awk 是一种处理文本文件的语言,是一个强大的文本分析工具。
awk 可以逐行读取文本文件,并提供类似编程语言的功能,例如:
变量定义与计算
条件判断与循环
字符串处理与格式化输出
这些特性让 AWK 在处理结构化文本(如 CSV、日志文件)时非常高效。
之所以叫 awk 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
java
awk options 'pattern {action}' file选项参数说明:
options:是一些选项,用于控制 awk 的行为。
pattern:是用于匹配输入数据的模式。如果省略,则 awk 将对所有行进行操作。
{action}:是在匹配到模式的行上执行的动作。如果省略,则默认动作是打印整行。
options 参数说明:
-F <分隔符> 或 --field-separator=<分隔符>: 指定输入字段的分隔符,默认是空格。使用这个选项可以指定不同于默认分隔符的字段分隔符。
-v <变量名>=<值>: 设置 awk 内部的变量值。可以使用该选项将外部值传递给 awk 脚本中的变量。
-f <脚本文件>: 指定一个包含 awk 脚本的文件。这样可以在文件中编写较大的 awk 脚本,然后通过 -f 选项将其加载。
-V 或 --version: 显示 awk 的版本信息。
-h 或 --help: 显示 awk 的帮助信息,包括选项和用法示例。
案例
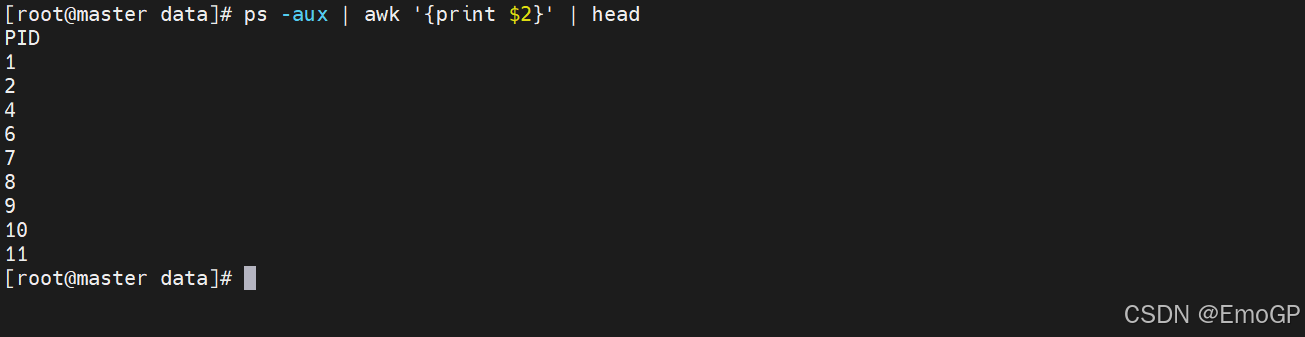
使用ps -aux命令后,取出PID列
ps -aux 输出结果的字段分隔符是空格,但需要注意的是:它使用的是多个连续空格作为分隔符(而非单个空格),并且字段之间的空格数量不固定(会根据字段内容长度自动调整,以对齐列)。
java
[root@master data]# ps -aux | head
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 194460 7592 ? Ss 10月24 0:35 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 10月24 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 10月24 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S 10月24 0:00 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S 10月24 0:08 [migration/0]
root 8 0.0 0.0 0 0 ? S 10月24 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 10月24 2:13 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< 10月24 0:00 [lru-add-drain]
root 11 0.0 0.0 0 0 ? S 10月24 0:03 [watchdog/0]这里 USER 与 PID、PID 与 %CPU 等字段之间是多个连续空格,而非单个空格。
用 awk 提取字段,无需精确指定空格数量,因为 awk 工具默认会将连续的空格、制表符等视为分隔符,直接按字段索引处理即可(例如 1 表示 USER,2 表示 PID 等)。