本文代码见:
上篇文章:
https://blog.csdn.net/2401_86123468/article/details/153913543?spm=1001.2014.3001.5501
1.String operations
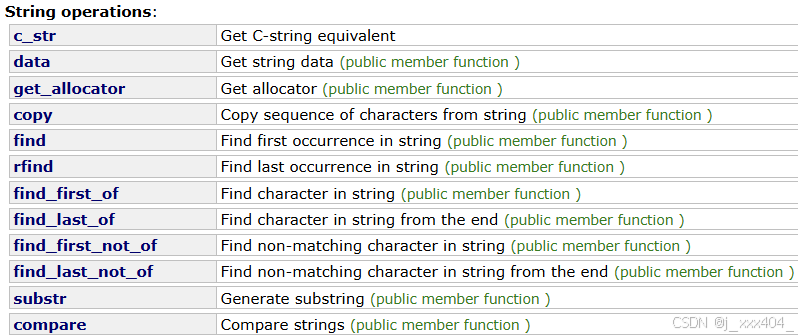
1.1c_str
以const char*返回指向地址的指针
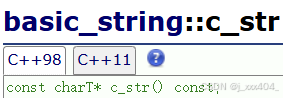
1.2data
和c_str作用相同,一般使用c_str
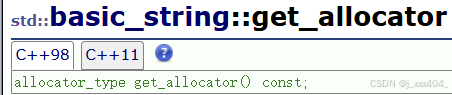
1.3get_allocator
获取字符串对象所使用的内存分配器,用于管理底层内存的分配与释放。
1.4copy和substr
将字符串从某一位置开始拷贝,不过,一般更推荐使用substr,因为copy还需要计算所开空间大小。


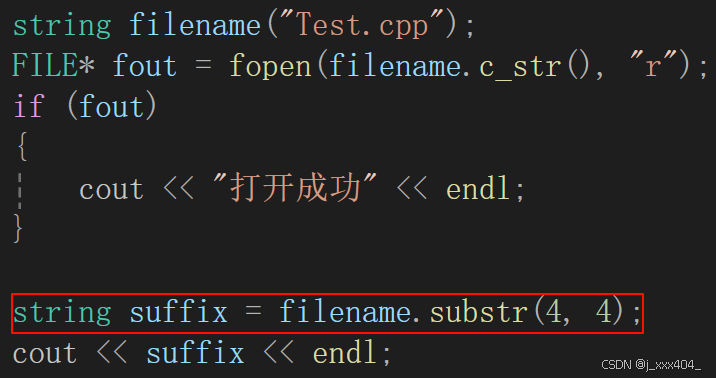
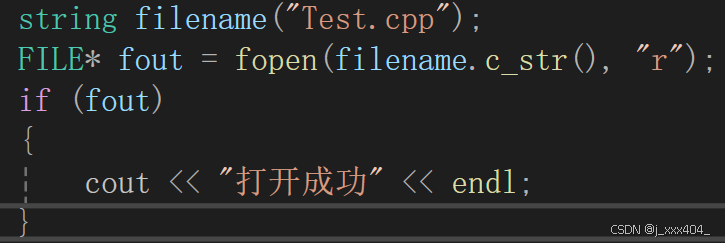
优化,取任意文件名的后缀:
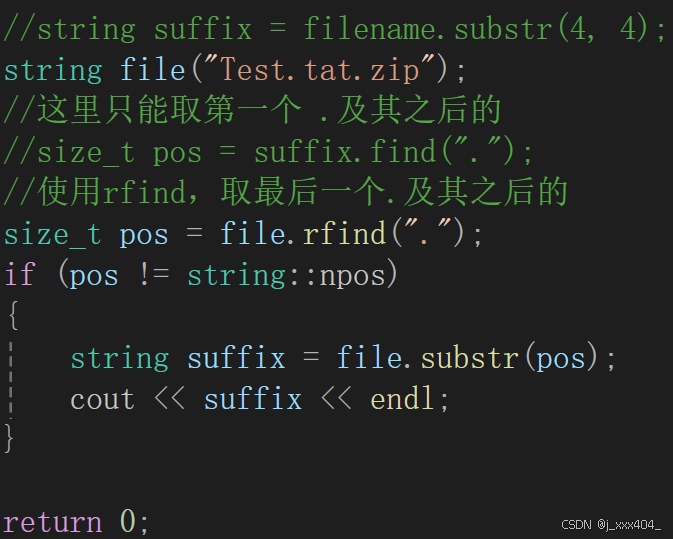
拓展:
1.5find_first_of
找到指定字符并返回

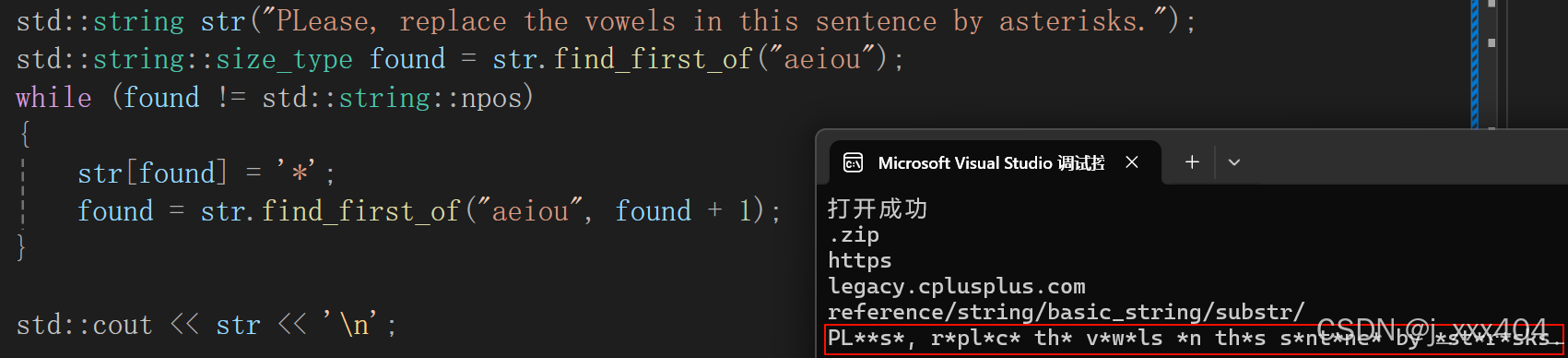
1.6find_last_of
与find_first_of相同,只不过是倒着找。
1.7find_first_not_of
将与指定字符不同的返回,保留指定字符。
1.8find_last_not_of
功能与find_first_not_of相同,只不过是倒着找。
1.9compare
更推荐使用运算符重载进行比较。
2.string类的模拟实现
使用命名空间,防止与库中的冲突。
2.1模拟实现构造函数
对无参和带参分别实现:
string.h
class string
{
public:
//构造函数(无参)
string()
//:_str(nullptr)//不能给空
:_str(new char[1] {'\0'})
, _size(0)
, _capacity(0)
{ }
//构造函数(带参)
string(const char* str)
: _size(strlen(str))
{
_str = new char[_size + 1];
_capacity = _size;
strcpy(_str, str);
}
const char* c_str()
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};分析下面有关带参的代码:
//构造函数(带参)
string(const char* str)
:_str(new char[strlen(str)+1])//这里strlen计算了三遍
, _size(strlen(str))
, _capacity(strlen(str))
{
strcpy(_str, str);
}此处的模拟调用三次strlen,效果并不好,需要修改至只需一次就可完整遍历:
//构造函数(带参)
string(const char* str)
: _size(strlen(str))
{
_str = new char[_size + 1];
_capacity = _size;
strcpy(_str, str);
}注意字符串后会包含\0,但strlen只返回有效字符个数,所以需要+1,为\0分配空间。
不过,无参的和带参的,全部改为带缺省值的更好:
string.h
class string
{
public:
string(const char* str = "")
: _size(strlen(str))
{
_str = new char[_size + 1];
_capacity = _size;
strcpy(_str, str);
}
const char* c_str()
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};Test.cpp
void test_string1()
{
string s1;
cout << s1.c_str() << endl;
string s2("xxx");
cout << s2.c_str() << endl;
}
}
int main()
{
try
{
xxx::test_string1();
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
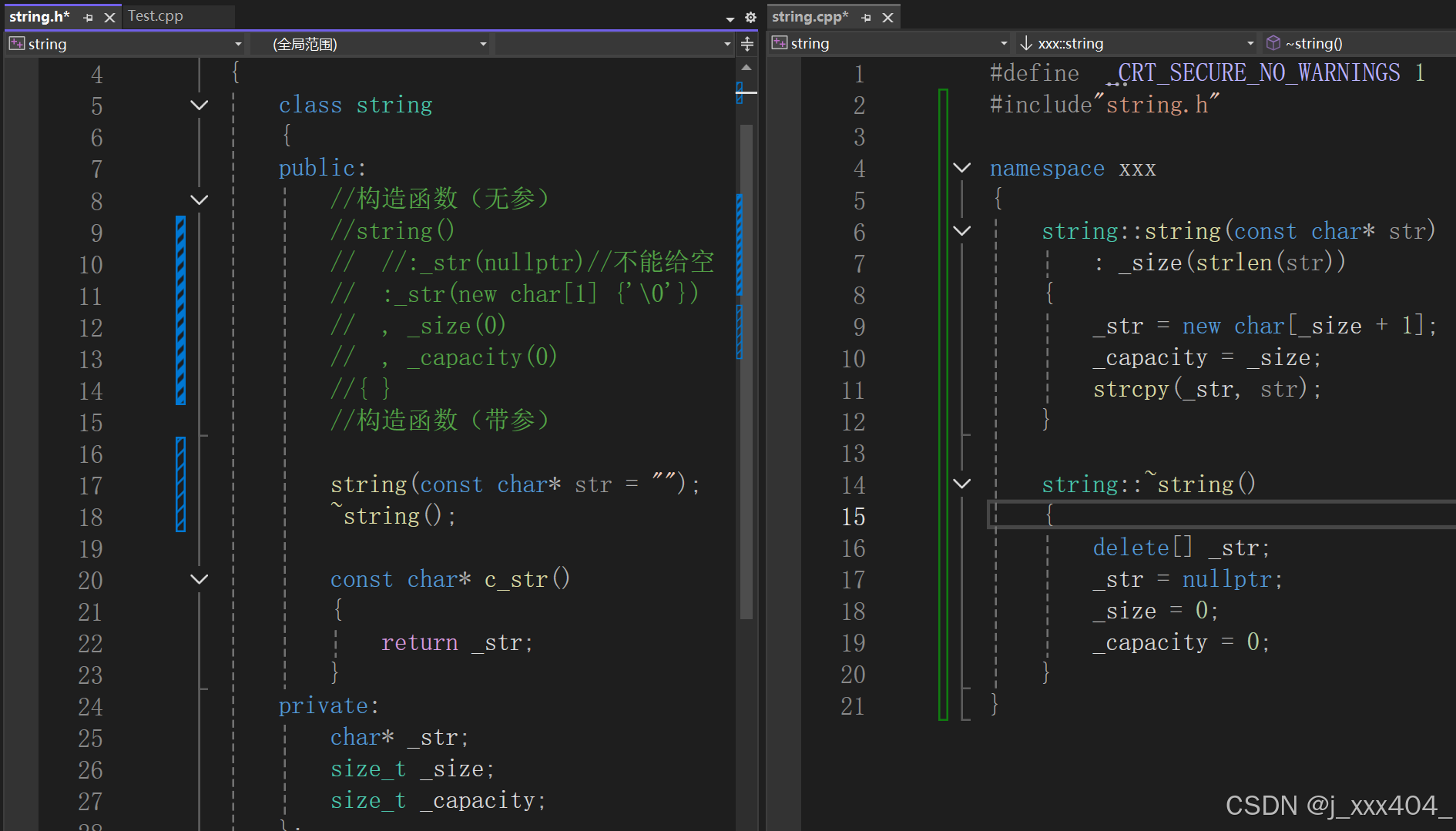
}2.2模拟实现析构函数
string.h
~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}从严格意义上来讲,我们需要完成声明和定义分离:
2.3遍历修改string
加入size,operator 以及将其和c_str改为const成员函数,非const也可以调用。
string.h
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
size_t size() const
{
return _size;
}Test.cpp
string s2("xxx");
cout << s2.c_str() << endl;
s2[0] = 'a';
cout << s2.c_str() << endl;
//遍历并修改
for (size_t i = 0; i < s2.size(); i++)
{
s2[i]++;
}
cout << s2.c_str() << endl;
const string s3("hello,world");
for (size_t i = 0; i < s3.size(); i++)
{
cout << s3[i] << "-";
}
cout << endl;2.4模拟实现迭代器和范围for
之后会用更复杂的方式完成,范围for循环实际上是基于迭代器的语法糖:
string.h
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}Test.cpp
const string s3("hello,world");
for (size_t i = 0; i < s3.size(); i++)
{
cout << s3[i] << "-";
}
cout << endl;
string s4 = "hello,world";
for (auto ch : s4)
{
cout << ch << " ";
}
cout << endl;
string::iterator it4 = s4.begin();
while (it4 != s4.end())
{
*it4 += 1;//可以修改
cout << *it4 << " ";
++it4;
}
cout << endl;
for (auto ch : s3)
{
cout << ch << " ";
}
cout << endl;
string::const_iterator it3 = s3.begin();
while (it3 != s3.end())
{
cout << *it3 << " ";
++it3;
}
cout << endl;在主函数中查看获取和显示迭代器类型的名称:
cout << typeid(xxx::string::iterator).name() << endl;
cout << typeid(std::string::iterator).name() << endl;结果是:
char * __ptr64
class std::_String_iterator<class std::_String_val<struct std::_Simple_types<char> > >2.5模拟实现插入和删除
2.5.1reserve,push_back,append
在实现插入操作时,需要考虑扩容问题。由于我们已经有rserve方法可用,所以不需要在插入函数中重复实现扩容逻辑,而是直接调用reserve来确保容量足够。
string.cpp
void string::reserve(size_t n)
{
//扩容
if (n > _capacity)
{
char* tmp = new char[n + 1];
//strcpy(tmp, _str);
memcpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void string::push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
void string::append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(std::max(_size + len, _capacity * 2));
}
//strcpy(_str + _size, str);
memcpy(_str + _size, str, len + 1);
_size += len;
}Test.cpp
string s1("xxx");
cout << s1.c_str() << endl;
s1.push_back('a');
cout << s1.c_str() << endl;
string s2("hello");
s2.append("xxxxxxxxxxxxx");
cout << s2.c_str() << endl;
string s3("hello");
s3.append("xx");
s3.append("xx");
cout << s3.c_str() << endl;2.5.2 +=
这里使用+=,复用append和push_back:
string.h
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}Test.c
string s3("hello");
s3.append("xx");
s3.append("xx");
cout << s3.c_str() << endl;
s3 += '*';
s3 += "xhellox";
cout << s3.c_str() << endl;2.5.3insert和erase
string.h
void insert(size_t pos, char ch);
void insert(size_t pos, const char* str);
void erase(size_t pos = 0, size_t len = npos);
private:
char* _str;
size_t _size;
size_t _capacity;
const static size_t npos;2.5.3.1插入字符串
string.cpp
const size_t string::npos = -1;
void string::insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//挪动数据
int end = _size;
while (end >= (int)pos)
{
_str[end + 1] = _str[end];
--end;
}
_str[pos] = ch;
_size++;
}插入数据时,这样的写法,不支持头插:

需要将size_t改为int,但程序依旧会挂,因为,虽然此时end显示为-1,但编译器进行转换时,范围小的像范围大的转,而无符号的范围比有符号范围更大,所以-1会转换为无符号,此时比0大。
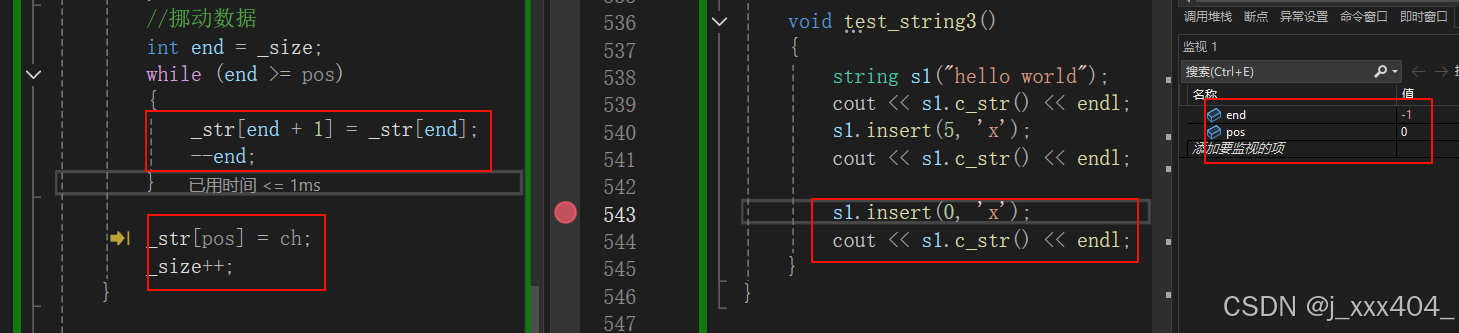
此处,使用最简单的方式进行优化:

第二种方式:
之前end所在位置为\0,所以需要end挪到end+1
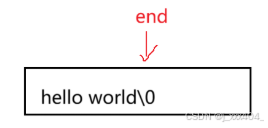
那么此时,将end放在\0之后,并且将循环条件改为>。

//挪动数据
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}2.5.3.2限定字符数插入字符串
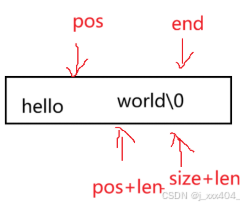
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(std::max(_size + len, _capacity * 2));
}
//挪动数据
//方法一
/*int end = _size;
while (end >= (int)pos)
{
_str[end + len] = _str[end];
--end;
}*/
//方法二
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
//strncpy(_str + pos, str, len);
memcpy(_str + pos, str, len);
_size += len;
}2.5.3.3erase
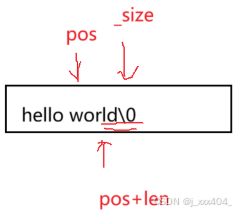
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
if (len == npos || len >= _size - pos)
{
//全删
_size = pos;
_str[_size] = '\0';
}
else
{
//删部分
//strcpy(_str + pos, _str + pos + len);
memcpy(_str + pos, _str + pos + len, _size - (pos + len) + 1);
_size -= len;
}
}strcpy运行逻辑:
原始字符串: "Hello, World!" (_size = 13)
删除: pos=7, len=5 (删除"World")
内存布局:
索引: 0 1 2 3 4 5 6 7 8 9 10 11 12 13
字符: H e l l o , W o r l d ! \0
strcpy 执行过程:
源指针 s = _str + 12 (指向 '!')
目标指针 p = _str + 7 (指向 'W')
循环步骤:
1. *p = *s → _str[7] = '!' (覆盖 'W')
p++, s++ → p指向_str[8], s指向_str[13]('\0')
2. *p = *s → _str[8] = '\0' (覆盖 'o')
循环结束
结果:
索引: 0 1 2 3 4 5 6 7 8 9 10 11 12 13
字符: H e l l o , ! \0 l d ! \0
字符串变为: "Hello, !"Test.cpp
void test_string4()
{
string s1("hello world");
cout << s1.c_str() << endl;
s1.erase(4, 3);
cout << s1.c_str() << endl;
string s2("hello world");
s2.erase(6);
cout << s2.c_str() << endl;
string s3("hello world");
s3.erase(6, 100);
cout << s3.c_str() << endl;
}2.6模拟实现拷贝构造(深拷贝)
string::string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}避免使用strcpy,原因见2.8
string::string(const string& s)
{
_str = new char[s._capacity + 1];
//strcpy(_str, s._str);
memcpy(_str, s._str, s._size + 1);
_size = s._size;
_capacity = s._capacity;
}2.7模拟实现赋值重载
string& string::operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}避免使用strcpy:
string& string::operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
//strcpy(tmp, s._str);
memcpy(tmp, s._str, s._size + 1);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}Test.cpp
void test_string5()
{
string s1("hello world");
string s2(s1);
s1[0] = 'x';
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
string s3("hello world xxx");
s1 = s3;
cout << s1.c_str() << endl;
cout << s3.c_str() << endl;
s3 = s3;
cout << s3.c_str() << endl;
cout << s3.c_str() << endl;
}能够理解上述代码后,我们来看看上述代码的预期行为(调用库):
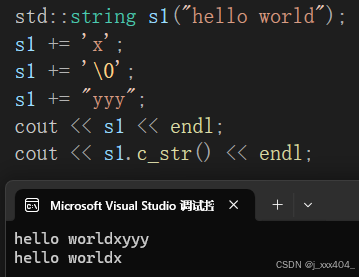
可见,我们此时使用c_str是有风险的,因为c_str遇到\0会返回。
2.8流插入
std::ostream& operator<<(std::ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}此时结果预期和库中的一样:
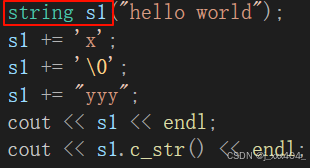
而造成这一切的原因是因为之前都是用了strcpy进行拷贝
对2.6中的原代码进行测试:
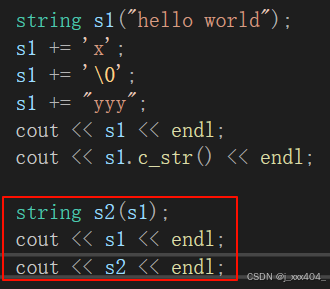
此时的结果为:
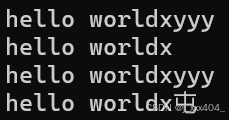
原因是因为在字符串在插入了\0,虽然它不会在结果中显式显示。并且,c_str会在遇到\0后停止但其size大小不变,因此会走完范围for,产生随机值,所以,我们在此处以及之后不使用strcpy(除过最开始的实现构造函数,因为那里是使用c型的构造)。
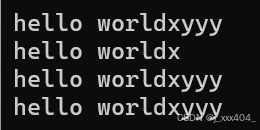
再将上述所有的strcpy改为memcpy(最开始的代码也都改了)后的结果:
2.9resize
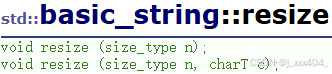
string.cpp
void string::resize(size_t n, char ch)
{
if (n <= _size)
{
//删除,保留前n个
_size = n;
_str[_size] = '\0';
}
else
{
reserve(n);
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\n';
}
}Test.cpp
string s1;
s1.resize(100, '*');
cout << s1 << endl;
s1.resize(6);
cout << s1 << endl;
s1.resize(10, '#');
cout << s1 << endl;2.10clear
string.h
void clear()
{
_str[0] = '\0';
_size = 0;
}2.11find
string.cpp
size_t string::find(char ch, size_t pos)
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
return i;
}
return npos;
}
size_t string::find(const char* str, size_t pos)
{
assert(pos <= _size);
const char* ptr = strstr(_str + pos, str);
if (ptr)
{
return ptr - _str;
}
else
{
return npos;
}
}2.12substr
string.h
public:
const static size_t npos; string.cpp
string string::substr(size_t pos, size_t len)
{
assert(pos < _size);
if (len == npos || len > _size - pos)
{
len = _size - pos;
}
string sub;
sub.reserve(len);
for (size_t i = 0; i < len; i++)
{
sub += _str[pos + i];
}
return sub;
}Test.cpp
string s1;
s1.resize(100, '*');
cout << s1 << endl;
s1.resize(6);
cout << s1 << endl;
s1.resize(10, '#');
cout << s1 << endl;
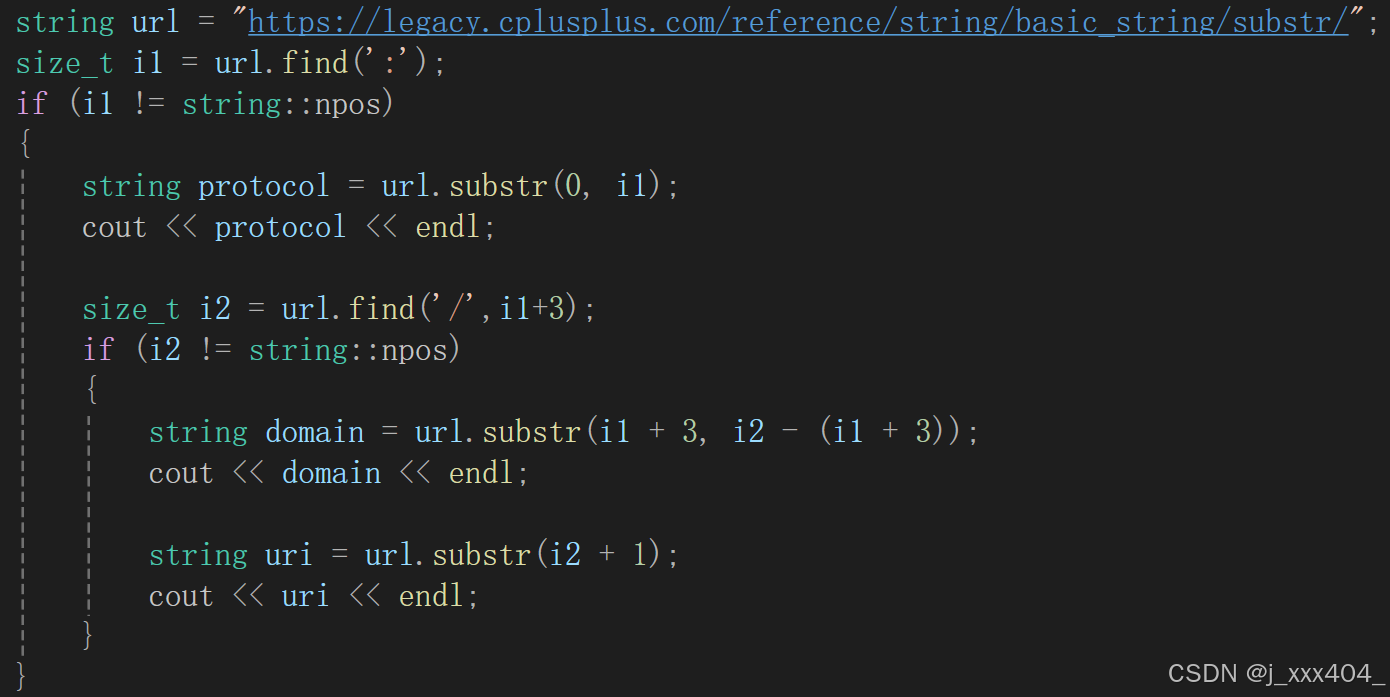
string url = "https://legacy.cplusplus.com/reference/string/string/rfind/";
size_t i1 = url.find(':');
if (i1 != string::npos)
{
string protocol = url.substr(0, i1);
cout << protocol << endl;
size_t i2 = url.find('/', i1 + 3);
if (i2 != string::npos)
{
string domain = url.substr(i1 + 3, i2 - (i1 + 3));
cout << domain << endl;
string uri = url.substr(i2 + 1);
cout << uri << endl;
}
}2.13流提取
std::istream& operator>>(std::istream& in, string& s)
{
s.clear();
char buff[256];
int i = 0;
char ch;
ch = in.get();
while (ch != '\n' && in.good())
{
buff[i++] = ch;
if (i == 255)
{
buff[i] = '\0';
s += ch;
i = 0;
}
ch = in.get(); // 继续读取下一个字符
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}Test.cpp
string s1, s2("xxxxxx");
cin >> s1 >> s2;
cout << s1 << endl;
cout << s2 << endl;2.14运算符重载
复用!!!
string.cpp
bool string::operator<(const string& s)const
{
return strcmp(_str, s._str) < 0;
}
bool string::operator<=(const string& s)const
{
return *this < s || *this == s;
}
bool string::operator>(const string& s)const
{
return !(*this <= s);
}
bool string::operator>=(const string& s)const
{
return !(*this < s);
}
bool string::operator==(const string& s)const
{
return strcmp(_str, s._str) == 0;
}
bool string::operator!=(const string& s)const
{
return !(*this == s);
}2.15getline
std::istream& getline(std::istream& in, string& s, char delim)
{
s.clear();
char buff[256];
int i = 0;
char ch;
ch = in.get();
while (ch != delim)
{
buff[i++] = ch;
if (i == 255)
{
buff[i] = '\0';
s += ch;
i = 0;
}
ch = in.get(); // 继续读取下一个字符
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}2.16swap
如下图,相对于算法库中的,标准库内的交换代价太大。

string.cpp
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}模拟标准模板库中的
string.h
template <class T>
void swap(T& a, T& b)
{
T c(a); a = b; b = c;
}
//优化
inline void swap(string& a, string& b)
{
a.swap(b);
}Test.cpp
xxx::string s3("hello world"), s4("xxxxxx");
s3.swap(s4);
swap(s3, s4);本章完。