标题:Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis
作者:Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, Ekaterina Deyneka, Tsai-Shien Chen, Anil Kag, Yuwei Fang, Aleksei Stoliar, Elisa Ricci, Jian Ren, Sergey Tulyakov
单位:Snap Inc., University of Trento, UC Merced, Fondazione Bruno Kessler
发表:CVPR 2024
论文链接 :https://arxiv.org/pdf/2402.14797
项目链接 :https://snap-research.github.io/snapvideo/
代码链接:暂无
关键词:文本到视频生成(Text-to-Video Synthesis)、时空 Transformer(Spatiotemporal Transformers)、扩散模型(Diffusion Models)、EDM 框架(EDM Framework)、FIT 架构(FIT Architecture)、视频生成效率优化(Video Generation Efficiency Optimization)、时空一致性(Temporal Consistency)
在文本引导的视觉生成领域,图像生成技术已实现极高的质量与通用性,但视频生成仍面临运动保真度低、计算开销大、时空一致性差等核心挑战。Snap Inc. 与多所高校联合提出的Snap Video,通过重构扩散框架、创新网络架构,首次实现了数十亿参数文本到视频模型的高效训练,在运动质量与生成效率上达到当时业界领先水平。
一、研究背景与问题提出
1.1 文本到视频生成的现状与痛点
近年来,基于扩散模型的文本到视频(Text-to-Video, T2V)技术快速发展,主流方法(如 Imagen Video、Make-A-Video)均以文本到图像模型为基础,通过插入临时层(如时间注意力)扩展 U-Net 架构,同时采用 "图像 + 视频" 联合训练以提升多样性。但这类方法存在三大核心缺陷:
- 模态不匹配:图像与视频的本质差异在于视频帧间的内容冗余(如连续帧的背景不变性),而现有方法将视频视为 "图像序列" 训练,导致训练与推理时的信号噪声比(SNR)失衡,引发运动 artifacts。
- 架构扩展性差:U-Net 需独立处理每个视频帧,引入时间维度后需 volumetric 注意力等计算密集型操作,训练与推理效率极低 ------ 这直接限制了模型规模(难以突破百亿参数),而规模正是提升生成质量的关键因素。
- 运动建模薄弱:现有方法将空间与时间建模分离(先处理单帧空间信息,再拼接时间关系),易生成 "动态图像"(仅轻微帧间变化)而非具有复杂运动的真实视频,且常出现闪烁、物体形变等时空不一致问题。
1.2 核心研究目标
Snap Video 的核心目标是构建一个 "视频优先"(Video-First)的生成框架(下图),解决上述问题:
- 重构扩散模型框架,适配视频的时空冗余特性,消除图像 - 视频模态不匹配;
- 设计高效的 Transformer 架构,替代 U-Net 以突破规模限制,同时提升训练 / 推理速度;
- 实现空间与时间的联合建模,生成更高质量、更复杂的运动,且保持文本语义对齐。
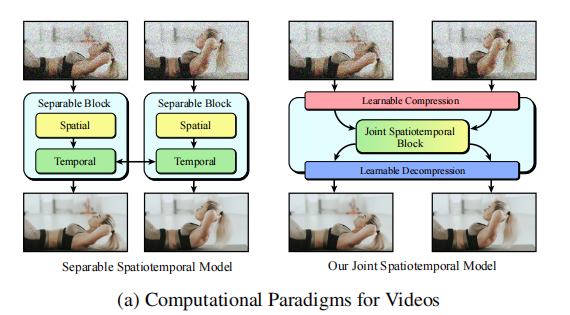
二、核心方法详解
Snap Video 的技术方案围绕扩散框架优化 、模态匹配策略 、高效网络架构三大模块展开,形成端到端的文本到视频生成系统。
2.1 基于 EDM 的视频扩散框架重构
现有扩散模型(如 EDM)为图像生成设计,直接应用于视频时会因帧间冗余导致 SNR 异常 ------ 视频帧的平均操作会降低噪声方差,使模型在低噪声水平下过度依赖 "帧平均" 恢复内容,引发训练 - 推理 mismatch。为此,Snap Video 对 EDM 框架进行了三点关键修改:
2.1.1 输入缩放与 SNR 校准
为保持视频与图像在扩散过程中的 SNR 一致,引入输入缩放因子 (其中 s 为空间上采样率,T 为视频帧数),将视频输入信号缩放至与图像相当的幅度。修改后的前向扩散过程定义为:
,其中
为原始视频,
为加噪后的视频,
为噪声标准差。这一修改确保了视频帧间冗余不会导致噪声被过度抑制,使扩散过程在时空维度上更稳定。
2.1.2 损失函数与参数重定义
为避免缩放因子引入的目标函数爆炸问题,重构了 EDM 的损失项与网络参数(如输入 / 输出缩放系数、跳跃连接系数)。核心是将训练目标与广泛使用的 v-prediction 框架对齐,确保 时目标函数仍稳定。关键参数定义对比如下表所示:

2.1.3 采样器适配
修改后的扩散过程需对应调整采样器:在推理时,先将去噪网络输出 除以
,再将最终去噪结果
乘以
恢复原始信号幅度,确保生成视频的亮度、对比度与训练数据一致。
2.2 图像 - 视频模态匹配策略
为解决 "图像与视频联合训练" 中的模态差异问题,Snap Video 提出将图像视为 "无限帧率视频":
- 原理:图像可看作
的视频(帧间无变化),通过引入 "可变帧率训练",在训练中动态调整图像的 "虚拟帧率",使模型将图像视为视频的特殊 case,而非独立模态;
- 优势:无需为图像与视频设计两套扩散参数,同时让图像训练数据辅助模型学习空间细节,视频数据辅助学习时间关系,消除模态切换带来的性能损失。
2.3 基于 FIT 的规模化时空 Transformer 架构
为替代效率低下的 U-Net,Snap Video 基于 FIT(Far-reaching Interleaved Transformers) 设计了高效的时空联合建模架构,核心是通过 "可学习的压缩 latent 表示" 实现时空维度的统一处理,大幅降低计算开销。
2.3.1 架构核心设计
FIT 的核心思想是 "聚焦计算于压缩的 latent 空间",而非原始像素空间,架构流程如下图所示(图 3b):
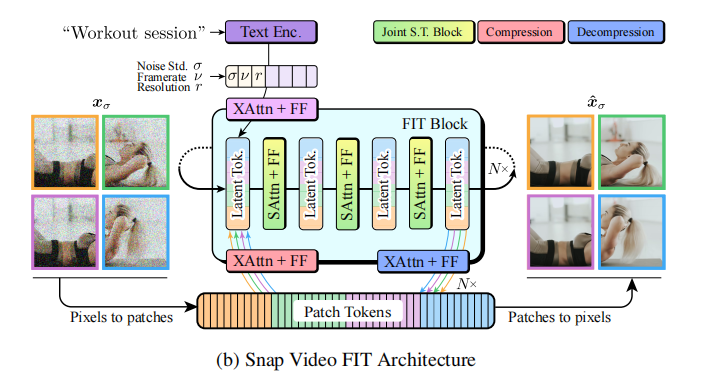
- Patch 化 :将输入视频(时空维度
- 分组与 Latent 初始化:将 Patch Tokens 按 "时空分组"(每组覆盖全部 T 帧,确保时间连续性),同时初始化一组 Latent Tokens(压缩表示,存储时空信息);
- FIT Block 计算:每个 Block 包含三步关键操作:
- Read 操作 :通过交叉注意力(Cross-Attention)将 Patch Tokens 的信息 "读入" Latent Tokens,同时融入文本嵌入(T5-11B 编码)、噪声水平
- Self-Attention:在 Latent Tokens 上执行自注意力,实现时空联合建模(无需分离空间 / 时间注意力);
- Write 操作:通过交叉注意力将 Latent Tokens 的信息 "写回" Patch Tokens,更新空间细节;
- Read 操作 :通过交叉注意力(Cross-Attention)将 Patch Tokens 的信息 "读入" Latent Tokens,同时融入文本嵌入(T5-11B 编码)、噪声水平
- 像素重建:将最终的 Patch Tokens 投影回像素空间,生成去噪后的视频。
2.3.2 关键优化(针对视频生成)
为适配视频的时空特性,对原始 FIT 进行三点修改:
- Patch 大小优化 :采用
- 分组策略调整:每组 Patch 覆盖全部 T 帧,确保 Latent Tokens 能建模完整的时间序列;
- 计算效率提升:移除原始 FIT 中对大量 Patch Tokens 的局部注意力,替换为前馈网络(FFN),降低计算复杂度(尤其对高分辨率视频)。
2.3.3 两阶段级联生成
为生成高分辨率视频(最终 px),采用两阶段级联模型:
- 第一阶段 :生成低分辨率视频(
- 第二阶段:对低分辨率视频进行上采样,聚焦于高频率细节(如纹理、光照),训练时对输入添加噪声以提升鲁棒性。
2.4 训练与推理细节
2.4.1 训练配置
- 数据集:126.5 万张图像 + 23.8 万小时视频(含人工标注与合成字幕);
- 优化器 :LAMB(适应大 batch 训练),学习率
- batch size:4096(2048 视频 + 2048 图像),支持 3.9B 参数模型训练;
- 训练步数:第一阶段 55 万步,第二阶段 37 万步(基于第一阶段权重微调)。
2.4.2 推理配置
- 采样器:EDM 的二阶 Runge-Kutta 确定性采样器;
- 采样步数:第一阶段 256 步,第二阶段 40 步;
- 优化策略:采用 Classifier-Free Guidance(提升文本对齐)、动态阈值(减少过饱和)、振荡引导(提升细节)。
三、实验验证与结果分析
Snap Video 在公开数据集(UCF101、MSR-VTT)与内部数据集上进行了全面评估,从定量指标、效率、用户研究三方面验证性能。
3.1 实验设置
- 评估指标:
- 视频质量:FID(帧间一致性)、FVD(视频生成质量);
- 文本对齐:CLIPSIM(生成视频与文本的 CLIP 相似度)、IS(Inception Score);
- 效率:训练吞吐量(ms / 视频 / GPU)、推理吞吐量(ms / 视频 / GPU);
- 基线方法:U-Net(85M/284M 参数)、Gen-2、Pika、Floor33、Make-A-Video 等主流 T2V 模型。
3.2 定量结果分析
3.2.1 架构效率对比(内部数据集,64×36px)
下表(表 2)对比了不同架构的性能与效率,可见 FIT 架构的显著优势:
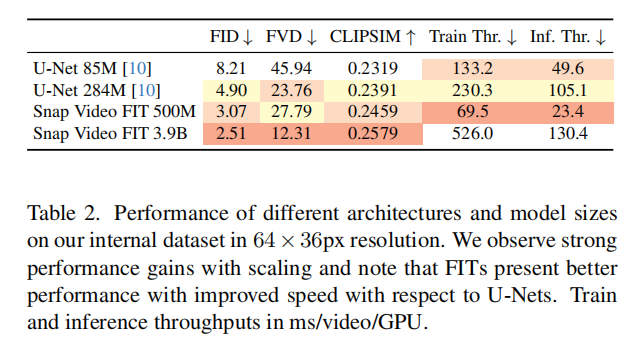
关键结论:
- FIT 架构在相同参数规模下,FID 比 U-Net 低 37%-50%,CLIPSIM 高 2%-7%,运动质量(FVD)提升更显著;
- 效率优势:FIT 500M 训练速度是 U-Net 284M 的 3.31 倍,推理速度是 4.49 倍;
- 规模扩展性:3.9B 参数的 FIT 推理速度仅比 284M U-Net 高 23%,但性能大幅提升(FVD 从 23.76 降至 12.31)。
3.2.2 扩散框架消融实验
验证输入缩放 、模态匹配(图像视为视频)的影响:
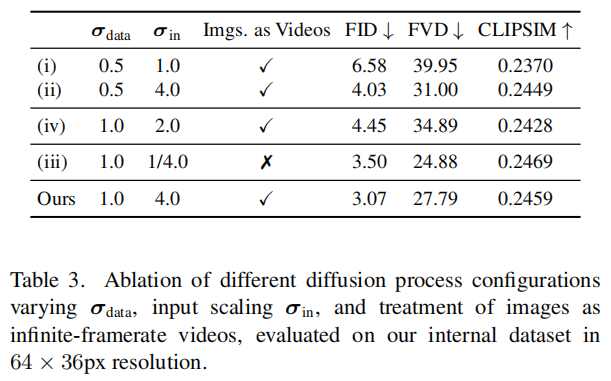
关键结论 :输入缩放 与模态匹配策略共同作用,使 FID 降低 53%、FVD 降低 30%,验证了框架重构的有效性。
3.2.3 公开数据集对比
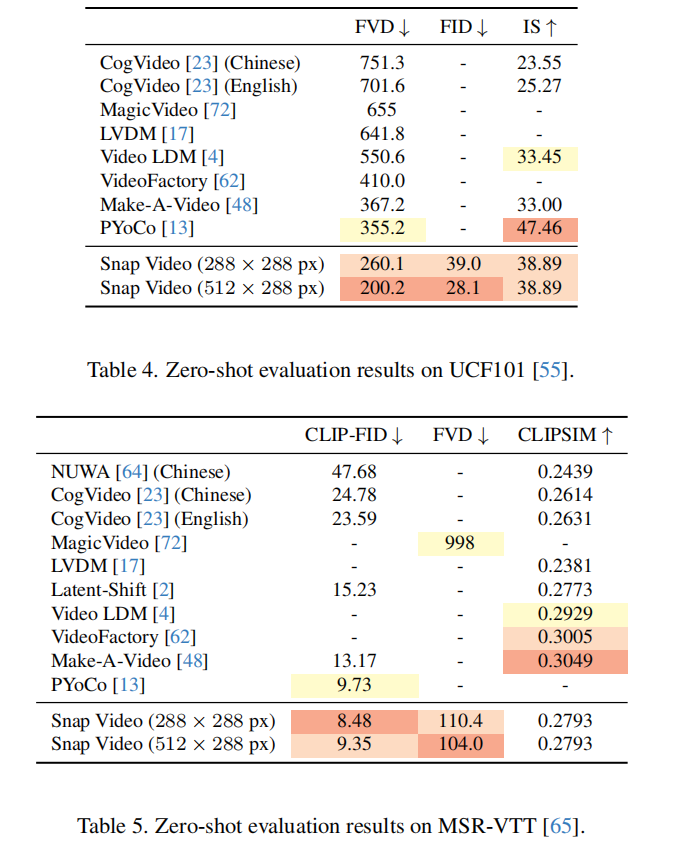
在 UCF101(动作视频)与 MSR-VTT(通用视频)上的零样本(Zero-Shot)性能:
- UCF101:Snap Video(512×288px)的 FVD 为 200.2,显著低于 Make-A-Video(367.2)、PYoCo(355.2),IS 达 38.89(与 Gen-2 相当);
- MSR-VTT:Snap Video 的 CLIP-FID 为 8.48(288×288px),优于 PYoCo(9.73)、Make-A-Video(13.17),CLIPSIM 达 0.2793(文本对齐能力强)。
3.3 用户研究结果
为验证主观质量,对 65 个 "高动态场景" 提示词(如 "沙漠越野车疾驰""太空战舰战斗")生成视频,对比 Snap Video 与 Gen-2、Pika、Floor33,5 名用户对 "照片真实感""文本对齐""运动数量""运动质量" 四项指标投票,结果如下表(表 6):
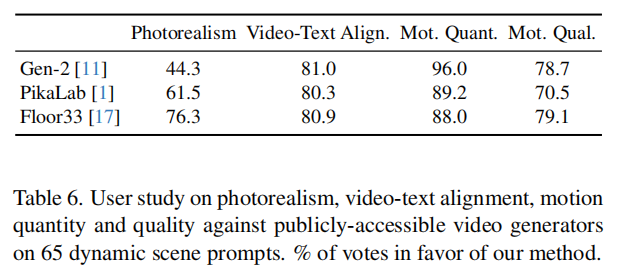
关键发现:
- Snap Video 的运动质量与数量远超所有基线,96% 的场景中运动复杂度高于 Gen-2(避免 "动态图像" 问题);
- 文本对齐率达 80% 以上,81% 的场景中优于 Gen-2;
- 照片真实感与 Gen-2 相当,显著优于 Pika 与 Floor33。
3.4 定性结果分析
下图(图 4)展示了 Snap Video 与主流方法的定性对比:

- 基线问题:Make-A-Video、PYoCo 等方法常出现 "闪烁"(如恐龙骨架视频的背景抖动)、"运动僵硬"(泰迪熊跑步动作不连贯);
- Snap Video 优势:能生成复杂运动(如宇航员厨房烹饪的连贯动作)、保持时空一致性(如金毛犬吃冰淇淋的场景中,沙滩与夕阳背景无闪烁),且细节更丰富(如毛发纹理、光影变化)。
四、局限性与未来方向
尽管 Snap Video 表现出色,但仍存在以下局限性:
- 文本渲染能力弱:生成包含文字的场景时(如广告牌、书籍),文字易拼写错误,原因是训练数据中 "文本描述 - 文字图像" 的对齐样本不足;
- 物体计数不准确:难以精确生成指定数量的物体(如 "3 只兔子" 可能生成 2 只或 4 只),因视频中物体的进出场景与相机运动导致计数标注噪声大;
- 复杂位置关系建模差:无法可靠生成包含复杂空间关系的场景(如 "红 - 绿 - 蓝三层立方体堆叠");
- 风格化一致性不足:部分场景中艺术风格(如梵高画风)仅体现在静态帧,帧间风格不一致;
- 否定提示处理差:难以理解否定性描述(如 "盘子里没有香蕉" 可能仍生成香蕉)。
未来方向可围绕:
- 引入 OCR 数据增强文本渲染能力;
- 设计专门的 "物体计数" 与 "空间关系" 监督信号;
- 融合 3D 几何先验,提升复杂场景的时空一致性;
- 优化提示词理解模块,增强对否定、风格等细粒度指令的支持。
五、总结与启示
Snap Video 的核心贡献在于:
- 框架层面:首次为视频生成重构 EDM 扩散框架,通过输入缩放与模态匹配解决图像 - 视频的本质差异;
- 架构层面:用 FITTransformer 替代 U-Net,实现 "时空联合建模 + 规模化训练",3.9B 参数模型训练效率比 U-Net 高 3 倍;
- 应用层面:验证了 "压缩 latent 表示" 在视频生成中的价值,为后续大模型(如百亿参数 T2V)提供了高效架构范式。
其技术启示在于:视频生成需 "视频优先" 设计,而非简单扩展图像模型 ------ 通过适配视频的时空冗余特性、优化计算效率,才能在规模与质量上突破现有瓶颈。Snap Video 的方法不仅提升了当前 T2V 的性能上限,也为多模态生成(如文本 - 3D 视频、交互式视频)提供了重要参考。