
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. map 核心概念:键值对与红黑树底层](#一. map 核心概念:键值对与红黑树底层)
-
- [1.1 什么是 map?](#1.1 什么是 map?)
- [1.2 关键类型定义](#1.2 关键类型定义)
- [二. map 基础操作:构造、遍历与增删查改](#二. map 基础操作:构造、遍历与增删查改)
-
- [2.1 构造与初始化](#2.1 构造与初始化)
- [2.2 迭代器遍历](#2.2 迭代器遍历)
- [2.3 插入操作(insert)](#2.3 插入操作(insert))
- [2.4 查找与删除(find/erase)](#2.4 查找与删除(find/erase))
- [2.5 核心特性:operator \[\] 的多功能性](#2.5 核心特性:operator [] 的多功能性)
- [三. map 与 multimap 的差异](#三. map 与 multimap 的差异)
- [四. map 实战:LeetCode 经典案例](#四. map 实战:LeetCode 经典案例)
-
- [4.1 随机链表的复制](#4.1 随机链表的复制)
- [4.2 前k个高频单词](#4.2 前k个高频单词)
- 结尾:
前言:
在 C++ STL 容器中,
map是兼具 "高效查找" 与 "键值映射" 能力的关联式容器,底层基于红黑树实现,支持 O(log N) 级别的增删查改操作,且会按键(Key)自动排序。本文将从 map 的核心概念切入,结合实操代码,详细讲解其构造、增删查改、迭代器遍历等基础操作,对比map与multimap的差异,并通过 LeetCode 案例展示实战价值,帮你彻底掌握 map 的使用。
一. map 核心概念:键值对与红黑树底层
1.1 什么是 map?
map 是一种 "键值对(Key-Value)" 容器,每个元素包含一个 不可修改的键 (Key) 和一个 可修改的值(Value),底层通过红黑树(平衡二叉搜索树)组织数据,因此具备两个核心特性:
- 键唯一:相同的 Key 无法重复插入;
- 自动排序 :遍历
map时(走的中序),元素会按 Key 的升序(默认用less<Key>比较)排列。
map的参考文档 :map - C++ Reference
1.2 关键类型定义
map 的模板参数与内部类型需重点理解,直接影响使用方式:
cpp
// map 模板定义
template <class Key, // 键的类型(Key)
class T, // 值的类型(Value,typedef 为 mapped_type)
class Compare = less<Key>, // 键的比较方式(默认升序)
class Alloc = allocator<pair<const Key, T>> // 空间配置器
> class map;
// 核心内部类型
typedef pair<const Key, T> value_type; // 红黑树节点存储的键值对(Key 不可改)
typedef Key key_type; // 键的类型
typedef T mapped_type; // 值的类型value_type:map存储的是pair<const Key, T>类型,其中Key被const修饰,意味着不能通过迭代器修改 Key (会破坏红黑树结构),但可以修改T(Value);Compare:默认用less<Key>实现升序,若需降序,可传入greater<Key>(如map<int, int, greater<int>>)
pair类型介绍(大家自己看看了解一下即可):
cpp
typedef pair<const Key, T> value_type;
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair() : first(T1()), second(T2())
{
}
pair(const T1& a, const T2& b) : first(a), second(b)
{
}
template<class U, class V>
pair(const pair<U, V>& pr) : first(pr.first), second(pr.second)
{
}
};
template <class T1, class T2>
inline pair<T1, T2> make_pair(T1 x, T2 y)
{
return (pair<T1, T2>(x, y));
}二. map 基础操作:构造、遍历与增删查改
结合具体的代码示例,分模块讲解 map 的常用操作,注释会补充关键细节。
2.1 构造与初始化
map 支持多种构造方式,包括默认构造、迭代器区间构造、初始化列表构造等,实际开发中初始化列表构造最常用:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <map>
#include <string>
using namespace std;
void test_map1()
{
// 1. 默认构造(空 map)
map<string, string> dict1;
// 2. 初始化列表构造(C++11,比较推荐)
map<string, string> dict2 = {{"sort", "排序"}, {"left", "左边"}, {"right", "右边"}};
// 3. 迭代器区间构造(从其他 map 或容器拷贝)
map<string, string> dict3(dict2.begin(), dict2.end());
// 4. 拷贝构造
map<string, string> dict4(dict3);
cout << "dict2 初始化结果:" << endl;
for (const auto& [k, v] : dict2) { // C++17 结构化绑定(简洁遍历)
cout << k << ":" << v << endl;
}
}
int main()
{
test_map1();
}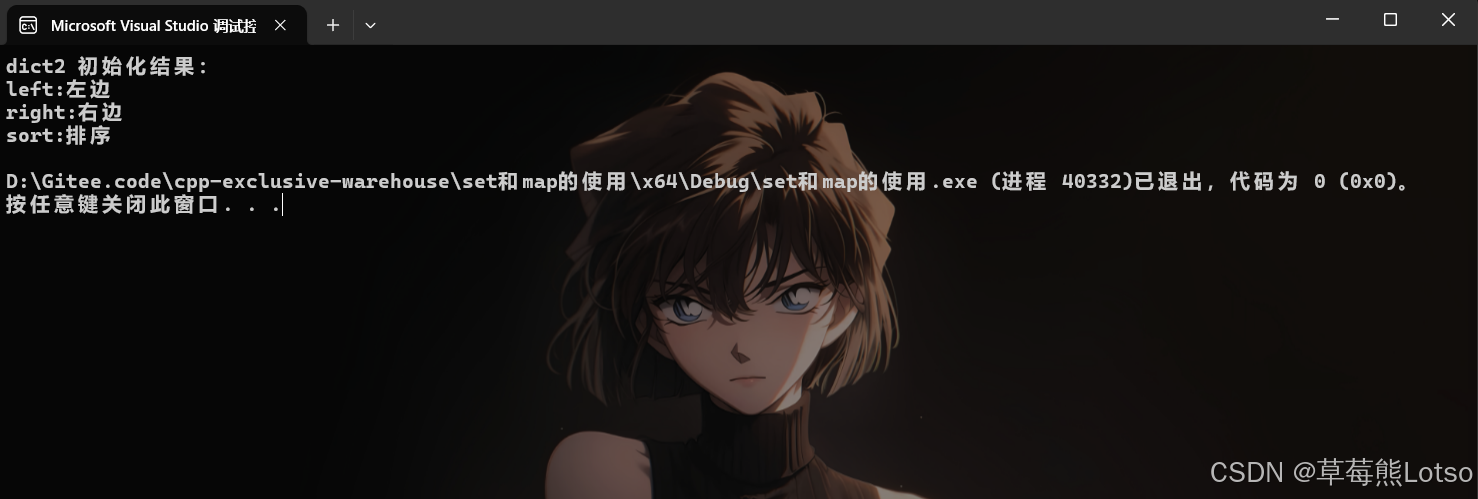
注意 :dict2 遍历结果按 Key 升序排列(left < right < sort ,按 ASCII 码比较),体现 map 自动排序特性。
2.2 迭代器遍历
map 的迭代器是双向迭代器 ,支持 ++/-- 操作,遍历方式包括 "迭代器循环""范围 for""结构化绑定",其中结构化绑定(C++17+)最简洁:
cpp
void test_map2()
{
map<string, string> dict = {{"sort", "排序"}, {"left", "左边"}, {"right", "右边"},{"string", "字符串"},{"map", "地图,映射"}};
// 方式1:普通迭代器遍历(支持修改 Value)
map<string, string>::iterator it = dict.begin();
while (it != dict.end()) {
// 关键:迭代器解引用得到 pair<const Key, T>,需通过 -> 访问 first/second
// (*it).first 等价于 it->first(推荐后者,更简洁)
cout << it->first << ":" << it->second << endl;
// 尝试修改 Key(编译报错!Key 是 const 的)
// it->first = "new_left";
// 修改 Value(合法)
if (it->first == "left") {
it->second = "左边(修改后)";
}
++it;
}
cout << endl;
// 方式2:范围 for 遍历(传引用避免拷贝,const 保护不被修改)
for (const auto& e : dict) {
// e 是 pair<const string, string> 类型
cout << e.first << ":" << e.second << endl;
}
cout << endl;
// 方式3:C++17 结构化绑定(最简洁,直接拆分 Key 和 Value)
for (const auto& [k, v] : dict) {
cout << k << ":" << v << endl;
}
}核心细节 :map 的 iterator 和 const_iterator 都不能修改 Key,但 iterator 可以修改 Value;若只需读取,优先用 const auto& 传引用,避免拷贝开销。
2.3 插入操作(insert)
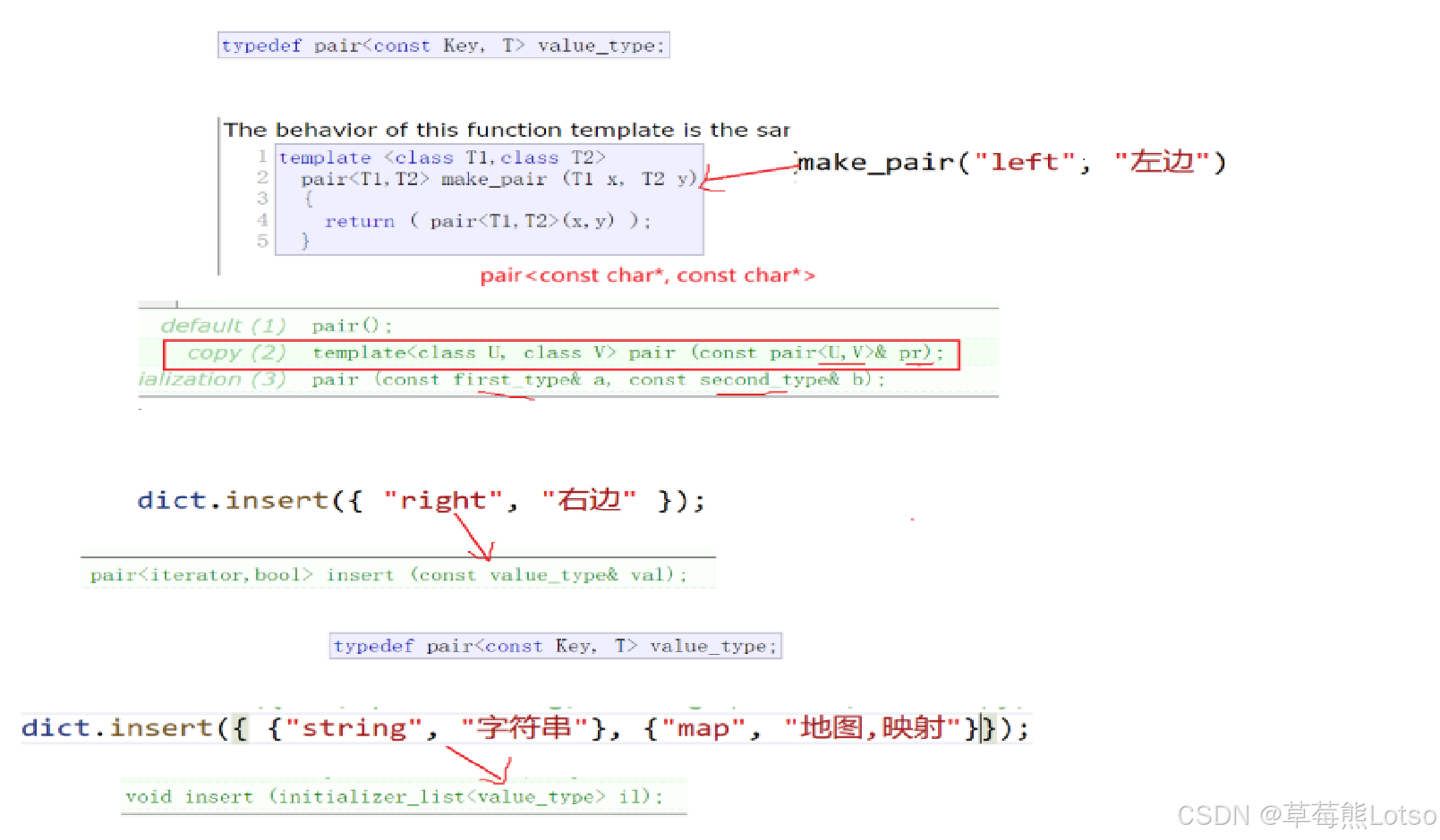
map 的 insert 接口用于插入键值对,返回 pair<iterator, bool>,其中:
iterator:指向插入成功的新节点,或已存在的相同 Key 节点;bool:true 表示插入成功,false 表示 Key 已存在、插入失败。

insert 支持多种插入形式,实际开发中推荐 "初始化列表" 和 "make_pair",以及多参数隐式类型转换:
cpp
void test_map3()
{
map<string, string> dict;
//方式1:插入 pair 对象(C++98 风格,较繁琐)
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
// 方式2:插入匿名 pair 对象(略简洁)
dict.insert(pair<string, string>("left", "左边"));
// 方式3:用 make_pair 生成 pair(推荐,无需显式写类型)
dict.insert(make_pair("right", "右边"));
// 方法4:初始化列表插入(C++11+,最简洁),用多参数的隐式类型转换
dict.insert({ "move","移动" });
// 批量插入多个键值对
dict.insert({ {"map", "映射"}, {"erase", "删除"} });
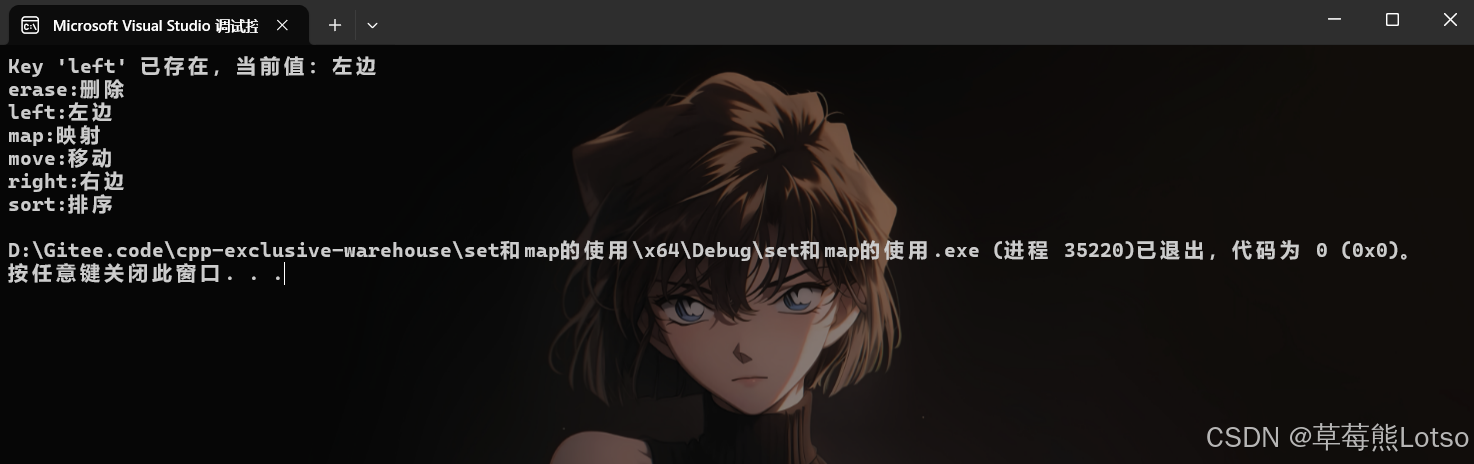
// 插入重复 Key(返回 false,不修改原数据)
auto ret = dict.insert({ "left", "左边(重复插入)" });
if (!ret.second) {
cout << "Key 'left' 已存在,当前值:" << ret.first->second << endl;
}
// 输出结果
for (const auto& [k, v] : dict) {
cout << k << ":" << v << endl;
}
}
int main()
{
test_map3();
}
2.4 查找与删除(find/erase)
(1)查找:find 与 count
find(Key):查找指定 Key,返回指向该 Key 的迭代器;若不存在,返回 end()(O(log N) 效率);count(Key):返回 Key 的出现次数(map 中 Key 唯一,故返回 0 或 1,可间接用于查找)。
(2)删除:erase
erase 支持三种删除形式:删除指定迭代器、删除指定 Key、删除迭代器区间,其中 "删除迭代器" 需先通过 find 确认 Key 存在,避免删除 end() 崩溃:
cpp
void test_map4()
{
map<string, string> dict = {
{"sort", "排序"}, {"left", "左边"}, {"right", "右边"}
};
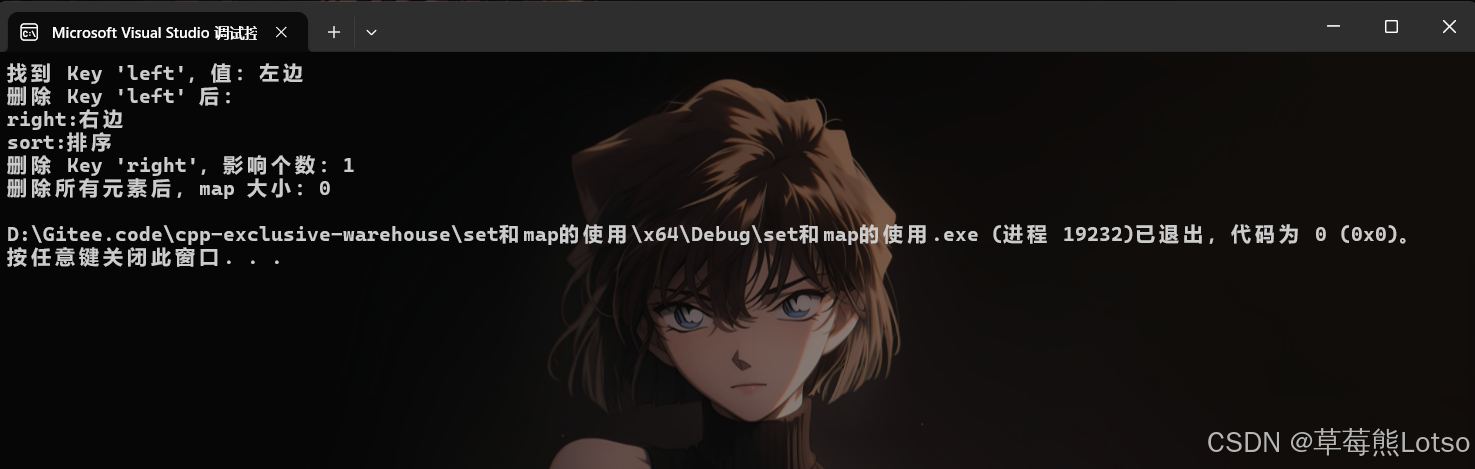
// 1. 查找 Key 'left'
auto pos = dict.find("left");
if (pos != dict.end()) {
cout << "找到 Key 'left',值:" << pos->second << endl;
// 2. 删除迭代器指向的节点(安全删除)
dict.erase(pos);
cout << "删除 Key 'left' 后:" << endl;
for (const auto& [k, v] : dict) {
cout << k << ":" << v << endl;
}
}
// 3. 直接删除指定 Key(返回删除的个数,map 中 0 或 1)
size_t del_cnt = dict.erase("right");
cout << "删除 Key 'right',影响个数:" << del_cnt << endl;
// 4. 删除迭代器区间(删除所有元素)
dict.erase(dict.begin(), dict.end());
cout << "删除所有元素后,map 大小:" << dict.size() << endl;
}
int main()
{
test_map4();
}
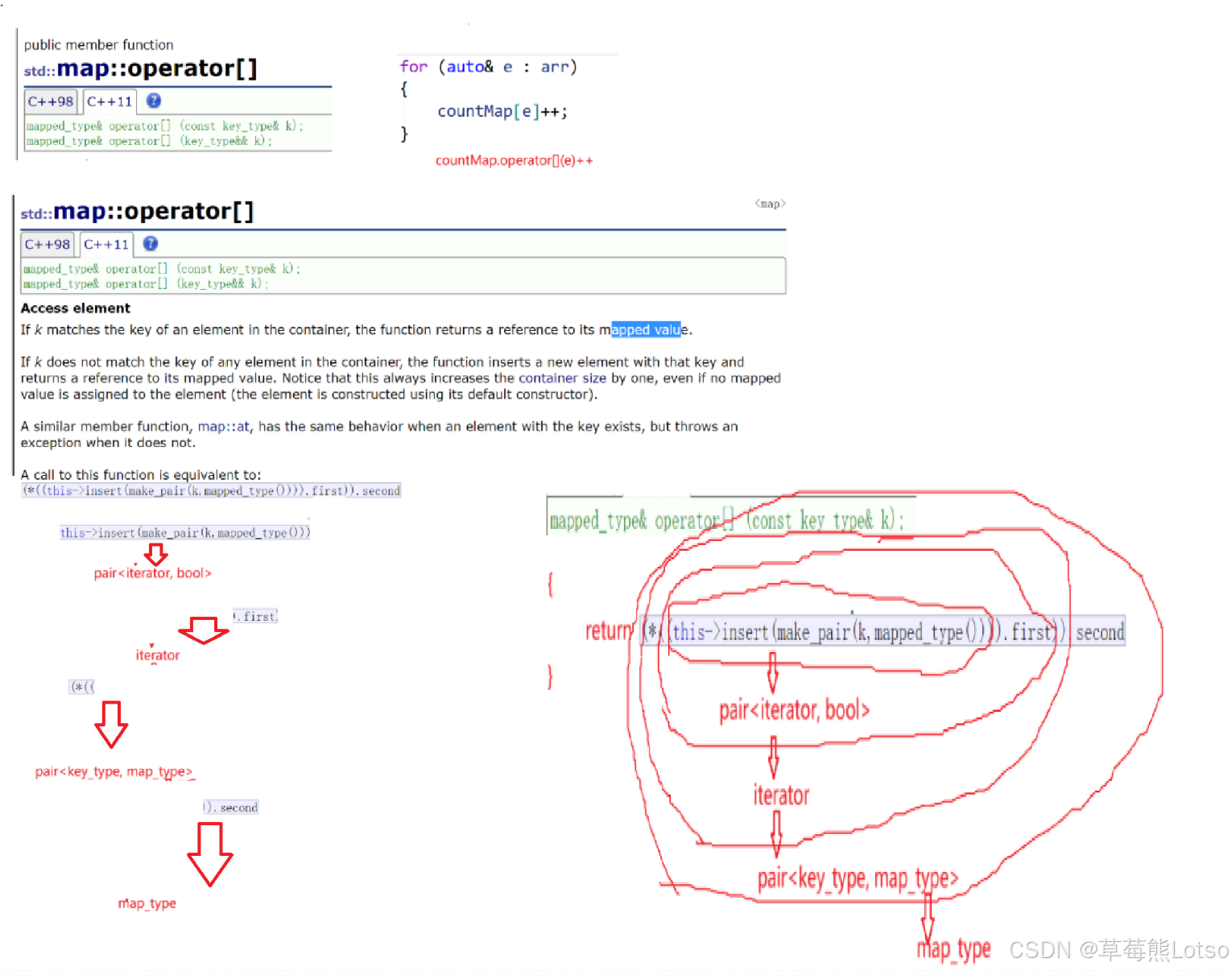
2.5 核心特性:operator \[\] 的多功能性
map 的 operator[] 是最灵活的接口,兼具 "插入、查找、修改" 三种功能,其内部实现依赖 insert,逻辑如下:
cpp
// operator[] 内部伪代码
mapped_type& operator[](const key_type& k) {
// 插入 {k, mapped_type()}(默认构造的 Value,如 int 为 0,string 为空)
pair<iterator, bool> ret = insert({ k, mapped_type() });
// 返回 Value 的引用(无论插入成功与否,都指向 Key 对应的 Value)
return ret.first->second;
}
基于此实现,operator[] 可灵活应对不同场景:
cpp
void test_map5()
{
map<string, int> countMap; // 统计水果出现次数
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "香蕉" };
// 这样很麻烦
//for (auto& e : arr)
//{
// auto it = countMap.find(e);
// if (it != countMap.end())
// {
// it->second++;
// }
// else
// {
// countMap.insert({ e,1 });
// }
//}
// 场景1:插入 + 修改(统计次数,最常用)
for (const auto& fruit : arr)
{
// 若 fruit 不存在:插入 {fruit, 0},返回 0 的引用,++ 后变为 1;
// 若 fruit 已存在:返回现有 Value 的引用,++ 后次数增加;
countMap[fruit]++;
}
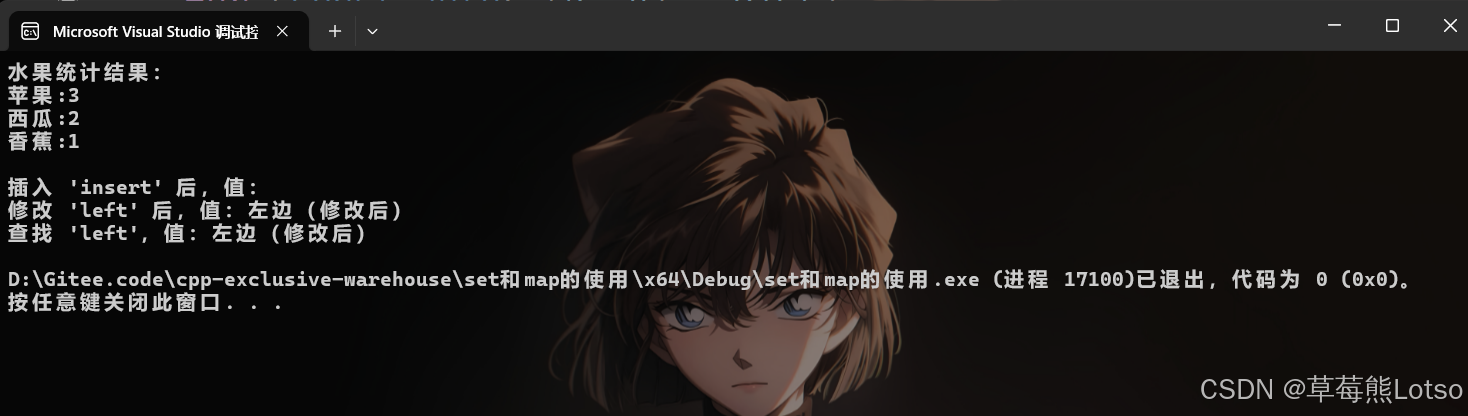
cout << "水果统计结果:" << endl;
for (const auto& [fruit, cnt] : countMap)
{
cout << fruit << ":" << cnt << endl;
}
cout << endl;
// 场景2:纯粹插入(Key 不存在时,插入默认 Value)
map<string, string> dict;
dict["insert"]; // 插入 { "insert", "" }(string 默认空)
cout << "插入 'insert' 后,值:" << dict["insert"] << endl;
// 场景3:插入 + 修改(Key 不存在时插入,存在时修改)
dict["left"] = "左边"; // 插入 { "left", "左边" }
dict["left"] = "左边(修改后)"; // 修改 Value 为 "左边(修改后)"
cout << "修改 'left' 后,值:" << dict["left"] << endl;
// 场景4:纯粹查找(Key 存在时,返回 Value 引用)
cout << "查找 'left',值:" << dict["left"] << endl;
// 对比:at() 接口(仅支持查找+修改,Key 不存在时抛异常,不插入)
dict.at("left") = "左边(at 修改)"; // 合法,修改 Value
// dict.at("nonexist") = "不存在"; // 抛出异常:out_of_range
}
int main()
{
test_map5();
}
关键区别 :operator[] 在 Key 不存在时会插入默认值,而 at() 会抛异常;若需 "严格查找" (不存在时不插入),优先用 find;若需 "统计次数""快速赋值",优先用 operator\[\]。
三. map 与 multimap 的差异
multimap 是 map 的 "兄弟容器",底层同样基于红黑树,但核心差异是 支持 Key 冗余(相同 Key 可重复插入),由此导致接口和使用场景不同:
| 特性 | map |
multimap |
|---|---|---|
| Key 唯一性 | 唯一(重复插入失败) | 不唯一(支持重复 Key) |
| operator\[\] | ✅ 支持(插入 / 查找 / 修改) | ❌不支持(Key 冗余,无法确定修改哪个) |
| find(Key) | 返回唯一 Key 的迭代器 | 返回中序遍历的第一个 Key 迭代器 |
| count(Key) | 返回 0 或 1 | 返回 Key 的实际出现次数 |
| erase(Key) | 删除唯一 Key(返回 0 或 1) | 删除所有相同 Key(返回删除个数) |
实际使用(大概看看就行):
cpp
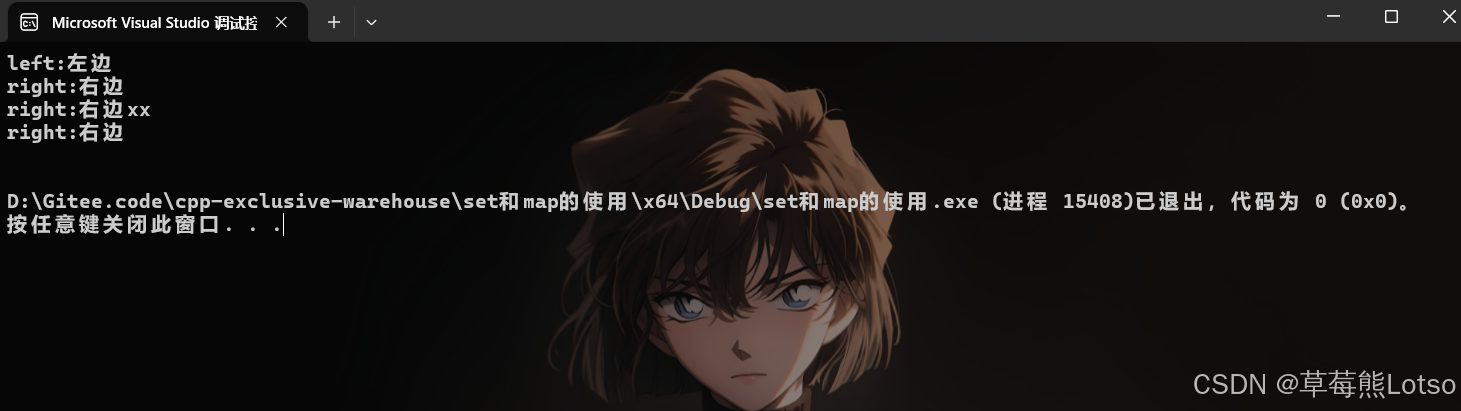
void test_multimap()
{
//multimap没有[]
multimap<string, string> dict;
dict.insert({ "right", "右边" });
dict.insert({ "left", "左边" });
dict.insert({ "right", "右边xx" });
dict.insert({ "right", "右边" });
for (const auto& [k, v] : dict)
{
cout << k << ":" << v << endl;
}
cout << endl;
}
int main()
{
test_multimap();
}
四. map 实战:LeetCode 经典案例
map 的核心价值在于 "高效键值映射" 和 "自动排序",在算法题中可简化复杂逻辑,以下是两个典型案例:
4.1 随机链表的复制
题目链接:
数据结构初阶阶段,为了控制随机指针,我们将拷贝结点链接在原节点的后面解决,后面拷贝节点还
得解下来链接,非常麻烦。这里我们直接让{原结点,拷贝结点}建立映射关系放到map中,控制随机指
针会非常简单方便,这里体现了map在解决⼀些问题时的价值,完全是降维打击。
C++算法代码:
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*,Node*> NodeMap;
Node*copyhead=nullptr,*copytail=nullptr;
Node*cur=head;
while(cur)
{
if(copyhead==nullptr)
{
copyhead=copytail=new Node(cur->val);
}
else{
copytail->next=new Node(cur->val);
copytail=copytail->next;
}
//原节点和拷贝节点通过map,kv存储
NodeMap.insert({cur,copytail});
cur=cur->next;
}
//处理random
cur=head;
Node* copy = copyhead;
while(cur)
{
if(cur->random==nullptr)
copy->random = nullptr;
else
// 查找
copy->random=NodeMap[cur->random];
cur=cur->next;
copy=copy->next;
}
return copyhead;
}
};4.2 前k个高频单词
题目链接:
本题目我们利用map统计出次数以后,返回的答案应该按单词出现频率由高到低排序,有一个特殊要
求,如果不同的单词有相同出现频率,按字典顺序排序。
解决思路1:
用排序找前k个单词,因为map中已经对key单词排序过,也就意味着遍历map时,次数相同的单词,
字典序小的在前面,字典序大的在后面。那么我们将数据放到vector中用一个稳定的排序就可以实现
上面特殊要求,但是 sort底层是快排 ,是不稳定 的,所以我们要用 stable_sort ,他是稳定的。
cpp
class Solution {
public:
struct kv_pair
{
bool operator()(const pair<string, int>& x, const pair<string, int>& y)
{
return x.second > y.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> CountMap;
for(auto& e:words)
{
CountMap[e]++;
}
vector<pair<string,int>> v(CountMap.begin(),CountMap.end());
//sort(v.begin(),v.end(),kv_pair());
// 得稳定排序
stable_sort(v.begin(),v.end(),kv_pair());
vector<string> ret;
for(size_t i=0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};解决思路2:(两种方法,两种容器)
将map统计出的次数的数据放到vector中排序,或者放到priority_queue中来选出前k个。利用仿函数
强行控制次数相等的,字典序小的在前面。
方案一:vector
cpp
class Solution {
public:
struct kv_pair
{
// 次数多的在前面,次数相等的时候,字典序小的在前面
bool operator()(const pair<string, int>& x, const pair<string, int>& y)
{
return x.second > y.second || (x.second == y.second && x.first < y.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> CountMap;
for(auto& e:words)
{
CountMap[e]++;
}
vector<pair<string,int>> v(CountMap.begin(),CountMap.end());
sort(v.begin(),v.end(),kv_pair());
vector<string> ret;
for(size_t i=0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};方案二:优先级队列
cpp
class Solution {
public:
struct kv_pair
{
// 次数多的在前面,次数相等的时候,字典序小的在前面
bool operator()(const pair<string, int>& x, const pair<string, int>& y)
{
// 要注意优先级队列底层是反的,大堆要实现小于比较,所以这里次数相等,想要字典序小的在前面要比较字典序大的为真
return x.second < y.second || (x.second == y.second && x.first > y.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> CountMap;
for(auto& e:words)
{
CountMap[e]++;
}
priority_queue<pair<string,int>,vector<pair<string,int>>,kv_pair> q(CountMap.begin(),CountMap.end());
vector<string> ret;
for(size_t i=0;i<k;i++)
{
ret.push_back(q.top().first);
q.pop();
}
return ret;
}
};结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:map系列容器是 C++ STL 中 "键值映射" 场景的核心工具,map的键唯一、multimap的键冗余特性,精准适配不同业务需求,底层红黑树更是保障了 O (log N) 的高效操作。从operator\[\]的多功能统计,到结构化绑定的简洁遍历,再到算法题中简化复杂逻辑的实战价值,它既降低了开发复杂度,又兼顾了性能与易用性。掌握其使用细节与场景适配,能为日常开发和算法实现提供有力支撑,是 C++ 开发者必备的容器技能。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
