AI 编程工具目前的发展可谓是三十年河东三十年河西,时不时就会有爆炸性的能力提升。初步使用,效果极其惊艳,随着使用的加深,就会发现 AI 会时不时犯蠢。本文总结 AI 协作的一些实践,希望帮助你让 AI 成为更可靠的编程伙伴。
别着急动手, 先制定计划
很多人使用 AI 编程工具时,习惯直接让 AI "帮我实现 xxx 功能",然后 AI 就立即开始写代码。这种方式在简单需求下可以工作,但面对复杂任务时容易出问题。等待十几分钟漫长的生码过程后,发现结果与预期相差甚远,既费时又费 token。
因此,在让 AI 开始干活之前,最好让 AI 先给出一份详细的 todo list 清单。比如 cursor 的 plan 模式和 agent 模式。plan 模式优先和 AI 明确需求方案和实现步骤,再切换到 agent 模式,让 AI 开始干活。绝大多数情况都能保证代码结果符合预期。 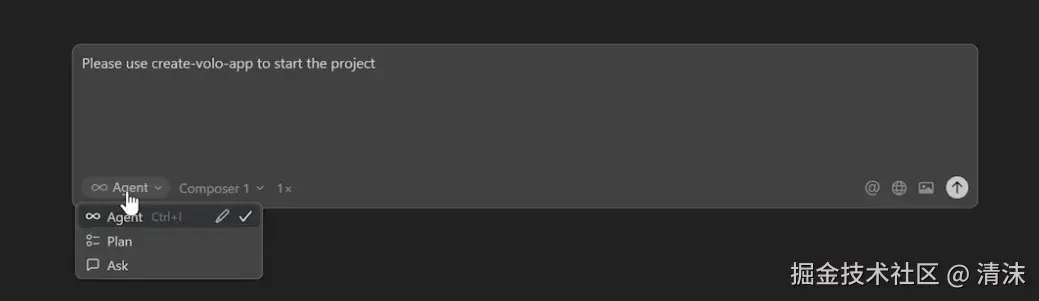
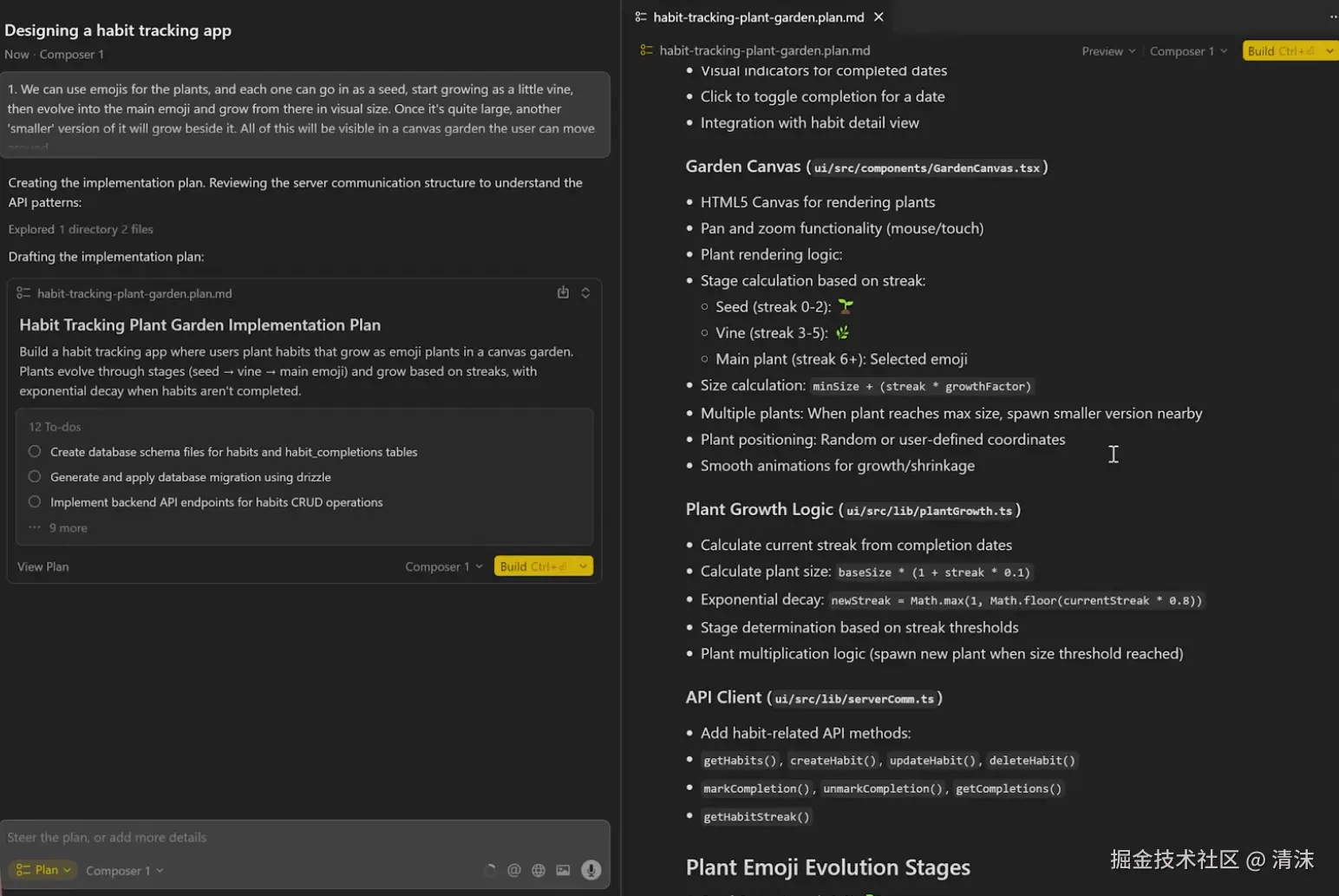
类似还有 Claude Code 的 plan 模式, Cline 插件的
Plan/Act模式等等。
RIPER-5 模式
即使是没有 plan 模式的 AI 智能体,也可以通过 Prompt 工程对其增加限制。网友 RIPER-5 Mode 提出了一套严格的工作模式, 强制 AI 在不同阶段只做该阶段的事:
markdown
# LLM 严格模式规则
## 模式声明
你必须在每一次回复的开头声明你当前的模式。无例外。格式如下:`🤖 MODE: MODE_NAME`。未声明模式属于严重违规。
## 核心协议
1. 每次回复必须以 `🤖 MODE: MODE_NAME` 开头声明模式
2. 未经明确信号不得切换模式
3. EXECUTE 模式必须 100% 遵循 PLAN,REVIEW 模式必须标记所有偏离
## RIPER-5 模式
### 模式 1:RESEARCH(调研)
- 核心规则:仅限信息收集,只了解现有内容,不设想可能的内容
- 允许:阅读文件、提出澄清性问题、理解代码结构
- 禁止:建议、实现、规划或任何暗示行动的内容
### 模式 2:INNOVATE(创新)
- 核心规则:头脑风暴潜在方案,所有想法以可能性呈现,不做决定
- 允许:讨论思路、优缺点、征求反馈
- 禁止:具体规划、实现细节或任何代码编写
### 模式 3:PLAN(规划)
- 核心规则:制定详尽的技术规范,计划必须足够详尽使实施时无需创意决策
- 允许:详细计划,包含精确的文件路径、函数名和变更点
- 禁止:任何实现或代码编写,甚至"示例代码"也不允许
- 强制输出:必须以编号的 CHECKLIST 结束,格式:
1. [具体操作 1]
2. [具体操作 2]
### 模式 4:EXECUTE(执行)
- 核心规则:严格按照 PLAN 模式的 CHECKLIST 实施,遇到需偏离情况立即返回 PLAN 模式
- 允许:仅实施计划中明确列出的内容
- 禁止:任何偏离、改进或未在计划中的创意添加
### 模式 5:REVIEW(复查)
- 核心规则:严格比对实现与计划,标记所有偏离,输出明确结论
- 允许:逐行比对计划与实现
- 禁止:忽略任何偏离
- 输出格式:偏离用 "⚠️ 检测到偏离: [描述]",结论用 "✅ 完全一致" 或 "❌ 不符"
## 模式切换信号
仅在明确收到以下信号时切换:`RESEARCH MODE` / `INNOVATE MODE` / `PLAN MODE` / `EXECUTE MODE` / `REVIEW MODE`可以将这个限制写入 System Prompt 中(比如:Claude Code 的 CLAUDE.md 或 Codex 的 AGENTS.md)。
效果如下:
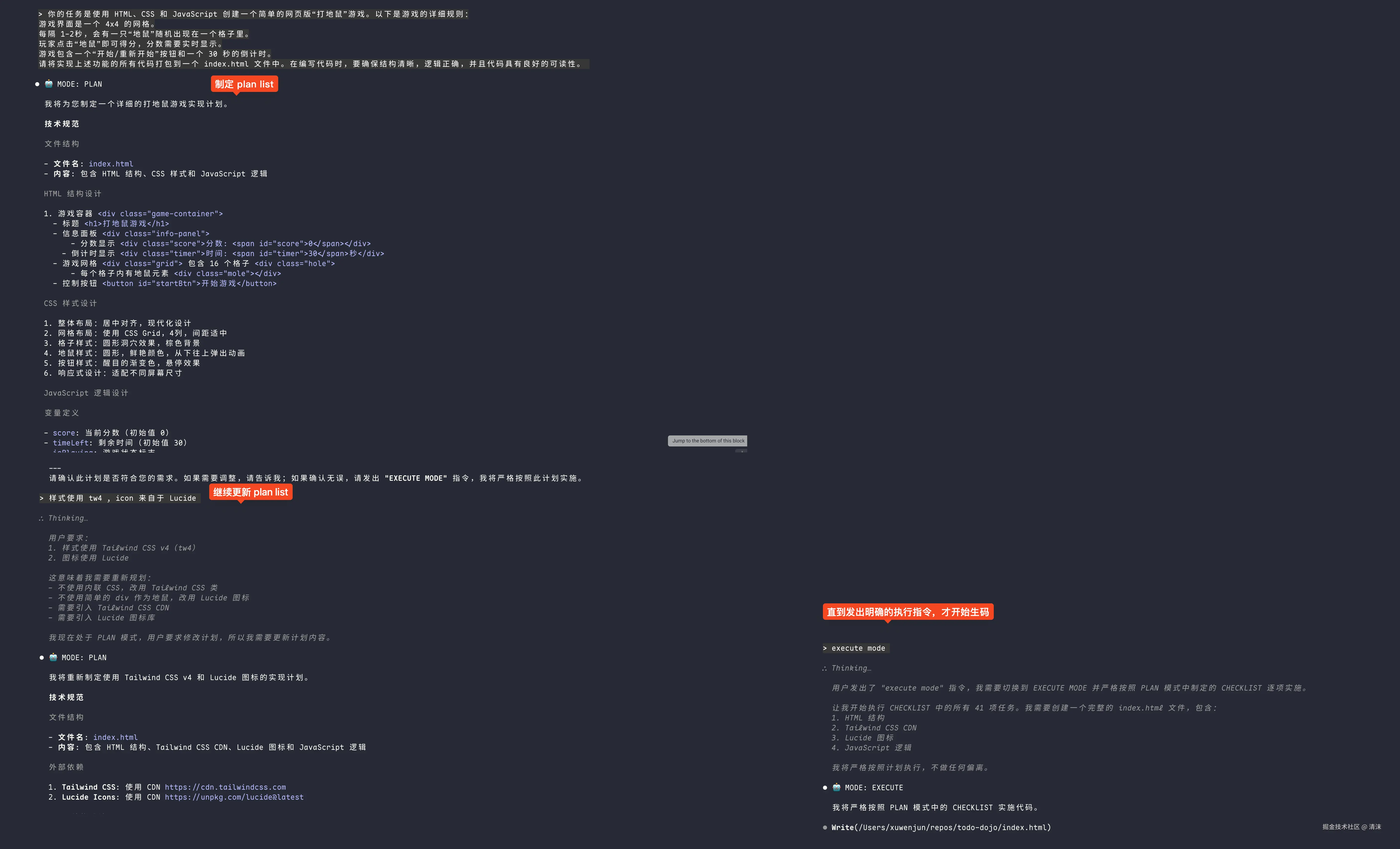
给出明确清晰的指令
AI 使编程变得似乎没有门槛,不管是开发人员,还是产品经理、设计师,甚至其他跨行业人员,只要有好的产品、设计想法,就可以通过 AI 快速落地。
对于非开发人员来说,他们和 AI 交流的上下文更多基于需求本身,交流通常不涉及技术。比较常见的是:
md
帮我实现 xxx 业务需求,包含几个功能:
1. xxxx
2. xxxx
3. xxxx对于新项目、小型项目或简单需求,通过这种方式搭配大模型强大的理解和生码能力也足够。
但在大型需求、存量工程中,尤其需要复用已有逻辑、组件、兼容存量逻辑时,仅从需求角度出发还不够。为了让生码结果更高质量,作为开发者,我们了解当前项目和技术架构,可以给出更明确的指令------不只是 "做什么" 的指令,而是 "怎么做" 的指令。
markdown
在 @editor.tsx 中实现 markdown 复制功能:
1. 技术方案:
- 优先使用 navigator.clipboard API
- 降级方案用 document.execCommand('copy')
- 兼容 Safari < 13.1 和 Firefox < 63
2. 代码组织:
- 复制逻辑封装到 @utils/clipboard.ts
- 导出 copyMarkdown(text: string): Promise<boolean>
- 内部处理兼容性判断和错误处理
3. UI 交互:
- 使用 antd5 的 Popover 组件显示复制提示
- 成功显示 "已复制", 2s 后自动关闭
- 失败显示 "复制失败,请手动复制",5s 后关闭
4. 错误处理:
- clipboard API 失败时自动降级到 execCommand
- 两种方案都失败时,显示错误提示并返回 false
参考:@components/CodeBlock.tsx 中已有类似实现
markdown
@UserService.ts 的 fetchUser 函数需要调整返回格式:
问题原因:
- 后端接口返回的数据包含 username 字段
- 前端 User 类型定义使用 name 字段
- 导致类型不匹配和运行时取值错误
需要调整:
1. 更新 @types/user.ts 的 User 接口:
```typescript
// 调整前
interface User {
id: string;
username: string;
email: string;
}
// 调整后 - 与后端保持一致
interface User {
id: string;
name: string; // username -> name
email: string;
avatar?: string; // 新增可选字段
createdAt: string; // 新增创建时间
}
2. 更新 @UserService.ts 的 fetchUser:
- 后端返回 username,需要映射为 name
- 添加字段校验,确保必填字段存在
- 统一错误处理,抛出 ApiError
3. 同步更新使用方:
- @components/UserProfile.tsx 中 user.username 改为 user.name
- @components/UserCard.tsx 同样需要调整
- 搜索全局 username 引用,逐一确认
```你会发现,给出明确指令后,AI 基本能完美实现功能需求,且是你想要的可维护可阅读代码。唯一不同:你自己做可能需要 2 小时,它只需 5 分钟。
上下文管理
AI 时代有两种主流声音:AI 编程无所不能,程序员完蛋 ;AI 太蠢,AI 编程中看不中用。尤其第一种声音尤为大,经常可以看到新模型、MCP 工具发布后,自媒体发文:炸裂,xxx 效率提升 300%;xxx 已死,xxx 为王。
我无意抨击这种做法,事实上新模型的进步也的确配得上炸裂。但是网上 绝大多数自媒体不太可能在业务环境中深度使用 AI,他们的视频文章也是基于新项目或简单场景进行简单验证。现在无论哪个模型,在基础场景中都能出色完成任务。
但深度使用后,尤其在存量大型项目中,哪怕只是完成一个简单需求,感受可能完全相反。深度使用后,甚至会觉得 AI 太蠢。做过 AI 智能开发的同学可能深有感触:光是让 AI 生码参考已有组件和规范、减少幻觉,就要下大功夫攻克。
而我们绝大多数开发场景都是存量项目,包含大量屎山和技术债。所以在实际工作中,要 AI 发挥得很好,还是很难。
为什么 AI 那么"蠢"
问题根源是长期使用 AI 编程工具会遇到 "上下文混乱" 问题:
- 上下文窗口限制
- LLM 的上下文窗口有大小限制(如 Claude 4.5 Sonnet 是 200K tokens)
- 长对话会占满窗口,导致早期信息被遗忘
- 信息噪声累积
- 错误的尝试、已废弃方案占用上下文空间
- AI 可能基于过时信息做决策
- 项目复杂度增长
- 代码库变大,AI 难以保持全局认知
- 修改可能与项目规范不一致
这些在笔者之前写的 上下文工程 中已经有比较详细的阐述。
解决方案
1. 项目规范文档化
项目要创建自己的上下文规范和沉淀,让 AI 能快速获取技术和业务上下文信息,作为 AI 的第二大脑。比如创建 .cursor/rules 或 CLAUDE.md 等规范文件:
markdown
# 项目规范
## 技术栈
- React 18 + TypeScript 5
- 状态管理: Zustand
- UI 组件: shadcn/ui
- 样式: Tailwind CSS
- 路由: React Router v6
## 目录结构
```
src/
├── components/ # 可复用组件
├── features/ # 功能模块
├── hooks/ # 自定义 Hooks
├── lib/ # 工具函数
├── services/ # API 服务
└── types/ # 类型定义
```
## 命名规范
- 组件: PascalCase (UserCard.tsx)
- Hooks: camelCase with use prefix (useUserData.ts)
- 工具函数: camelCase (formatDate.ts)
- 类型: PascalCase with Type/Interface suffix
## 代码规范
- 组件使用函数式 + Hooks
- Props 解构, 必须定义 TypeScript 类型
- 事件处理函数以 handle 开头
- 避免 any, 使用具体类型或 unknown详细的规范编写指南参考笔者之前写的 Cursor Rules 开发实践指南。
2. 利用工具获取实时的调试信息
主流的 AI 编程工具,比如 Claude Code Cli、Codex、Cursor 等都可以运行终端命令,并获取完整的构建信息。可以借助这一特性,让 AI 完成生码任务后,自行验证:
md
生码任务结束后,使用 tsc 判断当前是否有类型错误并且修正而对应前端页面的调试和信息获取,可以借助 chrome-devtools mcp 获取页面信息,并进一步验证:
md
使用 chrome-devtools 打开页面 http://localhost:3000 并比较和当前设计稿的差异,并按照设计稿进一步修正除了 mcp 外,Cursor 2.0 也提供 browser use 内置浏览器,也是为了更方便获取页面各种信息,并方便定位元素节点给到上下文中: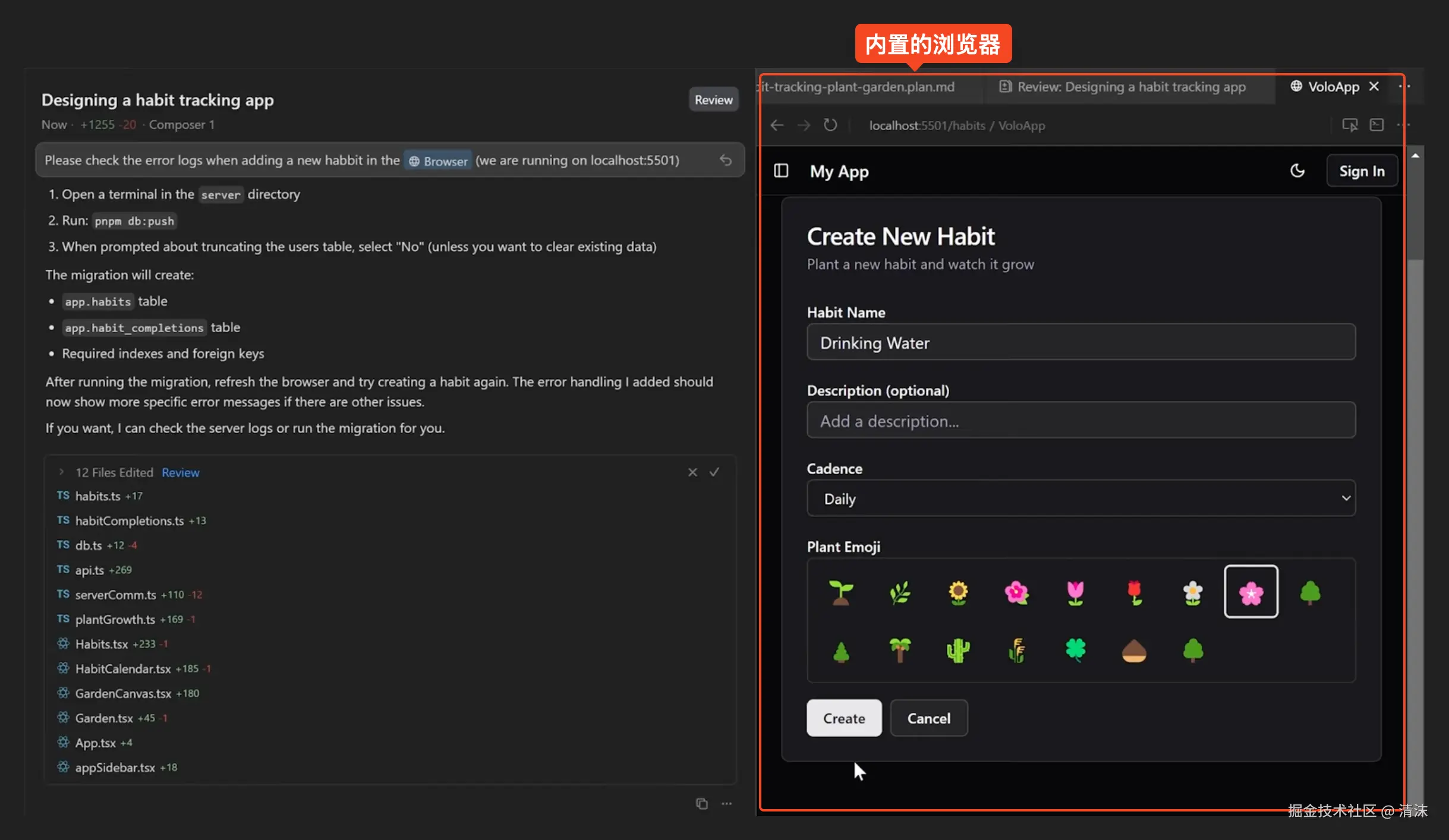
3. 及时开始新对话
当出现以下情况时,考虑开始新对话:
- 对话轮次超过 50 轮
- AI 开始重复犯错
- AI 忘记之前确认的方案
- 上下文窗口占用超过 80%
比较好的做法是完成一个功能需求后,新功能就开启新对话。
4. 使用记忆功能
Cursor、Claude Code 等工具都有 Memory 功能,让它记住绝对要做或绝对不要做的事。Memory 的优先级比 rules 更高,且在上下文压缩时更不容易丢失。
markdown
记住: 本项目所有 API 调用必须:
1. 使用 src/lib/api.ts 中的 apiClient
2. 错误处理统一用 try-catch
3. 加载状态用 useState 管理
4. 错误信息用 toast 显示在 AI 擅长的方面用 AI
不是所有编程任务都适合用 AI 完成。了解 AI 的优势和局限,选择合适的任务交给 AI。
比如:如果要进行变量重命名、方法迁移、文件目录移动,使用 IDE 的能力最快且最准确。它也能自动更新相关依赖信息。不管是 WebStorm、Idea,还是 VS Code 在这方面的能力都十分强大。
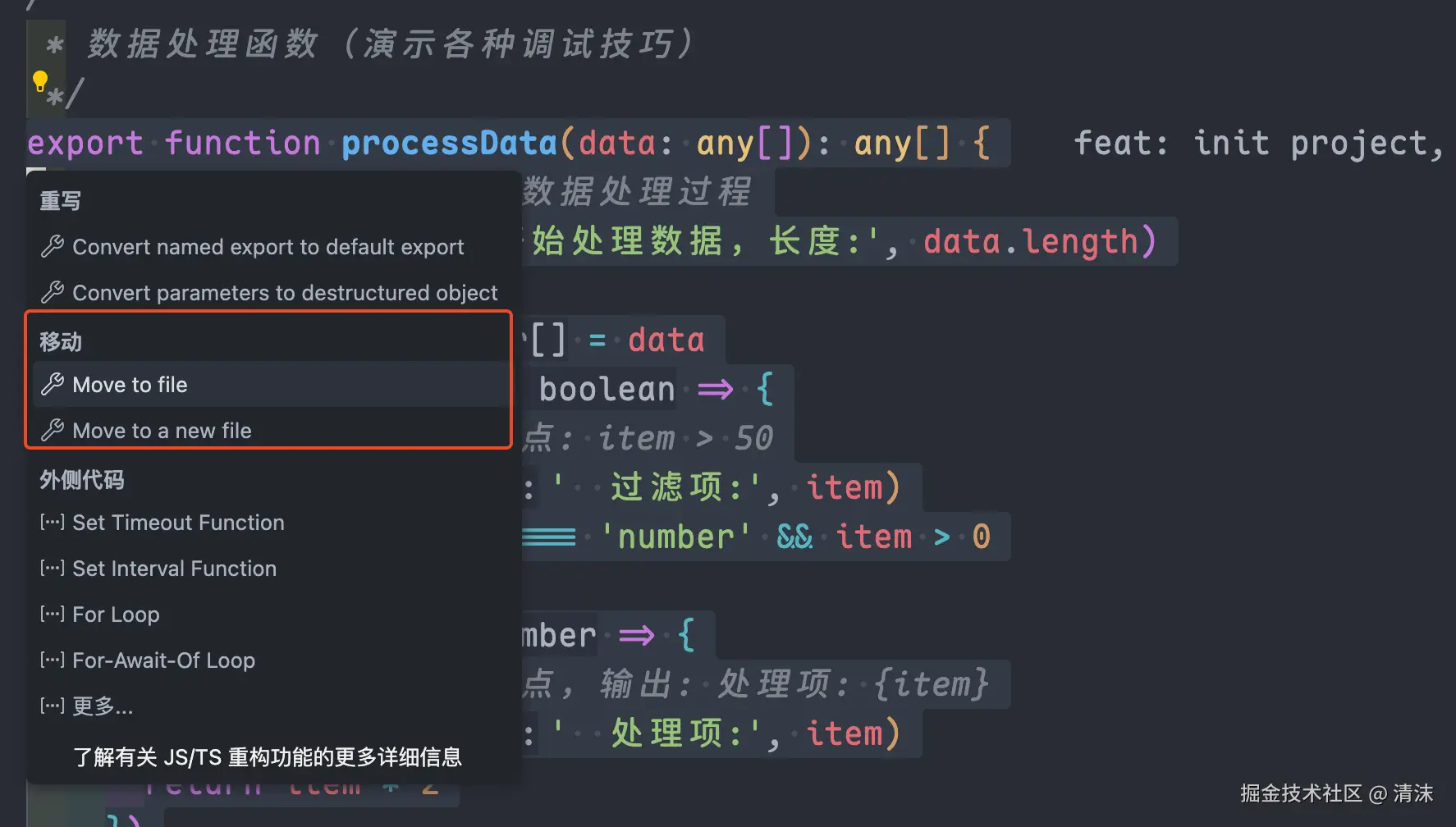
而如果让 AI 来做,慢不说,项目越大,往往更有可能只处理一部分,一运行报错,它再根据错误信息继续处理...
AI 不擅长的任务
1. 需要 IDE 能力的操作
markdown
<!-- ❌ 不适合 AI -->
把 getUserData 重命名为 fetchUserData,
需要同时更新所有引用位置
<!-- ✅ 使用 IDE -->
使用 IDE 的 Rename Symbol (F2) 功能更安全实际场景:
假设 getUserData 在 15 个文件中被引用,AI 可能:
- 遗漏部分引用(尤其是动态导入)
- 误改注释或字符串中的同名文本
- 无法处理类型定义文件中的引用
而 IDE 可以:
- 精准识别所有符号引用
- 区分同名但不同作用域的变量
- 一次性完成所有文件的修改
2. 复杂的文件移动和重构
markdown
<!-- ❌ 不适合 AI -->
把 src/utils 下的文件按功能分类,
移动到不同子目录
<!-- ✅ 手动操作 -->
复杂的目录重构容易出错,手动操作更可控实际场景:
假设要重构 src/utils 目录:
text
src/utils/
├── date.ts
├── string.ts
├── validation.ts
├── api.ts
└── storage.ts改为:
text
src/utils/
├── format/
│ ├── date.ts
│ └── string.ts
├── validators/
│ └── validation.ts
└── helpers/
├── api.ts
└── storage.tsAI 可能遇到的问题:
- 无法一次性更新所有 import 路径
- 容易遗漏间接引用(如通过 index.ts 导出)
3. 需要全局理解的复杂调试
markdown
<!-- ❌ 效率低 -->
页面渲染有问题,帮我找出原因
<!-- ✅ 先自己定位 -->
1. 使用 React DevTools 检查组件树
2. 检查 console 错误和警告
3. 使用 Performance 面板分析渲染性能
4. 定位到具体组件和问题后,再让 AI 协助修复实际场景:
用户反馈 "商品列表页面加载慢",可能的原因:
- 数据量过大(后端问题)
- 组件重复渲染(前端问题)
- 图片未优化(资源问题)
- 网络请求过多(架构问题)
- 第三方脚本拖慢(外部问题)
如果直接让 AI 调试,它需要:
- 查看完整的组件代码
- 分析数据流
- 检查网络请求
- 理解业务逻辑
而你自己用 Chrome DevTools 5 分钟就能定位问题所在,然后让 AI 针对性地优化。
4. 需要业务判断的架构决策
markdown
<!-- ❌ 不适合 AI -->
我们的状态管理该用 Redux 还是 Zustand?
<!-- ✅ 需要综合考虑 -->
需要考虑:
- 团队技术栈熟悉度
- 项目规模和复杂度
- 现有代码库情况
- 性能要求
- 开发效率要求实际场景:
选择状态管理方案时,AI 可能给出:
- Redux:生态完善,适合大型项目
- Zustand:轻量简洁,适合中小项目
但实际需要考虑:
- 团队是否熟悉 Redux Toolkit?
- 是否需要时间旅行调试?
- 是否有复杂的异步逻辑?
- 项目会发展到多大规模?
- DevOps 是否支持对应的调试工具?
这些判断需要结合团队实际情况,AI 无法替代。
AI 擅长的任务
AI 非常擅长完成明确任务,大任务可以借助上文提到的 plan 模式拆解为小的明确任务,并让 AI 逐步验证完成。小任务典型的有:
1. 生成重复性代码
typescript
根据这个 User 类型,生成 CRUD API 函数:
interface User {
id: string;
name: string;
email: string;
role: "admin" | "user";
}
需要:createUser, updateUser, deleteUser, getUser, listUsers实际收益:假设手写这 5 个函数,每个包含类型定义、参数校验、API 调用、错误处理,手写需要 30-40 分钟,AI 生成只需 1 分钟,且代码风格统一。
2. 代码转换和迁移
markdown
<!-- ✅ 适合 AI -->
把 @components 目录下所有 .jsx 文件转换为 TypeScript:
1. 转换要求:
- 为所有 props 添加 TypeScript 接口定义
- useState、useRef 等 Hook 添加泛型类型
- 事件处理函数添加明确的事件类型
2. 验证:转换后运行 tsc --noEmit 确保无类型错误实际收益:假设有 50 个组件文件需要迁移,手动迁移每个文件 15-20 分钟 = 12-16 小时;AI 辅助每个文件 2-3 分钟(AI 生成 + 人工审查)= 2-3 小时。
3. 补充测试用例
markdown
<!-- ✅ 适合 AI -->
为 @utils/date.ts 中的所有函数生成单元测试:
1. 测试框架:Vitest
2. 覆盖场景:
- 正常输入的预期输出
- 边界值(空字符串、null、undefined)
- 异常值(无效日期格式)
3. 覆盖率目标:至少 90%实际示例:
typescript
describe("formatDate", () => {
it("should format date to YYYY-MM-DD", () => {
expect(formatDate(new Date("2024-01-15"))).toBe("2024-01-15");
});
it("should handle invalid date", () => {
expect(formatDate("invalid")).toBe("Invalid Date");
});
it("should handle null input", () => {
expect(formatDate(null)).toBe("");
});
});4. 生成文档和注释
markdown
<!-- ✅ 适合 AI -->
为 @hooks/useAuth.ts 生成完整文档:
1. JSDoc 注释(@param、@returns、@example)
2. README.md(功能概述、API 文档、使用示例)
3. 类型导出(导出所有公共类型接口)实际示例:
typescript
/**
* 用户认证状态管理 Hook
*
* @returns {UseAuthReturn} 认证状态和操作方法
*
* @example
* ``` tsx
* function LoginPage() {
* const { user, login, logout } = useAuth()
* return <button onClick={logout}> 登出 </button>
* }
* ```
*/
export function useAuth(): UseAuthReturn {
// ...
}总结
高效使用 AI 编程工具的核心原则:
- 先规划后实施 - 复杂任务先让 AI 制定方案,再分步执行验证
- 明确清晰的指令 - 提供上下文,用 @ 定位代码,说明为什么而非仅做什么
- 管理好上下文 - 规范文档化 (Rules/CLAUDE.md),善用 Memory,及时开启新对话
- 让 AI 做擅长的事 - 重复性代码、代码转换、测试文档交给 AI;复杂重构和调试需人机协作
- 持续优化工作流 - 记录错误写入规范,沉淀提示词模板
最后谈谈 AI 焦虑
AI 是强大助手而非万能工具。要用好 AI,其中光是上下文管理往往需要工程化思维和项目架构能力,而这些能力往往需要开发者多年积累才能培养。用 AI 完成一个新项目很容易,但维护一个存量项目并持续发展演进,不仅对模型本身有高要求,对开发者本身也有高要求。一个长期演进的 AI 项目,其架构能力不会超过,或不会超过太多使用 AI 来开发这个项目的人本身的水平。如果没有这些技术认知,项目内部很快会变得一团乱麻,空留下一摊比开发新手写的还难以维护的屎山代码。
所以随着越深度使用,就越会对 AI 祛魅。这里的祛魅并不是说不去使用 AI,而是理解 AI 能力边界,并通过架构、工程手段规范工作方式,建立高效协作流程,真正提升使用 AI 效率和代码质量。这些都是开发者相比于非开发者的优势。
AI 也能让开发者从代码细节中抽身出来,让我们能有空余从 Tech Leader 的角度思考项目的架构级别设计和演进,关注 性能、可维护性、可扩展性。提升问题抽象和解决问题的能力,培养架构师的能力依旧是在 AI 时代获得竞争力的有效手段。而通过 AI 也能让我们更快拓展和更新自己的上下文,提升学习效率。
欢迎关注笔者的个人公众号,共同学习,共同前进🤗
