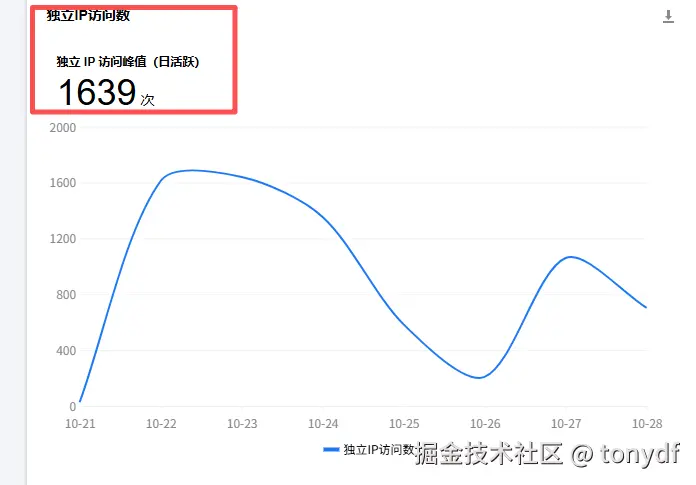
但现实是:
场景1:NAT 网络(最常见!)
- 学校机房、公司内网、家庭 Wi-Fi:几十甚至上百人共享同一个公网出口 IP。
- 结果:20 个学生同时访问你的网站 → 后台只记录 1 个独立 IP。
场景2:移动网络(4G/5G)
- 运营商使用 CGNAT(运营商级 NAT),成千上万用户共享少量公网 IP。
- 你和朋友用手机访问同一网站,服务器可能看到的是同一个 IP。
场景3:代理、CDN、VPN
- 用户通过公共代理、企业网关或商业 VPN 上网 → 多人流量从同一 IP 发出。
- 如果你的服务前有 CDN(如 Cloudflare),后端默认看到的是 CDN 节点 IP,而非用户真实 IP(需通过 X-Forwarded-For请求头参数来获取)。
所以:独立 IP 数通常严重低估真实用户数,尤其在移动端和企业网络场景下。
三、那到底该怎么统计"真实用户数"?
没有银弹,但有更靠谱的方法,取决于你的业务场景:
1. 有登录系统的应用(最准确)
- 直接统计活跃的登录用户 ID。
- 可结合会话(session)有效期判断"当前在线用户"。
2. 无登录的公开网站
- 前端埋点 + Cookie:如 微软的clarity、常见的百度统计、自研 JS 埋点等,少数场景用户可能会禁用js但对大部分团队业务来说,这种情况完全可以忽略。
笔者用的就是clarity+js埋点上报,也用过百度统计;
3. 设备指纹(谨慎使用)
- 通过浏览器特征(User-Agent、屏幕分辨率、字体、Canvas 渲染等)生成唯一指纹。
- 准确性较高,但涉及隐私合规问题(需 GDPR/CCPA 等授权)。
这个我也没试过,查资料看来的~
4. 日志分析 + 启发式去重
- 结合 IP + User-Agent + 访问时间窗口,估算"可能的独立用户"。
- 例如:同一 IP 在 30 分钟内使用相同浏览器 → 算作 1 个用户。
- 仍是估算,但比纯 IP 好。
ELK开起来,这应该算基础设施了~
四、请求数量也要重视
除了连接数和 IP 数,还有一个更直接影响服务器稳定性的指标:实际打到后端的 HTTP 请求量。
为什么请求量值得关注?
- 一个用户 ≠ 一个请求:现代网页动辄包含几十个资源(HTML、JS、CSS、图片、API 接口),一次页面加载可能触发 20+ 次请求。
- 自动化脚本/爬虫:恶意爬虫或自动化工具可在短时间内发起成千上万次请求,消耗 CPU、数据库连接、带宽。
- API 滥用:如果接口未做保护,攻击者可通过高频调用导致服务雪崩。
举个例子:
100 个真实用户正常浏览,可能临时产生 2000 个请求;
而1 个恶意脚本,也可能在 1 秒内发起 5000 个请求。
从"用户数"看,前者更多;但从"服务器压力"看,后者更危险。
防护实践
为了平衡用户体验与系统安全,应该采取分层防御策略:
1. 应用层限流(细粒度控制)
- 使用限流组件,基于以下维度进行控制:
- IP 地址:防止单 IP 高频刷请求;
- 自定义请求头(如 X-ClientID):针对合作方或 App 客户端分配唯一标识,实现按客户端限流(下图是笔者系统实现的一个限流效果);
- 用户身份(登录态):对已登录用户设置更高配额,未登录用户严格限制。
关于限流的内容,笔者之前写过一篇博客,传送门👉:xie.infoq.cn/article/083...
2. 网络层防护(大规模攻击兜底)
- 对于 DDoS 攻击(如 SYN Flood、HTTP Flood),应用层限流往往来不及响应。
- 可以依托云厂商(如阿里云、腾讯云、AWS Shield)提供的 DDoS 高防服务,在流量进入机房前就清洗异常流量。
- 这类服务能识别并拦截:
- 异常高的并发连接;
- 非法协议包;
- 分布式僵尸网络流量。
总结一下就是,限流方案解决的是"滥用"问题,DDoS 防护解决的是"洪水"问题。两者相辅相成(但DDoS防护一般都太贵,而且,大部分网站只要安全措施做的到位,也很少能引来"洪水",对待网络安全问题还是要客观,不能把所有问题都归咎为"被攻击",更多的还是考虑自身的系统建设是不是完善)。
3. 前端与缓存优化(从源头减压)
- 合理设置 Cache-Control / ETag,减少重复资源请求;
- 使用 CDN 缓存静态资源,避免请求直达源站;
- 对非关键接口做 前端防抖/节流(如搜索框输入延迟请求)。
结语
在分布式、高并发的现代 Web 架构下,"一个用户"早已不是一个简单的 IP 或连接。连接数、独立 IP、请求量,都是有用的信号,但绝不是用户数的代名词。
更重要的是,真实用户和恶意流量可能在数据上难以区分。因此,我们既要准确理解指标含义,也要构建多层次的防护体系------从应用限流到网络清洗,从缓存优化到行为分析。
下次看到监控面板上的"600 个连接"或"1000 个独立 IP",不妨多问一句:
这背后,到底有多少真实的人?又有多少请求正在冲击我们的服务?
可别再直接"除以6"就当终端数量啦,尤其涉及到一些写一些数据报告的场景,如果基础知识欠缺,报告的数据也是差之千里。